Use Cases
The use cases below describe many applications of tabular data. Whilst there are many different variations of tabular data, all the examples conform to the definition of tabular data defined in the Model for Tabular Data and Metadata on the Web [[!tabular-data-model]]:
Tabular data is data that is structured into rows, each of which contains information about some thing. Each row contains the same number of fields (although some of these fields may be empty), which provide values of properties of the thing described by the row. In tabular data, fields within the same column provide values for the same property of the thing described by the particular row.
In selecting the use cases we have reviewed a number of row oriented data formats that, at first glance, appear to be tabular data. However, closer inspection indicates that one or other of the characteristics of tabular data were not present. For example, the HL7 format, from the health informatics domain defines a separate schema for each row (known as a "segment" in that format) which means that HL7 messages do not have a regular number of columns for each row.
Use Case #1 - Digital preservation of government records
(Contributed by Adam Retter; supplemental information about use of XML provided by Liam Quin)
The laws of England and Wales place obligations upon departments and The National Archives for the collection, disposal and preservation of records. Government departments are obliged within the Public Records Act 1958 sections 3, 4 and 5 to select, transfer, preserve and make available those records that have been defined as public records. These obligations apply to records in all formats and media, including paper and digital records. Details concerning the selection and transfer of records can be found here.
Departments transferring records to TNA must catalogue or list the selected records according to The National Archives' defined cataloguing principles and standards. Cataloguing is the process of writing a description, or Transcriptions of Records for the records being transferred. Once each Transcription of Records is added to the Records Catalogue, records can be subsequently discovered and accessed using the supplied descriptions and titles.
TNA specifies what information should be provided within a Transcriptions of Records and how that information should be formatted. A number of formats and syntaxes are supported, including RDF. However, the predominant format used for the exchange of Transcriptions of Records is CSV as the government departments providing the Records lack either the technology or resources to provide metadata in the XML and RDF formats preferred by the TNA.
A CSV-encoded Transcriptions of Records typically describes a set of Records, often organised within a hierarchy. As a result, it is necessary to describe the interrelationships between Records within a single CSV file.
Each row within a CSV file relates to a particular Record and is allocated a unique identifier. This unique identifier behaves as a primary key for the Record within the scope of the CSV file and is used when referencing that Record from within other Record transcriptions. The unique identifier is unique within the scope of the datafile; in order for the Record to be referenced from outside this datafile, the local identifier must be mapped to a globally unique identifier such as a URI.
Requires: PrimaryKey, URIMapping and ForeignKeyReferences.
Upon receipt by TNA, each of the Transcriptions of Records is validated against the (set of) centrally published data definition(s); it is essential that received CSV metadata comply with these specifications to ensure efficient and error free ingest into the Records Catalogue.
The validation applied is dependent the type of entity described in each row. Entity type
is specified in a specific column (e.g. type).
The data definition file, or CSV Schema, used by the CSV Validation Tool effectively forms the basis of a formal contract between TNA and supplying organisations. For more information on the CSV Validation Tool and CSV Schema developed by TNA please refer to the online documentation.
The CSV Validation Tool is written in Scala version 2.10.
Requires: WellFormedCsvCheck and CsvValidation.
Following validation, the CSV-encoded Transcriptions of Records are transformed into RDF for insertion into the triple store that underpins the Records Catalogue. The CSV is initially transformed into an interim XML format using XSLT and then processed further using a mix of XSLT, Java and Scala to create RDF/XML. The CSV files do not include all the information required to undertake the transformation, e.g. defining which RDF properties are to be used when creating triples for the data value in each cell. As a result, bespoke software has been created by TNA to supply the necessary additional information during the CSV to RDF transformation process. The availability of generic mechanisms to transform CSV to RDF would reduce the burden of effort within TNA when working with CSV files.
Requires: SyntacticTypeDefinition, SemanticTypeDefinition and CsvToRdfTransformation.
In this particular case, RDF is the target format for the conversiono f the CSV-encoded Transcriptions of Records. However, the conversion of CSV to XML (in this case used as an interim conversion step) is illustrative of a common data conversion workflow.
The transformation outlined above is typical of common practice in that it uses a freely-available XSLT transformation or XQuery parser (in this case Andrew Wlech's CSV to XML converter in XSLT 2.0) which is then modified to meet the specific usage requirements.
The resulting XML document can then be used include further transformed using XSLTto create XHTML documention - perhaps including charts such histograms to present summary data.
Requires: CsvToXmlTransformation.
Use Case #2 - Publication of National Statistics
(Contributed by Jeni Tennison)
The Office for National Statistics (ONS) is the UK’s largest independent producer of official statistics and is the recognised national statistical institute for the UK. It is responsible for collecting and publishing statistics related to the economy, population and society at national, regional and local levels.
Sets of statistics are typically grouped together into datasets comprising of collections of related tabular data. Within their underlying information systems, ONS maintains a clear separation between the statistical data itself and the metadata required for interpretation. ONS classify the metadata into two categories:
- structural metadata: dimensionality, sort order, axis metadata, axis ordering etc.
- reference metadata: linked descriptive information.
These datasets are published on-line in both CSV format and as Microsoft Excel Workbooks that have been manually assembled from the underlying data.
For example, refer to dataset QS601EW Economic activity, derived from the 2011 Census, is available as a precompiled Microsoft Excel Workbook for several sets of administrative geographies, e.g. 2011 Census: QS601EW Economic activity, local authorities in England and Wales, and in CSV form via the ONS Data Explorer.
The ONS Data Explorer presents the user with a list of available datasets. A user may choose to browse through the entire list or filter that list by topic. To enable the user to determine whether or not a dataset meets their need, summary information is available for each dataset.
QS601EW Economic activity provides the following summary information:
- title: Economic activity
- dimensions: Economic activity (T016A), 2011 Administrative Hierarchy, 2011 Westminster Parliamentary Constituency Hierarchy
- dataset population: All usual residents aged 16 to 74
- coverage: England and Wales
- area types (list omitted here for brevity)
- textual description of dataset
- publication information
- contact details
Requires: AnnotationAndSupplementaryInfo.
Once the required dataset has been selected, the user is prompted to choose how they would like the statistical data to be aggregated. In the case of QS601EW Economic activity, the user is required to choose between the two mutually exclusive geography types: 2011 Administrative Hierarchy and 2011 Westminster Parliamentary Constituency Hierarchy. Effectively, the QS601EW Economic activity dataset is partitioned into two separate tables for publication.
Requires: GroupingOfMultipleTables.
The user is also provided with an option to sub-select only the elements of the dataset that they deem pertinent for their needs. In the case of QS601EW Economic activity the user may select data from upto 200 geographic areas within the dataset to create a data subset that meets their needs. The data subset may be viewed on-line (presented as an HTML table) or downloaded in CSV or Microsoft Excel formats.
Requires: CsvAsSubsetOfLargerDataset.
An example extract of data for England and Wales in CSV form is provided below. The data subset is provided as a compressed file containing both a CSV formatted data file and a complementary html file containing the reference metadata. White space has been added for clarity. File = CSV_QS601EW2011WARDH_151277.zip
"QS601EW"
"Economic activity"
"19/10/13"
, , "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count", "Count"
, , "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person", "Person"
, , "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)", "Economic activity (T016A)"
"Geographic ID","Geographic Area","Total: All categories: Economic activity","Total: Economically active: Total","Economically active: Employee: Part-time","Economically active: Employee: Full-time","Economically active: Self-employed with employees: Part-time","Economically active: Self-employed with employees: Full-time","Economically active: Self-employed without employees: Part-time","Economically active: Self-employed without employees: Full-time","Economically active: Unemployed","Economically active: Full-time student","Total: Economically inactive: Total","Economically inactive: Retired","Economically inactive: Student (including full-time students)","Economically inactive: Looking after home or family","Economically inactive: Long-term sick or disabled","Economically inactive: Other"
"E92000001", "England", "38881374", "27183134", "5333268", "15016564", "148074", "715271", "990573", "1939714", "1702847", "1336823", "11698240", "5320691", "2255831", "1695134", "1574134", "852450"
"W92000004", "Wales", "2245166", "1476735", "313022", "799348", "7564", "42107", "43250", "101108", "96689", "73647", "768431", "361501", "133880", "86396", "140760", "45894"
Key characteristics of the CSV file are:
- summary information for entire table provided at beginning of file
- multiple header lines
- comma delimited cells
- double quote escaping of text
Requires: MultipleHeadingRows and AnnotationAndSupplementaryInfo.
Correct interpretation of the statistics requires additional qualification or awareness of context. To achieve this the complementary html file includes supplementary information and annotations pertinent to the data published in the accompanying CSV file. Annotation or references may be applied to:
- a group of tables
- an entire table
- a row
- a coloumn
- an individual cell
Requires: AnnotationAndSupplementaryInfo.
Furthermore, these statistical data sets make frequent use of predefined category codes and geographic regions. Dataset QS601EW Economic activity includes two examples:
- topic category
T016A; identifying the statistical measure type - in this case, whether a person aged 16 or over was in work or looking for work in the week before the census - geographic area codes for 2011 Administrative Hierarchy and 2011 Westminster Parliamentary Constituency Hierarchy
At present there is no standardised mechanism to associate the catagory codes, provided as plain text, with their authoritative definitions.
Requires: AssociationOfCodeValuesWithExternalDefinitions.
Finally, reuse of the statistical data is also inhibited by a lack of explicit definition of the meaning of column headings.
Requires: SemanticTypeDefinition.
Use Case #3 - Creation of consolidated global land surface temperature climate databank
(Contributed by Jeremy Tandy)
Climate change and global warming have become one of the most pressing environmental concerns in society today. Crucial to predicting future change is an understanding of how the world’s historical climate, with long duration instrumental records of climate being central to that goal. Whilst there is an abundance of data recording the climate at locations the world over, the scrutiny under which climate science is put means that much of this data remains unused leading to a paucity of data in some regions with which to verify our understanding of climate change.
The International Surface Temperature Initiative seeks to create a consolidated global land surface temperatures databank as an open and freely available resource to climate scientists.
To achieve this goal, climate datasets, known as “decks”, are gathered from participating organisations and merged into a combined dataset using a scientifically peer reviewed method which assesses the data records for inclusion against a variety of criteria.
Given the need for openness and transparency in creating the databank, it is essential that the provenance of the source data is clear. Original source data, particularly for records captured prior to the mid-twentieth century, may be in hard-copy form. In order to incorporate the widest possible scope of source data, the International Surface Temperature Initiative is supported by data rescue activities to digitise hard copy records.
The data is, where possible, published in the following four stages:
- Stage 0: raw digital image of hard copy records or information as to hard copy location
- Stage 1: data in native format provided
- Stage 2: data converted into a common format and with provenance and version control information appended
- Stage 3: merged collation of stage 2 data within a single consolidated dataset
The Stage 1 data is typically provided in tabular form - the most common variant is
white-space delimited ASCII files. Each data deck comprises multiple files which are
packaged as a compressed tar ball (.tar.gz). Included within the compressed
tar ball package, and provided alongside, is a read-me file providing unstructured
supplementary information. Summary information is often embedded at the top of each
file.
For example, see the Ugandan Stage 1 data deck (local copy) and associated readme file (local copy).
The Ugandan Stage 1 data deck appears to be comprised of two discrete datasets, each
partitioned into a sub-directory within the tar ball: uganda-raw and
uganda-bestguess. Each sub-directory includes a Microsoft Word document
providing supplementary information about the provenance of the dataset; of particular
note is that uganda-raw is collated from 9 source datasets whilst
uganda-bestguess provides what is considered by the data publisher to be
the best set of values with duplicate values discarded.
Requires: AnnotationAndSupplementaryInfo.
Dataset uganda-raw is split into 96 discrete files, each providing maximum,
minimum or mean monthly air temperature for one of the 32 weather observation stations
(sites) included in the data set. Similarly, dataset uganda-bestguess is
partitioned into discrete files; this case just 3 files each of which provide maximum,
minimum or mean monthly air temperature data for all sites. The mapping from data file to
data sub-set is described in the Microsoft Word document.
Requires: CsvAsSubsetOfLargerDataset.
A snippet of the data indicating maximum monthly temperature for Entebbe, Uganda, from
uganda-raw is provided below. File = 637050_ENTEBBE_tmx.txt
637050 ENTEBBE
5
ENTEBBE BEA 0.05 32.45 3761F
ENTEBBE GHCNv3G 0.05 32.45 1155M
ENTEBBE ColArchive 0.05 32.45 1155M
ENTEBBE GSOD 0.05 32.45 1155M
ENTEBBE NCARds512 0.05 32.755 1155M
Tmax
{snip}
1935.04 27.83 27.80 27.80 -999.00 -999.00
1935.12 25.72 25.70 25.70 -999.00 -999.00
1935.21 26.44 26.40 26.40 -999.00 -999.00
1935.29 25.72 25.70 25.70 -999.00 -999.00
1935.37 24.61 24.60 24.60 -999.00 -999.00
1935.46 24.33 24.30 24.30 -999.00 -999.00
1935.54 24.89 24.90 24.90 -999.00 -999.00
{snip}
The key characteristics are:
- white space delimited; this is not strictly a CSV file
- summary information pertinent to the “data rows” is included at the beginning of the data file
- row, column and cell value interpretation is informed by accompanying Microsoft Word document; human intervention is required to unambiguously determine semantics, e.g. the meaning of each column, the unit of measurement
- the observed property is defined as “Tmax”; there is no reference to an authoritative definition describing that property
- there is no header line providing column names
- the year and month (column 1) is expressed as a decimal value; e.g. 1901.04 – equivalent to January, 1901
- multiple temperature values (“replicates”) are provided for each row; one from each of
the sources defined in the header, e.g.
BEA(British East Africa),GHCNv3G,ColArchive,GSODandNCARds512 - the provenance of specific cell values cannot be asserted; for example, data values for 1935 observed at Entebbe are digitised from digital images published in PDF (local copy)
A snippet of the data indicating maximum monthly temperature for all stations in Uganda
from uganda-bestguess is provided below (truncated to 9 columns). File = ug_tmx_jrc_bg_v1.0.txt
ARUA BOMBO BUKALASA BUTIABA DWOLI ENTEBBE AIR FT PORTAL GONDOKORO […]
{snip}
1935.04 -99.00 -99.00 -99.00 -99.00 -99.00 27.83 -99.00 -99.00 […]
1935.12 -99.00 -99.00 -99.00 -99.00 -99.00 25.72 -99.00 -99.00 […]
1935.21 -99.00 -99.00 -99.00 -99.00 -99.00 26.44 -99.00 -99.00 […]
1935.29 -99.00 -99.00 -99.00 -99.00 -99.00 25.72 -99.00 -99.00 […]
1935.37 -99.00 -99.00 -99.00 -99.00 -99.00 24.61 -99.00 -99.00 […]
1935.46 -99.00 -99.00 -99.00 -99.00 -99.00 24.33 -99.00 -99.00 […]
1935.54 -99.00 -99.00 -99.00 -99.00 -99.00 24.89 -99.00 -99.00 […]
{snip}
Many of the characteristics concerning the “raw” file are exhibited here too. Additionally, we see that:
- the delimiter is now tab (
U+0009) - metadata is entirely missing from this file, requiring human intervention to combine
the filename token (
tmx) with supplementary information in the accompanying Microsoft Word document to determine the semantics
At present, the global surface temperature databank comprises 25 Stage 1 data decks for
monthly temperature observations. These are provided by numerous organisations in
heterogeneous forms. In order to merge these data decks into a single combined dataset,
each data deck has to be converted into a standard form. Columns consist of: station
name, latitude, longitude, altitude,
date, maximum monthly temperature, minimum monthly
temperature, mean monthly temperature plus additional provenance
information.
An example Stage 2 data file is given for Entebbe, Uganda, below. File = uganda_000000000005_monthly_stage2
{snip}
ENTEBBE 0.0500 32.4500 1146.35 193501XX 2783 1711 2247 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193502XX 2572 1772 2172 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193503XX 2644 1889 2267 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193504XX 2572 1817 2194 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193505XX 2461 1722 2092 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193506XX 2433 1706 2069 301/109/101/104/999/999/999/000/000/000/102
ENTEBBE 0.0500 32.4500 1146.35 193507XX 2489 1628 2058 301/109/101/104/999/999/999/000/000/000/102
{snip}
Because of the heterogeneity of the Stage 1 data decks, bespoke data processing programs were required for each data deck consuming valuable effort and resource in simple data pre-processing. If the semantics, structure and other supplementary metadata pertinent to the Stage 1 data decks had been machine readable, then this data homogenisation stage could have been avoided altogether. Data provenance is crucial to this initiative, therefore it would be beneficial to be able to associate the supplementary metadata without needing to edit the original data files.
Requires: R-AssociationOfCodeValuesWithExternalDefinitions, SyntacticTypeDefinition, SemanticTypeDefinition, MissingValueDefinition, NonStandardCellDelimiter and ZeroEditAdditionOfSupplementaryMetadata.
The data pre-processing tools created to parse each Stage 1 data deck into the standard Stage 2 format and the merge process to create the consolidated Stage 3 data set were written using the software most familiar to the participating scientists: Fortran 95. The merge software source code is available online. It is worth noting that this sector of the scientific community also commonly uses IDL and is gradually adopting Python as the default software language choice.
The resulting merged dataset is published in several formats – including tabular text. The GHCN-format merged dataset (available from the US National Climatic Data Center's FTP site) comprises of several files: merged data and withheld data (e.g. those data that did not meet the merge criteria) each with an associated “inventory” file.
A snippet of the inventory for merged data is provided below; each row describing one of the 31,427 sites in the dataset. File = merged.monthly.stage3.v1.0.0-beta4.inv
{snip}
REC41011874 0.0500 32.4500 1155.0 ENTEBBE_AIRPO
{snip}
The columns are: station identifier, latitude,
longitude, altitude (m) and station name. The
data is fixed format rather than delimited.
Similarly, a snippet of the merged data itself is provided. Given that the original
.dat file is a largely unmanageable 422.6 MB in size, a subset is provided.
File = merged.monthly.stage3.v1.0.0-beta4.snip
{snip}
REC410118741935TAVG 2245 2170 2265 2195 2090 2070 2059 2080 2145 2190 2225 2165
REC410118741935TMAX 2780 2570 2640 2570 2460 2430 2490 2520 2620 2630 2660 2590
REC410118741935TMIN 1710 1770 1890 1820 1720 1710 1629 1640 1670 1750 1790 1740
{snip}
The columns are: station identifier, year, quantity
kind and the quantity values for months January to December in that year. Again,
the data is fixed format rather than delimited.
Here we see the station identifier REC41011874 being used as a foreign key
to refer to the observing station details; in this case Entebbe Airport. Once again, there
is no metadata provided within the file to describe how to interpret each of the data
values.
Requires: ForeignKeyReferences.
The resulting merged dataset provides time series of how the observed climate has changed over a long duration at approximately 32000 locations around the globe. Such instrumental climate records provide a basis for climate research. However, it is well known that these climate records are usually affected by inhomogeneities (artifical shifts) due to changes in the measurement conditions (e.g. relocation, modification or recalibration of the instrument etc.). As these artificial shifts often have the same magnitude as the climate signal, such as long-term variations, trends or cycles, a direct analysis of the raw time-series data can lead to wrong conclusions about climate change.
Statistical homogenisation procedures are used to detect and correct these artificial shifts. Once detected, the raw time-series data is annotated to indicate the presence of artifical shifts in the data, details of the homogenisation procedure undertaken and, where possible, the reasons for those shifts.
Requires: AnnotationAndSupplementaryInfo.
Future iterations of the global land surface temperatures databank are aniticipated to include quality controlled (Stage 4) and homogenised (Stage 5) datasets derived from the merged dataset (Stage 3) outlined above.
Use Case #4 - Publication of public sector roles and salaries
(Contributed by Jeni Tennison)
In line with the G8 open data charter Principle 4: Releasing data for improved governance,the UK Government publishes information about public sector roles and salaries.
The collection of this information is managed by the Cabinet Office and subsequently published via the UK Government data portal at data.gov.uk.
In order to ensure a consistent return from submitting departments and agencies, the Cabinet Office mandated that each response conform to a data definition schema, which is described within a narrative PDF document. Each submission comprises a pair of CSV files - one for senior roles and another for junior roles.
Requires: GroupingOfMultipleTables, WellFormedCsvCheck and CsvValidation.
The submission for senior roles from the Higher Education Funding Council for England (HEFCE) is provided below to illustrate. White space has been added for clarity. File = HEFCE_organogram_senior_data_31032011.csv
Post Unique Reference, Name,Grade, Job Title, Job/Team Function, Parent Department, Organisation, Unit, Contact Phone, Contact E-mail,Reports to Senior Post,Salary Cost of Reports (£),FTE,Actual Pay Floor (£),Actual Pay Ceiling (£),,Profession,Notes,Valid?
90115, Steve Egan,SCS1A,Deputy Chief Executive, Finance and Corporate Resources,Department for Business Innovation and Skills,Higher Education Funding Council for England, Finance and Corporate Resources, 0117 931 7408, s.egan@hefce.ac.uk, 90334, 5883433, 1, 120000, 124999,, Finance, , 1
90250, David Sweeney,SCS1A, Director,"Research, Innovation and Skills",Department for Business Innovation and Skills,Higher Education Funding Council for England,"Research, Innovation and Skills", 0117 931 7304, d.sweeeney@hefce.ac.uk, 90334, 1207171, 1, 110000, 114999,, Policy, , 1
90284, Heather Fry,SCS1A, Director, Education and Participation,Department for Business Innovation and Skills,Higher Education Funding Council for England, Education and Participation, 0117 931 7280, h.fry@hefce.ac.uk, 90334, 1645195, 1, 100000, 104999,, Policy, , 1
90334,Sir Alan Langlands, SCS4, Chief Executive, Chief Executive,Department for Business Innovation and Skills,Higher Education Funding Council for England, HEFCE,0117 931 7300/7341,a.langlands@hefce.ac.uk, xx, 0, 1, 230000, 234999,, Policy, , 1
Similarly, a snippet of the junior role submission from HEFCE is provided. Again, white space has been added for clarity. File = HEFCE_organogram_junior_data_31032011.csv
. Parent Department, Organisation, Unit,Reporting Senior Post,Grade,Payscale Minimum (£),Payscale Maximum (£),Generic Job Title,Number of Posts in FTE, Profession
Department for Business Innovation and Skills,Higher Education Funding Council for England, Education and Participation, 90284, 4, 17426, 20002, Administrator, 2,Operational Delivery
Department for Business Innovation and Skills,Higher Education Funding Council for England, Education and Participation, 90284, 5, 19546, 22478, Administrator, 1,Operational Delivery
Department for Business Innovation and Skills,Higher Education Funding Council for England,Finance and Corporate Resources, 90115, 4, 17426, 20002, Administrator, 8.67,Operational Delivery
Department for Business Innovation and Skills,Higher Education Funding Council for England,Finance and Corporate Resources, 90115, 5, 19546, 22478, Administrator, 0.5,Operational Delivery
{snip}
Key characteristics of the CSV files are:
- single header line
- comma delimited cells
- double quote escaping of text cells including the delimiter character (comma)
Within the senior role CSV the cell Post Unique Reference provides
a primary key within the data file for each row. In addition, it provides a
unique identifier for the entity described within a given row. In order for the
entity to be referenced from outside this datafile, the local identifier
must be mapped to a globally unique identifier such as a URI.
Requires: PrimaryKey and URIMapping.
This unique identifier is referenced both from within the senior post dataset,
Reports to Senior Post, and within the junior post dataset, Reporting
Senior Post in order to determine the relationships within the organisational
structure.
Requires: ForeignKeyReferences.
For the most senior role in a given organisation, the Reports to Senior Post
cell is expressed as xx denoting that this post does not report to anyone
within the organisation.
Requires: MissingValueDefinition.
The public sector roles and salaries information is published at data.gov.uk using an interactive "Organogram Viewer" widget implemented using javascript. The HEFCE data can be visualized here. For convenience, a screenshot is provided in .
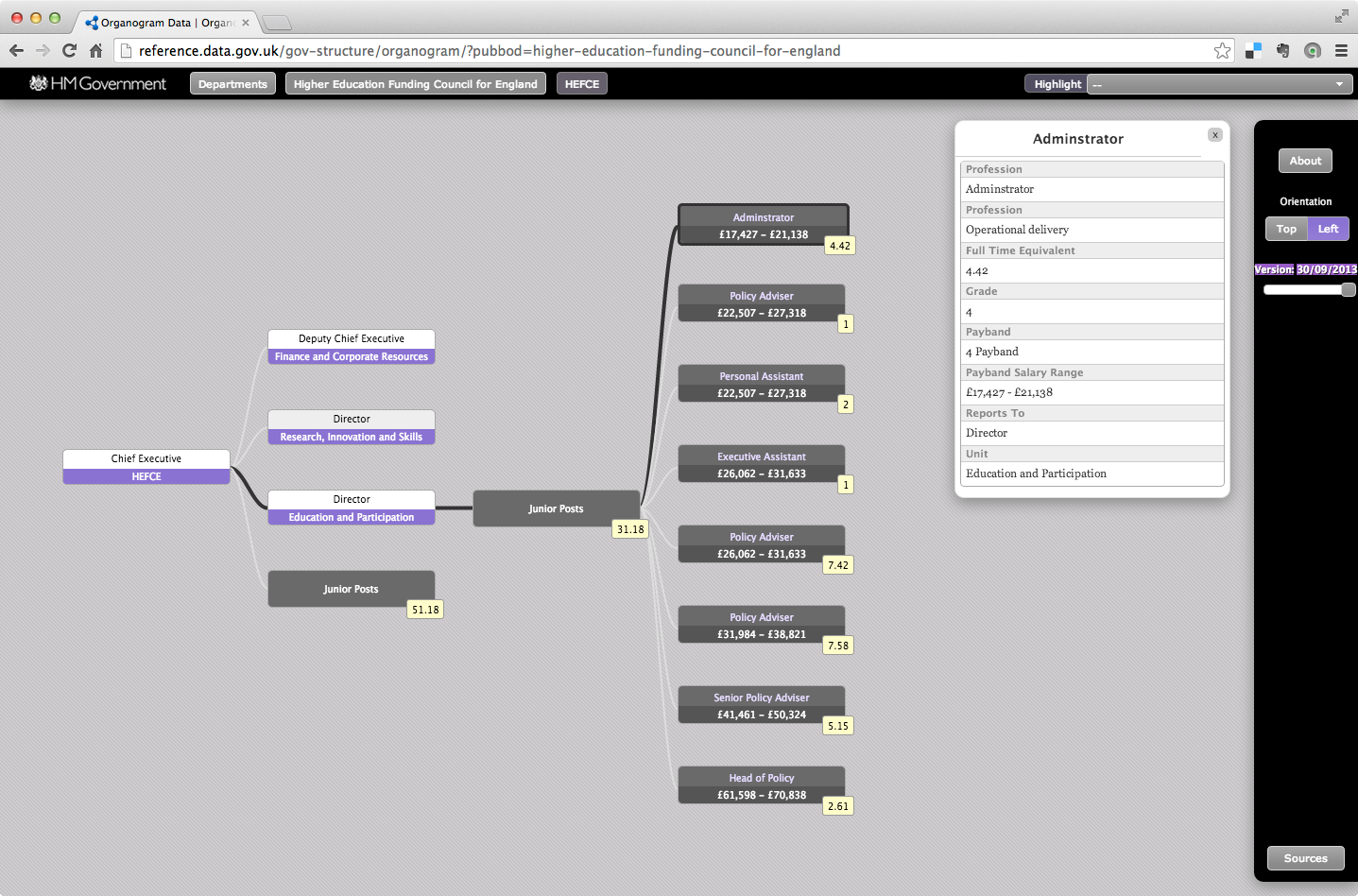
In order to create this visualization, each pair of tabular datasets were transformed into RDF and uploaded into a triple store exposing a SPARQL end-point which the interactive widget then queries to acquire the necessary data. An example of the derived RDF is provided in file HEFCE_organogram_31032011.rdf.
The transformation from CSV to RDF required bespoke software, supplementing the content in the CSV files with additional information such as the RDF properties for each column. The need to create and maintain bespoke software incurs costs that may be avoided through use of a generic CSV-to-RDF transformation mechanism.
Requires: CsvToRdfTransformation.
Use Case #5 - Publication of property transaction data
(Contributed by Andy Seaborne)
The Land Registry is the government department with responsibility to register the ownership of land and property within England and Wales. Once land or property is entered to the Land Register any ownership changes, mortgages or leases affecting that land or property are recorded.
Their Price paid data, dating from 1995 and consisting of more than 18.5 million records, tracks the residential property sales in England and Wales that are lodged for registration. This dataset is one of the most reliable sources of house price information in England and Wales.
Residential property transaction details are extracted from a data warehouse system
and collated into a tabular dataset for each month.
The current monthly dataset is available online in both .txt and
.csv formats. Snippets of data for January 2014 are provided below. White space
has been added for clarity.
pp-monthly-update.txt (local copy)
{C6428808-DC2A-4CE7-8576-0000303EF81B},137000,2013-12-13 00:00, "B67 5HE","T","N","F","130","", "WIGORN ROAD", "", "SMETHWICK", "SANDWELL", "WEST MIDLANDS","A"
{16748E59-A596-48A0-B034-00007533B0C1}, 99950,2014-01-03 00:00, "PE3 8QR","T","N","F", "11","", "RISBY","BRETTON","PETERBOROUGH","CITY OF PETERBOROUGH","CITY OF PETERBOROUGH","A"
{F10C5B50-92DD-4A69-B7F1-0000C3899733},355000,2013-12-19 00:00,"BH24 1SW","D","N","F", "55","","NORTH POULNER ROAD", "", "RINGWOOD", "NEW FOREST", "HAMPSHIRE","A"
{snip}
pp-monthly-update-new-version.csv (local copy)
"{C6428808-DC2A-4CE7-8576-0000303EF81B}","137000","2013-12-13 00:00", "B67 5HE","T","N","F","130","", "WIGORN ROAD", "", "SMETHWICK", "SANDWELL", "WEST MIDLANDS","A"
"{16748E59-A596-48A0-B034-00007533B0C1}", "99950","2014-01-03 00:00", "PE3 8QR","T","N","F", "11","", "RISBY","BRETTON","PETERBOROUGH","CITY OF PETERBOROUGH","CITY OF PETERBOROUGH","A"
"{F10C5B50-92DD-4A69-B7F1-0000C3899733}","355000","2013-12-19 00:00","BH24 1SW","D","N","F", "55","","NORTH POULNER ROAD", "", "RINGWOOD", "NEW FOREST", "HAMPSHIRE","A"
{snip}
There seems to be little difference between the two formats with the exception that all
cells within the .csv file are escaped with a pair of double quotes ("").
The header row is absent. Information regarding the meaning of each column and the abbreviations used within the dataset are provided in a complementary FAQ document. The column headings are provided below along with some supplemental detail:
Transaction unique identifierPrice- sale price stated on the Transfer deedDate of Transfer- date when the sale was completed, as stated on the Transfer deedPostcodeProperty Type-D(detatched),S(semi-detatched),T(terraced),F(flats/maisonettes)Old/New-Y(newly built property) andN(established residential building)Duration- relates to tenure;F(freehold) andL(leasehold)PAON- Primary Addressable Object NameSAON- Secondary Addressable Object NameStreetLocalityTown/CityLocal AuthorityCountyRecord status- indicates status of the transaction;A(addition of a new transaction),C(correction of an existing transaction) andD(deleted transaction)
Requires: AnnotationAndSupplementaryInfo.
Each row, or record, within the tabular dataset describes a property transaction. The
Transaction unique identifier column provides a unique identifier for that
property transaction. Given that transactions may be amended, this identifier cannot
be treated as a primary key for rows within the dataset as the identifier may occur
more than once. the primary key for each record. In order for the
property transaction to be referenced from outside this dataset, the local identifier
must be mapped to a globally unique identifier such as a URI.
Requires: URIMapping.
Each transaction record makes use of predefined category codes as outlined above; e.g.
Duration may be F (freehold) or L (leasehold). Furthermore,
geographic descriptors are commonly used. Whilst there is no attempt to
link these descriptors to specific geographic identifiers, such a linkage is likely
to provide additional utility when aggregating transaction data by location or region for further
analysis. At present there is no standardised mechanism to associate the catagory codes,
provided as plain text, or geographic identifiers with their authoritative definitions.
Requires: AssociationOfCodeValuesWithExternalDefinitions.
The collated monthly transaction dataset is used as the basis for updating the Land Registry's information systems; in this case the data is persisted as RDF triples within a triple store. A SPARQL end-point and accompanying data definitions are provided by the Land Registry allowing users to query the content of the triple store.
In order to update the triple store, the monthly transaction dataset is converted into RDF. The
value of the Record status cell for a given row informs the update process: add, update or
delete. Bespoke software has been created by the Land Registry to transformation from CSV to RDF.
The transformation requires supplementary information not present in the CSV, such as the RDF
properties for each column specified in the
data definitions. The need to create and maintain bespoke software incurs costs that may
be avoided through use of a generic CSV-to-RDF transformation mechanism.
Requires: CsvToRdfTransformation.
The monthly transaction dataset contains in the order of 100,000 records; any transformation will need to scale accordingly.
In parallel to providing access via the SPARQL end-point, the Land Registry also provides aggregated sets of transaction data. Data is available as a single file containing all transactions since 1995, or partitioned by year. Given that the complete dataset is approaching 3GB in size, the annual partitions provide a far more manageable method to download the property transaction data. However, each annual partition is only a subset of the complete dataset. It is important to be able to both make assertions about the complete dataset (e.g. publication date, license etc.) and to be able to understand how an annual partition relates to the complete dataset and other partitions.
Requires: CsvAsSubsetOfLargerDataset.
Use Case #6 - Journal Article Solr Search Results
(Contributed by Alf Eaton)
When performing literature searches researchers need to retain a persisted collection of journal articles of interest in a local database compiled from on-line publication websites. In this use case a researcher wants to retain a local personal journal article publication database based on the search results from Public Library of Science. PLOS One is a nonprofit open access scientific publishing project aimed at creating a library of open access journals and other scientific literature under an open content license.
In general this use case also illustrates the utility of CSV as a convenient exchange format for pushing tabular data between software components:
- making it easier to interpret the data on subsequent ingest
- being able to work with manageable chunks of a tabular data set (e.g. only subsets of the tabular dataset are ever materialised in a single CSV file, and we often want to know how that subset fits within the larger whole).
The PLOS website features a Solr index search engine (Live Search) which can return query results in XML, JSON or in a more concise CSV format. The output from the CSV Live Search is illustrated below:
id,doi,publication_date,title_display,author
10.1371/journal.pone.0095131,10.1371/journal.pone.0095131,2014-06-05T00:00:00Z,"Genotyping of French <i>Bacillus anthracis</i> Strains Based on 31-Loci Multi Locus VNTR Analysis: Epidemiology, Marker Evaluation, and Update of the Internet Genotype Database","Simon Thierry,Christophe Tourterel,Philippe Le Flèche,Sylviane Derzelle,Neira Dekhil,Christiane Mendy,Cécile Colaneri,Gilles Vergnaud,Nora Madani"
10.1371/journal.pone.0095156,10.1371/journal.pone.0095156,2014-06-05T00:00:00Z,Pathways Mediating the Interaction between Endothelial Progenitor Cells (EPCs) and Platelets,"Oshrat Raz,Dorit L Lev,Alexander Battler,Eli I Lev"
10.1371/journal.pone.0095275,10.1371/journal.pone.0095275,2014-06-05T00:00:00Z,Identification of Divergent Protein Domains by Combining HMM-HMM Comparisons and Co-Occurrence Detection,"Amel Ghouila,Isabelle Florent,Fatma Zahra Guerfali,Nicolas Terrapon,Dhafer Laouini,Sadok Ben Yahia,Olivier Gascuel,Laurent Bréhélin"
10.1371/journal.pone.0096098,10.1371/journal.pone.0096098,2014-06-05T00:00:00Z,Baseline CD4 Cell Counts of Newly Diagnosed HIV Cases in China: 2006–2012,"Houlin Tang,Yurong Mao,Cynthia X Shi,Jing Han,Liyan Wang,Juan Xu,Qianqian Qin,Roger Detels,Zunyou Wu"
10.1371/journal.pone.0097475,10.1371/journal.pone.0097475,2014-06-05T00:00:00Z,Crystal Structure of the Open State of the <i>Neisseria gonorrhoeae</i> MtrE Outer Membrane Channel,"Hsiang-Ting Lei,Tsung-Han Chou,Chih-Chia Su,Jani Reddy Bolla,Nitin Kumar,Abhijith Radhakrishnan,Feng Long,Jared A Delmar,Sylvia V Do,Kanagalaghatta R Rajashankar,William M Shafer,Edward W Yu"
Versions of the search results provided at time of writing are available locally in XML, JSON and CSV formats for reference.
A significant difference between the CSV formatted results and those of JSON
and XML is the absence of information about how the set of results provided in the HTTP response fit within
the complete set of results that match the Live Search request. The information provided
in the JSON and XML search results states both the total number of "hits" for the Live
Search request and the start index within the complete set (zero for the example provided
here as the ?start={offset} query parameter is absent from the request).
Other common methods of splitting up large datasets into manageable chunks include partitioning by time (e.g. all the records added to a dataset in a given day may be exported in a CSV file). Such partitioning allows regular updates to be shared. However, in order to recombine those time-based partitions into the complete set, one needs to know the datetime range for which that dataset partition is valid. Such information should be available within a CSV metadata description.
Requires: CsvAsSubsetOfLargerDataset.
To be useful to a user maintaining a PLOS One search results need to be returned in an organized and consistent tabular format. This includes:
- mapping search critiera cells to columns returned in the search results
- ordering the columns to match the order of the search criteria cells.
Lastly because the researcher may use different search criteria the header row plays an important role later for the researcher wanting to combine multiple literature searches into their database. The researcher will use the header column names returned in the first row as a way to identify each column type.
Requires: WellFormedCsvCheck and CsvValidation.
Search results returned in a tabular format can contain cell values that organized in data structures also known as micro formats. In example above the publication_date and authors list represent two micro formats that are represented in a recognizable pattern that can be parsed by software or by the human reader. In the case of the author column, microformats provide the advantage of being able to store a single author's name or multiple authors names separated by a comma delimiter. Because each author cell value is surrounded by quotes a parser can choose to ignore the data structure or address it.
Furthermore, note that the values of the title_display column contain markup. Whilst
these values may be treated as pure text, it provides an example of how structure or
syntax may be embedded within a cell.
Requires: CellMicrosyntax and RepeatedProperties.
Use Case #7 - Reliability Analyzes of Police Open Data
(Contributed by Davide Ceolin)
Several Web sources expose datasets about UK crime statistics. These datasets vary in format (e.g. maps vs. CSV files), timeliness, aggregation level, etc. Before being published on the Web, these data are processed to preserve the privacy of the people involved, but again the processing policy varies from source to source.
Every month, the UK Police Home Office publishes (via data.police.uk) CSV files that report crime counts, aggregated on geographical basis (per address or police neighbourhood) and on type basis. Before publishing, data are smoothed, that is, grouped in predefined areas and assigned to the mid point of each area. Each area has to contain a minimum number of physical addresses. The goal of this procedure is to prevent the reconstruction of the identity of the people involved in the crimes.
Over time, the policies adopted for preprocessing these data have changed, but data previously published have not been recomputed. Therefore, datasets about different months present relevant differences in terms of crime types reported and geographical aggregation (e.g. initially, each geographical area for aggregation had to include at least 12 physical addresses. Later, this limit was lowered to 8).
These policies introduce a controlled error in the data for privacy reasons, but these changes in the policies imply the fact that different datasets adhere differently to the real data, i.e. they present different reliability levels. Previous work provided two procedures for measuring and comparing the reliability of the datasets, but in order to automate and improve these procedures, it is crucial to understand the meaning of the columns, the relationships between columns, and how the data rows have been computed.
For instance, here is a snippet from a dataset about crime happened in Hampshire in April 2012:
Month, Force, Neighbourhood, Burglary, Robbery, Vehicle crime, Violent crime, Anti-social behaviour, Other crime
{snip}
2011-04 Hampshire Constabulary, 2LE11, 2, 0, 1, 6, 14, 6
2011-04 Hampshire Constabulary, 2LE10, 1, 0, 2, 4, 15, 6
2011-04 Hampshire Constabulary, 2LE12, 3, 0, 0, 4, 25, 21
{snip}
and that dataset reports 248 entries, while in October 2012, the crime types we can see are increased to 11:
Month, Force, Neighbourhood, Burglary, Robbery, Vehicle crime, Violent crime, Anti-social behaviour, Criminal damage and arson, Shoplifting, Other theft, Drugs, Public disorder and weapons, Other crime
{snip}
2012-10,Hampshire Constabulary, 2LE11, 1, 0, 1, 2, 8, 0, 0, 1, 1, 0, 1
2012-10,Hampshire Constabulary, 1SY01, 9, 1, 12, 8, 87, 17, 12, 14, 13, 7, 4
2012-10,Hampshire Constabulary, 1SY02, 11, 0, 11, 20, 144, 39, 2, 12, 9, 8, 5
{snip}
This dataset reports 232 entries.
In order to properly handle the columns, it is crucial to understand the type of the data contained therein. Given the context, knowing this information would reveal an important part of the column meaning (e.g. to identify dates).
Requires: SyntacticTypeDefinition.
Also, it is important to understand the precise semantics of each column. This is relevant for two reasons. First, to identify relations between columns (e.g. some crime types are siblings, while other are less semantically related). Second, to identify semantic relations between columns in heterogeneous datasets (e.g. a column in one dataset may correspond to the sum of two or more columns in others).
Requires: SemanticTypeDefinition.
Lastly, datasets with different row numbers are the result of different smoothing procedures. Therefore, it would be important to trace and access their provenance, in order to facilitate their comparison.
Requires: AnnotationAndSupplementaryInfo.
Use Case #8 - Analyzing Scientific Spreadsheets
(Contributed by Alf Eaton, Davide Ceolin, Martine de Vos)
A paper published in Nature Immunology in December 2012 compared changes in expression of a range of genes in response to treatment with two different cytokines. The results were published in the paper as graphic figures, and the raw data was presented in the form of supplementary spreadsheets, as Excel files (local copy).
Having at disposal both the paper and the results, a scientist may wish to reproduce the experiment, check if the results he obtains coincide with those published, and compare those results with others, provided by different studies about the same issues.
Because of the size of the datasets and of the complexity of the computations, it could be necessary to perform such analyses and comparisons by means of properly defined software, typically by means of an R, Python or Matlab script. Such software would require as input the data contained in the Excel file. However, it would be difficult to write a parser to extract the information, for the reasons described below.
To clarify the issues related to the spreadsheet parsing and analysis, we first present an example extrapolated from it. The example below shows a CSV encoding of the original Excel speadsheet converted using Mircosoft Excel 2007. White space has been added to aid clarity. (file = ni.2449-S3.csv)
Supplementary Table 2. Genes more potently regulated by IL-15,,,,,,,,,,,,,,,,,,
, , , , , , , , , , , , , , , , , ,
gene_name, symbol, RPKM, , , , , , , , ,Fold Change, , , , , , ,
, , , 4 hour, , , ,24 hour, , , , 4 hour, , , ,24 hour, , ,
, , Cont,IL2_1nM,IL2_500nM,IL15_1nM,IL15_500nM,IL2_1nM,IL2_500nM,IL15_1nM,IL15_500nM, IL2_1nM,IL2_500nM,IL15_1nM,IL15_500nM,IL2_1nM,IL2_500nM,IL15_1nM,IL15_500nM
NM_001033122, Cd69,15.67, 46.63, 216.01, 30.71, 445.58, 9.21, 77.32, 4.56, 77.21, 2.98, 13.78, 1.96, 28.44, 0.59, 4.93, 0.29, 4.93
NM_026618, Ccdc56, 9.07, 12.55, 9.25, 5.88, 14.33, 20.08, 20.91, 11.97, 22.69, 1.38, 1.02, 0.65, 1.58, 2.21, 2.31, 1.32, 2.50
NM_008637, Nudt1, 9.31, 7.51, 8.60, 11.21, 6.84, 15.85, 25.14, 7.56, 22.77, 0.81, 0.92, 1.20, 0.73, 1.70, 2.70, 0.81, 2.45
NM_008638, Mthfd2,58.67, 33.99, 245.87, 44.66, 167.87, 55.62, 204.50, 24.52, 176.51, 0.58, 4.19, 0.76, 2.86, 0.95, 3.49, 0.42, 3.01
NM_178185,Hist1h2ao, 7.13, 16.52, 7.82, 7.79, 16.99, 75.04, 290.72, 21.99, 164.93, 2.32, 1.10, 1.09, 2.38, 10.52, 40.78, 3.08, 23.13
{snip}
As we can see from the example, the table contains several columns of data that are measurements of gene expression in cells after treatment with two concentrations of two cytokines, measured after two periods of time, presented as both actual values and fold change. This can be represented in a table, but needs 3 levels of headings and several merged cells. In fact, the first row is the title of the table, the second to fourth rows are the table headers.
We also see that the first column gene_name provides a unique identifier for the gene described in each row, with the second column symbol providing a
human readable notation for each gene - albeit a scientific human! It is necessary to determine which column, if any, provides the unique identifier for the entity which
each row describes. In order for the gene to be referenced from outside the datafile, e.g. to reconcile the information in this table with other information about the gene, the local identifier must be mapped to a globally unique identifier such as a URI.
Requires: MultipleHeadingRows and URIMapping.
The first column contains a GenBank identifier for each gene, with the column name "gene_name". The GenBank identifier provides a local identifier for each gene. This local identifier, e.g. “NM_008638”, can be converted to a fully qualified URI by adding a URI prefix, e.g. “http://www.ncbi.nlm.nih.gov/nuccore/NM_008638” allowing the gene to be uniquely and unambiguously identified.
The second column contains the standard symbol for each gene, labelled as "symbol". These appear to be HUGO gene nomenclature symbols, but as there's no mapping it's hard to be sure which namespace these symbols are from.
Requires: URIMapping.
As this spreadsheet was published as supplemental data for a journal article, there is little description of what the columns represent, even as text. There is a column labelled as "Cont", which has no description anywhere, but is presumably the background level of expression for each gene.
Requires: SyntacticTypeDefinition and SemanticTypeDefinition.
Half of the cells represent measurements, but the details of what those measurements are can only be found in the article text. The other half of the cells represent the change in expression over the background level. It is difficult to tell the difference without annotation that describes the relationship between the cells (or understanding of the nested headings). In this particular spreadsheet, only the values are published, and not the formulae that were used to calculate the derived values. The units of each cell are "expression levels relative to the expression level of a constant gene, Rpl7", described in the text of the methods section of the full article.
Requires: UnitMeasureDefinition.
The heading rows contain details of the treatment that each cell received, e.g. "4 hour, IL2_1nM". It would be useful to be able to make this machine readable (i.e. to represent treatment with 1nM IL-2 for 4 hours).
All the details of the experiment (which cells were used, how they were treated, when they were measured) are described in the methods section of the article. To be able to compare data between multiple experiments, a parser would also need to be able to understand all these parameters that may have affected the outcome of the experiment.
Requires: AnnotationAndSupplementaryInfo.
Use Case #9 - Chemical Imaging
(Contributed by Mathew Thomas)
Chemical imaging experimental work makes use of CSV formats to record its measurements. In this use case two examples are shown to depict scans from a mass spectrometer and corresponding FTIR corrected files that are saved into a CSV format automatically.
Mass Spectrometric Imaging (MSI) allows the generation of 2D ion density maps that help visualize molecules present in sections of tissues and cells. The combination of spatial resolution and mass resolution results in very large and complex data sets. The following is generated using the software Decon Tools, a tool to de-isotope MS spectra and to detect features from MS data using isotopic signatures of expected compounds, available freely at omins.pnnl.gov. The raw files generated by the mass spec instrument are read in and the processed output files are saved as CSV files for each line.
Fourier transform (FTIR) spectroscopy is a measurement technique whereby spectra are collected based on measurements of the coherence of a radiative source, using time-domain or space-domain measurements of the electromagnetic radiation or other type of radiation.
In general this use case also illustrates the utility of CSV as a means for scientists to collect and process their experimental results:
- making it easier for data to be loaded into a spreadsheet to examine results
- being able to edit or select a portion of results to be plotted
- making it possible to combine all scans to examine full 2D composite image.
The key characteristics are:
- CSV uses fixed number of cells
- First row provides header cell tags, although the FTIR header begins with a comma
- All values are comma separated, but they can be delimited by tabs as well.
- Because the data is being collected from an instrument some of the columns represent measurement values taken during the experiment.
- Left column is typically regarded as the row primary key.
Requires: WellFormedCsvCheck, CsvValidation , PrimaryKey and UnitMeasureDefinition.
Lastly, for Mass Spectrometry multiple CSV files need to be examined to view the sample image in its entirety.
Requires: CsvAsSubsetOfLargerDataset .
Below are Mass Spectrometry instrument measurements (3 of 316 CSV rows) for a single line on a sample. It gives the mass-to-charge ranges, peak values, acquisition times and total ion current.
scan_num,scan_time,type,bpi,bpi_mz,tic,num_peaks,num_deisotoped,info
1,0,1,4.45E+07,576.27308,1.06E+09,132,0,FTMS + p NSI Full ms [100.00-2000.00]
2,0.075,1,1.26E+08,576.27306,2.32E+09,86,0,FTMS + p NSI Full ms [100.00-2000.00]
3,0.1475,1,9.53E+07,576.27328,1.66E+09,102,0,FTMS + p NSI Full ms [100.00-2000.00]
Below is a example FTIR data. The files from the instrument are baseline corrected, normalized and saved as CSV files automatically. Column 1 represents the wavelength # or range and the represent different formations like bound eps (extracellular polymeric substance), lose eps, shewanella etc. Below are (5 of 3161 rows) is a example:
,wt beps,wt laeps,so16533 beps,so167333 laeps,so31 beps,so313375 lAPS,so3176345 bEPS,so313376 laEPS,so3193331 bEPS,so3191444 laeps,so3195553beps,so31933333 laeps
1999.82,-0.0681585,-0.04114415,-0.001671781,0.000589855,0.027188073,0.018877371,-0.066532177,-0.016899697,-0.077690018,0.001594551,-0.086573831,-0.08155035
1998.855,-0.0678255,-0.0409804,-0.001622611,0.000552989,0.027188073,0.01890847,-0.066132737,-0.016857071,-0.077346835,0.001733207,-0.086115107,-0.081042424
1997.89,-0.067603,-0.0410459,-0.001647196,0.000423958,0.027238845,0.018955119,-0.065904461,-0.016750515,-0.077101756,0.001733207,-0.085656382,-0.080590934
1996.925,-0.0673255,-0.04114415,-0.001647196,0.000258061,0.027289616,0.018970669,-0.065790412,-0.01664396,-0.076856677,0.001629215,-0.085281062,-0.080365189
Use Case #10 - OpenSpending Data
(Contributed by Stasinos Konstantopoulos)
The OpenSpending and the Budgit platforms provide plenty of useful datasets providing figures of national budget and spending of several countries. A journalist willing to investigate about public spending fallacies can use these data as a basis for his research, and possibly compare them against different sources. Similarly, a politician that is interested in developing new policies for development can, for instance, combine these data with those from the World Bank to identify correlations and, possibly, dependencies to leverage.
Nevertheless, these uses of these datasets are possibly undermined by the following obstacles.
There are whole collections of datasets where a single currency is implied for all amounts given. See, for example, how all Slovenian Budget Datasets are implicitly give amounts in Euros. Given that Slovenia joined the Eurozone in 2007, the currency in has changed relatively recently. How do we know if a given table expresses currency amounts in “tolar” or “Euro”?
In order to be able to compare and combine these data with those provided by other sources like the World Bank, in an automatic manner, it would be necessary to explicitly define the currency of each column. Given that the currency will be uniform for a specific table, the currency metadata may be indicated once for the entire table.
Requires: UnitMeasureDefinition.
- Similar issues are also in the Uganda Budget and Aid to Uganda, 2003-2007 file,
where there are four columns related to the amount. Of these, "amount" (Ugandan Shillings implied)
and "amount_dollars" (USD implied) are mandatory. The value of these columns is implicit, and moreover, as explained in the
complementary information, the Ugandan Shillings amount is computed by converting
the Dollars amount using a ratio determined on year basis (e.g. 2003/4: 1 USD = 1.847 UGX). Since this ratio varies on year basis,
and still corresponds to an approximation of the yearly value of the exchange rate, in order to properly use these data, it would
be preferable to know how these were obtained, or where to find such information.
Requires: AssociationOfCodeValuesWithExternalDefinitions and AnnotationAndSupplementaryInfo.
-
Again in the Uganda Budget and Aid to Uganda, 2003-2007 file, if a row represents a
donation, then the values for the "amount_donor" (the amount in the donor's original currency) and "donorcurrency" (the donor's currency name) columns of
that row are reported.
Otherwise, the corresponding values are set to "0", to indicate that the row does not represent a donation and that the only relevant amounts for that row
are reported in the "amount" and "amount_dollars" column. To make these files machine-understandable, it is necessary to make this coding explicit.
Requires: MissingValueDefinition.
The datahub.io platform that collects both OpenSpending and Budgit data allows publishing data in Simple Data Format (SDF), RDF and other formats providing explicit semantics. Nevertheless, the datasets mentioned above present either implicit semantics and/or additional metadata files provided only as attachment.
Use Case #11 - City of Palo Alto Tree Data
(Contributed by Eric Stephan)
The City of Palo Alto, California Urban Forest Section is responsible for maintaining and tracking the cities public trees and urban forest. In a W3C Data on the Web Best Practices (DWBP) use case discussion with Jonathan Reichental City of Palo Alto CIO, he brought to the working groups attention a Tree Inventory maintained by the city in a spreadsheet form using Google Fusion. This use case represents use of tabular data to be representative of geophysical tree locations also provided in Google Map form where the user can point and click on trees to look up row information about the tree.
The example below illustrates the first few rows of data:
GID,Private,Tree ID,Admin Area,Side of Street,On Street,From Street,To Street,Street_Name,Situs Number,Address Estimated,Lot Side,Serial Number,Tree Site,Species,Trim Cycle,Diameter at Breast Ht,Trunk Count,Height Code,Canopy Width,Trunk Condition,Structure Condition,Crown Condition,Pest Condition,Condition Calced,Condition Rating,Vigor,Cable Presence,Stake Presence,Grow Space,Utility Presence,Distance from Property,Inventory Date,Staff Name,Comments,Zip,City Name,Longitude,Latitude,Protected,Designated,Heritage,Appraised Value,Hardscape,Identifier,Location Feature ID,Install Date,Feature Name,KML,FusionMarkerIcon
1,True,29,,,ADDISON AV,EMERSON ST,RAMONA ST,ADDISON AV,203,,Front,,2,Celtis australis,Large Tree Routine Prune,11,1,25-30,15-30,,Good,5,,,Good,2,False,False,Planting Strip,,44,10/18/2010,BK,,,Palo Alto,-122.1565172,37.4409561,False,False,False,,None,40,13872,,"Tree: 29 site 2 at 203 ADDISON AV, on ADDISON AV 44 from pl","<Point><coordinates>-122.156485,37.440963</coordinates></Point>",small_green
2,True,30,,,EMERSON ST,CHANNING AV,ADDISON AV,ADDISON AV,203,,Left,,1,Liquidambar styraciflua,Large Tree Routine Prune,11,1,50-55,15-30,Good,Good,5,,,Good,2,False,False,Planting Strip,,21,6/2/2010,BK,,,Palo Alto,-122.1567812,37.440951,False,False,False,,None,41,13872,,"Tree: 30 site 1 at 203 ADDISON AV, on EMERSON ST 21 from pl","<Point><coordinates>-122.156749,37.440958</coordinates></Point>",small_green
3,True,31,,,EMERSON ST,CHANNING AV,ADDISON AV,ADDISON AV,203,,Left,,2,Liquidambar styraciflua,Large Tree Routine Prune,11,1,40-45,15-30,Good,Good,5,,,Good,2,False,False,Planting Strip,,54,6/2/2010,BK,,,Palo Alto,-122.1566921,37.4408948,False,False,False,,Low,42,13872,,"Tree: 31 site 2 at 203 ADDISON AV, on EMERSON ST 54 from pl","<Point><coordinates>-122.156659,37.440902</coordinates></Point>",small_green
4,True,32,,,ADDISON AV,EMERSON ST,RAMONA ST,ADDISON AV,209,,Front,,1,Ulmus parvifolia,Large Tree Routine Prune,18,1,35-40,30-45,Good,Good,5,,,Good,2,False,False,Planting Strip,,21,6/2/2010,BK,,,Palo Alto,-122.1564595,37.4410143,False,False,False,,Medium,43,13873,,"Tree: 32 site 1 at 209 ADDISON AV, on ADDISON AV 21 from pl","<Point><coordinates>-122.156427,37.441022</coordinates></Point>",small_green
5,True,33,,,ADDISON AV,EMERSON ST,RAMONA ST,ADDISON AV,219,,Front,,1,Eriobotrya japonica,Large Tree Routine Prune,7,1,15-20,0-15,Good,Good,3,,,Good,1,False,False,Planting Strip,,16,6/1/2010,BK,,,Palo Alto,-122.1563676,37.441107,False,False,False,,None,44,13874,,"Tree: 33 site 1 at 219 ADDISON AV, on ADDISON AV 16 from pl","<Point><coordinates>-122.156335,37.441114</coordinates></Point>",small_green
6,True,34,,,ADDISON AV,EMERSON ST,RAMONA ST,ADDISON AV,219,,Front,,2,Robinia pseudoacacia,Large Tree Routine Prune,29,1,50-55,30-45,Poor,Poor,5,,,Good,2,False,False,Planting Strip,,33,6/1/2010,BK,cavity or decay; trunk decay; codominant leaders; included bark; large leader or limb decay; previous failure root damage; root decay; beware of BEES.,,Palo Alto,-122.1563313,37.4411436,False,False,False,,None,45,13874,,"Tree: 34 site 2 at 219 ADDISON AV, on ADDISON AV 33 from pl","<Point><coordinates>-122.156299,37.441151</coordinates></Point>",small_green
{snip}
The complete CSV file of Palo Alto tree data is available locally - but please note that it is approximately 18MB in size.
Google Fusion allows a user to download the tree data either from a filtered view or the entire spreadsheet. The exported spreadsheet is organized and consistent tabular format. This includes:
- mapping spreadsheet cells to columns in the CSV file.
- ordering the CSV columns to match the order of the spreadsheet columns.
- The CSV file provides a primary key for each row (column
GID), a unique identifier for each tree (columnTree ID), accounts for missing data, and lists characteristics describing the condition of the tree in the comments cell using a micro syntax to delimit the characteristics list. The spreadsheet also provides geo coordinate information pinpointing each inventoried tree.
In order for information about a given tree to be reconciled with information about the same tree originating from other sources, the local identifier for that tree must be mapped to a globally unique identifier such as a URI.
Also note that in row 6, a series of statements describing the condition of the tree and other
important information are provided in the comments cell. These statements are
delimited using the semi-colon ";" character.
Requires: WellFormedCsvCheck, CsvValidation, PrimaryKey, URIMapping, MissingValueDefinition, UnitMeasureDefinition, CellMicrosyntax and RepeatedProperties.
Use Case #12 - Chemical Structures
(Contributed by Eric Stephan)
The purpose of this use case is to illustrate how 3-D molecular structures such as the Protein Data Bank and XYZ formats are conveyed in tabular formats. These files be archived to be used informatics analysis or as part of an input deck to be used in experimental simulation. Scientific communities rely heavily on tabular formats such as these to conduct their research and share each others results in platform independent formats.
The Protein Data Bank (pdb) file format is a tabular file describing the three dimensional structures of molecules held in the Protein Data Bank. The pdb format accordingly provides for description and annotation of protein and nucleic acid structures including atomic coordinates, observed sidechain rotamers, secondary structure assignments, as well as atomic connectivity.
The XYZ file format is a chemical file format. There is no formal standard and several variations exist, but a typical XYZ format specifies the molecule geometry by giving the number of atoms with Cartesian coordinates that will be read on the first line, a comment on the second, and the lines of atomic coordinates in the following lines.
In general this use case also illustrates the utility of CSV as a means for scientists to collect and process their experimental results:
- making it easier for data to be loaded into a spreadsheet to examine results
- being able to edit or select a portion of results to be plotted
- making it possible to combine all scans to examine full 2D composite image.
The key characteristics of the XYZ format are:
- CSV contains two header rows, the first row containing the number of atoms in molecule (number of rows in data block). The second is a comment line.
- Each row in the data block used a fix number of cells (atom name followed by x, y, z coordinates).
- All values are delimited by spaces.
Requires: WellFormedCsvCheck, CsvValidation, MultipleHeadingRows and UnitMeasureDefinition.
Below is a Methane molecular structure organized in an XYZ format.
5
methane molecule (in angstroms)
C 0.000000 0.000000 0.000000
H 0.000000 0.000000 1.089000
H 1.026719 0.000000 -0.363000
H -0.513360 -0.889165 -0.363000
H -0.513360 0.889165 -0.363000
The key characteristics of the PDB format are:
- Each PDB record is self describing and contains different ways to document each protein.
- Each row of the file uses a token to depict the purpose of that row.
- Tabular data rows varies fixed number of columns (e.g. ATOM) to non-fixed number of columns (SEQRES) that specify the number of columns in the row.
- Because the PDB is a fully contained self describing record it also provides multiple tables to annotate the record. Each table appears to be delimited by a line in the file "...".
Requires: GroupingOfMultipleTables.
Below is a example PDB file:
HEADER EXTRACELLULAR MATRIX 22-JAN-98 1A3I
TITLE X-RAY CRYSTALLOGRAPHIC DETERMINATION OF A COLLAGEN-LIKE
TITLE 2 PEPTIDE WITH THE REPEATING SEQUENCE (PRO-PRO-GLY)
...
EXPDTA X-RAY DIFFRACTION
AUTHOR R.Z.KRAMER,L.VITAGLIANO,J.BELLA,R.BERISIO,L.MAZZARELLA,
AUTHOR 2 B.BRODSKY,A.ZAGARI,H.M.BERMAN
...
REMARK 350 BIOMOLECULE: 1
REMARK 350 APPLY THE FOLLOWING TO CHAINS: A, B, C
REMARK 350 BIOMT1 1 1.000000 0.000000 0.000000 0.00000
REMARK 350 BIOMT2 1 0.000000 1.000000 0.000000 0.00000
...
SEQRES 1 A 9 PRO PRO GLY PRO PRO GLY PRO PRO GLY
SEQRES 1 B 6 PRO PRO GLY PRO PRO GLY
SEQRES 1 C 6 PRO PRO GLY PRO PRO GLY
...
ATOM 1 N PRO A 1 8.316 21.206 21.530 1.00 17.44 N
ATOM 2 CA PRO A 1 7.608 20.729 20.336 1.00 17.44 C
ATOM 3 C PRO A 1 8.487 20.707 19.092 1.00 17.44 C
ATOM 4 O PRO A 1 9.466 21.457 19.005 1.00 17.44 O
ATOM 5 CB PRO A 1 6.460 21.723 20.211 1.00 22.26 C
...
HETATM 130 C ACY 401 3.682 22.541 11.236 1.00 21.19 C
HETATM 131 O ACY 401 2.807 23.097 10.553 1.00 21.19 O
HETATM 132 OXT ACY 401 4.306 23.101 12.291 1.00 21.19 O
Use Case #13 - Representing Entities and Facts Extracted From Text
(Contributed by Tim Finin)
The US National Institute of Standards and Technology (NIST) has run various conferences on extracting information from text centered around challenge problems. Participants submit the output of their systems on an evaluation dataset to NIST for scoring, typically in the form of tab-separated format.
The 2013 NIST Cold Start Knowledge Base Population Task, for example, asks participants to extract facts from text and to represent these as triples along with associated metadata that include provenance and certainty values. A line in the submission format consists of a triple (subject-predicate-object) and, for some predicates, provenance information. Provenance includes a document ID and, depending on the predicate, one or three pairs of string offsets within the document. For predicates that are relations, an optional second set of provenance values can be provided. Each line can also have an optional float as a final column to represent a certainty measure.
The following lines show examples of possible triples of varying length. In the second line, D00124 is the ID of a document and the strings like 283-286 refer to strings in a document using the offsets of the first and last characters. The final floating point value on some lines is the optional certainty value.
{snip}
:e4 type PER
:e4 mention "Bart" D00124 283-286
:e4 mention "JoJo" D00124 145-149 0.9
:e4 per:siblings :e7 D00124 283-286 173-179 274-281
:e4 per:age "10" D00124 180-181 173-179 182-191 0.9
:e4 per:parent :e9 D00124 180-181 381-380 399-406 D00101 220-225 230-233 201-210
{snip}
The submission format does not require that each line have the same number of columns. The expected provenance information for a triple depends on the predicate. For example, “type” typically has no provenance, “mention” has a document ID and offset pair, and domain predicates like “per:age” have one or two provenance records each of which has a document ID and three offset pairs.
The file format exemplified above opens up for a number of issues described as follows. Each row is intended to describe an entity (e.g. the subject of the triple, “:e4”). The unique identifier for that entity is provided in the first column. In order for information about this entity to be reconcilled with information from other sources about the same entity, the local identifier needs to be mapped to a globally unique identifier such as a URI.
Requires: URIMapping.
After each triple, there is a variable number of annotations representing the provenance of the triple and, occasionally, its certainty. This information has to be properly identified and managed.
Requires: AnnotationAndSupplementaryInfo.
Entities “:e4”, “:e7” and “:e9” appear to be (foreign key) references to other entities described in this or in external tables. Likewise, also the identifiers “D00124” and “D00101” are ambiguous identifiers. It would be useful to identify the resources that these references represent.
Moreover, “per” appears to be a term from a controlled vocabulary. How do we know which controlled vocabulary it is a member of and what its authoritative definition is?
Requires: ForeignKeyReferences, AssociationOfCodeValuesWithExternalDefinitions and SemanticTypeDefinition.
The identifiers used for the entities (“:e4”, “:e7” and “:e9”), as well as those used for the predicates (e.g. “type”, “mention”, “per:siblings” etc.), are ambiguous local identifiers. How can one make the identifier an unambiguous URI? A similar requirement regards the provenance annotations. These are composed by document (e.g. “D00124”) and page number ranges. (e.g. “180-181”). Page number ranges are clearly valid only in the context of the preceding document identifier. The interesting assertion about provenance is the reference (document plus page range). Thus we might want to give the reference a unique identifier comprising from document ID and page range (e.g. D00124#180-181).
Requires: URIMapping.
Besides the entities, the table presents also some values. Some of these are strings (e.g. “10”, “Bart”), some of them are probably floating point values (e.g. “0.9”). It would be useful to have an explicit syntactic type definition for these values.
Requires: SyntacticTypeDefinition.
Entity “:e4” is the subject of many rows, meaning that many rows can be combined to make a composite set of statements about this entity.
Moreover, a single row in the table comprises a triple (subject-predicate-object), one or more provenance references and an optional certainty measure. The provenance references have been normalised for compactness (e.g. so they fit on a single row). However, each provenance statement has the same target triple so one could unbundle the composite row into multiple simple statements that have a regular number of columns (see the two equivalent examples below).
{snip}
:e4 per:age "10" D00124 180-181 173-179 182-191 0.9
:e4 per:parent :e9 D00124 180-181 381-380 399-406 D00101 220-225 230-233 201-210
{snip}
{snip}
:e4 per:age "10" D00124 180-181 0.9
:e4 per:age "10" D00124 173-179 0.9
:e4 per:age "10" D00124 182-191 0.9
:e4 per:parent :e9 D00124 180-181
:e4 per:parent :e9 D00124 381-380
:e4 per:parent :e9 D00124 399-406
:e4 per:parent :e9 D00101 220-225
:e4 per:parent :e9 D00101 230-233
:e4 per:parent :e9 D00101 201-210
{snip}
Requires: TableNormalization.
Lastly, since we already observed that rows comprise triples, that there is a frequent reference to externally defined vocabularies, that values are defined as text (literals), and that triples are also composed by entities, for which we aim to obtain a URI (as described above), it may be useful to be able to convert such a table in RDF.
Requires: CsvToRdfTransformation.
Use Case #14 - Displaying Locations of Care Homes on a Map
(Contributed by Jeni Tennison)
NHS Choices makes available a number of (what it calls) CSV files for different aspects of NHS data on its website at http://www.nhs.uk/aboutnhschoices/contactus/pages/freedom-of-information.aspx
One of the files (file = SCL.csv) contains information about the locations of care homes, as illustrated in the example below:
OrganisationID¬OrganisationCode¬OrganisationType¬SubType¬OrganisationStatus¬IsPimsManaged¬OrganisationName¬Address1¬Address2¬Address3¬City¬County¬Postcode¬Latitude¬Longitude¬ParentODSCode¬ParentName¬Phone¬Email¬Website¬Fax¬LocalAuthority
220153¬1-303541019¬Care homes and care at home¬UNKNOWN¬Visible¬False¬Bournville House¬Furnace Lane¬Lightmoor Village¬¬Telford¬Shropshire¬TF4 3BY¬0¬0¬1-101653596¬Accord Housing Association Limited¬01952739284¬¬www.accordha.org.uk¬01952588949¬
220154¬1-378873485¬Care homes and care at home¬UNKNOWN¬Visible¬True¬Ashcroft¬Milestone House¬Wicklewood¬¬Wymondham¬Norfolk¬NR18 9QL¬52.577003479003906¬1.0523598194122314¬1-377665735¬Julian Support Limited¬01953 607340¬ashcroftresidential@juliansupport.org¬http://www.juliansupport.org¬01953 607365¬
220155¬1-409848410¬Care homes and care at home¬UNKNOWN¬Visible¬False¬Quorndon Care Limited¬34 Bakewell Road¬¬¬Loughborough¬Leicestershire¬LE11 5QY¬52.785675048828125¬-1.219469428062439¬1-101678101¬Quorndon Care Limited¬01509219024¬¬www.quorndoncare.co.uk¬01509413940¬
{snip}
The file has two interesting syntactic features:
- the cell separator is the not sign (¬, \u00AC) rather than a comma
- no cells are wrapped in double quotes; some cells contain (unescaped) double quotes
Requires: WellFormedCsvCheck, SyntacticTypeDefinition and NonStandardCellDelimiter.
Our user wants to be able to embed a map of these locations easily into my web page using a web component, such that she can use markup like:
<emap src="http://media.nhschoices.nhs.uk/data/foi/SCL.csv" latcol="Latitude" longcol="Longitude">
and see a map similar to that shown at https://github.com/JeniT/nhs-choices/blob/master/SCP.geojson, without converting the CSV file into GeoJSON.
To make the web component easy to define, there should be a native API on to the data in the CSV file within the browser.
Requires: CsvToJsonTransformation.
Use Case #15 - Intelligently Previewing CSV files
(Contributed by Jeni Tennison)
All of the data repositories based on the CKAN software, such as data.gov.uk, data.gov, and many others, use JSON as the representation of the data when providing a preview of CSV data within a browser. Server side pre-processing of the CSV files is performed to try and determine column types, clean the data and transform the CSV-encoded data to JSON in order to provide the preview. JSON has many features which make it ideal for delivering a preview of the data, originally in CSV format, to the browser.
Javascript is a hard dependency for interacting with data in the browser and as such JSON was used as the serialization format because it was the most appropriate format for delivering those data. As the object notation for Javascript JSON is natively understood by Javascript it is therefore possible to use the data without any external dependencies. The values in the data delivered map directly to common Javascript types and libraries for processing and generating JSON, with appropriate type conversion, are widely available for many programming languages.
Beyond basic knowledge of how to work with JSON, there is no further burden on the user to understand complex semantics around how the data should be interpreted. The user of the data can be assured that the data is correctly encoded as UTF-8 and it is easily queryable using common patterns used in everyday Javascript. None of the encoding and serialization flaws with CSV are apparent, although badly structured CSV files will be mirrored in the JSON.
Requires: WellFormedCsvCheck and CsvToJsonTransformation.
When providing the in-browser previews of CSV-formatted data, the utility of the preview application is limited because the server-side processing of the CSV is not always able to determine the data types (e.g. date-time) associated with data columns. As a result it is not possible for the in-browser preview to offer functions such as sorting rows by date.
As an example, see the Spend over £25,000 in The Royal Wolverhampton Hospitals NHS Trust example. Note that the underlying data begins with:
"Expenditure over £25,000- Payment made in January 2014",,,,,,,, ,,,,,,,, Department Family,Entity,Date,Expense Type,Expense Area,Supplier,Transaction Number,Amount in Sterling, Department of Health,The Royal Wolverhampton Hospitals NHS Trust RL4,31/01/2014,Capital Project,Capital,STRYKER UK LTD,0001337928,31896.06, Department of Health,The Royal Wolverhampton Hospitals NHS Trust RL4,17/01/2014,SERVICE AGREEMENTS,Pathology,ABBOTT LABORATORIES LTD,0001335058,77775.13, ...
A local copy of this dataset is available: file = mth-10-january-2014.csv
The header line here comes below an empty row, and there is metadata about the table in the row above the empty row. The preview code manages to identify the headers from the CSV, and displays the metadata as the value in the first cell of the first row.
Requires: MultipleHeadingRows and AnnotationAndSupplementaryInfo.
It would be good if the preview could recognise that the Date column contains a date and that the Amount in Sterling column contains a number, so that it could offer options to filter/sort these by date/numerically.
Requires: SemanticTypeDefinition, SyntacticTypeDefinition and UnitMeasureDefinition.
Moreover, some of the values reported may refer to external definitions (from dictionaries or other sources). It would be useful to know where it is possible to find such resources, to be able to properly handle and visualize the data, by linking to them.
Requires: AssociationOfCodeValuesWithExternalDefinitions.
Lastly, the web page where the CSV is published presents also useful metadata about it. It would be useful to be able to know and access these metadata even though they are not included in the file.
These include:
- Resource title
- Publisher
- License
- Abstract / description
- Date last updated
Requires: AnnotationAndSupplementaryInfo.
Use Case #16 - Tabular Representations of NetCDF data Using CDL Syntax
(Contributed by Eric Stephan)
NetCDF is a set of binary data formats, programming interfaces, and software libraries that help read and write scientific data files. NetCDF provides scientists a means to share measured or simulated experiments with one another across the web. What makes NetCDF useful is its ability to be self describing and provide a means for scientists to rely on existing data model as opposed to needing to write their own. The classic NetCDF data model consists of variables, dimensions, and attributes. This way of thinking about data was introduced with the very first NetCDF release, and is still the core of all NetCDF files.
Among the tools available to the NetCDF community, two tools: ncdump and ncgen. The ncdump tool is used by scientists wanting to inspect variables and attributes (metadata) contained in the NetCDF file. It also can provide a full text extraction of data including blocks of tabular data representing by variables. While NetCDF files are typically written by a software client, it is possible to generate NetCDF files using ncgen and ncgen3 from a text format. The ncgen tool parses the text file and stores it in a binary format.
Both ncdump and ncgen rely on a text format to represent the NetCDF file called network Common Data form Language (CDL). The CDL syntax as shown below contains annotation along with blocks of data denoted by the "data:" key. For the results to be legible for visual inspection the measurement data is written as delimited blocks of scalar values. As shown in the example below CDL supports multiple variables or blocks of data. The blocks of data while delimited need to be thought of as a vector or single column of tabular data wrapped around to the next line in a similar way that characters can be wrapped around in a single cell block of a spreadsheet to make the spreadsheet more visually appealing to the user.
netcdf foo { // example NetCDF specification in CDL
dimensions:
lat = 10, lon = 5, time = unlimited;
variables:
int lat(lat), lon(lon), time(time);
float z(time,lat,lon), t(time,lat,lon);
double p(time,lat,lon);
int rh(time,lat,lon);
lat:units = "degrees_north";
lon:units = "degrees_east";
time:units = "seconds";
z:units = "meters";
z:valid_range = 0., 5000.;
p:_FillValue = -9999.;
rh:_FillValue = -1;
data:
lat = 0, 10, 20, 30, 40, 50, 60, 70, 80, 90;
lon = -140, -118, -96, -84, -52;
}
The next example shows a small subset of data block taken from an actual NetCDF file. The blocks of data while delimited need to be thought of as a vector or single column of tabular data wrapped around to the next line in a similar way that characters can be wrapped around in a single cell block of a spreadsheet to make the spreadsheet more visually appealing to the user.
data:
base_time = 1020770640 ;
time_offset = 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32,
34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68,
70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102,
104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130,
132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158,
160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186,
188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214,
216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242,
244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270,
272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298,
300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326,
328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354,
356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 378, 380, 382,
384, 386, 388, 390, 392, 394, 396, 398, 400, 402, 404, 406, 408, 410,
412, 414, 416, 418, 420, 422, 424, 426, 428, 430, 432, 434, 436, 438,
440, 442, 444, 446, 448, 450, 452, 454, 456, 458, 460, 462, 464, 466,
468, 470, 472, 474, 476, 478, 480, 482, 484, 486, 488, 490, 492, 494,
496, 498, 500, 502, 504, 506, 508, 510, 512, 514, 516, 518, 520, 522;
The format allows for error codes and missing values to be included.
Requires: WellFormedCsvCheck, CsvValidation, UnitMeasureDefinition, MissingValueDefinition and GroupingOfMultipleTables.
Lastly, NetCDF files are typically collected together in larger datasets where they can be analyzed, so the CSV data can be thought of a subset of a larger dataset.
Requires: CsvAsSubsetOfLargerDataset and AnnotationAndSupplementaryInfo.
Use Case #17 - Canonical mapping of CSV
(Contributed by David Booth and Jeremy Tandy)
CSV is by far the commonest format within which open data is published, and is thus typical of the data that application developers need to work with.
However, an object / object graph serialisation (of open data) is easier to consume within software applications. For example, web applications (using HTML5 & Javascript) require no extra libraries to work with data in JSON format. Similarly, RDF-encoded data in from multiple sources can be simply combined or merged using SPARQL queries once persisted within a triple store.
The UK Government policy paper "Open Data: unleashing the potential" outlines a set of principles for publishing open data. Within this document, principle 9 states:
Release data quickly, and then work to make sure that it is available in open standard formats, including linked data formats.
The open data principles recognise how the additional utility to be gained from publishing in linked data formats must be balanced against the additional effort incurred by the data publisher to do so and the resulting delay to publication of the data. Data publishers are required to release data quickly - which means making the data available in a format convenient for them such as CSV dumps from databases or spread sheets.
One of the hindrances to publishing in linked data formats is the difficulty in determining the ontology or vocabulary (e.g. the classes, predicates, namespaces and other usage patterns) that should be used to describe the data. Whilst it is only reasonable to assume that a data publisher best knows the intended meaning of their data, they cannot be expected to determine the ontology or vocabulary most applicable to to a consuming application!
Furthermore, in lieu of agreed de facto standard vocabularies or ontologies for a given application domain, it is highly likely that disparate applications will conform to different data models. How should the data publisher choose which of the available vocabularies or ontologies to use when publishing (if indeed they are aware of those applications at all)!
In order to assist data publishers provide data in linked data formats without the need to determine ontologies or vocabularies, it is necessary to separate the syntactic mapping (e.g. changing format from CSV to JSON) from the semantic mapping (e.g. defining the transformations required to achieve semantic alignment with a target data model).
As a result of such separation, it will be possible to establish a canonical transformation from CSV conforming to the core tabular data model [[!tabular-data-model]] to an object graph serialisation such as JSON.
Requires: WellFormedCsvCheck, CsvToJsonTransformation and CanonicalMappingInLieuOfAnnotation.
This use case assumes that JSON is the target serialisation for application developers given the general utility of that format. However, by considering JSON-LD [[json-ld]], it becomes trivial to map CSV-encoded tabular data via JSON into a canonical RDF model. In doing so this enables CSV-encoded tabular data to be published in linked data formats as required in the open data principle 9 at no extra effort to the data publisher as standard mechanisms are available for a data user to transform the data from CSV to RDF.
Requires: CsvToRdfTransformation.
In addition, open data principle 14 requires that:
Public bodies should publish relevant metadata about their datasets […]; and they should publish supporting descriptions of the format, provenance and meaning of the data.
To achieve this, data publishers need to be able to publish supplementary metadata concerning their tabular datasets, such as title, usage license and description.
Requires: AnnotationAndSupplementaryInfo.
Applications may automatically determine the data type (e.g. date-time, number) associated
with cells in a CSV file by parsing the data values. However, on occasion, this is prone to
mistakes where data appears to resemble something else. This is especially
prevalent for dates. For example, 1/4 is often confused with 1 April
rather than 0.25. In such situations, it is beneficial if guidance can be given to the
transformation process indicating the data type for given columns.
Requires: SyntacticTypeDefinition.
Provision of CSV data coupled with a canonical mapping provides significant utility by itself. However, there is nothing stopping a data publisher from adding annotation defining data semantics once, say, an appropriate de facto standard vocabulary has been agreed within the community of use. Similarly, a data consumer may wish to work directly with the canonical mapping and wish to ignore any semantic annotations provided by the publisher.
Use Case #18 - Supporting Semantic-based Recommendations
(Contributed by Davide Ceolin and Valentina Maccatrozzo)
In the ESWC-14 Challenge: Linked Open Data-enabled Recommender Systems, participants are provided with a series of datasets about books in TSV format.
A first dataset contains a set of user identifiers and their ratings for a bunch of books each. Each book is represented by means of a numeric identifier.
DBbook_userID, DBbook_itemID, rate
{snip}
6873, 5950, 1
6873, 8010, 1
6873, 5232, 1
{snip}
Ratings can be boolean (0,1) or Likert scale values (from 1 to 5), depending on the challenge task considered.
Requires: SyntacticTypeDefinition, SemanticTypeDefinition and NonStandardCellDelimiter.
A second file provides a mapping between book ids and their names and dbpedia URIs:
DBbook_ItemID name DBpedia_uri
{snip}
1 Dragonfly in Amber http://dbpedia.org/resource/Dragonfly_in_Amber
10 Unicorn Variations http://dbpedia.org/resource/Unicorn_Variations
100 A Stranger in the Mirror http://dbpedia.org/resource/A_Stranger_in_the_Mirror
1000 At All Costs http://dbpedia.org/resource/At_All_Costs
{snip}
Requires: ForeignKeyReferences.
Participants are requested to estimate the ratings or relevance scores (depending on the task) that users would attribute to a set of books reported in an evaluation dataset:
DBbook_userID DBbook_itemID
{snip}
6873 5946
6873 5229
6873 3151
{snip}
Requires: R-AssociationOfCodeValuesWithExternalDefinitions.
The challenge mandates the use of Linked Open Data resources in the recommendations.
An effective manner to satisfy this requirement is to make use of undirected semantic paths. An undirected semantic path is a sequence of entities (subject or object) and properties that link two items, for instance:
{Book1 property1 Object1 property2 Book2}
This sequence results from considering the triples (subject-predicate-object) in a given Linked Open Data resource (e.g. DBpedia), independently of their direction, such that the starting and the ending entities are the desired items and that the subject (or object) of a triple is the object (or subject) of the following triple. For example, the sequence above may result from the following triples:
Book1 property1 Object1 Book2 property1 Object1
Undirected semantic paths are classified according to their length. Fixed a length, one can extract all the undirected semantic paths of that length that link two items within a Linked Open Data resource by running a set of SPARQL queries. This is necessary because an undirected semantic path actually corresponds to the union of a set of directed semantic paths. In the source, data are stored in terms of directed triples (subject-predicate-object).
The number of queries that is necessary to run in order to obtain all the undirected semantic paths that link to items is exponential of the length of the path itself (2n). Because of the complexity of this task and of the possible latency times deriving from it, it might be useful to cache these results.
CSV is a good candidate for caching undirected semantic paths, because of its ease of use, sharing, reuse. However, there are some open issues related to this. First, since paths may present a variable number of components, one might want to represent paths in a single cell, while being able to separate the path elements when necessary.
For example, in this file, undirected semantic paths are grouped by means of double quotes, and path components are separated by commas. The starting and ending elements of the undirected semantic paths (Book1 and Book2) are represented in two separate columns by means of the book identifiers used in the challenge (see the example below).
Book1 Book2 Path
{snip}
1 7680 "http://dbpedia.org/ontology/language,http://dbpedia.org/resource/English_language,http://dbpedia.org/ontology/language"
1 2 "http://dbpedia.org/ontology/author,http://dbpedia.org/resource/Diana_Gabaldon,http://dbpedia.org/ontology/author"
1 2 "http://dbpedia.org/ontology/country,http://dbpedia.org/resource/United_States,http://dbpedia.org/ontology/country"
{snip}
Requires: CellMicrosyntax and RepeatedProperties.
Second, the size of these caching files may be remarkable. For example, the size of this file described above is ~2GB, and that may imply prohibitive loading times, especially when making a limited number of recommendations.
Since rows are sorted according to the starting and the ending book of the undirected semantic path, then all the undirected semantic paths that link two books are present in a region of the table formed by consecutive rows.
By having at our disposal an annotation of such regions indicating which book they describe, one might be able to select the "slice" of the file he needs to make a recommendation, without having to load it entirely.
Requires: AnnotationAndSupplementaryInfo and RandomAccess.
Use Case #19 - Supporting Right to Left (RTL) Directionality
(Contributed by Yakov Shafranovich)
Writing systems affect the way in which information is displayed. In some cases, these writing systems affect the order in which characters are displayed. Latin based languages display text left-to-right across a page (LTR). Languages such as Arabic and Hebrew are written in scripts whose dominant direction is right to left (RTL) when displayed, however when it involves non-native text or numbers it is actually bidirectional.
Irrespective of the LTR or RTL display of characters in a given language, data is serialised such that the bytes are ordered in one sequential order.
Content published in Hebrew and Arabic provide examples of RTL display behaviour.
Tabular data from originating from countries where vertical writing is the norm (e.g. China, Japan) appear to be published with rows and columns as defined in [[RFC4180]] (e.g. each horizontal line in the data file conveys a row of data, with the first line optionally providing a header with column names). Rows are published in the left to right topology.
The results from the Egyptian Referendum of 2012 illustrate the problem, as can be seen in .
The content in the CSV data file is serialised in the order as illustrated below (assuming LTR rendering):
المحافظة,نسبة موافق,نسبة غير موافق,عدد الناخبين,الأصوات الصحيحة,الأصوات الباطلة,نسبة المشاركة,موافق,غير موافق
القليوبية,60.0,40.0,"2,639,808","853,125","15,224",32.9,"512,055","341,070"
الجيزة,66.7,33.3,"4,383,701","1,493,092","24,105",34.6,"995,417","497,675"
القاهرة,43.2,56.8,"6,580,478","2,254,698","36,342",34.8,"974,371","1,280,327"
قنا,84.5,15.5,"1,629,713","364,509","6,743",22.8,"307,839","56,670"
{snip}
A copy of the referendum results data file is also available locally.
Readers should be aware that both the right-to-left text direction and the cursive nature of Arabic text has been explicitly overridden in the example above in order to display each individual character in sequential left-to-right order.
The directionality of the content as displayed does not affect the logical structure of the tabular data; i.e. the cell at index zero is followed by the cell at index 1, and then index 2 etc.
However, without awareness of the directionality of the content, an application may display data in
a way that is unintuitive for the a RTL reader. For example, viewing the CSV file using
Libre Office Calc (tested
using version 3 configured with English (UK) locale) demonstrates the challenge in rendering the content correctly.
shows how the
content is
incorrectly rendered; cells progress from left-to-right yet, on the positive side, the Arabic text
within a given field runs from right-to-left. Similar behaviour is observed in Microsoft Office Excel 2007.
By contrast, we can see . The simple TextWrangler text editor is not aware that the overall direction is right-to-left, but does apply the Unicode bidirectional algorithm such that lines starting with an Arabic character have a direction base of right-to-left. However, as a result, the numeric digits are also displayed right to left, which is incorrect.

It is clear that a mechanism needs to be provided such that one can explicitly declare the directionality which applies when parsing and rendering the content of CSV files.
From Unicode version 6.3 onwards, the Unicode Standard contains new control codes (RLI, LRI, FSI, PDI) to enable authors to express isolation at the same time as direction in inline bidirectional text. The Unicode Consortium recommends that isolation be used as the default for all future inline bidirectional text embeddings. To use these new control codes, however, it will be necessary to wait until the browsers support them. The new control codes are:
- RLI (RIGHT-TO-LEFT ISOLATE)
U+2067to set direction right-to-left - LRI (LEFT-TO-RIGHT ISOLATE)
U+2066to set direction left-to-right - FSI (FIRST STRONG ISOLATE)
U+2068to set direction according to the first strong character - PDI (POP DIRECTIONAL ISOLATE)
U+2069to terminate the range set by RLI, LRI or FSI
More information on setting the directionality of text without markup can be found here
Requires: RightToLeftCsvDeclaration.
Use Case #20 - Integrating components with the TIBCO Spotfire platform using tabular data
(Contributed Yakov Shafranovich)
A systems integrator seeks to integrate a new component into the TIBCO Spotfire analytics platform. Reviewing the documentation that describes how to extend the platform indicates that Spotfire employs a common tabular file format for all products: the Spotfire Text Data Format (STDF).
The example from the STDF documentation (below) illustrates a number of the key differences with the standard CSV format defined in [[RFC4180]].
<bom>\! filetype=Spotfire.DataFormat.Text; version=1.0;
\* ich bin ein berliner
Column A;Column #14B;Kolonn Ö;The n:th column;
Real;String;Blob;Date;
-123.45;i think there\r\nshall never be;\#aaXzD;2004-06-18;
1.0E-14;a poem\r\nlovely as a tree;\#ADB12=;\?lost in time;
222.2;\?invalid text;\?;2004-06-19;
\?error11;\\förstår ej\\;\#aXzCV==;\?1979;
3.14;hej å hå\seller?;\?NIL;\?#ERROR;
-
The first line of the STDF file includes a byte order mark (BOM), the character sequence "
\!" and metadata about the file type and version to inform consuming applications.Requires: AnnotationAndSupplementaryInfo.
-
The second line is a comment line which is ignored during processing. The comment is recognised from the initial sequence of characters within the line: "
\*".Requires: CommentLines.
-
Lines three and four provide metadata: column heading names and the data types (including integer, real, string, date, time, datetime and blob) for each column respectively.
Requires: MultipleHeadingRows and SyntacticTypeDefinition.
-
Cells are delimited using the semi-colon "
;" character.Requires: NonStandardCellDelimiter.
-
Date and time values are strictly formatted;
YYYY-MM-DDandHH:MM:SSrespectively.Requires: CellMicrosyntax.
-
Base64-encoded binary values may be included. These are designated by setting the initial cell value to "
\#". -
A number of escape sequences for special characters are supported; e.g. "
\\" (backslash within a string), "\s" (semicolon within a string - not a cell or list item delimiter), "\n" (newline within a string) and "\t" (tab within a string) etc.These special characters don't affect the parsing of the data but are further examples of the use of microsyntax within cells.
Requires: CellMicrosyntax.
-
Null and invalid values are indicated by setting the initial character sequence of a cell to "
\?". Optionally, an error code or other informative statement may follow.Requires: MissingValueDefinition and CellMicrosyntax.
Although not shown in this example, STDF also supports list types:
- A valid list value must begin with "
\[" and end with "\]" followed by a terminating semicolon. - All list items are terminated by a semicolon, including the last item in a list.
Requires: CellMicrosyntax.
Use Case #21 - Publication of Biodiversity Information from GBIF using the Darwin Core Archive Standard
(Contributed by Tim Robertson, GBIF, and Jeremy Tandy)
A citizen scientist investigating biodiversity in the Parque Nacional de Sierra Nevada, Spain, aims to create a compelling web application that combines biodiversity information with other environmental factors - displaying this information on a map and as summary statistics.
The Global Biodiversity Information Facility (GBIF), a government funded open data initiative that spans over 600 institutions worldwide, has mobilised more that 435 million records describing the occurrence of flora and fauna.
Included in their data holdings is "Sinfonevada: Dataset of Floristic diversity in Sierra Nevada forest (SE Spain)", containing around 8000 records belonging to 270 taxa collected between January 2004 and December 2005.
As with the majority of datasets published via GBIF, the Sinfonevada dataset is available in the Darwin Core Archive format (DwC-A).
In accordance with the DwC-A specification, the Sinfonevada dataset is packaged as a zip file containing:
- tab delimited tabular data file:
occurrence.txt - metadata describing that tabular data file:
meta.xml - supplementary dataset metadata:
eml.xml
The metadata file included in the zip package must always be named meta.xml,
whilst the tabular data file and supplementary metadata are explicitly identified within the
main metadata file.
A copy of the zip package is provided for reference. Snippets of the tab delimited tabular data file and the full metdata file "meta.xml" are provided below.
"occurrence.txt"
----------------
id modified institutionCode collectionCode basisOfRecord catalogNumber eventDate fieldNumber continent countryCode stateProvince county locality minimumElevationInMeters maximumElevationInMeters decimalLatitude decimalLongitude coordinateUncertaintyInMeters scientificName kingdom phylum class order family genus specificEpithet infraspecificEpithet scientificNameAuthorship
OBSNEV:SINFONEVADA:SINFON-100-005717-20040930 2013-06-20T11:18:18 OBSNEV SINFONEVADA HumanObservation SINFON-100-005717-20040930 2004-09-30 & 2004-09-30 Europe ESP GR ALDEIRE 1992 1992 37.12724018 -3.116135071 1 Pinus sylvestris Lour. Plantae Pinophyta Pinopsida Pinales Pinaceae Pinus sylvestris Lour.
OBSNEV:SINFONEVADA:SINFON-100-005966-20040930 2013-06-20T11:18:18 OBSNEV SINFONEVADA HumanObservation SINFON-100-005966-20040930 2004-09-30 & 2004-09-30 Europe ESP GR ALDEIRE 1992 1992 37.12724018 -3.116135071 1 Berberis hispanica Boiss. & Reut. Plantae Magnoliophyta Magnoliopsida Ranunculales Berberidaceae Berberis hispanica Boiss. & Reut.
OBSNEV:SINFONEVADA:SINFON-100-008211-20040930 2013-06-20T11:18:18 OBSNEV SINFONEVADA HumanObservation SINFON-100-008211-20040930 2004-09-30 & 2004-09-30 Europe ESP GR ALDEIRE 1992 1992 37.12724018 -3.116135071 1 Genista versicolor Boiss. ex Steud. Plantae Magnoliophyta Magnoliopsida Fabales Fabaceae Genista versicolor Boiss. ex Steud.
{snip}
The key variances of this tabular data file with RFC 4180 is the use of TAB
%x09 as the cell delimiter and LF %x0A as the row
terminator.
Also note the use of two adjacent TAB characters to indicate an empty cell.
"meta.xml"
----------
<archive xmlns="http://rs.tdwg.org/dwc/text/" metadata="eml.xml">
<core encoding="utf-8" fieldsTerminatedBy="\t" linesTerminatedBy="\n" fieldsEnclosedBy="" ignoreHeaderLines="1" rowType="http://rs.tdwg.org/dwc/terms/Occurrence">
<files>
<location>occurrence.txt</location>
</files>
<id index="0" />
<field index="1" term="http://purl.org/dc/terms/modified"/>
<field index="2" term="http://rs.tdwg.org/dwc/terms/institutionCode"/>
<field index="3" term="http://rs.tdwg.org/dwc/terms/collectionCode"/>
<field index="4" term="http://rs.tdwg.org/dwc/terms/basisOfRecord"/>
<field index="5" term="http://rs.tdwg.org/dwc/terms/catalogNumber"/>
<field index="6" term="http://rs.tdwg.org/dwc/terms/eventDate"/>
<field index="7" term="http://rs.tdwg.org/dwc/terms/fieldNumber"/>
<field index="8" term="http://rs.tdwg.org/dwc/terms/continent"/>
<field index="9" term="http://rs.tdwg.org/dwc/terms/countryCode"/>
<field index="10" term="http://rs.tdwg.org/dwc/terms/stateProvince"/>
<field index="11" term="http://rs.tdwg.org/dwc/terms/county"/>
<field index="12" term="http://rs.tdwg.org/dwc/terms/locality"/>
<field index="13" term="http://rs.tdwg.org/dwc/terms/minimumElevationInMeters"/>
<field index="14" term="http://rs.tdwg.org/dwc/terms/maximumElevationInMeters"/>
<field index="15" term="http://rs.tdwg.org/dwc/terms/decimalLatitude"/>
<field index="16" term="http://rs.tdwg.org/dwc/terms/decimalLongitude"/>
<field index="17" term="http://rs.tdwg.org/dwc/terms/coordinateUncertaintyInMeters"/>
<field index="18" term="http://rs.tdwg.org/dwc/terms/scientificName"/>
<field index="19" term="http://rs.tdwg.org/dwc/terms/kingdom"/>
<field index="20" term="http://rs.tdwg.org/dwc/terms/phylum"/>
<field index="21" term="http://rs.tdwg.org/dwc/terms/class"/>
<field index="22" term="http://rs.tdwg.org/dwc/terms/order"/>
<field index="23" term="http://rs.tdwg.org/dwc/terms/family"/>
<field index="24" term="http://rs.tdwg.org/dwc/terms/genus"/>
<field index="25" term="http://rs.tdwg.org/dwc/terms/specificEpithet"/>
<field index="26" term="http://rs.tdwg.org/dwc/terms/infraspecificEpithet"/>
<field index="27" term="http://rs.tdwg.org/dwc/terms/scientificNameAuthorship"/>
</core>
</archive>
The metadata file specifies:
- a link to the supplementary metadata file
eml.xml - the data file encoding
UTF-8 - cell delimiter
- row terminator
- cell escaping
- the number of rows to skip at the beginning of the file before the data section (e.g. the length of the header section)
- the type of entity that each row in the tabular dataset describes
- the name of the tabular data file
occurence.txt - the column which provides the unique identifier for the entity described by each row
- the property type associated with each column based on the column number index
Requires: NonStandardCellDelimiter, ZeroEditAdditionOfSupplementaryMetadata and AnnotationAndSupplementaryInfo.
The ignoreHeaderLines attribute can be used to ignore files with column
headings or preamble comments.
In this particular case, the tabular data file is packaged within the zip file, and is referenced locally. However, the DwC-A specification also supports annotation of remote tabular data files, and thus does not require any modification of the source datafiles themselves.
Requires: LinkFromMetadataToData and IndependentMetadataPublication.
Although not present in this example, DwC-A also supports the ability to specify a property-value pair that is applied to every row in the tabular data file, or, in the case of sparse data, for that property-value pair to be added where the property is absent from the data file (e.g. providing a default value for a property).
Requires: SpecificationOfPropertyValuePairForEachRow.
Future releases of DwC-A also seek to provide stronger typing of data formats; at present only date formats are validated.
Requires: SyntacticTypeDefinition.
Whilst the DwC-A format is embedded in many software platforms, including web based tools, none of these seem to fit the needs of the citizen scientist. They want to use existing javascript libraries such as Leaflet, an open-Source javascript library for interactive maps, where possible to simplify their web development effort.
Leaflet has good support for GeoJSON, a JSON format for encoding a variety of geographic data structures.
In the absence of standard tooling, the citizen scientist needs to write a custom parser to convert the tab delimited data into GeoJSON. An example GeoJSON object resulting from this transformation is provided below.
{
"type": "Feature",
"id": "OBSNEV:SINFONEVADA:SINFON-100-005717-20040930",
"properties": {
"modified": "2013-06-20T11:18:18",
"institutionCode": "OBSNEV",
"collectionCode": "SINFONEVADA",
"basisOfRecord": "HumanObservation",
"catalogNumber": "SINFON-100-005717-20040930",
"eventDate": "2004-09-30 & 2004-09-30",
"fieldNumber": "",
"continent": "Europe",
"countryCode": "ESP",
"stateProvince": "GR",
"county": "ALDEIRE",
"locality": "",
"minimumElevationInMeters": "1992",
"maximumElevationInMeters": "1992",
"coordinateUncertaintyInMeters": "1",
"scientificName": "Pinus sylvestris Lour.",
"kingdom": "Plantae",
"phylum": "Pinophyta",
"class": "Pinopsida",
"order": "Pinales",
"family": "Pinaceae",
"genus": "Pinus",
"specificEpithet": "sylvestris",
"infraspecificEpithet": "",
"scientificNameAuthorship": "Lour."
},
"geometry": {
"type": "Point",
"coordinates": [-3.116135071, 37.12724018, 1992]
}
}
GeoJSON coordinates are specified in order of longitude, latitude and, optionally, altitude.
Requires: CsvToJsonTransformation.
The citizen scientist notes that many of the terms in a given row are drawn from controlled vocabularies; geographic names and taxonomies. For the application, they want to be able to refer to the authoritative definitions for these controlled vocabularies, say, to provide easy access for users of the application to the defintions of scientific terms such as "Pinophyta".
Requires: AssociationOfCodeValuesWithExternalDefinitions.
Thinking to the future of their application, our citizen scientist anticipates the need to aggregate data across multiple datasets; each of which might use different column headings depending on who compiled the tabular dataset. Furthermore, how can one be sure they are comparing things of equivalent type?
To remedy this, they want to use the definitions from the metadata file
meta.xml. The easiest approach to achieve this is to modify their parser
to export [[json-ld]] and transform the tabular data into RDF that can be easily
reconciled.
The resultant "GeoJSON-LD" takes the form (edited for brevity):
{
"@context": {
"base": "http://www.gbif.org/dataset/db6cd9d7-7be5-4cd0-8b3c-fb6dd7446472/",
"Feature": "http://example.com/vocab#Feature",
"Point": "http://example.com/vocab#Point",
"modified": "http://purl.org/dc/terms/modified",
"institutionCode": "http://rs.tdwg.org/dwc/terms/institutionCode",
"collectionCode": "http://rs.tdwg.org/dwc/terms/collectionCode",
"basisOfRecord": "http://rs.tdwg.org/dwc/terms/basisOfRecord",
{snip}
},
"type": "Feature",
"@type": "http://rs.tdwg.org/dwc/terms/Occurrence",
"id": "OBSNEV:SINFONEVADA:SINFON-100-005717-20040930",
"@id": "base:OBSNEV:SINFONEVADA:SINFON-100-005717-20040930",
"properties": {
"modified": "2013-06-20T11:18:18",
"institutionCode": "OBSNEV",
"collectionCode": "SINFONEVADA",
"basisOfRecord": "HumanObservation",
{snip}
},
"geometry": {
"type": "Point",
"coordinates": [-3.116135071, 37.12724018, 1992]
}
}
The complete JSON object may be retrieved here.
The unique identifier for each "occurence" record has been mapped to
a URI by appending the local identifier (from column id)
to the URI of the dataset within which the recond occurs.
Requires: URIMapping SemanticTypeDefinition and CsvToRdfTransformation.
The @type of the entity is taken from the rowType attribute
within the metadata file.
The amendment of the GeoJSON specification to include JSON-LD is a work in progress at the time of writing. Details can be found on the GeoJSON GitHub.
It is the hope of the DwC-A format specification authors that the availability of general metadata vocabulary for describing CSV files, or indeed any tabular text datasets, will mean that DwC-A can be deprecated. This would allow the biodiversity community, and initiatives such as GBIF, to spend their efforts developing tools that support the generic standard rather than their own domain specific conventions and specifications, thus increasing the accessibility of biodiversity data.
To achieve this goal, it essential that the key characteristics of the DwC-A format can be adequately described, thus enabling the general metadata vocabulary to be adopted without needing to modify the existing DwC-A encoded data holdings.
Use Case #22 - Making sense of other people's data
(Contributed by Steve Peters via Phil Archer with input from Ian Makgill)
spendnetwork.com harvests spending data from multiple UK local and central government CSV files. It adds new metadata and annotations to the data and cross-links suppliers to OpenCorporates and, elsewhere, is beginning to map transaction types to different categories of spending.
For example, East Sussex County Council publishes its spending data as Excel spreadsheets.
A snippet of data from East Sussex County Council indicating payments over £500 for the second financial quarter of 2011 is below to illustrate. White space has been added for clarity. The full data file for that period (saved in CSV format from Microsoft Excel 2007) is provided here: ESCC-payment-data-Q2281011.csv
Transparency Q2 - 01.07.11 to 30.09.11 as at 28.10.11,,,,,
Name, Payment category, Amount, Department,Document no.,Post code
{snip}
MARTELLO TAXIS, Education HTS Transport, £620,"Economy, Transport & Environment", 7000785623, BN25
MARTELLO TAXIS, Education HTS Transport, "£1,425","Economy, Transport & Environment", 7000785624, BN25
MCL TRANSPORT CONSULTANTS LTD, Passenger Services, "£7,134","Economy, Transport & Environment", 4500528162, BN25
MCL TRANSPORT CONSULTANTS LTD,Concessionary Fares Scheme,"£10,476","Economy, Transport & Environment", 4500529102, BN25
{snip}
This data is augmented by spendnetwork.com and presented in a Web page. The web page for East Sussex County Council is illustrated in
Notice the Linked Data column that links to OpenCorporates data on MCL Transport Consultants Ltd. If we follow the 'more' link we see many more cells that spendnetwork would like to include (see ). Where data is available from the original spreadsheet it has been included.
The schema here is defined by a third party (spendnetwork.com) to make sense of the original data within their own model (only some of which is shown here, spendnetwork.com also tries to categorize transactions and more). This model exists independently of multiple source datasets and entails a mechanism for reusers to link to the original data from the metadata. Published metadata can be seen variously as feedback, advertising, enrichment or annotations. Such information could help the publisher to improve the quality of the original source, however, for the community at large it reduces the need for repetition of the work done to make sense of the data and facilitates a network effect. It may also be the case that the metadata creator is better able to put the original data into a wider context with more accuracy and commitment than the original publisher.
Another (similar) scenario is LG-Inform. This harvests government statistics from multiple sources, many in CSV format, and calculate rates, percentages & trends etc. and packages them as a set of performance metrics/measures. Again, it would be very useful for the original publisher to know, through metadata, that their source has been defined and used (potentially alongside someone else's data) in this way.
See http://standards.esd.org.uk/ and the "Metrics" tab therein; e.g. percentage of measured children in reception year classified as obese (3333).
The analysis of datasets undertaken by both spendnetwork.com and LG-Inform to make sense of other people's tabular data is time-consuming work. Making that metadata available is a potential help to the original data publisher as well as other would-be reusers of it.
Requires: WellFormedCsvCheck, IndependentMetadataPublication, ZeroEditAdditionOfSupplementaryMetadata, AnnotationAndSupplementaryInfo, AssociationOfCodeValuesWithExternalDefinitions, SemanticTypeDefinition, URIMapping and LinkFromMetadataToData.
Use Case #23 - Collating humanitarian information for crisis response
(Contributed by Tim Davies)
During a crisis response, information managers within the humanitarian community face a significant challenge in trying to collate data regarding humanitarian needs and response activities conducted by a large number of humanitarian actors. The schemas for these data sets are generally not standardized across different actors nor are the mechanisms for sharing the data. In the best case, this results in a significant delay between the collection of data and the formulation of that data into a common operational picture. In the worst case, information is simply not shared at all, leaving gaps in the understanding of the field situation.
The Humanitarian eXchange Language (HXL) project seeks to address this concern; enabling information from diverse parties to be collated into a single "Humanitarian Data Registry". Supporting tools are provided to assist participants in a given response initiative in finding information within this registry to meet their needs.
The HXL standard is designed to be a common publishing format for humanitarian data. A key design principle of the HXL project is that the data publishers are able to continue publication of their data using their existing systems. Unsurprisingly, data publishers often provide their data in tabular formats such as CSV, having exported the content from spreadsheet applications. As a result, the HXL standard is entirely based on tabular data.
During their engagement with the humanitarian response community, the HXL project team have identified two major concerns when working with tabular data:
- Tabular data needs to be created, read by and exchanged between people speaking different languages. Many of these are basic spreadsheet users who find it far easier to use data with natural and clear language in the column headings. Having the column headings in their own language makes creating and interpreting the data a lot easier.
- Tabular data needs to be created that contains literal values in multiple languages. For example, the name of a town in English, French and Arabic. The total number of languages that the data might be expressed in cannot be easily determined in advance, and it should be possible for a data manager to introduce a new language variant of a column easily.
To address these issues, the HXL project have developed a number of conventions for publishing tabular data in CSV format.
Column headings in the tabular data are supplemented with short hashtags that are defined in the HXL hashtag dictionary. The hashtag provides the normative meaning of the data in the column while the column header from the original data, a literal text string, is informative. This allows software systems to quickly ascertain the meaning of the data irrespective of the column heading and language used in the original data. For example, where a column provides information on the numbers of people affected by an emergency, the heading may be one of: "People affected", "Affected", "# de personnes concernées", "Afectadas/os" etc. The hashtag #affected is used to provide a common key to interpret the data.
. Cluster, District, People affected, People reached
#sector, #adm1, #affected, #reached
WASH, Coast, 9000, 9000
WASH, Mountains, 1000, 200
Education, Coast, 15500, 8000
Education, Mountains, 750, 600
Health, Coast, 20000, 3500
Health, Mountains, 3500, 1500
(whitespace included for clarity)
Requires: MultipleHeadingRows and SemanticTypeDefinition.
Hashtags may be supplemented with attributes to refine the meaning of the data. A suggested set of attributes is provided in the HXL hashtag dictionary. For example, attributes may be used to specify the language used for the text in a given column using "+" followed by an ISO 639 language code:
. Project title, Titre du projet
#activity+en, #activity+fr
Malaria treatments, Traitement du paludisme
Teacher training,Formation des enseignant(e)s
(whitespace included for clarity)
Requires: MultilingualContent.
Where multiple data-values for a given field code are provided in a single row, the field code is repeated - as illustrated in the example below that provides geocodes for multiple locations pertaining to the subject of the record.
P-code 1,P-code 2,P-code 3
#loc+code,#loc+code,#loc+code
020503, ,
060107, 060108,
173219, ,
530012, 530013, 530015
279333, ,
(whitespace included for clarity)
Requires: RepeatedProperties.
In the example above, we see an often repeated pattern where data includes codes to reference some authoritative
term, definition or other resource; e.g. the location code 020503. In order
to make sense of the data, these codes must be reconciled with their official definitions.
Requires: AssociationOfCodeValuesWithExternalDefinitions.
A snippet of an example of a tabular HXL data file is provided below. A local copy of the HXL data file is also available: HXL_3W_samples_draft_Multilingual.csv.
Fecha del informe, Fuente, Implementador,Código de sector, Sector / grupo, Sector / group, Subsector, País,Código de provincia, Province, Region,Código del municipio,Municipality
#date+reported,#meta+source, #org, #sector+code, #sector+es, #sector+en,#subsector+en, #country, #adm1+code, #adm1+en,#region+en, #adm2+code, #adm2+en
2013-11-19,Mapaction OP, World VISION, S01,Refugio de emergencia,Emergency Shelter, ,Filipinas, 60400000, Aklan, VI, ,
2013-11-19, DHNetwork,DFID Medical Teams, S02, Salud, Health, , , 60400000, Aklan, VI, ,
2013-11-19, DHNetwork, MSF, S02, Salud, Health, , , 60400000, Aklan, VI, ,
2013-11-19, Cluster 3W, LDS Charities, S03, WASH, WASH, Hygiene,Filipinas, 60400000, Aklan, VI, ,
{snip}
(whitespace included for clarity)
Use Case #24 - Expressing a hierarchy within occupational listings
(Contributed by Dan Brickley)
Our user intends to analyze the current state of the job market using information gleaned from job postings that are published using schema.org markup.
schema.org defines a schema for a listing that describes a
job opening within an organization: JobPosting.
One of the things our user wants to do is to organise the job postings into categories
based on the occupationalCategory
property of each JobPosting.
The occupationalCategory property is used to categorize the described job. The
O*NET-SOC Taxonomy is schema.org's recommended
controlled vocabulary for the occupational categories.
The schema.org documentation notes that value of the occupationalCategory property
should include both the textual label and the formal code from the O*NET-SOC Taxonomy, as
illustrated below in the following RDFa snippet:
<br><strong>Occupational Category:</strong> <span property="occupationalCategory">15-1199.03 Web Administrators</span>
The O*NET-SOC Taxonomy is republished every few years; the occupational listing for 2010 is the most recent version available. This listing is also available in CSV format. An extract from this file is provided below. A local copy of this CSV file is also available: file = 2010_Occupations.csv.
O*NET-SOC 2010 Code,O*NET-SOC 2010 Title,O*NET-SOC 2010 Description
{snip}
15-1199.00,"Computer Occupations, All Other",All computer occupations not listed separately.
15-1199.01,Software Quality Assurance Engineers and Testers,Develop and execute software test plans in order to identify software problems and their causes.
15-1199.02,Computer Systems Engineers/Architects,"Design and develop solutions to complex applications problems, system administration issues, or network concerns. Perform systems management and integration functions."
15-1199.03,Web Administrators,"Manage web environment design, deployment, development and maintenance activities. Perform testing and quality assurance of web sites and web applications."
15-1199.04,Geospatial Information Scientists and Technologists,"Research or develop geospatial technologies. May produce databases, perform applications programming, or coordinate projects. May specialize in areas such as agriculture, mining, health care, retail trade, urban planning, or military intelligence."
15-1199.05,Geographic Information Systems Technicians,"Assist scientists, technologists, or related professionals in building, maintaining, modifying, or using geographic information systems (GIS) databases. May also perform some custom application development or provide user support."
15-1199.06,Database Architects,"Design strategies for enterprise database systems and set standards for operations, programming, and security. Design and construct large relational databases. Integrate new systems with existing warehouse structure and refine system performance and functionality."
15-1199.07,Data Warehousing Specialists,"Design, model, or implement corporate data warehousing activities. Program and configure warehouses of database information and provide support to warehouse users."
15-1199.08,Business Intelligence Analysts,Produce financial and market intelligence by querying data repositories and generating periodic reports. Devise methods for identifying data patterns and trends in available information sources.
15-1199.09,Information Technology Project Managers,"Plan, initiate, and manage information technology (IT) projects. Lead and guide the work of technical staff. Serve as liaison between business and technical aspects of projects. Plan project stages and assess business implications for each stage. Monitor progress to assure deadlines, standards, and cost targets are met."
15-1199.10,Search Marketing Strategists,"Employ search marketing tactics to increase visibility and engagement with content, products, or services in Internet-enabled devices or interfaces. Examine search query behaviors on general or specialty search engines or other Internet-based content. Analyze research, data, or technology to understand user intent and measure outcomes for ongoing optimization."
15-1199.11,Video Game Designers,"Design core features of video games. Specify innovative game and role-play mechanics, story lines, and character biographies. Create and maintain design documentation. Guide and collaborate with production staff to produce games as designed."
15-1199.12,Document Management Specialists,"Implement and administer enterprise-wide document management systems and related procedures that allow organizations to capture, store, retrieve, share, and destroy electronic records and documents."
{snip}
The CSV file follows the specification outlined in [[RFC4180]] - including the use of
pairs of double quotes ("") to escape cells that themselves contain commas.
Also note that each row provides a unique identifier for the occupation it describes. This
unique identifier is given in the O*NET-SOC 2010 Code column. This code can be considered
as the primary key for each row in the listing as it is unique for every row. Furthermore, the value
of the O*NET-SOC 2010 Code column serves as the unique identifier for the occupation.
Requires: PrimaryKey.
Closer inspection of the O*NET-SOC 2010 code illustrates the hierarchical classification within the taxonomy. The first six digits are based on the Standard Occupational Classification (SOC) code from the US Bureau of Labor Statistics, with further subcategorization thereafter where necessary. The first and second digits represent the major group; the third digit represents the minor group; the fourth and fifth digits represent the broad occupation; and the sixth digit represents the detailed occupation.
The SOC structure (2010) is available in Microsoft Excel 97-2003 Workbook format. An extract of this structure, in CSV format (exported from Microsoft Excel 2007), is provided below. A local copy of the SOC structure in CSV is also available: file = soc_structure_2010.csv.
Bureau of Labor Statistics,,,,,,,,,
On behalf of the Standard Occupational Classification Policy Committee (SOCPC),,,,,,,,,
,,,,,,,,,
January 2009,,,,,,,,,
*** This is the final structure for the 2010 SOC. Questions should be emailed to soc@bls.gov***,,,,,,,,,
,,,,,,,,,
,,,,,,,,,
,,,,,,,,,
,,,,,,,,,
,2010 Standard Occupational Classification,,,,,,,,
,,,,,,,,,
Major Group,Minor Group,Broad Group,Detailed Occupation,,,,,,
,,,,,,,,,
11-0000,,,,Management Occupations,,,,,
,11-1000,,,Top Executives,,,,,
,,11-1010,,Chief Executives,,,,,
,,,11-1011,Chief Executives,,,,,
{snip}
,,,13-2099,"Financial Specialists, All Other",,,,,
15-0000,,,,Computer and Mathematical Occupations,,,,,
,15-1100,,,Computer Occupations,,,,,
,,15-1110,,Computer and Information Research Scientists,,,,,
,,,15-1111,Computer and Information Research Scientists,,,,,
,,15-1120,,Computer and Information Analysts,,,,,
,,,15-1121,Computer Systems Analysts,,,,,
,,,15-1122,Information Security Analysts,,,,,
,,15-1130,,Software Developers and Programmers,,,,,
,,,15-1131,Computer Programmers,,,,,
,,,15-1132,"Software Developers, Applications",,,,,
,,,15-1133,"Software Developers, Systems Software",,,,,
,,,15-1134,Web Developers,,,,,
,,15-1140,,Database and Systems Administrators and Network Architects,,,,,
,,,15-1141,Database Administrators,,,,,
,,,15-1142,Network and Computer Systems Administrators,,,,,
,,,15-1143,Computer Network Architects,,,,,
,,15-1150,,Computer Support Specialists,,,,,
,,,15-1151,Computer User Support Specialists,,,,,
,,,15-1152,Computer Network Support Specialists,,,,,
,,15-1190,,Miscellaneous Computer Occupations,,,,,
,,,15-1199,"Computer Occupations, All Other",,,,,
,15-2000,,,Mathematical Science Occupations,,,,,
{snip}
The header line here comes below an empty row and is separated from the data by another empty row. There is metadata about the table in the rows above the header line.
Requires: MultipleHeadingRows and AnnotationAndSupplementaryInfo.
Being familiar with SKOS, our user decides to map both the O*NET-SOC and SOC taxonomies into a single hierarchy expressed using RDF/OWL and the SKOS vocabulary.
Note that in order to express the two taxonomies in SKOS, the local identifiers used in
the CSV files (e.g. 15-1199.03) must be mapped to URIs.
Requires: URIMapping.
Each of the five levels used across the occupation classification schemes are assigned to a particular OWL class - each of which is a sub-class of skos:Concept:
- From SOC -
- Major Group:
ex:SOC-MajorGroup - Minor Group:
ex:SOC-MinorGroup - Broad Group:
ex:SOC-BroadGroup - Detailed Occupation:
ex:SOC-DetailedOccupation
- Major Group:
- From O*NET-SOC -
ex:ONETSOC-Occupation
The SOC taxonomy contains four different types of entities, and so requires several different
passes to extract each of those from the CSV file. Depending on which kind of entity is being
extracted, a different column provides the unique identifier for the entity. Data in a given
row is only processed if the value for the cell designated as the unique identifier is not blank.
For example, if the Detailed Occupation column is designated as providing the
unique identifier (e.g. to extract entities of type ex:SOC-DetailedOccupation),
then the only rows to be processed in the snippet below would be "Financial Specialists, All Other",
"Computer and Information Research Scientists" and "Computer Occupations, All Other". All other rows
would be ignored.
{snip}
Major Group,Minor Group,Broad Group,Detailed Occupation, ,,,,,
, , , , ,,,,,
{snip}
, , , 13-2099, "Financial Specialists, All Other",,,,,
15-0000, , , , Computer and Mathematical Occupations,,,,,
, 15-1100, , , Computer Occupations,,,,,
, , 15-1110, ,Computer and Information Research Scientists,,,,,
, , , 15-1111,Computer and Information Research Scientists,,,,,
{snip}
, , 15-1190, , Miscellaneous Computer Occupations,,,,,
, , , 15-1199, "Computer Occupations, All Other",,,,,
, 15-2000, , , Mathematical Science Occupations,,,,,
{snip}
(whitespace added for clarity)
Requires: ConditionalProcessingBasedOnCellValues.
The hierarchy in the SOC structure is implied by inheritance from
the preceeding row(s). For example, the row describing SOC minor group "Computer Occupations"
(Minor Group = 15-1100 (above) has an empty cell value for column Major Group.
The value for SOC major group is provided by the preceeding row. In the case of SOC detailed
occupation "Computer Occupations, All Other" (Detailed Occupation = 15-1199),
the value of value for column Major Group is provided 20 lines previously when a value
in that column was most recently provided. The example snippet below illustrates what the CSV would
look like if the inherited cell values were present:
{snip}
Major Group,Minor Group,Broad Group,Detailed Occupation, ,,,,,
, , , , ,,,,,
{snip}
13-0000, 13-2000, 13-2090, 13-2099, "Financial Specialists, All Other",,,,,
15-0000, , , , Computer and Mathematical Occupations,,,,,
15-0000, 15-1100, , , Computer Occupations,,,,,
15-0000, 15-1100, 15-1110, ,Computer and Information Research Scientists,,,,,
15-0000, 15-1100, 15-1110, 15-1111,Computer and Information Research Scientists,,,,,
{snip}
15-0000, 15-1100, 15-1190, , Miscellaneous Computer Occupations,,,,,
15-0000, 15-1100, 15-1190, 15-1199, "Computer Occupations, All Other",,,,,
15-0000, 15-2000, , , Mathematical Science Occupations,,,,,
{snip}
(whitespace added for clarity)
It is difficult to programatically describe how the inherited values should be implemented.
It is not as simple as infering the value for a blank cell from the most recent preceeding row
when a non-blank value was provided for that column. For example, the last row in the example
above describing "Mathematical Science Occupations" does not inherit the values from columns
Broad Group and Detailed Occupation in the preceeding row because
it describes a new level in the hierarchy.
However, given that the SOC code is a string value with regular structure that reflects
the position of a given concept within the hierarchy, it is possible to determine the
identifier of each of the broader concepts by parsing the identifier string. For example,
the regular expression /^(\d{2})-(\d{2})(\d)\d$/ could be used to split the
identifier for a detailed occupation code into its constituent parts from which the
identifiers for the associated broader concepts could be constructed.
Requires: CellMicrosyntax.
The same kind of processing applies to the O*NET-SOC taxonomy; in this case also extracting
a description for the occupation. There is also an additional complication: where a
O*NET-SOC code ends in ".00", that occupation is a direct mapping to the
occupation defined in the SOC taxonomy. For example, the O*NET-SOC code 15-1199.00
refers to the same occupation category as the SOC code 15-1199:
"Computer Occupations, All Other"
To implement this complication, we need to use conditional processing.
If the final two digits of the O*NET-SOC code are "00", then:
- the entity is of type
ex:SOC-DetailedOccupation; - the unique identifier and notation for the concept comprises only the six numerical digits of the
O*NET-SOC 2010 Codecell value (e.g. in the formnn-nnnn); and - no skos:broader relationship need be defined.
else:
- the entity is of type
ex:ONETSOC-Occupation; - the unique identifier and notation for the concept comprises the eight numerical digits of the
O*NET-SOC 2010 Codecell value (e.g. in the formnn-nnnn.nn); and - a skos:broader relationship is defined with the broader concept from the SOC taxonomy identified by the first six numerical digits of the
O*NET-SOC 2010 Codecell value.
The example below illustrates the conditional behaviour:
row:
----
15-1199.00,"Computer Occupations, All Other",All computer occupations not listed separately.
resulting RDF (in Turtle syntax):
---------------------------------
ex:15-1199 a ex:SOC-DetailedOccupation ;
skos:notation "15-1199" ;
skos:prefLabel "Computer Occupations, All Other" ;
dct:description "All computer occupations not listed separately." .
row:
----
15-1199.03,Web Administrators,"Manage web environment design, deployment, development and maintenance activities. Perform testing and quality assurance of web sites and web applications."
resulting RDF (in Turtle syntax):
---------------------------------
ex:15-1199.03 a ex:ONETSOC-Occupation ;
skos:notation "15-1199.03" ;
skos:prefLabel "Web Administrators" ;
dct:description "Manage web environment design, deployment, development and maintenance activities. Perform testing and quality assurance of web sites and web applications." ;
skos:broader ex:15-1199 .
Requires: ConditionalProcessingBasedOnCellValues.
A snippet of the final SKOS concept scheme, expressed in RDF using Turtle [[turtle]] syntax, resulting
from transformation of the O*NET-SOC and SOC taxonomies into RDF is provided below. Ideally, all
duplicate triples will be removed - such as the skos:prefLabel
property for concept ex:15-1190 which would be provided by both the O*NET-SOC and SOC CSV files.
ex:15-0000 a ex:SOC-MajorGroup ;
skos:notation "15-0000" ;
skos:prefLabel "Computer and Mathematical Occupations" .
ex:15-1100 a ex:SOC-MinorGroup ;
skos:notation "15-1100" ;
skos:prefLabel "Computer Occupations" ;
skos:broader ex:15-0000 .
ex:15-1190 a ex:SOC-BroadGroup ;
skos:notation "15-1190" ;
skos:prefLabel "Miscellaneous Computer Occupations" ;
skos:broader ex:15-0000, ex:15-1100 .
ex:15-1199 a ex:SOC-DetailedOccupation ;
skos:notation "15-1199" ;
skos:prefLabel "Computer Occupations, All Other" ;
dct:description "All computer occupations not listed separately." ;
skos:broader ex:15-0000, ex:15-1100, ex:15-1190 .
ex:15-1199.03 a ex:ONETSOC-Occupation ;
skos:notation "15-1199.03" ;
skos:prefLabel "Web Administrators" ;
dct:description "Manage web environment design, deployment, development and maintenance activities. Perform testing and quality assurance of web sites and web applications." ;
skos:broader ex:15-0000, ex:15-1100, ex:15-1190, ex:15-1199 .
Once the SKOS concept scheme has been defined, it is possible for our user to group job postings by SOC Major Group, SOC Minor Group, SOC Broad Group, SOC Detailed Occupation and O*NET-SOC Occupation to provide summary statistics about the job market.
For example, we can use the SKOS concept scheme to group job postings for "Web Administrators" (code 15-1199.03) as follows:
15-0000"Computer and Mathematical Occupations" (SOC major group)15-1100"Computer Occupations" (SOC minor group)15-1190"Miscellaneous Computer Occupations" (SOC broad occupation)15-1199"Computer Occupations, All Other" (SOC detailed occupation)15-1199.03"Web Administrators"
Use Case #25 - Consistent publication of local authority data
Open data and transparency are foundational elements within the UK Government's approach to improve public service. The Local Government Association (LGA) promotes open and transparent local government to meet local needs and demands; to innovate and transform services leading to improvements and efficiencies, to drive local economic growth and to empower citizen and community groups to choose or run services and shape neighbourhoods.
As part of this initiative, the LGA is working to put local authority data into the public realm in ways that provide real benefits to citizens, business, councils and the wider data community. The LGA provides a web portal to help identify open data published by UK local authorities and encourage standardisation of local open data; enabling data consumers to browse through datasets published by local authorities across the UK and providing guidance and tools to data publishers to drive consistent practice in publication.
Data is typically published in CSV format.
An illustrative example is provided for data describing public toilets. The portal lists datasets of information about public toilets provided by more than 70 local authorities. In order to ensure consistent publication of data about public toilets the LGA provides both guidance documentation and a machine-readable schema against which datasets may be validated using on-line tools.
The public toilets CSV schema has 32 (mandated or optional) fields. The validator tool allows columns to appear in any order, matching the column order to the schema based on the title in the column header. Furthermore, CSV files containing additional columns, such as SecureDisposalofSharps specified within the public toilet dataset for Bath and North East Somerset (as shown below), are also considered valid. Additional columns are included where one or more local authorities have specific requirements to include additional information to satisfy local needs. Such additional columns are not supported using formal 'extensions' of the schema as the organisational and administrative burden of doing so was considered too great.
ExtractDate,OrganisationURI,OrganisationLabel,ServiceTypeURI,ServiceTypeLabel,LocationText,StreetAddress,LocalityAddress,TownAddress,Postcode,GeoAreaWardURI,GeoAreaWardLabel,UPRN,CoordinateReferenceSystem,GeoX,GeoY,GeoPointLicensingURL,Category,AccessibleCategory,BabyChange,SecureDisposalofSharps,OpeningHours,ManagingBy,ChargeAmount,Notes
15/09/2014,http://opendatacommunities.org/id/unitary-authority/bath-and-north-east-somerset,Bath and North East Somerset,http://id.esd.org.uk/service/579,Public Toilets,CHARLOTTE STREET ENTRANCE,CHARLOTTE STREET,KINGSMEAD,BATH,BA1 2NE,http://statistics.data.gov.uk/id/statistical-geography/E05001949,Kingsmead,10001147066,OSGB36,374661,165006,http://www.nationalarchives.gov.uk/doc/open-government-licence/version/2/,Female and male,Female and male,TRUE,TRUE,24 Hours ,BANES COUNCIL AND HEALTHMATIC,0.2,
15/09/2014,http://opendatacommunities.org/id/unitary-authority/bath-and-north-east-somerset,Bath and North East Somerset,http://id.esd.org.uk/service/579,Public Toilets,ALICE PARK,GLOUCESTER ROAD,LAMBRIDGE,BATH,BA1 7BL,http://statistics.data.gov.uk/id/statistical-geography/E05001950,Lambridge,10001146447,OSGB36,376350,166593,http://www.nationalarchives.gov.uk/doc/open-government-licence/version/2/,Female and male,Female and male,TRUE,TRUE,06:00-21:00,BANES COUNCIL AND HEALTHMATIC,0.2,
15/09/2014,http://opendatacommunities.org/id/unitary-authority/bath-and-north-east-somerset,Bath and North East Somerset,http://id.esd.org.uk/service/579,Public Toilets,HENRIETTA PARK,HENRIETTA ROAD,ABBEY,BATH,BA2 6LU,http://statistics.data.gov.uk/id/statistical-geography/E05001935,Abbey,10001147120,OSGB36,375338,165170,http://www.nationalarchives.gov.uk/doc/open-government-licence/version/2/,Female and male,Female and male,FALSE,Female and male,Winter & Su 10:00-16:00 | Other times: 08:00-18:00,BANES COUNCIL AND HEALTHMATIC,0,Scheduled for improvement Autumn 2014
15/09/2014,http://opendatacommunities.org/id/unitary-authority/bath-and-north-east-somerset,Bath and North East Somerset,http://id.esd.org.uk/service/579,Public Toilets,SHAFTESBURY ROAD,SHAFTESBURY ROAD,OLDFIELD ,BATH,BA2 3LH,http://statistics.data.gov.uk/id/statistical-geography/E05001958,Oldfield,10001147060,OSGB36,373809,164268,http://www.nationalarchives.gov.uk/doc/open-government-licence/version/2/,Female and male,Female and male,TRUE,TRUE,24 Hours ,BANES COUNCIL AND HEALTHMATIC,0.2,
{snip}
A local copy of this dataset is included for convenience.
Requires: WellFormedCsvCheck, CsvValidation and SyntacticTypeDefinition.