Datasets published on the web are accessed and experienced by
consumers in a variety of ways, but little information about these
experiences is typically conveyed. Dataset publishers many times lack
feedback from consumers about how datasets are used. Consumers lack an
effective way to discuss experiences with fellow collaborators and
explore referencing material citing the dataset. Datasets as defined by
DCAT are a collection of data, published or curated by a single agent,
and available for access or download in one or more formats. The Dataset
Usage Vocabulary (DUV) is used to describe consumer experiences,
citations, and feedback about the dataset from the human perspective.
By specifying a number of foundational concepts used to collect dataset
consumer feedback, experiences, and cite references associated with a
dataset, APIs can be written to support collaboration across the web by
structurally publishing consumer opinions and experiences, and provide a
means for data consumers and producers advertise and search for
published open dataset usage.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This is a draft document which may be merged with the Data Quality Vocabulary or
remain as a standalone document. Feedback is sought on the overall direction
being taken as much as the specific details of the proposed vocabulary.
Publication as a First Public Working Draft does not imply endorsement by the
W3C
Membership. This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other than work in
progress.
This document was produced by a group operating under the
5 February 2004 W3C Patent Policy.
The group does not expect this document to become a W3C Recommendation.
W3C maintains a
public list of any patent
disclosures
made in connection with the deliverables of the group; that page also includes
instructions for disclosing a patent. An individual who has actual knowledge of a patent
which the individual believes contains
Essential
Claim(s) must disclose the information in accordance with
section
6 of the W3C Patent Policy.
This vocabulary is meant to fill a niche that helps standardize the
way web published dataset usage be conveyed and shared. At this time is
no clear standard way to describe dataset usage on the Web. Without a
means to systematically describe dataset usage, searching and conveying
techniques are application specific and discovery and collaboration
across the Web is more difficult. This vocabulary also recommends and
requires data publishers to provide a mechanism of receiving data usage
from data consumers in the form of feedback,citation and data
correction.
2. Namespaces
The namespace for DCAT is http://www.w3.org/ns/dcat#.
However, it should be noted that DCAT makes extensive use of terms from
other vocabularies, in particular Dublin
Core. DCAT itself defines a minimal set of classes and properties
of its own. A full set of namespaces and prefixes used in this document
is shown in the table below.
Prefix
Namespace
dcat
http://www.w3.org/ns/dcat#
dct
http://purl.org/dc/terms/
dctype
http://purl.org/dc/dcmitype/
foaf
http://xmlns.com/foaf/0.1/
rdf
http://www.w3.org/1999/02/22-rdf-syntax-ns#
rdfs
http://www.w3.org/2000/01/rdf-schema#
skos
http://www.w3.org/2004/02/skos/core#
vcard
http://www.w3.org/2006/vcard/ns#
xsd
http://www.w3.org/2001/XMLSchema#
duv
http://www.w3.org/ns/duv#
oa
http://www.w3.org/ns/oa#
rev
http://purl.org/stuff/rev#
prov
http://www.w3.org/ns/prov#
cito
http://purl.org/spar/cito#
bibo
http://purl.org/ontology/bibo#
3. Audience
The DUV is intended for data producers and publishers interested in
tracking, sharing, and persisting consumer dataset usage. It is also
intended for collaborators who require an exchange medium to advertise
and interactively convey dataset usage.
4. Scope
The scope of DUV is defined by the Data on the Web Best Practices
(DWBP) Use Case document based on the data usage requirements about
datasets. These requirements include: citing data on the Web, tracking
the usage of data, sharing feedback and rating data. These requirements
were derived from fourteen real world use cases examples provided in the
use case document.
5. Relationship to other Vocabularies
The DUV is a “glue” vocabulary reusing and extending existing
vocabulary classes and properties to support citation, feedback, and
usage. This section provides our rationale and approach for vocabulary
selection and re-use.
Core to the dataset usage vocabulary is the “dataset”. The DUV uses
the Data Catalog (DCAT) vocabulary dcat:Dataset class and all properties
associated with the class. From a data usage perspective the DUV can be
considered an extension of the dcat:Dataset.
The Web Annotation Vocabulary is used to describe duv:Feedback as a
subclass inheriting the behavior of oa:Annotation. A crucial part of the
Web Annotation Model are “motivations” that describe the role of
particular Annotation. Each duv:Feedback must have at least one
oa:motivated_by property with a relationship to an instance of
oa:Motivation. A subset of the Motivation instances are important to
describe feedback to data publishers, and blogs between dataset
consumers. In addition to supporting duv:Feedback because the Web
Annotation vocabulary provides a generic way of annotating any web
resource, it is recommended that Web Annotation vocabulary be used to
annotate the duv:Dataset for uses beyond the scope of the DUV.
The Provenance Ontology (Prov-O) is a vocabulary used by data
providers to pass details about the data history to data users.
Properties associated with prov:Activity provide relationships
(prov:used, prov:hasGenerated) from a historical perspective using past
tense forms of words and phrases. The developed and duv:WebThing reuses
these properties by creating subProperties from Prov-O to describe usage
from a present tense perspective.
Both the Citation Typing Ontology (CiTO) and Dublin Core vocabularies
are used to describe citations and references between datasets and cited
sources.
6. Examples
This section shows some examples to illustrate the application of the
Dataset Usage Vocabulary.
Example 1 - Usage: A 2-D plot application developed by Laufer can be
used to create temperature plots and consumes temperature readings from
a dataset to produce the plot. A data logger used to provide temperature
readings uses a configuration file for operation of the data logger.
Example 3 - Citation: A technical report :paperA identified by a DOI
cites the dataset. The :dataset-03312013 is also identified by a digital
object identifier (DOI).
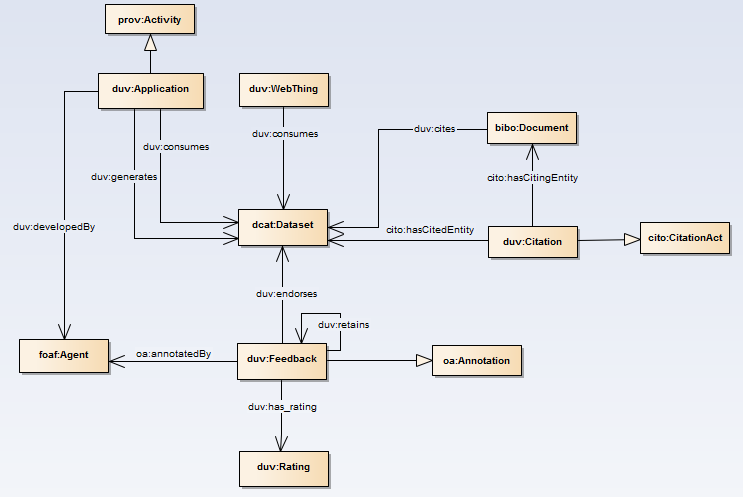
This section depicts the vocabulary as a conceptual model. Shaded
boxes are used to identify each class. Labeled open arrows identify
example properties between the classes. Unlabeled shaded arrows are used
to show inheritance with the parent class identified by the arrow head.
The classes duv:Application, duv:WebThing, and prov:Activity are used
to convey dataset usage. The classes duv:Citation, bibo:Document,
cito:CitationAct are used to represent citation. The classes
duv:Feedback, oa:Annotation, duv:Rating are used to represent feedback.
Fig. 1Diagrammatic overview of the Dataset Usage Vocabulary
Issue 1
Should usage be specified at the Dataset or
Distribution level?
Issue-169
8. Vocabulary Specification
Note
This is an initial proposal of DUV classes and properties. We are still evaluating the use of classes like duv:Citation and duv:Feedback.
The citing entity cites the cited entity, either directly and
explicitly (as in the reference list of a journal article),
indirectly (e.g. by citing a more recent paper by the same group
on the same topic), or implicitly (e.g. as in artistic
quotations or parodies, or in cases of plagiarism).
An activity is something that occurs over a period of time and
acts upon or with entities; it may include consuming,
processing, transforming, modifying, relocating, using, or
generating entities.
The definition of duv:Feedback needs to be reviewed
because it is not clear if it should be a subclass of oa:Annotation or
just an instance of oa:Motivation.
Issue-178
Property:
endorses
RDF Property:
duv:endorses
Definition
Agent provided feedback providing endorsement of dataset.
Capability of tracking data usage can help enhancing reputation of the
datasets. Records of data usage shows all the successful outcome of the
data usage and all the entities associated with it such as the person,
organisation, application, research projects that has used these
datasets. It increases trust in the data. It also provides provence
about how data versions over the time.
Data
is used in decision making process by Water Reservoir Managers.
Capability to track usage of data will lead to identification of
all the decisions and policy changes made by authorities based
on this data. It will also list applications, tools and
frameworks suitable for analysis of this kind of data.
Data
is used in Research;
Policy Making, Journalism; Development; Investments;
Governance; Food security; Poverty; Gender issues. Usage tracking
will help in assessing the impact of published data.
>Data
is put in public for reuse and reference in nature conservation
activities. Information about use of this data will
determined impact of this framework. Usage of this data MUST lead
to future publications of less heterogenous data and more and more
used of standardised thesauri.
Data
is used in computational models and studies. Capabilities to
track usage of data will enable data publishers to identify all
the users communities making use of this data. It will also
identify combined use of multiple datasets in one big study.
This will identify related datasets which can be recommended to
future users.
Data
is published in Linked Data Format for discovery and
recommendations of related datasets. Capability to keep track of
its usage will list all the tools and application suitable to be
used with this data. Because RDESC is not data publisher but
more of a data facilitator, usage tracking will identify highly
search dataset and the trends in the temporal, spatial and
domain specific search queries.
Data
is published with intelligent
openness to support research projects. Capability to track data
usage will provide adequate acknowledgement to data originator.
Data consumers should have a way of sharing feedback and rating data.
User
feedback is important to address data quality concerns about published
dataset. Different users may have different experience with the same
dataset so it is important to capture the context in which data was used
and the profile of the user who uses it. R-UsageFeedback should also
provide a way to communicate suggested corrections and update to the
datasets by the users back to data publisher. Data publishers should
have a review mechanism to incorporate submitted corrections.
Data
came from various publishers. As a catalog, the site has faced
several challenges, one of them was to integrate the various
technologies and formulas used by publishers to provide datasets
in the portal. User feedback can provided usabilities of those
technologies and formulas. User feedback can be used to
crowdsource discrepancies in the vocabularies used to
describe datasets.
Data
is used in computational models and studies. User feedback can
be used to identify good quality data required for good quality
research. completeness, time resolution and usability can be
captured using user feedback.>
RDESC
curate different data source and publish metadata in Linked Data
Format. User feedback is useful to assess metadata quality.
Availability of the source datasets, Correctness of persistent
URI, Correctness of the concepts defined in RDESC such as FOAF
Agents, Organizations, Physical Properties and Usability of the
search interface can be captured in user feedback.
Various
experiments and fields studies are performed to generate data
which is used in computational
models and bigger studies.Capability
to capture all the citations of the published data can justify
the efforts used in publishing. Citation information can be used
to identify all the user communities interested in data source.
On
27 March 2014, the LA Times published a story Women
earn 83 cents for every $1 men earn in L.A. city government. It
was based on an Infographic released by LA's City Controller,
Ron Galperin. This report could only cite data portal of all the
resource. It could not cite to exact dataset because tool long
URI.
RDESC
is a data curator so it uses data from different sources. But
this usage is not communicated to data publishers because of
lack of such mechanism provided by publishers.