The Best Practices
Assigning identifiers to real world things and information resources
In the geospatial community, the entities within datasets are usually information resources, representing areas on a map, which in turn represent real world things. These information resources are usually called 'features'. A feature is a representation of a real world thing and there could be, and often are, more than one feature representing the same real world thing. A feature often has, as a property, a geometry which describes the location of the feature.
For example, a lighthouse standing somewhere on the coast is a real world thing. In some dataset, an information record about this lighthouse exists: a 'feature'. In current practice, this feature will often have properties that are about the real thing (e.g. the height of the lighthouse) and properties about the information record (e.g. when it was last modified). There could be several features, in different datasets, that refer to the same lighthouse; one dataset has its location and date it was built, another has data about its ownership or about shipwrecks near the same lighthouse.
Mostly, people looking for information are interested in real world things, not in information resources. This means the real world things should get global identifiers so they can be found and referenced. The features and their map representations - geometries and topologies - should have global identifiers too so they can be referenced as well; and must have them if they are managed elsewhere.
Discussion on Features, information resources and real-world Things is unclear and needs redrafting
Use globally unique HTTP identifiers for entity-level resources
Entities within datasets SHOULD have unique, persistent HTTP or HTTP(S) URIs as identifiers.
The term "entity-level resources" is confusing and needs to be clarified or replaced.
Why
A lot of spatial data is available 'via the Web' - but not really 'on the web': you can download datasets, or view, query and download data via web services, but it is usually not possible to reference an entity within a dataset, like you would a web page. If this were possible, spatial data would be much easier to reuse and to integrate with other data on the Web.
Intended Outcome
Entities (SpatialThings) described in a dataset will each be identified using a globally unique HTTP URI so that a given entity can be unambiguously identified in statements that refer to that entity.
Possible Approach to Implementation
In order for identifiers to be useful, people should be comfortable creating them themselves without needing to refer to some top-level naming authority- much like how Twitter's hashtags are created dynamically. Good identifiers for data on the web should be dereferenceable/resolvable, which makes it a good idea to use HTTP URIs as identifiers. There is no top down authority that you have to go to in order to create such identifiers for spatial objects. So just make them up yourself if you need them and they don't exist. Best Practice 2: Reuse existing (authoritative) identifiers when available explains how to find already existing identifiers you can reuse.
Read [[DWBP]] Best Practice 11: Use persistent URIs as identifiers within datasets for general discussion on why persistent URIs should be used as identifiers for data entities. Using URIs means the data can be referenced using standard Web mechanisms; making them persistent means the links won't get broken. Note that ideally the URIs should resolve, however, they have value as globally scoped variables whether they resolve or not.
For guidance about how to create persistent URIs, read [[DWBP]] Best Practice 10: Use persistent URIs as identifiers. Keep in mind not to use service endpoint URLs, as these are usually dependent on technology, implementation, and/or API version and will probably change when the implementation changes.
update reference to DWBP BP 11 #identifiersWithinDatasets
Complete this section and How to Test section
How to Test
...
Evidence
Relevant requirements: R-Linkability.
Reuse existing (authoritative) identifiers when available
Avoiding the creation of lots of identifiers for the same resource
Why
In general, re-using identifiers for well-known resources is a good idea, because it discourages proliferation of disparate copies with uncertain provenance. Linking your own resources to well-known or authoritative resources also makes relationships between your data and other data, which refers to the same well-known resource, discoverable. The result is a network of related resources using the identifiers for the SpatialThings.
In the case of SpatialThings, a simple way of indicating a location is by referencing an already existing named place resource on the Web. For example, DBpedia and GeoNames are existing datasets with well-known spatial resources, i.e. besides place names and a lot of other information, a set of coordinates is also available for the resources in these datasets. The advantage of referring to these named place resources is that it makes clear that different resources which refer to, for example, http://dbpedia.org/page/Utrecht, are all referring to the same city. If these resources did not use a URI reference but a literal value "Utrecht" this could mean the province Utrecht, the city Utrecht (both places in the Netherlands), the South African town called Utrecht, or maybe something else entirely.
See also Best Practice 22: Link to resources with well-known or authoritative identifiers.
Some content of this BP may be moved to BP link-to-auth-identifiers.
Intended Outcome
Already existing identifiers for spatial resources are reused instead of new ones being created.
Possible Approach to Implementation
If you've got feature data and want to publish that as linked data, the first step is to see if there's an authoritative URI already available that you can reuse. If so, do that; else refer to Best Practice 1: Use globally unique identifiers for entity-level resources.
DBpedia and GeoNames are examples of popular, community-driven resource collections. Another good source of resource collections is often found in public government data, such as national registers of addresses, buildings, and so on. Mapping and cadastral authorities maintain datasets that provide geospatial reference data.
See Appendix B. Authoritative sources of geographic identifiers for a list of good sources of geographic identifiers.
How to Test
An automatic check is possible to determine if any of the good sources of geographic identifiers are referenced.
Evidence
Relevant requirements: R-GeoReferencedData, R-IndependenceOnReferenceSystems.
Working with data that lacks globally unique identifiers for entity-level resources
Spatial reconciliation across datasets
Why
There are many mechanisms to reconcile (i.e. find related, map or link) objects from different datasets. When two spatial datasets contain geometries, you can use spatial functions to find out which objects overlap, touch, etc. Based on this spatial correlation you might determine that two datasets are talking about the same places, but this is often not enough. For reasons of efficiency or simply for being able to use these spatial correlations in a context where spatial functions are not available, it is a good idea to express these spatial relationships explicitly in your data. There is also danger in relying on spatial correlation alone; you might conclude that two resources represent the same thing when in reality they represent, for example, a shop at ground level and living apartment above it.
Intended Outcome
Links between resources in datasets created from spatial correspondences.
Possible Approach to Implementation
If you want to link two spatial datasets, find out if they have corresponding geometries using spatial functions and then express these correspondences as explicit relationships.
In this best practice we only give guidance on spatial reconciliation (e.g. two mentions of Paris are talking about the same place). We do not address thematic reconciliation.
If the spatial datasets you want to reconcile are managed in a Geographic Information System (GIS), you can use the GIS spatial functions to find related spatial things. If your spatial things are expressed as Linked Data, you can use [[GeoSPARQL]], which has a set of spatial query functions available.
How to express discovered relationships is discussed in Best Practice 13: Assert known relationships.
This Best Practice needs more content.
So far we have discussed the short comings of using names as identifiers (and the subsequent need for reconciliation). We also need to discuss assigning URIs based on local identifiers; for example, row numbers from tabular data or Feature identifiers from geo-databases.
How to Test
...
Evidence
Relevant requirements: R-Linkability.
Provide stable identifiers for Things (resources) that change over time
Even though resources change, it helps when they have a stable, unchanging identifier.
Why
Spatial things can change over time, but as explained in Assigning identifiers to real world things and information resources, their identifiers should be persistent.
Should we reference the paradox of the Ship of Theseus to highlight there is no rigorous notion of persistent identity?
Intended Outcome
Even if a spatial thing has changed, its identifier should stay the same so that links to it don't get broken.
Possible Approach to Implementation
[[DWBP]] Best Practice 8: Provide versioning information explains how to provide versioning info for datasets. It doesn't provide information about versioning individual resources.
Spatial things can change in different ways, and sometimes the change is such that it's debatable if it's still the same thing. Think carefully about the life cycle of the spatial things in your care, and be reluctant to assign new identifiers. A lake that became smaller or bigger is generally still the same lake.
If your resources are versioned, a good solution is to provide a canonical, versionless URI for your resource, as well as date-stamped versions.
How to Test
Check the identifier for any version-dependent components.
Evidence
Relevant requirements: R-Linkability
Provide identifiers for parts of larger information resources
Identify subsets of large information resources that are a convenient size for applications to work with
Is the term "subset" correct?
Why
Some datasets, particularly coverages such as satellite imagery, sensor measurement timeseries and climate prediction data, can be very large. It is difficult for Web applications to work with large datasets: it can take considerable time to download the data and requires sufficient volume local storage to be available. To remedy this challenge, it is often useful to provide identifiers for conveiently sized subsets of large datasets that Web applications can work with.
Intended Outcome
Being able to refer to subsets of a large information resource that are sized for convienient usage in Web applications.
Possible Approach to Implementation
Two possible approaches are described below:
- Create named subsets.
- Determine how users may seek to access the dataset, determining subsets of the larger dataset that are appropriate for the intended application. A data provider may consider a general approach to improve accessibility of a dataset, while a data user might want to publish details of a workflow for others to reuse referencing only the relevant parts of the large dataset.
- Given the anticipated access pattern, create new resources and mint a new identifier for each subset.
- Provide metadata to indicate how a given subset resource is related to the original large dataset.
- Map a URI pattern to an existing data-access API.
Web service URLs in general not a good URI for a resource as it is unlikely to be persistent. A Web service URL is often technology and implementation dependent and both are very likely to change with time. For example, consider oft used parameters such as
?version=. Good practice is to use URIs that will resolve as long as the resource is relevant and may be referenced by others, therefore identifiers for subsets should be protocol independent.- Identify the service end-point that provides access to the larger dataset.
- Determine which parameters offered by the service end-point are required to construct a meaningful subset.
- Map these parameters into a URI pattern and configure an HTTP server to apply the necessary URL-rewrite.
How to Test
...
Evidence
Relevant requirements: R-Compatibility, R-Linkability, R-Provenance, R-ReferenceDataChunks.
More content needed for this BP.
Expressing spatial data
It is important to publish your spatial data with clear semantics. The primary use case for this is you already have a database of assets and you want to publish the semantics of this data. Another use case is someone wanting to publish some information which has a spatial component on the web in a form that search engines will understand.
The spatial thing itself as well as its spatial properties have semantics. There are several vocabularies which cover spatial things and spatial properties. If you need extra semantics not available in an existing vocabulary, you should create your own.
How to publish your vocabulary, which describes the meaning of your data, is explained in [[LD-BP]]. We recommend that you link your own vocabulary to commonly used existing ones because this increases its usefulness. How to do this is out of scope for this document; however, we give some examples of mapping relations you can use from OWL, SKOS, RDFS. And we do the mapping between some commonly used spatial vocabularies.
The current list of RDF vocabularies / OWL ontologies for spatial data being considered by the SDW WG are provided below. Some of these will be used in examples. Full details, including mapping between vocabularies, pointers about inconsistencies in vocabularies (if any are evident), and recommendations avoiding their use as these may lead to confusion, will be published in a complementary NOTE: Comparison of geospatial vocabularies.
Vocabularies can discovered from Linked Open Vocabularies (LOV); using search terms like 'location' or Tags place, Geography, Geometry and Time.
- W3C WGS84 Position
- schema.org
- OGC GeoSPARQL
- neogeo
- DBpedia (including dbpedia:Place)
- UK Ordnance Survey geometry
- UK Ordnance Survey spatial relations
- UK Office for National Statistics
http://statistics.data.gov.uk/def/statistical-geography#andhttp://statistics.data.gov.uk/def/statistical-entity#(URIs do not resolve) - XKOS (used for geographical hierarchies in some examples)
- Dublin core metadata 'DC Terms' (including dct:spatial and dct:coverage etc.)
- BBC's Place
- ISA Programme Location Core Vocabulary
- SWPortal ontology includes definition of location
- VCard ontology includes definition of location
- LOCN
- GeoRSS OWL
- stSPARQL from Strabon system (see publications iswc-strabon.pdf and eswc2013.pdf)
- gndo:#PlaceOrGeographicName
- IGN ontology for describing coordinate systems
- IGN ontology for describing geometry (re-using neogeo and geosparql)
- IGN ontology for describing administrative units
- IGN ontology for describing main features on the territory
- INSEE ontology for describing geometry
No attempts have yet been made to rank these vocabularies; e.g. in terms of expressiveness, adoption etc.
The motivation behind the ISA Programme Location Core Vocabulary was establishing a minimal core common to existing spatial vocabularies. However, experience suggests that such a minimal common core is not very useful as one quickly need to employ specific semantics to meet one's application needs.
Describing spatial resources
This entire subsection is concerned with helping data publishers choose the right spatial data format or vocabulary. Collectively this section provides a methodology for making that choice. We do this rather than recommending one vocabulary because this recommendation would not be durable as vocabularies are released or amended.
Do we need a subclass of SpatialThing for entities that do not have a clearly defined spatial extent; or a property that expresses the fuzzyness the extent?
Provide a minimum set of information for your intended application
When someone looks up a URI for a SpatialThing, provide useful information, using the common representation formats
Why
This will allow to distinguish SpatialThings from one another by looking at their properties; e.g. type, label. It will also allow to get the basic information about SpatialThings by referring to their URI.
Intended Outcome
This requirement should serve a minimum set of information for a SpatialThing against a URI. In general, this will allow to look up the properties and features of a SpatialThings, and get information from machine-interpretable and/or human-readable descriptions.
Possible Approach to Implementation
This requirement specifies that useful information should be returned when a resource is referenced. This can include:
- Expressing properties and features of interest for a SpatialThing using common semantic descriptions.
- Expressing names of places; provides multiple names for your SpatialThings if they are known. These could be toponyms (names that appear on a map) or colloquial names (that local people use for a place). This part will explain in more detail how to provide the names/labels for the spatial things that are referred to. (e.g. a way to do this could be rdfs:label)
- A 'place' may have an indistinct (or even undefined) boundary. It is often useful to identify spatial things even though they are fuzzy. For example: 'Renaissance Italy' or 'the American West'.
- Information (about a SpatialThing; a place) should be provided with information about authority (owner, publisher), timeliness (i.e. is it valid now? is it historical data?) and, (if applicable) quality. It is common, for example, that there exist many maps of a place - none of them the same. In that case users need to know who produced each one, to be able to choose the right one to use.
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-MultilingualSupport, R-SpatialVagueness
How to describe geometry
Geometry data should be expressed in a way that allows its publication and use on the Web.
Why
This best practice helps with choosing the right format for describing geometry based on aspects like performance and tool support. It also helps when deciding on whether or not using literals for geometric representations is a good idea.
Intended Outcome
The format chosen to express geometry data should:
- Support the dimensionality of the geometry;
- Be supported by the software tools used within data user community;
- Keep geometry descriptions to a size that is conventient for Web applications.
Possible Approach to Implementation
Steps to follow:
- Decide on the geometric data representations based on performance; in some cases, geometry can be 95% of the total data size;
- Determine the dimensionality of geometry data (0d 'point' to 3d 'volume')
- Choose the right format and deciding on when to use geometry literals. For geometry literals, several solutions are available, like Well-Known Text (WKT) representations, GeoHash and other geocoding representations. The alternative is to use structured geometry objects as is possible, for example, in [[GeoSPARQL]].
- There are also several suitable binary data formats (e.g. Google's protocol buffers for vector tiling); however, some binary formats do not (effectively) work on the Web as there are no software tools for working with those formats from within a typical Web application; to work with data in such formats, you must first download the data and then work with it locally.
- There are widespread practices for representing geometric data as linked data, such as using W3C WGS84 Geo Positioning vocabulary (geo)
geo:latandgeo:longthat are used extensively for describinggeo:Pointobjects. - Concrete geometry types are available, such as those defined in the OpenGIS [[Simple-Features]] Specification, namely 0-dimensional Point and MultiPoint; 1-dimensional curve LineString and MultiLineString; 2-dimensional surface Polygon and MultiPolygon; and the heterogeneous GeometryCollection.
How to Test
...
Evidence
Relevant requirements: R-BoundingBoxCentroid, R-Compressible, R-CRSDefinition, R-EncodingForVectorGeometry, R-IndependenceOnReferenceSystems, R-MachineToMachine, R-SpatialMetadata, R-3DSupport, R-TimeDependentCRS, R-TilingSupport.
Specify Coordinate Reference System for high-precision applications
A coordinate referencing system should be specified for high-precision applications to locate geospatial entities.
Why
The choice of CRS is sensitive to the intended domain of application for the geospatial data. For the majority of applications a common global CRS (WGS84) is fine, but high precision applications (such as precision agriculture and defence) require spatial referencing to be accurate to a few meters or even centimeters.
Add explanation of why there are so many CRSs.
Need to clarify when and why people use different CRS's
The misuse of spatial data, because of confusion about the CRS, can result in catastrophic results; e.g. both the bombing of the Chinese Embassy in Belgrade during the Balkan conflict and fatal incidents along the East Timor border are generally attributed to spatial referencing problems.
Intended Outcome
A Coordinate Reference System (CRS) sensitive to the intended domain of application (e.g. high precision applications) for the geospatial data should be chosen.
Possible Approach to Implementation
Recommendations about CRS referencing should consider:
- When a default Coordinate Reference System is sufficient.
- The choice of CRS should be sensitive to the intended domain of application for the geospatial data.
- WGS84 is a common choice of CRS - although this in itself is ambiguous: we need to assert whether data relates to the ellipsoid (datum surface) or the geoid (gravitational equipotential surface; EGM96).
- WGS84 is a reasonable choice for many human-scale activities (e.g. navigation). However, given that the earth's surface is constantly moving (e.g. Australia moves by 7cm per year), WGS84 is not appropriate for precision applications. For example, the defense community uses 12 separate Mercator projections to maintain accuracy around the globe whilst the Australian national mapping authority is considering use of a dynamic datum [citation required].
- For convenience, the CRS is often designated within the data format or vocabulary specification (e.g. W3C WGS84 Geo Positioning vocabulary) and, therefore, does not appear in the data itself. This is often considered as a default CRS. Data publishers and consumers should make sure they are aware of the specified CRS and any limitations that this may pose regarding the use of the data.
- Where a specific CRS is required, the data publisher should choose a vocabulary where the CRS can be defined explicitly within the data.
How to Test
...
Evidence
Relevant requirements: R-DefaultCRS
How to describe relative positions
Provide a relative positioning capability in which the entities can be linked to a specific position.
Why
In some cases it is needed to describe the location of an entity in relation to another location or in relation to location of another entity. For example, South-West of Guildford, close to London Bridge.
Intended Outcome
It should be possible to describe the location of an entity in relation to another entity or in relation to a specific location, instead of specifying a geometry.
The relative positioning descriptions should be machine-interpretable and/or human-readable.
Possible Approach to Implementation
The relative positioning should be provided as:
- A positioning capability to describe the position of entities with explicit links to a specific location and/or other entities.
- Semantic descriptions for relative positions and relative associations to an explicit or absolute positioning capability.
Do we need this as a best practice; if yes, this BP needs more content
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-SamplingTopology.
How to describe positional (in)accuracy
Accuracy and precision of spatial data should be specified in machine-interpretable and human-readable form.
Why
The amount of detail that is provided in spatial data and the resolution of the data can vary. No measurement system is infinitely precise and in some cases the spatial data can be intentionally generalized (e.g. merging entities, reducing the details, and aggregation of the data) [[Veregin]].
Intended Outcome
When known, the resolution and precision of spatial data should be specified in a way to allow consumers of the data to be aware of the resolution and level of details that are considered in the specifications.
Possible Approach to Implementation
...
We need some explanations for the approaches to describe positional (in)accuracy.
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-QualityMetadata.
How to describe properties that change over time
Entities and their data should have versioning with time/location references
Why
Entities and their properties can change over time and this change can be related to spatial properties, for example when a spatial thing moves from one location to another location, or when it becomes bigger or smaller. For some use cases you need to be able to explicitly refer to a particular version of information that describes a SpatialThing, or to infer which geometry is appropriate at a specific time, based on the versioning. To make this possible, the properties that are described for an entity should have references to the time and location that the information describing a SpatialThing was captured and should retain a version history. This allows you to reference the most recent data as well as previous versions and to also follow the changes of the properties.
Intended Outcome
Properties described in a dataset will include a time (and/or location) stamp and also versioning information to allow tracking of the changes and accessing the most up-to-date properties data.
Possible Approach to Implementation
Need to include guidance on when a lightweight approach (ignoring the change aspects) is appropriate
When entities and their properties can change over time, or are valid only at a given time, and this needs to be captured, it is important to specify a clear relationship between property data and its versioning information. How properties are versioned should be explained in the specification or schema that defines those properties. Temporal and/or spatial metadata should be provided to indicate when and where the information about the SpatialThing was captured.
For an example of how to version information about entities and their properties and retaining a version history, see version:VersionedThing and version:Version at https://github.com/UKGovLD/registry-core/wiki/Principles-and-concepts#versioned-types.
It is also useful to incorporate information on how often the information might change, i.e. the frequency of update.
Data publishers must decide how much change is acceptable before a SpatialThing cannot be considered equivalent. At this point, a new identifier should be used as the subject for all properties about the changed SpatialThing. Also see Best Practice 4: Provide stable identifiers for Things (resources) that change over time.
How to work with data that is such high volume (e.g. sensor data streams) that the data is discarded after a period of time?
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-MovingFeatures, R-Streamable
Publishing data with clear semantics
In most cases, the effective use of information resources requires understanding thematic concepts in addition to the spatial ones; "spatial" is just a facet of the broader information space. For example, when the Dutch Fire Service responded to an incident at a day care center, they needed to evacuate the children. In this case, the 2nd closest alternative day care center was preferred because it was operated by the same organization as the one that was subject of the incident, and they knew who all the children were.
This best practice document provides mechanisms for determining how places and locations are related - but determining the compatibility or validity of thematic data elements is beyond our scope; we're not attempting to solve the problem of different views on the same/similar resources.
Thematic semantics are out of scope for this best practice document. For associated best practices, please refer to [[DWBP]] Metadata, Best Practice 4 Provide structural metadata; and [[DWBP]] Vocabularies, Best Practice 15 Use standardized terms, Best Practice 16 RE-use vocabularies and Best Practice 17 Choose the right formalization level.
See also [[LD-BP]] Vocabularies.
Use spatial semantics for spatial Things
The best vocabulary should be chosen to describe the available spatial things.
Why
The spatial things can be described using several available vocabularies. A robust methodology or an informed decision making process should be adapted to choose the best available vocabulary to describe the entities.
Intended Outcome
Entities and their properties are described using common and reusable vocabularies to increase and improve the interoperability of the descriptions.
Possible Approach to Implementation
There are various vocabularies that provide common information (semantics) about spatial things, such as Basic Geo vocabulary, [[GeoSPARQL]] or schema.org that provide common information about spatial things. This best practice helps you decide which vocabulary to use. The semantic description of entities and their properties should use the existing common vocabularies in their descriptions to increase the interoperability with other descriptions that may refer to the same vocabularies. For this it is required to:
- Go through a selection process to decide on the existing and relevant vocabularies that can be used to describe the spatial things and their properties.
- Maintain links to the vocabularies in the schema definitions and provide linked-data descriptions.
- Define location and spatial references using the common vocabulary concepts whenever applicable instead of defining your own location instance.
- Provide thematic semantics and general descriptions of spatial things and their properties as linked data. They should have URIs in which when you look those up you can see what they mean. For more information refer to [[DWBP]] Best Practice 4: Provide structural metadata.
There are different vocabularies that are related to spatial things. This best practice will provide a method for selecting the right vocabulary for your task, in the form of a durable methodology or an actionable selection list.
The Basic Geo vocabulary has a class SpatialThing which has a very broad definition. This can be applicable (as a generic concept) to most of the common use-cases.
For some use cases we might need something more specific.
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-MobileSensors, R-MovingFeatures.
We might publish in the BP or a complimentary note a set of statements mapping the set of available vocabularies about spatial things. There are mappings available e.g. GeoNames has a mapping with schema.org. http://www.geonames.org/ontology/mappings_v3.01.rdf
Assert known relationships
Spatial relationships between Things should be specified in forms of geographical, topological and hierarchical links.
Why
It is often more efficient to rely on relationships asserted between SpatialThings rather than rely on solutions such as analysis of geometries to find out that two Things are, for example, at the same place, near each other, or one is inside the other. Describing the spatial relationships between SpatialThings can be based on relationships such as topological, geographical and hierarchical (e.g. partOf) links.
Relating SpatialThings to other spatial data enables, for example, digital personal assistants (e.g. Siri, Cortana) to make helpful suggestions or infer useful information such as "address" and "description" attributes added to extent data model of GeoLocation API. See also W3C EMMA 2.0; devices provide location and time-stamp data, and this helps us, for example:
- Determining whether 'this' device interaction was 'within' a car, rather than the device being carried by a pedestrian, may result in different outcomes or suggestions
- Determining whether an event for a traveler took place after the journey started and before it ended … we can infer the event was on-route
- 'near' is contextual - it depends if you're walking or driving
- Capturing social information; "I'm on my way to work" rather than "I'm here" … where work is a SpatialThing with indistinct boundaries
Intended Outcome
This requirement will allow expressing explicit spatial relationships between Things in the form of geographical, topological and hierarchical links that will not need post geometric processing and inferring to find the spatial links.
Possible Approach to Implementation
How to use spatial functions to find out if spatial things have corresponding geometries is described in Best Practice 3: Working with data that lacks globally unique identifiers for entity-level resources. This best practice describes how to express these discovered relationships between resources about physical and conceptual spatial things.
The asserted spatial semantics can include relationship such as nearby, contains, etc. This best practice requires specifying geometric, topological and social spatial relationships. It is also important to determine which relationships are appropriate for a given case (This is beyond the scope of this BP). This best practice requires:
- The geographical, topological and social hierarchy (part of) should be described with clear semantics and registered with IANA Link relations.
- Hierarchical relationships (i.e. part of, for example between administrative regions, have a specific need for defining "Mutually Exclusive Collectively Exhaustive" (MECE) set.
- Topological relationships that are described for an entity should have references to concepts such as over, under etc.
- Spatial relationships can use concepts such as Region Connection Calculus (RCC8) that contains, overlaps, touches, intersects, adjacent to, or "spatial predicates" or also other similar concepts from Allen Calculus.
Social relationships can be defined based on perception; e.g. "samePlaceAs", nearby, south of. These relationships can also be defined based on temporal concepts such as: after, around, etc. In current practice, there is no such property as samePlaceAs to express the social notion of place; enabling communities to unambiguously indicate that they are referring to the same place but without getting hung up on the semantic complexities inherent in the use of owl:sameAs or similar.
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-SamplingTopology, R-SpatialRelationships, R-SpatialOperators.
Which vocabularies out there have social spatial relationships? FOAF, GeoNames, ...
Temporal aspects of spatial data
Temporal relationship types will be described here and be entered eventually as link relationship types into the IANA registry, Link relations, just like the spatial relationships.
In the same sense as with spatial data, temporal data can be fuzzy.
Retain section; point to where temporal data is discussed in detail elsewhere in this document.
Spatial data from sensors and observations
The best practices described in this document will incorporate practice from both Observations and Measurements [[OandM]] and W3C Semantic Sensor Network Ontology [[SSN]].
See also W3C Generic Sensor API and OGC Sensor Things API. These are more about interacting with sensor devices.
Provide context required to interpret observation data values
Observation data should be linked to spatial, temporal and thematic information that describes the data.
Why
Processing and interpreting observation and measurement data in many use cases will require other contextual information including spatial, temporal and thematic information. This information should be specified as explicit semantic data and/or be provided as linked to other resources.
Intended Outcome
The contextual data will specify spatial, temporal and thematic data and other information that can assist to interpret the observation data; this can include information related to quality, observed property, location, time, topic, type, etc.
Possible Approach to Implementation
The context required to interpret observation values will require:
- Specify explicit semantics that describe temporal, spatial and thematic information related to an entity
- Provide links to to other related resources that can describe contextual information related to observation data
- Specify provenance and other related information to the observation
- Information related to the resource that provide the data (and properties of that resource/device; e.g. quality of measurement) can also help to interpret the observation data more effectively. For more information refer to SSN Ontology
How to Test
...
Evidence
Relevant requirements: R-ObservedPropertyInCoverage, R-QualityMetadata, R-SensorMetadata, R-SensingProcedure, R-UncertaintyInObservations.
Describe sensor data processing workflows
Processing steps that are used in collecting and publication of sensor data should be specified as semantic data associated to the sensor observations.
Why
Sensor data often goes through different pre-processing steps before making the data available to end-users. Providing information about these processes and workflows that are undertaken in collection and preparation of sensor data helps users understand how the data is modified and decide whether the data is appropriate for a given application/purpose.
Intended Outcome
Explicit semantic descriptions and/or links to external resources that describe the processing workflows that are used in collection and preparation of the sensor data.
Possible Approach to Implementation
Processing workflows are often employed to transform raw observation data into more usable forms. For example, satellite data often undergoes multiple processing steps (e.g. pixel classification, georeferencing) to create usable products. It is important to understand the provenance of the data and how it has been modified in order to determine whether the resulting data product can be used for a given purpose. This will require:
- Providing explicit semantics or links related to provenance data and semantic description of processing workflows that are applied to the raw data.
- Describing processing methods and their parameters (for example aggregation methods and their settings and functions that are applied).
- Providing links to the original data for each step (if the data is available).
- W3C PROV ontology can be used to describe the processing steps
How to Test
...
Evidence
Relevant requirements: R-ObservationAggregations, R-Provenance.
Relate observation data to the real world
Provide links between the observation and measurement data and the real world objects and/or subject of interest.
Why
Observation and measurement data usually represents a feature of interest related to Things: some thing or phenomenon in the real world that is being observed and measured. This link between the observation and measurement data and real world concepts and their feature of interest will help interpreting and using the data more effectively and will specify their relationships with concepts in the real world.
Intended Outcome
It should be possible for data consumers to interpret the meaning of data by referring to real world concepts and features of interest related to Things that are represented by the data.
Possible Approach to Implementation
Real world concept description metadata should include the following information:
- Concepts of sampling feature from observation and measurement data.
- Representation of the subject of interest and more specific concepts of "specimen".
- Links to the Thing that the observation and measurement data is related to.
How to Test
...
Evidence
Relevant requirements: R-SamplingTopology.
How to work with crowd-sourced observations
Crowd-sourced data should be published as structured data with metadata that allows processing and interpreting it.
Why
Some social media channels do not allow use of structured data. Crowd-sourced data should be published as structured data with explicit semantics and also links to other related data (wherever applicable).
Human-readable and machine-readable metadata data should be provided with the crowd-sourced data.
Contextual data related to crowd sourced data should be available. Quality, trust and density levels of crowd-sourced data varies and it is important that the data is provided with contextual information that helps people judge the probable completeness and accuracy of the observations.
Intended Outcome
It should be possible for humans to have access to contextual information that describes the quality, completeness and trust levels of crowd-sourced observations. It should be possible for machines to automatically process the contextual information that describes the quality, completeness and trust levels of crowd-sourced observations.
Possible Approach to Implementation
The crowd-sourced data should be published as structured data with metadata that allows processing and interpreting it. The contextual information related to crowd-sourced data may be provided according to the vocabulary that is being developed by the DWBP working group (see [[DWBP]] Best Practice 7: Provide data quality information).
How to Test
...
Evidence
Relevant requirements: R-HumansAsSensors.
How to publish (and consume) sensor data streams
The overall (and common) features of a sensor data stream must be described by metadata
Why
Providing explicit metadata and semantic descriptions about the common features of a sensor data stream allows user agents to avoid adding repetitive information to individual data items and also allows to automatically discover sensor data streams on the Web and/or to understand (for human users) and interpret (for machine agents) the common features of sensor data streams.
Intended Outcome
- It should be possible for humans to understand the common features of a sensor data stream.
- It should be possible for machine agents to interpret the common features of a sensor data stream.
- It should be possible for machine agents be able to automatically discover a sensory data stream.
Possible Approach to Implementation
The sensor data stream metadata should include the following overall features of a dataset:
- The title and a description of the stream.
- The keywords describing the stream.
- Temporal and spatial information of the data stream.
- The contact point of the data stream provider.
- The access point and service API information.
- Thematic features of the data provided by the sensor data stream.
The information above should be included both in the human understandable and the machine interpretable forms of metadata.
The machine readable version of the discovery metadata may be provided according to models such as Stream Annotation Ontology (SAO)
How to Test
...
Evidence
Relevant requirements: R-MachineToMachine, R-Streamable, R-TemporalReferenceSystem, R-TimeSeries.
Linking spatial data
For data to be on the web the resources it describes need to be connected, or linked, to other resources. The connectedness of data is one of the fundamentals of the Linked Data approach that these best practices build upon. The 5-star rating for Linked Open Data asserts that to achieve the fifth star you must "link your data to other data to provide context". The benefits for consumers and publishers of linking to other data are listed as:
- You can discover more (related) data while consuming the data.
- You can directly learn about the data schema.
- You make your data discoverable.
- You increase the value of your data.
- Your own organization will gain the same benefits from the links as the [other] consumers.
Just like any type of data, spatial data benefits massively from linking when publishing on the web.
The widespread use of links within data is regarded as one of the most significant departures from contemporary practices used within SDIs.
Crucially, the use of links is predicated on the ability to identify the origin and target, or beginning and end, of the link. Best Practice 1: Use globally unique identifiers for entity-level resources is a prerequisite.
This section extends [[DWBP]] by providing best practices that are concerned with creating links between the resources described inside datasets. Best practices detailing the use of links to support discovery are provided in .
[[DWBP]] identifies Linkability as one of the benefits gained from implementing the Data on the Web best practices (see [[DWBP]] Data Identification Best Practice 11 Use persistent URIs as identifiers of datasets and Best Practice 12 Use persistent URIs as identifiers within datasets). However, no discussion is provided about how to create the links that the use those persistent URIs.
Make your entity-level links visible on the web
The data should be published with explicit links to other resources.
Why
Exposing entity-level links to web applications, user-agents and web crawlers allows the relationships between resources to be found without the data user needing to download the entire dataset for local analysis. Entity-level links provide explicit description of the relationships between resources and enable users to find related data and determine whether the related data is worth accessing. Entity-level links can be used to combine information from different sources; for example, to determine correlations in statistical data relating to the same location.
Intended Outcome
- It should be possible for humans to understand and follow the the entity-level links between resources.
- It should be possible for machine agents to interpret and explore the the entity-level links between resources.
- It should be possible for machine agents to automatically determine (and find) relationships between entities by exploring the links between them.
- It should be possible for a third party, who owns neither subject or object resources, to publish a set of links between resources.
Possible Approach to Implementation
To provide explicit entity-level links:
- Publish the data with links (to uniquely identified objects) embedded in the data.
- Publish sets of links as a complementary resource.
- Publish summaries of links for the dataset so that the semantics of the links can be evaluated and accessed if deemed appropriate.
The use of Linksets needs further discussion as evidence indicates that it is not yet a widely adopted best practice. It may be appropriate to publish such details in a Note co-authoried with the DWBP WG.
[[gml]] adopted the [[xlink11]] standard to represent links between resources. At the time of adoption, XLink was the only W3C-endorsed standard mechanism for describing links between resources within XML documents. The Open Geospatial Consortium anticipated broad adoption of XLink over time - and, with that adoption, provision of support within software tooling. While XML Schema, XPath, XSLT and XQuery etc. have seen good software support over the years, this never happened with XLink. The authors of GML note that given the lack of widespread support, use of Xlink within GML provided no significant advantage over and above use a bespoke mechanism tailored to the needs of GML.
[[void]] provides guidance on how to discover VoID descriptions (including Linksets)- both by browsing the VoID dataset descriptions themselves to find related datasets, and using /.well-known/void (as described in [[RFC5758]]).
How would a (user) agent discover that these 3rd-party link-sets existed? Is there evidence of usage in the wild?
Does the [[beacon]] link dump format allow the use of wild cards / regex in URLs (e.g. URI Template as defined in [[RFC6570]]?
The examples contain only outline information; further details must be added.
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Provide meaningful links
When providing a link, a data publisher should opt for a level of formal and meaningful semantics that helps data consumers to decide if the target resource is relevant to them.
Why
Formal and meaningful semantics may help to provide explicit specifications that describe the intended meaning of the relationships between the resources.
Providing details of the semantic relationship inferred by a link enables a data user to evaluate whether or not the target resource is relevant to them. Describing the affordances of the target resource (e.g. what that resource can do or be used for) helps the data user to determine whether it is worth following the link.
Intended Outcome
The links provided for the data should allow different data consumers and applications to determine the relevance of a target resource to them. The links should be precise and explicit.
How do we know what is at the end of a link - and what can I do with it / can it do for me (e.g. the 'affordances' of the target resource).
How to describe the 'affordances' of the target resource?
Possible Approach to Implementation
Ensure that the type of relationship used to link between resources is explicitly identified. Provide resolvable definitions of those relationship types.
Please refer to Best Practice 13: Assert known relationships for details of relationship types that may be used to describe spatial links (e.g. geographical, hierarchical, topological etc.). [[DWBP]] Section 9.9 Data Vocabularies provides futher information on use of relationship types described in well-defined vocabularies (see [[DWBP]] Best Practice 16: Use standardized terms and Best Practice 17: Reuse vocabularies).
How to Test
...
Evidence
Relevant requirements: R-Linkability
Link to spatial Things
Create durable links by connecting Spatial Things.
Why
Links enable a network of related resources to be connected together. For those connections to remain useful over a long period of time, both origin and target resources need to have durable identifiers. Typically, it is the SpatialThings that are given durable identifiers (see Best Practice 1: Use globally unique identifiers for entity-level resources) whereas the information resources that describe them (e.g. geometry objects) may be replaced by new versions.
When describing the relationships between related spatial resources, the links should connect SpatialThings.
Intended Outcome
Providing machine-interpretable and/or human-readable durable links between SpatialThings.
This best practice is concerned with the connections between SpatialThings. When describing an individual SpatialThing itself, it is often desirable to decompose the information into several uniquely identified objects. For example, the geometry of an administrative area may be managed as a separate resource due to the large number of geometric points required to describe the boundary.
Also note that in many cases, different identifiers are used to describe the SpatialThing and the information resource that describes that SpatialThing. For example, within DBpedia, the city of Sapporo, Japan, is identified as http://dbpedia.org/resource/Sapporo, while the information resource that describes this resource is identified as http://dbpedia.org/page/Sapporo. Care should be taken to select the identifier for the SpatialThing rather than the information resource that describes it; in the example above, this is http://dbpedia.org/resource/Sapporo.
Possible Approach to Implementation
- Link to the identifier for the SpatialThing itself rather than information resource(s) that describe it.
- Be aware that objects that describe SpatialThings (e.g. the geometry of a hydrological catchment) are prone to change as the information is updated.
Refer to Best Practice 20: Provide meaningful links for further information on providing the semantics for links.
How to link to a resource as it was at a particular time?
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Link to resources with well-known or authoritative identifiers
Link your spatial resources to others that are commonly used.
Why
In Linked Data, commonly used resources behave like hubs in the network of interlinked resources. By linking your spatial resources to those in common usage it will be easier to discover your resources. For example, a data user interested in air quality data about the place they live might begin by searching for that place in popular data repositories such as GeoNames, Wikidata or DBpedia. Once the user finds the resource that describes the correct place, they can search for data that refers to the identified resource that, in this case, relates to air quality.
Furthermore, by referring to resources in common usage, it becomes even easier to find those resources as search engines will prioritize resources that are linked to more often.
Refer to Best Practice 24: Use links to find related data for more details about how a user might use links to discover data.
Intended Outcome
Data publishers relate their data to commonly used spatial resources using links. Data users can quickly find the data they are interested in by browsing information that is related to commonly used spatial resources.
Possible Approach to Implementation
The link must convey the semantics appropriate to the application (see Best Practice 13: Assert known relationships and Best Practice 20: Provide meaningful links for more information).
A list of sources of commonly used spatial resources is provided in .How to Test
...
Evidence
Relevant requirements: R-Crawlability, R-Discoverability.
Link your spatial resources to other related resources
Why
Relationships between resources with with spatial extent (i.e. size, shape, or position; SpatialThings) can often inferred from their spatial properties. For example, two resources might occur at the same location suggesting that they may be the same resource, or one resource might exist entirely within the bounds of another resource suggesting some kind of hierarchical containment relationship. However, reconciliation of such resources is complex: it requires some degree of understanding about the semantics of the two, potentially related, resources in order to determine how they are related, if at all.
Rather than expecting that data consumers will have sufficient context to relate resources, it is better for data publishers to assert the relationships that they know about. Not only does this provide data users with clear information about how resources are related, it removes the need for complex spatial processing (e.g. region connection calculus) to determine potential relationships between resources with spatial extent because those relations are already made explicit.
Where possible, existing identifiers should be reused when referring to resources (see Best Practice 2: Reuse existing (authoritative) identifiers when available). However, the use of multiple identifiers for the same resource is commonplace, for example, where data publishers from different jurisdictions refer to the same SpatialThing. In this special case, properties such as owl:sameAs can be used to declare that multiple identifiers refer to the same resource. It is often the case that data published from different sources about the same physical or conceptual resource may provide different view points.
Intended Outcome
A data user can browse between (information about) related resources using the explicitly defined links to discover more information.
In the special case that the property owl:sameAs is used to relate identifiers, information whose subject is one of the respective identifiers can be combined.
A data user should always exercise some discretion when working with data from different sources; for example, to determine whether the data is timely, accurate or trustworthy. Further discussion on this issue is beyond the scope of these best practices.
Possible Approach to Implementation
Given their in depth understanding of the content they publish, data publishers are in a good position to determine the relationships between related resources. Data publishers should analyze their data to determine related resources.
The mechanics of how to decide when two resources are the same are beyond the scope of this best practice. Tools (e.g. OpenRefine and Silk Linked Data Integration Framework) are available to assist with such reconciliation and may provide further insight.
The link must convey the semantics appropriate to the application (see Best Practice 13: Assert known relationships and Best Practice 20: Provide meaningful links for more information).
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Enabling discovery
[[DWBP]] provides best practices discussing the provision of metadata to support discovery of data at the dataset level (see [[DWBP]] section 9.2 Metadata for more details). This mode of discovery is well aligned with the practices used in Spatial Data Infrastructure (SDI) where a user begins their search for spatial data by submitting a query to a catalog. Once the appropriate dataset has been located, the information provided by the catalog enables the user to find a service end-point from which to access the data itself - which may be as simple as providing a mechanism to download the entire dataset for local usage or may provide a rich API enabling the users to request only the required parts for their needs. The dataset-level metadata is used by the catalog to match the appropriate dataset(s) with the user's query.
This section includes a best practice for including spatial information in the dataset metadata, for example, the spatial extent of the dataset.
However, one of the criteria for exposing data on the Web is that it can be discovered directly using search engines such as Google, Bing and Yandex. Current SDI approaches treat spatial data much like books in a library where you must first use the librarian's card catalog index to find the book on the shelf. As for other types of data on the Web, we want to be able to find spatial resources directly; we want to move beyond the two-step discovery approach of contemporary SDIs and find the words, sentences and chapters in a book without needing to check the card catalog first. Not only will this make spatial data far more accessible, it mitigates the problems caused when catalogs have only stale dataset metadata and removes the need for data users to be proficient with the query protocol of the dataset's service end-point in order to acquire the data they need.
In the wider Web, it is links that enable this direct discovery: from user-agents following a hyperlink to find related information to search engines using links to prioritise and refine search results. Whereas discusses the creation of links, this section is largely concerned with the use of those links to support discovery of the SpatialThings described in spatial datasets.
Related data to a spatial dataset and its individual data items should be discoverable by browsing the links
Why
In much the same way as the document Web allows one to find related content by following hyperlinks, the links between spatial datasets, SpatialThings described in those datasets and other resources on the Web enable humans and software agents to explore rich and diverse content without the need to download a collection of datasets for local processing in order to determine the relationships between resources.
Spatial data is typically well structured; datasets contain SpatialThings that can be uniquely identified. This means that spatial data is well suited to the use of links to find related content.
The emergency response to natural disasters is often delayed by the need to download and correlate spatial datasets before effective planning can begin. Not only is the initial response hampered, but often the correlations between resources in datasets are discarded once the emergency response is complete because participants have not been able to capture and republish those correlations for subsequent usage.
Intended Outcome
It should be possible for humans to explore the links between a spatial dataset (or its individual items) and other related data on the Web.
It should be possible for software agents to automatically discover related data by exploring the links between a spatial dataset (or its individual items) and other resources on the Web.
It should be possible for a human or software agent to determine which links are relevant to them and which links can be considered trustworthy.
What do we expect user-agents to do with a multitude of links from a single resource? A document hyperlink has just one target; but in data, a resource may be related to many things.
Possible Approach to Implementation
- For a given subject resource find all the related resources that it refers to.
- Evaluate the property type that is used to relate each resource in order to determine relevance (see Best Practice 20: Provide meaningful links).
- Use the metadata for the dataset within which the subject resource is described in order to determine which links to "trust" (e.g. whether to use the data or not); owner / publisher, quality information, community annotations (“likes”), publication date etc.
- Aggregate links from trusted sources into a database. Referring URLs can be indexed to determine which resources refer to the subject resource, i.e. "what points to me?". These referring links are sometimes called back-links. Dataset-level metadata may provide information regarding the frequency of update for the information sources, enabling one to determine a mechanism for keeping the aggregated link-set fresh.
These "back-links" can be traversed to find related information and also help a publisher assess the value of their content by making it possible to see who is using (or referencing) their data.
- Use network / graph analysis algorithms to determine related information that is not directly connected; i.e. resources that are connected via a chain of links and intermediate resources.
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Make your entity-level data indexable by search engines
Search engines should receive a metadata response to a HTTP GET when dereferencing the link target URI.
Why
Current SDI approaches require a 2-step approach for discovery, beginning with a catalog query and then accessing the appropriate data service end-point.
Exposing data on the Web means that it can be discovered directly using search engines. This provides a number of benefits:
- Spatial data will become far more discoverable because a user does not need any special knowledge to find the SDIs catalog service.
- Users can discover what data is actually available, rather than relying on the metadata that is infrquently published to the catalog and may have become stale.
- Users do not need to be proficient with the query protocol of the dataset's service end-point in order to acquire the data they need.
Search engines should be able to use links and URIs to discover indexable spatial data and to prioritize those spatial data collections within a search result.
Search engines use links to discover content to index and to prioritize that content within a search result.
Intended Outcome
Spatial data should be discoverable directly using a search engine query.
Spatial data is indexable by search engines; a search engine Web crawler should be able to obtain descriptive and machine interpretable metadata response to a HTTP GET when dereferencing the URL of a SpatialThing and to determine links to related data for the Web crawler to follow.
We make the assertion that data is not really 'on the web' until it's crawlable.
Possible Approach to Implementation
To make your entity-level data indexable by search engines:
- Generate one HTML page per resource. Include structured markup (see schema.org) that the search engines can use to make more detailed assumptions about your resource(s) and drive better search performance. Either create pages beforehand or generate them at query time via an API.
- Provide a path for search engines to find your pages - either crawling to each entity from a 'collection' object (which provides the entry point for the web crawler) or being directed by sitemaps.
- Search engines may be used to search spatial data based on identifier, location, time, etc (some examples are provided in [Section III.A, Barnaghi et al.]. The search for spatial data can be similar to the typical search query, but the search and use of results in many cases will be done by software agents and other services like Google Now that interpret information.
More discussion is required on how to structure meaningful (spatial) queries with search engines (e.g. based on identifier, location, time etc.).
As more spatial datasets are published that provide structured markup to search engine Web crawlers enabling the content of those datasets to be indexed, the more likely that search engines will provide richer and more sophisticated search mechanisms to exploit that markup which will further improve the ability of users to find spatial data.
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Include spatial information in dataset metadata
The description of datasets that have spatial features should include explicit metadata about the spatial information
Why
It is often useful to provide metadata at the dataset-level. The dataset is the unit of governance for information, which means that details like license, ownership and maintenance regime etc. need only be stated once, rather than for every resource description it contains. Data that is not directly accessible due to commercial or privacy arrangements can also be publicized using summary metadata provided for the dataset. [[DWBP]] section 9.2 Metadata provides more details.
For spatial data, it is often necessary to describe the spatial details of the dataset - such as extent and resolution. This information is used by SDI catalog services that offer spatial query to find data.
Intended Outcome
Dataset metadata should include the information necessary to enable spatial queries within catalog services such as those provided by SDIs.
Dataset metadata should include the information required for a user to evaluate whether the spatial data is suitable for their intented application.
Possible Approach to Implementation
To include spatial information in datasets one can:
- Provide information about the spatial attributes of the dataset; such as the spatial extent of the features described by the dataset.
- Use common vocabularies for geospatial semantics (e.g. GeoNames) and geospatial ontologies (see W3C Geospatial Incubator Group (GeoXG)'s report) to describe the spatial information for the datasets.
- Provide explicit metadata regarding mobility and/or APIs that can provide information about the spatial features (e.g. location) of a dataset or its data items.
How to Test
...
Evidence
Relevant requirements: R-Discoverability, R-Compatibility, R-BoundingBoxCentroid, R-Crawlability, R-SpatialMetadata and R-Provenance.
Exposing datasets through Web services
Should content from this section be moved to [[DWBP]] section 9.11 Data Access?
SDIs have long been used to provide access to spatial data via web services; typically using open standard specifications from the Open Geospatial Consortium (OGC). With the exception of the Web Map Service, these OGC Web service specifications have not seen widespread adoption beyond the geospatial expert community. In parallel, we have seen widespread emergence of Web applications that use spatial data - albeit focusing largely on point-based data.
This section seeks to capture the best practices that have emerged from the wider Web community for accessing spatial data via the Web. While [[DWBP]] provides best practices discussing access to data using Web infrastructure (see [[DWBP]] section 9.11 Data Access), this section provides additional insight for publishers of spatial data. In particular, we look at how Application Program Interfaces (API) may be used to make it easy to work with spatial data.
The term API as used here refers to the combination of the set of operations provided and the data content exposed by a particular Web service end-point.
Publish data at the granularity you can support
Granularity of mechanisms provided to access access a dataset should be decided based on available resources
Why
Making data available on the Web requires data publishers to provide some form of access to the data. There are numerous mechanisms available, each providing varying levels of utility and incurring differing levels of effort and cost to implement and maintain. Publishers of spatial data should make their data available on the Web using affordable mechanisms in order to ensure long-term, sustainable access to their data.
Intended Outcome
Data is published on the Web in a mechanism that the data publisher can afford to implement and support throughout the anticipated lifetime of the data.
Possible Approach to Implementation
When determining the mechanism to be used provide Web access to data, publishers need to assess utility against cost. In order of increasing usefulness and cost:
- Bulk-download or streaming of the entire dataset (see [[DWBP]] Best Practice 20: Provide bulk download)
- Generalized query API (such as WFS or SPARQL [[sparql11-overview]])
- Bespoke API designed to support a particular application (see Best Practice 28: Expose entity-level data through 'convenience APIs')
[[DWBP]] indicates that when data that is logically organized as one container and is distributed across many URLs, accessing the data in bulk is useful. As a minimum, it should be possible for users to download data on the Web as a single resource; e.g. through bulk file formats.
A data publisher need not incur all the costs alone. Given motivation, third parties (such as the open data community or commercial providers) may provide value-added services that build on simple bulk-download or generalized query interfaces. While establishing such arrangements is beyond the scope of this document, it is important to note that the data publisher should consider the end-to-end data publication chain. For example, one may need to consider including conditions in the usage license about the timeliness of frequently changing data.
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Expose entity-level data through 'convenience APIs'
If you have a specific application in mind for publishing your data, tailor the spatial data API to meet that goal.
Why
When access to spatial data is provided by bulk download or through a generalized query service, users need to understand how the data is structured in order to work effectively with that data. Given that spatial data may be arbitrarily complex, this burdens the data user with significant effort before they can even perform simple queries. Convenience APIs are tailored to meet a specific goal; enabling a user to engage with arbitrarily complex data structures using (a set of) simple queries. As stated in [[DWBP]], an API offers the greatest flexibility and processability for consumers of data; for example, enabling real-time data usage, filtering on request, and the ability to work with the data at an atomic level. If your dataset is large, frequently updated, or highly complex, a convenience API is likely to be helpful.
Intended Outcome
- The API provides a coherent set of queries and operations that help users achieve common tasks.
- Data users are presented with a set of simple operations within the API that enable them to get working with the data quickly; they do not need to understand the structure and semantics of the data up front.
- Data users are able to use progressively more complex features of the API as their understanding of the data increases.
- The API provides both machine readable data and human readable HTML markup; the latter is used by search engines to index the spatial data.
- The API encapsulates (i.e. hides) the complexity of the data is exposes.
- The API is versioned, enabling developers to upgrade their client application at a convenient time.
Possible Approach to Implementation
This best practice extends [[DWBP]] Best Practice 26: Use an API.
The API should be targeted to deliver a coherent set of functions that are design to meet the needs of common tasks. Work with your developer community to determine the tasks that they want to do with the data or use your experience to infer those tasks. Design your API to help developers achieve those tasks. API operations may be one of:
- query and response - for requesting data
- publish and subscribe - for disseminating real-time or event-based data
- transaction - for storing, modifying, processing or analysing data
Include light-weight queries and/or operations in the API that help users start working with your data quickly. The complexity of the data should be hidden from inexperienced users.
The API should offer both machine readable data and human readable HTML that includes the structured metadata required by search engines seeking to index content (see Best Practice 25: Make your entity-level data indexable by search engines for more details).
When designing the API, each operation or query should be focused on achieving a single outcome; this should ensure that the API remains light-weight. Groups of API operations may be chained together (like unix pipes) in order to complete complex tasks.
When designing APIs, data publishers must be aware of the constraints of operating in a Web environment. Providing access to large datasets, such as coverages, is a particular challenge. The API should provide mechanisms to request subsets of the dataset that are a convenient size for client applications to manage.
APIs will often evolve as more data is added or usage changes; queries or operations may be changed or new ones added. APIs should be versioned in order to insulate downstream client applications from these changes.
Regarding API design, also see [[DWBP]] Best Practice 21: Use Web Standardized Interfaces.
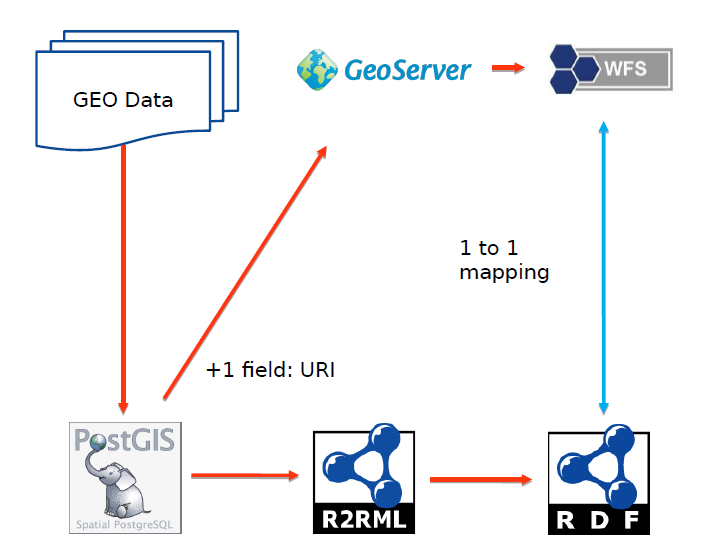
In the geospatial domain there are a lot of WFS services providing data. A RESTful API as a wrapper or a shim layer could be created around WFS services. GML content from the WFS service could be provided in this way as linked data or another Web friendly format. This approach is similar to the use of Z39.50 in the library community; that protocol is still used but 'modern' Web sites and web services are wrapped around it. Adding URIs in (GML) data exposed by a WFS is pretty straightforward, but making the data 'webby' is harder. There are examples of this approach of creating a convenience API on top of WFS, but rather than adapting the WFS (GML) output, it may be more effective to provide an alternative 'Linked Data friendly' access path to the data source; creating a new, complementary service endpoint e.g. expose the underpinning postGIS database via SPARQL endpoint (using something like ontop-spatial) and Linked Data API.
How to Test
...
Evidence
Relevant requirements: R-Compatibility, R-LightweightAPI.
APIs should be self-describing
APIs should provide a discoverable description of their contents and how to interact with it. Ideally this should be a machine-readable description.
Why
Good information about an API lets potential users determine if the API is a good resource to use for a given task and how to use it, as well as letting machines find out how to interact with it.
Intended Outcome
The API description enables a user to construct meaningful queries against the API for data that the API can actually provide.
A user can find the API description; e.g. via referral from the API or via a search engine query.
Possible Approach to Implementation
This best practice extends [[DWBP]] Best Practice 25: Document your API.
API documentation should describe the data(set) it exposes; the APIs operations and parameters; what kind of format / payload the API offers; and API versioning.
As a minimum, you should provide a human readable description of your APIs so that developers can read about how the API works. We recommend providing machine readable API documentation that can be used by software development tools to help developers build API client software. API documentation should be crawlable via search engines.
The API documentation should be generated from the API code so that the documentation can be easily kept upto date.
Where a parameter domain is bound to a set of values (e.g. value range, spatial or temporal extent, controlled vocabulary etc.), the API documentation or the API itself should indicate the set of values that may be used in order to help users request data that is actually available.
The API documentation should be discoverable from the API itself.
How to Test
...
Evidence
Relevant requirements: R-Discoverability ... others to be added.
Include search capability in your data access API
If you publish an API to access your data, make sure it allows users to search for specific data.
Should BP "Include search capability in your data access API" move to ?
Why
It can be hard to find a particular resource within a dataset, requiring either prior knowledge of the respective identifier for that resource and/or some intelligent manual guesswork. It is likely that users will not know the URI of the resource that they are looking for- but may know (at least part of) the name of the resource or some other details. A search capability will help a user to determine the identifier for the resource(s) they need using the limited information they have.
Intended Outcome
A user can do a text search on the name, label or other property of an entity that they are interested in to help them find the URI of the related resource.
Possible Approach to Implementation
to be added
How to Test
...
Evidence
Relevant requirements: {... hyperlinked list of use cases ...}
Dealing with large datasets
There are several Best Practices in this document dealing with large datasets and coverages:
- Best Practice 5: Provide identifiers for parts of larger information resources
- Best Practice 7: How to describe geometry
- Best Practice 28: Expose entity-level data through 'convenience APIs'
Should we discuss scaleability issues here?