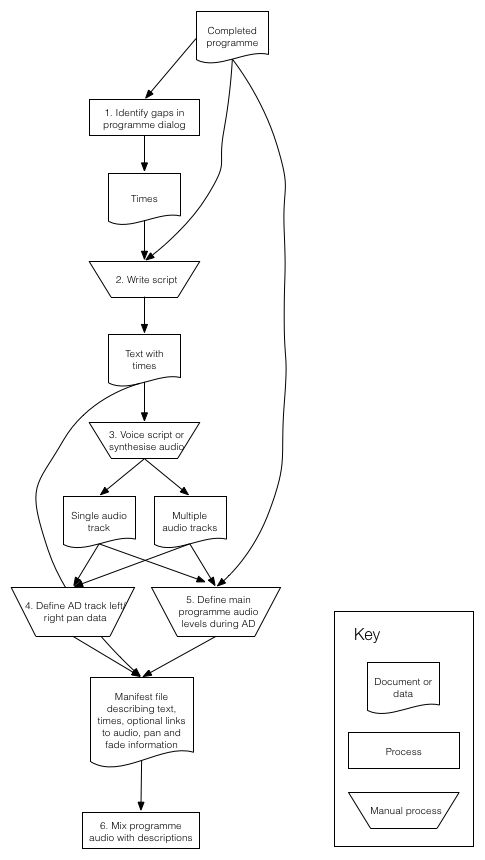
Scope
This specification defines a single text-based profile of the Timed Text Markup Language version 2.0 [[TTML2]]. This profile is intended to support audio description workflows worldwide, including description creation, script delivery and exchange and generated audio description distribution.
The proposed profile is a syntactic subset of the Timed Text Markup Language version 2.0 [[TTML2]], and a document can simultaneously conform to both the base standard and the proposed profile.
This document defines NO extensions to [[TTML2]].
This document is the first version of this proposal.
Documentation Conventions
This document uses the same conventions as [[TTML2]] for the specification of parameter attributes, styling attributes and metadata elements. In particular:
Section 2.3 of [[TTML2]] specifies conventions used in the [[XML]] representation of elements; and
Sections 6.2 and 8.2 of [[TTML2]] specify conventions used when specifying the syntax of attribute values.
All content of this specification that is not explicitly marked as non-normative is considered to be normative.
If a section or appendix header contains the expression "non-normative", then the entirety of the section or appendix is considered non-normative.
This specification uses Feature designations as defined in Appendices E at [[TTML2]]:
when making reference to content conformance, these designations refer to the syntactic expression or the semantic capability associated with each designated Feature; and
when making reference to processor conformance, these designations refer to processing requirements associated with each designated Feature.
If the name of an element referenced in this specification is not namespace qualified, then the TT namespace applies (see 9.3 Namespaces.)
Definitions
The following terms are used in this proposal:
Audio description An audio rendition of a Description or a set of Descriptions.
Audio description mixed audio track The output of an audio mixer incorporating the main programme audio and the audio description.
Description A set of words that describe an aspect of the programme presentation, suitable for rendering into audio by means of vocalisation and recording or used as a Text Alternative source for speech to text translation.
Default Region See Section 11.3.1.1 at [][TTML2]].
Document Instance As defined by [[TTML2]].
Document Interchange Context As defined by [[TTML2]].
Document Processing Context See Section 2.2 at [[TTML2]].
Feature See Section 2.2 at [[TTML2]].
Intermediate Synchronic Document See Section 11.3.1.3 at [[TTML2]].
Linear White-Space See Section 2.3 at [[TTML2]].
Main programme audio The audio associated with the programme prior to any mixing with audio description.
Markup Language A human-readable computer language that uses tags to define elements within a document.
Markup files contain standard words, rather than typical programming syntax.
Presentation processor See Section 2.2 at [[TTML2]].
Processor Either a Presentation processor or a Transformation processor.
Profile A TTML profile specification is a document that lists all the features of TTML that are required / optional / prohibited within “document instances” (files) and “processors” (things that process the files), and any extensions or constraints.
Related Media Object See Section 2.2 at [[TTML2]].
Related Video Object A Related Media Object that consists of a sequence of image frames, each a rectangular array of pixels.
Root Container Region See Section 2.2 at [[TTML2]].
Text Alternative As defined in [[WCAG20]].
Timed Text Text media that is presented in synchrony with other media, such as audio and video with (optional) specified text presentation styling information such as font, colour and position.
Transformation processor See Section 2.2 at [[TTML2]].
TTML A Markup Language designed for the storage and delivery of Timed Text, as defined in [[TTML2]] primarily used in the television industry.
TTML is used for authoring, transcoding and exchanging timed text information and for delivering captions, subtitles, and other metadata for television material repurposed for the Web or, more generally, the Internet.
Profile
Profile Resolution Semantics
For the purpose of content processing, the determination of the resolved profile SHOULD take into account both the signaled profile, as defined in , and profile metadata, as designated by either (or both) the Document Interchange Context or (and) the Document Processing Context, which MAY entail inspecting document content.
If the resolved profile is not the Profile supported by the Processor but is feasibly interoperable with the Profile, then the resolved profile is the Profile.
If the resolved profile is undetermined or not supported by the Processor, then the Processor SHOULD nevertheless process the Document Instance using the Profile; otherwise, processing MAY be aborted.
If the resolved profile is not the proposed Profile, processing is outside the scope of this specification.
If the resolved profile is the profile supported by the Processor, then the Processor SHOULD process the Document Instance according to the Profile.
Constraints
Document Encoding
A Document Instance SHALL use UTF-8 character encoding as specified in [[UNICODE]].
Foreign Element and Attributes
A Document Instance MAY contain elements and attributes that are neither specifically permitted nor forbidden by a profile.
A transformation processor SHOULD preserve such elements or attributes whenever possible.
Document Instances remain subject to the content conformance requirements specified at Section 3.1 of [[TTML2]].
In particular, a Document Instance can contain elements and attributes not in any TT namespace, i.e. in foreign namespaces, since such elements and attributes are pruned by the algorithm at Section 4 of [[TTML2]] prior to evaluating content conformance.
For validation purposes it is good practice to define and use a content specification for all foreign namespace elements and attributes used within a Document Instance.
Namespaces
The following namespaces (see [[xml-names]]) are used in this specification:
| Name |
Prefix |
Value |
Defining Specification |
| XML |
xml |
http://www.w3.org/XML/1998/namespace |
[[xml-names]] |
| TT |
tt |
http://www.w3.org/ns/ttml |
[[TTML2]] |
| TT Parameter |
ttp |
http://www.w3.org/ns/ttml#parameter |
[[TTML2]] |
| TT Feature |
none |
http://www.w3.org/ns/ttml/feature/ |
[[TTML2]] |
| TT Audio Style |
tta: |
http://www.w3.org/ns/ttml#audio |
[[TTML2]] |
| ADPT 1.0 Profile Designator |
none |
|
This specification |
The namespace prefix values defined above are for convenience and Document Instances MAY use any prefix value that conforms to [[xml-names]].
The namespaces defined by this proposal document are mutable [[namespaceState]]; all undefined names in these namespaces are reserved for future standardization by the W3C.
Synchronization
Each intermediate synchronic document of the Document Instance is intended to be presented (audible) starting on a specific frame and removed (inaudible) by a specific frame of the Related Video Object.
When mapping a media time expression M to a frame F of a Related Video Object (or Related Media Object), e.g. for the purpose of mixing audio sources signalled by a Document Instance into the main program audio of the Related Video Object, the presentation processor SHALL map M to the frame F with the presentation time that is the closest to, but not less, than M.
EXAMPLE 1
A media time expression of 00:00:05.1 corresponds to frame ceiling( 5.1 × ( 1000 / 1001 × 30) ) = 153 of a Related Video Object with a frame rate of 1000 / 1001 × 30 ≈ 29.97.
In typical scenario, the same video program (the Related Video Object) will be used for Document Instance authoring, delivery and user playback.
The mapping from media time expression to Related Video Object above allows the author to precisely associate audio description content with video frames, e.g. around existing audio dialogue and sound effects.
In circumstances where the video program is downsampled during delivery, the application can specify that, at playback, the relative video object be considered the delivered video program upsampled to is original rate, thereby allowing audio content to be presented at the same temporal locations it was authored.
Profile Signaling
The ttp:profile attribute SHOULD be present on the tt element and equal to the designator of the ADPT 1.0 profile to which the Document Instance conforms.
Features
See Conformance for a definition of permitted, prohibited and optional.
| Feature |
Disposition |
Additional provision |
| Relative to the TT Feature namespace |
#animation-version-2 |
permitted |
|
#audio |
permitted |
|
#audio-description |
permitted |
|
#audio-speech |
permitted |
|
#backgroundColor-block |
prohibited |
|
#backgroundColor-region |
prohibited |
|
#cellResolution |
prohibited |
|
#chunk |
permitted |
|
#clockMode |
prohibited |
|
#clockMode-gps |
prohibited |
|
#clockMode-local |
prohibited |
|
#clockMode-utc |
prohibited |
|
#content |
permitted |
|
#contentProfiles |
permitted |
|
#core |
permitted |
|
#data |
permitted |
|
#display-block |
prohibited |
|
#display-inline |
prohibited |
|
#display-region |
prohibited |
|
#display |
prohibited Consider display="none" in relation to AD content |
|
#dropMode |
prohibited |
|
#dropMode-dropNTSC |
prohibited |
|
#dropMode-dropPAL |
prohibited |
|
#dropMode-nonDrop |
prohibited |
|
#embedded-audio |
permitted |
|
#embedded-data |
permitted |
|
#extent-root |
prohibited |
|
#extent |
prohibited |
|
#frameRate |
permitted |
If the Document Instance includes any time expression that uses the frames term or any
offset time expression that uses the f metric, the ttp:frameRate attribute SHALL be present
on the tt element.
|
#frameRateMultiplier |
permitted |
|
#gain |
permitted |
|
#layout |
prohibited |
|
#length-cell |
prohibited |
|
#length-integer |
prohibited |
|
#length-negative |
prohibited |
|
#length-percentage |
prohibited |
|
#length-pixel |
prohibited |
|
#length-positive |
prohibited |
|
#length-real |
prohibited |
|
#length |
prohibited |
|
#markerMode |
prohibited |
|
#markerMode-continuous |
prohibited |
|
#markerMode-discontinuous |
prohibited |
|
#metadata |
permitted |
|
#opacity |
prohibited |
|
#origin |
prohibited |
|
#overflow |
prohibited |
|
#overflow-visible |
prohibited |
|
#pan |
permitted |
|
#pitch |
permitted |
|
#pixelAspectRatio |
prohibited |
|
#presentation |
prohibited |
|
#processorProfiles |
permitted |
|
#profile |
permitted |
See .
|
#region-timing |
prohibited |
|
#resources |
permitted |
|
#showBackground |
prohibited |
|
#source |
permitted |
|
#speak |
permitted |
|
#speech |
permitted |
|
#structure |
permitted |
|
#styling |
permitted |
|
#styling-chained |
permitted |
|
#styling-inheritance-content |
permitted |
|
#styling-inheritance-region |
prohibited |
|
#styling-inline |
permitted |
|
#styling-nested |
permitted |
|
#styling-referential |
permitted |
|
#subFrameRate |
permitted |
|
#tickRate |
permitted |
ttp:tickRate SHALL be present on the tt element if the document contains any time
expression that uses the t metric. |
#timeBase-clock |
prohibited |
|
#timeBase-media |
permitted |
NOTE: [[TTML1]] specifies that the default timebase is "media" if
ttp:timeBase is not specified on tt.
|
#timeBase-smpte |
prohibited |
|
#time-clock-with-frames |
permitted |
|
#time-clock |
permitted |
|
#time-offset-with-frames |
permitted |
|
#time-offset-with-ticks |
permitted |
|
#time-offset |
permitted |
|
#timeContainer |
permitted |
|
#timing |
permitted |
- All time expressions within a Document Instance SHOULD use the same syntax, either
clock-time or offset-time.
- For any content element that contains
br elements or text nodes or a
smpte:backgroundImage attribute, both the begin attribute and one of either the
end or dur attributes SHOULD be specified on the content element or at least one of its
ancestors.
|
#transformation |
permitted |
See constraints at #profile.
|
#visibility-block |
prohibited |
|
#visibility-region |
prohibited |
|
#writingMode-horizontal-lr |
prohibited |
|
#writingMode-horizontal-rl |
prohibited |
|
#writingMode-horizontal |
prohibited |
|
#zIndex |
prohibited |
|
Web Audio Mixing
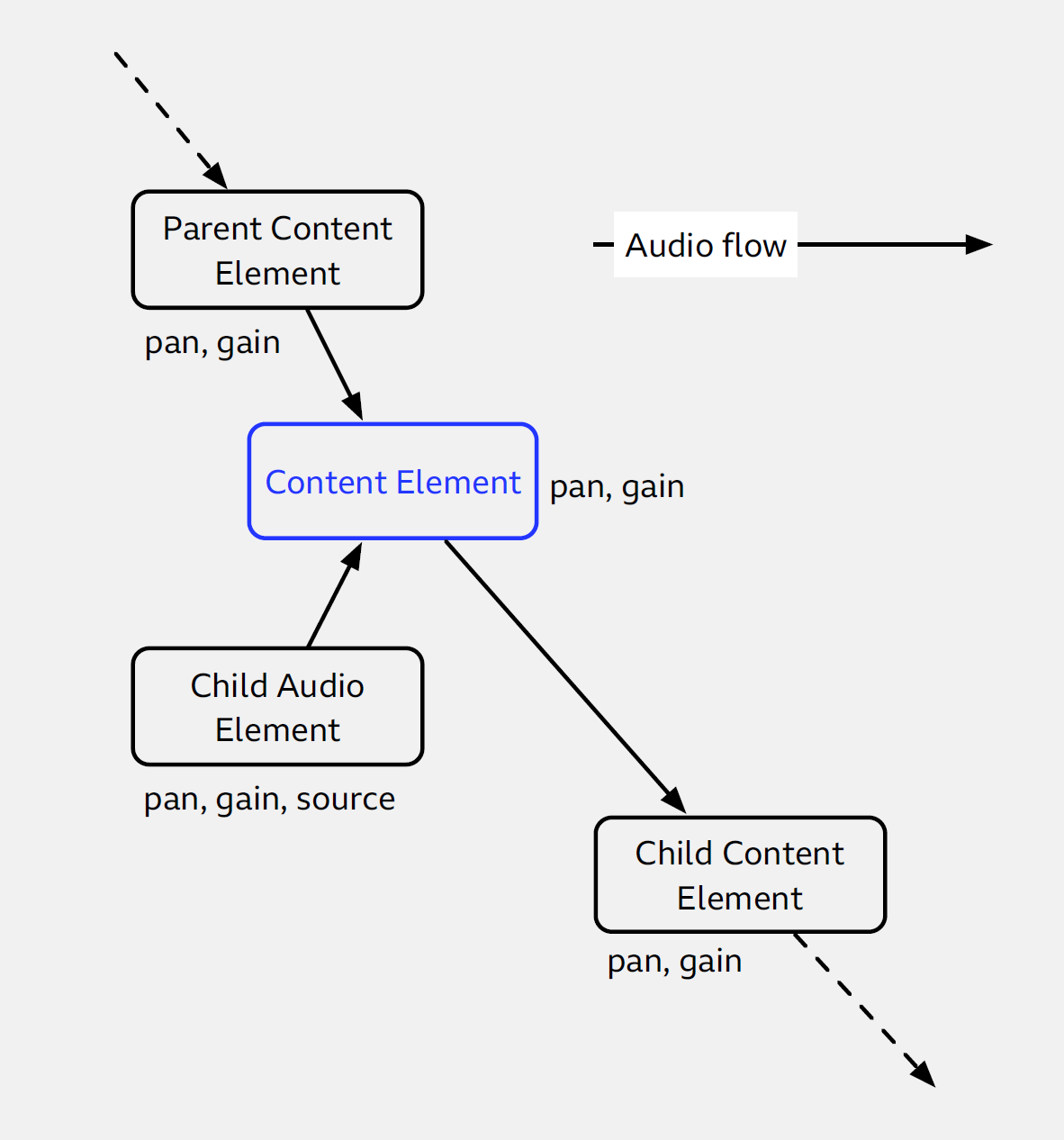
Every content element in the audio tree creates a mixer that adds the audio from its parent and its audio element children, and optionally applies a pan and gain to the output.
Every audio element provides an audio input from some audio resource, with its own pan and gain.
The output of every content element’s audio is passed to each of its children.
The audio output of all the leaf content elements is mixed together on the “master bus” in Web Audio terms.

Acknowledgements)
The editor acknowledges the current and former members of the W3C Timed Text Working Group (TTWG), the members of other W3C Working Groups,
and industry experts in other forums who have contributed directly or indirectly to the process or content of this document.
The editors wish to especially acknowledge the contributions by: