The Data Privacy Vocabulary [DPV] enables expressing machine-readable metadata about the use and processing of personal data based on legislative requirements such as the General Data Protection Regulation [GDPR]. This document acts as a ‘Primer’ for the DPV by introducing its fundamental concepts and providing examples of use-cases and applications. It is intended to be a starting point for those wishing to use the DPV and an orientation for people from all disciplines. The canonical URL for DPV is https://w3id.org/dpv# which contains its specification.
This primer document aims to ease adoption of DPV by providing:
A high-level conceptual explanation of the DPV and its modelling of concepts;
Self-contained examples that illustrate how the concepts and data models provided by DPV can represent information associated with personal data handling (for the concept, see Section); and
Guidance towards application of DPV in use-cases and technologies.
For a general overview of the Data Protection Vocabularies and Controls Community Group [DPVCG], its history, deliverables, and activities - refer to DPVCG Website.
The peer-reviewed article “Creating A Vocabulary for Data Privacy” presents a historical overview of the DPVCG, and describes the methodology and structure of the DPV along with describing its creation. An open-access version can be accessed here, here, and here.
Contributing to the DPV and its extensions The DPVCG welcomes participation regarding the DPV, including expansion or refinement of its terms, addressing open issues, and welcomes suggestions on their resolution or mitigation. For further information, please see the contribution section.
GitHub Issues are preferred for
discussion of this specification.
1. Introduction
The W3C Data Privacy Vocabularies and Controls Community Group (DPVCG) was formed in 2018 through the SPECIAL H2020 Project with the ambition of providing a machine-readable and interoperable vocabulary for representing information about the use and processing of personal data, whilst inviting perspectives and contributions from a diverse set of stakeholders across computer science, IT, law, sociology, philosophy – representing academia, industry, policy-makers, and activists. It identified the following issues through the W3C Workshop on Privacy and Linked Data:
lack of standardised vocabularies to represent concepts related to personal data, and who/how/where it is processed;
lack of descriptive taxonomies that describe how purposes of processing personal data which are not restricted to a particular domain or use-case; and
lack of machine-readable representations of concepts that can be used for technical interoperability of information.
The outcome of addressing these resulted in the creation of the Data Privacy Vocabulary (DPV) Specification, which provides a vocabulary and ontology for expressing information related to processing of personal data, entities involved and their roles, details of technologies utilised, relation to laws and legal justifications permitting its use, and other relevant concepts based on privacy and data protection. While it uses the EU’s General Data Protection Regulation (GDPR) as a guiding source for the creation and interpretation of concepts, the ambition and scope of DPV is to provide a broad globally useful vocabulary that can be extended to jurisdiction or domain specific applications.
People, organisations, laws, and use-cases have different perspectives and interpretations of concepts and requirements which cannot be modelled into a single coherent universal vocabulary. The aim of DPV is to act as a core framework of ‘common concepts’ that can be extended to represent specific laws, domains, or applications. This lets any two entities agree that a term, for example, PersonalData, refers to the same semantic concept, even though they might interpret or model it differently within their own use-cases.
2. Using DPV
The motivation of DPV is to provide a 'data model' or a 'taxonomy' of concepts that act as a vocabulary for the interoperable representation and exchange of information about personal data and its processing. For this, the DPV specification represents an abstract model of concepts and relationships that can be implemented and applied using technologies appropriate to the use-case's requirements. This specification is serialised using [SKOS] to produce a formal documentation of its contents.
2.1 DPV Serialisations
Figure 1 Serialisations of DPV specification
The DPV is serialised using [RDF] to provide a formal interoperable and machine-readable representation of information. While this enables its use as a semantic web vocabulary, the DPV can also be used without (or alongside) semantic web by either utilising a format such as [JSON-LD] that retains the semantics and provides convenience of using JSON, or through other formats such as a CSV or a flat-list of concepts. This section provides an overview of such approaches where DPV can be used both with and without semantic web.
The following are four (non-exhaustive) ways DPV can be used based on the requirements of an use-case. For guidance on how to adopt DPV concepts within an use-case, refer to Guidelines for Adoption and Use of DPV.
As a taxonomy or collection of concepts: The [DPV] specification provides a vocabulary of concepts (e.g. Purpose) and relationships (e.g. hasPurpose) without providing any restrictions on their usage (e.g. property range assertions). This specification can be used in cases where only the concepts within DPV are needed (e.g. as a list or hierarchy of purposes), either in RDF or as 'flat lists' or CSV files.
As a 'schema' or 'lightweight-ontology': The [DPV-SKOS] is a serialisation of the [DPV] specification that provides a lightweight ontology for modelling or annotating information. For this, it uses [SKOS] to represent the concepts and [RDFS] to model relationships between them. This serialisation can be used in cases where the DPV is to be used as a 'data model' or 'schema' without formal logical assertions. It is suitable in cases where simple(r) inferences are required, or where the strict interpretation or restrictions of OWL are not needed, or the rules/constraints are expressed in another language (e.g. SWRL or SHACL).
As an 'OWL2 ontology': The [DPV-OWL] is a serialisation of the [DPV] specification using [OWL] language. It should be used where the additional semantic relationships offered by OWL (based on description logic) are needed for modelling knowledge and describing desired inferences. OWL offers more powerful (and complex) features compared to RDFS regarding expression of information and its use to produce desired inferences in a coherent manner. See the Guide for using DPV in OWL2 guidance document.
Creating your own serialisation: For cases where the above are not suitable or sufficient, an adopter can create their own serialisation of the DPV by implementing the [DPV] specification in RDF (or other semantics-aware languages) or for alternate formats and environments such as CSVs, programming APIs, and frameworks. When using DPV in such a manner, it is advised to retain compatibility (and interoperability) by either using the entire IRI (e.g. https://w3id.org/dpv#Purpose) or providing documentation for how the custom implementation aligns with the [DPV] specification (e.g. stating MyPurposeConcept is the same as dpv:Purpose). Doing this ensures that the data remains compatible and interoperable with the other uses and applications of DPV.
2.2 Areas of Application
The following is an illustrative, but non-exhaustive list of applications possible with the DPV:
Document annotation - identifying and annotating concepts within documents such as privacy policies, legal compliance documentation, web pages;
Representing Policies – expressing policies for how personal data should be ‘handled’, policies for describing an use-cases’ use of personal data;
Representing Rules – creating and utilising rules for expressing requirements, constraints, or obligations regarding the necessity or optionality on the use of personal data, and for checking conformance with obligations such as for legal compliance.
DPV defines a broad notion of semantics for providing a conceptual model of concepts and relationships between them. As explained in the 2.1 DPV Serialisations section, [DPV] is the specification which is represented formally using [SKOS]. To use it as an 'ontology' or 'schema', it is recommended to serialise it into something that can model and represent the required interpretations or constraints. The following sections provides a brief overview of the modelling used in [DPV] specification and how it is converted into the ontologies [DPV-SKOS] and [DPV-OWL].
3.1 Concepts and Relationships
[DPV] is a collection of concepts. Here the term 'concept' is broadly used as consisting of a term non-exhaustively representing any of the following: idea, thought, meaning, object, event, relations, class, or category. Thus, in DPV, 'concepts' consist of terms and relationships between them. These include: Concept, has type, is instance of, and has applicable concept.
Figure 2 Concepts and Relationships
A ‘concept' in DPV is a 'term' representing information associated with that particular concept. For example, the concept Email refers to information about emails. This information may contain email addresses, aliases, signatures, and so on. While an intuitive use of Email may be taken to only refer to email address, within DPV concepts are defined with a strict scope as being representatives of all concepts that are inherently a part of it. Therefore, for emails, the concept Email is inclusive of email addresses, aliases, and so on from above. To specifically refer to 'email address', the concept Email Address should be used, which is a 'subtype' of Email.
Through this interpretation, the DPV is structured as a hierarchy of concepts where each parent or top or broader concept represents a broad set of information and its children or bottom or narrower concepts represent parts of that set.
Note: Caution against ambiguous interpretation of terms in practice
In taking this view of concepts and relationships, DPV provides a way to agree upon what a term means and is intended to represent. For example, when two different use-cases use the concept Personal Data using DPV, both refer to the same concept. Similarly, when Email is declared as a subtype of Personal Data, another entity receiving and reading this information must interpret it in the same manner. DPV is thus intended to be a foundational model for terms and relationships when representing and exchanging information.
3.2 DPV as an Ontology
Where the [DPV] specification defines concepts and relationships between them as 'terms' intended to represent them as 'concepts', the use of such concepts in actual use-cases is often accompanied with additional information and specific 'serialisation' that make it possible to use DPV in a given technological or theoretical framework.
For example, consider the relation has Personal Data, which is used to represent association with a Personal Data concept or its subtypes or its instances. While this information about what concepts the relationship is being used with/for can be implicit, it can also be explicitly declared as to: (i) express the inherent logic and interpretation explicitly; (ii) provide information for verification of its expression; and (iii) provide hints for identifying concepts to be associated with this relation. For example, specifying that the relation 'has personal data' must always be associated with 'Personal Data'. When considering such uses, DPV must be specified as an 'ontology' using a serialisation that supports representing this and any other required information.
One option to represent ontologies is RDF (RDF 1.1 Concepts and Abstract Syntax) which provides a formal method for expressing information or facts, with RDFS (RDF Schema 1.1) and OWL (OWL 2 Web Ontology Language Document Overview (Second Edition)) for representing a more detailed and logic-based assertion of the model in terms of relationships and restrictions. While there are other alternatives available to RDF for representing information, and to OWL for representing ontologies, the DPVCG uses these to serialise the DPV specification as an ontology.
The table provides an overview of the expression of concepts across the three DPV serialisations.
Most of the concepts within DPV are provided as hierarchies of classes representing categories of information, which are generic or abstract or broad so as to permit their application across a diverse and varied landscape of real-world use-cases. In order to accurately reflect the particulars of an use-case, concepts within DPV would (most likely) need to be extended. The specifics for how this should be done depend on the manner in which DPV is utilised. For example, in [DPV], the relations subTypeOf and instanceOf provide a way to indicate such applications.
If using [DPV-SKOS] semantics, extending is done using skos:broader, whereas [DPV-OWL] semantics uses the rdfs:subClassOf relationship. To create instances, both use rdf:type. Where an exact concept is not present within the DPV and a broad concept exists for representing the same information, one should subtype or extend that broad concept to define the required information.
The mechanism for extending concepts (via both subclasses/subtypes and instances) is useful to align existing concepts or vocabularies with the DPV taxonomies, such as by declaring them as subclasses of a particular concept. This permits the creation of domain or jurisdiction specific extensions, such as [DPV-GDPR] for expressing the legal bases provided by GDPR. Extensions also permit more accurate representations of a use-case by extending from multiple concepts to refine and scope the interpretation. This means each concept can have multiple parents representing the intersection of their respective sets.
Note: Clarity on combining, extending, and instantiating concepts
It is not necessary to extend concepts unless one wishes to depict use-case specific information. For example, if in a use-case it is sufficient to (only) say some information is collected, then dpv:Collect can be directly used. However, where more specific information is needed, such as also specifying a method of collection (e.g. CollectViaWebForm), then it is recommended to extend the concept, for example as <CollectViaWebForm a dpv:Collect>. If there are lots of forms and they need to be 'grouped' together as collection methods, then one would subtype/subclass Collect as CollectViaWebForm and create instances of it for each form to be represented.
Though this example used a web form as a method of collection by directly mentioning it within the concept as CollectViaWebForm, this may not always be desirable. For example, that same web form may also need to be represented separately for logging purposes. DPV is exploring the provision of a Technology concept to assist in representing information regarding how concepts are implemented and the use of specific technological artefacts such as web forms, databases, along with their functions such as data storage and retrieval.
3.4 Maintaining Interoperability
DPV intends to provide a base or foundational framework for different entities to exchange information and interpret concepts for interoperability. When an adopter (e.g. an organisation using DPV) extends concepts to refine them for their own use-case, the concept is still (weakly) interoperable by relying on DPV’s broad taxonomies to provide a common point of reference.
4. Core Concepts
4.1 Structure of DPV
Figure 3 DPV as a set of hierarchies
DPV can be viewed as a hierarchical taxonomy of concepts where each core concept represents the top-most abstract concept in a tree and each of its children provide a lesser abstract or more concrete concept. For example, consider the concept of PersonalData which is the abstract representation of personal data. It can be further refined or extended as SensitivePersonalData, and further as SpecialCategoryPersonalData and then as GeneticData and so on.
From this perspective, the top-most abstract concepts are collectively referred to as the core vocabulary within DPV. The goal of the DPV is to provide a rich collection of concepts for each of the top concepts so as to enable their application within real-world use-cases. The identification of what constitutes a core concept is based on the need to represent information about it in a modular and independent form, such as that required for legal compliance.
Each core concept is intended to be independent from other core concepts. For example, the Purpose (e.g. Optimisation) refers only to the purpose of why personal data is processed and is independent as a concept from the PersonalData (e.g. Location) or the Processing activities (e.g. collect, store) involved to carry out that purpose. Such separation is necessary in order to represent and answer questions such as:
Q: What data is being processed? Ans:dpv:PersonalData → dpv:Email
Q: Why is the data being processed? Ans:dpv:Purpose → dpv:Marketing
Q: What operations are done with the data? Ans:dpv:Processing → dpv:Collect, dpv:Store
Q: What justification is used to do the processing? Ans:dpv:LegalBasis → dpv:Consent, dpv:Contract
Q: How is the data directly or indirectly being protected? Ans:dpv:TechnicalOrganisationalMeasure → dpv:AccessControlMethod, dpv:PrivacyByDesign
Q: What rights are associated with the processing of data? Ans:dpv:Right → dpv:ActiveRight, dpv:PassiveRight
Q: What are the risks associated with processing of data? Ans:dpv:Risk → dpv:RiskLevel, dpv:Severity
Q: What is the contextual information associated with processing? Ans:dpv:Context → dpv:Duration, dpv:Scale
The separation of concepts creates a modular structure for concept hierarchies within DPV, which in turn allows an adopter to use one particular concept taxonomy or module (e.g. list of purposes) independently without reusing the others, or to select only those concepts which are needed for their particular use-case. The separation also permits greater flexibility of representation and usage - such as using different combinations of core concepts as needed in use-cases. For example, a use-case can specify a single concept representing both Purpose and Processing by combining their respective concepts from DPV. The modular design of DPV also makes it possible to define domain and jurisdiction specific concepts in a separate namespace - such as the NACE Taxonomy serialised in RDFS purpose taxonomy providing a way for Purpose to indicate sectors using NACE taxonomy, and the DPV-GDPR: Extension providing GDPR concepts for using LegalBasis to represent the legal bases provided by GDPR.
4.2 Overview of Core Concepts
Figure 4 Overview of concepts in DPV
PersonalData
Figure 5 Indicating applicable or relevant PersonalData
‘Personal data’ refers to any data about a natural person that can be used to identify them directly or, in combination with other information, indirectly. ‘Personal data’ is also commonly referred to as ‘personally identifiable information (PII)’. However the terms should not be interchangeably used as based on definitions (e.g. those in GDPR), ‘personal data’ can be interpreted as a broader term than PII, and where PII may refer to only to information that can directly identify a person. DPV’s definition of personal data is based on the broadest possible definition (i.e. from GDPR) as it covers a wider range of information considered ‘personal data’. Personal data can be declared as a category, such as ‘Email’, or an instance, such as ‘x@y.z’. PersonalData is associated with using the relation hasPersonalData.
Purpose
Figure 6 Indicating applicable or relevant Purpose
Representing the purpose for which personal data is processed, for e.g. ‘Personalisation’ as a broad category of purpose. Information about the purpose can be further specified by denoting information about its interpretation within a particular Sector, such as from standardised authoritative lists e.g. [NACE], to indicate domain-specific applications and interpretations, or to indicate applicability of sectorial laws.
Processing
Figure 7 Indicating applicable or relevant Processing
Representing processing as in the actions or operations over personal data, for e.g. collect, use, share, store. To indicate the origin or source of data, the concept DataSource along with relation hasDataSource is provided. For additional contextual information regarding operations or processing, such as whether it include humans or automation, the concept ProcessingContext is provided which can be associated using the relation hasContext (description of Context is provided later in the document). Examples of ProcessingContext include conditions such as profiling, automated decision making, human involvement.
LegalBasis
Figure 8 Indicating applicable or relevant LegalBasis
A legal basis is a law or a clause in a law that justifies or permits the processing of personal data in the specified manner. It is a jurisdictional concept given the scoping of laws to specified countries or regions, as well as a domain-specific concept given the specific laws enacted scoped to particular domains. A law, such as the GDPR, that regulates the use of personal data requires that every processing of personal data must be justified with some legal basis to ensure it is lawful, and to further assess its correctness, accountability, and impact based on the obligations applicable. However, what is considered a legal basis varies greatly across cultures, domains, use-cases, and laws themselves. The aim of DPV is therefore to provide an upper-level abstract taxonomy of categories of legal bases that can be customised and applied as needed.
Entities
Figure 9 Indicating applicable or relevant Entities
Representing the ‘entities’ or ‘actors’ involved in the processing of personal data. DPV provides a broad categorisation of entities based on their relevance in jurisprudence (i.e. legal roles) as well as categorisation in real-world (e.g. organisation types).
DataController
Figure 10 Indicating applicable or relevant DataController
Representing the organisation(s) responsible for processing the personal data.
DataSubject
Figure 11 Indicating applicable or relevant DataSubject
Representing the categories or groups (e.g. Users of a Service), or instances (e.g. Jane Doe) of individual(s) whose personal data is being processed.
Recipient
Figure 12 Indicating applicable or relevant Recipient
Represents the entities that receive personal data, e.g. when it is shared.
TechnicalOrganisationalMeasure
Figure 13 Indicating applicable or relevant TechnicalOrganisationalMeasure
DPV provides a taxonomy of technical and organisational measures for representing information about how the processing of personal data is technically and organisationally protected, safeguarded, secured, or otherwise managed. This is distinct from what technology is used for carrying out processing, and instead refers to what measures are in place (i.e. what the technology intends to provide in terms of features).
Technical and Organisational measures consist of activities, processes, or procedures used in connection with ensuring data protection, carrying out processing in a secure manner, and complying with legal obligations. Such measures are required by regulations depending on the context of processing involving personal data. For example, GDPR (Article 32) states implementing appropriate measures by taking into account the state of the art, the costs of implementation and the nature, scope, context and purposes of processing, as well as risks, rights and freedoms.
The broad concept TechnicalOrganisationalMeasure represents all technical and organisational measures, which are associated through the relation hasTechnicalOrganisationalMeasure. The concept TechnicalMeasure, associated using the relation hasTechnicalMeasure, concerns measures primarily achieved using some technology. Similarly, OrganisationalMeasure and the relation hasOrganisationalMeasure represent measures carried out through activities and processes at the management and organisational levels, which may or may not be assisted by technology.
Specific examples of measures in the article include:
the pseudo-anonymisation and encryption of personal data;
the ability to ensure the ongoing confidentiality, integrity, availability and resilience of processing systems and services;
the ability to restore the availability and access to personal data in a timely manner in the event of a physical or technical incident;
a process for regularly testing, assessing and evaluating the effectiveness of technical and organisational measures for ensuring the security of the processing.
Rights Exercise
Figure 14 Indicating applicable or relevant Right
The concept Right represents a normative concept for what is permissible or necessary in accordance with a system such as laws. To associate rights with concepts that are relevant or within which those rights occur, the relation hasRight is used. Rights can be passive, which means they are always applicable without requiring anything to be done, or active where they require some action to be taken to initiate or exercise them. To represent these concepts, DPV uses PassiveRight and ActiveRight respectively. Rights can be applicable to different contexts or entities. To differentiate rights applicable or afforded to data subjects, the concept DataSubjectRight is used. The information on exercising an active right is provided through a RightExerciseNotice which can be recorded through a RightExerciseRecord that can contain one or more RightExerciseActivity. This enables providing information about the existence of a right, how to exercise it, associate requirements for the exercising, and to keep detailed records of the interactions towards fulfilment of that right.
Representing risk(s) associated with a concept, for e.g. risk of unauthorised data disclosure related to processing, technical measure, or vulnerability of data subjects
Technology
Figure 16 Indicating applicable or relevant Technology
Representing the technologies used to implement the processing, or associated with the processing. For example, such as specific software products, algorithms, or approaches. This also involves specifying who is doing the implementing i.e. a technology and its implementer.
Temporal and Geo-Spatial Information for Storage
Figure 17 Indicating applicable or relevant temporal and geo-spatial information
Indicating information about storage of personal data, such as its location, duration, deletion (e.g. erasure mechanisms), or restoration (e.g. backup availability). Storage information can be part of the processing information (e.g. logs) or technical and organisational measure (e.g. indicating policies or plans in place) depending on context.
Location and Jurisdiction
Figure 18 Indicating applicable or relevant Jurisdiction
Representing the locations associated with entities, processing, data, and other information that is important to consider jurisdictions and from that understand the applicability of laws, involvement of authorities, and discover rights.
Rules
Rules are relevant to explicitly denote how a system should implement operations, and enable associating specifics such as requirements, constraints, and other forms of 'rules' that are needed in order to control executions or affect interpretations or achieve compliance (e.g. with law). DPV defines the concept Rule and relation hasRule to enable represenation of such conditions and requirements, and provides a minimal set of concepts for types of rules, namely - representing Permissions, Prohibitions, and Obligations. DPV does not define additional semantics for rules and limits its scope and focus to provide a simple way to specify common rules associated with personal data and its processing activities, with the recommendation to consider other richer and mature efforts dedicated to expression of conditions and rules, such as: [ODRL], [SHACL], and [RuleML].
4.3 Personal Data Handling
In legal terminology, it is common to refer to all information about how personal data is being processed using the colloquial term processing. This results in confusion between the use of processing as a concept referring to all information (i.e. purposes, personal data, collection, storage, etc.), and processing as a concept referring to (only) the specific actions or operations (e.g. collect, use).
To avoid this ambiguity and enable clarity of information, DPV defines a new concept called PersonalDataHandling for representing how the core concepts are related or apply to each other for a particular use-case. The association of a concept to PersonalDataHandling is made using the relationships or properties provided for each concept. For example, to indicate a PersonalDataHandling includes personal data, the relationship hasPersonalData is used along with the concept PersonalData. The following figure provides an overview of how the PersonalDataHandling concept provides a way to associate relevant concepts with one another through it.
Figure 19 PersonalDataHandling as a central concept
Note
Note that PersonalDataHandling is intended to provide a convenient concept for tying the core concepts together, and DPV does not make its use binding, nor does it constrain the relationships to only be defined between PersonalDataHandling and the other core concepts. This is so as to permit using DPV in alternate or differing models. For example, where a central concept already exists, such as when describing relevant information for a smartphone app, the concept for App can be a replacement for PersonalDataHandling based on statements such as <App> hasPurpose <SomePurpose>. Even in such cases, PersonalDataHandling can provide granular expression thereby enabling description of different contexts within which the app uses personal data, such as for registration or complaint resolution.
Nesting PersonalDataHandling to express granular models
The use of PersonalDataHandling can be nested, which means one instance can contain other instances, much like a box with several smaller boxes inside. This permits breaking down complex or dense use-cases into more granular ones and representing them in a more precise and granular fashion. In the above example, consider the following situation containing a single PersonalDataHandling instance consisting of two additional instances representing: (i) data is stored using a data processor, (ii) data is used for Marketing. While it is certainly possible to represent all of this information within one single instance of PersonalDataHandling, the adopter may decide to create separate instances of PersonalDataHandling based on requirements such as reflecting similar separations for legal documentation or accountability purposes.
Alternate Models to PersonalDataHandling
An instance where one may not wish to utilise PersonalDataHandling is where the adopter or use-case wants to indicate a different method for relating concepts together. For example, instead of expressing the relationship between personal data and purpose through a PersonalDataHandling instance, an alternate model could be one where the purpose directly specifies what personal data it uses as: <SomePurpose hasPersonalData SomePersonalData>. Similarly, another instance for such alternate use of concepts is to associate a legal basis directly with the purpose by using the hasLegalBasis relationship. To support such uses, DPV does not explicitly declare restrictions on the properties in terms of what concepts they can be used with (e.g it does not provide domain assertions). In case an adopter needs such explicit declarations, they can utilise or import the separate file declaring them.
The following figure indicates an alternate model which does not use PersonalDataHandling as a central concept, but instead uses the core concepts and relationships to structure information related to a Service.
Figure 20 Alternate model to PersonalDataHandling using core concepts and relationships
Note: Consequences of using a different model than PersonalDataHandling
When using custom-defined restrictions and data models, it is important to note the consequences such models have on interpretation and interoperability of data defined using DPV. For example, consider a compliance assessment tool that takes DPV data as input. If the tool expects a PersonalDataHandling with links to relevant information, using other alternate models and relationships can produce invalid or incorrect results. To avoid this, we recommend:
Documenting alternate models to clearly indicate their interpretation and use of DPV semantics;
Where possible, ensuring and providing mappings between the alternate models and the PersonalDataHandling or equivalent concepts within DPV so that the data can be transformed for interoperability;
Consider contributing your idea or implementation of an alternate model to DPVCG to create a ‘library of models’, which can act as documentation for adopters and provide better understanding of the model's impacts on requirements and interpretation of information specified using DPV. This exercise can also assist in selecting a common model as the 'default' and to provide mechanisms for conversion/interoperability between it and other models.
5. Taxonomies of Key Concepts
The following sections provide an overview of the taxonomies (i.e. hierarchies of concepts) provided by DPV for its core concepts.
5.1 Purpose
Figure 21 Overview of top-level concepts in Purpose taxonomy
DPV’s taxonomy of purposes is used to represent the reason or justification for processing of personal data. For this, purposes are organised within DPV based on how they relate to the processing of personal data in terms of several factors, such as: management functions related to information (e.g. records, account, finance), fulfilment of objectives (e.g. delivery of goods), providing goods and services (e.g. service provision), intended benefits (e.g. optimisations for service provider or consumer), and legal compliance.
Note: Purposes do not have a strict structure as used in real-world use-cases
It is important to note the following for real-world implications of Purpose:
There is no universal definition for what constitutes a ’purpose’ or what attributes are associated with it.
There are several distinct ways to model purposes, e.g. as a ‘goal’ such as ‘Delivery of Ordered Goods’; or as a statement explaining the processing of personal data, e.g. ‘Sending newsletters to Email’.
DPV does not define requirements for what is a ‘valid purpose’ as these are defined externally, e.g. in laws such as [GDPR] Article.5-1b where purposes are required to be ‘explicit and legitimate’.
Purposes have contextual interpretations within their application and domains i.e. depending on how they are used in an use-case). For example, ServiceProvision is interpreted distinctly across the use-cases of an online website, a goods delivery outlet, and a medical centre - even if they use the same term or wording.
Following from the above, most use-cases would need to extend one of the concepts within DPV’s purpose taxonomy to ensure its purpose descriptions are specific and understandable within the context of that use-case. We therefore suggest, where possible and appropriate, to create a customised purpose as required within the use-cases by extending or subtyping one or several purposes from the DPV taxonomy and to provide a human readable description to assist in its accurate interpretation (e.g. for RDF, using rdfs:label and rdfs:comment).
5.1.1 Sector of Purpose Application
DPV provides Sector that can be used to indicate the relevant information to further clarify or indicate how a purpose should be interpreted. Sector, used with the hasSector relation, denotes the sector or domain of application, such as Manufacturing. This can be used alongside existing official sector taxonomies such as [NACE] (EU), [NAICS] (USA), or [ISIC] (UN), as well as commercial industry taxonomies such as [GICS] maintained by organisations MSCI and S&P. Multiple classifications can be used through mappings between sector codes such as the NACE to NAICS mapping provided by EU.
Note: DPVCG provides a DPV-compatible NACE extension
DPVCG provides an interpretation of the NACE revision 2 codes which uses rdfs:subClassOf to specify the hierarchy between sector concepts. It is available as [DPV-NACE]. The NACE codes within this extension have the namespace dpv-nace and are represented as dpv-nace:NACE-CODE.
We are working on further alignments between the NACE codes and DPV's purpose taxonomy, and welcome contributions for the same.
While the use of Sector for restricting (personal data processing) purposes is an uncommon and undocumented practice in terms of legal enforcement, we provide this feature as the use of sector code can assist with identification and interpretation of information as well as legal or organisational obligations and policies. For example, indicating some purpose is to be implemented within manufacturing or scientific research facilities (e.g. medical centres) can assist in ensuring specific types of access control and policies are defined and implemented.
5.2 Processing Operations
Figure 22 Overview of top-concepts in Processing taxonomy
DPV’s taxonomy of processing concepts reflects the variety of terms used to denote processing activities or operations involving personal data, such as those from [GDPR] Article.4-2 definition of processing. Real-world use of terms associated with processing rarely uses this same wording or terms, except in cases of specific domains and in legal documentation. On the other hand, common terms associated with processing are generally restricted to: collect, use, store, share, and delete.
DPV provides a taxonomy that aligns both the legal terminologies such as those defined by GDPR with those commonly used. For this, concepts are organised based on whether they subsume other concepts, e.g. Use is a broad concept indicating data is used, which DPV extends to define specific processing concepts for Analyse, Consult, Profiling, and Retrieving. Through this mechanism, whenever an use-case indicates it consults some data, it can be inferred that it also uses that data.
Note: Need for ensuring accuracy of processing terms in an use-case
The definitions for describing and interpreting each processing concept is based on the following sources: language dictionaries (predominantly Oxford English), use of the term within legal documents (e.g. GDPR case law), and technology-specific interpretations such as for IT systems. Despite these, there may be distinct interpretations for what a term represents based on differences in practices, culture, language, and domains. In case an adopter or a use-case foresees such ambiguity or confusion, it is advisable to extend the relevant concepts and define them as needed, or create a separate extension.
5.2.1 Data Storage
Figure 23 Indicating Storage and Data Source for Processing
The processing taxonomy uses the concept Store to indicate data is being stored. To specify additional information such as its location, erasure or deletion, the generic concepts and relations associated with processing (i.e. location and duration) can be used. However, to emphasise that information about storage - such as policies, conditions, rules, or documentation - are critical on considerations of data protection and privacy as well as legal compliance, DPV provides specific concepts related to these.
The concept StorageCondition and the relation hasStorageCondition represent the general or abstract conditions associated with storage of data. This is specialised to indicate StorageDuration, StorageDeletion, StorageRestoration, and StorageLocation. This enables a document to directly specify information such as: "storage duration is 6 months" or "storage restoration uses 3 geo-distinct backup servers".
5.2.2 Data Source
For declaring the source of data, the DataSource concept along with hasDataSource relationship is provided to indicate where the data is collected or acquired from. For example, data can be obtained from the data subject directly (e.g. given via forms) or indirectly (e.g observed from activity, or inferred from existing data), or from another entity such as a third party.
Note: Source vs Origin
It is important to understand the distinction between a data source and data origin. The source of data refers to the direct or indirect place, entity, or other concept from which the data was collected (in any manner). The origin of data refers to the specific entity or artefact which produced or created the data. For example, consider a company that collects data from a public database that is populated by government bodies who themselves collect that data from people. In this case, the origin of that data is ultimately the people, but the sources of this information are the people, the government bodies, and the public database.
Using such two synonymous terms (source and origin) can lead to ambiguity and confusion. Therefore, we suggest using data source to indicate information as contextually required within a use-case. In most cases, this would be the direct source of data (i.e. public database in above example). In other cases, it would be relevant to indicating whether data originated from the data subject.
Data can be sourced from a public or a non-public source. The distinction is important given that a public source has different implications (and justifications) for the availability of that data as well as how it can be used. To represent these, DPV uses sub-types of data source as PublicDataSource and NonPublicDataSource. Public data sources can be datasets published by authoritative bodies, or census reports, or (public) websites. Non-public data sources are anything that is not publicly available - so data subjects, third parties, etc.
5.2.3 Automation in Processing
Automation is a broad concept that refers to automated or reduced human involvement in a process. Most (if not all) processing operations can be considered to be automated given that they are operated by machines and utilise digital information and mediums. However, even within this, specific forms and descriptions of automation are more important than others. For example, if the processing operations are intended to produce an output that will result in prosecution - then information about the automation utilised in this process is needed to understand if the decisions are fair, correct, unbiased, or to understand whether there has been some human oversight or involvement at various stages.
Note: Automation and Artificial Intelligence
DPV's concepts intentionally refer to "automation" rather than "artificial intelligence", where the former is considered a broader and more inclusive term than the latter. It also avoids delving into investigations of what is and how to define "AI". Given that AI is a form of automation, whether directly or indirectly applied, these terms within the DPV are also intended to supplement use-cases where AI is used, and to represent information regarding the degree of automation and involvement of humans within its processes.
DPV provides AutomationOfProcessing to represent the degree of automation, and the relation hasProcessingAutomation to associate it with contextual concepts. The degrees of automation are represented by FullyAutomatedProcessing, PartiallyAutomatedProcessing, and CompletelyManualProcessing.
To represent how humans are involved, the concept HumanInvolvement and relation hasHumanInvolvement are provided. Specific types of human involvement include: HumanInput, HumanOversight, and HumanVerification.
To indicate more specific applications: DecisionMaking and AutomatedDecisionMaking refer to use of processing to make decisions, AlgorithmicLogic for explaining the use of algorithms and specifics of processing logic, EvaluationScoring to indicate the processing evaluates or assigns scores (or metrics), InnovativeUseOfNewTechnologies to indicate there are innovative uses of novel technologies, and SystematicMonitoring to indicate the processing performs a systematic (or systemic) monitoring. These additional concepts are intended to model areas or topics that are considered sensitive or high-risk or require caution.
5.3 Personal Data
Figure 24 Personal Data concepts within DPV and their extension in dpv-pd
DPV provides the concept PersonalData and the relation hasPersonalData to indicate what categories or instances of personal data are being processed. As described earlier, common use of personal data concepts in the real-world consists of specifying as concepts both categories (e.g. Location) and instances (e.g. your exact location right now).
The DPV main or core specification only provides a structure for describing personal data, e.g. as being sensitive. For specific categories of personal data for use-cases, DPV-PD: Extension providing Personal Data Categories provides additional concepts that extend the DPV's personal data taxonomy. This separation is to enable adopters to decide whether the extension's concepts are useful to them, or to use other external vocabularies, or define their own.
Note: Clarity on Personal Data concepts being Categories and Instances
Real-world and common usage of personal data is at both an abstract level as well as specific level. For example, consider the sentence "We use your Email information...", which uses "Email" to represent a reference to what personal data is involved. Here, one may interpret Email as representing only the email address, or as a broad set of possible information related to emails, such as email address, email senders and recipients list, email service provider, email usage statistics and so on.
For ensuring clarity and resolving any potential ambiguity, DPV recommends being as specific as possible. This means where there is ambiguity as to what the information may be associated with or within a concept, it is advisable to resolve that ambiguity - either by choosing a more accurate concept from the taxonomy and/or by creating one through extension of an existing concept.
Note: Challenges in representing Personal Data concepts accurately
In addition to above, it is also challenging to accurately represent how concepts function within real-world use in terms of their encapsulation within one another. For example, when establishing the DPV, we discussed the modelling of personal data categories based on the scenario where a picture of passport is initially collected, and from it various categories are extracted, such as - name, address, and photo. For representing this, merely stating the personal data as ‘passport photograph’ would not be entirely accurate as there is additional information within the photograph.
A solution was established whereby the use-case is expected to declare what information it intends to collect or use through the mechanism of expression relation between its personal data categories. For the passport photograph scenario, the use-case would declare the class PassportPhoto with subtypes representing Name, Age, and so on. This is necessary to ensure the interpretation that using PassportPhoto means having access to and using all of its subsequent personal data categories.
While this is one possible solution, other methods exist, such as explicitly declaring the data categories and their encapsulation within one another, such as by reusing hasPersonalData or creating additional properties (e.g. containsData) to indicate a personal data concept, i.e. the passport photo, contains information associated through the relation, i.e. name, age, etc. We welcome discussions regarding both these methods.
Note: PII and Sensitivity of Data
PII (Personally Identifiable Information) and Sensitivity of data are common concepts in relation to use of personal data. PII is a term with variable definitions depending on the particular interpretation of personal and identifiable. While ISO standards define PII as a concept closer to the personal data definition within DPV, we are investigating the relation between the two. Possibilities include providing PII as an alternative label to personal data, or defining the two concepts as equivalent, or having PII as a subclass of Personal Data that refers only to identifiable information.
DPV provides the SensitivePersonalData concept, and we are investigating how to specify sensitivity of information, for example as a subjective scale from high to low. One approach is to reuse the Severity scale provided for risk assessment and express sensitivity as a form of severity associated with data. Alternative is to create a separate concept for Sensitivity.
5.3.1 Non-Personal and Synthetic Data
While the focus of DPV is on Personal Data, there may be a need to represent Non-Personal Data within the same contextual use-cases. For example, if the personal data has been fully, completely, and irreversibly anonymised, then it can no longer be said to be personal data. To enable this, and other representations, DPV provides the concept Data to represent any data, with subtypes PersonalData and NonPersonalData. Using these as annotations can assist in clearly indicating which data should be protected, or protected with more severe measures, or to determine the scope of regulations which only apply over operations involving personal data.
Data is further subtyped as SyntheticData - a new concept that represents generated data intended to mimic personal data within a system so as to aid in development and testing without using actual or real personal data. Since such synthetic data may be used in systems that assume it is personal data, it has not been declared as a specific category of personal or non-personal data to permit its use as either.
5.3.2 Categorisation based on Source
The concept DataSource refers to information associated with processing contexts for indicating how the data is sourced or obtained. In some cases, it may be desirable to directly express this information over the data itself, such as indicating a dataset is "collected personal data", or that a storage policy only applies over "inferred data". To enable such uses, DPV provides the following subtypes of personal data: CollectedPersonalData, DerivedPersonalData, InferredPersonalData, GeneratedPersonalData, and ObservedPersonalData. Here the terms derive and infer relate to creation of additional data based on existing data, whereas generate refers to creation of new data that is not derived or inferred.
5.3.3 Sensitive and Special Categories
For indicating personal data which is sensitive, the concept SensitivePersonalData is provided. For indicating special categories of data, the concept SpecialCategoryPersonalData is provided. In this, the concept sensitive indicates that the data needs additional considerations (and perhaps caution) when processing, such as by increasing its security, reducing usage, or performing impact assessments. Special categories, by contrast, are a 'special' type of sensitive personal data requiring additional considerations or obligations defined in laws (or through other forms) that regulate how they should be used or prohibit their use until specific obligations are met.
Note
DPV currently categorises personal data as sensitive based on existing research and literature, and as special categories based on [GDPR] Article 9. Both are subject to expansion in the future based on requirements and technological progress, and we welcome well-formed proposals for the same.
The sensitivity of personal data can be universal, where that data is always sensitive, or contextual, which means a use-case needs to declare it as such. For indicating personal data is sensitive (or special), it is sub-typed or declared as an instance of SensitivePersonalData, as shown in the example below.
In using these concepts, it is important to note that DPV's modelling of sensitive and special categories is non-exhaustive and as such should not be taken as an authoritative fact or a 'source of truth'. To assist with better identifying sensitive concepts, work is ongoing within DPV to identify and provide a reference list of (potentially) sensitive and special categories, and we welcome contributions for the same.
5.3.4 Anonymised Data
To specify data is anonymised, DPV provides two concepts. AnonymisedData for when data is completely anonymised and cannot be de-anonymised, which is a subtype of NonPersonalData. And, PseudonymisedData for when data has only been partially anonymised or de-anonymisation is possible, which is a subtype of PersonalData.
It is important to note that these definitions can be contextually difficult to apply or interpret. For example, consider the case where some data is indicated as being anonymised by itself without any available information to de-anonymise it. Though this can be considered as anonymised data, if there were to exist an external method or dataset that when combined with the anonymised dataset provides de-anonymised information - then this does not fit the definition of anonymised data.
Therefore, when indicating AnonymisedData, the understanding is that it is completely anonymised. Otherwise, given that regulations targeting PersonalData do not apply over anonymised data, the labelling of pseudo-anonymised or contextually anonymised data may lead to misleading representation and violating obligations.
We are exploring the provision of the concept ContextuallyAnonymisedData as a subtype of PseudonymisedData to indicate situations where data is locally or contextually considered anonymised without any guarantees of its anonymity outside of that context.
5.4 Technical and Organisational Measures
Figure 25 Overview of Technical and Organisational Measure concepts in DPV
DPV's taxonomy of tech/org measures are structured into two groups representing TechnicalMeasure and OrganisationalMeasure along with specific properties for each. Each term has a dedicated taxonomy that expands upon the core idea to provide a rich list of technical and organisational measures that are intended to protect personal data (and its associated entities and consequences).
Note
DPV is looking to enrich its taxonomy of technical and organisational measures through adoption of existing standards, best practices, and widely relevant practices. For this, we welcome contributions of concepts from sources such as ISO/IEC standards, ENISA, NIST, IETF, and others.
5.4.1 Technical Measures
Figure 26 Overview of Technical Measures in DPV (click to open in new window)
Technical Measures are implemented through technological means, such as machine-processing or automation or tools and services that are primarily technological in nature. To distinguish these with organisational measures, consider whether the measure is for human organisation and management (which makes it organisational) or an implementation detail (which makes it technical).
Examples of technical measures include use of specific access control methods, encryption, anonymisation, security protocols, and other similar concepts.
5.4.2 Organisational Measures
Figure 27 Overview of Technical Measures in DPV (click to open in new window)
Organisational measures are a corresponding counterpart to technical measures, and are intended to be implemented or realised through human action, whether directly by an individual, teams, or through an organisation's management (hence the term organisational). Implementing such measures may include use of technology or a tool, for example - a security training exercise that is carried out using some software, or to use information systems such as dashboards to keep track of information. However, the concepts themselves are structured as organisational based on who or what has to decide or implement the action. If it is to be performed through a technological means, then it is a technical measure. If it is to be performed through human or organisation management, then it is an organisational measure.
Examples of organisational measures include staff training, policies, notices, and other such concepts - which indicate that reflect organisational decisions and actions (e.g. privacy notices, policy for how to train new recruits).
5.4.3 Policies
A Policy is an organisational measure (given that it is decided and enabled by humans) that can be used to describe procedures or encode actions. It may be implemented manually (e.g. by employees) or technologically (e.g. by software or agents). Policies are an important aspect of personal data processing, and can be associated with a wide variety of concepts - such as processing operations, purposes, specific data categories, or legal bases. To enable such uses, DPV provides the relation hasPolicy and isPolicyFor to link or associate policies with their respective subjects or topics.
Note: Privacy Policy vs Privacy Notice
DPV does not provide the concept PrivacyPolicy, but instead suggests to use the better expressed and less ambiguous term - PrivacyNotice. This is to explicitly denote that the role of what is considered common as a "privacy policy" is actually a "notice" intended for end users and other individuals, instead of being an internal policy document for how the company should approach 'privacy'. More information about notices is provided in the next section.
Common policies provided by DPV include: InformationSecurityPolicy for how information is secured or safeguarded, and RiskManagementPolicy for how risks should be managed. In the future, we expect there to be more concepts added for dedicated policies as regulations and the general culture of privacy and data protection progresses.
5.4.4 Notices
A Notice is an artefact intended to provide information, most commonly to individuals who are viewing, visiting, or otherwise using a service. Legally, a 'notice' is provision of information with the intention of imparting knowledge. DPV represents notices through the concept Notice as a form of Organisational Measure, with the relation hasNotice enabling use or association of notice within some context.
Notices may contain only information, or also have interactive components intended to make decisions, offer choices and controls, or otherwise carry out processes that go beyond mere provision of information. Currently, PrivacyNotice and ConsentNotice are provided as specific forms of notices.
5.4.5 Records
Records, or storing of information with the intention to use it in the future, are an important obligation for several legal as well as other obligations related to data protection and privacy. To represent these, DPV provides the RecordsOfActivities concept for records in general, and DataProcessingRecords for records that relate to the processing of personal data. The concept RegisterOfProcessingActivities, based on [GDPR] Art.30, refers to a register or index of data processing activities, and is a specific type of data processing records. Where consent is used as the legal basis, the concept ConsentRecord relates to records related to such consent and its collection / use for processing of personal data.
Note: Records as documentation vs as operations
DPV also contains the Record concept as a type of Processing operation, and RecordManagement as a type of Purpose. The former refers to recording of personal data as a means to obtain it (e.g. record a conversation), while the latter relates to the use of personal data towards creating records and managing them as a purpose (e.g. record consent was given). These are distinct, though relevant to the organisational measures related to record keeping.
Record keeping may require further vocabularies to represent details such as various temporal annotations, provenance, statuses, or other contextual information that is not possible or provided for by DPV's concepts. In such cases, we suggest utilising other standardised vocabularies where applicable.
5.4.6 Security
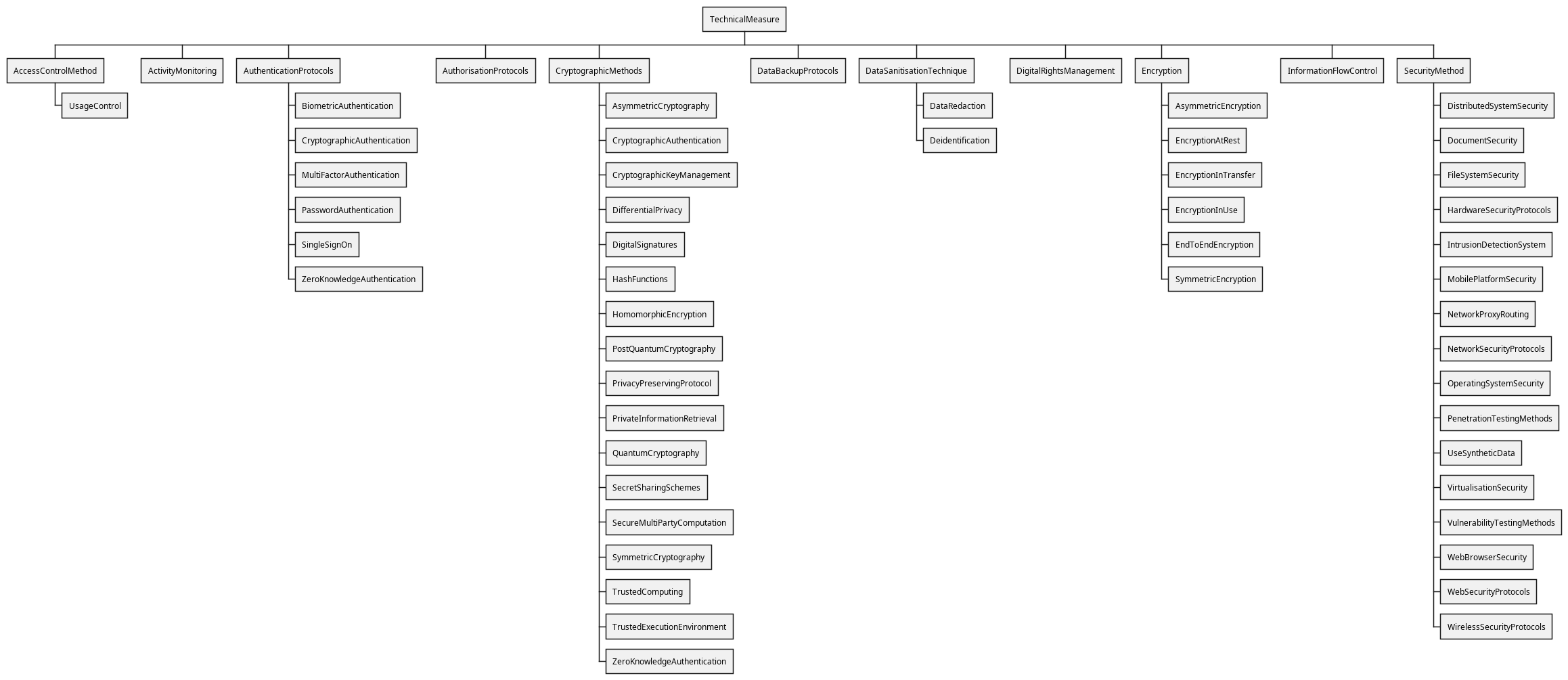
All technical and organisational measures are intended, by definition, to provide better security and handling of personal data and its associated processing and other activities. In DPV's taxonomy, some measures directly and specifically relate to security as their topic, whilst others provide their intended benefit indirectly. For example, the concept SecurityAssessments is an organisational measure relating to how security is assessed (and thus ultimately improved) - and is directly associated with security as a topic. Whereas a concept such as ProfessionalTraining relates to measures that are not directly tied to security, but can be associated in cases where the training is related to security or specific security measures or risks (e.g. cybersecurity data breach mitigations). The purpose EnforceSecurity provides a common umbrella term for personal data that is utilised for enacting and enforcing security measures, such as for authorisation and authentication.
Technical measures that relate specifically to security include SecurityMethod for providing security, and its subtypes for DocumentSecurity, FileSystemSecurity, HardwareSecurityProtocols, IntrusionDetectionSystem, MobilePlatformSecurity, NetworkSecurityProtocols, OperatingSystemSecurity, WebBrowserSecurity, WebSecurityProtocols, and more. Organisational measures that relate specifically to security include SecurityProcedure, and its subtypes for BackgroundChecks, CybersecurityAssessments, CybersecurityTraining, SecurityAssessments, and more.
5.4.7 Data Processing Agreements
The term Data Processing Agreement refers to a broad concept related to contracts or agreements between entities representing conditions regarding the processing of (personal-)data. This can include ad-hoc 'data handling' policies such as NDAs, embargoes, and enforcement of practices, as well as more formal and legal binding contractual obligations such as those between a Controller and a Processor.
To represent such concepts, DPV provides LegalAgreement, along with subtypes for NDA (Non-disclosure agreements), ContractualTerms, and DataProcessingAgreement. In these, it is important to remember that while contract can also be as a form of legal basis, the concept represented here is not necessarily the same contract as that is used to justify the processing of personal data with a data subject. Instead, contracts are a broad category representing contractual terms governing data handling within or with an entity.
For representing specific agreements between entities (other than those with data subjects - which are covered in Legal Basis taxonomy), DPV provides the following types of agreements:
ControllerProcessorAgreement: An agreement between a Controller and a Processor, where the Controller instructs the Processor(s) to carry out processing on its behalf.
JointControllersAgreement: An agreement between two or more Controllers to act as a 'Joint Controller'.
SubProcessorAgreement: An agreement between two or more Processors where one Processor instructs another to carry out processing on its behalf.
ThirdPartyAgreement: An agreement between a Data Controller or a Data Processor, and a Third Party. Note that this is a loosely defined concept, as depending on the jurisdiction, this relationship may result in the Third Party being a Data Controller or a Joint Data Controller.
To indicate the entities involved in an agreement, the relation hasEntity can be used, or relations associated with specific roles to indicate contextuality. For example, using hasDataController with a ControllerProcessorAgreement denotes the Data Controller for that agreement.
5.4.8 Data Transfer Safeguards
While all technical and organisational measures are intended to safeguard personal data and its associated activities, there may be contextual or use-case requirements to explicitly indicate safeguards against or for specific criteria. To enable such use, DPV provides the concept Safeguard and its subtype SafeguardForDataTransfer for indicating application when data is being transferred. Through these, it is possible to represent aspects such as policies for data transfers, specific measures such as encryption being applied, and other pertinent information in combination with DPV's concepts from technical and organisational measures.
Note: GDPR's Data Transfer Tools
[GDPR] and its various guidelines utilise the term "data transfer tools" to refer to specific measures that aid in safeguarding data transfers. Given this jurisdiction-specific nomenclature and its applicability being restricted to GDPR, DPVCG provides the concept DataTransferTool and its implementations (such as the SCCs above) within the [DPV-GDPR] extension.
5.4.9 Impact Assessments
Figure 28 Types of Impact Assessments in DPV
DPV provides the concept Assessment to represent various assessments and related procedures and processes that an organisation or entity may undertake. An important subtype of such assessments is the ImpactAssessment which refers to calculating or determining the likelihood of impact of an existing or proposed process and its involved risks or detriments. This could be inward facing - such as impact to the organisation, or outward facing - regarding impact to stakeholders such as individuals.
To represent privacy related impact assessments, the concept PIA (Privacy Impact Assessment) is provided. Similarly, the concept DPIA is provided for Data Protection Impact Assessment. Without getting into specifics of jurisdictional nomenclature (more specifically GDPR), DPVCG considers PIA and DPIA to be distinct terms based on their topic of focus. The PIA process is based on privacy as its focal point whereas the DPIA process considers the processing of personal data. Both refer to impacts (e.g. individuals affected), and may contain overlapping processes and outcomes. DPVCG suggests using the concept most suitable or applicable for a given use-case, or which matches the terminology of an obligation. For example, the concept DPIA would be more suitable for systems based on GDPR's requirements. It is also possible to utilise both terms to refer to the same process, for example to specify that an assessment satisfies both PIA and DPIA criteria (as suggested by CNIL - the French DPA).
Other assessments represented within DPV include: DataTransferImpactAssessment for impacts arising from data transfers, LegitimateInterestAssessment for determining the suitability of legitimate interest as a lawful basis, and SecurityAssessments to identify gaps, vulnerabilities, risks, and effectiveness of controls.
DPV provides the following categories of legal bases based on [GDPR] Article 6: consent of the data subject, contract, compliance with legal obligation, protecting vital interests of individuals, legitimate interests, public interest, and official authorities. Though derived from GDPR, these concepts can be applied for other jurisdictions and general use-cases. The legal bases are represented by the concept LegalBasis and associated using the relation hasLegalBasis.
When declaring a legal basis, it is important to denote under what law or jurisdiction that legal basis applies. For instance, using Consent as a legal basis has different obligations and requirements in EU (i.e. [GDPR]) as compared to other jurisdictions. Therefore, unless the information is to be implicitly interpreted through some specific legal lens or jurisdictional law, DPV recommends indicating the specific law or legal clause associated with the legal basis so as to scope its interpretation. This can be done using the relation hasJurisdiction or hasLaw.
For GDPR, DPVCG provides the DPV-GDPR: Extension providing GDPR concepts which defines the legal bases within [GDPR] by extending them from relevant concepts within the DPV. We welcome similar contributions for extending the GDPR extension as well as creating extensions for other laws and domains.
Note
When using legal bases, we advise careful consideration whether the information to be represented is regarding a specific instance (e.g. consent of an individual) or a general category (e.g. contract of service consumer/users), and to utilise DPV concepts accordingly.
Consent is an important legal basis given its emphasis on individual empowerment and control, as well as the attention and relevance it receives from being part of direct interactions with individuals. DPV provides concepts for representing information about how consent, as a legal basis, is utilised (by the Controller), provided or given (by the Data Subject), how long it is considered to be valid (its duration), and how it can be withdrawn. It also provides concepts related to management of information, such as keeping track of whether the consent has been requested, was refused, or has been given. This information can be utilised in applications associated with consent, such as creating a ‘record’ of consent or building and executing rules for compliance.
Given the reliance of consent as a legal basis whose validity is associated with requirements and obligations based on jurisdictional laws, DPV does not explicitly provide constraints on what should be considered a ‘valid’ consent. Instead, it focuses on providing declaration of information about consent so as to aid in the determination of its validity, and to record its use and changes over time. Further information concerning compliance obligations and requirements related to consent are considered within the scope of the DPVCG, and we welcome contributions on how this can be represented in a coherent manner that is compatible with the rest of DPV.
The concept Consent can be used as is or with another concept as its legal basis e.g. PersonalDataHandling and hasLegalBasis. Similarly, the relevant information, such as purposes or personal data for which consent is expressed can be associated with consent or the concept it is used within using relations such as hasPurpose and Purpose. The example on consent records demonstrates how DPV can be used to create a record of consent. The below example demonstrates how the consent concepts can be utilised to describe where consent is used as a legal basis, as well as to represent information about an individual's consent.
5.5.1.1 Consent Notice
Requirements for informed consent require provision of information before the consent is obtained so as to inform the individual. This information is typically provided through a notice, which can be specified using the concept ConsentNotice and the relation hasNotice. As with the previous notice example, a consent notice can be a link to the actual notice document or web-page, or contain description of the notice contents regarding processing of personal data.
5.5.1.2 Consent Types
By default, consent is expected to adhere to several requirements such as being informed, freely given, and so on - typically defined within law or other relevant guidelines, that determine how it is requested, expressed, and evaluated for validity. In DPV, these are referred to as types of consent.
DPV provides InformedConsent and UninformedConsent as two distinct concepts related to whether the consent is informed or not. For more types of informed consent, the concept ImpliedConsent specifies when consent is indirectly expressed or is assumed, and ExpressedConsent for when the individual specifically takes an action to (only) express their consent. The difference between the two can be better understood as follows: if the individual performs an action, and that action only relates to consent, then it is said to be expressed consent, whereas if that action also relates to other matters in addition to being about consent, then the interaction is said to be implied (form of) consent. Clicking a button on a consent notice is a direct action and is thus a form of expressed consent. Assuming consent based on continued scrolling of a web page is an indirect or assumed action, and is thus implied consent.
Note: Implied Consent in DPV is not the same as Medical Implied Consent
In medical terminology, "implied consent" is an assumption that the person's consent is present so as to avoid the restrictions of collecting consent prior to any (emergency)treatment. This is not the case with privacy and data protection perspectives, where 'implied consent', no matter how well intentioned the purpose may be, should not be considered 'assumed' without any specific action.
Therefore, we welcome well reasoned arguments and concrete proposals to express other types of consent, including justifications for where concepts such as AssumedConsent may be useful and have a basis in a law or other authoritative source.
When the expressed action for consent only (and only) refers to matters related to consent, then such consent is represented by ExplicitlyExpressedConsent. For example, if a button for expressing consent relates to conveying decisions about consent, but also other things such as to navigate to the next page, then this is a clear and specific action for expressing consent. However, if such a button only relates to indicating consent, then it is explicitly about consent, and is thus an instance of Explicitly Expressed Consent.
Note: Explicit consent in DPV, ISO, and GDPR
The term explicit consent is present in both ISO as well as GDPR and other laws. However, definitions differ significantly and are incompatible with each other. For example, what ISO considers 'explicit' would be 'expressed' (or regular) under GDPR. The approach taken by DPV is intentional towards enabling such variations to be expressed in specific extensions by building on top of the core vocabulary concepts. For example, the [DPV-GDPR] extension defines A6-1-a-explicit-consent and A9-2-a as subtypes of ExplicitlyExpressedConsent based on the specific requirements and criteria defined by GDPR.
5.5.1.3 Consent Status
The state or status of consent refers to the stage of information about a particular consent instance within its lifecycle. For example, (given) consent first starts with the identification of need to ask consent, then issuing a request (to the individual), making a decision (by the individual), and then following it up with further actions such as the individual withdrawing it. Keeping track of such information is necessary in order to determine whether the current stage of consent information is suitable for its use in justifying processing of personal data governed by that consent, as well as to fulfil obligations such as to keep records of consent. To assist with such consent information management, DPV provides Consent Status as a way to represent the lifecycle and usefulness of an instance towards processing personal data.
DPV's Consent Statuses are represented by ConsentStatus and indicated using hasConsentStatus relation. The statuses are segregated into two categories based on their interpretation towards processing: ConsentStatusValidForProcessing and ConsentStatusInvalidForProcessing. There are (currently) only two statuses that are valid for processing: ConsentGiven representing the individual has consented, and RenewedConsentGiven where an earlier given consent is renewed, refreshed, or reaffirmed.
The rest of (currently) 8 statuses refer to various stages that are considered invalid for processing. These are: ConsentUnknown for when information about the status is unknown or unconfirmed, ConsentRequested for when a request to obtain or give consent has been made, ConsentRequestDeferred for when the request was opted to be dismissed or delayed without a decision, ConsentRefused for when consent was refused, ConsentExpired for when the validity (temporal or otherwise) associated with a given consent instance has lapsed, ConsentInvalidated for when a given consent instance is found invalid e.g. by a court, ConsentRevoked for when a given consent instance is revoked or terminated such as when a service provider stops providing the service, and ConsentWithdrawn for when the individual withdraws a previously given consent.
5.5.1.4 Consent Indication
To indicate which entity is responsible for a specific consent stage (e.g. individual for given consent, requestor for consent requested), the relation isIndicatedBy is provided. It can be used with any Entity such as DataSubject or its subtypes such as User or specific instances of these to record information regarding who was responsible for the indicated status and consent action. To indicate the method by which an entity has indicated the specific consent, the relation hasIndicationMethod is provided. To indicate the time (or similar temporal information), the relation isIndicatedAtTime is provided.
Note: Common legal concepts/properties
The concepts and relations mentioned here regarding consent, such as isIndicatedBy, are also applicable and suitable for use with other legal bases or actions, such as contracts, legal requests, or exercising rights. Therefore, these can also be used in other contexts as deemed suitable. We are working on providing specific concepts and guidance for more detailed representation of information for such other legal bases and actions.
To specify consent provided by delegation, such as in the case of a parent or guardian providing consent for/with a child, the isIndicatedBy relation can be used to associate the parent or guardian responsible for providing consent (or its affirmation). Since by default the consent is presumed to be provided by the individual, when such individuals are associated with their consent, i.e. through hasDataSubject, the additional information provided by isIndicatedBy can be considered redundant and is often omitted.
Note: Planned deprecation of properties
The concepts/relations provided for consent in DPV v0.7 and earlier have been put on a sunset schedule with planned deprecation in favour of newer concepts/relations that offer a harmonised representation of information and consistency with other legal basis. The sunset concepts/relations have been retained for now given their prevalence in adopter's implementations. It is therefore suggested to use or to migrate existing uses to the newer concepts/relations described in this section.
Properties to be deprecated include: hasExpiry, hasExpiryTime, hasExpiryCondition, hasProvisionMethod, hasProvisionTime, hasWithdrawalMethod, hasWithdrawalTime, hasWithdrawalBy, hasProvisionBy, hasProvisionByJustification, hasWithdrawalByJustification, hasConsentNotice, isExplicit.
5.5.1.5 Duration of Consent
To indicate the duration or validity of a given consent instance, the existing contextual relation hasDuration along with specific forms of Duration can be used. For example, to indicate consent is valid until a specific event such as account closure, the duration subtype UntilEventDuration can be used with additional instantiation or annotation to indicate more details about the event (in this case the closure of account). Similarly, UntilTimeDuration indicates validity until a specific time instance or timestamp (e.g. 31 December 2022), and TemporalDuration indicates a relative time duration (e.g. 6 months). To indicate validity without an end condition, EndlessDuration can be used.
While the above information considered duration as determining the validity of given consent, there are also other uses of duration associated with consent. For example, the duration information is intended to be a trigger to confirm or renew consent instead of rendering it invalid immediately. Or, the duration associated with ConsentRequested could be used to indicate when consent should be requested again.
A ‘legal entity’ is an entity whose role is defined legally or within legal norms. DPV provides a taxonomy of entities based on their application within laws and use-cases. Alongside DataController and DataSubject, the DPV also defines other types of entities involved in the processing of personal data such as DataProcessor, ThirdParty, or terms associated with data transfers such as DataImporter and DataExporter. In addition to these, various kinds of Authority, including DataProtectionAuthority are also provided.
5.6.1 Entity Descriptions
Figure 32 Describing Entities in DPV
5.6.2 Legal Roles
Figure 33
To specify the roles organisations can take in the context of data processing, DPV defines the following concepts based on terminology from ISO 29100 and GDPR. In these, an entity can take on one or more roles as necessary or specified within an use-case.
DataController - An entity responsible for deciding the purposes and means of processing.
DataProcessor - An entity contracted by a Controller to carry out the processing.
DataSubProcessor - An entity contracted by a Processor to carry out the processing.
Recipient - An entity that is recipient of personal data
ThirdParty - An entity other than a Controller or a Processor who also processes personal data
DataExporter - An entity that exports data across a jurisdiction or context.
DataImporter - An entity that imports data into a jurisdiction or context.
JointDataControllers - Multiple Controllers that together are responsible as Controller(s) for the processing of personal data.
DataProtectionOfficer - An agent affiliated or part of another entity and represents it regarding overseeing processing of personal data and its relevant obligations.
5.6.3 Organisation Categories
Figure 34 Describing Entities in DPV
Organisation is a specified type of entity, representing common concepts such as Company or Business, as well as non-commercial entities such as NGO or University. To assist with expressing such common types of organisations, DPV provides concepts covering Industry, Governmental bodies, NGOs, For and Not-For Profits, and Academic or Scientific Organisations.
We are looking to provide a rich collection of organisation types to accurately reflect the contextual differences between specific organisation types based on domain (e.g. education and school) and roles (e.g. vendor, procurer). Suggestions and proposals for these are invited.
5.6.4 Authorities
The concept Authority is a specific Governmental Organisation authorised to enforce a law or regulation. Authorities can be associated with a specific domain, topic, or jurisdiction. DPV currently defines regional authorities for NationalAuthority, RegionalAuthority, and SupraNationalAuthority, and DataProtectionAuthority represents authorities associated with data protection and privacy. To associate authorities with concepts, the relations hasAuthority and isAuthorityFor are provided.
5.6.5 Data Subjects
DPV provides a taxonomy of data subject types to assist with describing what kind of individuals or groups are associated with an use-case. Some examples of such types are age-based roles: Adult and Child, ParentOfDataSubject, GuardianOfDataSubject; vulnerability: VulnerableDataSubject, ElderlyDataSubject, AsylumSeeker; domain-specific roles such as Patient, Employee, Student, jurisdictional roles such as Citizen, NonCitizen, Immigrant; and general roles such as User, Member, Participant, and Client.
To represent location, the concept Location along with relations hasLocation is provided. For geo-political locations, the concepts such as Country and SupraNationalUnion are subtyped, with hasCountry and ThirdCountry with hasThirdCountry provided for convenience in common uses (e.g. data storage, transfers).
To define contextual location concepts, such as there being several locations, or that the location is 'local' to an event, DPV provides two concepts. LocationFixture specifies whether the location is 'fixed' or 'deterministic', with subtypes for fixed single, fixed multiple, and variable locations. LocationLocality specifies whether the location is 'local' within the context, with subtypes for local, remote, within a device, or in cloud.
To represent locations as jurisdictions, the relation hasJurisdiction is provided. The concept Law represents an official or authoritative law or regulation created by a government or an authority. To indicate applicability of laws within a jurisdiction, the relation hasApplicableLaw is provided.
For indicating additional information regarding how the expressed information should be interpreted, or how it applies within a particular context, the Context concept along with the hasContext relationship can be used. Context refers to a generic collection of concepts that assist in indicating information such as the necessity, importance, environment - which aid in the interpretation or application of other core concepts.
5.8.1 Importance and Necessity
DPV provides two subtypes of concepts to denote contextual Importance and Necessity, which can be applied to specific contexts such as PersonalDataHandling, Purpose, PersonalData.
Importance is similar in application to Necessity, and provides a way to indicate how central or significant the indicated operation(s) are to the context (e.g. to the Controller). Subtypes of importance are PrimaryImportance to indicate 'main' or 'central' or 'primary' importance, and SecondaryImportance to indicate 'auxiliary' or 'peripheral' or 'secondary' importance.
Necessity enables specifying whether the contextual information is Required, is Optional, or is NotRequired. These can be used to indicate, for example, which parts of processing operations (e.g. purposes, personal data) are optional, and whether a particular processing operation is required to be carried out.
5.8.2 Duration and Frequency
To express the duration of events or operations, such as how long processing will take or the validity of consent, the concept Duration can be used. Duration is indicated using the relation hasDuration, and has the following subtypes:
TemporalDuration - indicating a relative temporal duration, e.g. 6 months.
UntilTimeDuration - indicating duration that occurs until the end of specified time, e.g. until 31 DEC 2022.
UntilEventDuration - indicating duration that occurs until the end of specified event, e.g. until account is closed.
FixedOccurencesDuration - a duration that is based on number of occurrences, e.g. until you view it 3 times
EndlessDuration - indicating a duration without an end condition or temporal notation.
Frequency indicates how frequently something occurs. Statistically, this can be expressed as the combination of number of occurrences and a time period, which can further be expressed as a probabilistic value or a percentage. For example, for something occurring once every year, the frequency is: 1 or 100% for 1 year. While such quantified representations are important for determining metrics and performing operations, DPV focuses on the qualitative labelling of such representations within a specific context.
The relation hasFrequency associates a frequency with a context, and can be expressed using the following subtypes:
ContinousFrequency - indicates things occurring continuously, e.g. location collection happens continuously.
SporadicFrequency - indicates things occurring sporadically or rarely or not often, e.g. collecting system usage logs every month.
OftenFrequency - indicates things happen often or regularly or commonly, e.g. online status is reported every 5 mins.
SingularFrequency - indicates things happen only once.
5.8.3 Scope and Justification
Scope, associated using the relation hasScope, indicates the extent or range or boundaries associated with(in) a context. For example, where processing only takes place for a specific service or within a jurisdictional framework.
Justification, associated using hasJustification, is another generic concept representing the argument or justification or reason provided to explain or document information within the specific context. For example, where an audit was rejected the justification for this rejection can be associated. Or, if processing was decided to be continued despite an assessment showing high-risk criteria, the outcome can express a justification.
5.8.4 Data and Processing Scales
Scale, associated using hasScale, refers to a measurement along some dimension. DPV provides (qualitative) scales for expressing Data Volume, Data subjects, and Geographical Coverage of processing. Along with these, DPV also provides a Processing Scale to express combinations of these. NOTE: The actual meaning or quantified amounts for each concept are not defined due to their interpretation based on contextual factors such as legislations, guidelines, domains, and variations across industries.
DataVolume refers to the volume or amount of data in the form of a scale with the following subtypes: HugeDataVolume, LargeDataVolume, MediumDataVolume, SmallDataVolume, SporadicDataVolume, SingularDataVolume, and is associated using hasDataVolume.
DataSubjectScale refers to the volume or amount of data subjects in the form of a scale with the following subtypes: HugeScaleOfDataSubjects, LargeScaleOfDataSubjects, MediumScaleOfDataSubjects, SmallScaleOfDataSubjects, SporadicScaleOfDataSubjects, SingularScaleOfDataSubjects, and is associated using hasDataSubjectScale.
GeographicCoverage refers to the volume or amount of geographical area covered by the processing in the form of a scale with the following subtypes: GlobalScale, NearlyGlobalScale, MultiNationalScale, NationalScale, RegionalScale, LocalityScale, LocalEnvironmentScale, and is associated using hasGeographicScale.
ProcessingScale, also associated using hasScale, represents an interpretation of the other scales to express whether the combination entails a specific threshold for qualifying as 'large scale'. Specific subtypes defined for these are: LargeScaleProcessing, MediumScaleProcessing, SmallScaleProcessing.
To assist with expressing the state or status associated with various activities, DPV provides the Status concept that can be associated contextually using the hasStatus relation. Specific subtypes are provided as ActivityStatus, ComplianceStatus including Lawfulness, AuditStatus, ConformanceStatus, and RequestStatus.
ActivityStatus represents a state or status of an activity's operations and lifecycle, which includes ActivityProposed, ActivityOngoing, ActivityHalted, ActivityCompleted, and ActivityNotCompleted.
ComplianceStatus represents status associated with compliance with some norms, objectives, or requirements. Types include Compliant, PartiallyCompliant, NonCompliant, ComplianceViolation, ComplianceUnknown, ComplianceIndeterminate. The association with a law or objective can be specified using hasApplicableLaw or hasPolicy directly for the status or indirectly through the concept whose status is being represented.
Lawfulness represents a special type of ComplianceStatus which relates to legal compliance, or lawfulness, and has types Lawful, Unlawful, and LawfulnessUnkown.
AuditStatus represents the state or status of an audit, where the term audit is loosely defined, and may or may not relate to legal compliance - for e.g. for impact assessments, or as part of certification, or organisational quality assurance processes. Types of audits include AuditApproved, AuditConditionallyApproved, AuditRejected, AuditRequested, AuditNotRequired, and AuditRequired.
ConformanceStatus represents the status of conformance, which is defined distinctly from compliance by considering voluntary association or following of a guideline, requirement, standard, or policy, and where compliance is related to the (legal or other systematically defined) conformity of a given system or use-case with rules which may dictate obligations and prohibitions that must be followed. To provide an illustrative example, consider conformance with a standard on best practices regarding security may assist in the demonstration of compliance with a legal norm requiring organisational measures of security. Types of conformance defined are: Conformant and NonConformant.
RequestStatus represents the state or status of requests, which can be between entities such as data subjects and controllers regarding exercising of rights, or between controllers and processors regarding processing operations, or between authorities and controllers regarding compliance related communications. Types of request statues are: RequestInitiated, RequestAcknowledged, RequestAccepted, RequestRejected, RequestFulfilled, RequestUnfulfilled, RequestRequiresAction, RequestRequiredActionPerformed, RequestActionDelayed, and RequestStatusQuery.
For risk management, DPV's provides a lightweight risk ontology based on commonly utilised concepts regarding risk mitigation and risk management. While these concepts permit rudimentary association of risks and mitigations within a use-case, it is important to note that DPV (currently)
does not provide comprehensive concepts for risk management.
For more developed representations of risk assessment, mitigation, and management vocabularies, we suggest the adoption of relevant standards, such as the ISO/IEC 31000 series, and welcome contribution for their representation within DPV through Risk Extension for DPV.
5.9.1 Risk and Mitigation
The central concepts within DPV's risk management vocabulary are Risk (associated using hasRisk) and its mitigation through RiskMitigationMeasure (associated using mitigatesRisk and conversely isMitigatedByRisk). Through these, risk can be associated with specific concepts (e.g. data categories) or contexts (e.g. personal data handling).
To express quantified and qualified attributes associated with risk, such as levels and severity, DPV provides the following concepts: RiskLevel (associated using hasRiskLevel) to indicate the 'level' or 'magnitude' of risk; Severity (associated using hasSeverity) to indicate the magnitude of being unwanted or causing unwanted impacts, and Likelihood (associated using hasLikelihood) to indicate the probability of it taking place.
To express remaining risk after mitigation, the concept ResidualRisk (associated using hasResidualRisk and conversely isResidualRiskOf) is provided. To represent the management of risk and the procedures and methods associated with it, the concept RiskManagementProcess is defined as part of the Technical and Organisational Measures.
5.9.2 Consequences and Impacts
Figure 37
To represent the consequences and impacts of a risk event taking place, DPV provides the following concepts: Consequence arising from the context (e.g. data breach or unauthorised access to data) and the Impact caused (e.g. identity theft).
Consequences are associated using hasConsequence, and subtyped to indicate whether the consequence was due to the event successfully taking place (ConsequenceOfSuccess) or due to its failure in successfully completing or not taking place (ConsequenceOfFailure) or as side-effects (ConsequenceAsSideEffect).
Impacts are associated using hasImpact, with the specific entity being impacted indicated using hasImpactOn. Impacts are subtyped to represent: Benefit, Detriment, Damage (MaterialDamage, NonMaterialDamage), and Harm
.
5.10 Exercising Rights
Figure 38
The concept Right represents a normative concept for what is permissible or necessary in accordance with a system such as laws. To associate rights with concepts that are relevant or within which those rights occur, the relation hasRight is used. Rights can be passive, which means they are always applicable without requiring anything to be done, or active where they require some action to be taken to initiate or exercise them. To represent these concepts, DPV uses PassiveRight and ActiveRight respectively. Rights can be applicable to different contexts or entities. To differentiate rights applicable or afforded to data subjects, the concept DataSubjectRight is used.
The information regarding hwo to exercise a right is provided through RightExerciseNotice and associated using the isExercisedAt relation. This information can specify contextual information through use of other concepts such as PersonalDataHandling to denote a necessaryPurpose of IdentityVerification as part of the rights exercise.
A RightExerciseActivity represents a concrete instance of a right being exercised. It can include contextual information such as timestamps, durations, entities, etc. that can be part of record-keeping. An activity can be a single step related to rights exercise -- such as the initial request to exercise that right, or its acknowledgement, or the final step taken to fulfil the right (e.g. provide some information), or it can also be a single activity describing the entire rights exercise process(es). To collate related activities associated with a rights exercise (e.g. associated with a specific data subject or a specific request), the concept RightExerciseRecord is useful. The information provided to describe or in fulfilment of a right exercise is represented by RightFulfilmentNotice and that associated when a right exercise cannot be fulfilled is represented by RightNonFulfilmentNotice.
To indicate contextual information about Right Exercise activities, DPV suggests reuse of existing relations, such as those from DPV itself and DCMI Metadata Terms (DCT). For example, dct:accessRights can be used to specify constraints or requirements regarding access (e.g. log in required), or dct:hasPart and dct:isPartOf to express records and its contents, dct:valid to express validity constraints on the exercising being made available, foaf:page to specify the location or provision of notice, and hasStatus to represent the status of an activity.
When rights require the provision of information which beyond a static common notice, for example a document personalised to the individual's information, or a dataset containing the individual's data, DPV recommends using Data Catalog Vocabulary (DCAT) - Version 2 to model the contents as a dcat:Resource or other relevant concepts from [DCAT] and [DCT] such as dct:format, dct:accessRights, and dct:valid.
5.11 Rules
DPV provides the concept Rule to specify requirements, constraints, and other forms of 'rules' that are associated with specific contexts (e.g., processing activities) using the relation hasRule. DPV provides three forms of Rules to represent Permission, Prohibition and Obligation, and their corresponding relations hasPermission, hasProhibition and hasObligation, to indicate a Rule that specifies whether something is permitted, prohibited or an obligation, respectively. DPV does not define additional semantics for rules and limits its scope and focus to provide a simple way to specify permissions, prohibitions, and obligations as common rules associated with personal data and its processing activities. For a more extensive and richer set of semantics and concepts to represent rules, DPVCG suggests looking towards other languages, such as [ODRL], [SHACL], and [RuleML] that have been developed with the specific goal of representing and applying rules. We welcome contributions for aligning DPV with these, and for providing guidance on how to complement DPV's rule-based concepts with external languages.
In representing Rules, DPV only provides the concept and does not express any inherent semantics on what those rules mean in relation to each other. For example, DPV does not express Permission to be non-compatible or disjoint from Prohibition. This is to separate the interpretation and application of rules based on the necessities of a use-case. For example, in a legal investigation it may be prudent to specify permission and prohibition can never occur together, but this may not be true if there are different legal requirements that allow a prohibition to be resolved or deferred, such as through another permission that overrides the prohibition.
DPV does not specify 'default' in relation to rules, i.e. it does not provide an interpretation of whether some rules apply automatically unless otherwise declared. For example, in declaring an instance of Personal Data Handling, the assumption is that the activities are modelled for what is happening or what is intended/planned to happen. The explicit annotation using a Permission rule adds information about whether some activity is permitted (and its associated information). Instead, if the use-case is using DPV to only document activities that are permitted, there is no need to explicitly specify the permissions. Similarly, just because something is happening or planned to happen, it cannot be assumed to be permitted (e.g., from evaluation of legal requirements).
To associate a rule with a specific context, which can be a PersonalDataHandling or PersonalData or Purposes, the relations hasPermission, hasProhibition and hasObligation are provided. Additional types of rules can be added to DPV by extending the Rule Concept (e.g., :MyRule rdfs:isSubClassOf dpv:Rule).
5.12 Data Transfers
Note: Data Transfer concepts will be added in the near future
5.13 Data Breach
Note: Data Breach concepts will be added in the near future
6. Extensions
6.1 DPV-PD (Personal Data)
DPV-PD: Extension providing Personal Data Categories provides additional concepts that extend the DPV's personal data taxonomy based on an opinionated structure contributed by R. Jason Cronk from EnterPrivacy. This separation is to enable adopters to decide whether the extension's concepts are useful to them, or to use other external vocabularies, or define their own.
Concepts within [DPV-PD] are broadly structured in top-down fashion by utilising their relevance and origin as:
Internal (within the person): e.g. Preferences, Knowledge, Beliefs
External (visible to others): e.g. Behavioural, Demographics, Physical, Sexual, Identifying
Social: e.g. Family, Friends, Professional, Public Life, Communication
Financial: e.g. Transactional, Ownership, Financial Account
Tracking: e.g. Location, Device based, Contact
Historical: e.g. Life History
6.2 DPV-GDPR
While several of DPV's concepts are inspired from the GDPR, the use of DPV itself does not point towards specific concepts from GDPR such as legal bases in Article.6. This is to enable use of DPV with different jurisdictional and domain terminologies through the use of extensions. [DPV-GDPR] provides an extension of DPV's concepts for the GDPR for the following.
Legal Bases (Art.6) - DPV's legal bases are extended to represent specific clauses from GDPR Art.6 (e.g. A.6-1a consent).
Legal Bases (Art.9) - DPV's legal bases are extended to represent specific clauses from GDPR Art.9 (e.g. A.9-2a explicit consent).
Legal Bases (Data Transfers) - DPV's DataTransferLegalBasis is extended to represent GDPR's Articles 45, 46, and 49.
Data Transfer Tools - Mechanisms defined by the GDPR for data transfers, e.g. contractual clauses.
DPIA - Statuses for representing DPIA related procedures and outcomes, e.g. necessity, high-risk, and consultation required.
6.3 DPV-TECH
DPV-TECH: Extension providing Technology-relevant concepts extends the DPV's terms to represent further specific details regarding technologies, their management, and relevance to actual real-world tools and systems. It provides concepts for the following:
Type of technology: Data, Operational, Security, Management, Identity, Surveillance
Communication method: WiFi, Bluetooth, GPS, Cellular Network
Actors: Developer, Provider, User, Subject
The intention and aim of developing the DPV-TECH extension is to describe real-world tools and services, such as a specific cloud storage provider, and provide categorisation and metadata to connect it to DPV's concepts, such as to indicate the cloud storage instance features encryption at rest as a technical measure. Through these, the management and documentation of use-cases can be made easier by providing the relationships between tools/services and technical measures as a 'knowledge graph'.
6.4 DPV-LEGAL
[DPV-LEGAL] provides jurisdictional concepts such as locations (countries), memberships (e.g EU/EEA), laws (e.g. GDPR), authorities (e.g. CNIL for FR), and adequacy decisions (e.g. EU - UK). It also provides relationships between these, e.g. to indicate country FR has law GDPR which is enforced by CNIL authority.
The goal of the DPV-LEGAL extension is to assist with identifying relevant laws, authorities, and data transfer implications. It also provides information about these concepts, e.g. authority contact information or website.
As with the rest of DPV, we welcome contributions and discussions to expand the DPV-LEGAL taxonomies.
6.5 RISK
Risk Extension for DPV builds on top of the lightweight risk framework within DPV by providing the following extensive concepts related to risk assessment and management. We are in the process of identifying additional concepts and taxonomies for the risk extension, such as for risk management procedures and the creation of a risk ontology based on ISO standards.
Risk Controls - categories of measures such as those related to risk source, likelihood, consequence, vulnerability, as well as the intended effect in terms of monitoring, controlling, halting, removing, or reducing.
Consequences and Impacts - list of consequences such as data breaches, costs, identity theft and several others that are categorised based on DPV's impact framework i.e. damage, harm, or detriment.
Scale for Risk Levels, Severity, and Likelihood - a 7 point qualitative scale to express concepts associated with levels, severity, and likelihood of risk and its consequences.
Risk Matrix - an encoded form of risk matrices based on combinations of severity and likelihood along with the resulting risk level. Risk matrix nodes and values are provided for dimensions 3x3, 5x5, and 7x7.
Risk Assessment Techniques - list of risk assessment techniques, based primarily on IEC 31010:2019, and other sources.
Risk Methodologies -list of risk methodologies based on ISO standards, ENISA reports, and other sources.
6.6 RIGHTS
Impact assessments related to impact on individuals and society require representation of rights as concepts which may be affected or impacted. To assist with these, Rights Extension for Data Privacy Vocabulary is provided. Currently, it provides a taxonomy of concepts to represent the EU Charter of Fundamental Rights.
7. Contributing to DPV
The DPVCG welcomes participation regarding the DPV, including expansion or refinement of its terms, addressing open issues, and welcomes suggestions on their resolution or mitigation.
While we welcome participation via any and all mediums - e.g., via GitHub pull requests or issues, emails, papers, or reports - the formal resolution of contributions takes place only through the DPVCG meeting calls and mailing lists. We therefore suggest joining the group to participate in these discussions for formal approval.
For contributions to the DPV, please see the section on GitHub. The current list of open issues and their discussions to date can be found at GitHub issues. Note, GitHub Issues are preferred for discussion of concepts and proposals.
To suggest a new term, we request following information:
term
description of the term
whether it should be a class or a property
relation to existing term(s) in DPV e.g. through sub-classes
source (where applicable)
justification or relevance of why this term should be added (where not obvious)
Notes
This document is based on inspiration from the following:
DPVCG was initiated as part of the SPECIAL H2020 Project, which received funding from European Union’s Horizon 2020 research and innovation programme under grant agreement No. 731601. This work and Harshvardhan J. Pandit have been funded by the Irish Research Council Government of Ireland Postdoctoral Fellowship Grant #GOIPD/2020/790.
Thanks to Georg P Krog (Signatu), Piero Bonatti (Universita' di Napoli Federico II), and Beatriz Esteves (Universidad Politécnica de Madrid) for their comments on drafts of this document.