Data Model and Representations
See [[DID-CORE]] for normative requirements associated with the Data Model.
See [[DID-CORE]] for normative requirements associated with Representations.
There is no strong consensus regarding preserving data model properties across representations. Removing properties when converting a DID document can result in an inability to maintain interoperability with [[VC-DATA-MODEL]]. See Drawbacks and Benefits.
Drawbacks
The DID document data model contains properties (such as `id`, `verificationMethod`, and `service`), which are defined in a way that is independent of a concrete representation. There are a number of known representations, including JSON and JSON-LD (defined by DID Core), and CBOR (defined by a DID WG Note). Additional representations (such as XML, YAML, CBOR-LD, and others) are possible and could be defined in the future. For each of these representations, a combination of production and consumption rules defines the concrete syntax of properties, but the semantics of properties are independent of any given representation. In other words, in every representation of a DID document, there is always a way to represent a `service` or a `verificationMethod`, and their meanings are consistent across conformant representations.
In addition to properties, a DID document may contain representation-specific entries which may be required by certain representations in order to fully represent the DID document data model and its properties. For example, the JSON-LD representation of a DID document (with media type `application/did+ld+json`) requires the `@context` representation-specific entry, in order to correctly express the semantics of properties such as `id`, `verificationMethod` or `service` within the JSON-LD representation. This enables JSON-LD’s semantics which are based on a decentralized, permissionless, open-world data model.
In contrast to this, the (non-LD) JSON representation (with media type `application/did+json`) does not have this semantic capability; instead, (non-LD) JSON documents always need agreement on semantics in some out-of-band way that is not part of the document itself. In the case of DID documents using the (non-LD) JSON representation, those semantics are typically established by the DID Spec Registries. Therefore, establishing semantics of DID document properties in the (non-LD) JSON representation does not require the representation-specific `@context` entry, as is required by the JSON-LD representation.
As with the (non-LD) JSON representation compared to the JSON-LD representation, similar considerations apply between the (non-LD) CBOR representation and the CBOR-LD representation.
Other examples of representation-specific entries could be XML namespace definitions or YAML tags, although these particular representations have not been defined at the time of this writing.
If an entry that is specific to one representation appears in another representation, it can be called a representation-foreign entry. An example of this is a `@context` entry appearing in the `application/did+json` representation.
Examples of representation-specific entries and representation-foreign entries:
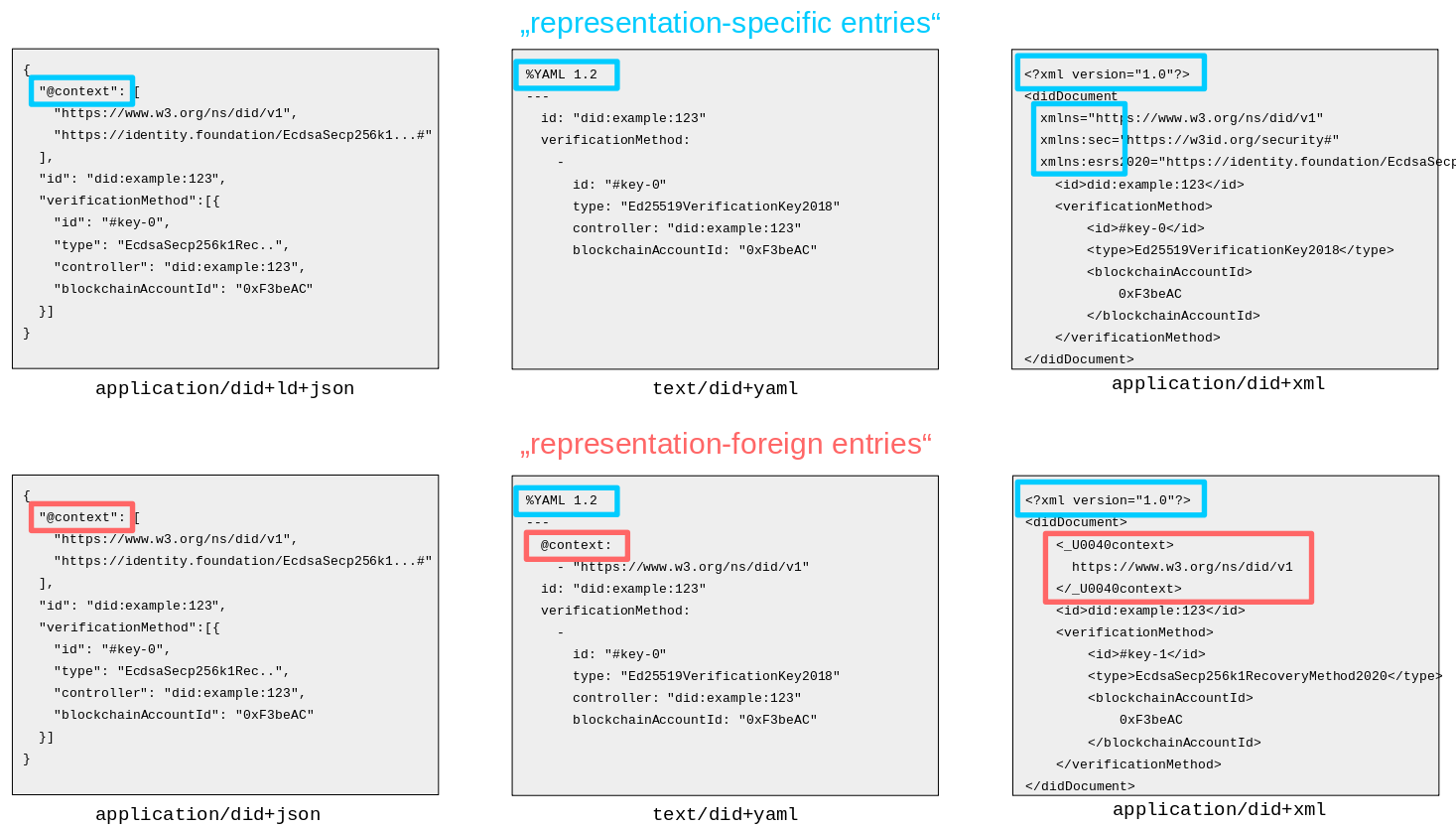
Avoid representation-foreign entries
It is bad practice and potentially harmful for producers to include "representation-foreign entries" in DID documents.
Different implementations of DID document consumers may or may not be able to properly understand the meaning and processing rules of representation-foreign entries. Since DIDs and DID documents form an open ecosystem with many producers and consumers, a producer cannot anticipate the behavior of a consumer with regard to representation-foreign entries.
For example, if a producer adds an
@context
entry to a DID document in the
application/did+json
representation, some consumers (those that understand JSON-LD, such as
JSON-LD document loaders) may process
it
in one way, while other consumers (those that only understand plain
JSON, without any JSON-LD specific rules)
may process it in a different way.
This can lead to inconsistent behavior by consumers that cannot be predicted by a producer.
Reliance on representation-foreign entries
It is bad practice and potentially harmful for consumers to rely on representation-foreign entries in DID documents.
As a special case of the previous section, certain consumers may go as far as relying on the presence of representation-foreign entries. For example, an incorrectly implemented consumer of DID documents in the `application/did+json` representation may attempt to apply JSON-LD tooling to that representation. That tooling is dependent on the presence of the `@context` representation-foreign entry, which is not actually required (and in fact discouraged) to be used in the `application/did+json` representation.
The result is lack of interoperability, since such consumers will throw errors even if the returned DID document representation is actually conformant.
Security problems with representation-foreign entries
If some implementations of DID document consumers process representation-foreign entries, and others don’t, then this can lead to security holes, since the semantics of DID document properties will not be interpreted in a predictable way.
For example, consider the following DID document, and assume that the JSON-LD context `https://example.com/myextensions/other-definitions.jsonld` defines `blockchainAccountId` in a way that is different from the property listed in the DID Specification Registries.
{
"@context":[
"https://www.w3.org/ns/did/v1",
"https://example.com/myextensions/other-definitions.jsonld"
],
"id":"did:example:123456789abcdefghi",
"verificationMethod":[{
"id": "did:example:123456789abcdefghi#vm-3",
"controller": "did:example:123456789abcdefghi",
"type": "EcdsaSecp256k1RecoveryMethod2020",
"blockchainAccountId": "eip155:1:0xF3beAC30C498D9E26865F34fCAa57dBB935b0D74"
}]
}
If this DID document is consumed as `application/did+json` by an implementation that doesn't understand JSON-LD, it will interpret `blockchainAccountId` as the property listed in the DID Specification Registries, and it will process it accordingly.
If the exact same DID document is consumed as `application/did+json` by an implementation that understands JSON-LD, it may interpret `blockchainAccountId` using the provided JSON-LD context, and therefore process it differently.
It is a common mistake to claim that "JSON-LD is just JSON", and to justify injecting the `@context` representation-foreign entry into a DID document in the `application/did+json` representation. This claim however is true only on the syntax level, but wrong and dangerous on the semantic level, especially when security-related properties are involved. In the example above, different consumer implementations are likely to come to different conclusions on how the DID can be controlled.
Representation-foreign entries in DID documents should be avoided, since they can lead to inconsistent and unpredictable DID control decisions.
Conversion between Representations
The DID document data model and the production/consumption rules of representations have been designed to enable lossless conversion between representations. Conversion between representations is achieved by executing the consumption rules of the source representation, and then the production rules of the target representation.
The DID Specification Registries [[DID-SPEC-REGISTRIES]] provide additional information about properties as well as representation-specific entries that help with such conversion. For example, a DID document in the `application/did+json` representation can be converted to the `application/did+ld+json` representation by adding a `@context` representation-specific entry during production, using the JSON-LD context information in the DID Specification Registries [[DID-SPEC-REGISTRIES]].
Conversely, a DID document in the `application/did+ld+json` representation can be converted to the `application/did+json` representation by removing the `@context` representation-specific entry during consumption.
Representation-foreign entries in DID documents should be avoided, since the implications on lossless conversion between representations is unclear.
Benefits
Implementers are not required to support all representations.
For example, an implementation might choose to only support
application/did+json,
and choose not to support application/did+ld+json,
application/did+dag+cbor,
application/did+xml, application/did+yaml,
etc...
Implementers might prefer to use JSON or YAML representations to implement both the abstract data model and concrete reprepresentations.
When converting between an implementation of the abstract data model and a representation that is capable of preserving all properties, all properties SHOULD be preserved.
For example, preserving @context in YAML,
allows for the document to later be used with
documentLoaders
that use
JSON-LD Framing
to perform
dereferencing.
---
"@context":
- https://www.w3.org/ns/did/v1
- https://w3id.org/security/suites/jws-2020/v1
id: did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
verificationMethod:
- id: did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
type: JsonWebKey2020
controller: did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
publicKeyJwk:
kty: EC
crv: P-384
x: ELYfgFzSi43VGgKlyuYBKeoW00DmNqf5VuMWD1iUTTHQ8NRQrR4KHShzH_DrvOhh
y: sftqdHdso4JPQO3MLnsXmWbAFqjmHLgP8H_DZSLxx3ei9kLj_W3R6NhtH03bwE1C
assertionMethod:
- did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
authentication:
- did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
capabilityInvocation:
- did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
capabilityDelegation:
- did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
keyAgreement:
- did:key:z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6#z82Lkm8gN2PGD7WbUiTUKRHgSptPhGPAQG9HT9HybYE9LoKYwcikh5rAU9gGo3qTne3ZHf6
Preserving members across representations is also common in OpenAPI Specification 3.1.0, which supports JSON Schema represented as YAML or JSON.
DID methods that support both application/did+ld+json and
application/did+json
ought to return application/did+json with an
@context, because it enables
both representations to be used with tooling and standards that support
semantics (such as [[VC-DATA-MODEL]]),
and because the default behavior of JSON processors is to ignore object
members that are not understood.
DID document representations produced by an implementation ought to be treated as immutable, since any tampering, including adding, removing, or reordering core or representation specific entries might be considered malicious, since it alters the integrity of the produced DID document.