Use Cases
Client side applications can be generally classified into the following categories:
- Render intensive application:
-
Render intensive applications are client side applications whose main task is to fetch content from the backend server then render that content in the front-end. For example, news, social media Web applications, and mobile applications belong to this category.
- Computing intensive application:
-
Computing intensive applications are client side applications whose main task is to do computing intensive work on the client. For example, mobile gaming applications need to calculate certain objects' location and other complex parameters based on user interaction then rendering in the client side.
- Hybrid application:
-
Hybrid applications are applications whose main task includes both rendering intensive work and computing intensive work. For example, modern e-commerce mobile applications leverage machine learning inference in the client side for AR/VR type user experiences. At the same time, e-commerce mobile applications need to fetch dynamic content based on user preferences.
- Mobile/static client:
-
Some client side applications remain at a static location most of the time. For example, a camera for traffic monitoring and analysis does not require mobility support. On the other hand, some client side applications will change location continuously. For example, applications running on a connected vehicle or self driving vehicle will change location rapidly with the vehicle.
The use cases in the following sections are generally classified into the following categories based on different workload types.
Accelerated workloads
For this category of use cases, the client side application leverages the edge cloud for accelerating certain workloads by offloading those workloads to the edge.
Cloud App (UC-CA)
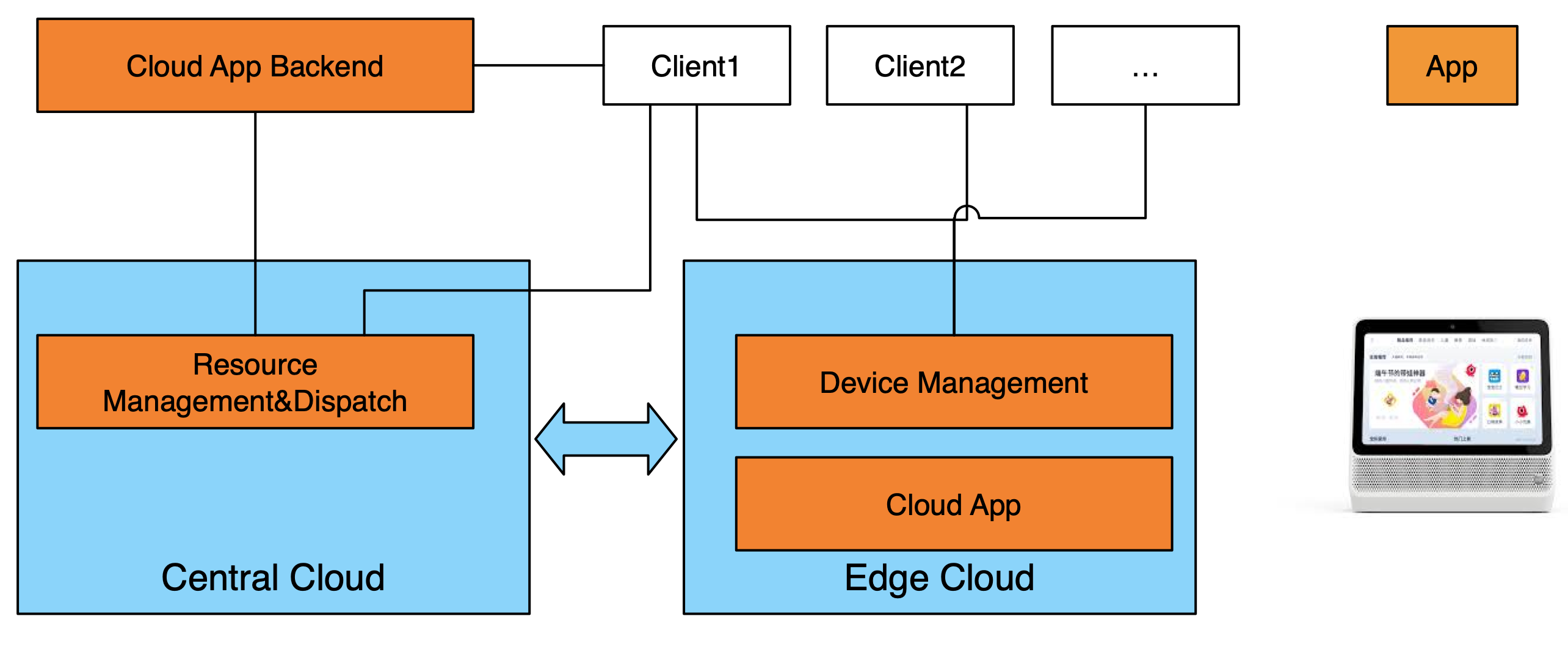
A Cloud App is a new form of application which utilizes cloud computing technology to move a client side application's workload to the Edge Cloud and/or a Central Cloud. The user interaction happens at the client device side and the computing and rendering process happens in the Edge Cloud side. This can accelerate the client side application's performance, lower the client's hardware requirements, and reduce cost.
As one example of a cloud App, Alibaba Group's Tmall Genie smart speaker leverages the Edge Cloud to offload its computing intensive and accelerated workload from the client side to the Edge Cloud.
The client, the Central Cloud, and the Edge Cloud work together in a coordinated way for Cloud Apps. Typically, the control and orchestration function is located in the Central Cloud. The computing intensive function is located in the Edge Cloud. The user interaction and display function is located in the client.
VR/AR Acceleration (UC-VR)
VR/AR devices such as VR/AR glasses normally have limited hardware resources, so it is preferred to offload computing intensive tasks to Edge Resources for acceleration. This reduces delay since the Edge Resource is deployed near the location of the user.
Note: this could be generalized to "acceleration of low-latency tasks". Some other examples might include game physics simulation or CAD tools (in a business environment). The latter might add confidentiality constraints (a business user may want to offload to on-premises computers). This pattern is for local communication to/from the client. See also "Streaming Acceleration", where the communication is in-line with an existing network connection.
Cloud Gaming (UC-CG)
Cloud gaming is a game mode which leverages Cloud and/or Edge Resources. Under the operation mode of a cloud game, the games are running on the Cloud side, and the game images are compressed and transmitted to users by video stream through the network after rendering. The cloud gaming user can receive the game video stream and can send control commands to the cloud to control the game.
Taking a "Click-and-Play" scenario for example, since all the rendering and control commands are offloaded to an Edge Resource, the cloud game user doesn't need to install the game locally. The user can just click the game and then play it easily.
By offloading the gaming workload to the edge and making full use of the computing power and low-latency network, the cloud gaming can provide a smoother experience.
Streaming Acceleration (UC-SA)
In the case of video acceleration, we may want to offload work to a location with better compute performance that is already on the network path. Specifically, consider a low-performance client that wants to compress video or do background removal as part of a teleconference. It could connect over a local high-performance wireless network to a local edge computer (perhaps an enhanced ISP gateway box) that would then perform the video processing and forward the processed video to the network.
Note: this pattern is for communication "in-line" with an existing network connection. See also "VR/AR", where the communication is to/from the offload target.
Online Video Conference (UC-VC)
One special case of streaming acceleration consists of online video conference applications. Suppose that an online video conference system provides a real-time translation and subtitles service. This will use AI/Machine learning technology and it is computing intensive. Also, the real time translation service is very delay sensitive.
The online video conference application could be installed on PC terminals or mobile terminals. For PC terminals, there is enough computing resources and enough disk storage to allow the installation of the online video conference application. In this case, the computing intensive work could be done in the PC terminal, providing an ultra-low-latency user experience.
For mobile terminals, there is limited disk storage and limited computing capability, so it is not possible to run the computing intensive task on the mobile terminals. In this case, the computing intensive task could be offloaded to the Edge, also providing a low-latency user experience.
It is preferred that in this use case the online video conference application can offload the computing intensive task according to the terminal capability and Edge Resources availability. The online video conference service provider can provide consistent user experience on different terminals.
Machine Learning Acceleration (UC-MLA)
Machine learning inference can be done in the client side to reduce latency. W3C is working on the WebNN standard that allows client side developers to leverage the machine learning acceleration hardware that resides in client side devices.
The client side devices may have different hardware capabilities. For example, some mobile phones have very limited hardware resources and do not have a GPU. It is very difficult for this kind of client device to run machine learning code. So in this scenario, it is preferred to offload machine learning code to the Edge Cloud. The user experience is greatly improved in this case.
Image and Video Processing and Understanding (UC-IVPU)
One special case of machine learning acceleration is image and video processing and understanding. For some mobile image/video processing applications, it is required to use machine learning algorithms for image/video analysis and processing. This normally needs an NPU (Neural Processing Unit) chipset on the terminals for better performance. For terminals without an NPU chipset, it is preferred to offload the machine learning computing intensive workload to the Edge Cloud as this will provide a consistent user experience on different terminals.
Professional Web-based Media Production (UC-PWMP)
Another special case and example of machine learning acceleration is professional web-based media production. Processing and rendering media is a complex task. For example, a video editing application needs to do image processing, video editing, audio editing, etc., so it has high performance requirements.
Professional web-based media production heavily relies on web-based media editing tools, and may include AI-based operators which can be used to do cutting, editing, transcoding, and publishing of videos to the cloud. Since the Edge Cloud has more computing power and is close to the user's location, by offloading the expensive rendering process to the Edge, web appliations can render media more quickly and provide a better user experience.
Background Rendering (UC-BR)
As a special case of UC-PWMP and UC-IVPU, a user may want to execute a background task, for example for rendering or machine training. This task would execute even while the initiating web application is not active. Such tasks are not latency sensitive and so could also be performed in the cloud, but the user may wish to execute them on hardware under their control for privacy or confidentiality reasons.
Robustness of Workload Acceleration for Certain Applications
For applications which offload some parts of its functionality to the Edge Cloud, if the Edge Cloud is not available due to client mobility or other reasons, it is preferred that the functionality could be handed over back to the client when necessary. More complex rules could be designed to improve the robustness of the application.
Live video broadcasting mobile application (UC-LVB)
One example of such a use case is: for mobile applications (for example, live video broadcasting mobile applications) that leverage the Edge Cloud for computing and/or machine learning acceleration, when certain conditions (Edge Cloud availability, network conditions, etc.) are not met for workload acceleration by offloading, they could have the ability to migrate workloads back to the client side to ensure the robustness and availability of the application.
Automatic License Plate Recognition (UC-ALPR)
Another example is automatic license plate recognition. For such applications, offline processing can provide 90% recognition rate. Online processing on the Edge improves the recognition rate to 99%. It is preferred to offload the license plate recognition computing intensive task to the Edge when the network connection is stable. If the network condition is not stable or broken, the offloaded computing intensive task could move back to the terminals to guarantee the availability of the service.
IoT workloads
In general, there are many opportunities for IoT devices to offload work to another computer, since they are generally constrained in processing power, energy, or both. Video processing however is of special interest because of its high data and processing requirements and privacy constraints. In this case the offload source is not necessarily a browser or web application but the process may be indirectly managed by one, and the capabilities provided by the proposed standard (e.g., a discoverable compute utility) can also be used directly by an IoT device.
Robot Navigation Acceleration (UC-RNA)
Consider a robot navigating in a home using Visual SLAM. In this case the robot has limited performance due to cost and power constraints. So it wishes to offload the video processing work to another computer. However, the video is sensitive private data so the user would prefer that it does not leave the user's premises, and would like to offload the processing to an Edge Resource, which in this case may be an existing desktop computer or an enhanced gateway computer (e.g., provided by an ISP). Latency may also be a concern, as the robot needs the results immediately to make navigation decisions, for example to avoid a wire or other obstacle on the floor.
Child Monitor (UC-CM)
In this use case a smart camera is directed to inform a parent if children leave a designated area, for example a yard. This requires person detection, a video analytics service which is computationally intense and difficult to perform on a phone. However, for privacy reasons, the parent does not want to stream video to the Cloud and perform processing there; instead they want to run the computation on an Edge Resource under their direct control. In this case, the parent also wants to run the processing as a background task that executes even when the browser/web app that invoked it is closed.
Gap Analysis
Common approaches for offloading
Currently, there are two common approaches for offloading. One is to send the code in the request from the client to the Edge Resource, the other is to have the Edge Resource fetch the code from file repositories on the Edge and execute them. Both work fine, but both approaches also have some downsides.
- Sending code from client to edge
-
In this approach, the client sends the local code to the Edge Resource, which then executes the code on the Edge side. The downside is obvious: since more data is transferred in the request it may cause network latency. Handling more data will also put more strain on the resource-constrained end device. Meanwhile, some code is sensitive, data security is also an big issue.
- Fetching code from file repositories and executing on the edge
-
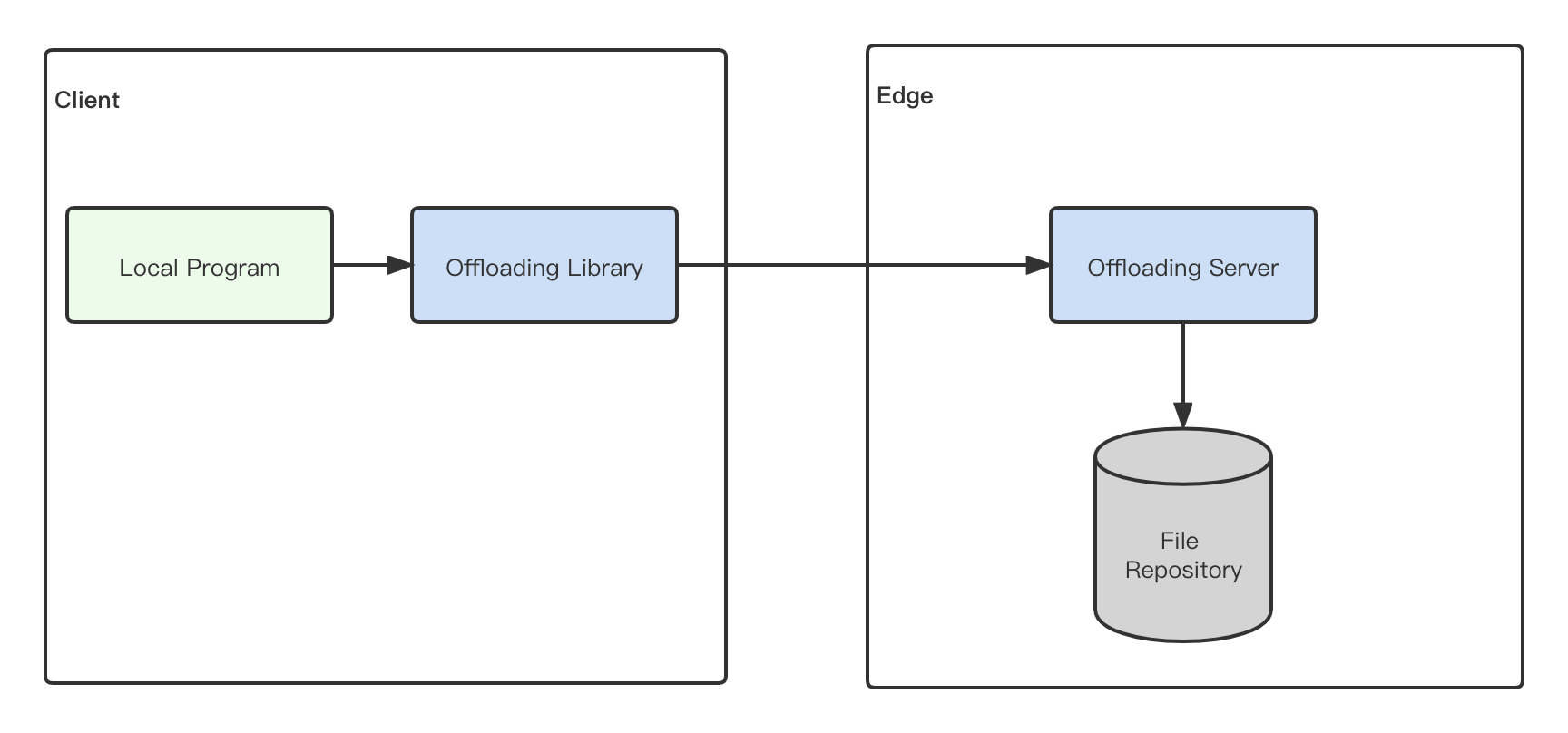
Fetching code from file repositories In this approach, the client leverages a user-defined offloading library to send proper parameters to the Edge Resource. The Edge Resource will then fetch the specified code from repositories and then execute the code.
The downside of this approach is that additional file repositories are needed and the developers have to upload the code to the repository and make sure the local and the Edge have the same version of the code.
Meanwhile, since the offloading library plays an important role in offloading, developers need to create a robust offloading policy to discover and connect with Edge Resources, decide which parts of the code can be offloaded, and the time to offload. This will put more strain on the developer and affect the overall programming experience and the productivity.
Conclusion
The two approaches discussed above are mostly similar. The main difference is the way code is sent to the edge. However, in addition to the downsides mentioned, some common issues or pain points still remain and need to be addressed.
- Discrepancies between the client runtime and the Edge runtime may cause failures, as well as differences in the runtime between one Edge Resource and another. So a unified runtime needs to be considered. A WebAssembly runtime may be a good choice.
- Capabilities for discovering and connecting with Edge Resources are needed.
- Some parts of the code might be sensitive, and the developer might not want it to be sent over the internet. Capabilities for developers to configure which parts can be offloaded are needed.
- When certain conditions are met, such as if there is no Edge Resource in proximity to the user or the internet is lost, code should be executed locally instead of offloaded. That is to say, the developer will need to know what might be offloaded to a server but does not need to decide or care about when it is offloaded.
- Security and privacy are important, so secure communication mechanisms are needed.
There is no W3C standard currently available to address the above gaps. To achieve interoperability between different vendors, standardization is needed.
Requirements
General Requirements
The following are a set of high-level requirements, cross-referenced with related use cases.
| Name | Description | Use Cases |
|---|---|---|
| Performance | The overall performance of an application using offload, as measured by user responsiveness or time to completion of computational work as appropriate, should be improved. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Scalability | Efficient implementation in a virtualized cluster environment (i.e., a Cloud system) should be achievable. |
UC-CA UC-CG UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR |
| Flexibility | The solution should allow a variety of Edge Resources from different providers to be used. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Compatibility | The proposed standards should be as consistent as possible with existing web standards to maximize adoption. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR |
| Resiliency | The solution should allow adaptation to changing circumstances such as changes in relative performance, network connectivity, or failure of a remote Computing Resource. |
UC-CA UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-LVB UC-ALPR |
| Security | The standards should be consistent with existing security expectations for web applications. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Privacy | The standards should be consistent with existing privacy expectations for web applications or provide enhanced privacy. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Control | The use of resources should ultimately be under the control of the entity responsible for paying for their use. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
Detailed Requirements
Some more detailed requirements are listed below, cross-referenced with related use cases and related high-level requirements.
| General Requirements | Name | Description | Use Cases |
|---|---|---|---|
| Performance | R1: Client Offload | Clients should be able to offload computing intensive work to an Edge Resource. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Resiliency | R2a: Application-Directed Migration | The application should be able to explicitly manage migration of work between Computing Resources. This may include temporarily running a workload on multiple Computing Resources to hide transfer latency. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Resiliency | R2b: Live Migration | The Edge Cloud should be able to transparently migrate live (running) work between Computing Resources. This includes between Edge Resources, Cloud Resources, and back to the client, as necessary. If the workload is stateful, this includes state capture and transfer. |
UC-CA UC-VR UC-VC |
| Flexibility | R3: Discovery | A client should be able to dynamically enumerate available Edge Resources. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Flexibility | R4: Selection | A client should be able to select between available resources, including making a decision about whether offload is appropriate (e.g., running on the client may be the best choice). This selection may be automatic or application-directed, and may require metadata or measurements of the performance and latency of Edge Resources, and may be static or dynamic. To do: perhaps break variants down into separate sub-requirements. Also, it needs to be clear about how this is different from the out-of-scope issue "Offload policy". |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Flexibility | R5: Packaging | A workload should be packaged so it can be executed on a variety of Edge Resources. This means either platform independence OR a means to negotiate which workloads can run where. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Flexibility | R6: Persistence | It should be possible for a workload to be run "in the background", possibly event-driven, even if the client is not active. This also implies lifetime management (cleaning up workloads under some conditions, such as if the client has not connected for a certain amount of time, etc.) |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Security, Privacy | R7: Confidentiality and Integrity | The client should be able to control and protect the data used by an offloaded workload. Note: this may result in constraints upon the selection of offload targets, but it also means data needs to be protected in transit, at rest, etc. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Control | R8: Resource Management. | The client should be able to control the use of resources by an offloaded workload on a per-application basis. Note: If an Edge Resource has a usage charge, for example, a client may want to set quotas on offload, and some applications may need more resources than others. This may also require a negotiation, e.g., a workload may have minimum requirements, making offload mandatory on limited clients. This is partially about QoS as it relates to performance (making sure a minimum amount of resources is available) but is also about controlling charges (so a web app does not abuse the edge resources paid for by a client). |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Scalability | R9: Statelessness | It should be possible to identify workloads that are stateless so they can be run in a more scalable manner, using FaaS cloud mechanisms. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Compatibility | R10: Stateful | It should be possible to run stateful workloads, to be compatible with existing client-side programming model expectations. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Performance | R11: Parallelism | It should be possible to run multiple workloads in parallel and/or express parallelism within a single workload. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Performance | R12: Asynchronous | The API for communicating with a running workload should be non-blocking (asynchronous) to hide the latency of remote communication and allow the main (user interface) thread to run in parallel with the workload (even if the workload is being run on the client). |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Security | R13: Sandboxing | A workload should be specified and packaged in such a way that it can be run in a sandboxed environment and its access to resources can be managed. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
| Performance, Compatibility | R14: Acceleration | A workload should have (managed) access to accelerated computing resources when appropriate, such as AI accelerators. Note: Since the availability of these resources may vary between Computing Resources these need to be taken into account when estimating performance and selecting a Computing Resource to use for offload. Access to such resources should use web standards, e.g., standard WASM/WASI APIs. |
UC-CA UC-VR UC-CG UC-SA UC-VC UC-MLA UC-IVPU UC-PWMP UC-BR UC-LVB UC-ALPR UC-RNA UC-CM |
Architecture Proposals
This document proposes some different possible architectures to address the needs identified above.
Seamless code sharing across client/edge/cloud
This architecture allows the client, Edge, and the Central Cloud to share a common code running environment which allows the task running in either client, edge, cloud or both in a coordinated way.
The proposed high level architectures is shown in the following figure:
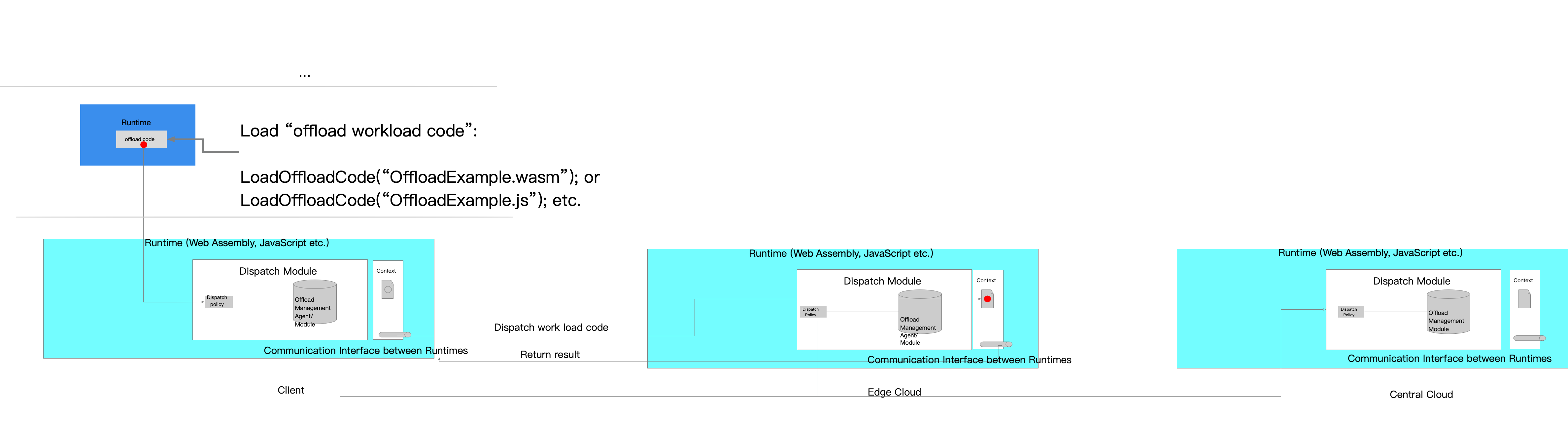
In this architecture, the code of the workload in the client side could be offloaded to the Edge Cloud and can also be handed to the Central Cloud and handed back to client. The high-level procedure is as follows:
- The client side application encapsulates offloaded workload code into an offloaded code module and loads the code module using specific APIs for the runtime environment. There may be different types of runtime environment, for example, WebAssembly or JavaScript runtimes. The offloaded workload will be written according to the specific runtime.
- The client's runtime dispatch policy module queries the dispatch policy from the Offload Management Module which is located in the Edge Cloud or the Central Cloud.
- The Offload Management Module sends a dispatch policy to the client side application.
- The client side runtime sends the offloaded code to the target Edge Cloud/Central Cloud according to the dispatch policy.
- The target Edge Cloud/Central Cloud executes the offloaded workload and returns the result to the client application.
- If offloading is not feasible in certain conditions, for example, if the network connection between the client and Edge Cloud is not stable or there are not enough resources in the Edge Cloud, the offloaded workload should handover back to the client side to ensure the availability of the client application.
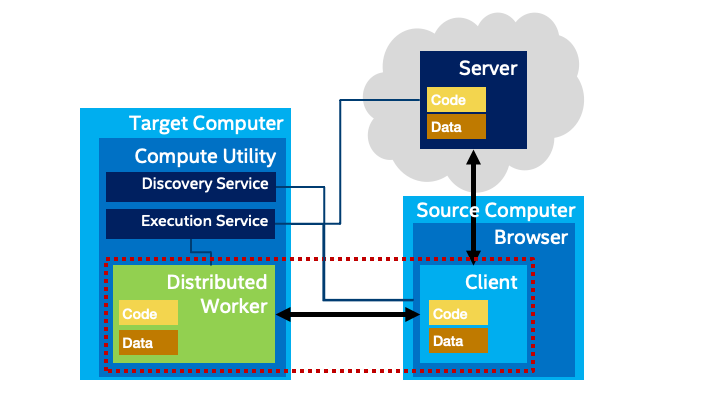
Distributed Workers
The Web already has a set of standards for managing additional threads of computation managed by application code loaded into the browser: Web and Service Workers. Workers already support a message-passing style of communication which would allow them to execute remotely. This architectural option proposes extending Workers to support edge computing as follows:
- Compute Utility services would be made available on the network that could provide a capability to execute Worker payloads. For fallback purposes, the client itself would also offer a Compute Utility to support local execution when needed. It would also be possible for the origin (the server) to host a Compute Utility. However, in general Compute Utilities could be hosted at other locations, including in desktops on the LAN, within a local cloud, or within edge infrastructure.
- Application developers would continue to use existing APIs for Workers, but could optionally provide metadata about performance and memory requirements which could be used to select an appropriate execution target.
- Browsers would collect metadata about available Compute Utility services, including latency and performance, and would select an appropriate target for each Worker. The user would have controls in the browser to control this rule, including the ability to specify specific offload targets or to force local execution when appropriate. Note: the reason it is suggested that the browser makes the decision and not the application is to prevent fingerprinting and associated privacy risks. Metadata about available Compute Utilities might otherwise be used to infer location. The proposed architecture hides this information by default from the application while still supporting intelligent selection of offload targets.
- Once a Compute Utility is selected, the browser would automatically (transparent to the application) use the network API of the Compute Utility to load and execute the workload for the Worker. Note that in the existing Worker API, a URL of a JavaScript workload is provided to the Worker.
- The Compute Utility itself would be responsible for downloading the workload, it would not have to be downloaded to the browser and then uploaded. Also, a WASM workload could be used, bootstrapping from the standard JavaScript workload. In general, the workload execution environment should be the same as the normal Worker execution environment. However, access to accelerators to support performance and other advanced capabilities will become more important in this context.
The proposed high level architecture is shown in the following figure. The browser discovers Compute Utilities using a Discovery mechanism. Discovery services in each discovered Compute Utility return metadata, which then allows the selection of a Compute Utility for each workload. A Workload Management service is then used to load and run a packaged workload for the worker.
Standardization Proposals
WebAssembly as unified runtime
This proposal proposes to extend the WebAssembly runtime and use it in both client side and Edge Cloud as a unified runtime.
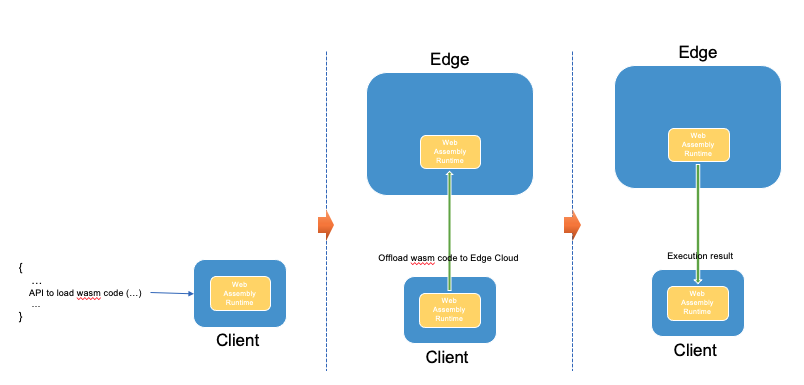
The proposed solution includes the following parts:
- Load WASM code
-
The client loads the WebAssembly code by invoking a standard API. This API should indicate that the WASM code could be offloaded to Edge cloud when certain conditions are met. This API should also set the destination Edge cloud's location identifier.
- Offload WASM code to Edge Cloud
-
The client side's WebAssembly runtime executes the WASM code and when certain conditions are met, it offloads the WASM code to the Edge cloud.
- Run WASM code on Edge cloud
-
The WASM code runs on the Edge cloud, and return the result back to the client side.
- Dispatch back to the client
-
When certain conditions are met, the WASM code is dispatched back to the client side and continue to run.
Potential Standards
- JavaScript API to specify workloads:
- This JavaScript API is to be used by a web application to specify a workload. It indicates this workload may be offloaded to the edge cloud when certain conditions are met. The standardization of this API is required since different implementations should implement this API in the same way to make sure that application developers have the same user experience.
- Communication mechanism and protocol between client and Edge Cloud:
- The communication mechanism, the communication protocol, and the interface (network API) between the client side and the Edge cloud should be standardized to enable the interoperability of different Edge Cloud providers.
- Edge Cloud availability and network condition discovery:
- The workload should only be offloaded when certain conditions are met. These condition may include Edge Cloud availability and network conditions.
Out of Scope
The following topics will be out of scope of standardization work:
- Offloading policy:
- This proposal recommends that the offloading policy is not standardized to allow flexible implementation by different vendors.
Conclusion & Recommendations for the Way Forward
As analyzed in the gap analysis section and in the potential standards section, the proposed potential standards work is to specify a standardized common mechanism to offload code to the Edge Cloud. There may be multiple potential solutions and some of them may be related to WebAssembly and some may be related to web platform APIs.
The proposed next step is to continue exploratory work on potential architecture and standardization proposals by forming a W3C Community Group, which would allow collaboration on solution designs.
This Community Group could firstly develop a standard solution architecture. If the standard solution architecture requires extension of current W3C standards, it would work together with related Working Groups (for example, WebAssembly Working Group, etc.) to develop the extensions.
If new W3C standards are needed, after developing specifications in the Community Group, the Community Group could propose creating a Working Group for standardization.
Contributors
Feiwei Lei, Alibaba Group
Jingyu Yang, Alibaba Group
Wenming Wang, ByteDance
Dian Peng, ByteDance
Lei Zhao, China Mobile