The language enablement work of the W3C involves documenting gaps in Web support for users of a given language or script, and then requesting that those gaps be addressed by spec developers or browser implementers.
This page describes practical steps for editing a gap-analysis document starting from a standard template.
How to Document a Gap: Quick summary
- Identify the Right Repository
Each script or language group has its own GitHub repository under the W3C organization. For example:
- Tibetan: w3c/tlreq
- N’Ko: w3c/afrlreq
- Arabic: w3c/alreq
You can find the full list of repositories on the Language Enablement page.
- Open a GitHub Issue
Once in the right repo:
- Click Issues > New Issue > Add a new gap analysis topic
- Follow the instructions in the gap-analysis issue template.
- Provide:
- A clear title (e.g., “Incorrect vowel positioning in Tibetan stacked syllables”).
- A description of the problem.
- Screenshots or test cases if possible.
- Information about which browsers or specs are affected.
- Any local expectations or typographic norms.
- Label and Track the Gap
Contact the maintainers. They will:
- Label the issue (e.g., gap, css, html, tlreq). This automatically adds the issue to the Gap Analysis document.
- Publish an update to the Gap Analysis document.
- Add the gap report to the Gap Analysis Pipeline—a dashboard that tracks the status of all known gaps.
- Follow Up
- Join the relevant mailing list (e.g., public-i18n-tibetan@w3.org) to receive digests of updates.
- Participate in discussions or provide clarifications as needed.
- Optionally, contribute to the gap analysis document or layout requirements if you have deeper expertise.
- Tips for Effective Contributions
- Focus on describing the problem, not proposing solutions.
- Use real-world examples from books, signage, or native apps.
- Be specific about pain points for users or content creators.
The gap-analysis pipeline
The gap-analysis pipeline allows us to track progress of the gaps that have been documented.
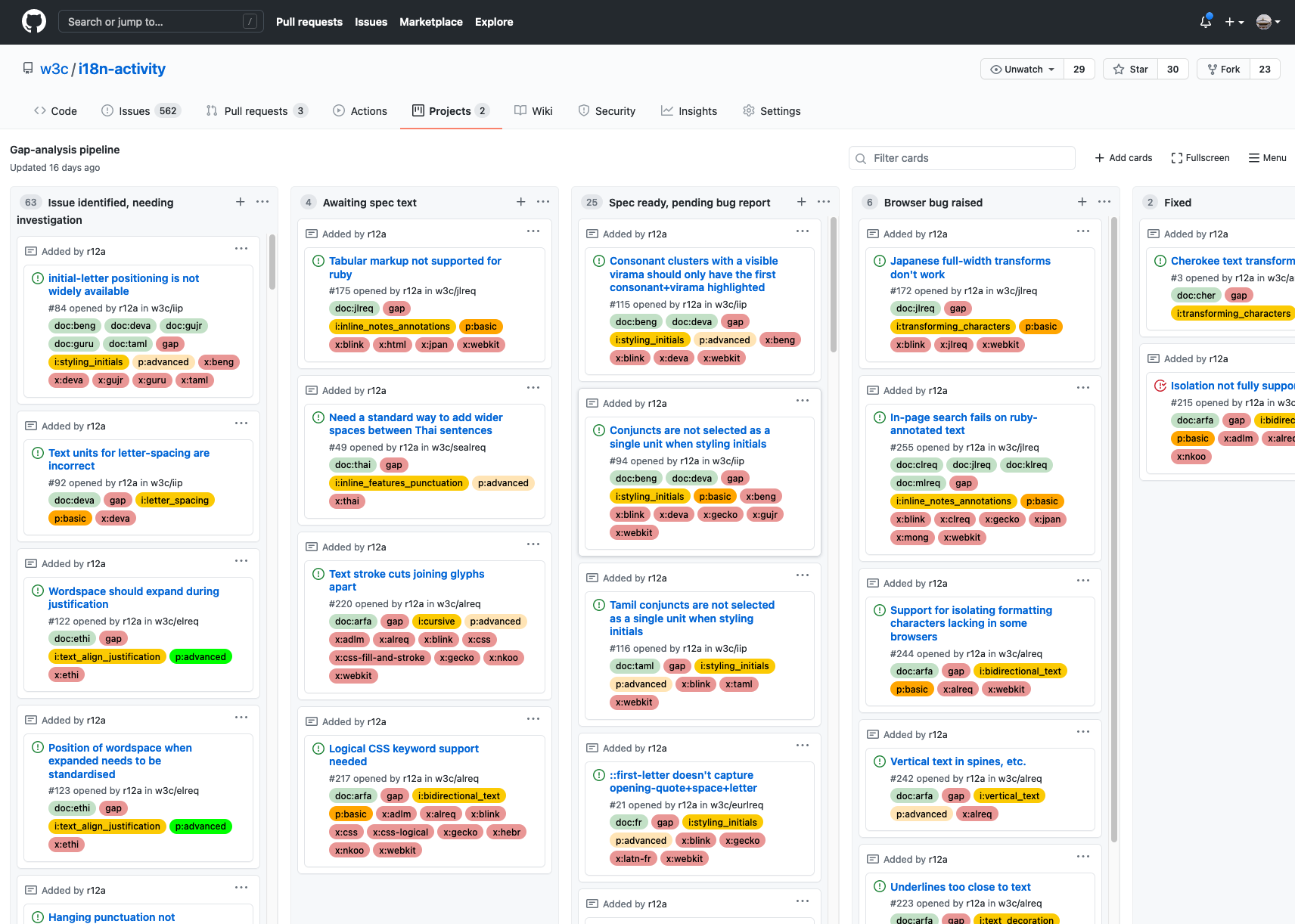
The pipeline contains only one card per gap, but labels indicate all the gap-analysis documents where that gap is relevant.
Other labels can be used to filter the information shown. For example, it is possible to show just the issues needing attention by a particular browser engine, and then to further filter that information to show only those items with a priority of 'basic'. If a browser or spec bug is fixed, the relevant label is removed so that the pipeline constantly shows the current status.
Other labels allow you to find all gaps related to a particular feature, such as letter-spacing, or justification, or all issues with a given priority.
The columns indicate what needs to happen next for a particular gap.
Cards in the left-most column need additional research and/or clearer documentation before they can move to one of the other columns.
The aim is to move all cards into the right-hand column ('Fixed').
Describing a gap
The HTML template
A standard template is used for the gap-analysis documents of all groups. It is an HTML document. See, for example, the Bengali gap-analysis document.
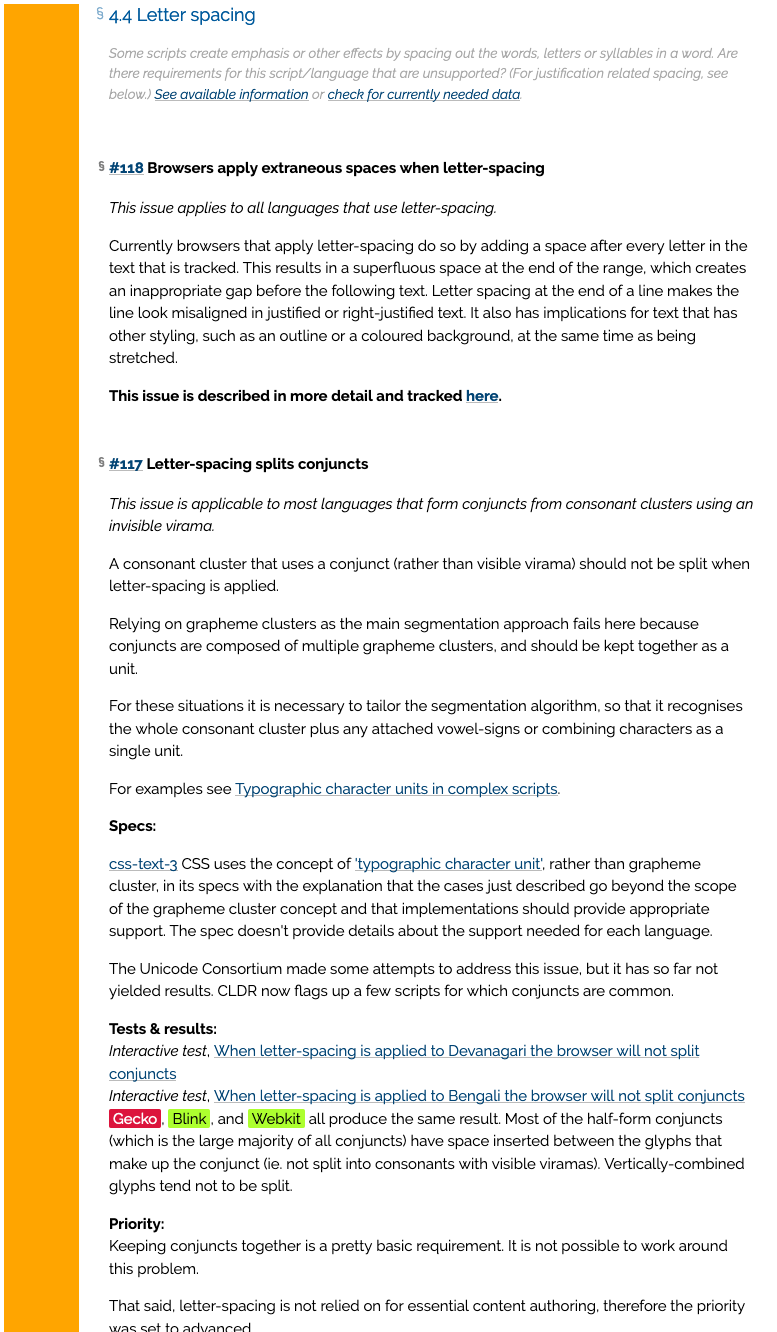
The first 3 levels of headings in a gap-analysis document are fixed. They conform to a standardised set of categories that are used throughout the language enablement framework. This makes tooling work, simplifies links, and provides a useful harmonisation of approach across all the groups working on language enablement.
The paragraph in the HTML document immediately after the section title is intended to give you ideas about what you should write about. It is not an exhaustive list, by any means. You should leave that text in place. The links it contains may give you additional ideas of things to describe here – they link to currently outstanding questions or spec/browser bugs relating to this topic.
GitHub issues
The main content of the document is contained in small topic sections. These are authored in GitHub issues – one issue per topic, in the issue list of the group's repository. Here's an example of an issue.
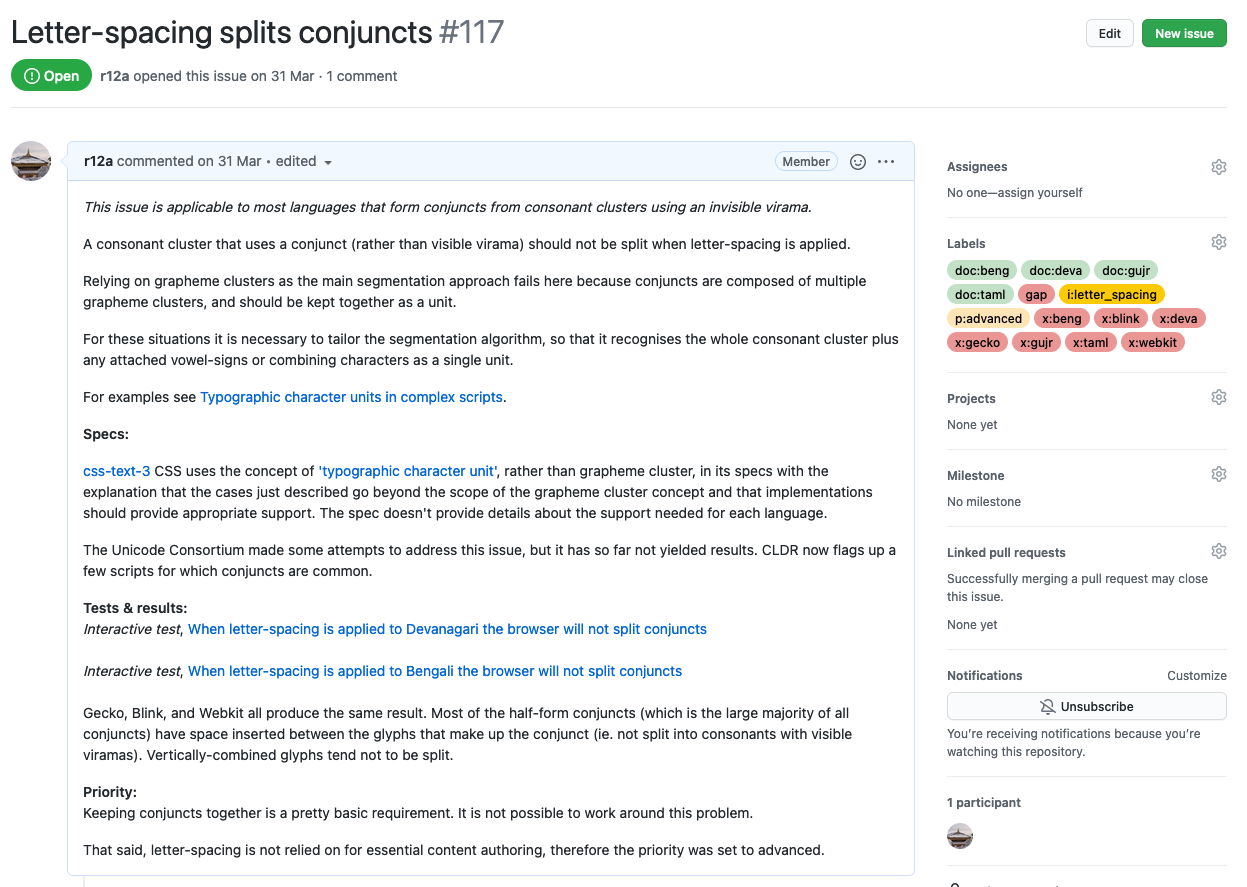
The content is added to the first comment field in the issue list, and some standard boilerplate text is added to the second. Only the content of the first comment field will appear in the gap-analysis document.
People can create additional comments below the first two to suggest or contribute changes. Changes to the content are made by editing the first comment (those changes can be inspected using the available pulldown in the comment header).
The content of the first comment should closely follow the structure that is suggested when you create a new issue. This includes the following:
- (intro) how the feature is supposed to work. Point to the requirements document or similar for additional information.
- The Gap: how the feature is broken for users (ie. what can't they do). This should summarise the results of any tests. Also point to any relevant discussions in the issue list of the repo.
- Priority: an explanation of why you assigned the priority you did.
- Tests: links to tests or screen snaps that show the feature failing, and, where useful, a summary of the results of those tests. The summary can be copied from the GH issue that records the test results (ie. the list of browser engine data), if appropriate.
- Spec status: pointers to the CSS or other W3C specs that relate to this feature, with descriptions of whether a sollution to the gap is mentioned or not.
- Action taken: links to any browser or other bug reports that have been raised.
- Outcomes: a description of any fixes or developments.
If describing gaps that affect more than one language in the same document, and there is a difference in the level of support, make it clear which language is relevant to the text.
See also the section about what to do when the same gap is relevant to more than one gap-analysis document.
Special features
Images. When an issue is incorporated into the editor's draft some transformations are applied automatically. These generally mean that it is easier for you to type stuff in the issue.
If you want to include an image in your gap report, follow these steps:
- drag the image into the issue while editing. This will add the image to GH and will show some markdown or some markup.
- copy the image to the relevant language enablement repo and install it at <gap_analysis_file_location>/images/.
- set the filename of the image in the /images folder to be the same as the alphanumeric sequence after the final slash in the location indicated by GitHub. It is also a good idea to add the extension (which won't be in the GH issue), especially if this is an SVG file.
You should not point out to an image elsewhere on the Web, because all images need to be located locally when you publish the page.
If your image is represented in the GH issue using HTML markup, you can change the alt and width/height attribute values, and those will be captured in the document. Other attribute values won't be.
Headings As shown in the template, the subheadings inside the issue comment should follow ###. There should always be 3 # signs. The headings will be wrapped in h5 markup in the editor's draft.
GitHub issue labels
Some labels are applied automatically by the issue template. Others are applied by the maintainers. Gap report descriptions in GitHub issues are automatically pulled into the HTML document if the right labels have been applied to that issue. (Refresh the HTML page of the editor's draft and you should see the change immediately.) Labels are also used for filtering in the gap-analysis pipeline. The required labels are:
- the label gap. Only issues with this label are parsed for inclusion in the gap-analysis doc.
- a label beginning with doc: (eg. doc:beng for the Bengali gap-analysis doc). Even if the group has only one gap-analysis doc, such as for the Chinese and Japanese groups, this label should be applied (ie. doc:clreq or doc:jlreq, respectively). There can be more than one of these labels, if the gap applies to more than one gap-analysis document in the same repo.
- one or more labels beginning with i: (for 'index'). These labels indicate which section(s) the item will be placed in (eg. eg. i:letter_spacing), so there is a defined set of possibilities. It's fine to have more than one such label, if you think the topic is equally applicable to more than one section.
- a label beginning with p:, to indicate the priority for that issue. Each of these labels has a different colour. The usual possibilities are: p:basic, p:advanced, or, rarely, p:broken. If an issue has been fixed, or the text is describing the fact that there is no problem, you can use the label p:ok.
- labels to indicate where work is needed to address the issue. These labels all begin with x:. If work is required on a spec, the label will include the short-name for that spec, eg. x:css-text. If a browser bug has been raised, add the name of the browser engine, eg. this will typically be one of x:blink, x:gecko, or x:webkit. If the required fix has been provided, these labels should be removed. That way it is possible to filter the issues in the gap analysis pipeline to see what currently needs attention for a given spec or browser.
- labels to indicate the languages and scripts applicable for this gap report. Language labels begin with l:, followed by the BCP47 language tag (eg. l:lo for Lao). Script labels begin with s:, followed by the ISO script tag (eg. s:laoo for Lao).
When the same gap belongs in several documents
In some cases, the same gap is relevant to many languages and can be reported in a number of gap-analysis documents. We try to avoid repeating all the detailed information in more than one place by adopting one of 2 strategies.
In some cases, a problem may have aspects that are slightly different from language to language. In this case you may need to create more than one GitHub issue. If you do, indicate in the title of the issue which language/script this relates to.
If the same gap applies to multiple documents in the same repository (eg. a letter-spacing issue that applies to Bengali, Devanagari, Gujarati, and Tamil documents, which are all stored in the same indic repository) simply record the information once, with language-specific examples if needed, and apply two or more doc: labels.
If the same gap applies to multiple documents across different repositories (eg. incorrect application of quotation marks, which affects most documents regardless of the repo where the gap-analysis documents are stored), then choose one repository where you will create a GitHub issue with all the details about tests, spec and browser support. This is the issue that will be tracked in the gap-analysis pipeline.
In the other repositories create a 'stub issue' with the same title that gives a brief introduction to the problem at hand, and optionally contains examples or tests relevant to the language(s) of that repo, but points the reader to the details you are maintaining in the other repo. To do this, after the introduction you should include something along the lines of:
“For more details, see [this GitHub issue], which is being used to track this gap. Please add any discussion there, and not to this issue.”
with a link to the detailed issue. Here's an example.
Adding a priority
When the HTML file pulls in the topics, it automatically works out a priority to assign to a section containing multiple topics. If several topics in the same section have different priorities assigned to them, the lowest denominator wins. The possibilities are:
okna(not applicable)advanced(needs work for advanced level support)basic(needs work for basic styling support)broken(basic display issues that prevent effective use of this language on the Web)
The priority chosen will affect the colour of the block alongside the section, and add some summary text at the end of the section.
Note that this priority labelling is NOT about how badly broken the feature is – it's about how the lack of the feature affects the use of the Web in this language.
Basic styling is the level that would be generally accepted as sufficient for most Web pages. Advanced level support would include additional features one might expect to include in ebooks or other advanced typographic formats. There may be features of a script or language that are not supported on the Web, but that are not generally regarded as necessary (usually archaic or obscure features). In this case, the feature can be described here, but the status should be marked as ok.
The decision as to what priority level is assigned to a described gap is down to the experts doing the gap analysis. It may not always be straightforward to decide.
A section can be scored as ok if the feature in question is specified in an appropriate specification, and is supported by user agents. A specification that is in CR or later and has two implementations in 'major' browsers will count. This means that the feature may not be supported in all browsers yet. (At some point in the future we may try to distinguish, visually, whether support is available in a specification but still pending in major browsers or applications.) On the other hand, you may feel it's important to have more than two major browsers supporting the feature, in which case you can assign a problem status.
If a section is given a class of ok or na you can leave the description blank, or you can add explanatory text. Whatever you prefer. It is possible to create such content in GitHub issues, or the staff contact or group editor may prefer to quickly change the HTML directly for these sections.
Referring to tests
The language enablement framework provides instructions for how to create two types of test. The exploratory/interactive format is most likely to be used for gap-analysis work. You can read how to create tests by following the links from the page Writing i18n tests. The gap analysis doc should summarise the detailed results indicated for the tests it refers to.