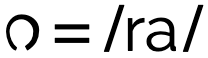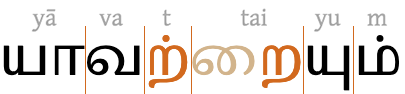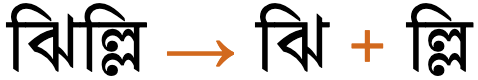The basic unit of text is not always a Unicode code point when it comes to text operations such as the following:
line breaking & hyphenation
letter spacing & justification
cursor movement
forward delete
dropped initials
vertical text
truncation
CSS defines the typographic character unit as a basic unit of text for use with these editing operations, however the meaning of that term can vary according to the operation, and there are issues in working with such units in complex scripts. In this article we look at examples of some of those differences and issues.
Inherent vowels, conjuncts & vowel-killers
In this section we set the scene by describing how most Brahmi-derived scripts work.
Inherent vowels & vowel-signs
Writing systems that derive from the former Brahmi script, whether in India or other parts of Asia, tend to automatically associate an inherent vowel sound with each consonant. The specific sound varies with the language, and for some orthographies there can be different sounds in different contexts.
The glyph used for the consonant 'r' in Malayalam has an inherent 'a' vowel, built in. View characters.
To express a vowel other than the inherent one, you add a vowel-sign to the consonant. For most South Asian scripts, this involves a single combining character, but other languages may use multiple combining characters, or mixtures of combining and ordinary spacing characters. Vowel-signs may appear above, below or on either side of the base, or may be a single character that produces separate glyphs on more than one side of the base consonant (a circumgraph) .
A writing system with inherent vowels that are modified by the use of vowel-signs is often referred to as an 'abugida'.
Vowel-signs (coloured) changing the sound /ka/ into /ku/, /ko/, and /kaːi/ in Balinese. View characters.
Consonant clusters & conjunct forms
The languages that use these scripts also have consonant clusters. There are a number of ways of indicating that the vowel is not pronounced between the consonants that make up a cluster. The shape of the clustered consonants may, for example, be merged, or one consonant may be stacked above the other, and so on. When the shapes of a sequence of consonants are changed to indicate a cluster, this is referred to as a conjunct.
Conjunct formation is usually triggered in Unicode text by adding a combining character, the vowel-killer, after each consonant that loses its vowel. When the vowel-killer causes a conjunct to form, it becomes invisible. In the following figure, the second syllable of the word 'shakti' in computer memory is the sequence of characters KA+vowel_killer+TA+I.
The Hindi word 'shakati' (left) which has no clusters, and the word 'shakti' (right) where the second orthographic syllable is a conjunct cluster. Colours are used to highlight consonants (orange) and the (prescript) 'i' vowel (tan). Typographic unit boundaries are shown by thin vertical lines. View characters.
The vowel-killer is generically referred to as a virama, although each language has its own name, such as halant, hasant, pulli, viramamu, etc. Each script in Unicode that uses a vowel-killer has its own code point for that character.
The important rule is that conjuncts are never normally split apart by operations such as line breaking & hyphenation, letter spacing & justification, cursor movement, forward delete, highlighted initial paragraph letters, vertical text, and truncation.
This also affects placement of vowel-signs. As can be seen in the Hindi example above, the left-positioned vowel-sign is therefore placed to the left of the whole cluster, even though it is pronounced after the last consonant in the group.
Note that forwards and backwards deletion will typically each delete different numbers of characters per keypress, and backwards deletion may break down conjuncts when forward deletion does not. Also, we will see later that vowel-signs may be split apart from the conjunct during justification or letter-spacing, however the conjunct itself still resists decomposition in this case.
Because of this resistance to breaking conjuncts, Brahmi-derived orthographies are typically parsed into orthographic syllables. These differ from phonetic syllables, because they include a whole consonant cluster and any combining characters that follow it as a single unit.
The Hindi word 'hindi', showing the 2 orthographic syllables, 'hi' and 'ndi'. View characters.
The word 'hindi', just above, is split into two orthographic syllables, 'hi' and 'ndi', although the phonetic syllables are 'hin' and 'di'.
Clusters with a visible vowel-killer
Rather than forming a conjunct, sometimes consonant clusters are indicated by the presence of a visible vowel-killer alongside the relevant consonant(s). In this case, no shape changes are produced. This is, in fact, the default approach for Tamil.
The Tamil word 'yavattaiyum', showing the 2 geminated consonants (orange) with a vowel-killer dot above the first, and a prescript vowel (tan). Typographic unit boundaries are shown by thin vertical lines. View characters.
Where a visible vowel-killer is used, it is possible to split apart the consonants that make up a cluster while breaking lines, spacing text, etc.
The handling of left-positioned vowel-signs is also different from the case where conjuncts are produced. In Tamil, the left-positioned vowel-sign does push apart the consonants that make up the cluster, as can be seen in the figure.
In Unicode text the same code point is generally used for both the invisible conjunct-former and the visible vowel-killer, and the different display effects are produced by font rules.
The messy bits
Unfortunately, consonant cluster handling is not quite as clear-cut as implied above. Orthographies don't always indicate a consonant cluster using a conjunct or a vowel-killer.
For example, as a general rule Hindi doesn't pronounce a vowel after the penultimate consonant in a word if there is a vowel-sign at the end. However, It doesn't indicate the vowel absence by a conjunct or vowel-killer.
In other orthographies, such as commonly in Gujarati and Bengali, there is often no indication of where consonant clusters appear. You simply have to know how to pronounce the word.
Segmentation for the Gujarati word 'ɡarkəm', where the 'rk' cluster is not signalled by any vowel-killer or conjunct. Nor is the missing inherent vowel of the final 'm'. View characters.
These differences, however, don't normally cause problems for text segmentation. A sequence of consonant glyphs that is actually a cluster, but which is not connected visually is treated as so many separate typographic character units, and can be handled using grapheme clusters (see below).
Problems with conjuncts
Now we examine some of the problems encountered when dealing with conjunct forms.
Grapheme clusters
In order to approximate user-perceived character units for editing operations, Unicode uses a set of generalised rules to define grapheme clusters – sequences of adjacent code points that can be treated as a unit by applications.
Typically, a grapheme cluster is a single base character plus any combining characters that follow it. A single alphabetic character like e [U+0065 LATIN SMALL LETTER E] is a grapheme cluster, but so also is ề [U+0065 LATIN SMALL LETTER E + U+0302 COMBINING CIRCUMFLEX ACCENT + U+0300 COMBINING GRAVE ACCENT].
Grapheme clusters need to span conjuncts
The figure just below shows how the Bengali word 'jhilli' is split into its two orthographic syllables, 'ji' and 'lli'. The second orthographic syllable is a conjunct, representing a doubled 'l' sound followed by the sound 'i'.
The Bengali word 'jhilli', showing the 2 orthographic syllables, 'jhi' and 'lli'. View characters.
The code points in that word are shown in fig_jhilli_codepoints, with dotted lines to indicate where grapheme cluster boundaries fell before Unicode version 15.1:
Code points that make up the Bengali word 'jhilli'.
The green (upper) line separates two orthographic syllables; but the second orthographic syllable (the conjunct) was also divided into two grapheme clusters at the red (lower) line (ie. after the virama). This is inappropriate, since the conjunct should not be split.
Unicode version 15.1 introduced some new rules, on a per script basis, to address this problem. Grapheme clusters were extended so that they are not terminated by a virama for Bengali, Devanagari, Gujarati, Oriya, Telugu, and Malayalam. However, the problem remains for several other scripts.
This means that for scripts of this type that are still waiting for the new grapheme cluster rules to be added to the Unicode Standard, additional tailoring rules needed to be applied, over and above the default grapheme cluster segmentation, in order to identify appropriate text boundaries, ie. treating the whole orthographic syllable as a unit.
Font-dependent segmentation
Some applications successfully apply tailoring rules to treat conjunct clusters as unbreakable units, providing a way to address the problem just mentioned. There is, however, an additional problem which is somewhat less tractable.
In a nutshell, if the vowel-killer is hidden, CvCV should be treated as an unbreakable unit, and if the vowel-killer is visible it should be treated as two separate segments (Cv and CV).
What's problematic about this is that
there is no difference whatsoever in the underlying code point sequence, and yet the segmentation behaviour has to be different. The only clue as to how to segment this sequence comes in the visually rendered shapes
.
Currently, browsers are unable to distinguish between consonant clusters that should be handled as a single unit, and those that should not.
This causes a problem for a script such as Tamil, which almost always uses the visible vowel-killer (pulli) to indicate consonant clusters, but has two clusters for which the same vowel-killer code point produces conjuncts ('ksh' and 'shri'). Normally, Tamil consonant clusters can be split into multiple text units, but not those which are conjuncts. It is therefore necessary to apply different rules, according to the specific letters occuring in the syllable.
The Unicode Standard recognises 3 types of vowel-killer. Pure_Killer types are always rendered visibly and don’t cause conjunct formation. They are generally not a problem for segmentation. Invisible_Stacker types always cause conjunct formation, and should never be rendered visibly. Breaking between such viramas and subsequent consonants is always wrong, but unfortunately that’s what applying grapheme cluster rules does. Virama types are sometimes rendered visibly in a way that breaking after them would be fine, and sometimes they participate in conjunct formation, so that breaking after them causes problems. These are particularly problematic, for the reasons described here.
But the problem is wider than this. It is possible that, for the exact same sequence of characters, one font has the glyphs needed for a particular conjunct, but another doesn't. In the latter case, the font will generally show the vowel-killer explicitly to indicate the absence of the intervening vowel.
Here, for example, is a rendering of the Bengali word in fig_jhilli_codepoints without the conjunct formation.
The Bengali word 'jhilli' without conjunct formation. The highlighted items are the visible vowel-killer (left) and the letter 'i' (right). Typographic unit boundaries are shown by thin vertical lines.
Note, in particular, that the prescript vowel sign ('i') now appears between the two 'l' letters. It doesn't appear to the left of the whole cluster any more. A crucial difference between this and what we saw before is that we now have three segments in the word: 'jhi' + 'l' + 'li', and text can be split at any of these grapheme cluster boundaries.
However, because it is impossible to tell the difference between the two different rendered outcomes by looking at the code points, unless some way is found to detect the shape of the actual rendered text it is not possible to always apply the correct segmentation in the face of such variations. The new grapheme cluster rules for Bengali grapheme clusters will keep the sequence 'lli' together, as a single segment, whereas the previous rules would have actually created the split we need here. On balance, however, keeping this sequence together is likely to be less problematic than splitting conjuncts apart when the virama is invisible.
If an author wants to force the virama to be visible, they can follow it with a zero-width non-joiner format character. That will then result in the three segments for the word 'jhilli' seen in fig_jhilli_virama, when split into grapheme clusters.
Segmentation that splits glyphs
The figure just below shows a news column where the second line is a single word. The word is so long that there is no room to add another word to the line. To maintain the justified line ends, the word has been stretched to fit by inserting equal amounts of space between each grapheme cluster.
A line containing a single Thai word applies inter-grapheme spacing to justify the text.
Combining characters above and below base characters are kept with the base, but space is added between any spacing vowel-signs and the base consonant. This is mostly straightforward in Thai because, unlike South Asian scripts, most vowel-signs are ordinary spacing characters, and therefore grapheme-clusters.
One particular combination, however, needs some extra attention. The sequence shown at the left of the figure just below has to be broken down into one base character and two combining marks, and then the spacing needs to be applied before the second mark.
When letters are spaced, SARA AM needs to be recomposed, and the space inserted between the two new components. View characters.
Apart from the extra work required to recompose the vowel-signs, notice that the space is now inserted between two combining marks, ie. the first item is a grapheme cluster but the second is a code point.
Tamil and other writing systems take this a step further, particularly in relation to text justification and letter-spacing.
Tamil has many very long words, and in Tamil news columns it may not be possible to fit more than a single word on a line. In such cases it is common to, again, stretch the word to fit the whole width of the line. However, to do so, equal space is added between each non-connected glyph across the line, regardless of whether a glyph is a grapheme cluster, or even a single code point.
An example from a news column of a single word stretched to the line width (middle line).
As for the Thai example, the space is inserted evenly between the unconnected glyphs.
Tamil glyph separation. The vowel-signs are coloured, and on the top line the grapheme-cluster boundaries are shown with thin vertical lines. The first vowel-sign is a circumgraph (ie. a single code point that renders glyphs on more than one side of the base). The bottom line shows how this word would be expanded to fill a line. View characters.
In fig_partridge, the last grapheme cluster (on the right) is kept intact, because the vowel-sign is joined to the base consonant.
To its immediate left, the base character and combining mark that make up the middle syllable have been split apart, so the units are codepoints rather than grapheme clusters.
The decision as to which sequences of base character plus combining character constitute typographic units, in this case, depends on how the glyphs will be rendered.
The sequence of three items on the far left is actually composed of only two code points, க [U+0B95 TAMIL LETTER KA] followed by the circumgraph ௌ [U+0BCC TAMIL VOWEL SIGN AU]. Notice that there are spaces between the base consonant and both glyphs that make up the vowel-sign.
In such cases, the typographic unit may be at the sub-codepoint level !