This specification defines WebVMT, the Web Video Map Tracks format, which is an enabling technology whose main use is for marking up external metadata track resources in connection with the HTML <track> element. WebVMT files provide map presentation, annotation and interpolation synchronized to web media content, and more generally any form of data that is time-aligned with audio or video content, including those from location-aware devices such as dashcams, drones and smartphones.
This document is a Note, it has not been widely reviewed and should be considered as experimental only. It may serve as the base for an upcoming W3C Recommendation.
This document is an explanatory specification, intended to communicate and develop the draft WebVMT format through discussion with user communities.
Use Cases
This section details example scenarios in which WebVMT can add significant value with identified benefits.
Coastguard/Mountain Rescue
A missing person is reported to the rescue services, who deploy a drone to search inaccessible areas of coastline or moorland for their target. The drone relays back a live video stream from its camera and geolocation data from its GPS receiver to a remote human operator who is piloting it.
As the search continues, the operator spots a target on the video feed and can instantly call up an electronic map, synchronized to the video, which has been automatically following the drone’s position and plotting its ground track. The display gives the operator immediate context for the video, and allows them to override the automatic map control and zoom in to pinpoint the target’s precise location from the features visible in the video and on the map/satellite view. They mark the location and then zoom out to assess the surrounding terrain and advise the recovery team of the best approach to the target. For example, the terrain may dictate very different approach routes if either the person has twisted their ankle at the top of a cliff, or has fallen and is lying at the bottom of the same cliff, though the co-ordinates are almost identical in both cases.
The operator has been able to make important decisions quickly, which may be life critical, and deploy recovery resources effectively.
Rapid decision making;
Effective resource deployment.
Area Survey
A survey drone is equipped with a camera which records an image of the ground directly below it. The pilot is a remote human operator, tasked with surveying a defined area from particular height in order to capture the required data.
As the survey progresses, zones are automatically marked on the map to represent areas which have been included. Once the drone has finished its sweep, the operator can quickly confirm whether the required area has been completely covered. If any areas have been missed, the pilot can use the map to navigate and make additional passes to fill the gaps, before returning to base.
Adding WebVMT files to the survey archive provides a geospatial index to the videos, allowing a particular geographic location to be found more rapidly by virtue of their small file size in comparison to their linked media. Online video archives can be indexed more quickly using this web-friendly format.
The operator has been easily able to verify the quality of their own work and correct any errors, saving time and additional effort in redeployment. Video footage has been indexed by geolocation rapidly and in a search-engine-friendly format.
Autonomous quality assurance;
Cost saving;
Rapid archive indexing for search engines.
Outdoor Trails
An outdoor sportsperson, e.g. snowboarder or cyclist, is equipped with a helmet camera and/or mobile phone to record video footage and GPS data. They set off to find new challenges and practice their skills, e.g. off-piste or on mountain trails, and discover new routes and areas that they would like to explore in future, chatting to the camera as they go. Afterwards, they upload the video to share their experience with the online community, so others can quickly identify locations of particularly interesting sections of the featured trail. Using the synchronized map view in their browser, community members can easily see where they need to go in order to explore these places for themselves.
The operator has been able to fully engage in their sporting activity, without making any written notes, while simultaneously recording the details needed to guide others to the same locations. Their changing location over time can also be used to calculate speed and distance information, which can be displayed alongside the footage.
Non-invasive capture;
Information sharing;
Speed and distance calculation.
TV Sports Coverage
A TV production company is covering a sports event that takes place over a large area, e.g. rallying, road cycling or sailing, using a number of mobile video devices including competitor cams, e.g. dash cams or helmet cams, and drones to provide shots of inaccessible areas, e.g. remote terrain or over water.
Feeds from all the cameras are streamed to the production control room, where their geolocation data are combined on a map showing the locations of every competitor and camera, each labelled for easy identification. The live map enables the director to quickly choose the best shot and anticipate where and when to deploy their drone cameras to catch competitors at critical locations on the course as the competition develops in real time.
Multiple operators can function concurrently, both autonomously and under central direction. Mobile assets can be monitored and deployed from an operations centre to provide optimum coverage of the developing live event.
Multiple mobile video devices;
Real time asset management.
Proxy Explorer
Important details of a remote area have been captured on video. It is not possible to revisit the location for safety reasons or because it has physically changed in the intervening time. Footage can be retrospectively geotagged against a concurrent map to allow the viewer to better interpret and identify features seen in the footage. Explanatory annotations can be added to the WebVMT file to help future viewers' understanding and aggregate the collective analysis.
Multiple operators can contribute their observations to provide a group analysis, iteratively adding new details and discarding out-of-date information. Experts can offer insight about filmed locations, which would otherwise be inaccessible to them.
Remote analysis of inaccessible locations;
Knowledge aggregation and sharing for archive footage.
Treasure Hunt
A TV production company designs a new game show which involves competitors searching for targets across a wide area, with an operations centre remotely monitoring their progress and providing updates. Competitors are equipped with body-worn video or helmet cameras to relay footage of their view.
Geolocation context allow central operators to better understand the participants' actions and to remotely direct them more efficiently. Competitors' positions can displayed to the TV audience on annotated 2D- or 3D-maps for clearer presentation.
Speed and distance calculation;
Knowledge aggregation and sharing for real-time footage.
Swarm Monitoring
A swarm of drones is deployed to perform a task, and their operations are monitored centrally. Geolocation details of the swarm are automatically collated and broadcast to the drone pilots, showing the locations of all the drones and each is circled with a suitable safety zone to warn their operators in case two units find themselves flying in close proximity.
Pilots are safely able to operate either autonomously or under the direction of central control. Extra zonal information can be added to the operators' maps to show the outer perimeter of their operating area and warn of fixed aerial hazards, e.g. a radio mast, or transient hazards, e.g. a helicopter.
Static and dynamic hazard indication;
Central swarm monitoring;
Autonomous swarm monitoring.
Crisis Response
Disaster strikes, e.g. hurricane or tsunami, and emergency response teams are deployed to the affected area. However, it is difficult to verify which problems people are facing, what resources would help them and exactly where these events are occurring. Maps are unreliable as the infrastructure has been damaged, though people on the ground have the relevant knowledge if it could be reliably recorded and shared.
Anyone with a basic smartphone could video events with reliable geospatial data, as GPS receivers can operate without the need for a mobile phone signal by using satellite data, to accurately document the problems they face. Even if the cell network is not operational, this information can be physically delivered to crisis coordinators to notify them of the issues that need to be addressed, including accurate location data in a common format. Response teams can quickly search archived video by location to verify latest updates with recent context. Crisis events can be reliably recorded, knowledge can be shared and aggregated, and relief resources can be accurately targeted and deployed to the correct locations.
Reliable dispersed information gathering and sharing;
Accurate resource deployment.
Police Evidence
A web-based police system is established to allow dashcam video evidence of driving offences to be submitted digitally by members of the public who have witnessed them. Detectives are able to identify the time and vehicles involved directly from the uploaded footage, and accurately determine the location at which the incident occurred from the digital timed metadata included.
The ability to accept open format data also makes the system available to cyclists and pedestrians who can record video with location on their helmet cameras and smartphones respectively, providing wider access to the service beyond the dashcam community. Metadata, e.g. location, from different video manufacturers is often recorded in mutually-incompatible formats, but WebVMT support enables synchronized location (and other) data to be extracted from recordings using manufacturers' or community tools, without affecting source video integrity, and submitted to the police system in a common format, significantly reducing development costs.
Officers have been able to identify incident locations quickly and accurately, without sacrificing evidence integrity. The online service has been made available to a wider audience of drivers, cyclists and pedestrians, without incurring additional development costs.
Accurate location with evidence integrity preserved;
Development costs reduced;
Service extended to a wider audience.
Area Monitoring
An area of interest is monitored operationally by a collection of different mobile video devices, e.g. drones, body-worn video, helicopter, etc. Video footage, possibly in different formats, is added to an archive with location (and other) metadata in a common format which forms a time-location index suitable for rapid parsing by a web crawler. Users can submit online queries to search by location and return a time-ordered sequence of video frame stills captured within a radial distance of the chosen location. Alternatively, sensor data can be searched, e.g. for high readings, to return matching geotagged video frames for further analysis.
Video archives can be quickly indexed using a common metadata format regardless of video encoding, e.g. MPEG, WebM, OGG, and video files are only accessed in case of a positive search result, which reduces bandwidth in comparison to embedded metadata. Linked files also allow different security permissions to be applied to the crawling and querying processes, so an AI algorithm can be authorised to read metadata without being able to access image content if there are security concerns over data privacy, e.g. illicit facial recognition.
Homogenized video metadata from disparate sources;
Reduced search bandwidth;
Structured security support;
Web search engine compatible.
Vehicle Collision
Dashcam footage is searched to automatically identify vehicle collisions from impact acceleration profiles recorded in video metadata. Dashcam manufacturers typically embed metadata in an unpublished format and provide a proprietary video player to allow users to display it. Exporting embedded metadata to a linked file in a web-friendly format enables searchable video archive data to be shared quickly and easily, without affecting evidence integrity, and to be accessed through a common web interface.
Vehicles can be automatically monitored using a low-cost dashcam and web-based tools to ensure that collisions are accurately recorded by drivers and that commercial vehicles remain safe and undamaged. Interoperability means that users are not limited to a particular brand and can share evidence with insurers and the police in a common format without damaging its integrity.
Accurate vehicle collision detection;
Common format for data sharing;
Web search support;
Evidence integrity preserved.
Golden Tutorial
Augmented reality (AR) software is used to control assets or view content in situ at a particular location. For example, nearby street lights can be switched off or on by a service engineer for maintenance purposes, or an architect can see how their structural design integrates with the surrounding landscape at its proposed location before any building work has started.
Video footage can be recorded with location, camera orientation and other metadata so AR overlays be generated on demand. Such recordings can be used to demonstrate how AR content is displayed and controlled in order to educate users with a 'golden tutorial', to provide 'proof of action' as evidence of work done for auditing purposes, or to create example data for AR software testing and debugging.
Accurate AR video and data recording;
Improved AR software development.
Virtual Guide
A user triggers an audio track which provides guidance about the local area or instruction for a known object, e.g. Web of Things (WoT) device at that location. The audio timeline is synchronized with events that can display AR content, control WoT devices and display points of interest on a map which provide guidance with real world context by highlighting places or objects of interest and showing possible actions.
Users can be guided by a virtual assistant through an area of interest or sequence of actions augmented with AR/VR and WoT devices to visualise events and by an annotated map or model to provide additional geospatial context. Greater insight is given to the user by showing detailed views of the location on a map or internal structure of the identified object using a virtual model.
Contextual guidance provided in situ;
Concurrent operation with AR/VR video;
Integration with Web of Things.
State of the Art
No standard format currently exists by which web browsers can synchronise geolocation data with video. Though many browser-supported formats exist to present the two data streams separately, e.g. MPEG for video and GPX for geolocation, there is no viable synchronisation mechanism for video playback time with geolocation information.
Current Solutions
Material Exchange Format (MXF) was developed by the Society of Motion Picture and Television Engineers (SMPTE) to synchronise metadata, including geolocation, with audio and video streams using a register of key-length-value (KLV) triples. The breadth of its scope has resulted in interoperability issues, as different vendors implement different parts of the standard, and has produced implementations from high-profile companies which are mutually incompatible. KLVs can also be embedded within MPEG files, though this does not address the synchronisation issue for other web video formats such as WebM.
Video camera manufacturers have taken various approaches, resulting in a number of non-standard solutions including embedding geolocation data within the MPEG metadata stream in disparate formats, such as Motion Imagery Standards Board (MISB) or Go-Pro Metadata Format (GPMF), or recording a separate geolocation file in a proprietary format alongside the associated video file. From a hardware perspective, a few high-end cameras provide geotagging out of the box and all require an add-on device to support this feature.
Geospatial data are not currently accessible in the video Document Object Model (DOM) in HTML nor via video playback APIs in smartphones, e.g. Android, though their host devices are typically equipped with both a video camera and Global Navigation Satellite System (GNSS) receiver capable of capturing the required information.
In sharp contrast, still photos have a well-established geotagging standard called Exif, which was published by the Japan Electronic Industries Development Association (JEIDA) in 1995 and defines a metadata tag to embed geolocation data within TIFF and JPEG images. This is widely supported by manufacturers of photographic equipment and software worldwide, including low-end smartphones, making this feature cheap and accessible to the public.
Growing Requirements
Historically, there has been no requirement for a comparable video standard, but the urgency for such a standard is growing fast due to the emerging markets for 'mobile video devices,' e.g. drones, dashcams, body-worn video and helmet cameras, as well as the rise in high-quality video and geolocation support in the global smartphone market.
Accessible Standard Opportunity
Using current W3C recommendations, it is possible for a programmer to synchronise video-geolocation 'metadata' with a <video> element using a <track> child element. However, this is a non-trivial development task which requires an understanding of the video DOM events and Javascript file handling, making it inaccessible to the vast majority of web users. Video metadata tracks are an identified kind of track data in HTML, though metadata content is difficult to access due to the text-based nature of existing DOM support.
Establishing a standard file format would allow interoperability and information sharing between the public, the emergency services, police and other mobile video device users, e.g. drone pilots, giving cheaper and easier access to this important resource. Native web browser support for geotagged video using this file format would also make this freely accessible to most web users and enable integration with existing web services such as online maps and search engines. Current low-end smartphones already provide suitable hardware to concurrently capture video and geolocation streams, which would make this technology easily accessible to the general public, and encourage the user and developer communities to grow rapidly.
Proposed Solution
This proposal constitutes a lightweight markup language to synchronise video with geolocation data for display on electronic maps, such as OpenStreetMaps. It offers presentational control of the map display, e.g. pan and zoom, and annotation to highlight map features to the viewer, e.g. paths and zones.
WebVMT (Web Video Map Tracks) format is intended for marking up external map track resources, and its main use is for files synchronising video content with an annotated map presentation. Ideas have been borrowed from existing W3C formats, including WebVTT's HTML binding and its block and cue structures, and SVG's approach to drawing, in order to display output on an electronic map.
The format mimics WebVTT's structure and syntax for media synchronisation, with cue details listed in an accessible text-based file linked to a <video> or <audio> DOM element by a child <track> element in an HTML document.
<!doctype html>
<html>
<head>
<title>WebVMT Basic Example</title>
</head>
<body>
<!-- Video display -->
<video controls width="640" height="360">
<source src="video.mp4" type="video/mp4">
<track src="maptrack.vmt" kind="metadata" for="vmt-map" tileurl="https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png?key=VALID_OSM_KEY">
Your browser does not support the video tag.
</video>
<!-- Map display -->
<div id="vmt-map" style="height: 360px; width:640px;"></div>
</body>
</html>
The WebVMT format file, e.g. maptrack.vmt, contains the map cues associated with the video, e.g. video.mp4.
The meaning of for and tileurl attributes for user agents is an open question. Initial solutions can be built using Javascript, with existing map libraries such as Leaflet, though the vision is that future user agents will handle map rendering in the longer term.
Map Cues
Map cues display their payload between a start time and end time. The end cue time may be omitted to represent an unknown time.
Hello World
Here is a sample WebVMT file with a cue highlighting Tower Bridge in London on a static map.
CSS style sheets can also be embedded within WebVMT files. Style blocks are placed after any headers but before the first cue, and start with the word STYLE.
Comment blocks can be interleaved with style blocks.
WEBVMT
MEDIA
url:http://example.com/movies/Greenwich.mp4
mime-type:video/mp4
MAP
lat:51.478 lng:-0.001
rad:50
STYLE
::cue {
stroke: red;
}
NOTE Comments are allowed between style blocks
STYLE
::cue {
stroke-opacity: 0.9;
}
/* Style blocks cannot use blank lines nor "dash dash greater than" */
NOTE Prime Meridian marker
00:00:00.000 -->
{ "move-to":
{ "lat":51.477901, "lng": -0.001466 }
}
{ "line-to":
{ "lat":51.477946, "lng": -0.001466 }
}
NOTE Style blocks may not appear after the first cue
Data Synchronization
Arbitrary data may be associated with a WebVMT cue using a sync command, in a similar fashion to the GPX <extension> element.
WEBVMT
NOTE Associated video
MEDIA
url:Animals.mp4
mime-type:video/mp4
NOTE Map config
MAP
lat:51.1618 lng:-0.1428
rad:200
NOTE Cat, top left, after 5 secs until 25 secs
00:00:05.000 —-> 00:00:25.000
{ “sync”: { “type”: “org.ogc.geoai.example”, “data”:
{ “animal”:”cat”, “frame-zone”:”top-left" }
} }
NOTE Dog, mid right, after 10 secs until 40 secs
00:00:10.000 —-> 00:00:40.000
{ “sync”: { “type”: “org.ogc.geoai.example”, “data”:
{ “animal”: ”dog”, “frame-zone”: ”middle-right" }
} }
Sensor data can be interpolated between sample points to provide intermediate values where necessary, while retaining the original source data sample values.
Three interpolation schemes are supported:
Step: the value remains constant until the next sample time, e.g. vehicle gear selection - see ;
Linear: the value is linearly interpolated to the next sample time, e.g. temperature - see ;
Discrete: the value is only valid instanteously at the sample time, e.g. headcount in a video frame - see .
Step Interpolation
A stepwise-interpolated value, e.g. vehicle gear selection, remains constant until the next sample time.
Step interpolation.
WEBVMT
NOTE Required blocks omitted for clarity
NOTE Step interpolation of sensor1 data
gear = 4 after 2 secs until 6 secs
00:00:02.000 --> 00:00:06.000
{ "sync":
{ "type": "org.webvmt.example1", "id": "sensor1", "data":
{ "gear": "4" }
}
}
NOTE Step interpolation of sensor1 data
gear = 5 after 6 secs until 9 secs
00:00:06.000 --> 00:00:09.000
{ "sync":
{ "type": "org.webvmt.example1", "id": "sensor1", "data":
{ "gear": "5" }
}
}
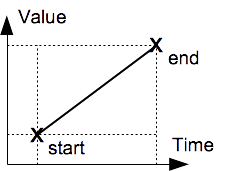
Linear Interpolation
A linearly-interpolated value, e.g. temperature, changes to a final value at the next sample time in direct proportion to the elapsed sample interval.
Linear interpolation.
WEBVMT
NOTE Required blocks omitted for clarity
NOTE Linear interpolation of sensor2 data
temperature = 14 -> 16 after 4 secs until 6 secs
00:00:04.000 --> 00:00:06.000
{ "sync":
{ "type": "org.webvmt.example2", "id": "sensor2", "data":
{ "temperature": "14"}
}
}
{ "sync":
{ "type": "org.webvmt.example2", "id": "sensor2", "end": "00:00:06.000", "data":
{ "temperature": "16"}
}
}
NOTE Linear interpolation of sensor2 data
temperature = 16 -> 19 after 6 secs until 9 secs
00:00:06.000 --> 00:00:09.000
{ "sync":
{ "type": "org.webvmt.example2", "id": "sensor2", "end": "00:00:09.000", "data":
{ "temperature": "19"}
}
}
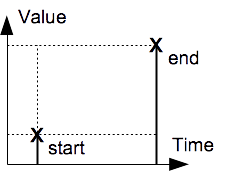
Discrete Interpolation
A discretely-interpolated value, e.g. headcount in a video frame, is only valid instanteously at the sample time.
Discrete interpolation.
WEBVMT
NOTE Required blocks omitted for clarity
NOTE Discrete interpolation of sensor3 data
headcount = 12 at 4 secs
00:00:04.000 --> 00:00:04.000
{ "sync":
{ "type": "org.webvmt.example3", "id": "sensor3", "data":
{ "headcount": "12" }
}
}
NOTE Discrete interpolation of sensor3 data
headcount = 34 at 6 secs
00:00:06.000 --> 00:00:06.000
{ "sync":
{ "type": "org.webvmt.example3", "id": "sensor3", "data":
{ "headcount": "34" }
}
}
Live Stream Interpolation
Live streams can be recorded with interpolation using unbounded cues, i.e. a cue with an unknown end time.
In this example, the result is identical to the previous step interpolation example but without requiring knowledge of any future data values during the live capture process.
WEBVMT
NOTE Required blocks omitted for clarity
NOTE Step interpolation of live1 data
gear = 4 after 4 secs until next update
00:00:04.000 -->
{ "sync":
{ "type": "org.webvmt.example1", "id": "live1", "data":
{ "gear": "4" }
}
}
NOTE Step interpolation of live1 data
gear = 5 after 6 secs until next update
00:00:06.000 -->
{ "sync":
{ "type": "org.webvmt.example1", "id": "live1", "data":
{ "gear": "5" }
}
}
NOTE End (step) interpolation of live1 data
gear = 5 at 9 secs
00:00:09.000 --> 00:00:09.000
{ "sync":
{ "type": "org.webvmt.example1", "id": "live1", "data":
{ "gear": "5" }
}
}
In the next example, the result is identical to the previous linear interpolation example but without requiring knowledge of any future data values during the live capture process.
WEBVMT
NOTE Required blocks omitted for clarity
NOTE Linear interpolation of live2 data
temperature = 14 after 4 secs until next update
00:00:04.000 -->
{ "sync":
{ "type": "org.webvmt.example2", "id": "live2", "data":
{ "temperature": "14" }
}
}
{ "sync":
{ "type": "org.webvmt.example2", "id": "live2", "end": "00:00:06.000", "data":
{ "temperature": "16" }
}
}
NOTE Linear interpolation of live2 data
temperature = 16 after 6 secs until next update
00:00:06.000 -->
{ "sync":
{ "type": "org.webvmt.example2", "id": "live2", "end": "00:00:09.000", "data":
{ "temperature": "19" }
}
}
NOTE End (linear) interpolation of live2 data
temperature = 19 at 9 secs
00:00:09.000 --> 00:00:09.000
{ "sync":
{ "type": "org.webvmt.example2", "id": "live2", "data":
{ "temperature": "19" }
}
}
Values may not be interpolated during capture as future data are unknown, e.g. for linear interpolation, though can be correctly interpolated after capture, once end values are known during subsequent playbacks.
Path Interpolation
A WebVMT path describes the trajectory of a moving object which consists of a timed sequence of locations. The object's location may be interpolated between consecutive values in the sequence to calculate the distance travelled over time.
The path attribute may be set to identify an individual path. This allows a path:
to be styled with CSS, e.g. colour;
to be associated with speed and distance attributes during playback;
to be uniquely associated with the video footage.
In this example, an interpolated path is traced from London to Brighton:
Embedded YouTube content can be displayed using an <iframe> element, specifying the unique 10-character content identifier for the posted video, using the official YouTube IFrame API with the Javascript API enabled.
Hello YouTube
A child <track> pseudo-element within the <iframe> links it with WebVMT using the same syntax as for the <video> DOM element.
Note that the <track> pseudo-element is actually replaced by the <iframe> content when the page is loaded.
The url in the MEDIA block should match the src attribute of the <iframe> element without the query.
WEBVMT
NOTE Associated YouTube video
MEDIA
url:http://www.youtube.com/embed/YOUTUBE_VIDEO_ID
mime-type:video/mp4
Conformance classes
This specification describes the conformance criteria for user agents (relevant to implementors) and WebVMT files (relevant to authors and authoring tool implementors).
Syntax defines what consists of a valid WebVMT file. Authors need to follow the requirements therein, and are encouraged to use a conformance checker. Parsing defines how user agents are to interpret a file labelled as text/vmt, for both valid and invalid WebVMT files. The parsing rules are more tolerant to author errors than the syntax allows, in order to provide for extensibility and to still render cues that have some syntax errors.
User agents fall into several (possibly overlapping) categories with different conformance requirements.
User agents that support scripting
All processing requirements in this specification apply. The user agent must also be conforming implementations of the IDL fragments in this specification, as described in the Web IDL specification.
User agents with no scripting support
All processing requirements in this specification apply, except those in Planned Interfaces.
User agents that do not support CSS
All processing requirements in this specification apply, except parts of Parsing that relate to stylesheets and CSS, and all of CSS Extensions. The user agent must instead only render the WebVMT cue in an appropriate manner. Any other styling instructions are optional.
User agents that do not support a full HTML CSS engine
All processing requirements in this specification apply. However, the user agent will need to apply the CSS related features in Parsing, and CSS Extensions in such a way that the rendered results are equivalent to what a full CSS supporting renderer produces.
User agents that support a full HTML CSS engine
All processing requirements in this specification apply. However, only a limited set of CSS styles is allowed because user agents that do not support a full HTML CSS engine will need to implement CSS functionality equivalents. User agents that support a full CSS engine must therefore limit the CSS styles they apply for WebVMT so as to enable identical rendering without bleeding in extra CSS styles that are beyond the WebVMT specification.
Conformance checkers
Conformance checkers must verify that a WebVMT file conforms to the applicable conformance criteria described in this specification. The term "validator" is equivalent to conformance checker for the purpose of this specification.
Authoring tools
Authoring tools must generate conforming WebVMT files. Tools that convert other formats to WebVMT are also considered to be authoring tools.
When an authoring tool is used to edit a non-conforming WebVMT file, it may preserve the conformance errors in sections of the file that were not edited during the editing session (i.e. an editing tool is allowed to round-trip erroneous content). However, an authoring tool must not claim that the output is conformant if errors have been so preserved.
Unicode normalization
Implementations of this specification must not normalize Unicode text during processing.
Data Model
The data model of WebVMT consists of four key elements: the linked media file, the video viewport, cues, and the map viewport. The linked media file contains audio or video data with which cues are synchronized. The video viewport is the rendering area for video output. Cues are containers consisting of a set of metadata lines. The map viewport is the rendering area for metadata output, for example graphical annotations overlaid on an online map.
Overview
The WebVMT file is a container file for chunks of data that are time-aligned with a video or audio resource. It can therefore be regarded as a serialisation format for time-aligned data.
A WebVMT file starts with a header and then contains a series of data blocks. If a data block has a start time, it is called a WebVMT cue. A comment is another kind of data block.
A WebVMT file carries cues which are identified as metadata and specified in the kind attribute of the track element in the HTML specification.
The data kind of a WebVMT file is externally specified, such as in a HTML file’s track element. The environment is responsible for interpreting the data correctly.
A WebVMT cue is rendered as an overlay on top of the map viewport.
WebVMT Cue
A WebVMT cue is a text track cue that additionally consists of the following:
A cue text
The raw text of the cue which is interpreted as time-aligned metadata, and rules for its interpretation.
A WebVMT cue without an end time indicates that the cue is an unbounded text track cue, for example during live streaming when the time of the next data sample is unknown or when the duration of the media is unknown.
A WebVMT cue with negative cue times maintains timing information prior to the start of the media, for example to preserve speed information for a WebVMT path.
WebVMT Location
A WebVMT location consists of:
A location latitude
The latitude in degrees of the location.
A location longitude
The longitude in degrees of the location.
A location altitude
Optionally, the altitude in meters of the location.
Location information is provided in terms of World Geodetic System coordinates, WGS84. Altitude is measured in meters above the WGS84 ellipsoid, and should not be confused with the height above mean sea level.
WebVMT Map
A WebVMT map is the map viewport and provides a rendering area for WebVMT cues.
A WebVMT media is metadata for the linked media with which WebVMT cues are synchronized, for example audio or video.
A WebVMT media enables a web crawler to rapidly search media metadata by providing sufficient information to construct a time-metadata index of the linked media file without opening it. Search engine data throughput is reduced as only matching media files selected by the user need be read, and non-matching media files are not accessed at all. Care should be taken to maintain WebVMT media details correctly, for example when a media file is renamed.
A null media URL indicates that no linked media file exists.
A media MIME type
The MIME type of the linked media file.
A null media MIME type indicates that no linked media file exists.
A media start time
The global time and date at which the linked media file begins.
The media start time allows multiple WebVMT files to be aggregated. A null media start time indicates that no start time is associated, for example in the case of an animation.
A media path
The path identifier which uniquely identifies the moving object capturing the linked media file.
A null media path indicates that no moving object is associated, for example when no linked media file exists.
WebVMT Command Structures
A WebVMT command is an instruction to display WebVMT metadata content.
A WebVMT command consists of one of the following components:
Vertex locations are listed sequentially around the perimeter of the polygon. The last vertex should not repeat the value of the first, as this is implicit.
Paths
A WebVMT path consists of all the path segments with the same path identifier.
A path segment consists of a sequence of contiguous WebVMT path fragments that describe the trajectory of an object moving through the mapped space.
A WebVMT line is a straight line from the start location to the end location. The location of the moving object can be linearly interpolated between the fragment start time and the fragment end time.
Synchronized Data
A WebVMT synchronized data command synchronizes a sample from a data source with a WebVMT cue.
A WebVMT file body consists of the following components, in the order given:
An optional U+FEFF BYTE ORDER MARK (BOM) character.
The string "WEBVMT" (W U+0057 LATIN CAPITAL LETTER W, E U+0045 LATIN CAPITAL LETTER E, B U+0042 LATIN CAPITAL LETTER B, V U+0056 LATIN CAPITAL LETTER V, M U+004D LATIN CAPITAL LETTER M, T U+0054 LATIN CAPITAL LETTER T).
Optionally, either a U+0020 SPACE character or a U+0009 CHARACTER TABULATION (tab) character followed by any number of characters that are not U+000A LINE FEED (LF) or U+000D CARRIAGE RETURN (CR) characters.
Two or more WebVMT line terminators to terminate the line with the file magic and separate it from the rest of the body.
The following components, in any order, separated from each other by one or more WebVMT line terminators.
A WebVMT line terminator consists of one of the following:
A U+000D CARRIAGE RETURNU+000A LINE FEED (CRLF) character pair.
A single U+000A LINE FEED (LF) character.
A single U+000D CARRIAGE RETURN (CR) character.
A WebVMT media metadata block consists of the following components, in the order given:
The string "MEDIA" (M U+004D LATIN CAPITAL LETTER M, E U+0045 LATIN CAPITAL LETTER E, D U+0044 LATIN CAPITAL LETTER D, I U+0049 LATIN CAPITAL LETTER I, A U+0041 LATIN CAPITAL LETTER A).
Zero or more U+0020 SPACE characters or U+0009 CHARACTER TABULATION (tab) characters.
A WebVMT style block consists of the following components, in the order given:
The string "STYLE" (S U+0053 LATIN CAPITAL LETTER S, T U+0054 LATIN CAPITAL LETTER T, Y U+0059 LATIN CAPITAL LETTER Y, L U+004C LATIN CAPITAL LETTER L, E U+0045 LATIN CAPITAL LETTER E).
Zero or more U+0020 SPACE characters or U+0009 CHARACTER TABULATION (tab) characters.
Any sequence of zero or more characters other than U+000A LINE FEED (LF) characters and U+000D CARRIAGE RETURN (CR) characters, each optionally separated from the next by a WebVMT line terminator, except that the entire resulting string must not contain the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN). The string represents a CSS style sheet; the requirements given in the relevant CSS specifications apply.
The WebVMT cue payload consists of a WebVMT metadata text, but must not contain the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN).
A WebVMT cue identifier is any sequence of one or more characters not containing the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN), nor containing any U+000A LINE FEED (LF) characters or U+000D CARRIAGE RETURN (CR) characters.
A WebVMT cue identifier can be used to identify a specific cue, for example from script or CSS.
The WebVMT cue timings part of a WebVMT cue block consists of the following components, in the order given:
A WebVMT timestamp representing the start time offset of the cue. The time represented by this WebVMT timestamp must be greater than or equal to the start time offsets of all previous cues in the file.
One or more U+0020 SPACE characters or U+0009 CHARACTER TABULATION (tab) characters.
One or more U+0020 SPACE characters or U+0009 CHARACTER TABULATION (tab) characters.
Optionally, a WebVMT timestamp representing the end time offset of the cue. The time represented by this WebVMT timestamp must be greater than or equal to the start time offset of the cue.
The WebVMT cue timings give the start and end offsets of the WebVMT cue block. Different cues can overlap. Cues are always listed ordered by their start time.
A WebVMT timestamp consists of the following components, in the order given:
Optionally (required if hours is non-zero):
Two or more ASCII digits, representing the hours as a base ten integer.
A : U+003A COLON character.
Two ASCII digits, representing the minutes as a base ten integer in the range 0 ≤ minutes ≤ 59.
A : U+003A COLON character.
Two ASCII digits, representing the seconds as a base ten integer in the range 0 ≤ seconds ≤ 59.
A . U+002E FULL STOP character.
Three ASCII digits, representing the thousandths of a second seconds-frac as a base ten integer.
A WebVMT comment block consists of the following components, in the order given:
The string "NOTE" (N U+004E LATIN CAPITAL LETTER N, O U+004F LATIN CAPITAL LETTER O, T U+0054 LATIN CAPITAL LETTER T, E U+0045 LATIN CAPITAL LETTER E).
Optionally, the following components, in the order given:
Either:
A U+0020 SPACE character or U+0009 CHARACTER TABULATION (tab) character.
Any sequence of zero or more characters other than U+000A LINE FEED (LF) characters and U+000D CARRIAGE RETURN (CR) characters, each optionally separated from the next by a WebVMT line terminator, except that the entire resulting string must not contain the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN).
WebVMT metadata text consists of any sequence of zero or more characters other than U+000A LINE FEED (LF) characters and U+000D CARRIAGE RETURN (CR) characters, each optionally separated from the next by a WebVMT line terminator. (In other words, any text that does not have two consecutive WebVMT line terminators and does not start or end with a WebVMT line terminator.)
The WebVMT media settings list consists of zero or more of the following components, in any order, separated from each other by one or more U+0020 SPACE characters, U+0009 CHARACTER TABULATION (tab) characters, or WebVMT line terminators, except that the string must not contain two consecutive WebVMT line terminators. Each component must not be included more than once per WebVMT media settings list string.
For the purpose of resolving a URL in the MEDIA block of a WebVMT file, or any URLs in resources referenced from MEDIA blocks of a WebVMT file, if the URL’s scheme is not "data", then the user agent must act as if the URL failed to resolve. If the url value does not match the src attribute of the HTML <track> element, then the src value takes precedence.
A WebVMT media MIME type setting consists of the following components, in the order given:
The WebVMT map settings list consists of the following components, in any order, separated from each other by one or more U+0020 SPACE characters, U+0009 CHARACTER TABULATION (tab) characters, or WebVMT line terminators, except that the string must not contain two consecutive WebVMT line terminators. Each component must be included once per WebVMT map settings list string.
When interpreted as a number, a WebVMT altitude represents the height in meters above the WGS84 ellipsoid. Care should be taken not to confuse this with the height above mean sea level.
A WebVMT map zoom setting consists of the following components, in the order given:
A WebVMT zone identifier is any sequence of one or more characters not containing the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN), nor containing any U+000A LINE FEED (LF) characters or U+000D CARRIAGE RETURN (CR) characters.
A WebVMT zone identifier is a string which uniquely identifies a zone in the WebVMT file, for example a safety zone around a moving object.
A WebVMT polygon command consists of a JSON text representing the following JSON object:
A WebVMT location attribute list consists of a JSON text representing a list of the following JSON values in any order, separated from each other by a , U+002C COMMA character:
When interpreted as a number, a WebVMT altitude represents the height in meters above the WGS84 ellipsoid. Care should be taken not to confuse this with the height above mean sea level.
WebVMT Path Commands
A WebVMT path annotation command consists of one of the following components:
A WebVMT path identifier is any sequence of one or more characters not containing the substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN), nor containing any U+000A LINE FEED (LF) characters or U+000D CARRIAGE RETURN (CR) characters.
Notice how you can express the cues in this WebVMT file as a tree structure:
2km Circle at (0, 0)
Line (0, 0) to (0.12, 0.34)
Line (0.12, 0.34) to (0.56, 0.78)
30km Circle at (0, 0)
Line (0.87, 0.65) to (0.43, 0.21)
Line (0.43, 0.21) to (0, 0)
If the file has cues that can’t be expressed in this fashion, then they don’t match the definition of a WebVMT file using only nested cues. For example:
In this ninety-second example, the two cues partly overlap, with the first ending before the second ends and the second starting before the first ends. This therefore is not a WebVMT file using only nested cues.
Parsing
WebVMT file parsing is similar to WebVTT parsing, though many of those steps can be skipped as WebVMT files are metadata files.
WebVMT File Parsing
A WebVMT parser, given an input byte stream, a text track list of cues |output|, and a collection of CSS style sheets |stylesheets|, must decode the byte stream using the UTF-8 decode algorithm, and then must parse the resulting string according to the WebVMT parser algorithm. This results in WebVMT cues being added to |output|, and CSS style sheets being added to |stylesheets|.
A WebVMT parser, specifically its conversion and parsing steps, is typically run asynchronously, with the input byte stream being updated incrementally as the resource is downloaded; this is called an incremental WebVMT parser.
A WebVMT parser verifies a file signature before parsing the provided byte stream. If the stream lacks this WebVMT file signature, then the parser aborts.
The WebVMT parser algorithm is as follows:
Let |input| be the string being parsed, after conversion to Unicode, and with the following transformations applied:
Replace all � U+0000 NULL characters by � U+FFFD REPLACEMENT CHARACTERs.
Replace each U+000D CARRIAGE RETURNU+000A LINE FEED (CRLF) character pair by a single U+000A LINE FEED (LF) character.
Replace all remaining U+000D CARRIAGE RETURN (CR) characters by U+000A LINE FEED (LF) characters.
Let |position| be a pointer into |input|, initially pointing at the start of the string. In an incremental WebVMT parser, when this algorithm (or further algorithms that it uses) moves the |position| pointer, the user agent must wait until appropriate further characters from the byte stream have been added to |input| before moving the pointer, so that the algorithm never reads past the end of the |input| string. Once the byte stream has ended, and all characters have been added to |input|, then the |position| pointer may, when so instructed by the algorithms, be moved past the end of |input|.
Let |seen cue| be false.
If |input| is less than six characters long, then abort these steps. The file does not start with the correct WebVMT file signature and was therefore not successfully processed.
If |input| is exactly six characters long but does not exactly equal "WEBVMT", then abort these steps. The file does not start with the correct WebVMT file signature and was therefore not successfully processed.
If |input| is more than six characters long but the first six characters do not exactly equal "WEBVMT", or the seventh character is not a U+0020 SPACE character, a U+0009 CHARACTER TABULATION (tab) character, or a U+000A LINE FEED (LF) character, then abort these steps. The file does not start with the correct WebVMT file signature and was therefore not successfully processed.
If |position| is past the end of |input|, then abort these steps. The file was successfully processed, but it contains no useful data and so no WebVMT cues were added to |output|.
The character indicated by |position| is a U+000A LINE FEED (LF) character. Advance |position| to the next character in |input|.
If |position| is past the end of |input|, then abort these steps. The file was successfully processed, but it contains no useful data and so no WebVMT cues were added to output.
Header: If the character indicated by |position| is not a U+000A LINE FEED (LF) character, then collect a WebVMT block with the |in header| flag set. Otherwise, advance |position| to the next character in |input|.
If |position| is past the end of |input|, let |seen EOF| be true. Otherwise, the character indicated by |position| is a U+000A LINE FEED (LF) character; advance |position| to the next character in |input|.
If |line| contains the three-character substring "-->" (- U+002D HYPHEN-MINUS, - U+002D HYPHEN-MINUS, > U+003E GREATER-THAN SIGN), then run these substeps:
If |in header| is not set and at least one of the following conditions are true:
|line count| is 1
|line count| is 2 and |seen arrow| is false
...then run these substeps:
Let |seen arrow| be true.
Let |previous position| be |position|.
Cue creation: Let |cue| be a new WebVMT cue and initialize it as follows:
Collect WebVMT cue timings from |line| for |cue|. If that fails, let |cue| be null. Otherwise, let |buffer| be the empty string and let |seen cue| be true.
Otherwise, let |position| be |previous position| and break out of loop.
Otherwise, if |line| is the empty string, break out of loop.
Otherwise, run these substeps:
If |in header| is not set and |line count| is 2, run these substeps:
If |seen cue| is false and |buffer| starts with the substring "STYLE" (S U+0053 LATIN CAPITAL LETTER S, T U+0054 LATIN CAPITAL LETTER T, Y U+0059 LATIN CAPITAL LETTER Y, L U+004C LATIN CAPITAL LETTER L, E U+0045 LATIN CAPITAL LETTER E), and the remaining characters in |buffer| (if any) are all ASCII whitespace, then run these substeps:
Otherwise, if |seen cue| is false and |buffer| starts with the substring "MAP" (M U+004D LATIN CAPITAL LETTER M, A U+0041 LATIN CAPITAL LETTER A, P U+0050 LATIN CAPITAL LETTER P), and the remaining characters in |buffer| (if any) are all ASCII whitespace, then run these substeps:
Otherwise, if |seen cue| is false and |buffer| starts with the substring "MEDIA" (M U+004D LATIN CAPITAL LETTER M, E U+0045 LATIN CAPITAL LETTER E, D U+0044 LATIN CAPITAL LETTER D, I U+0049 LATIN CAPITAL LETTER I, A U+0041 LATIN CAPITAL LETTER A), and the remaining characters in |buffer| (if any) are all ASCII whitespace, then run these substeps:
Media creation: Let |media metadata| be a new WebVMT media.
Let |buffer| be the empty string.
If |buffer| is not the empty string, append a U+000A LINE FEED (LF) character to |buffer|.
Append |line| to |buffer|.
Let |previous position| be |position|.
If |seen EOF| is true, break out of loop.
If |cue| is not null, let the cue text of |cue| be |buffer|, and return |cue|.
Otherwise, if |stylesheet| is not null, then parse a stylesheet from |buffer|. If it returned a list of rules, assign the list as |stylesheet|'s CSS rules; otherwise, set |stylesheet|'s CSS rules to an empty list. Finally, return |stylesheet|.
Otherwise, if |media metadata| is not null, then collect WebVMT media settings from |buffer| using |media metadata| for the results. Construct a WebVMT media object from |media metadata|, and return it.
Otherwise, return null.
WebVMT Map Settings Parsing
When the WebVMT parser algorithm says to collect WebVMT map settings from a string |input| for a text track, the user agent must run the following algorithm.
For each token |setting| in the list |settings|, run the following substeps:
If |setting| does not contain a : U+003A COLON character, or if the first : U+003A COLON character in |setting| is either the first or last character of |setting|, then jump to the step labeled next setting.
Let |name| be the leading substring of |setting| up to and excluding the first : U+003A COLON character in that string.
Let |value| be the trailing substring of |setting| starting from the character immediately after the first : U+003A COLON character in that string.
Run the appropriate substeps that apply for the value of |name|, as follows:
Next setting: Continue to the next setting, if any.
WebVMT Media Settings Parsing
When the WebVMT parser algorithm says to collect WebVMT media settings from a string |input| for a text track, the user agent must run the following algorithm.
For each token |setting| in the list |settings|, run the following substeps:
If |setting| does not contain a : U+003A COLON character, or if the first : U+003A COLON character in |setting| is either the first or last character of |setting|, then jump to the step labeled next setting.
Let |name| be the leading substring of |setting| up to and excluding the first : U+003A COLON character in that string.
Let |value| be the trailing substring of |setting| starting from the character immediately after the first : U+003A COLON character in that string.
Run the appropriate substeps that apply for the value of |name|, as follows:
Next setting: Continue to the next setting, if any.
WebVMT Cue Timings Parsing
When the algorithm above says to collect WebVMT cue timings from a string |input| for a WebVMT cue |cue|, the user agent must run the following algorithm.
Let |input| be the string being parsed.
Let |position| be a pointer into |input|, initially pointing at the start of the string.
If the character at |position| is not a - U+002D HYPHEN-MINUS character then abort these steps and return failure. Otherwise, move |position| forwards one character.
If the character at |position| is not a - U+002D HYPHEN-MINUS character then abort these steps and return failure. Otherwise, move |position| forwards one character.
If the character at |position| is not a > U+003E GREATER-THAN SIGN character then abort these steps and return failure. Otherwise, move |position| forwards one character.
If |position| is not past the end of |input| and the character at |position| is an ASCII digit, collect a WebVMT timestamp. If that algorithm fails, then abort these steps and return failure. Otherwise, let |cue|'s text track cue end time be the collected time.
Otherwise (|position| is past the end of |input| or the character at |position| is not an ASCII digit), let |cue|'s text track cue end time be the value positive Infinity.
When this specification says that a user agent is to collect a WebVMT timestamp, the user agent must run the following steps:
Let |input| and |position| be the same variables as those of the same name in the algorithm that invoked these steps.
Let |most significant units| be minutes.
If |position| is past the end of |input|, return an error and abort these steps.
If the character at |position| is a - U+002D HYPHEN-MINUS character, let |negative| be true and move |position| forwards one character. Otherwise, let |negative| be false.
If |position| is beyond the end of |input| or if the character indicated by |position| is not an ASCII digit, then return an error and abort these steps.
Interpret |string| as a base-ten integer. Let |value1| be that integer.
If |string| is not exactly two characters in length, or if |value1| is greater than 59, let |most significant units| be hours.
If |position| is beyond the end of |input| or if the character at |position| is not a : U+003A COLON character, then return an error and abort these steps. Otherwise, move |position| forwards one character.
If |string| is not exactly two characters in length, return an error and abort these steps.
Interpret |string| as a base-ten integer. Let |value2| be that integer.
If |most significant units| is hours, or if |position| is not beyond the end of |input| and the character at |position| is a : U+003A COLON character, run these substeps:
If |position| is beyond the end of |input| or if the character at |position| is not a : U+003A COLON character, then return an error and abort these steps. Otherwise, move |position| forwards one character.
If |string| is not exactly two characters in length, return an error and abort these steps.
Interpret |string| as a base-ten integer. Let |value3| be that integer.
Otherwise (if |most significant units| is not hours, and either |position| is beyond the end of |input|, or the character at |position| is not a : U+003A COLON character), let |value3| have the value of |value2|, then |value2| have the value of |value1|, then let |value1| equal zero.
If |position| is beyond the end of |input| or if the character at |position| is not a . U+002E FULL STOP character, then return an error and abort these steps. Otherwise, move |position| forwards one character.
If |string| is not exactly three characters in length, return an error and abort these steps.
Interpret |string| as a base-ten integer. Let |value4| be that integer.
If |value2| is greater than 59 or if |value3| is greater than 59, return an error and abort these steps.
Let |result| be |value1|×60×60 + |value2|×60 + |value3| + |value4|/1000.
If |negative| is true, let |result| be 0 - |result|.
Return |result|.
CSS Extensions
This section specifies some CSS pseudo-elements and pseudo-classes and how they apply to WebVMT. This section does not apply to user agents that do not support CSS.
Introduction
The ::cue pseudo-element represents a cue.
The ::cue(selector) pseudo-element represents a cue or element inside a cue that match the given selector.
Similarly to all other pseudo-elements, these pseudo-elements are not directly present in the <video> or <audio> element’s document tree.
A WebVMT node object is a conceptual construct used to represent components of cue metadata so that its processing can be described without reference to the underlying syntax.
Processing Model
Pseudo-elements apply to elements that are matched by selectors. For the purpose of this section, that element is the matched element. The pseudo-elements defined in the following sections affect the styling of parts of WebVMT cues that are being rendered for the matched element.
A CSS user agent that implements the text tracks model must implement the ::cue and ::cue(selector) pseudo-elements.
The ::cue pseudo-element
The ::cue pseudo-element (with no argument) matches any WebVMT node objects constructed for the matched element.
The following properties apply to the ::cue pseudo-element with no argument; other properties set on the pseudo-element must be ignored:
stroke
stroke-opacity
stroke-width
fill
fill-opacity
The ::cue(selector) pseudo-element with an argument must have an argument that consists of a CSS selector. It matches any WebVMT node object constructed for the matched element that also matches the given CSS selector.
The following properties apply to the ::cue() pseudo-element with an argument:
stroke
stroke-opacity
stroke-width
fill
fill-opacity
Properties that do not apply must be ignored.
CSS Cascades
For the purpose of determining the cascade of the declarations in STYLE blocks of a WebVMT file, the relative order of appearance of the style sheets must be the same order as they were added to the collection, and the order of appearance of the collection must be after any style sheets that apply to the associated <video> or <audio> element’s document.
Known Issues
This section captures issues which have been identified, but are not yet fully documented.
As the specification develops, issues will be moved out of this section and included elsewhere in the document, until it is no longer needed and is completely removed.
Planned Features
This section lists potential features which have been identified during the development process, but have not yet matured to a full design specification.
Features which appear in this section warrant further investigation, but are not guaranteed to appear in the final specification.
Markers
An image linked to and displayed at an offset from a geolocation.
Labels
A text string linked to and displayed at an offset from a geolocation.
Tile Shortcuts
Shortcuts to popular tile URLs for easy access and to help avoid URL syntax errors.
Layers
Syntax to allow more than one layer of map tiles to be specified, e.g. 'map' and 'satellite' layers.
This should be functional, but remain lightweight.
Multiple APIs
The current tech demo is based on the Leaflet API, but should be broadened to support other web map APIs, e.g. Open Layers.
A hot-swap feature would allow users to switch API on-the-fly to take advantage of the unique features supported by different APIs, e.g. Street View.
Camera Direction
Camera orientation may not match the direction of travel, or may be dynamic, e.g. for Augmented Reality. Field of view and zoom level also affect video frame content and may vary over time.
Co-ordinate Reference Systems
Although originally conceived for Earth-based use, spatial data in other environments could be accommodated by specifying the co-ordinate reference system. For example, location on another planet, e.g. Mars, or in an artifical environment, e.g. a video game.
Moving Objects
WebVMT paths represent objects moving through the mapped space, though could be extended to support properties associated with motion such as distance travelled, speed, heading, etc. through a defined API.
WebVMT zones represent regions in the mapped space, which could be extended to support WebVMT path properties for their centroid's motion and include dynamic properties such as area and volume.
Care should be taken to build a lightweight interface which includes simple, common properties that are useful to most use cases and avoids overloading with unnecessary edge cases, processing overheads and complexity.
Height Reference
In addition to height above the WGS84 ellipsoid, an option could be added to measure altitude from mean sea level, e.g. for an aircraft, using a suitable Earth Gravitational Model (EGM) or from ground level, e.g. for the height of a structure.
Planned Interfaces
This section lists interfaces which have been identified during the development process, but have not yet matured to a full design specification.
This registration is for community review and will be submitted to the IESG for review, approval, and registration with IANA.
Type name:
text
Subtype name:
vmt
Required parameters:
No parameters
Optional parameters:
No parameters
Encoding considerations:
8bit (always UTF-8)
Security considerations:
Text track files themselves pose no immediate risk unless sensitive information is included within the data. Implementations, however, are required to follow specific rules when processing text tracks, to ensure that certain origin-based restrictions are honored. Failure to correctly implement these rules can result in information leakage, cross-site scripting attacks, and the like.
Interoperability considerations:
Rules for processing both conforming and non-conforming content are defined in this specification.
Published specification:
This document is the relevant specification.
Applications that use this media type:
Web browsers, other media players and location-aware video devices such as drones, dashcams and smartphones.
Additional information:
Magic number(s):
WebVMT files all begin with one of the following byte sequences (where "EOF" means the end of the file):
EF BB BF 57 45 42 56 4D 54 0A
EF BB BF 57 45 42 56 4D 54 0D
EF BB BF 57 45 42 56 4D 54 20
EF BB BF 57 45 42 56 4D 54 09
EF BB BF 57 45 42 56 4D 54 EOF
57 45 42 56 4D 54 0A
57 45 42 56 4D 54 0D
57 45 42 56 4D 54 20
57 45 42 56 4D 54 09
57 45 42 56 4D 54 EOF
(An optional UTF-8 BOM, the ASCII string "WEBVMT", and finally a space, tab, line break, or the end of the file.)
File extension(s):
"vmt"
Macintosh file type code(s):
No specific Macintosh file type codes are recommended for this type.
Person & email address to contact for further information:
Rob Smith <rob.smith@awayteam.co.uk>
Intended usage:
Common
Restrictions on usage:
No restrictions apply.
Authors:
Rob Smith <rob.smith@awayteam.co.uk>
Change controller:
W3C
Fragment identifiers have no meaning with text/vmt resources.
Privacy and Security Considerations
Text-Based Format Security
As with any text-based format, it is possible to construct malicious content that might cause buffer over-runs, value overflows (e.g. string representations of integers that overflow a given word length), and the like. Implementers should take care in implementing a parser that over-long lines, field values, or encoded values do not cause security problems.
Styling-Related Privacy and Security
WebVMT can embed CSS style sheets, which will be applied in user agents that support CSS. Under these circumstances, the privacy and security considerations of CSS apply, with the following caveats.
Such style sheets cannot fetch any external resources, and it is important for privacy that user agents do not allow this. Otherwise, WebVMT files could be authored such that a third party is notified when the user watches a particular video, and even the current time in that video.
It is possible for a user agent to offer user style sheets, but their presence and nature will not be detectable by scripts running in the same user agent (e.g. browser) since the CSS object model for such style sheets is not exposed to script and there is no way to get the computed style for pseudo-elements other than ::before and ::after with the getComputedStyle() API.
Scripting-Related Security
WebVMT does not include or enable scripting. It is important that user agents do not support a way to execute script embedded in a WebVMT file.
However, it is possible to construct and deliver a file that is designed not to present timed metadata, but instead to provide timed input (‘triggers’) to a script system. A poorly-written script or script system might then cause security, privacy or other problems; however, this consideration really applies to the script system. Since WebVMT supplies these triggers at their timestamps, a malicious file might present such triggers very rapidly, perhaps causing undue resource consumption.
Location-Related Security
WebVMT provides a common format in which to share location data synchronized with video for the web. Proper consideration should be given to any sensitive details that may be revealed as a result of sharing such personal information. For example, posting a geotagged image online can reveal the location of the content creator at a particular time which can infer their absence from distant locations since travelling takes time. The identities of people who appear in video frames may be determined visually to also reveal their presence at a nearby location or their absence from a distant one.
In order to share content responsibly, users should consider:
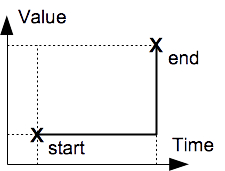
Comments
Comments are blocks that are preceded by a blank line, start with the word
NOTE(followed by a space or newline), and end at the first blank line.Comment Block
Comment block format is identical to WebVTT.
WEBVMT NOTE Associated video MEDIA url:/home/myuser/movies/TowerLandmarks.ogg mime-type:video/ogg NOTE Map config MAP lat:51.506 lng:-0.076 rad:500 NOTE Tower Bridge 00:00:01.000 --> 00:00:05.000 { "move-to": { "lat": 51.504362, "lng": -0.076153 } } { "line-to": { "lat": 51.506646, "lng": -0.074651 } } NOTE City Hall 00:00:02.000 --> { "circle": { "lat": 51.504789, "lng": -0.078642, "rad": 20 } } NOTE Tower Of London This line is also part of the comment 00:00:03.000 --> 00:00:04.000 { "polygon": { "perim": [ { "lat": 51.507193, "lng": -0.074844 }, { "lat": 51.508756, "lng": -0.074716 }, { "lat": 51.509036, "lng": -0.075638 }, { "lat": 51.508929, "lng": -0.077162 }, { "lat": 51.507727, "lng": -0.077848 }, { "lat": 51.507220, "lng": -0.075767 } ] } }