WebPerf WG @ TPAC 2021
Logistics
When
October 25-29 2020 - 8am-11am PST
Registering
- Register! https://www.w3.org/2021/10/TPAC/Overview.html
- Free for WG Members and Invited Experts
- If you’re not one and want to join, ping the chairs to discuss (Yoav Weiss, Nic Jansma)
Calling in
Attendees
- Yoav Weiss (Google)
- Nic Jansma (Akamai)
- Lucas Pardue (Cloudflare)
- Subrata Ashe (Salesforce)
- Nicolás Peña Moreno (Google)
- Michal Mocny (Google)
- Patrick Meenan (Google)
- Andrew Comminos (Facebook)
- Ilya Grigorik (Shopify)
- Boris Schapira (Contentsquare)
- Noam Helfman (Microsoft)
- Giacomo Zecchini
- Ian Clelland (Google)
- Addy Osmani (Google)
- Noam Rosenthal
- Steven Bougon (Salesforce)
- Wooseok Jeong(Facebook)
- Caio Gondim (The New York Times)
- Tim Dresser (Google)
- Scott Gifford (Amazon)
- Colin Bendell (Shopify)
- Sérgio Gomes (Automattic)
- Howard Edwards (Bocoup)
- Courtney Holland (Bocoup)
- Simon Pieters (Bocoup)
- Carine Bournez (W3C)
- Scott Haseley (Google)
- Paul Calvano (Akamai)
- Andy Davies (SpeedCurve)
- Katie Sylor-Miller (Etsy)
- Andrew Galloni (Cloudflare)
- Tim Kadlec (WebPageTest)
- Cliff Crocker (SpeedCurve)
- Annie Sullivan (Google)
- Alex Christensen (Apple)
- Nitin Pasumarthy (LinkedIn)
- Prasanna Vijayanathan (Netflix)
- Thomas Steiner (Google)
- Sean Feng (Mozilla)
- Vaspol Ruamviboonsuk (Akamai)
- Benjamin De Kosnik (Mozilla)
- Leonardo Balter (Salesforce)
- Philip Walton (Google)
- Aram Zucker-Scharff (The Washington Post)
- Matthew Ziemer (Pinterest)
- Utkarsh Goel (Akamai)
Agenda
Times in PT
Monday - October 25
Timeslot (PST) | Subject | POC |
8:00-8:30 | Yoav, Nic | |
08:30-9:00 | Nic, Yoav | |
9:00-9:30 | Noam Rosenthal | |
9:30~9:45 | Break | |
9:45-10:30 | Noam Rosenthal | |
10:30-11:00 | Yoav |
Recordings: NavigationTiming and cross-origin redirects, Preload cache specification, Measuring preconnects
Tuesday - October 26
Timeslot | Subject | POC |
8:00-8:30 | Fergal | |
08:30-9:00 | pagevisibility and requestIdleCallback: move processing to HTML? | Noam Rosenthal |
9:00-9:30 | Nic Jansma | |
9:40~9:55 | Break | |
9:45-10:30 | Yoav | |
10:30-11:00 | Michal |
Recording: BFCache, RUM pain points, Measuring SPAs
Wednesday - October 27
Timeslot (PST) | Subject | POC |
8:00-8:30 | Nic Jansma | |
08:30-9:00 | Noam Helfman | |
9:00-9:30 | Addy Osmani Pat Meenan | |
9:30~9:45 | Break | |
9:45-10:30 | Andrew Comminos | |
10:30-11:00 | Xiaocheng Hu |
Recording: zstd in the browser, responsiveness in Excel, Optimizing 3P script loading, JS profiling improvements, renderblocking attribute
Thursday - October 28
Timeslot (PST) | Subject | POC |
8:00-8:30 | Yoav | |
08:30-9:00 | Yoav | |
9:00-9:30 | Thomas Steiner | |
9:30~9:45 | Pet camera break | |
9:45-10:30 | ||
10:30-11:00 | Yoav |
Recording: Content negotiation and Client Hints, User preferences media features, Personalizing Performance, LCP updates
Sessions
Intros, code of conduct, agenda review, meeting goals - Nic, Yoav
Minutes
- TPAC 2021!
- Yoav: Missing: Provide methods to observe and improve aspects of application performance of user agent features and APIs
- ... Notable highlights including tighter integration with Fetch and HTML
- ... Spec cleanup improve processing models and align better with Fetch/HTML
- ... A/B testing meeting last Feb which had a lot of insights from industry at large
- ... Helped bridge gaps between different parts of the industry. Hoping to see results at some point.
- ... Help from W3C folks to setup auto-publishing and auto-tidying. Helps smooth over day-to-day friction in publishing specs
- ... 168 closed issues on different Github repos
- ... Rechartered takes us until 2023
- ... Incubations
- ... Talk more about incubations tomorrow
- ... Seeing if we're interested in adopting them more officially
- ... All seeing an increase in adoption

.png)
- ... Working group having a direct impact on users
- ... New members!
.png)
- ... Housekeeping and Code of Conduct
.png)
- ... Recording presentations and publishing the videos
- ... Would appreciate secondary scribes
- ... Yoav and Nic will take turns with minuting
- ... Once in a while we lose a sentence or the speaker has moved on and we're behind in scribing
- ... Having someone to take on as secondary scribe is extremely helpful
- Quick overview of scribe requirements… capture sentiment and cover when Nic/Yoav are talking.
WG introspection - Nic
Summary
- Rotating meeting times can help folks in different TZs
- Discussion summaries and WG updates can keep the broader community informed. Also created Slack/Matrix channels for comms.
- There’s interest in expanding the discussion scope, assuming we can navigate IPR
Minutes
- Nic: Want to see where we are as a group.
- … Slides meant to facilitate discussion - feel free to bring up ideas
- … The WG has 94 participant across 20 organizations
- … Decent increase in participation
- Stats: 94 participants (signups), 20 organizations, 4 invited experts
- Increase in participation over time
- How can we improve?
- Diversity, Meeting Times, Newsletter, Social Media/Twitter engagement, Discussion Scope, …
- Diversity:
- Want to promote diversity of people, voices, genders, companies and locations
- Want to reduce barriers as much as possible
- TimeZones - have a US/EU focus, but times are more US friendly. A recurrent point of feedback
- Cost of participation - may be interesting to see if it stopped folks from participating.
- A lot of people may be volunteered or only partially supported by their employer. Maybe we can better highlight accomplishments to make that easier
- Technical history can be daunting
- Meeting times - currently 1pm EST 10am PST. 7pm for EU, middle of night for Asia
- One thought is to have an alternating cadence to make it easier for EU folks. E.g. maybe 2 hours earlier
- Doesn’t help with China and Japan
- Any thoughts?
- Cliff: Are meetings recorded?
- Nic: In the past we were able to record the full meetings. Currently we only record presentations with no discussions, due to W3C process changes. We have minutes.
- Dan: What are other teams doing? What day is the group meeting?
- Nic: Thursdays. Other groups have most of the participants be US based.
- Yoav: From what I've seen in other groups it's mostly US centric. Early US West
- NoamR: Rotating 2 hours earlier would be significantly better for IL TZ
- Nic: Any concerns from US folks?
- Nic: Should we do a poll?
- Note: Available at https://docs.google.com/forms/d/1jkZPL8BjsN112uJi75DO2n0RnaSCVc_5Uft66hxoGIE/edit
- Yoav: One option is rotating. Another option is if US West are open to 2 hrs earlier.
- Nic: That doesn’t solve Asia though.
- NoamR: If we have a particular participant from Asia, we can have a one-time meeting that is better for those timezones.
- Nic: Great idea. Will follow up with a poll
- .. Newsletter
- … meeting minutes take a while to digest. This suggestion is for a quarterly updates coming from the group. Could allow folks that can’t keep up with the day to day to get a glimpse of what the group is working on
- … Would require work, but maybe presenters can create blurbs of their presentations and discussion conclusions
- Michal: Like the idea of a newsletter but curious about the intended audience. Is it for ourselves or for an external audience. Are other WGs doing that?
- Nic: Not aware of other WGs doing that.
- Carine: We had WGs that had their own updates. Preferred way is to publish a blog post on the W3C blog
- Yoav: What I've done in the past for TPACs is have a 3-line summary for what was presented, discussion and conclusions. This was driven a lot by folks presenting. Makes sense to extend this to bi-weekly presentations. Once in a while wrap them up into a digestible form.
- ... Michal to answer your question I think it can be useful for ourselves, to see discussions without reading minutes
- ... But more for external audiences to see what we're discussing and see if they want to be part of that discussion
- Cliff: One thing that could be nice when trying to read the summary, is reading arguments before/against. Any time you're trying to read through things, it's useful to see arguments. Could be useful for a broader audience where english is not primary language or not as technical.
- Nic: Would be helpful to have the initiator/presenter to do that work that day, and the chairs can commit to organize that later on. (rather than the chair trying to summarize).
- … We could try it and see what it gives. For last year’s TPAC we had presenters summarizing. We can try it and see
- NoamH: Good idea. Personally had questions from my org where folks wanted highlights from the WG, and had to write them himself. Having this would be useful.
- Nic: Agree it’d be nice to have an easy place to point out things that can be later shared with internal orgs.
- … Followup: we’ll try to do that and see how it goes
- ... Social media!
- … Trying to use it again, mostly around notifications for meetings, minutes available, etc
- … Share updates with the community
- … Worthwhile to have a slack channel for the webperf WG on the webperformance slack?
- Anne: Matrix
- Yoav: Any appetite for a Matrix channel?
- NoamR: Matrix makes more sense
- Andy: Depends on who you want to reach
- Nic: we could have channels on both and see what happens. Let’s give that a try
- Yoav: both makes sense
- Yoav: We've been talking with a few folks to see how we can improve things and make it more interesting
- ... One point of feedback was that current discussions are highly focused on WG deliverables, mostly around webperf measurement
- ... Somehow we have less ways of discussing improving performance
- ... Less deliverables that touch on that
- ... I thought we could instead of limiting discussion scope to WG deliverables to somewhat expand it and discuss work that is impacting web performance, happening in WHATWG/WICG and elsewhere
- ... Reach out to other working groups
- ... Generally have a more working group opinion on things happening in webperf space instead of focusing just on deliverables
- ... WDYT about discussion scope expansion? Shouldn't impact charter or deliverables, just things we would be discussing in WG that we wouldn't discuss otherwise
- ... Benefits for us could make it more interesting. Benefits for broader platform is it could bring our expertise to other discussions where we're not necessarily seeing it right now, i.e. in HTML spec. Right now a missed opportunity.
- Dan: I think it's a good idea, the collected expertise of the members in this group would be a shame to waste. A lot happening in field right now going beyond scope of standards. Impacting how people use the platform. So I'm definitely in favor.
- Yoav: Maybe I'm wishful hearing, are you suggesting expanding the scope to userland issues (framework) or is that overreach?
- Dan: Framework issues can be a really touch subject and could be political
- ... Userland tendencies and approaches yes
- Carine: I'm wondering if we should open W3C CG to see if they want to pair on that sort of stuff. Going too far from charter we could have IPR problems. Others might think we're doing too much incubation and not other activities like testing and going to REC.
- ... Pair with another CG and see how it goes
- Yoav: Could be interesting in terms of other working groups like Immersive Web where they have a similar model. Do you know what they're doing there, and would it make sense to split discussions, once a month CG and once a month WG.
- Carine: Immersive Web was predating WG. They were in CG first and moved to WG.
- ... There are possibilities of doing more incubation and doing more outreach
- Michal: I thought you said it was already in the charter and we haven't done this enough, and that was the feedback rather than expanding.
- Yoav: Wasn't thinking of expanding the charter. Not part of deliverables.
- ... One specific example in group's expertise would've been useful, for lazyloading on HTML I think there were this working group should've provided more feedback on and haven't.
- ... That's work happening in HTML, so a WebPerf CG wouldn't have helped there
- ... What I'm thinking is essentially bring up subjects to this group where members of this group can discuss, and as a groups we can provide feedback on relevant issues to e.g. HTML or other specs
- ... And if that feedback is targeted at WICG I think that is fine, working group members are probably also WICG members.
- Anne: Could be sketchy from WHATWG side.
- Yoav: If someone provided feedback on WG call and they're not a WHATWG member, that could be problematic.
- Yoav: Would give this more thought. A CG won't help either, as the CG will have IPR commitment but won't be WHATWG members.
- Carine: Except that it's not limited to W3C membership
- Philippe: Let's say there's a HTML proposal that happens in WICG and gets a PR for WHATWG, how do you guys handle it?
- Anne: There is a risk there that's assessed on a case-by-case basis.
- Philippe: IPR on contributions but not on the whole. Better than nothing. There's a risk but it's somewhat limited
- Yoav: Let me think through the IPR risk here, a broader question is is there interest for these discussions to happen on the WG calls.
- Pat: I have a vested interest, but I don't know there are other WGs that in incubation phase would be brainstorming and working through issues. WHATWG works off PRs and issues.
- ... Not aware of another WebPerf group other than this one. It does help to have broad industry commitment and contribution early in brainstorming phase around gaps, working across browsers, privacy, developers, etc
- ... e.g. Preload
- Anne: More review on WHATWG side would be welcome. Good to have other people from different perspectives on these PRs.
- Yoav: Take an AI to figure out if this is a mess from IPR perspective, and think through ways we could bring in those issues from HTML/Fetch/etc for the group to discuss.
Navigation Timing and cross-origin redirects - Noam Rosenthal
Summary
- Navigation Start being the time origin exposes cross-origin information, about the length of the time before the user reached the document’s origin. This is a problem, however any change to this would incur a lot of implications on the baselines of tests and on the usefulness of RUM testing in certain situations.
- It is not clear how to proceed, Though some suggestion were brought up such as allowing same-site redirects to still be exposed in this way.
- The conversation was missing people from the security/privacy space to weigh in on the implication of keeping things as they are.
Minutes
- Noam: Starting with a controversial topic! Navigation Start Time
- ... Polarized discussion on the issue
- ... From HR time spec
.png)
- ... When you click a link or submit a form, not necessarily the same origin as where you're going
- ... Time Origin is our 0 / epoch for everything
- ... All of our PerformanceTimeline numbers are based on that, performance.now() uses that as its origin
- ... Point in time where user started navigation somewhere
- ... Takes us to a X-O issue with this
.png)
- ... Lets say a user navigates using address bar to site-a.com
- ... site-a.com sends 302 to site-b.com
- ... Exposed Cross-Origin time
- ... "Prehistory" before I know what happened. I know how long it took but not what happened at all.
- ... Not the only case
.png)
- ... site-a.com submits a form to site-a.com, on POST send back a new Location to site-b.com
- ... So Pre-History is exposed, maybe on site-b.com I can detect there was a POST
- ... Doesn't have to be a redirect, because navStart happens before a bunch of events, unload/pagehide/vischange, those are fired after navigation start
- ... So any time spent on some site that runs those events would be noticed by that Prehistoric time on site-b.com
- ... All of those are combined, so Prehistoric time is a cloud of different things
.png)
- ... unload/pagehide/vischange, submit, redirects, etc
- ... Things the destination can figure out
.png)
.png)
- ... For RUM there's also random things influencing the numbers
.png)
- ... Malicious effects on other site's loading times by sending users with long redirects
- ... Graph between potentially harmful vs. potentially useful:
.png)
- ... Conclusions
.png)
- ... Two main options
.png)
- ... Option 1 is to stay the same, too late to change, would affect epoch and have comparison challenges
- ... Option 2 is to move time origin to redirect start time of current origin. I just don't know if I was redirected here by something that took a long time.
- ... If this is something we want to change, how would we ship this?
.png)
- Yoav: RUM is Real-User Monitoring, apps and dashboards that reflect the user performance and would be affected by this change. If we changed timeOrigin in this particular version of this browser that shipped this change, all impacted metrics affected by X-O redirects or other events, would move down which seems like a perf improvement but would result in confusion
- Noam: One option that I forgot to put in slides is to change resolution to timeOrigin that's very coarse, but still helps provide the time to get here
- ... Could help fix some of the issues with session sharing, but not share sensitive information
- Anne: I think that exposing the time of navigation is also possibly a problem. Once we've implemented various anti-tracking policies, the timing allows these two origins to do some correlation
- Yoav: Agree this is a future problem, not a current problem. I think Jan pointed out current problems with what we are doing now, specifically referrer guessing. Because referrer A uses a slow redirector and referrer B uses a fast redirector, you could guess which one.
- ... From my perspective that leads me to believe that we should fix this, but interested in the "how can we ship this discussion"
- Anne: I think if we come up with a solution it better take that into account. If we're making a change, make it once.
- Sergio: Provide an example that it's not particularly useful. In production at Automatic, we host wordpress.com and people have subdomains of wordpress.com. We set up RUM with monitoring based on NavTiming. Looked for pages with slow DNS times. domainLookupEnd
- ... Saw a lot of those in a couple pages, this isn't happening in DNS, it's happening before that.
- ... Happening if you type if you picked a wrong subdomain, you go to wordpress.com/typo. We found this through our logs that we found multiple levels of redirects, and caused people to take a lot of time landing on the final page.
- ... We've been able to mitigate some of this by removing a few HTTP to HTTPS redirects
- ... Been able to mitigate a real perf problem for users from this API
- ... Not saying this problem doesn't have privacy issues or shouldn't be fixed
- ... We wouldn't never been able to think to add e.g. TAO headers to find this problem
- ... Maybe have a coarse number to define how much time was spent before navigation, or a "there were redirects"
- Noam: Could we assume some of the redirects were Same Site?
- Sergio: Possible, but in this particular instance it's subdomains that don't exist
- ... Could be from custom domains or auth flows or redirect flows for things like OAuth
- ... There's a category of performance issues that would become invisible unless you have the right headers set for every request
- Noam: For this particular problem you don't need every request to have the right headers, unless the earliest one has the right headers
- Sergio: That's correct, there are a few issues as the metric definitions would change based on whether the headers would be set or not
- ... I just wanted to bring up this example showing where this info was useful
- Andy: I get why we want to change it. Removing what that time does is it removes the reflection of User Experience. Losing long redirect times changes how e.g. the experience of LCP is reported
- Yoav: I think it's interesting to think of this as a two-part problem: How can we fix the current problem, how can we ship something that doesn't break dashboards. Part two is how we can re-expose that information in a safe way. Sounds like there's an appetite for part two.
- Andy: Value in knowing that data, that time
- Scott: One question about discussion is, are you just thinking about moving navigationStart or adjusting redirectStart/redirectEnd or unloadStart/unloadEnd. So right now navigationStart is the only way to gather information for X-O pages.
- Noam: redirectStart/End is under-specified, go to this problem by trying to specify it
- ... If we choose to live with current situation, which I don't think we can, we might as well expose it
- ... But first of all I want to start with epoch
- ... That information is the hardest to change
- Scott: What we use some of the data for in same-origin, redirects and unload times we've had real actionable data to drive those down
- ... Other is that domains for a large company is complicated, many TLDs
- ... Reason why solving this could lose data for optimizing user experience
- Yoav: You'd need something like First Party Sets or something
- Pat: A lot of what we've heard so far, but I'd be really concerned that the performance measurements wouldn't be usefully representative of the UX. As far as the loading from when they took an action until anything.
- ... Canonical problem case is an ad placed somewhere on 3P site or AdWords that has click-trackers, and marketing team adds trackers for the site, you lose ability to see the UX is bad
- ... I think we'd be blowing up the usability of the loading metrics
- Yoav: One thing we could do as a bandaid is we could block this information if Referrer policy says we should block it
- Katie: To add to data points where it's valuable, just last month we used abnormally long prefetch times to find traffic from a scraper/bot. We saw huge spikes in RUM from page load time. A lot of these data points have abnormally large before-Fetch. We used that point to track down other signals that it's a scraper/bot that we could block from our RUM collection.
- ... I'll also add that it's a little confusing sometimes that with this data, you see the problem from these redirects on the following page, not the source page. We saw problems from the checkout page on our home page. Changes happened on the checkout page, but metrics were not showing them in the checkout page, but on the next one.
- ... Not always intuitive to use, but there's value to knowing that and to uncover bugs and bad experiences
- ... Does measure something of value to users
- NPM: Sounds like there's a lot of people that think the data is valuable. Is this an urgent problem to fix?
- ... Doesn't seem like the solutions would work for the discussed use-cases
- Noam: I don't think this is urgent to fix, but I ran into it. By coarsening the numbers, the averages and big problem could be useful for people, but harder to track. Could be bandaid to problem, can't correlate click-time on navStart on millisecond to see it's the same user.
- Yoav: Agree it's not necessarily urgent, but there is at least one problem we know of. For sites that have Referrer policy, that could be used to infer which site linked to. Seems like a cross-origin leak that we should fix once, ideally.
- NPM: Can you explain the Referrer issue?
- Yoav: Your traffic is coming from two major sites. Both don't send Referrer. One has a fast redirector and the other has a slow redirector. You'd be able to tell which of the two sites sent traffic based on timing.
- ... Don't know how realistic that scenario is or urgency
- ... More future-facing scenario where we don't want Site-A communicating userID to Site-B. navigationStart and click time could help them communicate bits of information between two sites.
- ... Ideally we would want to minimize the amount of bandaids here and come up with a real solution
- Noam: I suggest we continue this on Github issue
- Yoav: What is the size of the impact on dashboards?
- Nic: baseline changes cause confusion. This is a thing that will happen incrementally, and would not be able to compare the metrics.
- … Will change all the metrics. Would definitely be a big concern
- … As a counter point, some customers excluded all the “pre-historic” data, because they don’t care about that. So some of them choose to start at fetchStart
- Cliff: +1. It would be extremely disruptive, so we have to be very careful rolling this out.
- Nic: Some corps may have millisecond goals to their metrics, and changing the baseline would require communication
- Cliff: Same challenge with synthetic. RUM can be trusted, so changes can be disruptive
- Dan: There were changes to CWVs over the past couple of months, so if communicated appropriately and correctly, it’s something that people can deal with.
- Noam R: The forum of this conversation that are into performance rather than privacy. We should talk about it with both teams in the room. People can bring valuable information about attack vectors from that works.
Preload - Noam Rosenthal
Summary
- Preload cache is not specified, leading to a lot of different behavior across browsers.
- It was pointed out that preload headers should be supported alongside link headers.
- The Pull request for this is underway.
Minutes
- Noam: Conversation about preload - issue #590
- … Came from an investigation of what preloads are and what they should be
- … Premise - fetch early something you’d use later
- … Avoiding a situation where things you know you need to load are delayed - a good problem to solve
- … But the premise doesn’t go into the details
- … 3 topics:
- … availability - once you loaded the resource, is it available forever, for any request, in workers?
- … caching - should preload interact with cache headers? What does it mean to expire? Can it expire before it loads?
- … error handling - preloaded the resource and it’s an error, should you try to reload before use? If it’s not a network error, but an image you can’t decode? 404?
- … Not theoretical issues, but implemented very differently between the different browsers. Resources errored in preload will be fetched again. Same for undecodable images. Preload with fetch is inconsistent.
- … Chrome optimizes for next request, Chromium will keep the preload for the next request, but not after that (beyond HTTP cache)
- … It’s not necessarily a huge issue for users as the worst case is a double request, but getting it to work across browsers is difficult. You can improve performance in one browser and hinder it in another.
- … Possible solutions, trying to have a simple definition:
- … naive early load - fetch the resource and count on the HTTP cache to keep the response.
- … Could result in double requests if the HTTP cache evicted
- Type specific resource cache - uses the `as` value and adds it to the list of loaded images. Problem here is that un-decoded images can double download.
- ... Also that type-specific cache would need to be specified
- … Strong Cache - similar to the Cache object of SW, and ignore caching headers. Equivalent to having the link header hold the response, and have future element reuse that response before calling the Fetch algorithm. Need to be careful with workers.
- Similar to having a cache object is a SW, we return the response regardless of if it’s an error, etc
- Yoav: One thing about Chromium implementation is the memory cache as a fallback for Preload cache. Some things are kept in the memory-cache that may not go to the HTTP cache. One of the benefits of that architecture in Webkit and Chromium, is that the HTTP cache has more overhead. Having a close-by cache is beneficial vs. loading things into HTTP cache and hoping for the best
- Noam: See memory cache similar to HTTP cache, it interacts with cache headers.
- Yoav: To some extent
- ... It's equivalent to Webkit Resource Cache
- ... Memory Cache is also not well defined, possibly another issues
- Dan: I don't know how important it is to discuss, but when would something NOT be in Preload Cache but would be in Memory Cache.
- Yoav: Chromium-specific, after first request is hit (preload with IMG tag using preload), resource is no longer in Preload cache but resource is maybe in Memory cache, assuming another element is holding it
- Noam: Preload is a "strong cache" for one hit
- Dan: Memory cache doesn't necessarily respect Cache headers?
- Yoav: Correct, it's a weak cache so if no element is holding that resource, it's gone from the cache. Respecting some cache headers but not all, e.g. no-store. Maybe some variant of Vary header. Won't necessarily respect Caching lifetimes. Considered since it's loaded in document once, it can be used in same document again even if it's expired
- Anne: What are the conceptual problems with trying to merge those caches, Memory and Preload Caches
- ... It would no longer be one-time-use, is that a problem?
- Yoav: How cache started in Chromium, Preload cache is version of Memory cache
- Pat: Semantics are different from just one-use, ignores no-cache etc. Preload allows you to re-use that one-time-only API, where Memory Cache wouldn't cache it at all.
- Anne: Primarily around Fetch and XHR calls?
- Pat: Script returning different content for a URL, e.g. ad
- Yoav: JSONP scenario
- Noam: Many of those scenarios I wouldn't expect them to use Preload
- Anne: Resource Cache is fairly limited, its scope is wider. e.g. a stylesheet could be cached in one document and re-used in the next document. Where Preload is scoped to a document?
- Pat: Yes
- Yoav: Because Memory Cache is a weak cache, it should evict resources
- Anne: If you keep current document open and navigates to a new tab, it could re-use
- Yoav: If same renderer
- ... With a new process you may have to go to the HTTP Cache
- Dan: Seems to me the bigger distinction is that Preload is not just caching, then it's also parsing or additional action for various types of resources, not just loading into memory as-is
- Anne: That might not be observable, up to implementations
- Dan: Optimization that you may or not notice
- Yoav: It is web-exposed, things not in Memory Cache don't have ResTiming entries
- ... If you go to the HTTP Cache you do trigger them
- Dan: Seems to be a significant implementation distinction in browsers between Memory Cache and Preload Cache.
- Noam: That problem is what can create several network requests in scenario of invalid image and things
- Dan: Exactly if you don't parse the image or script you don't know it's invalid
- Simon: Related topic, speculative HTML parsing. Is that considered in this realm of things.
- Yoav: Related, they're cache in Memory Cache. Slightly different rules between WebKit and Chromium
- ... Initially Preload Cache was just another case of speculative parsing we're using Memory Cache for, later changed in Chromium
- Simon: In Memory Cache for speculative parsing, there is no reference for the resource
- Yoav: No reference to the element
- Anne: Maybe there's ways where we can merge concepts but keep the same behavior? If something was entered into this cache due to Preload it has a one-time flag. Flag can be considered for different scenarios.
- Pat: One case is if you have link rel=preload, and you remove the link, does it stay in Memory Cache or does it get removed?
- Noam: Yes removed, possibly in HTTP Cache
- Anne: There with a one-time flag?
- Pat: But the link was what put it there with a one-time flag
- Anne: I think you can make an argument either way
- Noam: If we create a semantic where link tag is responsible for reference, you can remove link tag when you no longer want to use it
- ... Remove it when ready
- ... Definitely be better to specify that's what it does and have platform tests
- Pat: Removing the link tag as the forced condition for the one-time would be a problem for header-based preloads
- Noam: Is header Preload in use?
- Pat: Yes, mostly from HTTP/2 Push
- Simon: On topic of removing resource from Preload cache when you remove <link> element, I know of a pattern where you use rel=preload and you change the rel attribute to stylesheet
- ... Shouldn't prune resource immediately
- Anne: Do you consider resources not having RT entries a bug? Seems like a bug
- Yoav: If we added it, almost all resources would have two RT entries. Due to speculative preloads we don't want two entries at least. For preload as well, I wouldn't consider it a problem. If it was used there was no request going out from renderer
- Noam: Bug is that resource cache isn't specified
- Anne: You could end up with a document where it doesn't see any RT entries because of sibling documents. Agree with deduping for some, but maybe not entirely.
- Yoav: Have possibly at least one entry in a document
- Alex: I recently fixed some RT bugs in this area, one of the WPT tests would speculatively parse the HTML it receives and then speculatively fetch script, put in Memory Cache and look at RT data for that
- ... I used the RT of the real network fetch, but then if you fetch it again it says 0ms
- ... Because it did actually go to the network at some point. But seems like it's not well specified
- Yoav: Is that Preload or speculative preloading in general
- Alex: Speculative preloading based on HTML parsing
- Noam: Thanks for the one-time semantics explanations. I’ll try to specify something in that area that matches what browsers do
- … errors? We can specify that once the rest is specified
- … about HTTP errors, that’d have to be part of the spec
- … IMO, errors should be forwarded
- Anne: you might want to test this. We can render 404 images, if they were actual images. Not sure it’s cached
- … Otherwise, some browsers have XSS checks for some images. Further questions for CSS (e.g. if it doesn’t have the right mime type)
- Simon: For images, per spec it doesn’t put an image in the cache if it’s not a valid image. We’d only cache successful images. Maybe we can change that. Not sure browsers follow that.
- Noam: In preload they do, but maybe for 2 out of 3 browsers
- Anne: At least in Firefox preload hooks into existing caching infrastructure, which can explain some observations.
- Noam: We should either go resource specific, or go towards a generic cache. It can be resource specific, but we need to specify it.
- Anne: There are a couple of types where there’s a spec, but otherwise there isn’t
- Yoav: Memory Cache distinguishes destinations where HTTP Cache doesn't
- Pat: Those are spec'd in Sec-Fetch-Dest?
- Yoav: HTTP Cache doesn't necessarily Vary on those
- Pat: As part of spec process for Memory Cache we can
- Anne: Depends on where cache is placed, if you can get an entry out of it
- Yoav: A lot of checks that Memory Cache currently does is to avoid that scenario and we should maintain that property
- Dan: In context of errors, if it's a HTTP error then it's an error, but if the actual resource is an error, we kind of ignore that because not all browsers will parse all resources?
- Anne: What we're saying is it might be type specific
- Yoav: I think we can specify it can be type-specific but interoperable
- Dan: You would assume script would be pre-parsed across all browsers
- Yoav: Doesn't have to be preparsed, as long as it's eventually parsed
- Anne: Aim to specify the observable behavior is equivalent (network traffic, not perf)
- Simon: And RT API
- Noam: Same mixture of preloads and resources should end in same number of resource requests and RT entries
- ... Should still cache invalid script with an error
- ... With images I think it should be specified
- ... Even if an image got a 404, first request going through Preload should get that 404
- ... In general if we go with first request thing, if one-shot thing from Preload is available, we just get that response and clear it, everything else separate from this
- ... Fetching resource first checks Preload, separate from Resource Cache
- Noam: Please be involved in GH discussion
Measuring preconnects - Yoav Weiss
Summary
- I outlined the difficulties in knowing if preconnects were helpful
- Folks pointed out that since connections are potentially shared between browsing contexts, the information may not be easy/safe to expose
- Reporting on unused preloads seemed to have more support
Minutes
- Yoav: ResourceTiming gives us a connection time
- ... So we can know when a connection was re-used because fetchStart==connectStart==connectEnd
- ... Know whether resource was pre-connected
- .. Can't distinguish between implicit preconnects (knows things about user), explicitly preconnets (tags), or re-used persistent connections
.png)
- ... We don't know when they happen?
- ... We don't know if they were useful?
- ... Implicit preconnects
.png)
- ... Reused persistent connections
- ... Explicit preconnects is <link rel=preconnect>
- ... Opened issue many years ago about RT and preconnect
- ... Recently more relevant with Early Hints
.png)
- ... Early Hints allow server to send HTTP response headers via 103 Early Hints status before it gets the rest of the content / original hints
- ... Preload or Preconnect headers use-case
- ... For Preloads, we can estimate those were useful via RT API. But for Preconnects we don't know if the connection happened due to Early Hint and wasn't available before
- ... A few options for how we could distinguish
.png)
- ... When did preconnects happen? vs. the fact that it did happen
- ... Finding useless preconnects
.png)
- Pat: Unless you're assuming network partitioning on a per-doc basis, the connection pools don't belong to any document. Two tabs open, one could be creating connections for the other one. I don't know you want to leak that info unless it was a request on that document creating it
- Yoav: Should be partitioned for all top-level same-site
- Anne: Connection pools are partitioned, but you concern is valid
- ... If top level site A, and a embeds B, A shouldn't be able to detect if it's a reused connection
- ... At some point there will be leaks because there's not a key for the whole chain
- Yoav: Saying if A embeds B, B loads a resource from C, and A loads C it can see if there's an information leak
- Pat: Is it not enough if you're doing Early Hints trial from Preconnect, and you see the B fork of trial that it spends N% of time less in connections?
- Yoav: What I hear from field is that it's hard to tell those scenarios apart
- Pat: If it's not having an effect though?
- Yoav: If you have a very low data volume on some origins, hard to tell whether it theoretically worked or not
- Dan: Being reporting on unused Preloads would be much more important than unused Preconnects, consequences much more severe
- Anne: Assuming Preload is document scoped, you fire off a report
- Andy: When I've used Preconnect we just look at the effect on the 3P that we're connecting to (e.g. Cookie Consent banner). Measure something that matters.
- Dan: Way that you should look is the reverse, if you added Preconnect and it helped. Then you make changes in code and it no longer helps but nobody checks anymore. All those marketing pixels that live forever.
- Yoav: Going back to the useless Preconnect case, I take your point that you can't expose that cross-origin iframe, but that's not the only case for Preconnects. Any objections to preconnects the same origin triggered, or that didn't use? Hard, I have to think about it more.
BFCache - Fergal Daly
Summary
- Chrome, Firefox and Safari now support back/forward cache. Chrome is working on increasing its hit-rate. RUM vendors can help by exposing BFCache hit-rates in dashboards (some already are).
- We would also like to expose the reason for cache misses (e.g. holding a WebLock). Proposing an API for this and would like feedback (seems like exposing via PerformanceTimeline is favoured in this session). Already exposing reasons in DevTools.
- Unload is a big blocker on desktop for Chrome and Firefox (Safari ignores it) and problematic legacy API in general. We want people to use pagehide, visibilitychange or others like upcoming beacon-API, (sorry no link yet). Chrome is doing outreach and exposing in lighthouse.
- Feedback is that customers don't get "BFCache", maybe another name would help.
Minutes
- Fergal: Team effort - bfcache-dev@chromium.org
- … quick summary of BFCache.
- … Firefox and Safari have them for a while, Chrome recently added
- … Navigating away from a page discards the objects created. With BFCache the page is paused, and can be resumed without re-parsing
- … Makes history navigation instant (for the most part)
- … See 10-35% of history navigations served from the BFcache, aiming for 50% next year.
- … Have requests for RUM folks. Would be great those metrics included BFCache hit rates for the sites in question
- … Would be great if dashboards tell people what’s causing their sites to miss BFCache
- … and would be great to move off of unload events
- … Need more awareness - many developers are unaware of it
- … e.g. Wikipedia fixed it quickly once they were aware of them
- … If you’re brought back from BFCache, the event has a persisted bit that’s true
- … Can divide that by navigation entries with a “back_forward” type
- …< Insert code example here>
- … Lots of reasons why you’d be blocked from BFCache
- … Chrome initially blocked everything that could’ve been problematic and now working on unblocking those
- … Example - cache-control: no-store
- … If you hold a weblock it’s difficult to put you in BFCache, we’d have to let other folks take it and kick you out
- … Other features as well result in blocking
- … Pages can see that, handle it properly in pagehide, and be able to go into the BFCache
- … Explainer on an API that would give you the reasons for why you didn’t make it into the BFCache
- … https://github.com/rubberyuzu/bfcache-not-retored-reason/blob/main/NotRestoredReason.md
- … Give you frame URL, and reasons when possible (i.e. when not cross-origin)
- .. Would like feedback on the shape of the API
- … Could attach it to PageShow, NavigationTiming or Reporting API.
- … Would love feedback on the GH issue
- … Would like to enable sites to drive their cache hit rates
- … DevTools show such reasons, but that’s limited
- … We also want to ask people to stop using unload
- … Android ignores unload for BFCached pages
- … Safari is the same
- … Chrome desktop cannot do the same, but it is the largest BFCache blocker
- … You can change unload usage to pagehide usage typically. PageHide is more reliable
- … You can also tell apart PageHide that goes into BFCache
- … Sometimes VisibilityChange can be a good replacement.
- … If you have unload use-cases that are not replaceable, please reach out.
- … Orthogonal, but there’s a proposal for a beacon API that delivers information after the page is discarded regardless of reason
- … Almost every usage of unload can be replaced by PageHide, but it’s still not 100% reliable, and there’s no “last PageHide”, so hard to send a final beacon from the page.
- Nic: Thanks! Definitely something that we are planning to support in our dashboard. Glad you’re thinking about attribution when things don’t work out. Have to think through about the best delivery mechanism. Generally favor PerformanceTimeline.
- … BFCache itself is a mouthful and we’re not sure how to explain that. Maybe as a community we can figure out a better name? Common terminology?
- Olli: Blazingly-Fast cache, originally
- Dan: We already collect this info, exposed to us rather than to users, as they can’t disable it. Did the work of removing the unload event. Collect the data of when a BFCache occurs.
- … We don’t normally look at those numbers. The motivation to collect it was to get the best performance possible and avoid interference with CWVs.
- … We don’t actually get BFCache for Chrome, because we use WebWorkers for most of our sessions.
- Fergal: Working on dedicated workers support
- Yoav: Performance timeline may not be available at the time of the page unloading for RUM scripts?
- Fergal: Data should be available to a page that wasn't able to BFCache when the page comes back in at the pageshow event, so the RUM script should be there
- Cliff: As a RUM provider, we’re excited about exposing more navigation types as dimensions. Similarly excited about attribution
- … How we talk about BFCache is important, as we have more non-technical folks. So language is important. Worthy a discussion. +1 on PerformanceTimeline
- Nic: Suggestion to create an issue on naming suggestions. Nic to take AI
- Alex: We’ve been measuring and trying to increase BFCache use, so interested in this direction. Recently renamed it from PageCache to BFCache
- Olli: How to deal with cross-origin iframes? E.g. youtube widgets
- Fergal: When an iframe is blocked and its cross-origin is blocked. You don’t know what URL it was. But if you added it to your page, you should know what that widget is and where it came from.
- … Looking at logs we’re trying to find the worst offenders and get them to remove their unload handlers.
- Ian: Wanted to talk about the reporting API. I know Firefox and Safari made some work on that, and we could use the infrastructure to report BFCache related info.
- Fergal: If there are problems in the explainer with the ReportingAPI, let us know.
- Ian: Example is not bad, but would require the code to run in the page.
- Fergal: I’ll add a note about reporting to the explainer.
- Anne: Interested in Reporting API and Observer. We have a behind a flag implementation for both. Only integrated with CSP, need another feature to justify shipping it.
- … We’re still supportive of the API once there’s justification.
- Steven: Where in devtools can you see BFCache misses?
- Fergal: shipping in Chrome 95. Under “application”
PageVisibility and requestIdleCallback - Noam Rosenthal
Summary
- PageVisibility and requestIdleCallback are slowly folding their content into the HTML spec.
- It was agreed that PageVisibility can be folded entirely (which has since happened), and that requestIdleCallback would fold only the deadline algorithm for now.
- Regarding the future of requestIdleCallback, some request was made to expose some of the deadline information outside the context of the idle period deadline.
Minutes
- Noam: Discussion topic, not presentation
- … In my work I'm going through a lot of WebPerf specs, cleaning up old issues
- ... Cleaning up technical debt
- ... Common thread of what I'm doing is moving things into Fetch and HTML
- ... Last year moved from ResourceTiming and NavigationTiming into Fetch and HTML
- ... This year, same thing but also getting into smaller specs
- ... Recent PRs they're very close to removing the entire spec into HTML
- ... pageVisibility PR https://github.com/whatwg/html/pull/7238
- ... Defines event, states, hidden, etc in HTML
- ... Makes pageVisibility spec itself not have anything but prose (that could be transferred to HTML spec)
- ... Same for requestIdleCallback https://github.com/whatwg/html/pull/7166
- ... Attempts to define what "deadline" means, which is a bit hand-way today
- ... Defines an event loop terms, and testable terms
- ... A lot of the rIC spec is about that
- ... Issues in the rIC repo are about the deadline not being well defined
- ... Some of this takes the "hook" concepts in PageVis spec, which other things can call
- ... Why not just call them one-by-one and we can call them in order
- ... Making it more predictable and clear is a big Pro
- ... One con of putting things in HTML spec. I'm a member of W3C and WHATWG, not sure if everyone else is
- ... In general there are fewer reviewers available in HTML specs
- ... However it's a different process than working with W3C specs that may feel more experimental, the process can go faster for better or worse
- Yoav: From my perspective I think that it makes sense for these two specs to be better aligned with HTML. The PRs that I looked at make general sense and agreed that they don't leave a lot beyond setting up the context in those documents
- ... Those two specs define bits whose processing is outside of HTML
- ... Makes sense for those two specs to move
- ... Unless there's a specific reason why we shouldn't
- NPM: My only concern for Page Visibility is if we ever decided to expose additional information via the Observer that we have discussed in the past, we'd have to revive the spec we just killed.
- Yoav: Or another Visibility Observer we'd have to add that to the charter
- NPM: Regarding rIC I'm not super familiar with it, not sure if there are any intended additions to it
- Yoav: Spec editing situation there is complex, no longer involved
- Scott: We have plans to keep working ins scheduling space, but not necessarily rIC
- ... Taking over editor and ramping up on it
- ... I think it does make sense in HTML, given how integrated it is, no objections at this point
- ... If we did have to expand on it for any reason, we could do a PR to HTML, or try to monkey patch it through a different spec
- Noam: Wanted to suggest - some of these specs are tiny, it may be better to arrange specs per subject rather than function
- Scott: This is what we’re doing with the Scheduling APIs. One option would be to move that processing to the scheduling APIs spec. It’s similar event loop modifications, but maybe it should be in HTML
- Noam: Makes sense to have the event loop modifications be part of HTML and keep the web exposed bit in W3C
- … If anyone is interested in the deadline discussion, it felt that no one is extremely familiar with it.
- … A deadline is when you get an idle callback you get a number of seconds you have for “idleness”. May make sense to see if people are using it in a meaningful way.
- Olli: Have you compared how different browsers implement it?
- Noam: Added WPTs, and based on the definition, browsers handle it differently. Not super different.
- … Nice to work on it, as it required a lot of timer revamp in HTML, and now it’s better defined.
- Philip: I used that deadline in the past in code. At the time, it was only implemented in Chrome. I avoided running the cleanup code if the idle time was lower than 16. Not the most useful signal, but nice to know what idle period I was in.
- Noam: Might be more explicit to just expose that: is there a pending render opportunity
- … That’s how the deadline logic is implemented.
- Olli: Not quite true in Firefox. We can create new rendering opportunities as needed to improve performance
- NoamR: best guess
- NoamH: Using it as a heuristic to execute expensive/blocking tasks. A better approach for the render opportunity is the isRenderPending.
- … We do use the deadline and skip tasks when there’s no time
- Scott: isFramePending is useful outside of rIC, so it largely takes care of that use case. Deadline also takes into account pending timers.
- Noam: Those are the 3 things that can effect it: timers, rendering opportunity, 50ms timeout.
- … Can be useful generally
- Scott: People also ask for deadlines outside of rIC as a useful signal
- Alex: We have devices with variable framerates that can be greater than 60 FPS, so don’t want to encourage the web to be locked into 60 FPS.
- Noam: This is where deadline fails. It’s heuristics based on assumptions, rather than providing the signals directly. Libraries could then do that for people.
- Michal: Followup to Alex’s comment. What’s running on that frame? Hard to know ahead of time, but maybe you could use past info to predict the future.
- … Skipping a main frame update is not equally bad in all situations.
- Noam: I’ll open an issue to consider exposing direct signals instead of deadline heuristics.
- Dan: Just wanted to say that I’m hard-pressed to think of a really good use-case for rIC, and it’s starting to see it as an anti-pattern. So maybe it's not worth investing in it.
- Philip: To clarify, I was looking for a dedicated scheduling API, to fire low priority tasks. Could be a better API to better handle that use case.
- NoamH: In the same sense, having a signal of how much time you have remaining, enables you to split you tasks.
- Dan: If it’s a DOM related task it shouldn’t be in rIC
- NoamH: Render less important aspects of the UI (generate HTML using React). You could consider doing that in a worker, but there are tradeoffs.
- Dan: That’s the part we need to fix.
- Yoav: Moving things over may also depend on ability to discuss WHATWG things
- <TODO> conclusions
RUM pain points - Nic Jansma
Summary
- Discussed what "ideal" RUM API characteristics are, including being able to look-back into history and having enough attribution to be able to affect the metric
- RUM needs around more SPA support, better ResourceTiming visibility, observing cross-origin frames, and other resource characteristics
- Would like to see a more reliably mechanism for ensuring beacons are sent (beyond Beacon API), maybe through Reporting API
- Echos of support from other RUM vendors and companies using RUM for their own analytics
Minutes
- Nic: Wanted to talk about RUM pain points from my point of view, influenced by feedback from SpeedCurve and Pinterest
- … Ideal RUM APIs
- … Prefer APIs that can look back into history - performance timeline or perfObserver with a buffered flag.
- … even if your library wasn’t on when the event happened, you can collect it later
- … As a 3P provider, we sometimes load late, and such APIs are critical
- … Attribution is key
- … We’ve been getting better with that. In previous discussion with Fergal we discussed BFCache attribution, which is great
- … SPA support - designing APIs with SPA support in mind. Some of the current APIs don’t work great with SPA, e.g. LCP
- … Want to see RUM loading improve. We’re using a loading snippet that’s 2.5K
- … Put this junk in the pageload to avoid affecting onload performance.
- … Can run scripts at onload and have visual indicators
- … So jump through hoops to avoid it. Async and defer are blocking onload.
- … There is a possible solution in resource loading orchestration, where there are different hints to load scripts at different stages
- … When RUM measures something people ask “why” and “how to fix it”
- … LCP.element and CLS.sources are great examples for attribution out the gate
- … LongTasks are the flip side. They have no attribution detail which helps find the source.
- … In a modern website you have so many dependencies that current attribution doesn’t help
- … Pinterest wanted to do better root cause analysis, and knowing the trigger would really help
- … JS self profiling could help, but it’s a sampling API so it may not help in all cases.
- … Last year we had a great presentation from Patrick Hulce on that front.
- … SPAs - affect nearly every RUM metric
- … Many metrics are irrelevant
- … You have to think about how they affect an SPA
- … In mPulse we have an “are you an SPA” boolean that then measures different things
- … AppHistory can help, but for Soft navigation, we can hook into some events to know when it starts
- … But we don’t know when it ends
- … We listen to mutation observer, patch Fetch, and doing a lot of work that we’d love for the browser to help us do better.
- … For MPAs, the page is loaded once the onload fired. For SPAs onload doesn’t matter
- … We’re definitely talking more about SPAs, but we’re not yet there.
- … e.g. LCP needs a reset
- … on the other hand, CLS does work well with SPAs, because you have all the events to slices them as you want
- … So need to focus on new APIs supporting SPAs
- … Network visibility - some proposals but no solutions
- … If you measure resources, all cross-origin iframe resources are not visible, which constitute 30% of hits and 50% of bytes.
- … So we show customers waterfalls, but they are incomplete
- … Particularly painful for ads
- … Also for CLS, visible in devtools but cross-iframe CLS is invisible to RUM
- … Proposal for a “bubbles” API to bubble up resource entries to the top-level document, and cross-origin iframes can opt-in to share that data.
- … Observing when network requests start
- … Enables SPA monitoring. Currently patch Fetch and XHR. Otherwise incomplete, and makes it hard to calculate network idleness.
- … Ongoing work on Fetch+SW integration - better cache hit rate reporting would help Pinterest
- … More information not exposed for resources›
- … No consistency on non-200 responses. Want more visibility into that
- … Worthwhile to continue past discussion on TAO and relationship with CORS
- … Last thing: reporting API
- … Browser extensions polluting data
- … Would love to tag on metadata
- … Today the only way is through the URL
- … would be useful to add session ID, session length during the lifetime of the page
- … May have privacy and security implications
- … Was a presentation to use reporting as a more reliable beaconing mechanism
- … mPulse sends beacons when the page loads, because it’s most reliable. Would like to send it later, to enable more data. There are some downsides to sending 2 beacons.
- … Some customers send it later, but there’s a reliability cost
- … Lost beacons means losing experiences
- … For some customers that’s a good tradeoff, but an API that would fix that tradeoff would be helpful.
- … Thanks for SpeedCurve and Pinterest for their ideas.
- Katie: Wanted to say +100000 to all of that. Owns and maintains internal RUM. Same issue. We do all kinds of wild stuff to work around that.
- … A couple of years ago we moved our JS build system, and when they tried to launch their perf monitoring went off the chart.
- … Grouping the perf monitoring bundle ith the JS, so performance changes changed when perf monitoring ran
- … Ended up inlining that code to avoid variation
- … We see this when running the monitoring code on the same thread, changes result in impact on the measurement.
- … Big problem overall: attribution, SPAs
- NoamH: Curious - are your customers interested in hang detection - when the page blocks.
- Nic: Yeah and the reporting API crash reporting is great. A freezing API would be a good fit as well.
- NoamH: We’re exploring similar ideas
- Olli: In slide 2 you mentioned looking back in history. Need to be careful. E.g. last year a social media site used a buffer size of 100000, which resulted in huge memory bloat.
- … Maybe the APIs should be designed to prevent such misuse
- Nic: ResourceTiming has explicit control over the buffer. PerfObserver doesn’t allow infinite buffer size
- … We have a doc that suggests recommended buffer size for implementations.
- … Definitely a tradeoff there.
- Dan: At Wix we also use inhouse perf monitoring. Definitely echo everything you said on attribution, despite controlled env. With regard to SPAs, what you do with CLS creates some discrepancy between how you measure CLS and how CrUX measures CLS. We decided to align with CrUX because that’s what users see.
- … What do you think about integration with privacy cookie banners, consent, etc?
- Nic: We indeed report a different metric from CrUX. Customers use both data points.
- … CLS sessions is a great way to think of this, and points out the worst layout experiences.
- … Otherwise, we have some customers that try to measure the effect of privacy banners, etc. Still at early stages.
- Dan: Wasn’t asking about the banner’s perf implications, but about the consent policy itself. Avoid reporting things, etc.
- Nic: Gave customers the choice and it depends on their policies.
- Cliff: On the LCP issue, is there an open issue on that?
- Nic: There’s an open issue to reset LCP.

Measuring SPAs - Yoav Weiss
Summary
- Outlined a path to reporting soft navigation in RUM APIs, including related paint timings.
- There was interest in that happening, but also in a “Paint Timing reset” API
- We should be careful not to take the first paint after a navigation (e.g. button color change, spinner) as *the* FCP.
Minutes
- Yoav: Soft navigations are hard
- ... aka same-document navigation
- ... with History API, user typically clicks on something, fetches content, history.pushState(), DOM modifications
- ... AppHistory API proposal, user-initiated link or "appHistory.navigte()" API and "navigate" event
- ... transitionWhile() with a Promise that fetches content and modifies DOM
- ... What's hard? There's no clear start point (History API model)
- ... Don't know when navigation has started, hard to link to user click event
- ... Hard to distinguish URL-changing interactions from soft navigations
- ... No correlation to paint events that happen afterwards to soft nav itself
- ... Paints may happen after nav but may not be related to nav work itself
- ... No clear starting point: App History came up with "user initiated navigation" (anchor or form)
- ... Interactions vs. navigation: detect <main> paints? % of screen painted?
- ... What happens when main element is on a small part of the screen? Mis-incentivising
- ... Maybe we can filter interactions based on past hard navigation
- ... Paint correlation - same as responsiveness
- ... Exact same problem we have for soft navs we have for responsiveness, we don't know next frame is related to that user action
- ... Potentially async work that can happen and need to be completed before related frame is presented on screen
- ... AppHistory - limit tracking to promise chains
- ... Any promise that dirties the DOM and is paint causing, we can track back to navigation
- ... Promise Hooks, V8 internal API, an option but has performance implications
- ... Look at tracking tasks from render side
- ... <demo!>
- ... On AppHistory demo page, you can see navigation and task that resulted in a layout operation
- ... Essentially I think that it's far from done and there's still a bunch of problems, e.g. prototype doesn't handle userland promises
- ... Path between navigation or click events and the DOM operations that result
- ... We may not have to rely on AppHistory, although alignment could be nice
- ... Responsiveness could use same mechanism
- ... Maybe this has effects on LongTask attribution
- ... Caveats: Cannot track all tasks, e.g. data queues
- ... If people are putting data into a queue and getting it later, we don't have a way to correlate and say these tasks are a continuation of one another
- ... I think from a navigation perspective this is fine
- ... We can essentially tell developers that if they want to be able to track soft navigation, this is not something they should be doing as part of their navigation flow.
- ... Might be easier to implement when task scheduling is centralized
- ... Not sure if this is cross-browser compatible, so feedback would be appreciated
- ... If we want to expose paint events as a result of this correlation tracking, there may be security restrictions on a number of paint events, to avoid developers gaming this somehow and get more paint events than they should to sniff out visited state on links
- ... It's possible the requirement for a user-initiated navigation would make it so this throttling is not needed, but I haven't passed this bys security folks
- ... So if we can detect soft navs, what can we do?
- ... perf-timeline#82 API shape for monitoring new navigation-like entries
- ... Point in time developer resolved the promise
- ... API shape for same document entries, as well as other navigation-like entries
- ... One result of past discussions is we need a Navigation ID to correlate other performance entries with that navigation (e.g. RT, UT) to be able to group them per-navigation
- ... Real, BFCache, Soft navs
- ... Paint-timing for same-document navigation, would enable Paint Timing correlation
- ... Navigation ID helps to correlate to relevant navigation
- ... May or may not depend on App History API
- Scott: This is cool, one of the things we're going to think about next year. Otherwise penalizes SPA-style nav even though it's better for users
- ... We have a lot of metrics around "largest" or "first"
- ... Wonder if shorter-term work is resetting timers or on navigation so we can re-use those same mechanisms
- ... Worry if handling a soft-nav diverges too much from initial nav, harder to explain to developers how to optimize this
- Yoav: Reason it's hard to reset and re-fire LCP and FP and other metrics, right now with History API we don't have a clear starting point. When do we restart them? If we fire them, what's their time origin? Makes it hard
- ... Security concerns around exposing paint times more often than once per navigation because it can be used as an attack vector for :visited link-based history interpolation
- ... Tie that to user-initiated navigation and not be completely JavaScript controlled
- Scott G: One other big blind spot for SPA nav, RT don't show up until they're complete, because we don't know the beginning.
- ... User-space solutions may help
- Yoav: Aligns with what Nic was asking for with more network awareness in APIs
- ... I'm skeptical with userland implementation, unless it's app-specific if you instrument it fully with ElementTiming and such
- ... Harder for RUM providers to generically pick up from any app
- ... Require a browser implementation, hopeful that timelines won't be too long
- ... Typing as fast as I can
- Steven: Clearly a need for a concept of a reset, each MPA navigation you get LCP, FID, etc. In SPA you can't get them
- ... I decide now it's called interaction/navigation/transaction, reset
- ... In our use-case, we have a big SPA. We have concept of our own navigation, when we decide click of user was a navigation, we reset all of our measurements. We don't just want to measure soft navigation, but also interactions. Tab within subtab.
- ... Because we're measuring at navigation level, we'd miss measurement of sub-tabs, but sometimes those are very important. We've moved to the aspect of "transaction". Ideally we want to measure every click. You can almost forget concept of navigation, and you can measure every interaction
- ... To me I would not be opposed to every click or tab we'd reset measurements, and we the developer would send it back for reporting
- Yoav: What would you measure after that reset?
- Steven: CLS, FID, LCP, usage of JS thread, how long did it take when user clicked
- ... Sometimes we get stuck at the navigation concept, and we may another measurement down on the page somewhere
- ... A reset mechanism we could call on every click would be more useful for app developers
- Yoav: I would argue you can already do all those things, i.e. FID based on event timing. CLS based on layout shifts.
- ... For LCP I'm not sure what it's meaning would be if we don't have the concept of tying those paints to the click
- ... Responsiveness API would solve your problem for interaction-related things
- ... Hoping to solve for navigation with similar mechanism
- ... LCP I don't know if it makes sense to have user-based mechanism
- ... AI to post issue to minutes and we can discuss
- Nic: Awesome we can ask for something in one presentation and have a proposal in the next. Would help with SPA monitoring and LT monitoring. Would be powerful
- Pat: In SPA, for LCP, hard to know if DOM is changing
- ... For Chrome, trying to avoid gaming of metrics and making them consistent across all sites
- ... Don't want it to impact search
- ... Back to ResourceTiming events, something we do in synthetic a lot, looking at when the page finished based on network activity. We see when requests are started, completed, etc.
- ... We can wait for 2 seconds of idle after things finish
- ... Would help in the generic case but also the app-specific case
- ... e.g. we have specific widgets are kicking off activity and want to know when that's done
- ... I don't know if the network timeline currently as it's modeled would support something, but if we had incremental updates as request is issued, cors-allowed, complete would help that case
- ... Paint linking back to user input is absolutely critical thing to pull out and tease out separately
- ... Other things that are LEGO building blocks to measure SPAs well generically and specific cases
- Dan: I would also like to add that I would love to have an SPA compatible LCP event, moreso FCP. For example suppose what triggered it is a button that clicked, so the button repaint could be FCP. Think carefully when measuring the "first" paint. LCP may not want to track before some network response finishes. Not exactly clear. Reason FCP is so important is I've seen a lot of SPAs where there's no visual indication that something has been clicked for a very long time, where MPA the browser itself gives indication.
- Yoav: We can take the last correlated paint as the first paint. App History API has a definitive end when the developer resolves the Promise, vs. History API where it’s not known when it finishes
- Michal: Clarifying question for Scott - do you think we should start experimenting with resetting timers in parallel to trying to automatically detect soft navigations?
- Scott G: Both in parallel is what I was thinking about, the problem with automatically measuring is that it may take a long time for all browsers to implement. We need something to fill the gap while a proper solution is baked in and becomes a standard for everyone.
.png)
.png)
.png)
Animation smoothness - Michal Mocny
Summary
- Follow-up from a recent presentation on Animation Smoothness.
- Discussed evaluation criteria for animation frame visual completeness vs. animation smoothness, the states a single animation frame can have, and what that means for the observer.
- Discussion involved making sure the metric is accessible to less-technical folks, emphasized the importance of attribution, as well as a request to get the expected device refresh rate.
Minutes
- Michal: We talked about this last year and I've recently presented, so I'm not going to go over the full thing, but links to previous dive
- ... Rather get feed back from folks
- ... Today: Frame Completeness vs. Animation Smoothness
- ... Possible states for a single Animation Frame
- ... What is Animation Smoothness?
- ... Goals i to deliver complete animation frames in a timely manner
- ... 2nd goal is to identify frame updates when they matter, i.e. no jank
- … Frame completeness vs animation smoothness
- … a single animation frame is not necessarily presented or dropped
- … there may not be a rendering update
- You can have a partially presented frame
- … Even if you produce an update you can miss content (checkerboarding)
- … quality vs. quantity (e.g. low bitrate smooth video)
- … Difference between some updates and animation updates
- … So, we have to start by detecting active animation
- … try to direct web developers towards composited animations
- … So for a web metric, we need a way to classify if a given frame factors into smoothness
- .. Main thread affecting smoothness
- <slide>
- Compositor
- <slide>
- … So we don’t know immediately if an update impacts smoothness. But we have to wait for the LT to complete before we know if all its frames were delayed or not.
- So tried to create a simplified diagram
- Conceptually a frame is not a boolean, but a fractional, probability value
- NoamH: I really like the breakdown. Very technical discussion that requires browser architecture understanding. How do I communicate this up to less technical folks? Can we have a definition that doesn’t rely on internals?
- Michal: Great question. Wanted to show y’all the details and then we can discuss simplifications. Made some API proposals in the past.
- .. Our job to put this all together. For each animation frame, we can label for completeness and smoothness
- .. Or we can combine them to a score
- … Important to think about average throughput
- … But sometimes also important to minimize max latency
- … Want developers to focus on the situation and adapt to it.
- NoamH: It feels to me that, given different frame rates on different devices, it’s important to have a framerate that matches the device.
- .. Maybe we can have an API that enables us to define what’s the level of smoothness that we desire?
- Michal: In some earlier version, average throughput was saying “you’re penalized on every missed opportunity”. Didn’t handle the case where higher frame rates mean you have more opportunities to miss.
- … But if look at frame to frame latency, lower framerates give you more time to get it right.
- … Users with higher framerate requirements can have different bars
- NoamH: Is there an API to expose the current refresh rate?
- … The desired refresh rate may depend on app type: e.g. Game vs. business
- Michal: Attribution? Lab tooling give you animations by type
- … common issues:
- ..animation on the main thread + long tasks
- .. Or compositor animations that overwhelm the GPU
- … So could be completely unrelated to JS
- … So even knowing these things can be useful
- …. So maybe we can expose such top causes

ZStandard in the Browser - Nic Jansma
Summary
- Zstandard has interesting characteristics of being relatively high compression and relatively low CPU cost
- Having the browser support it as an Accept Encoding could provide a benefit for CDNs and Origins that want to compress their dynamic content with higher compression than gzip but less CPU cost than Brotli. If supported by JavaScript Compression API, uses include uploads, beacons, profiling data.
- Interest from other members. Interesting idea to expand Beacon API to request it compresses uploads first. Concerns from browser vendors around binary size, needing to update Compression API to let you specify level.
Minutes
- Nic: zstd is a recent compression algorithm, pushed by the Facebook team
- … want to go over use-cases and background, and talk about maybe adding support for the web, in the browser
- … I’m not an expert on zstd, just a user.
- … May be interesting in the contexts of compression streams, on top of content-encoding
- … published by FB, adopted across the web in tooling
- … Not much web server support for it, there’s maybe an nginx module
- … Not necessarily supported by CDNs, but in many custom client-server set ups
- … At Akamai have been using it for at-rest storage
- … It’s faster than gzip with smaller files
- … experimenting with it internally, and think that the browser use-case can be a good fit
- … zstd published benchmarks
- Zlib is limited in compression ratios, and loses speed fast
- Comparing speeds, zlib is slower per compression ratio compared to brotli and zstd
- In comparable speeds, zstd is better than brotli
- If we’re comparing compression ratios, it’s also faster than brotli
- Diff between zstd and brotli (on the lower compression levels)
- Decompression speeds are not worse than brotli and zlib
- Precompressing static content gives better compression than gzip, but it’s similar to brotli, and is very CPU intensive
- Where zstd would shine is with dynamic content: HTML pages, API call JSON, etc
- Typically, you wouldn’t brotli 11 these.
- With zstd you could use these lower compression levels that are way better than gzip, as well as low-compression-level brotli
- Less CPU == less costs
- Provides faster decompression in the client, but requires a bit more memory usage
- Another use case: compression streams. Useful for different things (local storage, beacons, profiling data), and zstd can provide a much faster way to do that kind of compression on the client.
- For mpulse, beacons are ~10KB after a lot of client side processing. Gzip can help, but gzip is more costly from a CPU perspective. Zstd can be more efficient
- For profiling data, it can be huge, and could benefit from compression
- Downsides
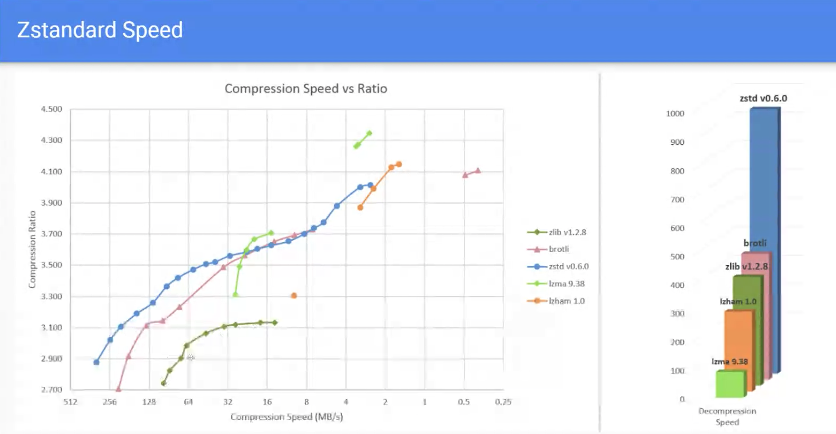
- Not as good as brotli on small files - may be related to a dictionary. We could provide a similar one for zstd
- Binary size increase - not sure what that would be, but certainly a cost
- Zstd uses more memory, as the compression window is larger
- Compression level can impact the memory required for decompression
- From a CDN perspective, there are downsides to store an additional content encoding, as it can result in cache fragmentation and lower hit rates
- Origins often speak gzip, and CDNs would need to “translate” that, which adds a cost
- Dictionaries
- Brotli has a 120KB dictionary. May be biased towards older content or some languages.
- Zstd would need something similar to compete over smaller files.
- We could also consider an origin-specific custom dictionary
- Per-origin shared dictionary can be complex from a privacy perspective, but we could use Origin Policy or build such a dictionary over time.
- Thoughts?
- Cliff: Curious if that's gone anywhere with CDN vendors? Brotli adoption was limited until the CDNs supported it
- Nic: Can’t speak for other CDNs. At Akamai we have support for content-encoding at the edge, so it would be interesting
- Andrew: Haven’t looked at it in details as use brotli 11 a lot, and haven’t seen a lot of advantage over brotli 5
- Adam: Involved in the Compression Streams API, but also partially responsible for working out zstd for Content-Encoding. Wanted to say that the compression stream API is used in 1% of page loads, which is decent. Getting to a point where we can justify adding zstd.
- … The main calculation is the binary size addition. Every user would need to download it, and unclear if it’d pay back the costs.
- … Currently the API only supports gzip level 6. With zstd we could have more flexible ability. From the graph it looks like there are a lot of compression levels.
- Nic: 20 or so
- Adam: Uploading beacons and profiling data is an important use-case, and is probably responsible for the majority of adoption. Interested in whether the zstd library supports streaming compression. Last time we talked about it, it didn’t. The compression streams API needs streaming.
- Andrew: I think that it does. There are many internal use case that would rely on it. I can double check.
- Nic: I similarly think it does
- Adam: I’m really interested in implementing. It has a lot of promise and a lot of potential benefits. Chicken and egg problem that until we implement there’s no benefit.]
- … Even for an experiment, we’d need to pay the costs.
- … In an ideal world, someone could provide stats on savings
- Andrew: I don’t have exact numbers for facebook.com zstd vs. brotli.
- … We do have numbers of zstd vs. gzip and saw significant improvements
- … The main benefit is from the shared dictionary use case, which shows 30% improvements
- … That could be very useful
- Adam: Followed some of the discussion, but privacy barriers were high and discussion stalled
- … From an implementation perspective, if your asset is in your cache and the shared dict is not, since the asset in cache is compressed, that’s a problem.
- … Wouldn’t want to block on figuring out shared dicts
- Pat: At 1% usage starts to get interesting. If Facebook and mPulse can bump up the stats, would that increase interest?
- Adam: If percentages go up, that would empower us to implement zstd.
- Pat: On the call we have a lot of beacon providers that can materially move those numbers
- Nic: chicken and egg
- Andrew: lack of beacon support is holding us back, there’s a chromium implementation quirk that prevents this from running on page unload, because the API is async
- Adam: May need to add a sync API without streaming
- … Also not happy about blocking the main thread
- … For unload cases, you could send data through the SW
- Andrew: it’s in contexts without a SW
- Adam: Please file an issue for a sync API. Not impossible
- Yoav: Not excited about a sync API/unload. We should discuss alternatives.
- … Also what’s the binary cost?
- Adam: Haven’t tried yet
- Ian: +1 on an alternative beacon support that’d help here
- … Also concerned about potential server support. Also, any danger of compression bombs
- Nic: Yeah, we control both endpoints, but in general this can be a problem.
Responsiveness measurement in Excel - Noam Helfman
Summary
- We discussed how "Microsoft Excel for the Web" leverages Event Timing API to measure responsiveness of user interactions, the metrics Excel creates with the API, as well as challenges and ideas for further improvements.
- Then we talked about the importance of tracking event-driven paints vs. the next paint, what’s “contentful” in that context, interactionIDs and how they (won’t) help here, and how future scroll measurements may help.
- Noam would file various issues with API improvement ideas.
Minutes
- NoamH: Noam from Microsoft Excel.
- … Wanted to talk about our thinking on responsiveness in the app
- … Excel is a complex SPA
- … We want to improve interactivity. Talked about animation smoothness yesterday and navigation responses
- … Want to talk about short interactions
- … Using LongTasks to measure issues, but it’s hard to get attribution and it’s mainly about JS execution
- … Alternative approach is using a rAF loop. Only trigger it once the user starts interacting, to avoid wasting battery, so miss the interaction start
- … Want to be as accurate as possible, use it for regression detection, want to use it as an org internal metric to keep us on track, etc
- Definitions:
- … User action- interaction expecting a response
- … Response time - duration of user action till a meaningful response. Aligns with event timing
- … Responsive user action - every response time is below 100ms
- …
- Use PerfObserver for events with 100ms responses
- startTime is associated with the event timestamp, which is when the user input happens
- … For every user action we use addEventListener and then call a global function that uses it as a key, as well as a string that represents the user action
- We want to correlate the user action with the EventTiming entry. We do that by storing the events in a map with the timestamp as a key
- When processing event timing, we look for the user action in the map based on the event timestamp
- After that they log the information and account for it
- It’s not a responsive metric on it’s own
- … We defined a responsive session as one where 90% of sessions are responsive
- … Responsiveness - rate of responsive sessions per action
- Challenges:
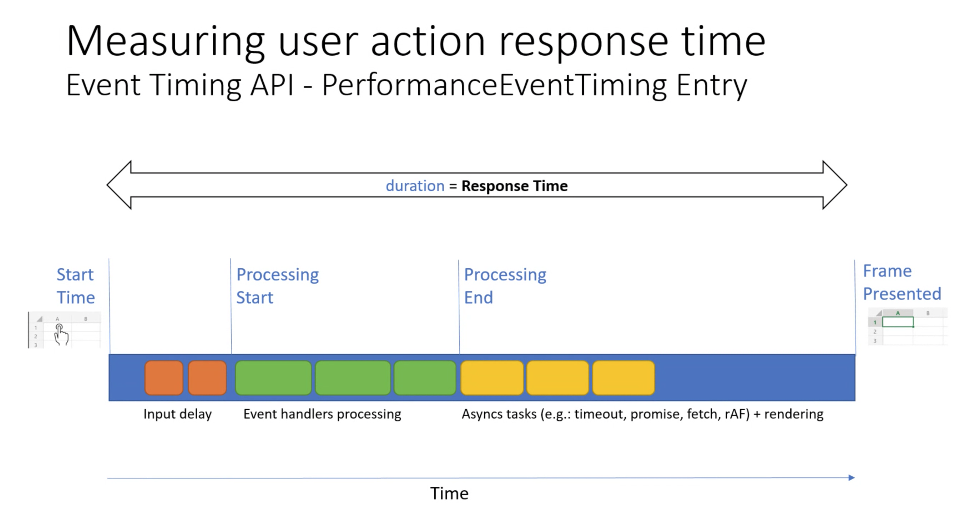

- Hard to integrate - we need to inject a JS call to each event handler. Want to ensure that when developers add it, it’d be added to the event handler’s sync part, not the async part.
- You also want to make sure that it’s part of an event handler that modifies the DOM
- Hard to correlate input DOM events with event timing entries - ideally the API would make it easier. Could add an eventID, or use tags on the DOM event
- Event Timing doesn’t support scrolling yet, and that has been discussed previously. Would help us understand scrolling responsiveness.
- Hard to understand timing gaps. Long event handler processing times are known, but hard to know tasks after that (e.g. “is it GC?”). Attribution would be helpful
- Correlating event timing entries with hidden page state is hard
- Summary:
- Event Timing API is very useful, even if improvements can be made
- Thinking about JS-self-profiling and cross event timing entries with profiles that’d allow better analysis
- Would be happy for Event Timing support from other vendors
- Thoughts?
- Michal: Minor clarification. You mentioned first meaningful paint, but then talked about input delay.
- … Do you need to handle all those async tasks, or are you interested in the first frame
- Noam: async callbacks may be scheduled and can get in the way of the frame presented, if those async tasks are blocked
- … Assumption it that the DOM modification happens inside the sync event handlers
- Michal: Curious about it in the context of task tracking
- Noam: We try to do similar things without task chaining using Element Timing. Requires some heuristics.
- Nicolás: Thanks for the use case presentation. Useful to know and may encourage other vendors to implement.
- … Thanks for showing the challenges. Are there GH issues for all of them?
- Noam: I can certainly file issues
- Nicolás: We’ve been working on something similar and tracking interactions. We have something called interaction ID which is shipping in Chromium, but is not available in the event itself, so won’t solve your problem.
- Noam: We looked at it, but it’s more around coordinating multiple related events
- Steven: Yesterday, we talked about resetting the measurements and wondered: if FCP was resettable, would that help you?
- Noam: The tricky part is what “first” and “contentful” means. For complex responses, the immediate response could be a spinner, which is not contentful. We want to measure the spinner and ensure it’s there ASAP (<100 ms).
- … If we open a dropdown menu, it may come from a JS that we haven’t downloaded yet.
- Dan: Wanted to comment that in this context, FCP is indeed problematic. If the click is instigated via mouse or keyboard, the border of the button would be drawn. So different interactions can change these animations.
- … You would also miss CSS animations that won’t count as contentful
- Michal: FP and FCP are weird on an existing page. Many interactions are not contentful.
- … FP may make sense
- … “frame presented” is an equivalent of LCP but may be app specific
- Noam: DOM modifications in an async task may not happen in the current frame, and rendering would happen due to some other task. That’s the challenge for us, to make sure we’re tracking it in the right place
- Sean: Do you have similar data from Firefox?
- Noam: Using the API only in Chromium. We understood the API is not fully supported
- Sean: It’s fully supported now
- Noam: We’ll take a look at that.
- … For firefox, we’re using metrics based on LongTasks and rAF
- Alex: IIUC, motivations for limiting paint timing exposure is to prevent timing attack from seeing things like visited links
- … Initial thought is that if we expose PaintTiming again after user interaction, that might be limited enough to make PaintTiming attacks impractical
- .. So would enable exposing paint timing in those scenario
- Noam: Also, if the browser had a paint sequence ID that is then reflected in the Paint Timing entries
- Yoav: Linking DOM operations and paints may not be trivial (at least in Chromium)
- Michal: I like how you defined Responsiveness but you say “per action”. Are you slicing sessions that had at least one user interactions
- Noam: Yeah, otherwise we’d have sessions with no interactions that would skew the result
- … The 90% is aiming to exclude outliers. Experimenting with thresholds
- Michal: If a user action was done less than 10% of the time, would fast interactions drown it
- Noam: no because we bucket different interactions separately.
- Michal: question on scrollstart. Scrollstart doesn’t have high latencies typically
- … Is it threaded scrolling or do you have a non-passive scroll where the scroll events block on the main thread.
- Noam: Looking at scrolls with rAF loops to look for LTs during the scroll
- … So we miss the part where we start the scroll
- … And then we look at the animation smoothness of the scroll
- Michal: We should follow up on it. Threaded scrolling can result in slow animation frames that are not actionable
- Nicolás: Not sure if developers can tell if scrolling is fully composited. Scrollstart can help there as well
- … Planning on tackling this problem so stay tuned and come help shaping the API.
- … Otherwise, agree it’s more of a smoothness issue
- Noam: But it could also be related to JS tasks
- Michal: It will depend. May be most interesting to know. But if the scroll doesn’t block on main, you won’t get that info.
Optimizing Third-party script loading - Addy Osmani + Pat Meenan
Summary
- Two primary ways to approach mitigating the performance impact of 3Ps on the web: giving developers (who are sufficiently perf savvy) the right controls, the user-agent intervening in cases where 3Ps may have an egregious impact on performance
- Controls: better ways to tackle loading sequencing between 1P and 3P, preload, priority hints (do check out the origin trial!), early hints.
- Interventions: lazy-loading embeds, throttling 3Ps detected to be likely less critical to the page based on heuristics. Some visual demos were shown of potential impact.
- From the discussion: general support for the idea, but emphasis that there need to be ways to opt out if a business understands the performance vs. marketing/KPI trade-offs of a 3P and still want to load it without the interventions applied.
Minutes
- Addy: Discuss third-party (3P) script loading
- ... Has impacted web performance for over a decade
- ... Ideas to incrementally improve performance for platform
- ... What's the problem with loading performance?
- ... What do we mean by third party scripts?
- ... We have been doing a lot of research on Chrome side
- ... Most studies via developer surveys or lab analysis shows that optimizing 3P remains top challenges for sites that want to do well on performance and with metrics like Core Web Vitals (CWV)
- ... Large percentage of JS execution on web tends to be 3P code
- ... Impact on web:
- ... Metrics, do sites have insights into their 3Ps, improving attribution and IFRAME activity
- ... Organizations issues, the audiences adding 3Ps may not be perf experts. Using tag manager into pages. Often working around engineering teams
- ... Ecosystem - are 3P incentivized about their footprint? Some are not
- ... Web platform side, giving developers sufficient knobs to have more control over this problem.
- ... Developer tooling so developers have enough attribution in lab and field
- ... Pat will talk about resource ordering on platform side
- ... I'll talk about browser side
- Pat: As Addy's mentioned getting the order right can have a huge impact on performance
- ... Studies going back showing cutting load times in half if you can predict order resources need to be loaded in
- ... What can we do to give knobs to dev to order things
- ... Origin rules moving script to end of body
- ... async/defer has been added giving some success
- ... Lazy Loading for image and IFRAMEs in particular
- ... Hinting to browser for things it can't discover like DNS-prefetch, preconnect, Preload
- ... Some of the things that are more in-flight right now, we're experimenting with Priority Hints to give knobs to indicate which scripts/images are more important.
- ... Things that are hard to get right automatically all of the time,w e can give developers explicitly controls
- ... At a protocol level, H/2 had priority support of some kind, wasn't greatly supported or implemented. Improved as part of H/3.
- ... Doesn't work across origins, so doesn't work with 3Ps
- ... When you have 10 different origins serving content in parallel, with priorities among them
- ... Early Hints in experiments right now as well where you can do preconnect/preload earlier in the process
- ... Is there something missing being able to define an explicit order
- ... For Google Fonts, you know you have a CSS that will load a font but not which one, you can preconnect but not preload
- ... Execution control: Preload and insert script tag dynamically
- ... One of the things we're playing with is preloading script and onload handler decides if it's the right time to insert the tag dynamically
- ... Do we need something declarative to not insert a script after X event
- ... Rendering, black box right now
- ... Everything in head that's blocking is render blocking
- ... A/B scripts anti-flicker scripts bane of our existence
- ... Block rendering, something more declarative we could do?
- ... Safari and Chrome have different views about incrementally display content as it arrives vs. first render event
- ... Do devs need more control over that?
- ... If we find we have all of the atomic controls for devs to do exactly the ordering they want to give the optimal experience, we don't necessarily know the adoption will be huge but do we have the knobs to make those changes
- Addy: For folks that are incentivized, how can we give them knobs? But for folks that are incentivized but don't have control to make changes, how can we intervene?
- ... An intervention is UA opts for an intentional deviation from a behavior the developer expects/relies on. Not risk-free
- ... Motivated by the desire to fulfill an important user need
- ... Interventions have successfully improved UX over the years. Passive touch listeners, throttling timers that are out of view in other frames, throttling expensive timers
- ... Played out to varying degrees of success
- ... Case to be made where the platform could be helping people if we can get this right
- ... Two examples, Pat talked about knobs and loading=lazy.
- ... Focus on Images and Iframes
- ... What if the browser was to help out here a little more by default
- ... Embeds today are highly interactive, loading hundreds of KB of script, taking up main thread and causing resource contention
- ... Maybe video players much loader down don't need to be eagerly loaded
- ... What is the potential perf improvement here
- ... Significant improvements to Total Blocking Time (TBT) and data savings
- ... Another idea is to identify 3Ps that are less critical on page
- ... 3Ps responsible for 57% of JS execution on th web
- ... Social media sharing, live help, A/B testing or personalization
- ... Sometimes these are important for critical loading path
- ... Can't arbitrarily throttle anything that's not 1P
- ... Few potential ideas for how one could go about identifying less critical
- ...
- ... Lot of potential signals one could use
- ... Developer annotation could help
- ... What are the opportunities here? One thing we've been doing is working with partners
- ... Optimizing 3P script loading, could you see significant improvement to loading metrics
- ... To what extent can you see business improvements
- ... Improvements in LCP, CWV pass rates, better TTI, in addition to business outcome improvements across the board
- ... Potentially appetite in ecosystem without affecting business outcomes in a negative way
- ... How do we make sure interventions had limited surprise?
- ... How are we thinking about heuristics, lazy loading embeds
- ... All would need to be validated in production
- ... Potentially if we were able to build confidence in these ideas, we may be able to ship by default
- --- questions ---
- Aram: Note that loading of stuff below the fold especially video and audio is often a technique to prepare revenue-generating elements.
- ... Might be less transparent now than a couple years ago, because monetization techniques are server-side insertion
- ... I'm generally pro the idea of interventions but it might be good for developers who are thinking about this, I definitely want this to overwrite the intervention for revenue reasons
- Addy: Fully agree, if there is an intervention, we want to make sure for folks who are conscious of the tradeoffs can choose the right behavior at the end of the day
- Dan: Two points. We agree this is a significant issue for customers building websites at WIX. How much of a performance price are they paying for 3P scripts on their site? Reminders about the fact they still have 3P scripts in case they forget.
- ... Lot of things we can do there for our side as a platform for building websites
- ... A lot of the stuff you're saying it relevant for 1P scripts, for example I'm using React with SSR or SSG, I may want to delay the download of beginning of hydration script after LCP image finishes downloading, and delay execution of hydration script after image finished rendering
- ... Nothing to do with 3P scripts but for syncing execution
- Pat: FWIW all of the explicit controls we discussed don't differentiate between 1P and 3P, so please use them
- ... All of the explicit controls are intended for used for 1P, and help within protocol-level prioritization as well
- ... Interventions are more around 3P because it's a little easier to carve out
- Dan: Even with the controls available and are improving, happy with Preload, it still can be really challenging for syncing resources for optimal sequence. Prioritizing urgent vs. important.
- ... Not familiar with websites that are using hydration that are able to pull off the scenario I just described
- Pat: Priority Hints might be useful for that case
- Dan: On our backlog, on our end not all relevant resources are downloaded from same domain
- Pat: Priority Hints doesn't care about origin
- Scott: One comment is that it seems like the work you're investigating here is that it's close to the attribution work that others have talked about. 1P sites don't push further on 3P because it's harder to understand how a 3P script is causing the performance for the site.
- Mystery can also happen in 1P contexts in large orgs, where teams are far apart
- ... Question was how some of these interventions depend on the behaviors of the 3P scripts. Would choices of interventions affect 3P script developers?
- ... Might need to change long tasks or network requests so I can get back in good graces.
- Addy: I would be happy if 3Ps react in that way where they can invest in improvements.
- ... Interested in hearing about 3Ps what optimizations we have in mind
- ... Yelling at 3P via developer tools and guidance
- Pat: On the attribution and reporting side, CWV and search data goes back to the website, and there's not a cross-industry way to blame specific 3P. An example question, does mPulse, across all websites cause long tasks? Can we attribute specific 3Ps causing issues?
- ... Or even with Google A/B Optimize if we can somehow attribute that to LCP delays, should we be doing work with 3Ps
- ... Extensions are an interesting twist to that as well, if adblock causes longtasks by injecting code into page, website doesn't have any control over that
- Scott: Extension case is super interesting. Wonder if this is surfaced to users. Common extensions can really impact analysis, and users have no idea
- Dan: Wanted to respond. Our experience is not positive. We have a flag to completely disable 3P scripts. We use it to prove to customers that 3P cause slowness, but they “need to run that marketing campaign” and that beats everything else
- Nic: One comment I had - attributing to 3Ps, we are completely blind to 3P iframes. Some way for iframes to share data and linkage between requests triggering requests would really help us to help our customers to understand the effect of a script, beyond just turning it off and seeing what happens. Dependency tree of resources would help.
- Addy: Agree about the gap there. Thought about this from a CrUX perspective, but for privacy reasons it’s hard to offer aggregate insight into what 3Ps are doing. May be able to say what classes of 3Ps are doing.
.png)
.png)
.png)
.png)
JS self-profiling: Long Tasks and VM state - Andrew Comminos
Summary
- The JS Self-Profiling API has shipped in Chrome 94, and we have real-world data confirming the performance of the Blink/V8 implementation.
- It’s been a useful tool for discovering JS side footguns, but we have limited insight into non-JS execution, as well as when the profiler is not running.
- The markers proposal was discussed, which adds context to samples about running gc/layout/paint/etc.
- To resolve challenges developers have with attributing the cause of long tasks, another proposal to extend the long tasks API with JS samples from the profiler was discussed.
Minutes
- Andrew: Recent updates to JS Self Profiling API, improvements that are interesting and worth discussing
- ... Recap to where we are now
- ... API for those that aren't familiar
- ... Web-exposed sampling profiler for measuring JavaScript
- ... Think of dev tools profiler but on web
- ... Provide real-user samples vs. biased developers device
- ... Shipped in Chrome 94
- ... Usage:
- ... Send over a trace, with Compression Streams over to your server for analysis
- ... Server can do trace aggregation, helps developers get an idea what's slow on client machines
- ... API used in conjunction with Perf Timeline, can do cross-correlation
- ... Send over Long Task entries, EventTiming, Nav/Resource data
- ... Trace format:
- ... Trie of JavaScript frames, similar to Chrome/Spidermonkey
- ... What's working well?
- ... Facebook and other large properties have gotten signal for how it can be used
- ... Did not introduce unmanageable overhead, <1% impact for top-line metrics
- ... Drop-in solution for client teams to focus on perf, make perf more accessible
- ... Easy tracing
- ... Strong adoption from other industry partners
- ... What could we do better?
- ... In interest of focusing on client JS, we omitted other top-level UA work
- ... GC and Paints missing
- ... Indistinguishable from idle execution
- ... Interactions with Long Task API can be cumbersome
- ... Don't want to be enabling profiler on all page loads, but might want to figure out if we get a bad sample why it's slow
- ... Attribution has been discussed in working group
- ... Some of our ideas for how it we can get better UA state
- Corentin: To solve the issues highlighted by Andrew, like to propose a way to mark state
- ... Highlight category of work by UA at time it was captured
- ... Bring us closer to capabilities of profilers in Dev Tools
- ... Event can be categorized in different types of tasks
- ... We focus what could be marker candidates
- ... Main issue is interoperability, want marker to have some meaning across traces and UAs
- ... Interested in feedback in proposal for what would be most relevant and safe
- ... Could consider garbage collection, parer marker
- ... On rendering side things are more difficult to spec
- ... General Paint marker that aggregates style/layout/paint
- ... But would be useful to split these markers
- ... API modification
- ... What it could look like in an actual case
- ... "gc" marked on right side
- ... Highlight idle, rendering events
- ... Security and privacy concerns
- ... Need to avoid new side channels
- ... Some events that aren't immediately attributable to an origin
- ... Could require isolations to attach that marker to a sample
- ... Started a TAG review
- ... Open questions:
- ... With JS Self Profiling API, we could make Long Task API more actionable
- ... If you're running a profiler, you can cross-correlate with Long Task Observer
- ... Find root cause, expensive sampled functions
- ... Identify UA-level work for free
- ... Drawback: Recording all samples, to correlate with Long Task Observed
- ... Increases memory and CPU
- ... Can we limit sample to only during Long Tasks
- ... No Active profiler necessary
- ... Interested in feedback for this proposal, hope it improves LT attribution
- ... Open questions:
- --- questions ---
- Randell: With Long Tasks, one thing that I've used in the past for capturing similar data in other profilers to have an event that tells you something has occurred, so you could save the current set of samples some configurable amount of time when you have an indication of Long Task. You don't need to retain a large amount of data
- ... Continue it until the end of the Long Task eventually
- ... Some tricks can be played to limit memory and CPU overhead
- ... API seems interesting and useful. Main concerns are security around cross-origin and timing exposure for Spectre and other issues, might be covered in spec
- Andrew: Thanks for feedback
- ... Trying to be conservative with overhead and make accessible for web developers
- ... Hard to spin up trace processing infrastructure to support these cases
- ... Is a single sample enough? Keeping a small buffer to backtrack, is more robust
- Randell: Related to this, is the impact of user performance on different classes of machines
- ... Developer machine vs. reference laptop not as happy taking any sort of profile
- ... Relative impact can be larger on lower-end machines
- Andrew: Our earlier number of 1% shared before was across all profiles. Some may be higher or smaller
- ... Found a lot of issues front he profiler itself
- ... RE: security, bunch of issues added to Github in past few months, had several reviews
- ... Discussions around around timing precision, clamping to 10ms
- ... Using ECMA realm-based checks
- Yoav: Exposing the markers to PerformanceTimeline instead of profiler, would you expect makers to have same overhead as profiling
- Andrew: Main concern is instrumentation vs sampling
- ... GC itself would expose in timeline
- ... Performance tradeoffs
- Yoav: Long Task attribution, assuming we can actually pull it off, starting profiling when LT is in progress (or if possible retroactively when it started), it could be a big complement around SPA measurement
- ... Generally linking tasks without overhead of profiling, but would only give entrypoint to tasks. Complementing that with LongTask specific profiling could be powerful in my opinion.
- Andrew: With our usage of Profiling API internally, we do a subset of all interactions which is good in aggregate, but we encounter situations where something is bad and we don't have profiling, not enough signal
- NPM: Recall we shipped a version which does not restrict on some initial security primitives, not the case for a lot of the browser work, so is the plan to gate that new feature by these security primitives?
- Andrew: Ideally we can do some as much as we can to origins, investigating from security POV. In many cases we're not able to.
- ... Would have to be some sort of extended security model
- ... Already exists with measureMemory() model where if we're Cross-Origin-Isolated we include additional heap statistics
- Yoav: We have different clamping for timers for Cross-Origin Isolated or not
- Andrew: TL;DR - still exploring
- NPM: Today measureMemory() doesn't work without Cross-Origin Isolation
- ... Long Tasks use-case I find exciting, but the major cost is initializing the profiler. Is this convenience for developers or would we have these on by default? What's the benefit?
- Andrew: Developer ergonomics, you have to define buffers and attribution. Aiming for wider adoption
- ... Conceivable doing stack sampling itself, overhead could be mitigated by one-off sample vs. periodic sampling where we can bail out sooner if we're not a part of a Long Task
- Noam: RE: CPU overhead, for us the approach you're taking using profiler in sampling approach, we do it periodically. Some interval, evaluating performance of profiler.
- ... If you want to overlay that with Long Tasks, you may not hit tasks with profiler
- ... What we think would work is if you have a site that's sufficiently active with samples, statistically you'll get LongTasks and stack measurements and combine them
- Andrew: We're doing something similar, finding intersection with Long Tasks
- ... Main concern is that this doesn't happen frequently enough. Need larger sample size which increases burden in aggregate from profiler.
- Noam: It is a solution if there's no other technical solution from browser
- Nic: If there is an active sampling profiler when the LT happens, you could attach the profile to the LT, rather than doing the intersection later
- Andrew: Looked into that, by providing an ID inside the samples
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Renderblocking attribute - Xiaocheng Hu
Summary
- A proposal for a 'renderblocking' attribute to improve resource loading performance and UX (FOUC, FOIT, CLS, etc.) was presented.
- Then we discussed various extended syntaxes for more use cases, and 3rd party abuse risks with possible mitigations.
Minutes
- Xiaocheng: Proposal for a `renderblocking` attribute for link resources and scripts
- ... Already have a render blocking mechanism in browsers
.png)
- ... Typical timeline is after navigation we block rendering while loading scripts and stylesheets
- ... While we have a mechanism it has some drawbacks
- ... Not browser specified behavior in all cases
- ... e.g. does requestAnimationFrame() fire? Should only be when rendering
- ... Only supports stylesheets and scripts, may want to block on other resources
- ... Only supports parser-inserted resources, resources inserted by script we don't have any way to block render on it
- ... Proposal:
- ... Makes it explicitly render-blocking, or on preload/script
- ... One major use-case is to eliminate layout shift caused by webfonts
- ... Fallback font comes in first while loading
- ... Then we font swap once it comes in, causing layout shift
- ... By renderblocking on font, we're not rendering anything with font
- ... Second use-case is renderblocking on async script
- ... By default it doesn't block parser but we don't know where/when it's executed
- ... A/B testing frameworks that is not that important so it doesn't have to block parsing but we'd like to be executed before rendering starts so we can do some tasks
- ... So we can setup to measure metrics in rendering
- ... Prevent FOUC for loader scripts
- … <shows flash of unstyled content when a site loads>
- … The website is using a loader script so that the stylesheet and scripts are not parser-inserted so they don’t block rendering, which is bad visually.
- … With the renderblocking attribute we can easily solve this by adding it to script inserted stylesheets
- … As a prerequisite we’d need to define what is “render blocking”
- … Proposal is to have the UA enter a render-blocking period after navigation and have that period end when all render blocking resources have loaded
- … side-product: have a before-render listere
- Could examine when the rendering starts or what resources have loaded by then
- Technical details - it’s a boolean attribute, has to be on elements in the <head> and inserted before the body parsing starts. Doesn’t care if element is parser inserted.
- … link has to be stylesheet or preload, on script it mustn’t be defer
- … The other attributes should allow the element to be fetched, e.g. shouldn’t be disabled
- … media attribute evaluates to true, etc
- … renderblocking=false - can be used for async styles, but can be done today with hacks
- … considered adding a timeout, let’s developers decide on the UX, but hard to decide what the value should be
- … RE the proposal to synchronize milestones on page lifetimes, that’s a larger scope problem
- …
- … Web fonts need to be as fast and stable as local fonts, but that’s not achievable
- … We want no layout shift and no delay, but that’s impossible
- … font display optional can give us that, but the font is not guaranteed to be used
- Layout shift can be minimized with size-adjust but not eliminated.
- This proposal enabled us to achieve consistency with delays
- Andy: Coming back to font trilemma, why would someone choose render-blocking over font-display:block for example
- Xiaocheng: font-display:block doesn't prevent rendering for the entire page
- ... The blank space is measured with a fallback font
- ... So when webfont is loaded, we need to swap fonts
- ... So reserved space may get bigger or smaller
- Yoav: A complement to the platform to use-cases you mention. Couple places to make it more extensible, mentioning my proposal for milestones, differences for "before" milestones is that you're not implying any loading semantics when it comes to scripts
- ... Relying on folks to add async attribute, may be interesting to have first semantics but have them be applied before first render
- ... If you have multiple scripts they will run in-order vs. async which is race-y and problematic as Pat earlier described
- ... Might be interesting to think about that
- ... How much complexity would it add to the proposal?
- ... Other point, from a syntax perspective for mPulse they're wanting their RUM loading script to load as soon as possible, but not block any of the events
- ... For that kind of script, not just renderblocking=false but loadblocking=false
- ... Maybe "blocking=render" it could be "blocking=none" or "blocking=onload"
- ... Could give more leeway with future extensions
- Xiaocheng: Broaden scope of proposal
- Nic: I was thinking the same thing. This is focused on rendering but a related use case is a JS library that doesn't want to block the load event. A future extension would be great.
- Simon: I quite like the proposal and it seems like a useful feature. On the topic of future extensions - if we want to do that, we shouldn’t be using a boolean attribute, as current browsers would treat it as a true value and it wouldn’t be future compatible.
- … It should be an enumerated attribute and that would give us more control on what happens with unknown values, for better future compatibility
- … It depends on what we want the fallback behavior to be in future extensions
- … One other thought- the explainer brings up progressive JPEGs as a use case for the timeout extension and my reaction is that a timeout may not be the best way to solve for that. Maybe a “block until image metadata is loaded”, etc instead of waiting on a timeout
- Xiaocheng: would like this to work also on other resources, but for images, we may want to unblock it once certain progress is passed, but hard to define that.
- Simon: The spec has a concept of knowing the dimensions before loading the full image. So defining is possible.
- Cliff: A comment - appreciate the last slide with the trilema for fonts. It’d be very interesting to see data on sites that implemented this, improving something like CLS and what was the impact elsewhere. Would be great to see with data if this is helpful or just providing a footgun.
- … This can be dangerous to give 3Ps the ability to render block the content.
- … Great proposal, but would love to see the impact as a whole
- Aram: Cliff made a good point. The idea of 3Ps implementing this may do so against the will of the site owner, and there’s a high risk for that. It may make sense to add a permission policy so that only 1Ps can set that attribute. I like it overall. I like the timeout approach and I can see how it can be useful for both development and production.
- … It can also put pressure on ill-performing 3Ps, especially if that timeout is trackable.
- … Being render blocking takes pressure off 3Ps and a timeout puts the pressure back on.
.png)
.png)
.png)
.png)


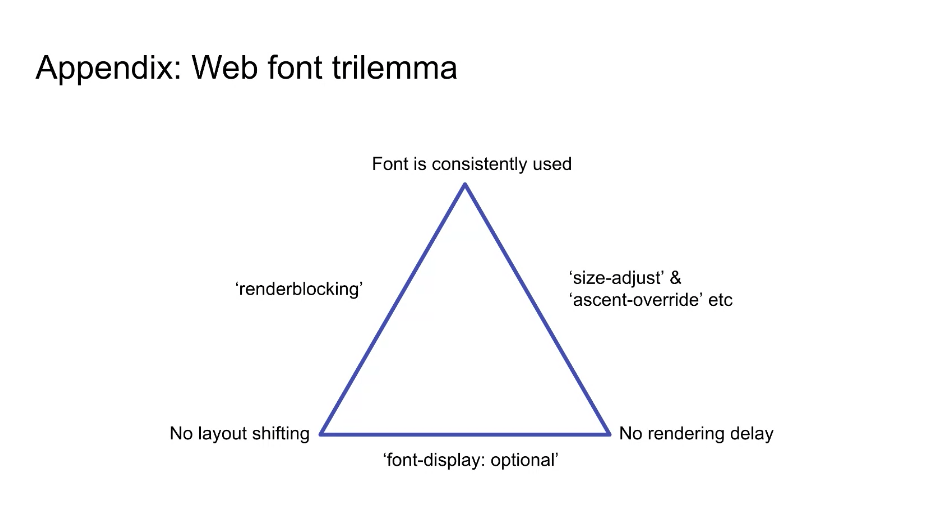
Adopting incubations & spec status - Yoav Weiss
Summary
- Interest in adoption for EventTiming and LCP => Yoav will send CfCs
- Interest in adoption for ElementTiming, but we concluded we’d discuss further on a future call
- Layout Instability: Chrome team to share implementation experience on a future call
- IsInputPending: Blocked on issue 44
- Interesting but too early to adopt: Memory measurement, Scheduling APIs, JS profiling
Minutes
- Yoav: Previous discussion about a year ago on incubations
- ... Conclusions was people needed more time with incubations to see if Working Group has consensus on adopting or not
- ... A year has passed so interesting to go through incubations and see what people think
- ... See if there's appetite for adoption
- ... I can start CfC process
- ... Event Timing
- ... Issue on Github to gather support
- ... Major change here is Mozilla prototyping
- Benjamin: We're OK with this now, thanks for waiting
- ... We're still working on it, but from Issues concern has gone down and we're OK with this
- Anne: Some concerns with how it integrates with DOM spec. Currently ends up monkey-patching the dispatch algorithm to add timestamps here and there. What's the plan there?
- ... Historic problem where webperf specs don't specify principals
- Yoav: Ideally I think we'd figure out a way to create hooks in DOM that call into algorithms in EventTiming or vice-versa
- ... Integration points that are not monkey-patch
- ... As part of move from WICG to Working Group we can take on that work
- NPM: Historically we've taken approach to monkey patch while incubating and once it's more material we can send relevant PRs
- ... Need to accepting positions, so we can move forward
- ... HTML is it possible to have properties for Window outside of HTML spec
- ... As well as hook to update rendering for event duration, we'd add that similar to how we added it for PaintTiming
- Anne: Generally adding new globals is fine, small issues around ordering, we have those all order
- ... Partial interfaces all over, haven't yet become a problem
- Yoav: From Admin POV, I'll send out a new CfC for that to see if there's any objections from other members. If not, we can pull spec in.
- ... ElementTiming
- ... If I remember correctly the position issue was leaning toward prototyping but didn't make a concrete position on that
- ... Any updates from Mozilla?
- Benjamin: We're in a better place here than last year
- Anne: Is Apple on the call?
- Alex: I'm looking up history of this, not on top of my mind
- ... Found history of EventTiming position, and it seems like we think that there are too many proposals solving similar problems
- ... Lack of clarity on #91 for EventTiming on concurrent definition of First Input is unclear
- ... I'll have to look for ElementTiming
- NPM: #91 was closed, so re-open if it's still an issue
- Alex: You're right, seems no longer an issue
- ... No hard objection, just general "we need to examine use-cases" and solve for that
- ... Also seems like with EventTiming people are moving forward, so that has impact
- Yoav: There's a thread ( https://www.mail-archive.com/webkit-dev@lists.webkit.org/msg29850.html)
- Anne: For ElementTiming, there are some issues but they're mostly addressable, we might have a security problem with Decode API
- Yoav: Interesting outcome, I'm planning on talking later today about LCP and animated images and hoping to expose more timestamps.
- Alex: Re: ElementTiming, post to webkit-dev email list last Oct 30th 2021, we're concerned how this exposes paint timing, and the definition of set of known text nodes is unclear, and this API seems to expose significant runtime and memory cost
- Sean: We didn't see huge overhead, not sure if Chromium folks saw something
- NPM: We didn't see anything either, we only need to compute any of the attributes when developer explicitly adds Element Timing attributes to node
- Alex: That's encouraging
- ... But the paint timing exposure is still a concern
- NPM: Not clear about specific concern, but for images we do gate it on TAO. We can already infer some of that information from decode API.
- Benjamin: Is this mostly a privacy concern around exposure?
- Alex: I think it's a privacy concern, not completely sure, just reading things
- ... Seems like there's a way to use this API to determine when things are painted more-or-less, privacy concern
- Yoav: Would it make sense to schedule a separate session in a weekly call to talk through the specific concern
- Benjamin: Would you want to see horizontal review by privacy group
- Yoav: Review would be significantly later down the road, not typically at adoption but later phases when moving to CR
- Anne: Let's do research and come back
- Yoav: Followup on WG calls
- ... Layout Instability
- Yoav: Worthwhile to adopt?
- Benjamin: Have not prototyped, more we look at it the more concerned we are about performance implications, want to prototype more before WG adoption
- ... Agree useful and cool thing, but significant concerns have come up
- Yoav: Make sense to have WG discussion to share Chromium experience to see if there are parallels you can draw from, or just do work internally and come back later?
- Benjamin: Yeah if you want to share we'd love to hear it
- Yoav: Will organize that
- ... LCP
- Alex: Nothing internally on LCP, but LayoutStability
- ... Bookkeeping for LayoutInstabiliy seems burdensome for implementors, but may be done
- ... Animations may not be handled correctly, jank during user interaction may go undetected
- Michal: In terms of "during interaction", if that's related to hadRecentInput, they're still tracked then, but it's just interpretation if they're important by developer
- Scott: Feedback from a consumer of these metrics, LCP has been very helpful for us to detect slow Ajax calls in particular. We're already using it as one of our key metrics for latency, because we can't find something comparable
- ... Correlates to our own analysis for when a page is ready
- ... If not standard, teams will optimize just for browsers that have it
- Yoav: In terms of LCP, do Mozilla folks see it tied to ElementTiming for adoptions
- Benjamin: For implementation perspective for sure
- ... Positions have softened for LCP, clearly useful, lot of spec work went in over the last year
- Yoav: Does it make sense for me to revive the CfC, or is that too early?
- ... isInputPending
- Benjamin: Mozilla has an open bug blocking this, issue#44
- ... https://github.com/WICG/is-input-pending/issues/44
- Yoav: Is Andrew on the call today?
- ... Useful feedback, and I think we can definitely bug folks to see how this would be better defined
- Benjamin: If this can be figured out in the spec then Mozilla is a yes
- Alex: We continue to be opposed due to click-jacking and cross-origin IFRAME cases
- ... Cross-origin IFRAME that then moves, unclear if click-jacking can be prevented
- Yoav: A lot of work went into clear up that area in Chrome implementation before shipping
- ... Might be worthwhile to take a second look
- ... Next step would be to fix up issue#44.
- ... If you could document your issues in Github that would be useful
- ... Then we could have a session where we could talk through this
- Yoav: List of other incubations that have been discussed in the group
- ... Don't have time to talk about all of those specifically
- ... In particular Post-Task that Scott talked about multiple times on calls, having more granular userland coordinated scheduling has shown promise
- ... Compression Streams discussed yesterday in terms on zstandard
- ... Computer pressure newer and possibly more controversial
- ... If you think other incubations could be interest to adopt, let me know
- Benjamin:
- Yoav: CfCs for those?
- Benjamin: Too early, but implementation prototypes in Mozilla for those
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Content negotiation and Client Hints - Yoav Weiss
Summary
- Presented the Client Hints infrastructure as a safer and more correct content negotiation mechanism
- Interest in the infrastructure from both potential consumers and browser vendors, but not necessarily in the WG
- Reminder that existing content negotiation mechanisms are heavily relied upon.
Minutes
- Yoav: Want to talk about content negotiation and Client Hints
- ... Project I’m involved in for many years, and in WG for many years, but for some reason those two worlds never collided
- ... Wanted to talk to WG about that feature, and content negotiation in general
- ... Content negotiation is a thing:
- `Accept` for things the browser says it supports
- `Accept-Encoding` for encodings
- `User-Agent` - heavy hammer that's being used for content negotiation for different things
- `Accept-Language` adapts site's content to user language when it's set
- ... Server adopts response based on headers, not just URL
- ... Also other forms of content negotiation that are geographically based, or other characteristics
- ... At the same time, passive fingerprinting is also a thing
- ... A lot of that information that the headers expose can be used for passive fingerprinting
- ... Enabling servers to tell those users apart without having to do anything about it
- ... As opposed to active fingerprinting, where the server actively asks for information
- ... For example, when asking for info, security and privacy researchers and browsers can spot that fact
- ... That brings us to Client Hints
- ... It’s a content negotiation mechanism that limits amount of information sent by default
- ... Limits passive fingerprinting
- ... Asks for specific server opt-ins for things it needs
- ... Has privacy advantage, as well as correctness advantage
- ... Essentially, the client sends out a request to the server, initial request doesn't contain any high-entropy hints, but just some low-entropy ones that it sends by default
- ... Server then asks for specific high-entropy hints
- ... That opt-in is persistent for the browser's session
- ... Following requests would contain those hints, and the server can do content negotiation based on that
- ... Works great for subresources but less good for navigation responses
- ... Not sent to cross-origin contexts by default
- ... Requires Permission Policy-based delegation for cross-origin resources
- ... Top-level origin needs to delegate to other origins if it wishes to do so
- ... In order to resolve the very first request issue, related proposal called Client Hints Reliability
- ... Parallel Critical-CH response header that origin prefers a redirect over getting the response wrong
- ... Important for correctness issues, once we use CH beyond just an optimization
- ... Avoid issues even in the case of a redirect
- ... Separate proposal called ALPS and ACCEPT_CH HTTP frame
- ... Negotiates hints as part of H/2 or H/3 SETTINGS phase
- ... Stealing a RTT and avoids a redirect
- ... In terms of privacy, information exposed with Client Hints is information that should be regarded as active information exposure as it requires an opt-in
- ... Browser could refuse to send that information, or lie in weird cases (not currently happening)
- ... Don't expose anything new that isn't exposed normally otherwise
- ... Responsive images
- ... User Agent client hints break apart UA string into various fields
- ... Network information is something we've discussed in the past
- And a few more:
- ... Thinking about Accept header as it's getting longer and violates CORS restrictions
- ... One recent example that came up is font negotiation
- ... Some developers want to send dedicated CSS per font technology
- ... For new and exciting font formats, it can get hefty and would like to avoid it
- ... Font format negotiation can be supported by browser in `Accept` headers is not exposed to the CSS request
- ... May be better to try to fix that with Client Hints
- ... Where the server would explicitly indicate which format it is interested in supporting
- Dan: We have been looking at something that could be served like something like this
- ... Concept of something like reduced experience or quality mode
- ... Identifying low-end scenarios and intentionally delivering a limited experience
- ... Avoiding/reducing quality of images
- ... Replacing background videos with still images and stuff like that
- ... Problematic as ideally images are specified in HTML response, don't want to use JavaScript as it delays download
- ... Gets worse instead of better
- ... For images, if CDN understands this part of the request header, it can serve back different image that's lower quality
- ... e.g. replacing video with a still image
- ... Interesting and I like the concept
- Yoav: Would like to see more on device capability front?
- Dan: Battery, dark mode, etc
- Eric: As a consumer of Client Hints, for responsive image solutions, Cloudinary loves Client Hints.
- …Taking complexity out of markup, and moving it to the server, accomplishes a number of things:
- …It makes things simpler for authors, who no longer have to author srcsets (or pre-generate resources)
- …It allows resource selection logic to update over time, evolving in step with best practices, and adapting to new inputs (e.g., bandwidth/rtt), without requiring markup changes
- …It allows resource generation and selection to be informed by image content (e.g., making different decisions for photographic vs non-photographic images)
- …It allows resource generation to be informed by incoming requests (so we generate a set of resources people would actually benefit from)
- …I hope to do some more work quantifying some of these gains
- Sergio: I was wondering if there are any plans or possibility exists for browser functionality of ECMAScript level, solve some issues with differential builds
- Yoav: Short answer is it can be. Client Hints not the issue, but what "level of support X" means
- ... Lengthy thread on HTML pitching a markup-based solution
- ... The main problem there is reaching consensus on what different levels mean
- ... A problem today and not one we have solved yet
- Alex: Our position is often misinterpreted: Client Hints sounds great, a replacement for User Agent is needed and wonderful, we just disagree what parts of it can be trivially queried.
- ... e.g. let's include the amount of memory on the device
- ... That opposition should not be interpreted as opposition to Client Hints in general?
- Yoav: Do you see exposing memory from Client Hints different than JavaScript?
- Alex: No, both should be prevented
- ... Things like DPR, that would be great
- Benjamin: Dark mode?
- Alex: Won't be able to answer the question
- Yoav: We can disagree what needs or needs not to be exposed in JavaScript
- ... Are we OK to adopt CH infrastructure in WG, and talk about specific features later
- Alex: I think so
- ... Whether it's this group or a different group?
- Benjamin: Agreed, not sure if CH is appropriate in WebPerf WG
- Yoav: Opinions on what would be the right group?
- Benjamin: Group on UA versioning in HTML?
- Nic: Comment on the Accept header, I came across a similar issue when adopting AVIF
- … My server infra is sniffing the Accept header, but the CDN cache based on the accept header was cache busting, so the noise of the Accept header was going against me
- … Specific format support headers would’ve been better
- Ian: In regards to Alex, I don't know if it responds directly to Webkit's concerns, with Permissions Policy the developer can block any high- or low- entropy hints with headers
- Katie: As folks are thinking about this, that User-Agent detection and headers that are sent, these are deeply intertwined in multiple parts of our infrastructure. We take fingerprint of order and content of request headers, we identify bot traffic, DDOS attacks, etc.
- ... UA detection not just on website for what to serve, data processing is in multiple layers
- ... There's a long lead time for folks to take investment to change over how we do our UA detection in lots of different systems
- Yoav; Question for how browsers can differentiate appropriate logic from tracking
- Katie: We use UA for proxy for what's available on the client, e.g. screen size, does it support touch, etc
- ... Instead of using UA from proxy, getting that important data we need, sorting out what data comes as part of that navigation
- ... Lot of work we do switching out HTML served to users based on UA
- ... As long as there's really clear guidelines and lead time, for making switch from one to another
.png)
.png)
.png)
.png)
User Preferences Media Features - Thomas Steiner
Summary
- Thomas presented a quick live demo of Google Search using the `Sec-CH-Prefers-Color-Scheme` hint to adopt the site upon the first load, followed by questions around why `media` attribute on `link` wasn't enough to cater for the same use case (since an additional request is necessary, so you can't inline the CSS).
- It was pointed out that this could also improve accessibility (no motion on Apple Watch landing page, but CSS for motion is still loaded).
- Mozilla's (represented through Benjamin) stance was that they don't have an opinion right now. Apple's position (represented through Alex) was that since it's trivial to obtain the same info via JS, this new client hint doesn't cause an additional privacy issue.
Minutes
- Thomas:
- Google has a dark mode, you can see that through devtools by changing the appearance preferences
- …”auto” means you switch to night mode depending on the time
- … Sites that rely on the settings cannot rely on a cookie, as the “auto” mode can switch over time
- … Ideally, we want to deliver the smallest HTML possible, but can’t do that without knowing what color scheme the user may have
- … Google is a pretty lean site, but has a lot of CSS that depends on light vs dark mode.
- … We worked on exposing the user’s preferred color scheme as early as possible.
- … This requires the page to be loaded before we know that info, but we wanted to know that before the HTML is served.
- … Filtering on document requests, we can see that the server send a header `Accept-CH: sec-ch-prefers-color-scheme` and also marking it as a Critical-CH
- … Switching to light mode, you can see that the request indicates light mode and the site responded to that.
- … Idea is to take all user preferences we have in CSS and translate them into Client Hints
- … In Chromium we’ve implemented prefers-color-scheme
- … Got an explainer, ran through a TAG review
- … Trying to get a holistic view on this
- … Using this at google.com and coming to youtube, avoid a flash of light theme
- … Hoping for other vendor interest, because at scale it makes a difference.
- Anthony: why is media attribute not sufficient?
- Thomas: The CSS is inlined to improve performance, so the link element’s media is not sufficient.
- … It could be enough for most pages, but not for high-traffic ones
- Eric: subresources are also a thing that can benefit from this
- … Images can also differ based on dark/light mode
- Thomas: Picture could use the media attribute, but cannot inline
- Eric: No control over the markup, but have control over subresource serving
- … So modifying images based on that seems cool
- Thomas: There’s also page experience difference for prefers-reduced-motion, so it may be interesting for apple.com to not load the motion related code when it’s not needed.
- … Idea is to expose CSS MQ preferences as client hints.
- Michal: The example about the a11y feature shows that your choices are either to delay the response or load the lowest common denominator.
- … For the a11y case, a heavy version is likely to be loaded and then unused.
- Thomas: Saw people comment on the apple watch landing page and investigated it. Saw throttling when not using reduced motion.
- .. asked for Apple and Mozilla positions
- Benjamin: no position ATM
- Alex: I agree that it’s trivially queryable if dark mode, so I don’t think putting it in a client hint is an additional privacy problem.
- Thomas: To add to the privacy question, Brave tells pages that you prefer light mode even if you're in dark mode. So you could lie in MQs as well as CH.
Personalizing Performance - Nitin Pasumarthy, Prasanna Vijayanathan
Summary
- Performance affects user engagement. But sometimes a one size fits all optimization may not be optimal. LinkedIn Lite used Netinfo’s ECT class to dynamically pick image resolutions on feed. Though the online A/B results were positive, this approach had several drawbacks. Netinfo was unavailable on iOS, 80% of users were marked under a single bucket which limited its use, doesn't account for client / device performance and doesn’t differentiate CDN versus data center performance.
- LinkedIn’s performance team designed a deep neural network model to predict the expected page load time (PLT) class using low entropy features like country, OS info, browser info and ASN. These results were better than NetInfo’s as expected.
- They plan to open source this generalized PLT predictor model and also publish a blog on how a performance / frontend engineer can productionize it easily with node.js and use it to personalize their company’s performance at scale!
Minutes
- Nitin: would like to share our work (Nitin from Linkedin and Prasanna from Netflix)
- … How we personalized the experience of Linkedin through 2 approaches:
- … Using netinfo and experience using it
- ... and solved those challenges through ML, how we can personalize performance
- … Linkedin lite is a performance-first site. Want to load 90%ile under 6 seconds
- … All testing is on 2G networks and the site is SSRed
- … First experiment was adapting the image resolutions
- … Linkedin Lite was designed to work for everyone, and wanted to double the size of images to people that can “afford” it from a network perspective
- … Why personalize images - it really drives engagement
- … First approach - NetInfo and on-device measurements
- … Used the API to only view high quality images when the connection was 4G
- … Server side used the netinfo information sent from the client for quality classification and send suitable resolution
- … And then requests to the image provider are for the appropriate images
- … Results
- … pretty good results overall
- … but the downsides were: netinfo is not supported everywhere and iOS is a big share and is not supported
- … 80% of requests are marked as 4g, so we cannot do much to granularity find users with poor networks. Seemed odd.
- … Capped at 2Mbps, which is not future (present, even) proof
- … There was also a significant difference in the distribution between NEtInfo and LinkedIn’s API data
- … May be related to CDN perf vs. data centers, or to the type of requests
- … Netinfo covers the network, but wanted something that covers the device capabilities as well
- … wanted to use page load time to cover the experience more holistically
- … Performance as a Service
- … It’s hard to measure the user’s experience, and doing that in real-time is harder. Wanted to be able to modify pages based on that.
- … also wanted to have this starting from the very first request.
- … At a high level
- … Geo and network from IP addresses and device and browser info from User-Agent.
- … So we built the model and trained it offline based on RUM data
- … and got a correlation of the features to classes and came up with a complex model
- … results
- … better than the netinfo results
- … Very complex model
- … Hard to generalize this concept and build models at this scale, as we have a lot of data
- … Planning to open source this model soon, and explain why we think the model can work for any company
- … How do I deploy this model?
- … Article coming up on deploying this using tensorflow.js node
- Cliff: Awesome presentation and being open about sharing it is great. Curious on netinfo and other things you’re using. Any standards that you would improve to make this easier?
- Nitin: From netinfo’s perspective, our ideal API would be based on entire page load time, and return granular information about downlink throughput, and break it down by CDNs and data centers. They are different in their perf characteristics.
- … If such an API could be built that would’ve been helpful
- Yoav: Would be great if y’all worked with the NetInfo API folks to improve it. Also - what would happen when browsers start masking IP addresses and UA information?
- Nitin: We’d see an immediate drop in accuracy from IP address masking. We’d lose the geography feature. We can try to compensate for it with getting the info from elsewhere.
- … Feature ranking - rank these features based on their impact
- … So when we did that ranking device and browser were the most important and less from IP address
- … But will continue to explore other real-time features
- … Would explore how to use less granular information.
- Yoav: may be interesting to think about a coarse equivalent
- Eric: How do you think about facts about the user’s connection (netinfo) vs. user preferences (savedata)?
- Nitin: Right now the model just gives the quality based on the model, but different teams use it for different things: chang images or some other changes.
- … haven’t considered taking user prefs to the model
- Prasanna: the model didn’t use such features, but could be explored once the model is open sourced
- Nitin: features like number of cores and device memory could be helpful, but we didn’t include them yet. We also don’t yet looking into RTT and throughput exposed by netinfo, but planning to look into it.
- Prasanna: Wanted to add that collaboration on netinfo - having smartness go into netinfo could move that processing to the client side.


LCP updates - Yoav Weiss
Summary
- Presented various efforts to improve LCP
- Positive feedback on the metrics (correlates with business metrics)
- Missing point for improvement: inline SVG elements should be counted for LCP
- Otherwise, there’s clear need to fix background image heuristics
Minutes
- Yoav: Talked a lot about LCP in the past
- ... Looking for updates or improvements or ways it can be better
- ... LCP has shipped in Chromium/Chrome for a while
- ... Gathered data showing correlation with general performance
- ... And now case studies showing high impact
- ... Very strict A/B testing conditions show increased sales by 8% which is a lot
- ... Clear studies showing high-impact for metric
- ... At the same time, exposure in wild shows some gaps we need to better handle
- ... Progressive images not accounted for, last frame of image is rendered, where other frames could be good enough
- ... Similar situation with animated images that are auto-playing, first fully-rendered frame is good enough paint point other than waiting for full video/animation script to end
- ... Videos are currently ignored, video posters are taken into account, where auto-playing ones are not. Discrepancy vs. animated images.
- ... Canvas is currently ignored, maybe it shouldn't be
- ... Background image heuristics are not ideal
- ... There are also some loopholes, techniques making rounds to trick the metric
- ... Good to cleanup from metric perspective
- ... Ways that metric diverges from actual user experience and that's not great
- ... For Progressive Images, a lot of discussion on a couple issues between folks from image compression community and folks working on LCP to try to figure out a way to account for progressive images
- ... Looking for heuristics that can apply to progressive jpegs
- ... Also JPEG-XL looking to the future, but not a current issue
- ... Right now we're trying to get industry data on progressive images
- ... Some teams saying we need to make sure metric is nudging folks towards the right behavior
- ... Despite having opinions for/against progressive images in the community for 10+ years we have very little data showing progessive rendering is actually better than non-progressive rendering. I found no data.
- ... Seems we should figure out that point before making a call on progressive images
- ... Some research was done on that front, is highly contentious
- ... I'd love to see data from folks serving images. See what's driving more engagement and getting happier users
- ... Beyond progressive, there's Animated Images
- ... Linked issue where we aim to report first full frame
- ... Do we want a new attribute to expose that first frame?
- ... Don't want to overwrite the current (final frame's) render time
- ... When to report the LCP candidates? Right now high linkage between time entries reported and its actual render time
- ... If it's the first frame time we'd consider “start time” for LCP, we may want to report the entry before it’s done and change it later. Tradeoffs either way.
- ... Related to that, do we change current startTime from render time to first frame time
- ... Similarly all those questions apply to videos
- ... Plus do we want to report auto-looping videos for LCP candidates
- ... My opinion is we do but would want to hear of any other concerns
- ... Canvas is currently largely ignored, want to take draw-image calls into account
- ... Maybe we can consider other canvas operations
- ... Discussion worth having
- ... Better aligning metric with UX, how to handle low-entropy images
- ... e.g. Creating an infinitely large transparent SVG
- ... Better detection for background images
- ... Currently all things I'm actively looking into
- --- discussion ---
- Dan: As you know we've had a lot of discussions around LCP, I would like to start by saying it seems to me part of the issue with LCP and all CWVs, simultaneously used to improve performance of webpages but also for SEO
- ... A lot of these things around gaming metrics are because they're used for SEO, or trick contractors
- ... If we didn't have this issue, used for performance purposes, we'd need to concern ourselves a lot less with gaming the system
- Yoav: To some extent. Metrics by definition is gamification of web performance. And when you gamify things, there can be cheating
- ... Examples of folks out there that are cheating Lighthouse, which doesn't have SEO implications but it is perceived
- Dan: Perceived SEO possibly
- ... With regard to low-res images, should have impact on metrics just not LCP
- ... LCP is for when page is visually complete
- ... Given existence of metrics like Speed Index, value in building up display gradually
- ... Value in low-quality placeholders, just not as part of LCP
- Yoav: Goal for progressive images is to not account for low-quality placeholders, but if you have 80% (for example) of progressive jpeg, the visual difference between that and 100% of the image may not be visible.
- ... Created a benchmark that is not publicly available, and it is hard to tell apart images once a certain number of scans is there, tell apart that image from eventual image.
- ... Question that I got that I don't have an answer for is, why don't people compress images to visually complete and not send more?
- ... Goal is to not account for low quality placeholders, but for hardly-distinguishable from final image quality
- Dan: Would agree with that sentiment, maybe smaller images can be sufficient, if they’re good enough
- ... On the front of background images
- ... This heuristic of what image needs to be, is highly problematic
- ... If you accept canvas, you should accept SVGs
- Yoav: Different between SVG element and SVG images
- ... Another point to address
- Dan: They do account for FCP of course, discrepancy for FCP and LCP
- Cliff: Comment around gamification, any time you tie an incentive to a metric that's not tied to UX, you're going to see this. It's human nature. It's an outcome, but doesn't account for all other improvements others see.
- ... It sucks but and we should go after snake-oil salesman
- ... We shouldn't discount progress we're making
- ... For progressive rendering especially, that's opinionated, maybe for starters look at median
- ... In general my feedback would be we're seeing a lot of stories where this is having an impact on UX metrics and business outcomes
- ... On whole LCP improving things
- ... Still benefiting us for the greater good
- Yoav: One point on progressive rendering, it's very hard to do that in real time. Approach we're trying to take for progressive jpegs, regards number of bits for each pixel from overall 8-bits as a proxy for final quality. Can be computed relatively quickly. Can't do complex image analysis on the fly. Some heuristic-based.
- Cliff: Understandable, more point that we can continue to make it harder to game, improve edge-cases and we'll see improvement across the board.
- Katie: We have run experiments with progressive images, I don't have data at hand, but I can see about finding results and sharing it.
- ... At least one we ran on iOS apps, we'd know if it improved conversion or not and business metrics
- ... I can try to get more data
- ... We love LCP out of all CWVs, has most correlation with business metrics
- ... FID graphs all over the place, same for CLS
- ... LCP clearly as bounce-rate goes up and conversion goes down
- ... I'll have to talk to legal folks but will see what I can share more broadly with the community
- Benjamin: Comment about Canvas and SVG element
- ... Big deal and I'd like to see SVG element support even without other nested SVG elements
- ... Important and it's going to resolve some oddities with video and animated
- Yoav: I think the exclusion of SVG elements is just implementation complexities, not anything beyond
- Katie: Since we're talking about that, we have an internal metric where logo renders, and we use inline SVG, a little annoying no good way for us to measure it with rAF() call and inline JS, but awesome if inline SVG were included
- ... Marketing pages with inline SVG as header image
- Benjamin: We can start with subset of SVG that allows for shapes and text would cover a lot of use-cases
- Dan: Stress again how problematic the lack of distinction between foreground and background images.
- ... Get decision and move from FMP to LCP, but reality where some sort of big background image that's not 100% of viewport is problematic
- ... We're seeing lot of cases where images not important for page are being used as element for LCP
- ... Another problem is around use of auto-playing animated galleries
- ... WIX users use animated galleries
- ... LCP would be second or third image in gallery which is artificially delayed, and that's a problem
- Yoav: Why isn't first image in gallery being picked
- Dan: First image may have lower resolution, in some cases where galleries change size
- ... Mostly about resolution
- Yoav: If you have specific examples and can open issues
- Dan: We've resized downloaded image to fix resolution, but can open an issue
- NPM: We're aware heuristic for background images is not perfect. Hard for an arbitrary website. Based on the size is it the main content? Based on other characteristics, if it's clearly not, what could we use to determine it's not the main content on the page?
- ... We've tried to fix carousel by not ignoring removed elements
- ... But if you have smaller image then larger image in carousel, since it's a larger image and the user hasn't interacted
- ... Hard to distinguish that vs. something else like image just loaded later
- ... Github tracker for posting issues and things to do to improve metric
- Sergio: Issue not directly a problem with metric itself. loading=lazy. In case of WordPress, core has started lazily loading images by default, could be cases where it's hero images or things that are LCP candidates
- ... I don't know if that goes towards Nicholas's point where using "lazy" as a signal, I could see this going either way
- ... Problem we've come across somewhat often
- Patrick: Problem is when lazy gets slapped on everything, the actual Hero image may have Lazy on it. Bad for all sorts of reasons, if we use that as part of heuristic the problem would be ignored
- Yoav: For my perspective, this is LCP is doing its job, signalling a real issue
- ... Images loaded after layout
- ... LCP is helping point to real issues
- ... Complex setup for many people to get right
- ... Solution is to fix loading=lazy to be more viewport-aware (no clear answer, current situation is not great)
- Benjamin: Question not about LCP, how Web Vitals evolves?
- ... When first presented, talked about how it would be updated every year
- Annie: What we said when we launched is we wouldn't update the set more than once a year
- ... Ecosystem takes a long time to adjust to them
- ... People will most likely optimize for the metrics if we give them time
- ... Focusing on getting feedback from different sources
- ... Not trying to stick to a schedule
- ... Web Vitals metrics that may not be graduated to enforced in search
.png)
.png)
.png)
.png)
.png)