Participants
- Nic Jansma, Yoav Weiss, Rafael Lebre, Hemanth Kishen, Garrett Rieger, Amiya Gupta, Carine B, Noam Helfman, Alex Christensen, Benjamin De Kosnik, Giacomo Zecchini, Abin Paul, Patrick Meenan, John Engebretson, Mike Henniger, Dan Shappir, Lucas Pardue, Zach Leatherman, Michal Mocny, Myles Maxfield
Admin
- Next Meeting: July 21st 8am PST / 11am EST
Minutes
Incremental Font Transfer review - Garret Rieger
Presentation recording (partial)
Summary
- Incremental Font Transfer enables use of web fonts in cases where it’s currently infeasible (e.g. CJK, emoji fonts) due to font size
- Two methods: patch subset and range request. Patch subset is better, but requires a smart server.
- The WG showed enthusiasm and provided feedback.
Minutes
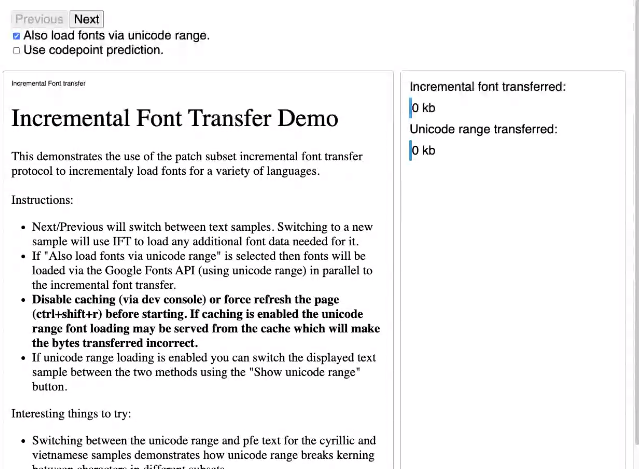
- Garret: Working on a new transfer mechanism for fonts
- ... Example for CJK fonts, have 60k+ characters in a font
- ... Typically most pages only need ~1k characters at a time
- ... Naive way is to load full font, several MB, but you only need a small part of it
- ... Attempts to solve this over the years
- ... Notable one us Unicode Range, loading subsets
- ... This is better than sending the whole font, but not ideal as it still sends more than you need
- ... Interactions between characters in different subsets no longer work
- ... e.g. in Arabic, interactions between characters and you can't break them up into subsets
- ... IFT attempts to solve this
- ... You leave font as one complete unit, your client loads parts of the font
- ... When you go to another page, you can patch in more data for that font
- ... Keeps those inter-character interactions intact
- ... Demo in WASM
- ... Comparison of IFT vs. Unicode range
- ... Loading font from server, patching, just like a real implementation of IFT would
- ... IFT grabs 11 kb, Unicode grabs 32 kb
- ... Next page with new characters
- ... IFT added in extra data that was missing
- ... Unicode range already had what it needed
- ... Several more navigations:
- ... Now Unicode needs to grab more for new language
- ... When switching to Unicode range, the kerning rules between the characters don't work, and things like the "period" after the "y" in the title are off
- ... With Chinese:
- ... Unicode grabbed ~800kb data, vs. IFT 113kb
- ... Also an interesting scenario is with emojis
- ... Unicode range is quite large
- ... End of demo
- ... What's going on under the hood
- ... Specification gives two methods for IFT
- ... First method, Patch Subset, shown through simulations is superior to the other method, but significant downside -- intelligent server required to run
- ... This option may not work with vanilla CDN
- ... Second method, Range Request, server-side just needs to be a HTTP server
- ... Won't be as efficient as the first one, but will give options for people to use this tech
- ... Patch Subset: The client sends a request that says "I have a font with these specific code points, plus additional code points", server determines the state the client is at vs. where it should be, generates a patch
- ... The client will take that and generate the set
- Myles: Range Request is a similar method where it's based on the model of video files, you can seek to the middle to start playing. This is a similar model where if the font has a TOC that maps glyphs to byte locations in the file, then the browser can download that particular range
- ... Metadata piece at the beginning of the file that has the map of glyphs to byte ranges, browser downloads whatever it needs via Range Requests
- Garrett: Person authoring the page just says "I want to use IFT", and the server determines the method to use
- ... Any questions?
- Amiya: Great demo. I was wondering if the TOC approach is already part of the font, or does it add an overhead?
- Garret: No changes to fonts themselves, but we require glyph table at the end of the font
- Patrick: Wondering if you have a sense for how often within a given origin or site you get needs for different subsets that would justify patching vs. a subsetted font for that site
- Garret: Multiple subsets generates quite a few additional network requests which is detrimental to performance.
- ... Server can send back more characters than was requested by the client
- ... Intelligent server could decide to send more
- Patrick: With cache and network partitioning, a given font file is less likely to be used across origins/sites
- ... Full font vs. subsetted to that site's needs, do you have a sense for how many sites would benefit from incremental approach vs. just subsetting their content?
- Garret: Some sites will have a fixed or well-known subset ahead of time. IFT may not be as useful in those cases.
- ... IFT is more useful where content isn't known ahead of time, e.g. chat, social or news site with comments on it.
- Myles: Common for website with many different pages to have the same CSS and Fonts for each, when making it you may not know which pages it apply to
- Noam: First of all, great proposal. Glad to see cases for error handling and retries. In places where we dynamically loaded web fonts in the past, error handling wasn't reliable.
- Garret: For the Patch Subset method, we have checksums in request/responses to make sure everyone's on the same page. i.e. server assumes they have one version of a font but the client has another. Checksums help keep everyone in sync
- ... Server can respond in a way "replace your whole font with a new one instead"
- ... Allows for font version upgrades to potentially happen
- ... Server can send a patch to get someone up from v1 to v2
- ... Spec does talk about how to handle error scenarios
- ... Definitely let us know / file an issue, because we want to make sure it's well addressed in the spec
- Zach: Two questions. First, when I do web font loads, and I'm trying to do the font load before the first render, it's a race. Can I use this, or is it too slow to load a small subset, then load below-the-fold characters later?
- Garret: We think there's a good use-case here. We're aiming for this to be extremely fast. We developed a very fast Harfbuzz subsetter for this purpose.
- ... Hoping it'll be indistinguishable from a static file load
- Myles: We could add an API to the platform for loading content above-the-fold vs full.
- ... We could have this in link rel=preload, etc
- ... Spec doesn't have any of this stuff right now, but would be a welcome addition
- Zach: Do you have a sense of what the overhead differences between Patch Subset and Range Requests are?
- Garret: Not yet, but I could send it out to the mailing list
- ... Why there is the difference in overhead between the two: in Range Requests there's no compression across the different ranges, and each is compressed separately from the others. Patch Subset uses a shared dictionary. For CJK there's benefits to referencing a character set the browser already downloaded earlier.
- Myles: Range Request just gets regular HTTP compression (for that request)
- Yoav: Think this could be a game-changer in use-cases that aren't currently possible
- ... Hesitant in cases where this is possible, will this be faster?
- ... Similar to what Pat mentioned around Font Subsetting vs. this
- ... Reading through the spec, I have questions but I'll file issues for most
- ... I thought the negotiation part of the protocol is unorthodox, i.e. w/ query parameter is not done elsewhere
- Garret: Someone has also pointed this out, there's a QUERY HTTP method that might get past some of the weirdness
- ... Constraint we're working on is that the first request doesn't need a CORS preflight, query parameter is the only way we can make that happen
- ... With QUERY, we still get that but it works more like a POST request
- Yoav: Answers my question of why not use a request header, because it triggers a CORS preflight
- ... Have you considered delivering the glyph dimensions first? From a font delivery perspective with layout shifts, once browser has dimensions, it can set a final layout
- Garret: With Range Requests you download the header with the shapings you need
- ... Interesting for possibility of that on the patch method
- ... Could request sizing. Not something spec talks about, but doesn't prohibit either
- Noam: In Excel Online, we try to provide a fast page load experience by showing a preview of the page before content. Sometimes preview is from local cache, which means client may not have fonts to fully render the content
- ... What we do is we use a list of fallback fonts, and once loaded, we render everything
- ... We would like to have that time period as short as possible
- ... Takes a lot of time to load the real fonts if it's missing
- ... We usually don't need all contents, just parts of the glyphs
- Garret: Could definitely help. With IFT it can grab a small subset. If you need more later it can be pulled in.
- ... One more use-case is with fonts that cover all languages, e.g. Google Fonts. Use that font and whatever language comes up it pulls in just that section
- Amiya: Is there a threshold for how often the User Agent should make these patch requests? Every character? Batching these requests?
- Garret: We leave that up to the implementer. Spec mostly covers protocol between client and server.
- Myles: There’s also a privacy concern that the font server would learn things about the page’s content.
- ... One of the ways we're mitigating that is by injecting noise
- ... That process from browser's perspective, starting at page and requesting content, requires content modeling and prediction
- Garret: If content is being added, you may want to delay a bit before you make the request
- ... We're hoping the server or client can request more than they need
- ... So if we can smartly grab the set of characters, then you may only need a few small requests
- Yoav: On the privacy front, we'd be sending client state to servers that only currently get CORS-anonymous request
- ... Servers are not getting any kind of state
- ... Since font would be partitioned on top-level origin, it may not be awful
- ... I didn't see this in the Privacy Section of the spec
- Garret: Things like Unicode range, can see what the client already has depending on what they request.
- Yoav: I guess we can also mask current state by injecting noise into the current state
- Garret: Please open issues for any feedback you have
- ... https://github.com/w3c/IFT/issues/
- ... Will send out results of report to mailing list
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Field-based User Flows - Michal
Summary
- Problem: Field data shows performance issues, but we cannot reproduce locally in order to debug. How can we reproduce field results locally (Understanding User Journey)?
- Prerequisite is to understand the user environment (correct site, network, device, geo) as well as metadata about the metrics (which route, loading vs post-load issues, which dom nodes shifted/interacted)
- Potential solution: could we use performance timeline to report a full User Journey in a format that tools like Lighthouse/WebPageTest can replay?
- Demo: A prototype that achieves the above, using EventTiming.
Minutes
- Michal: We wanted to talk about a problem we're hearing more and more about
- ... New and exciting capabilities
- ... Moving from field results to lab reproduction
- ... Replaying user journeys
- ... Problem: You have some field data that suggests there's some sort of metrics problem. e.g. CWV from Page Speed Insights, CrUX. Maybe you have your own RUM analytics that suggests users are having a problem.
- ... You try and fail to reproduce locally
- ... Surprisingly common problem, and increasingly so
- ... With CLS, this can happen (and with INP)
- ... Not quite sure: Is field data wrong?
- ... Has it already been patched?
- ... First steps is to test same site your users are using
- ... Are you actually testing against production? vs. staging/local
- ... Network differences or device specific differences
- ... Setup specific caching conditions
- ... Client-specific state, i.e. logged in, or they were getting a sign-up flow
- ... Third-party specific state, e.g. ads or extensions
- ... These days it's more than that, especially for full-page lifecycle metrics
- ... e.g. CLS high in field, I tested locally (Lighthouse, doesn't interact with page), developer can't repro
- ... But CLS is recorded not just page-load, but also through page life
- ... If you know from field data that it's coming post-load, you should know Lighthouse will never uncover that problem
- ... INP is an interaction metric, which Lighthouse doesn't do
- ... Right now it's guesswork, to try to find what interaction by what user and why
- ... If you're collecting your own RUM metadata:
- ... Tracking down CLS issues, not just total CLS, but what was time of the largest CLS window, which element shifted the most. What route was the user on?
- ... INP time of interaction, was it tap vs. keyboard, which key, what element was being interacted with
- ... All of this data is very useful
- ... Philip Walton has written about measuring CLS in the field, going from field to lab
- ... Alongside recording CLS for page, he recorded the single worst element to shift
.png)
.png)
.png)
.png)
.png)
... In this particular sample site, there's only one issue that stands out.
... If you see a table like this, and you're the author, there's a strong hint of what's going on
... Only 18% of visits/users, what's the likelihood of being able to reproduce without this table guiding you?
... This is CLS, but INP is a post-load metric first and foremost
... If you're already using an API like EventTiming to capture interactions, and you have attribution, there's a new set of features in Dev Tools and Lighthouse around User Flows
... Record and re-run
... Useful for CI and testing
... As an experiment, would it be possible to take PerformanceTimeline, could you construct user-flow that you could replay automatically in the wild
... Trivial to set up
.png)
... Go from node to query selector
... Selectors aren't always stable across renderings
... Use performance APIs
.png)
... Get a list of things user clicked on, and in what order
... Example from in the field:
.png)
Now I can replay using a snippet like before
.png)
... Bunch of different ways to do this type of replay
... DEMO
... Get a Lighthouse Timespan report
.png)
... Lighthouse has audits for INP
... A lot of style and layout and rendering delay afterwards
... WebPageTest script automation
.png)
... Made an alternative converter for WPT scripting format
.png)
... Out of the box no problem, runs in WebPageTest
.png)
... Mostly a load-based audit
... Agg field data users experience is the truth. A single lab replay is an anecdote, and easy to miss seeing these real issues
.png)
... Setting up the right environment is first and foremost
... Following the right user flows is important for post-page-load metrics
... If you record metadata about your vitals, field data might give you enough to know what to target
... But beyond that, we could use PerfTimeline to automate flows for replay
... PT limited and EventTiming API has its limitations
... Do we need to do more in terms of creating full field-data User Flows
... Maybe we need a first-class Performance API for that
Pat: Good overlap between this and the self-profiling API, especially for INP if you want to get profiles of field data
Michal: One common request we get in particular is if it's not input delay and not processing time, and a huge gap in time of presentation delay, what is happening there? Style, layout, etc? Self-Profiling can help there in particular.
Pat: I don't think there's any part that helps w/ diagnosing extension-related performance problems though
Yoav: I don't expect us to have that ability due to fingerprinting concerns
Nic: Thinking about this a lot. With Boomerang we’ve tried to capture that in the past (interactions, mouse movements), and being able to go from the problem to how to solve it is the golden ticket for our customers.
… Try to capture attribution on the beacon, but hard to translate this to something actionable
… Would love to see how this works out in practice. Very promising.
Noam: Problem/use-case is extremely important. We do this on a daily basis.
... back to Patrick's point, we use JS Self-Profiling API. But to do that, we use EventTiming and cross samples with ET API. So we know where to focus instead of fixing random slow callstacks.
... We get what is slow, and what is the root cause.
... If this is due to sync layout or rendering or style calc, this is a huge challenge for us, and we're promoting the "markers" feature for JS Self Profiling as it would help there. It would give us a root cause in production for users.
... We rarely use lab perf test for those challenges
Michal: There are a set of features that the best in the world need to solve problems for their customers. Which is different from the majority of users, who just need to know how to solve CWV problems. Different solutions for each
Dan: Just wanted to mention that I'm facing a current real use-case. On one of our applications, we're experiencing bad 90 percentile performance on low-end devices. Just being able to tell if the majority of the issue is slow-networks or slow-cpu is very difficult. Knowing that would help us know where to focus our efforts to get biggest win
... Maybe sum up LongTasks over time and get that data back
... Not necessarily guaranteed all CPU time is spent in Long Tasks, could be in shorter tasks
... Just knowing CPU % within period of time, even without attribution, would be useful
... Strong indicator of the direction to take
Michal: In that case are you trying to answer the question "is the environment at fault" or the "site at fault".
Dan: Is the problem mostly network related (API calls to backend are taking a long time to complete, backend is slow) or about just high CPU utilization on low-end devices due to third-party scripts etc
... For example we made significant effort, reduced a lot of script download, but impact has been negligible
... Show impact to bosses, the effort didn't justify the results
Yoav: Do we need browser APIs that make this easier?
... e.g. the getSelector() hack should be easier to do
... Maybe need a way to buffer ahead of time, capture all of EventTiming below 16 or all in general for this kind of use-case
Dan: Based on real use case, this would've been useful for me at WIX
... Whole bunch of websites and little insight into how each were built
... Really challenging when we had large CSS values to identify main culprit
... Type of image instead of specific image
Nic: Can we do a hands-on at TPAC?
Everyone: YES!