WebPerf WG @ TPAC 2022
Logistics
Where
Monday: North Tower - 3rd floor - Junior A
Tuesday: South Tower - 4th floor - Granville
Thursday: Residential/Concourse Tower - 3rd floor - Finback
Friday: North Tower - 4th floor - Port McNeill
When
September 12,13,15,16 2022 - 9am-12pm PST
Registering
- Register! https://www.w3.org/register/tpac2022
- Register by Aug 05 for the Early Bird pricing
- Health rules: Masks on, daily COVID tests
- All WG Members and Invited Experts can participate
- If you’re not one and want to join, ping the chairs to discuss (Yoav Weiss, Nic Jansma)
Calling in
Attendees
- Yoav Weiss (Google) - in person
- Nic Jansma (Akamai) - in person
- Barry Pollard (Google) - in person
- Patrick Meenan (Google) - Remote
- Jeremy Roman (Google) - in person
- Sean Feng (Mozilla) - in person
- Simon Pieters (Bocoup) - remote
- Michal Mocny (Google) - in person
- Amiya Gupta (Microsoft) - remote
- Rachel Wilkins (Bridge and Switch) - remote
- Ian Clelland (Google) - in person
- Andrew Comminos (Meta) - in person
- Scott Haseley (Google) - remote
- Kouhei Ueno (Google, Tokyo) - in person - near the door
- Paul Calvano (Etsy) - remote
- Nolan Lawson (Salesforce) - in person
- Noam Helfman (Microsoft) - remote
- Dominic Cooney (Meta) - in person
- Andy Luhrs (Microsoft) - remote
- Benjamin De Kosnik (Mozilla) - remote
- Steven Bougon (Salesforce) - remote
- Theresa O’Connor (Apple, TAG) - in person, just for the PING joint session
- Charlie Harrison (Google) - in person
- Jeff Jaffe (W3C) - part-time in person
- Aram Zucker-Scharff (The Washington Post) - in person, early departure
- Alex Christensen (Apple) - in person
- Andy Davies, SpeedCurve - remote
- ... please add your name, company (if any) and if you’re planning to attend remotely or in person!
Agenda
Times in PT

Monday - September 12
Timeslot (PST) | Subject | POC |
9:00-9:30 | Intros, CEPC, agenda review, meeting goals, introspection | Yoav, Nic |
9:30-10:00 | Noam R (Yoav) | |
10:00-10:30 | Domenic | |
10:30~10:45 | Break | |
10:45-11:00 | Amiya G | |
11:00-11:30 | Michal | |
11:30-12:00 | Barry | |
12:00-13:00 | Lunch | |
13:00-17:00 | Webperf Debugging Workshop (in-person) | |
17:00-17:30 | Mark Nottingham | |
17:30-18:00 | Fergal |
Recordings:
Tuesday - September 13
Timeslot | Subject | POC |
9:00-9:30 | Noam R (Ian) | |
9:30-10:30 | APA joint meeting: Accessibility and the Reporting API | |
10:30~10:45 | Break | |
10:45-11:30 | Alex C | |
11:30-12:00 | Yoav |
Recording:
Thursday - September 15
Timeslot (PST) | Subject | POC |
9:00-9:45 | Responsiveness @ Excel | Noam H |
10:00-11:00 | PING joint meeting:
| Yoav |
11:00-11:15 | Break | |
11:15-12:00 | Colin |
Recording:
Friday - September 16
Timeslot (PST) | Subject | POC |
9:00-9:30 | Nic | |
9:30-10:00 | Yoav | |
10:00-10:30 | Amiya | |
10:30~10:45 | Break | |
10:45-11:30 | Performance beyond the browser | Lucas |
11:30-12:00 | Yoav |
Recording:
Sessions
Intros
Summary:
- Review of 2022 highlights, including processing model changes and features added to ResourceTiming, adopting LCP and EventTiming, and moving some specs to HTML
- The Working Group continues to discuss WICG incubations, and some of these have been adopted in the past (future session discusses rechartering and these incubations more)
- Review of Code of Conduct, Health rules and Agenda for the week
Prefetch processing model
Summary:
- Proposal - `<link rel prefetch>` would be only for same-origin document prefetches, and same-partition subresources. We’d remove the “5 minute rule” and apply regular caching rules. (other than ignoring `Vary: Accept` at consumption time.
- An “idle priority” preload can replace some of the current uses for same-document prefetch (even if preload is mandatory, and prefetch is not)
- Dropping the “5 minute rule” would reduce some current usefulness for same-origin navigation prefetches. We should look into the impact, and if we go ahead with it, tell developers about it (and have them e.g. use stale-while-revalidate)
No-Vary Query
Summary:
- General positive reception.
- Points raised during discussion:
- Be sure this gets surfaced to HTTP WG to maximize the likelihood this gets used throughout the stack, not just in browsers.
- Some worry about people losing their ability to cache-bust if they accidentally use No-Vary-Query: *. A number of possible mitigations were mentioned.
- Unclear how `No-Vary-Query: order` treats differing values, e.g. ?a=1&a=2 vs. ?a=2&a=1. The explainer needs to be clear and maybe add different variants.
Element Timing and Shadow DOM
Summary:
- Element Timing API is an important step forward for pages to observe rendering performance
- Unfortunately Element Timing does not support Shadow DOM; pages using Web Components cannot use this great API
- Largest Contentful Paint does include Shadow DOM elements in its calculations, which is seemingly inconsistent behavior; we should work towards ensuring Element Timing can support Shadow DOM
- Discussion:
- LCP spec relies on Element Timing, so has a similar issue (even if Chromium implementation diverges)
- We should fix this and there are multiple options to do so
- Continue discussion in a followup call
Exposing more paint timings
Summary:
- Multiple specs refer to “paint timings”: Paint Timing, Element Timing, LCP, Event Timing… summarize the different ways there timings are currently specced and how they differ
- Showcase an example, using FCP and Image decode (sync, async, decode()) how there are interop issues across all browser implementations.
- Propose that there is no single best time point that works for all use cases, instead, we should expose multiple time points with unique names (as we already do with loadTime + renderTime, and as we already plan to expand with firstAnimatedFrameTime etc)
- Discussion
- WebKit implementation is being modified and observed differences may change
- Firefox aren’t interested in exposing “commit to GPU” timestamps, due to privacy concerns
Super early hints
Summary:
- Proposal to allow early connection hints, perhaps through SVCB DNS header, to allow frequently used domains (e.g. asset domains, or image CDNs) that are used on most pages, to be initiated at as soon as connection is opened, rather than wait for first response to HTML response (either through 103 Early Hint preconnects, or within HTML response).
- Proposal was positively received (Cloudinary expressed interest).
- Next steps: discuss with SVCB spec owners if that is a good place for this. Email thread started.
CDNs and resource timing info
Summary:
- Proposal to add cache and proxy information to resource timing, to allow better measurements of CDN (and similar) performance (compared to synthetic measures used today). E.g., cache hit latency, miss latency, hit ratio. Next step: develop a proto-spec.
Unload beacon
Summary:
- Proposal to provide a web API that reliably sends queued requests on page discard.
- Clarifying API behaviors: a single PendingBeacon object represents a request, backgroundTimeout vs timeout.
- Discussions around API’s capabilities: e.g., can it be abused, how long should a beacon stay alive, etc
Resource timing and iframes
Summary:
- Presentation on the cross-origin information leaks made possible because iframe resources are included in resource timing.
- Proposals to remove them or reduce the information obtainable through that API.
- Discussion brought strong preference towards “option 3”
- “Do something different between same-origin/TAO frames (measure first navigation and report as completely as it can) and cross-origin/no-TAO just gets start and time of the load event”
- There’s some hesitance RE it throwing the complexity on API consumers. Need to better understand that cost
- Aggregated reporting may save us in the future
APA joint meeting - A11y and the Reporting API
Summary:
- The APA would want Reporting API to have reports on automatically detected a11y issues, user reported a11y issues, slow loading sites
- Such reporting would need to take user privacy into account - there’s tension between user’s need for accessible/adapted experience and not revealing themselves as AT users
- There’s potential interest in satisfaction survey reporting
Server Timing and fingerprinting risk
Summary:
- Server Timing enables a passive cross-origin resource to communicate information to the Window, that can then be read by other cross-origin scripts run in the top-level document’s context.
- Apple wants the UA to be able to not expose the info across sites (TLD+1), and potentially across origins.
- Same question for transferSize, encodedBodySize, etc
- Agreement from RUM collectors that same-site Server-Timing and sizes is better than none.
Aggregated reporting
Summary:
- Proposal - we could safely expose some cross-origin data if we only do that in aggregate, by relying on Aggregated Reporting.
- Need to be careful not to expose business data of embedded pages - that’s different from current threat models, where we protect user data
Responsiveness at Excel
Summary:
- This talk goes over the journey Microsoft Excel Online went when trying to find an effective user facing responsiveness metric.
- We explain how we measure responsiveness on the client using Event Timing API and then the different ways we explored to utilize the measurement to define a new responsiveness metric which is effective in detecting regression and has high reliability.
- We show how using the Average Session Responsiveness metric turned out to be a very effective path and propose an hypothesis why that is.
Joint meeting with PING
Summary:
- Discussion on the principles around opt-outs for ancillary data, vs. ancillary transport mechanisms.
- Some agreements, e.g. turn off reporting when JS is disabled
- Some disagreements, e.g. whether we should provide an opt-out for the transport mechanisms, that’s equivalent to a “do not monitor me” bit
- We’ll continue the conversation
Early Hints - lessons learned
Summary:
- Mileage varies wildly - early Hints & Resource Hints still require context and developer intention to get it right.
- Most of the gains Shopify saw were from pre-connect and unblocking the tcp+tls bottleneck
- There are a number of outstanding issues to be resolved: reporting the initiator, responseStart definition, and sub-resource early hints
Rechartering
Summary:
- Need to re-charter for 2023 (2021 charter expires in February 2023)
- A few specs have been moving out of WebPerfWG and into HTML, this is good
- We've recently brought in EventTiming and LCP
- Discussed barriers to Layout Instability
- Considering bring in parts of ElementTiming into LCP and parts into PaintTiming
- No other incubations being adopted
Sustainability and WebPerf
Summary:
- There’s a bunch of overlap between web performance and sustainability
- We don’t currently expose information on server-side energy consumption, but maybe we should
- Discussion on how that information can be exposed, what more can we do
- Might be worthwhile to add to the charter
Forward referenced data URIs
Summary:
- For a certain class of web pages that render dynamic and highly variable content (e.g. search engine result pages), embedding images using Data URIs is the most efficient way to deliver those images over the network because the benefits of browser caching are minimal
- Data URI payloads need to be declared where they are used
- Dynamically generating base64 encodings for these images on-the-fly is expensive and causes a server-side bottleneck if done serially. Instead a common approach is to append these to the end of HTML sections and hoist them into the appropriate img tags using JS. This JS should also be inline since it needs to run quickly.
- What if there was a way to provide a forward pointer to a Data URI payload that appears later in the page? That would enable generating them in a non-blocking fashion on the server and eliminate the need for inline JS to implement this. Also it would cut down on redundant Data URI payloads such as 1x1 placeholders which currently need to be declared repetitively.
- SVG does potentially support this already so a solution may be to wrap the embedded images inside an SVG
Performance Beyond the Browser
Summary:
- Web Performance WG work might be applicable to a slightly more broad set of environments than just the browser such as edge compute (think node.js, deno, Cloudflare workers etc).
- Spec tweaks, possibly motivated by new requirements or other constraints, might help adopt existing designs to the environs where they find perf measurement valuable.
- The WinterCG, is helping codify the considerations in W3C, so we cross pollinated in the session.
- The session was closed with brief discussion on a variety of analysis concerns sitting just outside the envelope of browser perf monitoring - hars, netlogs, NEL.
Task Attribution
Summary:
- TaskAttribution has a bunch of potential use cases - SPA heuristics, LT attribution, privacy protections
- For privacy protections, we’d need to think defensively, and protect against code polluters
- Discussion around traces and if the WG should also cover cross-implementation lab tooling related efforts
Minutes
Monday 9/12
Intros, CEPC, agenda review, meeting goals, introspection - Yoav, Nic
Summary:
- Review of 2022 highlights, including processing model changes and features added to ResourceTiming, adopting LCP and EventTiming, and moving some specs to HTML
- The Working Group continues to discuss WICG incubations, and some of these have been adopted in the past (future session discusses rechartering and these incubations more)
- Review of Code of Conduct, Health rules and Agenda for the week
Minutes:
- Nic says hi
- Mission Statement: “Provide methods to observe and improve aspects of application performance of agent features…”
- Highlights from 2022
- 249 Closed Issues, yay!
- Rechartering talk on Friday
- Incubations:


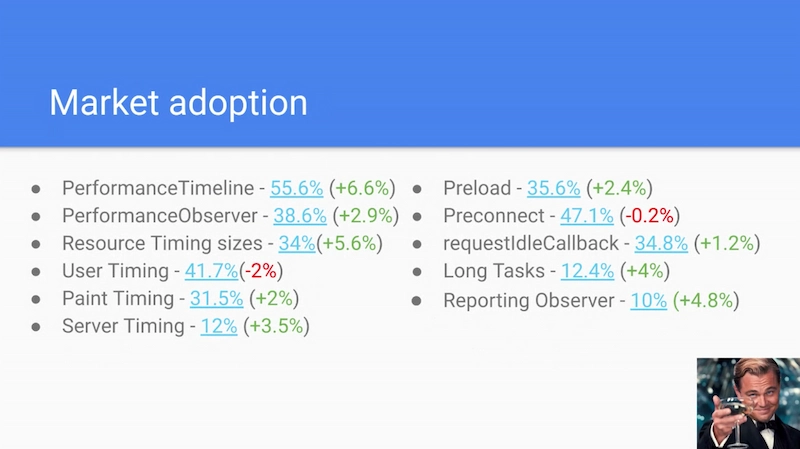
- Market Adoption!
- <Insert Humour here>
- Quick TPAC Schedule review
- 2 additional slots in the late afternoon for APAC folks
- CEPC overview
- Presentations will be recorded; please do not interrupt to prompt for questions until the presentation is complete so that we can record. (same as WG meetings)
- Health rules
Prefetch processing model - Noam/Yoav
Minutes:
- <Congratulations Noam & family!>
- Yoav: Trying to "unbreak" the model
- ... What is prefetch used for?
- ... Used to prefetch HTML for docs the user may soon navigate to
- ... At the same time, for low-priority resources that are likely to be used on the current page but don't want them to get in the way (CSS that is relevant for lower parts of the page)
- ... There are a lot of differences in how vendors implement
- ... and when trying to test the current behavior
- Chromium - Prefetch works well for same-site navigation as well as subresources
- ... For cross-site documents there is an undocumented codepath (hack) where as="document" puts the resource in the resource's partition rather than the site that's initiating it
- ... One way to solve cross-origin navigation
- ... Resource survives in cache for 5 minutes without the need to re-validate unless the caching headers are restrictive/no-store
- … special headers for signed exchange support
- Gecko - special prioritization for prefetches after load event
- ... No specific cache semantics
- ... X-Moz Prefetch header
- ... (Chrome has a Purpose header)
- WebKit - it's behind a flag (off-by-default)
- ... Simple low-priority fetch
- Issues: 5-minute rule is getting in way of caching semantics and can cause correctness problem
- ... Major differences between same-site and cross-site behaviors
- ... Different accept headers can break caching / Vary: Accept
- Noam has a spec PR html PR#8111
- ... No special timed (i.e. ~5min) cache semantics
- ... No as=document
- ... Send “Sec-Purpose: Prefetch”
- ... Ignore “Vary: Accept” when consuming prefetch
- <Discussion!>
- Anne (Apple): Wondering about Sec-Fetch-* headers, are they included in Prefetch?
- Yoav: They would have to be, we need to figure out what the value would be
- Domenic: The value would follow normal rules, would we need to vary Sec-Fetch-Dest
- Anne: Some implementations that might go to the HTTP cache
- Yoav: You'd need the HTTP cache to address that
- ... Some HTTP caches are shared system wide
- Domenic: To clarify Noam's motivation is that there's a lot of content in the wild that doesn't have `as` attributes.
- Yoav: We’d need to define `as` attribute since it's not really defined today
- ... And have everyone adapt their prefetches
- Domenic: Destination is just prefetch right now
- Yoav: yeah but it's not the consumers destination
- Dan: Noticed there's no explicit reference in presentation to data-saver mode
- ... As far as I know prefetch does nothing in data-saver, we should be explicit about that in the spec
- Yoav: There was some spec language that prefetches are optional resource
- Dan: Seems to me we need to be explicit about data saver
- Domenic: Data-saver is not a spec concept, but a browser feature
- Anne: Should say UAs are allowed to do this if UA has preferences
- Yoav: Yes instead of specifying a specific mode that doesn't translate across browsers
- Dan: Mentioned use of prefetch for downloading low-priority content with assets on the same page
- ... These days we also have the option of preloading with low priority
- ... Any benefit for prefetch in those cases?
- Yoav: Also use-case of same-site subresources for the next page
- ... Load CSS or JavaScript for a likely next page the user will go to
- ... If you were to preload that, there are advantages if you have special cache semantics
- … but some of the use-cases could be addressed with low-priority preload
- Barry: Preload is mandatory
- Dan: Next page assets, prefetch is appropriate and preload is not
- ... Low-priority resources w/in same page, and that's what I'm asking about
- ... Is there any opinion on our part when talking about low-pri resources for the same page
- ... Qwik framework uses prefetch for this
- ... Should they be using low-priority preload instead?
- Patrick: Low-pri preload is generally a lot higher priority than prefetch (in Chrome)
- ... So need to define another idle level of priority
- ... Firefox loads 1-at-a-time after onload
- Dan: You're saying there's low and even lower
- Patrick: CSS in Chrome's scheme, with no priority it's the highest resource, but even low-pri CSS it's still a high-priority in Chrome, it's not idle priority
- Yoav: If we settle on needing to define 'as' attribute for all resources, maybe it's easier to add this extra priority, it's an idle resource
- Patrick: Biggest difference around optional, instead of a must
- Dan: In some engines, JavaScript gets parsed
- ... Based on Qwik’s usage pattern they should use preload instead of prefetch
- Michal: They switched to prefetch because parsing was the problem
- Barry: Also compat issue where everyone else could see it as a high-priority preload
- Dan: One more point, no special timing in part of the proposal, what does that mean in the context of cache revalidation
- Yoav: One thing would've been a "single use", cache can use it once
- Domenic: Proposal is it populates the HTTP cache and that's it
- Yoav: If you're prefetching no-cacheable resources this would do nothing
- ... Compat analysis Noam did, this isn't a thing that happens
- ... Avoid special cache handling semantics
- ... Tell developers to only prefetch cacheable things
- Dan: If there is a need for re-validation, we lose most of the benefit of prefetch…
- Yoav: Is there a reason why the content can't be cacheable?
- Dan: A lot of websites who currently have revalidation requirements for the HTML
- ... Not necessarily thinking about short-duration caching
- ... They basically just require revalidation, and when it's required, prefetching will have effectively no value
- Yoav: If HTML is non-cacheable or requires revalidation, speculation rules?
- Domenic: We don't have anything until Noam's proposal that is just populating the http cache
- Anne: Would this only work for same-origin things, or same HTTP partition?
- Domenic: It would just go in your current partition
- ... It could be useful if you embed a cross-site image on your page
- Yoav: But not for cross-site documents
- Anne: link rel=prefetch would no longer be useful for SERP results
- Jeremy: If you want to do a cross-origin fetch there's a lot of complexity
- Dan: If I understand correctly, if I want to avoid revalidation be explicit about it and set cache headers to avoid revalidation
- Yoav: Proposal, I'm not sure I fully agree with that conclusion
- ... You make a good point this is a significant downside for same-site document prefetches
- ... If we are keeping special semantics for speculation rules we can also keep them for prefetch
- Domenic: There's memory caches and HTTP cache, if you want memory cache use preload
- Jeremy: Situation most commonly seen on HTML resources, not subresources
- ... It's more likely the author will be able to update to change the Caching headers
- Dan: I really wish more browsers would implement stale-while-revalidate
- ... Any thoughts about bulk prefetches for resources for a page
- Yoav: No-state prefetch kind of thing?
- Jeremy: We have it implemented in Chrome, have done some experimentation
- ... Need to be fairly confident the navigation will occur because it takes so much more bandwidth
- ... Prerender is the other side of that, not clear if the intermediate point is valuable vs. just prefetching the resource
- Yoav: Next steps is discussion on the issue
- https://github.com/whatwg/html/pull/8111
- https://github.com/whatwg/html/issues/5229
No-Vary-Query - Domenic
Minutes:
- Domenic: Will scroll through the explainer:
- https://github.com/WICG/nav-speculation/blob/no-vary-query/no-vary-query.md
- … Probably will be renamed to No-Vary-Search
- … about making this faster due to cache misses due to query params (?foo=bar)
- … originally for prerender/prefetch, but may be widely application
- … HTTP cache, SW, shared worker, …caches
- Want more cache hits, fewer misses, may be nice!
- … You can use the header to:
- Ignore the order of the query params (wow)
- Ignore specific query params
- Please ignore everything, except specific parameters
- Should be clear why this is useful, but here are some use cases
- … Inconsistent referrer… maybe append random things to URL, swap order, etc
- … Customizing Server behavior… e.g. modify priority or load balancing or debugging customizations– but don’t affect the response. This metadata is not really part of the resource. Would be better to store this in headers, but you cannot always do that (and some web platform features don't allow it, e.g. iframes)
- … There are also queries that are used for client side processing… State tracking etc, Analytics data, login processes. In theory they could use fragments, but sites use queries e.g. because they’re used to them, or because they sometimes want to pass the same info to the server.
- … With preloading, prefetching and prerendering, sites may be interested in having that data client side. So, prerendering changes the calculus here
- … Specific to prerendering - the URL may contain data not yet determined during fetch
- … imagine an article with hero image and headline, and you want to store state of which was clicked (via=headline)
- … you want to prerender once, for either case, but you DO want to send the query params after activations
- something like “No-Vary-Query: via”
- Detailed Design
- ... Structured header
- … HTTP Caches, request vs response
- …preloading caches, today keyed by request URL
- …ServiceWorkert cache api, already has handling for Vary header
- …Other URL-keyed caches (list of available images, module maps, shared workers, like rel=preload)
- Not quite sure if we want to change the behavior of all of these
- … Not going to change the response
- …when you request a resource with a new URL with new query params that are ignored, the response will store the URL you requested. Not going to be modified
- …it's more complicated for prerendering… the current process is to activate with the initial URL, then on activation you have to history.repalceState with the new URL
- …Interaction with storage partitioning… doesn’t affect
- ... Redirects are complicated - the request URL vs. response URL, what if some redirects have the header and some don't (redirects can come from cache)
- ... Worked out some examples, user might see something they didn't quite expect
- ... If there is a redirect you want to put it on the original request URL, since that's what these are key'd on
- Anne: What if a redirect goes cross-origin, it'd be the final URL you'd use
- Domenic: SW cache, prerender cache, keyed on the request URL
- Anne: Aren't they keyed on the final URL?
- Domenic: I think they're keyed on the initial one
- Anne: Might be abused?
- Yoav: Keep for discussion at the end
- … More complex No-Vary rules
- … We could expand this in the future for regexes, case insensitivity
- … Option for the future: similar “No-Vary-Path”
- …Security perspective seems fine, and could be very useful for client-side applications
- …ServiceWorkers had to limit the flexibility for replacing paths, some sec issues there
- … And parsing paths is quite a bit harder and cannot re-use the same header rules as for No-Vary-Search
- …Referrer Hint
- …Optional: can we provide a <meta> version
- … could be difficult, but would help developers
- … <grumbling, please no>
- … security and privacy is probably fine :P
- … Origin is the boundary. Modifying query params is widely possible and done already, (history.replaceState etc)
- … For privacy, it sounds similar to link tracking at face value but it is very different. It's basically the opposite: treat two requests as the same, vs treat a single resource as different
- Anne: Did you discuss syntax
- Domenic: It's a structured header, use URL Search Params
- Dominic Cooney: Curious thought how this would be implemented.
- …How would it work if a bunch of requests are made which claim to not vary on search, but then the last response claims that it DOES vary, what happens?
- Jeremy: Create a canonical cache key? Is it different from Vary?
- ... Can't comment on any particular HTTP cache
- Domenic: This is at the explainer stage and not yet implementation stage, feedback from implementers so far suggests this seems doable
- Jeremy: Some CDNs offer something like this
- Domenic: Would be cool if CDNs used this instead of a custom thing
- Edward: Work on content delivery at CloudFlare. CF documentation does not give an indication on how they treat query parameter ordering. Query-string sort. Although in some cases it requires the request to cooperate with that. Query parameter ordering does matter in our particular case.
- Barry: If order doesn't matter, and you've got a parameter repeated, then which is it?
- Domenic: We've been thinking mostly on the key level, so I don't have a clear answer right away. Does order mean key order or key+value order, sort keys and values
- Barry: Related to Vary header which is not a structured header, could people use the quote and get it wrong since they're interlinked and have a different syntax
- Domenic: Good point, something to be sure about when implementing diagnostics
- Alex: If I have something in my cache which is a=b and I make a request for a=c, what would the response URL be?
- Domenic: The one that was requested currently
- Alex: Concerned about regular expressions
- Anne: Can we use URLPattern-safe subsets?
- Michal: The request URL would be replaced, so the order in Barry's question shouldn't matter, because it would be interpreted by the thing that interprets the response. If you don't ignore it, it doesn't affect i
- Yoav: When you have a request going out, you need to match it
- Domenic: If you say No-Vary-Query: X, then it doesn't matter that X is
- Jeremy: If you said No-Vary-Query: X, then it doesn't matter at all, but if you say No-Vary-Order: order, then it does
- Anne: You would ignore both right?
- Domenic: In this case you're not ignoring any parameters, just the order
- Barry: If i said country=CA and country=UA
- Jeremy: Conceptually it's an ordered multimap, some servers will do same things or different things depending on the order
- ... 95% of servers don't have repeated query parameters, so most use-cases won't matter
- Domenic: Maybe there should be a special case for multiple values, or I do care
- Dan: If you wanted to ignore a parameter called "order" would you include it in quotes?
- Domenic: Yes
- Kouhei: We should support a PHP get query param that uses the same key multiple times
- ... Common way to pass parameters [stackoverflow]
- Yoav: Requires web-platform processing model as part of fetch
- .. Assuming we'd want this outside the browser to various caches and CDNs etc
- Domenic: First focus is preloading caches but we think it'd be useful generally
- Do we coordinate with the HTTP specs? Or do this work in the WG first
- ... at least affects the caching spec
- Domenic: How would they feel about a webperf spec patching RFC?
- Anne: Is mnot around?
- Yoav: Would be valuable to get feedback from that community, at the same time I don't think this should block the web processing model. We can define the header.
- Domenic: We already modify the HTTP semantics a lot in Fetch
- Yoav: But not for other caches
- Anne: To reach maximum potential we want it not just in browsers but all intermediaries
- Yoav: Good to get feedback
- Lucas: +1 to what Yoav is saying, we don't need to define every header in HTTP land
- ... But the interplay here with server-side and CDN it needs wider review
- ... RFC linked isn't even the most current one right now
- ... Even if you want to do your own thing, having awareness of what else is happening is good
- Ian: None of the semantics of the query string are in HTTP? Is it all just convention?
- ... Lots of query parameters in the wild that might not be compliant
- ... For fragments?
- Domenic: We see some cases where servers process it. They would need to move ot client-side processing if they use this header
- Jeremy: In practice a lot the UTM headers are processed by client-side SDKs, a server could process but they don't
- Alex: I realize the point is to provide this type of thing, they use a random query parameter, and they can't get their content to go to the server.
- Jeremy: They could always use "except='my-cache-busting-paramter'"
- Alex: If you have the content already on a bunch of people's devices, how do you bust it?
- Anne: Should we do a "*" in the first version?
- Barry: With a warning?
- Yoav: Or a no-cache query parameter in the spec, a special that is always in the "except" list?
- Kouhei: On reload?
- Yoav: Cache-Control: no-cache on the request?
- Dominic C: Lot of history with AppCache, worth studying
- Tom: JavaScript that does replace-state, are you considering a client hint?
- Domenic: JavaScript works except in prerendering case, on prerendering change event we do replacestate, saying everything is changing
- Tom: Do you still have to send down the JavaScript that does the replacestate
- Domenic: No
- Tom: Do you know on the server if this has any impact?
- Tom: On the server you need to know if you're doing this or not, how do you know?
- Yoav: If this isn't supported you wouldn't do preloading at all
- Domenic: I would want to make sure to work through this example
Element Timing and Shadow DOM - Amiya
Minutes:
- Amiya: WebPerf eng at Microsoft, first TPAC
- … Revisit an old issue and share observations
- … Before ElementTiming, webdevs had no direct way to see when elements are painted
- … As a workaround, there were approximation
- … Observe an image used the RT API or a load handler, but those are not accurate
- … For a text element, might use an inline script tag. Have an inline script with a perf marker
- … requestAnimationFrame and other variants were also used to tell the browser to record a marker at the next frame
- … This is not totally accurate and potentially over report the number
- … Including the script tag may change the rendering behavior of the browser and introduce new paints
- … Element Timing fixed all this and got a way to get that info
- … Built a couple of pages to demo this:
- Shadow DOM: https://amiyagupta.github.io/demopages/tpac-2022/shadow.html
- No Shadow DOM: https://amiyagupta.github.io/demopages/tpac-2022/noshadow.html
- Source code: https://github.com/amiyagupta/demopages/tree/main/tpac-2022
- … Same page also implemented with Shadow DOM where the image is implemented as a shadow dom element
- … Element timing attribute on the outer div and inside the shadow element
- … In the regular page, all the ET entries are fired
- … With the shadow dom page, no element timing is fired for the image
- … You can’t observe external or internal elements to the shadow DOM
- … Wanted to bring the discussion up again, and move this forward
- … The behavior is by design because shadow DOM is isolated, but we can have elements that opt-in to being observed. Elements should be able to opt in
- … Implications of this: shadow DOM can’t use element timing
- … For msn.com: moved from React to we components, and lost element timing data (and are using hacks instead)
- … LCP still captures the shadow DOM element, but Element Timing doesn’t.
- … Seems like a mismatch between those two approaches, where the declarative approach doesn’t capture the full picture
- Dan: Never tested it, but LCP when recorded by CrUX looks at iframes, but not in the webperf API
- … with shadow DOM, what’s the element reported by LCP?
- Amiya: good question, we could try it and see
- Dan: The discrepancy with LCP seems weird.
- … Other point - Can you implement a performance observer within the context of the custom element?
- Amiya: Haven’t tried it, not sure that works
- Dan: Consider web components to be iframes light, so..
- Yoav: From my perspective, web components are not a security boundary, they're a way for developers to isolate code to make authoring easier, not to hide information from the page.
- ... You cannot run JavaScript in a different "world" in the component, still have the same window/PerformanceTimeline etc.
- ... No current way to get that info from inside that shadow DOM, at the same time I'm not sure what was the original reasoning to segregate to not report Element Timing to shadow DOM
- ... At very least the opt-in option seems reasonable
- ... If you're importing a component from an unknown author, you should still be able to opt-in
- Nolan: I haven't heard relevant issues, but two precedents. One is declarative shadow DOMs, includeShadowRoots=true, it will just pierce and serialize those recursively.
- ... The other is cross-root delegation spec, can't access ARIA attributes across boundary
- ... Either the onus is on the web component author to export, or on PerformanceObserver owner to say they want to pierce everything
- Yoav: Worthwhile to look at original reasoning
- Shuo: LCP and ElementTIming difference, in current spec LCP shouldn't include things in Shadow DOM.
- ... LCP depends on ElementTiming
- Yoav: At the same time I think we want LCP to include those
- Shuo: Not sure?
- Michal: If the whole page is a giant component in Shadow DOM and that's the only visible portion
- Dominic C: I worked on Chrome when we worked on Shadow Elements etc.
- ... Things should be consistent
- ... General philosophy is it's an encapsulation mechanism
- ... From that POV there's two good choices, outer element can have ElementTiming, constituent timings are opaque to the page. That's the low-fi version.
- ... High-fi version is the element can control interior and exterior timings
- ... Very sympathetic to this issue
- Yoav: To understand, in case there's no opt-in, we're just reporting the timing of the custom element, regardless of what's inside it
- ... If the element author defines a more granular mapping, we can define more granular things
- ... Best path forward is to schedule this for a longer session on one of the upcoming calls and make sure relevant people will be on that call
.webp)
Exposing more paint time points - Michal
Minutes:
- Michal: Talking about PaintTiming and potentially exposing more
- ... Several specs that expose some concepts of paint timing
- … Several reasonable interpretations
- … Multiple time points are interesting and important to developers
- … No specific proposal, wants to drive towards clarity and consistency
- … Paint timing marks the point in time the browser renders a given document
- … LCP builds on that and element timing, exposes load time and a render time
- … Element Timing, same as LCP
- … Event Timing, start time of the event and the duration, which are effectively the render time
- … interop issues aside - how do you do paint timing and image decode
.webp)
- Create an image and the decode async, sync or just wait on the image to load, decode and attach it at that point
- Async - image loaded, attached to the DOM and not wait for the image decode
- So user would see the render before the image is decoded
- Decoupled from when the image become available
.webp)
- … The common case - decode sync
- Load the image, wait for rendering to happen, which will kick off a decode
- …In all browsers decode is async, we don’t block on decoding
- …But there’s no rendering until that decode is complete
- …Two different rendering tasks that will happen when an image loads - two rendering opportunities
- …Might depend on conditions on the page which one is used
- …That means that the timing that’s marked for images that are sync decode is the time they are attached to the DOM
- …There are differences between browsers and it’s complicated
- …If you use film strips, you see the differences
- …Differences in Firefox are pretty small, side effect of default async decode. So the FCP is for non-image elements of the page. Safari is default sync decode.
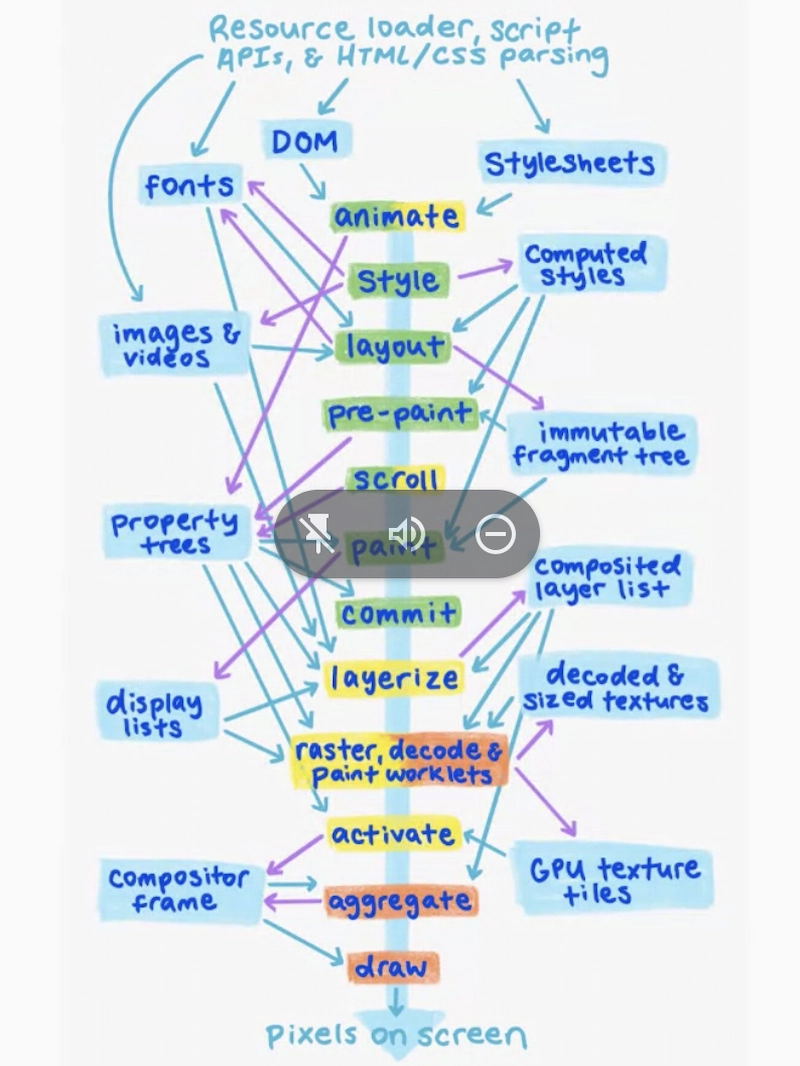
- …Why is this difficult? Linear process on how you do rendering
- … step 16 in “update the rendering” is pretty unspecified
- … In reality, this is Chromium’s rendering process
- … Firefox is similar
- … Summary from ChrisH on interpreting the rendering steps and how they are assumed to be serial but many happen in parallel. That’s possible because it’s not really observable, but the performance timeline violates that.
- … Discussion on whether this can be resolved differently. Original paint timing exposed something similar to Chromium, but changed due to spec issues
- … Focusing on Event Timing - The goal is to be under 100ms of interaction. Small differences in what’s measured make a big impact
- …Many things developers can do to shoot themselves in the foot
- …Even when you start a rendering task in the browser, it takes time before rendering actually happens: input delay, rendering work
- … Lots of things that can prevent a rendering opportunity from happening
- …So when we tell developers “render took a long time”, that’s a black box
- …Other issues with multiple timepoints: progressive images, FCP>LCP with non-TAO, render time decouples from load time (e.g. through JS)
- …Optimize LCP guide - element render delay shouldn’t take a long time, but it tends to be larger than expected
- …Summary
- Alex: From my perspective you're correct, complicated is a good way to describe it
- ... It's undergoing major changes right now in WebKit, things you observe may change
- Michal: I know you don't get accurate representation time for the system, but you at least know when that frame was submitted. Not well spec'd.may be hard to spec parallelism.
- Shou: For us we could know the time committing to the GPU, but we don’t want to expose that time due to privacy concerns
- Michal: For event timing, we're rounding off timings to 8ms. My understanding was that the amount of rendering work that happens vs. saying it took X frames to generate a result
- … Maybe we can solve the use case without exposing accurate timing
- Barry: Specifically for the FCP > LCP problem, should we fall back to FCP?
- Michal: That’s what we were suggesting. Chromium doesn’t expose the beginning of the rendering task. In this case, the earlier timestamp is more valuable
- Yoav: Are privacy concerns around visited links or other things?
- Shou: Building the complexity of the website, you log into a page reveals whether you were logged in or not. Paint timing can differ whether logged in or not.
- Yoav: You don't get paint timings outside of the context in which you see this information anyway, right?
.webp)
.webp)
.webp)
Super Early Hints - Barry
Minutes:
- Barry: Proposal for even earlier hints for connections
- Many use cases for cross-origin requests - image CDNs, etc
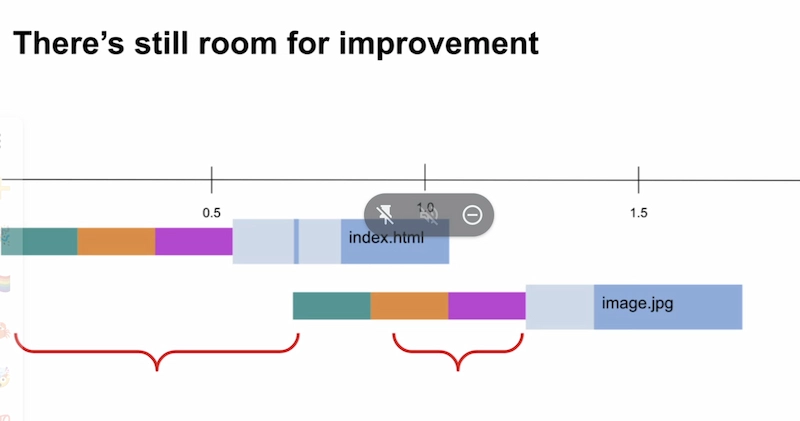
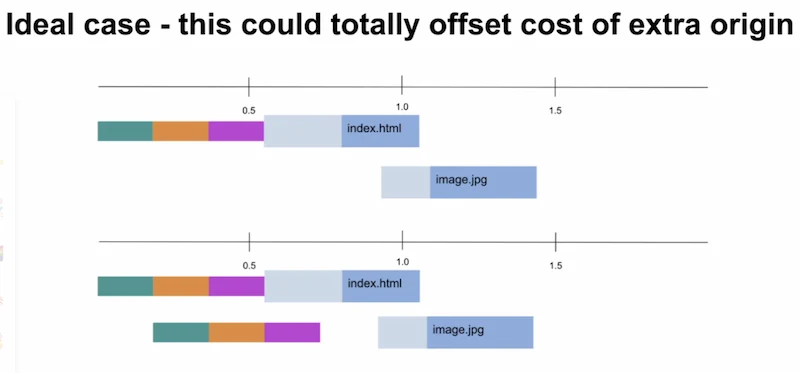
- Extra origins have a performance cost - require another connection
- Gap between when the image is discovered and when it downloads
- Preconnect can minimize that gap. 103 response can help even further
- But it’s still never as fast as using the same origin as the HTML
- Using less origins is a best practice
- Everything on the same domain may not be practical
- Proxy requests through a domain - has security consideration, and feels icky. There’s also the backend connection cost
- Is there another way?
- Linking the resource request to the connection with 103, but it’s more of a connection-level setting
- For most cases, these secondary domains are shared across most pages on the origin
- Can we treat this as a connection level request?
- Gaps
- Until the first load, we’re not doing much else
- Front loading that work to that first gap would be better
- Could we tell with DNS, TLS or HTTP settings that this secondary connection is needed?
- Question re performance of the different options, but also has deployability differences
- Recently standarding HTTPS/SV/CB which may be best amongst all three
- Some concerns: footgun for performance reasons (over connecting), security/privacy, is this DNS’ role
- 2 questions for y’all:
- Is this worth pursuing?
- Preference RE the layer?
- Dominic: For web.dev that sounds great, but for a broader domains they could vary greatly
- Pat: Shopify that used Early Hints always have a static domain. Also Amazon. So this would be useful
- … If this was a DNS record, maybe this is a web-only addition
- … Strong preference to DNS because it’s easier to add
- Alex: Is there limit to how much data DNS can send
- Pat: Need to be careful of DNS for reflection attacks and DDoS
- Barry: Should be easy for people to do, but shouldn’t change every time you change your page
- Alex: If you have 300 domains, would DNS be upset about that
- Barry: Browsers can only use the first 1-2 values to prevent that
- Yoav: And what Alex is saying is that DNS could choke on that many values
- Barry: Only for preconnects, not preloads
- Lucas: Thought about it a bit, but we should be talking about new records. HTTPS specialization records allow that and we should look into it, and concerns should feed into considerations for those RFCs
- … We have a record for this, let’s use it
- Eric: Super interested in this, and the problem is well known. Can unlock some things worth pursuing. Aware of couple instances of similar things: Critical-CH
- Yoav: Accept_CH frames
- Barry: DNS may be easier to deploy than HTTP or TLS settings
- Nic: Could see CDNs handling these things for their customers
- Barry: Cloudflare offers 103s
- Nic: One challenge at the DNS layer, you don’t know the URL. So different parts of the domain may have different needs
- Yoav: URL knowledge (or lack of) are not DNS specific
- Ian: Do you expect it’d cascade?
- Barry: Yeah. Google Fonts as an example (CSS domain and font domain)
- Michal: Curious if browsers do any of this speculatively?
- Pat: Chrome has a network predictor, but it takes a while to learn, and that’s on a per-user, per-device basis
- … hit levels are only good for sites you visit a lot
- … would learn only for very frequent domains
- Barry: so smaller websites don’t benefit
- Amiya: Similar to what Pat said, IE used to do that. At least do a DNS lookup.
- Ian: Most people don’t run their own DNS servers, and the registrar does that for them. Some people run their own servers but not their DNS
- Pat: we could technically do both
- Barry: best to speak to HTTP/SV folks to see what their point of view
- Yoav: Might be worthwhile to query developers
- Barry: CDNs can provide a one click stop
Webperf Debugging Workshop (in-person)
CDN Resource-Timing info - Mark
Minutes:
- Proto-explainer
- Talking about a proposal - for a long time we didn’t have good ways to measure performance, and ResourceTiming came along and RUM gave visibility
- In the world of CDNs we’re stuck measuring perf using the older techniques - ping resources from data centers around the world
- What if we could collect better data about how CDNs are performing, so that users can make better decisions
- CDNs make lots of claims about their performance, or 3Ps do that, but it’s very synthetic
- In the HTTPWG we defined 2 new HTTP headers:
- Cache-Status - hit, miss, freshness lifetime
- Proxy-Status - this is why this proxy generated an error, etc
- Both those specs are based on structured headers, maps easy into JS/JSON
- The proposal is to expose the contents of those headers as JS as part of ResourceTiming (considering TAO, etc)
- Enables using hit/miss as dimensions
- Gives you a much better idea about how your CDN is performing (or your reverse proxy)
- I think folks are interested - question of getting browsers interested in implementing
- Because it’s structured headers, may not be too hard to implement
- Nic: Love this idea. Would be beneficial for people that want to capture the info
- .. With server timing you could choose to communicate the same info
- … Some CDNs are using the ServerTiming header to do that
- … Seems like Cache status gives more structure
- … Any benefits beyond the structure over server timing?
- Mark: Not just structure but also semantics. Enable to compare apples to apples when comparing CDNs, especially for multi CDN
- … Also pretty common hierarchical caching. As a customer, I want to understand where my hits are coming from. Edge caches or central ones
- … Server timing was about the origin server, where this is more cache specific
- Nic: Cache-Status gives you which cache it is
- Amiya: Can a CDN game its metrics? It’s self-reporting
- .. If used for comparative analysis, may incentivize inaccurate reporting
- Mark: The kind of response on hit or miss, no good answers.
- … reporting high latency hits as a miss would still reduce their hit rate
- … timing is still collected on the browser, so they could lie, but the benefit is not high
- Amiya: What about suppressing the headers for slow responses? Could be ways to misuse it
- Mark: Yeah, but if this ecosystem evolves, there can be demand for these headers from customers
- Michal: There’s a precedent of user timing having arbitrary json payloads. Here we would have RT exposing arbitrary JSON payloads. Are there other things we’d want to expose from headers?
- Mark: The Cache-Status seems super important. The Proxy-Status just seems easy if we;re doing the first. It’s more about error handling
- … For other headers, good question.
- Yoav: Same concerns as ServerTiming https://github.com/w3c/server-timing/issues/89
- .. Also, CDNs would not want to get caught lying
- Mark: Limiting this to just same origin, it would still be useful
- Paul: Would also be interesting to add to that is a CDN identifier
- … For multi-CDN customers looking at their RUM data, they can split other than using Server Timing
- … Currently using a Forward header to communicate the info to the client
- Mark: the specs have an identifier for each ‘hop’; it’s just a string, so the assumption is that CDNs will identify themselves there, along with the relevant part of their infrastructure. E.g., “cloudflare-edge-MEL’.
- … Lots of weird CDN architectures, so can’t make assumptions about them
- Nic: With Cache-Status, it doesn’t really emit timing information. Is that intentional?
- Mark: I assumed we used ResourceTiming to measure client visible timings. We could extend it
- Nic: Our RUM customers today can expose origin time vs. edge time to give them insights on that breakdown
- Mark: Would hope we’d get good input from CDNs so that customers could make meaningful comparisons between them.
- Yoav: Next steps?
- Mark: develop the explainer and write a proto spec that people can comment on.
- Yoav: implementation interest?
- Mark: Intend to get CDNs to apply pressure on browsers of the same companies
- Michal: To what extent are CDNs replaceable and equivalent? There are some CDNs that are coupled to a certain tech stack.
- … Could you assess them without issues with correlation?
- Mark: Depends on what CDN you're talking about. I’m talking about classic CDNs - Akamai, Fastly, Cloudflare. You’re talking about platform CDNs. Can be complex to tease out their performance story
- … Edge compute - lots of different solutions there, which this won’t address
- … but we need common metrics to make good comparisons
- … For edge compute we’re not there yet
Unload beacon - Fergal + Ming
Minutes:
- Ming: Page Unload Beacon API
- ... Focused on current API and some pending issues and discussions
- ... Motivation: Provides a more reliable way to beacon data, sends data to a server without expecting a response
- ... Analytics data, requirement to send data at the "end" of a user session, but not a good time in page's lifecycle to make a call
- ... Want to expand sendBeacon API
- ... PendingBeacon would represent a piece of data that would be sent later to a target URL
- ... Sent on page discard, plus a customizable timeout
- ... Support both GET and POST methods
- ... Ideally, we would like browser to support crash recovery from disk, but some privacy concerns
- ... Basic shape: Construct a PendingGetBeacon or PendingPostBeacon, will queue and the browser will later send out when page is being discarded
- ... Has properties like url, method and pending state
- ... Check property before updating PendingBeacon
- ... Mutable properties such as backgroundTimeout and timeout
- ... API is simple, can also send the beacon out now, or deactivate
- ... For Get you can update its URL, for Post you can update its data
- ... Constructor takes an argument to specify backgroundTimeout or timeout
- ... backgroundTimeout will send the beacon approx that time after being hidden
- ... timeout is like a setTimeout() to send the beacon, but is more reliable
- ... Updating the property will reset that timer
- ... Concrete example:
- Thomas: Why would you pick a backgroundTimeout number
- Ming: How long do you want to wait for beacon to be sent
- ... If tab is minimized it would be in a hidden state
- ... But maybe page will come back after hidden, and you don't want the beacon to be sent
- ... If page goes back to visible, it will be stopped
- Fergal: Tradeoff between wanting to minimize beacons sent and wanting to get as much information as much as possible
- Jeremy: Why is setURL only available on GetBeacon?
- Fergal: It would be immutable for a POST beacon and mutable for a GET beacon
- ... In terms of type safety, you can only attempt to set the URL on a GET beacon
- Jeremy: But why can you not change on the POST beacon but can on GET beacon?
- Ming: Open issue to discuss
- Jeremy: Seems like an artificial constraint
- Alex: Confused by API shape, it seems like if you make two new PendingGetBeacons
- Ming: They are different objects, with same target URL, it will make the request twice
- Alex: You can have a whole bunch of PendingGetBeacons to different URLs
- Ming: Or even to the same URL
- Alex: And if you create one and it never gets referenced again, and it gets GCd, it will still send
- Ming: Yes, it shouldn't get GC'd until it gets sent off
- Domenic C: Given you need to support cancelation anyway, if network activity is happening in a different process, couldn't it be racey
- ... Why do you need to be able to modify it, why can't you just cancel and create a new one
- Fergal: Renderer is full control unless renderer dies, so multi-process concerns are not there
- ... There's a thread, the ergonomics get really tricky when you do that
- ... Example is you have a beacon and accumulate data, and eventually send it, you want to know if the last one was sent or not. Can't tell if it's async until after the fact.
- Domenic C: Understood
- Ming: It's better to make constructor support actual post-data etc
- ... But some cases you want to construct beacon and update its data later
- Domenic C: No code sample for PendingPostBeacon, in this example for PendingGetBeacon, there are other event loops in between right?
- Ming: Yes
- Sean: Existing issue for current Beacon API, the tab could be killed at any time and the unload event fires
- ... It would still persist with this API right?
- ... Otherwise you can rely on page hidden / visibility change?
- ... Can current Beacon API support the same with pagevis event
- Ming: Can achieve the same with page vis changes, but No good way to support if the page was discarded
- Fergal: Plus the ability to send a beacon with backgroundTimeout
- Sean: Developers would typically want to send the beacon right away
- Ming: In Chrome’s case, the renderer can crash, but you want to still send out a beacon
- Olli: Wouldn’t developers abuse this API in the background tabs? Browsers throttle background, so developers could create thousands of new beacons and send them?
- Fergal: To what end? You could do the same in the foreground
- Olli: To overcome the limits
- Michal: You’re saying you wouldn’t be scheduled, so then you can’t update the beacon
- Olli: You’d need to update the beacon ahead of time
- Jeremy: UAs can apply reasonable resource limits here to avoid gigabytes of updates
- Fergal: If you have the event loop running, you can do this with fetch. Otherwise, there isn’t a point
- Olli: In order to update the pending state, you need to run the event loop
- Fergal: A DoS attack here, but no new information
- Jeremy: Don’t want the background tabs to ping the server, but we can apply reasonable limits
- Barry: As a RUM provider, I can see the use case
- Jeremy: There are reasons for us to want to limit that - avoid users pinging the server constantly
- Dominic: Any reason the beacon isn’t integrated as a Fetch option?
- Ming: only allow you to attach the data but not to configure the request itself
- Sean: If I set the timeout to 1 minute and I close the tab, would the beacon be sent?
- Ming: When the tab is close, the beacon is sent immediately
- … The renderer gets discarded so the browser would send it
- Alex: What if you close the browser?
- Ming: Not sure. Initially wanted to support browser crash recovery from disk. But due to privacy concerns around network change, we may not do that.
- … If the beacon is still queued when the user reconnects to a different network, that’s not what the user expects.
- … Can leak navigation history. So don’t want to implement crash recovery at the moment
- Fergal: Maybe we can keep the beacons but only send them when you go back to the site that registered them.
- Ming: Beacon may be old
- Fergal: reduces utility, but may be worth doing
- Michal: Would beacons built ahead of time be an actual performance win?
- Fergal: That’s the original motivation for this. Key feature to allow people to remove unload handlers
- … About to start an origin trial for this, if people want to use it
- Nic, Thomas: interested!
- Michal: Is it also more ergonomic to use?
- Nic: The API fits well with what we’re doing today. Interested in getting better reliability. Won’t stream more data.
- Barry: Reliability + atm RUM providers don’t measure full-lifecycle metrics (CLS)
- Thomas: concerned about log loss. In native we can log everything and this gets us a little bit closer. Batching and crashes are still missing.
- Barry: How often do browser crashes happen?
- Thomas: hard to say
- Jeremy: <missed question>
- Thomas: Android would preserve the logs offline. Can do that with session storage, but they get old.
- Ian: Makes sense to hold on to them until the user goes back to the page.
- Jeremy: <missed comment>
- Thomas: no one wants their logs dropped
- Nic: For RUM we may not want data that’s too old
- Barry: For crash reports, you want to store them
- Jeremy: You need to make sure you respect Clear-Site-Data, etc
- Thomas: In any case, we regard events based on the timestamp in which they were logged, not when they were received on the server side
- Fergal: Limit of 48 hours
- Ming: Still pending discussion
- Fergal: Maybe it should be implementation defined
- Alex: Not thrilled about persisting this to disc at all. Like the idea of sending a beacon decoupled from the same time when the next page is loaded, to avoid congestion.
- … But would also want an aggressive cap on the amount of time we’re willing to wait. E.g. 1 minute
- Ming: There’s a discussion about how long we should wait.
- Alex: If the user closes the browser or the browser crashes, the data is lost. Too bad
- Fergal: We don’t want to give more capability than developers have. Keeping the data in local storage is possible, but this seems like a better API for everyone
- Barry: arguing about 0.0000% case
- Michal: If you navigate away and unload, we’d eagerly send. If the tab is discarded, we’d send it within a minute. So I guess there’s no contention
- Alex: What's the timeout?
- Barry: It’s for a backgrounded page. It’s still there.
- Fergal: yeah, the timeout is for the page when it’s not discarded.
- Alex: In that case, I’d want to send it 10 seconds later.
- Ming: Open an issue in the repo
- Jeremy: If you read the timeout property, do you get the time that’s left?
- Fergal: Currently you’d get the last value you set.
- Ian: timeout = timeout is that a reset? Maybe it’s a write only.
- Michal: Somebody said they used Fetch to send the beacon eagerly. Why would beacon be lossy? Is there something about Fetch that’s keeping the page alive?
- Ming: You’re describing a different issue. Probably a bug.
.webp)
.webp)
.webp)
.webp)
Tuesday, 9/13
Resource Timing and iframes - Noam/Ian
Minutes:
- Ian: Iframes break ResourceTiming, and they don't play well together
- ... Current way this works is you can use RT inside a document, and you can look into an IFRAME you embed
- ... The IFRAME itself is going to see a NavTiming entry expressing details of its own navigation
- ... The containing document will get a RT entry that contains info about the doc that gets loaded
- ... IFRAMEs can sen TAO to optionally expose additional information
- ... Get a RT entry for the first navigation following through any redirects
- ... Any time you change the src attribute from containing document you should get a RT entry
- ... Gets added at the end of the BODY stream
- ... Unlike the load event
- ... But navigation of IFRAMEs have issues
- ... Can be canceled before it's reported -- client-side redirects, user navigates away, scripts
- ... Multiple navigations can happen from the same
- ... Session restore can cause issues
- ... Metrics might be misleading
- ... Cross-origin user behavior is exposed, e.g. navigate away
- ... Would TAO be good enough to opt-in for that?
- ... What should we do?
- ... Option 1 - Break up, don't put IFRAMEs in RT
- ... Could post-message to embedder, regular resources stay in RT
- ... Option 2 - Expose only the start/end time in an entry
- ... Safe, consistent between origins
- ... Lose some information, does not fit with what RT already does
- ... Option 3 - Do something different between same-origin/TAO frames (measure first navigation and report as completely as it can) and cross-origin/no-TAO just gets start and time of the load event
- ... Any other options?
- – Q & A –
- Yoav: Question we should be asking, is what does the current data we're exposing give us in case of use-cases
- ... Without any opt-ins what does it give?
- Nic: In the same origin case today, we can crawl all the same origin pages and get their resource timings – gather all of the timings for any subframe's resources, helps when treating frames like an image, helps understand the “page weight”, and of course just understand iframe timings
- … For the cross origin case, it can give us a hint that there was more content loaded that you don’t know about
- … When visualizing things, you’d see the existence of these frames even if not the data
- … Can deduce some things based on times
- … 30+% of resource urls and over 50% of bytes (5 years ago) are hidden
- … Having the entry be there in an incomplete state, it’s a helpful thing for reconstructing the waterfall later
- … Our RUM customers would be confused if their cross-origin iframes disappeared
- … Option 3 sounds ideal, as we’d still get the data
- … This is just a partial picture, but just the knowledge of the iframe’s existence is helpful
- Ian: For same origin frames, you could just look at their navigation timing info?
- Nic: exactly
- Ian: cross origin frames, you don’t get their transfer size
- Nic: get it if they have TAO
- Ian: If all you get is navigation timing, you’d still be able to do same origin
- Nic: Yeah, but not for cross-origin ones
- Ian: A separate proposal to have cross-origin frames to share that
- Nic: They’d have to opt in, where here we get that info without an opt in
- Michal: Can we get navigation timing propagation? Does navigation ID open up the option to expose navigation timing?
- Ian: You’re not gonna see this from the top-level frame
- … The frame has its last navigation where the embedder should only see the first one
- Yoav: Theoretically if we were to redesign from scratch… resource timing would just be for resources, and navigation timing we would have for frame timing..
- … The processing model is very different
- … But it's unclear if the churn that this would entail at this point is worth the churn
- ... but this is very valuable information which we don't want to lose
- … Maybe there is another Option 4:
- … I have ideas around Aggregated Reporting. Unclear still if that will work, but perhaps it can help
- … so far we have been concerned about the data sizes, but maybe we can look at timestamps of when things happened (this origin loaded this frame?)
- … Hard to bring that information back to construct a whole waterfall?
- … Won't necessarily solve all the use cases we have right now
- … Option 3 feels kind of awkwards… seems like too much special casing
- … But PoC deprioritizes implementer/spec complexity
- Nic: … Option 3 sounds like it requires a lot of special handling, is that for implementers?
- Ian: …No, for the developer/consumer, you will have to know that you have to handle differently depending on the resource type, because the timings measured will differ.
- Barry: For cross-origin images, you get the get the last byte, and not any of the other timings
- … Should be more consistent with that
- Ian: Cross-origin images and scripts, you can get information about their sizing from time, but you don’t get information about what the user did
- Pat: The razor is “can you get the same data from load events”. The Frame Timing proposal fits that model, which would give you the same information as attaching an onload/onerror event to the frame.
- … That’s how we got to where we are with cross-origin images and scripts
- Ian: You certainly get more than that right now
- … Option 3 is roughly equivalent to that
- Jeremy: How do you deal with redirects?
- Ian: TAO is sticky through the chain. Any non-TAO redirect fails the resource TAO
- Jeremy: checks Timing Allow fail is checked
- Yoav: We should really understand how this is used
- … Option 1 removes a TON of complexity
- … Option 2 involves a lot of code. At least in Chromium
- … Option 3 just fiddles some things around, easy for implementers, but the cost to developers may be significant
- Andy Davies: (in chat) Going for the option that leaves API consumers to handle edge cases doesn't make sense to me. Need to understand API consumer cost
- Nic: I’d have to think about it, but you can still get some of the same information about SO frames by crawling in and getting the data from frame perf timeline. Cannot do that for cross-origin frames, but we cannot do that today anyway
- Yoav: There is a separate proposal, for frames to expose up perf timings
- … Is it possible that we lean on that? Without frame bubbling up you just get Option 3, but it incentivized opt in to “frame bubbles” (cross frame performance timeline)
- Ian: Okay, interesting
- Colin: Is it only iframes that have this?
- … Do <video>, HLS, <model> tags have similar issues?
- … This are sort of like iframes embedded on the page
- Yoav: These are not iframes, these are resources
- … It's different because of cross-document navigation and being unable to expose
- Sean: What about <embed>?
- Yoav: right, and <object>. These are “types of iframes”
- … It would make sense for them to also fall into this model… but probably people don't care about these as much, since they are far less popular and far more legacy usage only. It would be good to handle these if it's possible.
- Alex: I think I like Option 3 of the three.
- Ian: <Re-iterates Option 3>
- Yoav: Let's start with Option 3 in the short term to eliminate any issues today, and then we have some time to evaluate other alternatives that reduce complexity.
APA joint meeting: Accessibility and the Reporting API
Minutes:
- Janina: Thank you for meeting with us. Could learn from you about ways to improve accessibility by gathering data on it.
- … Would be great to learn about load times - some pages are slow to load on bad networks
- … Not acceptable. Just an example that came up
- … Want to understand the reporting api better
- … As a leading question: can we make fast loading be a normative requirement?
- Intros: Janina Sajka, Matthew Atkinson, Scott Hollier, Lionel Wolberger
- Lionel: APA is reviewing specs towards the needs of accessibility. In 2018 we said “no need to review”, but then realized it can be useful
- … Use case for reporting TLS cert failures
- … Janina pointed out load times because that’s a recent concern. A failure of accessibility on the page is something that the user agent can be aware of
- … UA assembles resources and then fails due to TLS cert failure
- … UA builds an accessibility tree and the tree building can fail. Could be very interesting to report back on
- …another case - User access a form themselves, but some forms were inaccessible
- … a blind individual is trying to access the form and fails. Can they report that the form has failed them?
- … motor impaired person will use their keys to navigate, but would be interesting to enable them to report them
- … A web page is comprised of many resources - what if the report could go to the provider of the service (e.g. chat service)
- Matthew: automated things that can be detected are one thing. (30-40%)
- … Human side of things. Have a product to enable a11y reporting through the page. Interesting to have it standardized
- … Wanted to understand the performance envelope
- Yoav: What I'm hearing is there are 3 different cases
- ... One is browser automatically detects accessibility issues and reports them to an endpoint that registers as interested in that info
- ... Second is user-generated reports, give the user a way to say this is bad
- ... Third is around loading performance, since it's a multi-dimensional aspect, there are many different APIs this working group is working on that report on dimensions of that problem
- ... Are you asking to make use of those APIs or do you want the UA to have a conclusion on what is too slow and report those conclusions?
- Janina: Would like to have a conversation around what is too slow, even with US infrastructure bill that doesn't cover the planet and making sure people w/ lesser resources can participate better
- ... Knowing when load starts and when it becomes interactive is important
- ... Could lead to algorithms that load less eye candy
- David: Big implications on the cognitive disability community, when I get my news on the phone, but whenever you load a lot of articles that have content, it doesn't load continuously all at once.
- ... Ads shift screen up/down whatever, we lose our place and trains of thought
- ... Creates cognitive fatigue and losing train of thought
- ... If it's loaded in one continuous it would be OK
- Yoav: That aligns perfectly with what this group does in its day to day
- ... Google has this Core Web Vitals program that defines thresholds for what is good/needs improvement/poor
- ... And we could have a normative version of that that is reporting in cases if one of those dimensions fails
- ... Loading performance, shifts, responsiveness
- ... On this front, there's perfect alignment for what you're asking for and what we're doing her
- Ian: I'm editor of Reporting spec
- ... First off, I'm excited about possibility of Accessibility standard that could leverage this
- ... Reporting is a mechanism other specs could use
- ... Doesn't define any reports, but here's a standard way of reporting
- ... Could be any other server that you setup to collect them
- ... Other specs are responsible for what goes into a report
- ... What the endpoint does is up to the site developer
- ... e.g. Sets up headers that ask for "CSP" reports, and please send to this reporting server. Or crash reports
- ... They could say "please set up Accessibility reports" and send to this server
- ... Sub-documents can set up their own configurations, e.g. chat server asks for reports to go to a separate place
- ... With certain triggers, if the tree is malformed (or things we can detect happen), please generate a report and send it to whatever is configured
- Eric: Could we take existing automated tooling checks and it could hook into existing tech and report through API?
- Ian: If you have a document policy, you could use it to apply restrictions around accessibility requirements and report any violations through the reporting API
- Yoav: Document policy is a different spec that allows site to say specific policies on the document being loaded
- Matthew: To add context, there's different ways you might get these automated accessibility tests
- ... One is by using Axe built into Chromium
- ... Or another browser extension, which do accessibility testing
- ... Third is a service that crawls and does tests. Headless browser.
- ... Key thing is the browser itself at the moment doesn't do anything with that information
- ... Not just at document load time, it's whenever, as DOM changes so does accessibility tree
- ... Depends on when I push the button in the browser to run the tests
- ... We'd need a way to package it and send it to particular endpoints
- ... Addition to browser extensions/APIs and that's setting aside the format of the report
- ... Not just at document load time for the accessibility stuff
- Ian: With Reporting API being part of the browser, anytime something happens you want to report on, we buffer them and send out as a batch
- Janina: If a subcomponent encounters issues it could report to another endpoint
- Ian: If the subcomponent opts into it
- Yoav: Iframes can set up their own Reporting API header
- Ian: Yes
- Michal: Was there a spec for user reporting accessibility concerns?
- Ian: Would that be a browser UI that reports having accessibility issues?
- Janina: We are encouraging a browser standard mechanism
- ... That goes to whoever owns the domain
- Yoav: We need to be careful that users don't create cross-origin leaks for themselves and report their own state
- ... In general from implementation, the accessibility tree is not always built, it's only built for users that need it?
- Lionel: Not quite correct, it's always built, depends on whether it's consumed
- Chris: In Chromium, the accessibility tree isn't created until the APIs are used by the browser
- ... Browser has a mode, as accessibility code tends to be very expensive
- ... Difficult to expose this reporting information outside the context that it's already being produced
- ... That's in Chromium, I believe the same in other UAs
- Alex: I think that's the same in Webkit
- Lionel: Chromium knows if the Accessibility API has been called
- ... Does it share that information, if it's logged into the profile
- Chris: It does not
- Lionel: Does the browser have knowledge of whether you're using the accessibility tree?
- Chris: It does know when you're using accessibility tech, as APIs from screen reader, it's calling an API
- ... Tree is not really something operating system APIs know about
- ... Tree is an implementation detail of the browser
- Scott: Browser detects if you have high-contrast mode in OS
- Matthew: Reasonable if APIs are being called, not controversial, but we are concerned as a community about users inadvertently telling others they're using accessibility tech
- ... Many different reasons why someone may be calling these APIs, testing it, might be using assistive tech
- ... Somewhere between 1/4 to 1/3 of users can see the screen, but they use it to understand the text
- ... Generally we don't want to share private information and it's probably not accurate
- Chris: It is really important, there's no way for a website developer to directly detect it, by design
- ... So Reporting API needs to take that into account, especially if user reports it
- Janina: Tomorrow we have a meeting with verifiable credentials
- ... So you'd only have to share this data once
- ... We want to simplify so you don't have to set each time with every device
- ... We think there's an opportunity
- Noam H: I was wondering, and I think I got the answer, whether it's interesting for us to measure time the accessibility tree is available, like we measure if FCP
- ... People who don't see well may not care about when pixels are displayed, but when they can "see" accessibility content and when it's available
- ... From what I hear, that would violate some privacy constraints
- Yoav: Problem from exposing on a per-user basis
- ... Maybe this would fit into aggregated reporting
- ... You don't know anything about any particular user, but here's your histogram for accessibility tree building in rough buckets
- Michal: As a preview, would you get daily info?
- Yoav: Browser would send encrypted reports to the origin, which it can send to aggregation service, which could produce summary reports from all users
- Lionel: Satisfaction survey upon consuming a service is ubiquitous today
- ... Has that come up for Reporting API
- Ian: It has not
- Lionel: If we could learn how accessible the internet is, that would be helpful from our perspective
- Michal: The Reporting APIs role is not to decide what to report, it's how to report what you already measure
- ... If user wants to fill out a bubble to report on how it works, Reporting API or Agg reporting, etc
- Barry: Reporting API is set up by the site owner, it's up to them to report on. It's not sent to some central group
- Annie: Aggregated reporting, even if it's aggregated, my understanding is quite a bit of accessibility use cases is bots, and they use access tech, so it might skew numbers
- Lionel: We have a lot to learn
- ... Chrome browser has a login, a profile
- ... When I'm logged into Chrome on another computer, it seems to me the browser knows everything I did on the other computer, bookmarks, profile, dark mode
- ... That's in the browser, Chrome?
- Chris: Yes
- Lionel: The browser could choose to know that accessibility APIs are used?
- Chris: Yes
- Lionel: Is Google currently storing this?
- Chris: I don't believe so, we only store information necessary for the user's settings
- ... We don't have a setting that automatically turns on accessibility
- ... Chrome OS still has this distinction
- ... Device can have accessibility turned on, and it persists
- Janina: I would expect on reboot it doesn't need me to turn it back on
- Matthew: Browser responds to AT
- Michal: Is there a request to add a feature like that?
- Lionel: Not yet, no
- ... We have needs for motor-impaired person to not share things they don't want to shahre
- ... Progressive trust, as you interact with an entity more and more
- ... I'm looking to gain enough understanding
- ... Understanding Reporting API would support
- ... To start, load times, would the Reporting API carry that?
- Yoav: Reporting API was designed to carry non-performance things, as RUM and other tech and delivery performance information
- ... But Reporting API could
- Lionel: We spoke on failures on level of accessibility tree, or before they have a user experience
- ... Endpoint would need to be configured
- Ian: There would need to be a spec, like Accessibility Reporting, not part of Reporting API but built on top of it
- Yoav: Needs to take into consideration the privacy concerns
- Janina: We would need to write that using your framework, but at the point we'd need to go through W3C process
- Yoav: Yes
- Lionel: Survey for happy/unhappy, you'd have to build and aggregation thing
- Yoav: Aggregation is a very early-stage proposal from myself, it's something being built for other purposes, for privacy/monetization purposes, and I'm hoping to use it here
- ... If and when that happens, you'll be able to use the same thing from that perspective
- ... You may not need aggregation for user satisfaction surveys
- Lionel: We can put that off for now
- Janina: I'd like to discuss at a later time
- Michal: Anything Reporting API reports would need to be a spec
- ... i.e. User Satisfaction, is it a concern that this specific user is unsatisfied, can use Reporting API
- ... But if it is a concern, you may need aggregated reporting
- Lionel: Any website can ask if you're satisfied today, why would we want to use the Reporting API for a satisfaction survey?
- ... All of the entities building websites today are overburdened from accessibility, challenging for business
- ... Can you build an I'm-Accessible-Or-Not, they may need to get an accessibility provider
- ... Reason why we're interested in more automating this, not all businesses would need to build it on their own
- Barry: The API will be there, there's not button-click from the browser
- Yoav: Maybe there would be browser interest in exposing browser UI in a standard way
- ... You'd need a separate spec and see if there's implementer interest
- ... If not the reporting mechanism would be standardized
- Lionel: HTTP certificate failure is that implemented or being used
- Ian: Not currently
- ... Content Security Policy violations, etc.
- Lionel: Is that a general endpoint or up to each
- Ian: Both, some websites do it on their own, some depend on third-party services
- Lionel: We could learn more from Reporting API
- Barry: Not a general CSP reporting, you do it your own or there's some services
- Yoav: We'll connect offline
- Pat: Think of the Reporting API itself as just a guaranteed delivery mechanism for something that people were before using Fetch/XHR. Reliable mechanism.
- ... What it gets reported and to who, is under the site's control
- ... Some exceptions like error logging and NEL that can be relayed elsewhere
- ... Reporting API has guarantees built-in
- Chris: The happiness survey you're describing sounds like a general user-survey feature
- Yoav: Wikimedia suggested at some point, we might be able to connect
- Humans can (also) measure your performance — Gilles Dubuc
- Human performance metrics
- A large-scale study of Wikipedia users' quality of experience
- Matthew: One of the things we wanted to get from this, is if our use-cases would fit into the envelope of Reporting API. Seems like they do
- ... I like use of aggregation for user's privacy, one of the things I'm thinking about is if a site has contacted me to test it for accessibility, and I have a tool that's generating a whole list of problems with specific DOM nodes, that's technical information
- ... We might want to provide users a choice whether they want aggregated or sending it straight through, and what that choice makes for their privacy
- Yoav: I could see a permission-prompt for providing more debugging information about their experiences
Server Timing and fingerprinting risks - Alex Christensen
Minutes:
- Alex: A few thoughts on the server timing API, and what motivates our decisions on what features to enable
- … have a strong belief the web should be a safe place
- … “privacy is a fundamental human right” (apple.com/privacy)
- … “security and privacy are essential” (W3C TAG Ethical Web Principles)
- … “the internet is for end users” (RFC 8890)
- … conflicting interests that underpin the design decisions in this group
- … What kinds of things can server timing enable?
- … Can enable good things - to make the web faster and better, and that’s great
- … Can also be used for bad things - tracking information, especially cross origin
- … Server timing enables a new channel of sorts
- <img src="https://example1.com/img.webp"><script src="https://example2.com/analytics">
- … Would enable a host of image to send number to the page embedding the image
- … Can enable the cross-origin server to say “we determined it’s user1234”
- … This was an issue when trying to enable
- … If you have complete control over example.com’s servers you could expose that information in other ways
- … But that argument doesn’t hold for us. “We can do this here, so let’s expose it over there” is not compelling
- … We consider this as a problem we’re working to solve
- … We are one of browsers that are working on proxy technologies that hide IP addresses. So trying to overcome that privacy front
- … Trying to increase the privacy of our users on the web - not a fight we are about to stop fighting
- … RE server timing specifically, we introduced TAO - what if the server says it’s ok to expose that information
- … Fixes some information, but doesn’t solve tracking - trackers want to expose the information
- … Proposed a solution - adding to the spec wording that says that the UA can prevent cross-origin access completely
- … Would same-site only server-timing still be useful?
- … People noticed that our performance timing implementation doesn’t expose sizing information
- … We removed information about the size of the HTTP header, and made it much more likely we’d ship it
- … Currently implemented off by default
- … Still of the opinion that the cross-origin case still exposes too much information, even with TAO present
- … Proposed a similar solution - make it so that a UA can choose not to expose these values, even with a TAO header
- … Similar question - would same-site only transfer size be useful?
- … Stepping back - many of the features have the form of enabling new measurement means
- … Sympathetic, but hard to distinguish between a RUM provider and a fingerprint
- … the former is ok, but they look the same
- … Also seem features like CompressionStream - which are generally great
- … May increase fuzzing area, but it’s recently implemented and on by default
- … On its way to STP
- … Interested in feedback on the questions
- <discussion>
- Yoav: I think you implied, the same information is visible by CORS
- Alex: A lot of it, CORS cannot see encoded transfer size
- Yoav: If I'm a tracker that got information about a user, I can embed that information in an image, on a script, just in a response
- Alex: Or in text of the response
- Domenic: A more basic question, if there are new capabilities, then they must all be polyfillable? But that's not true
- Yoav: SeverTiming gives JavaScript visibility into a specific HTTP header
- ... Polyfill-able on server-side and coordination work, but easier through API
- ... For ResourceTiming transfer sizes, visible with CORS but you don't know what happened pre-compression but you could communicate that from the server
- ... So it's not exposing new capabilities
- ... I respect the perspective of this being another way of exposing this information
- ... At the same time, I have trouble seeing how you could block other vectors that could expose the same
- Jeffrey: Privacy argument, this is not an existing data leak, data leak is essential to the platform, we couldn't expose the data w/out breaking the web
- ... If you have a tracker of some sort that wants to expose a user ID, they could put it in the response. We can't block that because we'd have to stop CORS.
- ... We can't make that improvement, so we can expose that data in another way
- ... And you don't think you can expose that new way?
- Alex: Correct
- Jeffrey: Could you ever remove CORS?
- Alex: Not today, possible in the future, a dream that we won't let go of
- Colin: Would constraining your value in the timeline of the TTFB, putting a duration of a 64-bit int, you're limited to a value under 100ms, if we constrained those values so they had to be within the time period of the delivery cycle, would that alleviate some of the concerns
- ... With TAO you don't get description field, but you get duration as long as it's within a realistic window
- Alex: It could reduce surface area for fingerprinting
- Patrick: Would only reduce that in the case where you can transmit one value, otherwise you can transmit several bit fields
- Alex: Even low/medium/high would be more likely to be enabled
- ... Constraining to a smaller subset of the numbers is a good set
- ... A small subset of allowed values is a better step
- ... Not exposing the information at all is even better
- Colin: From a vendor perspective, there are sets of origins that are the "same" origin even though they're cross-origin behaviors, but they're as authoritative as primary site
- ... If there was another mechanism, we use ServerTiming from cross-origin, because we control both sides of that equation, akin to Origin Sets
- ... So they could be associated together
- Alex: I understand those needs, and it would be unreasonable to move the other origins to be under the primary domain, but there's difficulty in allowing this while still getting approval to turn it on internally and preventing use we don't want
- Eric: Is Webkit open to things that fall in that bucket of reduced sets of values, or is it a hard line where they're trying to shut it off entirely
- Alex: A lot easier for me to get approval to turn on one-of-three values vs. int64 range
- Jeffrey: Does it allow sending these across two top-level sites, or just within one tab?
- Yoav: It's part of the ResourceTiming entry, so reported into timeline of the document loading the resource
- ... That potentially cross-origin resource communicates back to the top-level origin
- Jeffrey: Threat model is two different top-level sites can't exchange an identifier
- ... Sending ServerTiming within a top-level site doesn't violate that thread model?
- ... Any number of bits within that same document is acceptable with that threat model since it's not across top-level documents
- Domenic: It's sending it across sites but not documents
- Yoav: If there's a single document, it's getting information from subresources that are cross-site
- Ian: A cross-origin script could then read that data
- Yoav: They don't have any credentials that are specific to those resources
- ... They could have a side-channel to identify that user
- Jeffrey: A fingerprinting script on the origin could accomplish this
- Yoav: With less accountability
- Jeffrey: So what is Safari worried about here?
- Alex: Safari is worried about old un-maintained websites, being retrofitted via ServerTiming to pass tracking information between third-parties
- ... That do not change their content, but are hosted by a host that can add HTTP headers
- Charlie Harrison: You're assuming website is a non-colluding actor here
- ... Scripts are maliciously learning things that the website does not want share about the user
- Alex: And the user does not want to be tracked across this website
- ... A lot of the focus on our discussions, how does this affect the CDN/tracker/website host
- ... We need to focus on how this affects the end-user holding a device in their hand and has no idea what this device is doing
- ... Wants to navigate web without being tracked
- Domenic: You can't join user identities because they're not in play
- Charlie: That's not the threat model, evil.com is embedded in honest.com, and we want them to learn very little about the users on honest.com
- ... Via ServerTiming they learn marginally more about the users
- Domenic: If evil.com is embedded they could just read the cookies
- Jeremy: With partitioning, the example involves example2.com collaborating with example1.com to identify the user in the top-level site's partition, which network state partitioning is supposed to isolate from example1.com as a top-level site
- Alex: That's how we want to be but we're not quite there
- ... Until we're there this isn't a valid threat
- ... Because of things we can't expose here
- Jeffrey: Once those are fixed, would this be an acceptable header?
- Alex: Possible
- ... Once we fix all known tracking vectors, then there should be no problem here
- ... But even at that point, we're hesitant on things like this
- Colin: Are you expecting to apply strict cross-origin definition or are you thinking of sites an descendents
- Alex: Working towards TLD+1 being the boundary
- Nic: evil.com would need to be a script itself
- Alex: it’s receiving information from evil2.com
- … If they’re both scripts, they could collude on window, but they may not be both scripts
- … To return to the original questions - would same-site info be useful? Or is the use case about third parties
- Colin: The value is definitely there
- Nic: More useful than what we have today. A step in the right direction
- Yoav: same questions and answers for what Mark talked about yesterday
- Alex: How can we reason about the information? Are we just trying to make it simpler to gather information?
- Nic: Yes
- Jeremy: If we’re trying to get the actual timing information, TAO is the only way to get that
- Alex: Exposed most of the timing information, just not server timing and sizes
- Nic: RE difficulty, page that’s tracking with RUM. Want to know if it’s a cache hint at the edge, or time to the origin. Way easier to add that to a server timing headers
- Colin: Allows us to remove a lot of cookies that communicated that information
- Nic: Asked colleagues what things they’d like more information about. ServerTiming in Safari was a very common topic. Moving in the direction you’re proposing would be helpful
- Charlie: posting slides?
- Alex: no
- Charlie: Would be useful to post the threat model on the issue. Feels like there might be a path forward to make everyone happy
- … 90% of the way to understand, but more info would help
- Alex: Can disclose the info from the slides onto the issue
- Colin: Server timing on the img includes a “request ID” that’s scripts can pick up
- Domenic: When reporting this, how important is that script src is on a different origin?
- Jeremy: The document is a legacy one and only the 3P responses are malicious
- Alex: In the example, example1 has info that example2 does not have. Enabling example1 to send this info to example2
- … both parties want this to happen
- … The human looking at the phone does not want this to happen
- Barry: Could also be inadvertently passing information
- Alex: even this that are not malicious have effects that are not desired
- Jeffrey: Should not allow the site to know the user there is a user on some other site
Aggregated Reporting - Yoav
Minutes:
- Yoav: Idea, not even yet a proposal
- ... Haven't run it by security folks, people may say this is a bad idea
- ... Generally cross-origin leaks are bad [mmm k]
- ... We don't want them
- ... They allow evil.com to grab user state from an embedded victim.com and abuse that knowledge about the user
- ... What if we passed cross-origin information by aggregating so they don't have that particular risk
- ... Efforts around attribution reporting API that reports around ad conversions
- ... Browser essentially sends encrypted aggregatable report to origin
- ... Reports the origin cannot read, key and value are dimensions of the report are tucked into the key
- ... Origin sends those reports to aggregation service, it's trusted and has the keys, and it turns them into summary reports
- ... Maybe we can do the same? A lot of information that is either a cross-origin leak of a severity that we're trying to get rid of
- ... Or get new information that we can't today
- ... DNS resolution times are blocked on TAO, but not data for origin to give
- ... resource sizes and things that happen inside of iframes, this is new information we'd like to have
- ... LCP render times, there's a separate discussion to be have, whether they're not exposed already
- ... If they need to be protected as they currently are, we could report them in some form of aggregate
- ... Made up name for the API, tells browser I'm interested in particular feature or data
- ... Feature is the data reported, key is the dimensions, e.g. reported feature + hashed origin
- ... Value is the measurement
- ... Summary reports represent some lossy data per origin
- ... We'd need predefined hashing per origins
- ... RUM providers would need to create hash tables of popular origins that they want to know the hash of
- ... Do that kind of translation when reporting that to dashboards/users
- ... Aggregation can't give us specific URLs, won't fit into the key (create too many hash values to be useful)
- ... Maybe we could do that for popular URLs
- ... Not everything can be a dimension of a specific measurement, e.g. nextHopProtocol and dropping that or modifying the way we report it. Hard to see how it fits as an aggregated reporting when we want it to be a dimension for specific measurements
- ... Report it as a bitset on these aggregated measurements
- ... But not able to retrofit that as a dimension on user-specific measurements
- ... Big question, is it safe?
- ... Have not run this by security people in proper channels
- ... Safe for individual users, where we won't be exposing information about them
- ... But embedded origins may not want it exposed
- ... Login rates that can be business information that don't want embedded to know what percentages are logged into their widgets
- ... Summary reports could maybe made lossy enough to avoid it
- ... To the extreme, just two buckets, bi-modal distribution but not much more than that
- ... Requires analysis and better math
- ... A bucket is a range on which we report a measurement
- ... And if we have bi-modal distribution we'd go for median for each model
- ... Least-useful number that doesn't expose anything super-secret
- ... For alternatives there's the Private Aggregation API that is a worklet that gets all the data it needs, but it can't communicate other than agg reports
- ... Each site or RUM provider builds their own scheme
- ... And summary reports are being sent
- ... Unclear if we could reasonable about summary report limitation
- ... Use-cases for accessibility, another use-case with that kind of mechanism is unrelated to performance, but for accessibility users, we can't expose which users are using assistive technology
- ... Other examples as well
- ... From cross-origin information angle, but there may be other angles where this kind of reporting can be useful
- ... Document has comment access to the world
- Artur: From a security POV is that relying on technology for use-cases, for ads use-case they need this otherwise they lose out. For this case, useful data, but difficulty for users as they need to build cloud infrastructure.
- ... A fair amount of work
- ... Is the incentive there to do all of that
- Nic: from a RUM provider perspective, I can see us handling this for our CDN and RUM customers. Another stream of pre-aggregated data
- … would need to report that to our customers, but can’t see why it won’t be compatible. But customers would want it
- Artur: a third party that does that work makes sense
- Nic: In many cases, websites pay others to do aggregation for them
- Camille: Once we have this information in Aggregate APIs, could we remove some of the per-user information from e.g. ResourceTiming APIs?
- Yoav: Yes I think that's a goal
- Charlie: I think a good output from the web platform security folks is what we would be trying to protect with something like this
- ... Challenge I have with this proposal, aggregated reporting was intended to protect individuals and their privacy
- ... it's unclear between full total protection of all x-o information and information that protects just one user, is where we are on the spectrum
- ... this doesn't feel like a place where we normally make decisions on the security side and it's usually more black and white
- ... where I'm struggling with understanding are we comfortable providing cross-origin aggregates
- Camille: What the issue is with cross-origin leaks in general
- ... Generally the cross-site leaks we see can be used to determine if a particular person is browsing this website right now, and I can understand that because?, the concern is if I am restrictive of ?, and I want to target specific individuals, I install an exploit in a particular browser
- ... I don't do it everywhere as it could be found by security researchers
- ... In general the concern of cross-site leak is ability for a particular page at a precise moment to identify if a user has particular data points
- ... Or for employers to know if they're going to a site e.g. cancer survivors
- Artur: A nefarious actor can take additional action, in addition to privacy which is more concerned about the aggregate
- Whether probabilistic attacks are possible, duplicate encrypted reports and extract information about a specific user, there would be a concern about this but I don't know if that would be different for what we would do ?, so if we have a case why doesn't expose individual data
- Charlie: I do think we could work to plug all those leaks.
- ... My question is more actually the only thing we care about from the security side
- ... Yoav brings up info about evil.com learning aggregate estimate of how many users has X, the threat is not to an individual, but to the proprietary data the site has
- ... Not sure how much we care about that threat
- ... Individual stuff we can say theoretically we know how to do it, but this other stuff is so nebulous
- ... At one extreme you can't give any information
- Camille: focused on the threat to the individual user
- Charlie: If this is not something we care about protecting, that’s fine
- David: In terms of attacks to individual users, in the context of ads we worry about the scale of attacks. Not-scalable attacks are not relevant in the ads works
- … We have to make sure that aggregated reporting works well in the non-scalable threat model
- … Some of the protection are not probabilistic, but incomplete in the context of a single user
- … Counting the number of logged in users seems like an improvements
- Yoav: There is data that we currently exposd on individual basis that we could move to aggregated only
- …but there is also data that is not currently exposed, and which we think aggregate reporting would enabled (new data)
- …In this case we would need to make sure that’s safe
- David: Okay so some data is strictly better to expose only to aggregate by moving from individual, but new information would we would have to review
- Yoav: Regarding the threat model to embedded widgets, we don’t want to expose their business info to the embedders, as we don't want businesses on the web to die. We need to consider it, and whether my naive bucketing solution is good enough or not
- Charlie: before we discuss solutions, we need to nail down requirements
- ... I don't think we need to go into extreme mode, just two buckets
- ... We should be more reasoned about what we're trying to protect and just protect that
- Sean: I don't feel comfortable seeing this, motivation is helping ads. We think the web should be open to all and accessible to all. Feels weird we're targeting a subset of users.
- ... Aggregating reports would help ad providers to get user data
- ... So this would be hard for Mozilla to support
- Yoav: This infrastructure is being proposed and built for ad attribution purposes, and this use-case is a very different one
- ... Plus accessibility use-case from earlier today
- ... I think it would be a shame if we got hung up on the ad attribution parts of it
- Charlie: If we were to propose this divorced from any ad aggregate data, does that change your perspective if it's not closely linked?
- ... Problem with just this proposal in isolation?
- ... Overall background is we're building infrastructure aggregating generally, and one use-case is for ads
- ... But this isolated use-case could be used even if we didn't ship ads stuff
- Sean: I would be more open to that, but my concern is this document mentions ads as the motivation
- Yoav: I was just explaining how this worked in the ads world
- ... If we were to build all of this infrastructure regardless of the ads use-case, it would be worthwhile to consider this proposal without how we got to how we built this infrastructure
- Michal: To link back to accessibility, you would not want to expose this information to page authors. So ads reporting would be a separate distinct feature. Agg Reporting API would be the feature that does it
- ... Mozllla could have an opinion on Agg Reporting API separate from ads stuff
- Yoav: SImilar to Reporting API today, infrastructure, which some may not want crash reporting but do want to CSP reporting
- ... We can split this into infrastructure and reports that rely on the infrastructure, and you could support the infrastructure but not all reports
- Artur: I think there will be more and more use-cases for aggregated reporting infrastructure, and I think it's possible ads may not be one of them
- ... ironically the original impetus may have been ads, but they may be using something different in the future
- ... Consider this as a technology to expose information we otherwise could not
- Alex: 128 bits is too many
.webp)
Thursday, 9/15
Responsiveness @ Excel - Noam
Minutes:
- NoamH: Talk about the responsiveness metric built in Excel
- … interested in feedback
- … Trying to create a metric for responsiveness
- … What’s responsiveness?
- Response time under 100ms
- Using Event Timing
- Capturing unresponsive interactions - start by creating a map that tracks all the interactions we care about
- … set a dom event and store the interaction with the timestamp of the event as the key
- … in a click event, we call the function to store the event
- … Use PerfObserver that tracks slow interactions
- … Using the start time of the perf entry (same as the event timestamp, by spec) as the key to find the event info
- … Once we have measurements, we measure if it was responsive or not
- … metric is useful for the business to want to make sure it’s stable
- … want to use it for regression detection or improvements
- … Meaningful through out session (for some definition of session)
- … metric per named interaction
- … multiple attempts and iterations
- … #1 - %age of responsive sessions
- … responsive session - 90% of interactions are responsive
- … ended up being noisy
- … lot of variance in the number of interactions per session, which biased those with few interactions
- … unclear what numbers made sense, and tweaking them was challenging
- … attempt #2 - %age of responsive interactions
- … better than #1, but wasn’t sensitive enough for regressions in A/B testing scenarios (didn’t detect known regressions)
- … Current approach - average session responsiveness
- … number of responsive interactions divided by total number of interactions, then divided by the number of sessions
- … math intuition is that average of average tends to converge
- … “strong law of large numbers”
- … very stable and able to detect regressions
- … adopting it as our main metric of responsiveness
- …
- … Detects small regressions reliably
- … Still exploring other ideas and taking a look at INP
- <discussion>
- Michal: incredibly useful! Clarification question: You showed some code where you named each interaction. Is this unrelated to the overall responsiveness?
- Noam: Our metric is per type of interaction. Always look at a specific named interaction
- … important to understand not just the general rates, but what users actually used in order to optimize those paths
- Michal: average of averages swept outliers under the rug. On average excel is probably very responsive
- … so you’re looking for small aggregate changes
- … different from a general interaction pattern
- … we’re looking more for outliers
- Noam: simplified some of it. Can expand RE outliers
- … starting this measurement once we consider things “stabilized”, after initial loading
- … track it by type of interaction, but there are many different types, which lead to small samples
- … aggregate them by bucketing similar interactions together, which helps reduce the noise from outliers
- Dan: Excellent presentation!
- … Comment - a key aspect here is that Excel is an application. Differences are starting to fade, but excel is an extreme here.
- … users with applications make a significant distinction between “load” and “use”. Fine with loading lag if it’s responsive later
- … another difference with this application is that you expect to see more distinct user interactions. Excel-type applications are used differently than a commerce web site or a blog.
- Question - you segment your data by the element/component. Also segment by device type or geo?
- Noam: haven’t got to that yet. Didn’t do research there yet
- … Not advocating for this metric, could be useful for cases similar to Excel
- Dan: Wix editor seems also similar. Maybe dashboards as well - have few interactions with lengthy processing
- … key point is that there are wide variety of interaction types on the web
- .. great you picked one that works well for your scenario
- Noam: Will try to test INP as well, which was announced after this research
- Michal: INP is supposed to be broadly applicable, but you should also collect RUM to get a more specific metrics
- … For INP we tried to segment by interaction type (keyboard vs. mouse)
- … thought people would expect different things
- … Got a lot of feedback that this is confusing
- … Then we found that the metric split is not necessarily different in terms of values
- … In term of responsiveness there was a lot of similarity
- … Before load and after load split is interesting
- … with smoothness we found the distinction important, but was difficult to find the point in time to split on
- … even LCP was tricky
- … what do you use for “load”?
- Noam: Great point. Evaluating ways to improve that. Markers in the code, because we control the app.
- … Another approach - a period of stability in terms of long tasks
- Michal: Until that point is reached, do you measure nothing?
- Noam: measure but different focus
- Michal: In our research, one idea was to track the amount of time is taked to stabilize smoothness. Still care that it takes a long time, but wanted to measure it separately.
- Javad: Is the session an HTTP session?
- Noam: I didn’t get into what the session means. Can be thought of as the time between when you opened the tab until when you closed it
- Javad: Each tab has access?
- Noam: Each open tab is considered a session
- Javad: Can you calculate the sigma inside a single tab?
- Noam: We sed the telemetry to the server, so do the processing there
- Ian: Looking at the definition, the impact of a single poor interaction is greater the fewer interactions are in the session. Is there a high correlation between short sessions and poor responsiveness?
- Noam: Our hypothesis as well. Think there’s contribution of non-responsive experience to short sessions
- … users not feeling productive
- … mathematically, the distribution tends to flat out between small and high #interactions
- … specifically dealt with this problem
- Michal: Seeing this as well and will follow up
- Noam: happy to collaborate further
- Dan: how sensitive is this metric to changes? How quickly are regressions identified?
- Noam: found it extremely sensitive and trying to reduce it
- … heard from engineers that they can’t add more code without regressing
- … not consider everything a regressions, just the more prominent ones
- … helped us find huge problems
- Michal: used 100ms as the threshold
- Noam: yeah. Why not 200?
- Michal: For us a 100 is the target, but measuring p98, “interactions should be under 100ms but nothing should be over 200”
- … since you’re tracking the average, 100 is the right number
- Noam: Considered a lower number, for keyboards
- Michal: different input delays for different hardware types
- … touch input is sampled in different rates, where keyboard is immediate
- … so touch keyboard is slower
- Noam: noticed a difference between keyboards. Also between mouse and keyboard
- Javad: in the mission “provide metrics for UA features and APIs”
- … is the result of the measurement in the UA?
- Michal: The metric uses Event timestamps and event timing entries that are available
- … reports each tab at the end of the session would upload the data
- Noam: works for large numbers of users. For small sites the variance may be too high
- Javad: on the client side, this is not available
- Michal: Right, aggregate distributions of performance data across users can only be available on the server, but there are still… many things you can do client only… can adjust features based on performance feedback
- Noam: Can keep values in a worker
- Michal: Support the APIs you need for field measurement
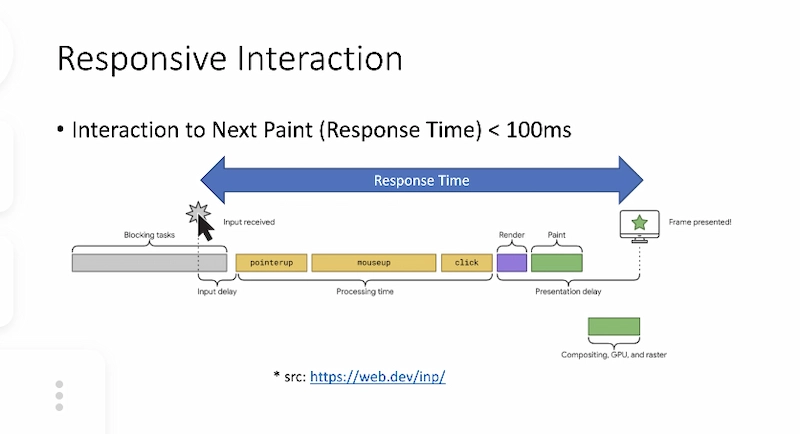

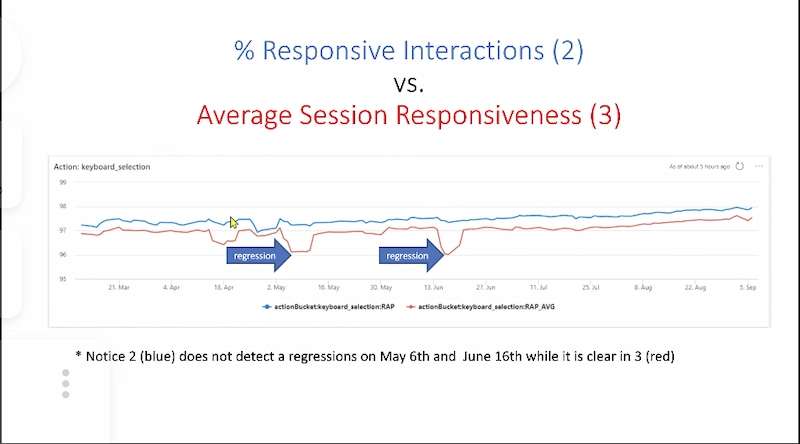
PING joint meeting
Minutes:
- Yoav: Welcome to WebPerf
- ... Few lingering issues that we want to hash out and reach conclusions or at least come to an understanding
- ... ResourceTiming issues
- nextHopProtocol
- ... Concern that it can reveal things about the user's network, e.g. existence of a proxy
- ... At the same time, talking to folks who use this attribute as a dimension, it's critical to deploy and maintain various protocols
- ... Splitting of traffic for H1 vs. H3 clients
- ... Trying to maintain use-cases while at the same time
- ... H1 vs. H2 can probably be detected w/out this attribute
- ... For H2 vs. H3 they're starting to look very similar and are not very detectable in similar means
- ... Try to maintain use-cases w/out risk
- Timing-Allow-Origin and history
- ... Potential history leaks, can it be closed?
- ... Solved by cache and network state partitioning
- ... Comment on issue asking if it can be closed
- ... Or continue the discussion if there are still things unaddressed
- Timing-Allow-Origin semantics
- ... And how the semantics have changed over time
- ... Indeed something we did and we sort of regret
- ... we do have an ongoing effort to break the data up into network, origin, and resource, level information, where TAO will be some sort of declaration for the resource..
- … other types of timings will be pushed into aggregated reporting (we discussed Tuesday)
- …maybe we can use this mechanism to report in agg and not per-user, protect privacy, but still be useful. e.g. DNS reporting, no implications on a single user but very useful to monitor in aggregate
- …ongoing work to undo some of the semantic expansion work we did with TAO, working to make sure it make sense form a developer perspective
- …hopefully that resolves this issue
- ... Issue of deployability and monitoring
- ... Critical for enabling modern development, preventinging regressions, enabling evolution of the platform, and ensuring optimal UX
- ... Contrasting with specific issues against Reporting API infrastructure, and ancillary uses
- ... Provides necessary support to primary activities of the operation
- ... Necessary is the key word
- ... From those issues there are various discussions whether users can opt out of, or have to opt into
- ... We need to make a clear distinction on data vs. transport
- ... Reporting API is an infrastructure API, similar to Beacon API or PendingBeacon API
- ... They are similar to Fetch
- ... If specific data is sensitive, we should talk about data's sensitivity, in a global and holistic way
- ... Talking about Reporting API more specifically and what data it provides, it has different buckets and policies
- ... CSP, document policy, etc
- ... Enablers to deploying new security primitives to the web
- ... New sites cannot deploy without risking regressing or causing severe outages
- ... Need these report-only modes to deploy these policies safely
- ... Then we have deprecation reports, had a breakout session around their criticality to web's evolution
- ... Interventions, some engines may choose to create interventions on websites' contents, and enables websites to know about that
- ... We have crash reports
- ... We also talked about surfacing Accessibility issues or severe perf issues through the API
- ... Then there's the question of what problem we're trying to solve, but having users opt-in or opt-out to this infra or data
- ... Are we trying to avoid over-exposure of the data, battery, data plans, etc? Not clear from Issues
- ... Why not have an infrastructure opt-in or opt-out?
- ... As long as the data is available by other means, developer will figure out ways to gather and send that data out
- ... Adding friction to well-lit path we want them to take, they'll take hackier paths
- ... Prevent them from moving to nicer and hopefully more user-friendly APIs like Beacon/Reporting that provide a clearer way of gathering that data
- ... A lot of the performance data is what developers can deduce from load events, timeouts, rAFs, that have performance impacts and we want developers to collect them w/out performance costs
- ... Why not have data opt-in / opt-out?
- ... A lot of the data there is no way to opt-out data from websites from data they rely on
- ... For example CSP reports, those are things we want reported but also on client-side
- ... We need developers to be able to do things about CSP violations
- ... Other than that, there's the issue of data-bias, if a slice of the population will opt-out of the data, we will have a blind spot
- ... e.g. for deprecation reports, collecting data for feature use, certain segments of the population are somewhat invisible, and can cause us to make bad decisions missing data from those populations
- ... Reporting API is a way for us as a community to recoup that visibility
- ... So sites can make changes about those deprecated features
- ... W/out it it can result in a blind spot
- ... Analogies: Brick and mortar stores, we don't want stores to facially recognize us, see us from other stores, and yell at us
- ... At the same time, putting opt-ins at this data, would allow users to turn off "user counters" in stores
- ... Or sensors in stores that detect shelf is empty, we don't want individual shoppers to prevent means from functioning properly
- ... Beyond that there's no reasonable expectations that shoppers can do that
- ... Opt-in here would send message that this data will be somewhat scary, or websites are wrongfully collecting this data about their users
- ... I don't believe that's the case, and if there are specifics that are sensitive, we should discuss those
- ... "We have collective interests in aggregating data..."
- ... “We should look at what would make the web platform prosper in a holistic way” – Jeffery Yasskin, paraphrasing Professor Viljoen
- <discussion>
- Nick Doty: Initial thoughts
- ... Seems like there are specific issues, I don't have answers to those right now
- ... Seems like most of your interest is in the general direction of user control vs. various reporting mechanisms
- ... Ongoing conversation that we're not going to resolve today
- ... Fine to give arguments, I can give some initial reactions
- ... Common argument we confront, is if we don't provide a Reporting API, sites are going to do it some other way
- ... I think that's useful to think about, but it can come across as a threat
- ... If you don't provide that data, the website will be worse
- Yoav: Performance monitoring in general started from hacks that we tried to pave into more user-friendly paths
- ... I'm not trying to say that as a threat, but it's how I predict things will go down
- Theresa: Question, buying a new Mac that goes through a flow asking questions
- ... "Do you want to share data w/ Apple about usage?"
- ... "Do you want to share data w/ third-party app developers?"
- ... Opt-in all system-level reporting
- ... Why is the web any different?
- Michal: If you say no to those two, what happens if you visit a website in Safari, can that website not report anything back?
- Theresa: XHR and Fetch still work
- ... Native apps can use HTTP/etc
- Michal: Reporting API is best way itself
- Theresa: System has an API, if the user chooses not to, those reports stop working
- Yoav: I think it makes sense to potentially have an opt-in or opt-out for data that is not available by other means
- ... For example, crash reporting specifically, I can see why they'd require a separate category
- ... For other types of monitoring data, that are available by other means, I don't see why such an opt-in would be required
- ... If we don't have an opt-in to provide load event on an image, we shouldn't have an opt-in for providing the same data in other ways
- ... For CSP violations, if we're willing to expose to content on client side, there's no material difference from user's perspective in providing the same data to developers more ergonomically in ways that are more user friendly
- ... For OS opt-in, you're getting specific reports that provide extra data that is not available to the apps otherwise (for 3P apps)
- ... Are we talking about separate data or a more convenient way?
- Pete: I hear a lot of "sensitive" and "sensitive data", I want to caution the group to not talk about user data that's not sensitive, vs. user data w/ PII
- ... Data that at first looks non-sensitive can be transformed for malicious purposes
- ... My alarm bells go off when emphasizing sensitive as a partition line
- ... Little confused by saying web will fall apart w/out this, vs. sites will get it either way
- ... Certainly categories of data being collected via these APIs that are difficult to collect, or are noisy, or prohibitive
- ... APIs are endorsements to collect this information
- ... Some of this is data that's not collectible otherwise
- ... Some are endorsements for things sites maybe should not be collecting
- ... Finally we run around in these conversations around data being useful for solving problems, uncontroversial, should users be in the loop for deciding if that user's data is worth it for that risk
- ... Cases we want an opt-in
- ... Question is whether user should have say in providing data that can solve problems
- ... This isn't Fetch, Fetch is an API for solving problems for users
- ... Reporting API isn't that, it's for sites to solve site problems
- ... Just because they write bits to the network, Reporting API is not Fetch
- Yoav: Reporting API does not expose data, it is infrastructure
- ... It allows you to send data, but I don't see distinction between Fetch and Reporting and Beacon as they're all means for sites to send data out to the server
- ... Or to get data from the server
- ... Used interchangeably, one is more reliable than others in some scenarios, but they have been and will be used interchangeably by developers to get data that is already available on the client side
- Jeffrey: Slides listing data we'd like to send over Reporting API
- ... Some of these arguably have user data in them, some don't
- ... Deprecation reports are not related to the user
- ... Makes sense to argue about each of these, see if we need an opt-in or opt-out
- ... e.g. Crash reports may have user data in it
- ... Make a decision for each piece of data
- ... But the channel over which it gets exposed, Reporting/JS API, seems like it should be less controversial
- ... Reporting API is a way for site to send data up to a certain point
- ... We can argue on what types of data are allowed to be sent
- Yoav: Crash reports and maybe Interventions, Crash reports are main outlier here that they provide data that is not available otherwise to the website
- ... Future Accessibility issues is also one where we will have to tread carefully vs. privacy
- Jeffrey: Focus on less controversial bits of data, CSP violations, etc
- ... Is PING OK with Reporting API to not share user data
- Yoav: Network Error Logging is not included in the slide
- ... NEL should also be there and falls into category of new data
- Nick: Seems like that's a small slice, not satisfy use-cases for things that are not user-data
- Jeffrey: Can we agree that things that are not user-data, reported elsewhere, can we discuss later more controversial things
- Nick: What things are not user data?
- Jeffrey: Deprecation reports, CSP violations
- Nick: What is the site learning about if they're not learning about their users?
- Jeffrey: Themselves
- Yoav: For CSP, about third party violations
- ... Similar to JS running on the site that can be running
- Michal: They are already learning these things, and they are not choosing to report it through a transport, one of which is Reporting API
- Pete: Ones not containing user data, is for Reporting API is not needed
- ... e.g. CSP errors, Reporting API is least needed
- ... Deprecation can be done by audits
- Yoav: Breakout session w/ Salesforce yesterday, hour long on how we need to solve the problem deprecation reports is solving, communication, auditing. Doing these things in the lab is not something large websites can do, nor small websites can reasonably be expected to keep up with
- ... Not necessarily practical
- ... For both of those things, large CSP deployments, for large and sprawling set of properties, etc
- Colin: Very much what we see in our Shopify merchant base where they use Google Tag Manager GTM and depending on the time of data different scripts are detected
- ... Helps to have that feedback loop where they want to enforce
- Pete: This does feel cheaper for sites if they collect billions of data points
- ... Seems like sites putting their responsibility on collecting users data
- ... e.g. what user interactions tripped over which APIs
- Yoav: Can be polyfilled easily by wrapping over those APIs
- Pete: <missed comment>
- Yoav: User behavior on the first party top-level origin is from your perspective user data?
- Pete: How the user interacts with the site is user-data, yes
- ... Especially code-paths that are unlikely to be hit or uncommon
- Nick: Can we get to some points even if we're not going to come to a conclusion
- ... Some of the discussion was around bias, want good data, helps them fix things, I think the conclusion you're making is we shouldn't have opt-in or even opt-out as that might give people a choice in a systematic way that would skew data
- Yoav: I think this choice is unneeded, if the data is available otherwise, and doesn't expose anything specific about the user the site doesn't already know
- ... Same way we don't have user choice on load events in images
- ... A lot these things are how the web operates, data available to websites, don't need opt-out for data in one place and not in others
- ... w/ caveat about things not currently available, being a potentially different conversation
- ... Case I have in mind with that bias is deprecation reports, we have in Chrome as a product, we collect data in wild on a slice, and we make decisions on that data that typically work
- ... But sometimes we miss segments of the population that doesn't opt-in or opts-out
- ... Having those opt-ins for OS makes sense, you want users to have control over what data is sending that is not otherwise available
- ... For websites, they're running code on your machine and have access and send that data, adding friction in one specific case is useful, and will help users in any way, other than adding a decision point for them to make
- ... Hurting overall user-base, as developers will get that data in another non-friendly way
- Nick: So bias is not an issue, you can get the data otherwise
- Yoav: For Deprecation reports, we want an ergonomic way for developers to track
- ... Limiting access to this data won't add privacy but will add bias
- Theo (chrome): Followup on what you said about browser/os showing opt-out
- … systems honor that opt-out because it's correct to do for users, not because they cannot
- … browsers are in a tough space, because they may still have some ability to respect the user decision
- Yoav: Not sure how it works on native, but presumably crash reports get data that the app typically doesn’t have
- Theo: Chrome also has a (reporting process?) and so users could opt-out
- Jeffery: I think the bias problem is such that, users who are more likely to opt-out of this feature, because of privacy preferences, may also have different behaviors
- … that causes real harm to the web, in that we may break the web for a particular subset of users
- … these proposals may actually break a set of users that we most want to protect in this case (disservice to self)
- Nick: Maybe one way to think of it… there is a utility advantage if they do not opt out… so it is in all our advantage to convince them to not opt-out… rather than preventing them
- Alex (Apple): If a user browses the web with JS disabled, should the reporting API also be disabled?
- Yoav: Sure, fair enough, in this case the data is not available then it should not be available here
- Ian: Yes, because it limits access to fetch, beacon and other alternatives which were mentioned
- Charlie: Draw a parallel to the discussion we had yesterday, about the “access-control: public” thing, the interesting tension between footguns and ergonomics…
- … if these apis are not available or unreliable, we can get into a similar situation where devs have a complex polyfill and go that direction… there is nothing we can do to disable such a polyfill
- … in some sense, this is a fundamental thing we need to figure out.
- … to what extent do we say, all else equal, we focus on ergonomics until we truly hit a security/privacy boundary
- … right now we are saying, let's not optimize ergonomics…
- Yoav: yeah but the data is there…
- Charlie: Yes, the argument is conceptually clear – but today and yesterday, we are hearing that maybe we don't want to make it easy or ergonomic… because we don’t want it to be misused
- … in theory a site can report what a user did on every frame, technically, but that doesn’t mean we should make it easy
- Jeffrey: This comes up in some discussions with “frameworks” for sec/privacy, there's a physical world analogy, technically you can go to city hall and look up personal info – but that doesn’t mean we should send it out en-masse
- … Some of these apis seem to be fine en-masse, but some of the others, maybe not so much
- … maybe some are ok and some are not
- Yoav: Okay, right, NEL is indeed some data that is not broadly available through other means
- … but what you are describing is a comparison in orders of magnitude, vs here which is almost equally easy
- … devrel teams can just write a quick polyfill over fetch() and that wouldn’t change the calculus
- Alex: If information is currently gatherable, but work is being done or planned to obfuscate it, should that information be reported to the reporting API?
- Yoav: we should have that conversation, but it should be specific to the specific data that we are collecting, and not the transport itself.
- Nick: Often we have such discussions in Privacy discussions… but many people are not happy with the privacy status quo on the web… just because data is available does not mean that it must always be available… worth considering relative to status quo
- …Last thing: well-lit-paths… sometimes we can offer a better solution, where users have more control. Even if there exists an alternative. We can make a pitch: more efficient, and more user control… its purpose-specific and its for-debugging websites.
- …it may actually undermine the use cases
- Michal: Would the opt-in/out be per site or globally applied?
- Jeffrey: we certainly would not want to interrupt the user, would need to be global, but perhaps with some way to override per site
- Yoav: question for data providers – if such a choice was available, if you could use a data measurement approach that was subjected to opt-ins or opt-out, would you?
- Dan Shappir: Opt out or opt in? That would make all the difference in the world…
- Ian: Is that because of the expected opt-in rates?
- Dan: exactly
- Ian: There is indeed a difference between an API that has 99% opt-in rate, etc
- Jeffery: Chrome’s Crash reporting solution is opt-out, and I suspect this would be similar
- Theodore: In Chrome, opt-out only features, we get under 5% opt outs
- Nick Doty: If a user specifically wanted to opt-out of something, would we specifically want to undermine their choice?
- Colin: Shopify uses this data already typically on a subset of users, but in the big picture, we want to use this as a signal for our merchants – we want to bring them into the story when we know they have something to fix. I.e. notify once we know there is an issue
- … If the question is between zero data or some data, of course some data is better
- Nic: This data is typically used for prioritization [...]
- … From Akamai RUM it's a similar story… we are not sure if we would bother to override user choice… we track CSP etc violations
- … I’d like to know what the text of the opt-out would be
- Yoav: Do-not-track bit,... we may want a similar do-not-monitor bit, and regardless of the API they are not monitorable
- … This is a question that goes far beyond the infrastructure, on the other hand, that is fingerprintable
- Nick: Maybe we specifically disable reporting API in those cases
- Ian: (...) I would be comfortable with an opt-out for reporting api if, Pete mentioned there is a different between immediate reporting vs out-of-band reporting
- … right now the specific Issue filed is as “Reporting API should be opt-in”
- … would it satisfy requirements (...) of the issue
- Nick: …Maybe there is a more general conversation about measurement apis in general…
- Jeffrey: Pete’s opinion may differ from PING’s opinion en-masse… we should add it to PING agenda for a future meeting.
- Yoav: We should also bring in Greg from Salesforce to share their practical struggles here.
- Nick: I am not sure if specifications are the place to do this…
- Jeffery: Typically how it affects spec is the wording “if the user has decided not to collect this data, then do this"
- … if available, do such and such, if not, do something else
- Nicolás: If that was true, it would affect every single spec – it would be better to just disable the reporting API
- Yoav: Perhaps to leave room for UA-specific decision making
- Yoav: Thank you for the discussion… we are closer, but still plenty left
Early Hints: Lessons Learned - Colin
Minutes:
- Colin: From Shopify. Data I’m sharing shouldn’t be used for anything beyond illustrative purposes
- … Saw page improvements for merchants. Over 500ms faster FCP at p50
- … merchants can build web sites from off the shelf components
- … head of line blocking, resources discovered late
- … TLS tax for connection establishment
- … leaving a large gap of time where the browser is not efficient
- … first engagement is super important - 10% faster => 7% increase in conversion
- … Past attempts: H2 push, resource hints
- … the latter depends on how discoverable the resource is. Competing with the renderer, so better for indirect resources
- … challenges - adding HTTP headers is hard, adding a new status is also hard
- … developers in the shopify ecosystem have a hard time with that
- … relaying through a CDN is also hard
- … browser support also lacking
- … used a static resource domain - used to be a past best practice, hard to unwind
- … Sites are not cacheable
- … Implementation - exposed APIs to developers to add preloads, both as a header and in markup
- … added rel=preconnect for link headers
- … limited to preloading shopify resources and not third parties and the number of preloads
- API example
- Send the link header as part of a 200 response
- Cloudflare would cache the link header, and use it to generate a 103 for followup requests to this same resource
- Isolated this to H2/H3 as well as user agent detected
- Chrome M95 introduced early hints behind feature flags and a field trial for Black Friday
- … failures: enabled scoped to HTTPS, and thought it’d eliminate middle box issues
- … proxies out there, with this code
- Found issues like that in various proxy stacks used (code copy-pasted for ~20 years)
- Limited the use to H2 and H3 connections
- Ran into issues with Lighthouse - lighthouse was looking at the first response and saw it has first response of 0 and fail
- Started using User Agent to get around that
- Great results from gymshark
- Global results
- Challenge in collecting the data, had to jump through hoops because it was unclear if the client that had the field trial enabled and can actually do EH
- Saw good results across different geos
- Looking at TTFB, they saw it got worse
- Had to re-analyze the data given that responseStart is the early hint
- Time-to-last-byte was also worse, but 10s of ms
- Makes sense that there’s extra cost
- 10ms on TTFB is worth 500ms better LCP
- Lesson learned
- issues:
- responseStart should be when the authoritative response landed
- Added initiator-type=early hints but it ended up being racy
- Conversations around subresources and worker usage
- Browser adoption
- Reporting of orphaned requests
- Otherwise, most gains were from preconnect
- Working on unwinding the separate domain, but early hints gives them time to do that, while getting around the old bugs
- Yoav: Regarding reporting of orphaned requests, Reporting API?
- Ian: Yes seems interesting for it
- Yoav: Dev console issues should generally be unsafe
- Ian: Discoverable in the lab, or does iit need to be in the field?
- Colin: Yes, there are a spectrum of users, majority can be determined in lab environments, but it can happen anywhere
- Jeremy: Can we understand how many of these were sometimes used vs. became obsolete because of structural changes to the HTML
- Yoav: Cross-origin credentialed vs. non-credentialed, is that preconnect?
- Colin: We solved that by doing both all the time, since both will be used
- ... We see repeatedly, they use webfonts, we try to turn on crossorigin, they're clever and it gets downloaded uncredentialed
- Yoav: even if we got rid of connection pools and had a single for connection, you would need request mode matching
- ... We could have initially had fonts, there is no no-cors fonts, so regardless it should always be cors mode preload
- ... Not where we went
- Colin: Having clear reporting, if you thought you downloaded checkout script but it was unused
- Jeremy: Try to use a font but didn't use cross-origin, does it show up in dev tools
- Yoav: Yes, but easy to miss
- ... Closing feedback loop would be good
- Colin: How do you tighten up message in dev tools
- ... Need to decipher
- Jeremy: They're trying to move some stuff from console warnings to Issues, more details
- Yoav: Console issue is timeout-based
- ... Reporting API could be smarter, at the end of the session
- Barry: Two reasons, preloaded and wasted, preloaded and wasn't used right away so it shouldn't be preloaded
- Jeremy: Why are resources orphaned? Was the URL wrong to begin with, or did it become outdated?
- Colin: Mostly the latter.
- Jeremy: Shopify surface for issues?
- Colin: Want to do more. Give them more information at the right time
- Jeremy: When shopify devs look for issues, where do they expect to find issues?
- Colin: Most of the time they don’t know where to look. Typically online and ad hoc
- Barry: Can I sell you Super Early Hints?
- Dan: Seen areas where areas where people preconnect or dns-prefetch all their 3P origins which can degrade performance
- Andy: How would you handle cross-origin requests? In EU you can’t use Early Hints until you got consent
- Colin: part of the reason why we scope it to site. What’s the buyer leak exploit vector? Need vetting process
- Michal: to yesterday’s conversations about headers and body. If you scan the response body to extract headers (i.e. http-equiv)... this seems very similar. So why is automatically modifying headers based on the response body difficult when we can do it for Early Hints? Perhaps the difference here is that its OK to get Early Hints wrong some of the time (first response and after every change to resources)
- Colin: The headers are held on until we’ve gone through our object model. The link header is cached in the CDN. Worst case scenario, the link header is out of date on the first request. It’s always replaced by the last successful response. Acceptable loss of one request’s
- Yoav: It's all headers, vs. putting something in the content, messier from CDN code perspective
- Colin: Edge case, need to sort out interop between CDN and edge, how do I emit some Link headers I want cached for Early Hints but not all Link headers, maybe I want to list all images possible
- Yoav: Link rel=push all over again
- Barry: If you Early Hints image w/ srcset, it doesn't know which to pick, so no benefit of putting in HTTP response
- Yoav: You have to wait for the document to be committed, and preload scanner to run first buffer before running anything
- Barry: Not bad, but it will have to wait
- Yoav: Unless we do Viewport header and add Early Hints support to it as well
- Colin: subresources and fetch doesn’t trigger Early Hints This is useful for marking things like webfonts as an earlyhint on a css request, or images from a fetch() request that is transf
- Jeremy: the liquid snippet, are you buffering the entire body before sending the preload?
- Colin: It is buffered before the headers are released
- Jeremy: HTTP headers are hard for developers. Would that approach help developers set other headers in a similar way?
- Colin: We focus on the outcome you want to create, not the mechanism. What other headers would you want?
- Yoav: Document policy
- Colin: We should just do that for you and remove the cognitive load
- Jeremy: being able to set a header based on the template is a capability that shopify has, though? Can you add other features that would result in headers?
- Colin: yeah. Headers are hard for partner developers. Inside the platform we can add headers. Prefer add it there over educating devs
- Michal: For long tail of headers.

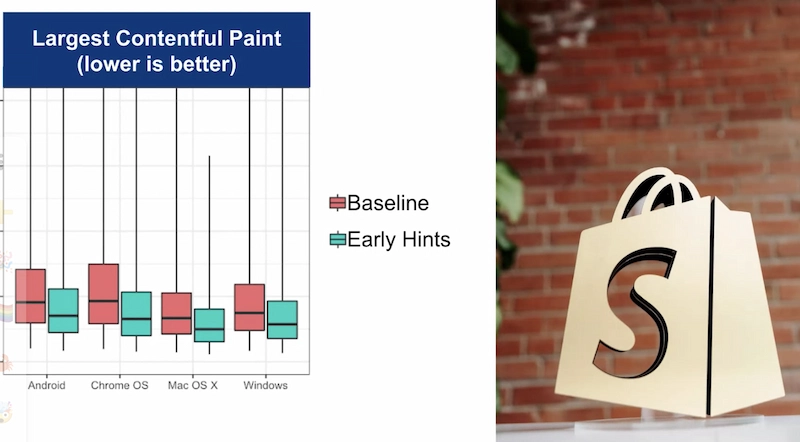

Friday 9/16
Rechartering, incubation and spec status - Nic
Minutes:
- Nic: Welcome to the last day!!
- … let’s talk about rechartering!
- … living under our 2021 charter
- … Expires in February 23, so need to look at the charter and renew it
- … See if there are any changes to be made, specs to adopt from incubation, discontinue, etc
- … The charter contains our scope, went through it in 2021 and made some modifications. Can reevaluate, but seems still appropriate
- … themes are measurement, scheduling and adaptation
- … Specs in W3C page. Some things are changing
- … e.g. Resource Hints is being discontinued, but work is not complete yet
- … e.g. for preload and page visibility we mention that things moved, may have work in the resource hints repo to do the same
- … Preload was moved, repo was archived and the text describes how it was moved
- … editor draft redirects to HTML
- … For PageVisibility, we should discontinue it in the charter. Moved to HTML, the repo is archived, but we should mention why it was archived
- … The draft says it’s discontinued, but may want to auto-redirect
- … Beacon and rIC were being pushed to REC, but now think that new incubations may be appropriate to incorporate into them
- … E.g. unload beacon => Beacon, postTask => Scheduling APIs
- … EventTiming and LCP were recently adopted, not yet listed in the charter, so need to do that
- … LCP could incorporate ElementTiming, something to consider
- … Timing names registry, we may want to make it an official registry
- … Would need to consider merging LCP into Paint Timing
- … List of incubations in different states. We’ll discuss in a bit
- … Considering looking at Interop 2023, there may be things we want to propose
- Michal: 2023 effort started
- … Goals are to focus on WPT and driving towards interop in various areas
- … surveys, usage and bugs were the input
- … timeline to propose things
- … Might consider propose, as there’s demand for the performance work we do, and we have bugs
- … Focus to take interop past that finish line
- … Another reason is to signal to the community that’s focused on this, that webperf is part of the platform
- … wanted to think if it’s a good idea
- Nic: Thoughts on the charter?
- Alex: Last time we explicitly mentioned the added scope. Is there added scope since last charter?
- Nic: Event Timing and LCP
- Alex: 3 themes, one is measurement. Can we change it to be privacy preserving measurement?
- Nic: We talk about privacy in the charter. Haven’t reviewed it recently.
- Michal: No concerns about it
- Alex: Trying to suggest that as the PING noted, the privacy of the web needs moving, and a group that focuses on measurement is moving in the wrong direction
- Michal: There’s a tradeoff here
- Yoav: something concrete behind this?
- Alex: Steer feature proposals towards anonymity, which is more likely to gain consensus
- Olli: Mozilla agrees with this
- Lucas: That’s literally the name of an IETF WG. How much overlap is there? Some of the use cases there is for Firefox telemetry to anonymize the information for browser telemetry.
- … Maybe they are solving all the problems there.
- Alex: Wasn’t aware of that
- Lucas: know some of the folks. Can put people in touch
- … Asked about the RUM stuff Cloudflare is doing.
- … As a larger group of people we can talk about these things
- Yoav: Please put us in touch!
- Michal: You asked about Paint Timing, LCP and Element Timing. Event Timing builds on top of Paint Timing and Element Timing
- … PaintTiming should be its own spec, define the infra.
- … Then LCP and Element Timing define when you expose those
- … may not make sense
- Yoav: Should we bring over Element Timing? Tied at the hip to LCP
- Nic: RE LayoutInstability, we had a presentation about the implementation complexities. Not sure it helped. Would it be a good time now to bring it out of incubation?
- Sean: Our position is the same as last time. May have actual difficulties to implement. Neutral opinion on the API in general.
- Michal: Element Timing would be great to merge part into Paint Timing and part into ElementTiming
- Sean: What would the name be if we merge LCP and ElementTiming?
- Michal: need to figure out
- … Scheduling APIs would be great to adopt. rIC is not enough
- Scott: Merging those makes sense. Wonder about Mozilla’s opinions
- Olli: have an implementation for postTask. Not sure what’s the benefits of merging them. Both integrate with the HTML specs.
- … Not yet shipping postTask
- Yoav: Interest in adopting to the WG?
- Olli: I think both should go into the HTML spec
- Yoav: Something to consider for rechartering
- … Scott - interest in moving things to HTML?
- Scott: Can take that on
- Alex: Layout instability - current position is opposed, but haven’t been updated recently, so maybe issues were resolved
- … concerned about difficulty of implementation
- … animations and scrolling aren’t handled well
- … position fixed and things that happen because of user interaction
- … Lots of room for improvement before we’d support it but we can discuss
- … biggest thing is that the bookkeeping is burdensome
- … Discussing it makes sense
Sustainability and WebPerf - Yoav
Minutes:
- Yoav: Bring some ideas to the group to see what we think
- ... The world is literally burning.. where I live summer was significantly warmer…
- … it seems computing is somewhere between 2-4% overall co2 emissions
- … I suspect it is closer to 4% and that the web is sa sizeable chunk of that
- ... Native apps are there, but web is driving a lot of traffic
- ... Split of CO2 emissions seems to be
.webp)
- 20% are client-side usage
- 16% for network
- 45% for device manufacturing
- 19% for data centers
- … From a web perspective, web performance perspective… there is a tonne of alignment between making things faster, use less battery, and be more sustainable
- … On client-side consumption, as we drive to user less javascript, optimize network usage, use less battery –
- (… aside: right now we are not doing things like driving usage of dark mode…)
- … perhaps we can spin out into: great for users, but also sustainability
- … on the network side… all the work we are doing helps here (batching…)
- … device production… maybe? wishful thinking, but if we made everything faster, maybe people wouldn’t need to upgrade devices as frequently (of course, more speculative than these others)
- … for servers… we have no way of knowing how much energy, or which energy, went into producing content… could we evolve server timing to do something like this?
- … expose aggregate amortized figures… initiation voluntary, non verifiable basis, and expand from there… seems within the realm of our typical capabilities
- There is also a sustainable web CG
- … currently discussion what to focus on… we could connect and collaborate on the above
- Let’s chit-chat.
- Colin: At a macro-level, we would like to participate in this
- ... How do we get feedback to developers on their cost, in aggregate
- ... shoesbycolin.com causes so many KWH per request, some feedback mechanism
- ... Challenge is collecting that in a privacy-preserving way?
- ... Great place here, faster things are, tightly correlated with reducing energy consumption
- ... How do we collect that data and feed it back to the user?
- ... Is there a meaningful metric to expose to an average user?
- ... What can they do with a metric like mwHours? What action?
- Yoav: Potentially more useful to services and developers than to end-users?
- Colin: Useful for consumers, analogy w/ electric car company. Comparing miles driven and how much they'd save vs. gas.
- ... I struggle with what metric they can compare to others
- Ian: Users already get this on native apps, but the only thing you can choose to do is use it less
- Colin: People just complain about it more, look how much battery it's using
- Pat: Main point is a lot of the potentially wasteful work we may be doing in pre-* (load/fetch/etc), maybe weave something into the specs about hit rates, when they're doing things wastefully
- ... Not sure impact is visible on client side
- ... Might use more back-end resources, that seems to be the main point we can have some impact
- Colin: I like that, combining with Reporting API, e.g. on preloading things that are below the fold
- Yoav: On prerender/prefetches/etc you never used
- ... Tied to server-side costs, that would incentivize hosting providers to ensure costs are accurate
- ... Report to themselves or developers what are the related costs
- ... Or CO2 emissions
- Colin: Even just bytes downloaded
- Olli: Though Reporting API is an overhead
- Ian: We do try to aggregate reports, e.g. radio is only woken up once
- Nolan: Worth calling out there's Jevons paradox here, request being 10% faster that might just have people consume 10% more content
- ... Might be worthwhile getting some numbers/estimates here
- Olli: Low-level, e.g. with Layout Instability, overhead in measurement
- ... Need to think about with algorithms we implement
- Barry: But that needs to be compared to how it can find problems triggering more layout work
- Olli: UserTiming examples with over-usage
- ... e.g. FB was in horribly slow with thousands of marks
- Yoav: We're already incentivized to solve, I think that for adding Layout Instability to Chromium, it needs to pass performance bots. Incentivized to make as cheap as possible
- Olli: We need to also think about sustainability
- Yoav: Are there cases where they're not 1:1?
- ... Or CPU use is decoupled from battery use
- Michal: I know FB removed a lot of things, because they were incentivized to make it faster
- Olli: Algorithm still requires it?
- Yoav: The problem was they enabled a very large buffer, algorithm requires sorting every time you get the entries
- Olli: APIs that don't allow developers to make those mistakes
- Nolan: One situation I commonly see, if you have a long-running page, the developer is queuing up constants setIntervals or rAF, they're always doing tasks per-frame.
- ... But it's constantly chewing up CPU
- ... Only way they know is by looking at Task Manager and noticing
- ... Neat to capture that
- Michal: It is possible, the easiest thing to measure right now is main-thread CPU performance client-side, so classes of applications choose to focus energy there.
- ... On the other hand, classes of applications with huge server payload
- ... Really hard to get that right
- ... And what types of energy
- ... Worried about getting it wrong and incentives that drives
- ... Shame involved because labels applied
- ... You've pushed things in a certain direction
- ... Tough problem because it overlaps with work we're doing
- ... Anecdote, smart thermostat, reporting on energy used, but my energy use went up because it wasn't as smart as it could be
- ... Worry about getting a half-job done quickly
- ... Something to be said for invisible hand of economics doing a more powerful job here
- Jeremy: Across devices energy use and characteristics are different
- ... Solar vs. coal-based power, impact on device use is different
- Yoav: Solar panel over head, walking around with phone, we don't care
- ... We still strive to reduce energy consumption, helps in all cases
- Jeremy: Tradeoffs vs. user experience or higher-quality video, tradeoff is different based on the cost
- Barry: Conversation vs. charter, would we add sustainability to the charter
- ... Metrics should be built with that in mind
- Yoav: I would be favorable, no concrete deliverables but it would make sense to add that alignment to the charter itself
- Michal: To take credit for the work we're doing
- Yoav: And to spin up new work in this area
- ... Conversations about value vs. cost
- Eric: Native platforms do this, XCode and Apple have some diagnostics
- ... It's all unit-less
- ... Gauge low/medium/high
- ... Somehow meant to flag high energy usage to developers
- ... More we can learn from what they're doing, how effective that is
- Tim: Perspective from synthetic tooling side of things
- ... WebPagetest issue around exposing energy use, the most popular issue of all time on WPT repo
- ... Also hearing a lot from companies in Europe who want some level of this reporting built into the tool and reports
- ... Chief concerns are most of what is out there are proxy metrics / approximations
- ... Even high/medium/low, very fuzzy proxy
- ... We want to figure out right balance giving something for people to go off, which has a strong enough connection to reality
- ... Actionability of those insights
- ... Report on certain things not being used
- ... Those are appealing, tangible
- ... We can tell developers to do these X things
- ... Tell energy use in loading page
- ... Those things are appealing from reporting perspective
- ... Lighthouse has interest, Edge, problem is everyone has is to solve this, do something
- ... Some many ways of measuring are too fuzzy
- Eric: One actionable thing, notification from browser if tabs are using too much energy
- ... If that could be sent to the Reporting API in that circumstance
- Yoav: What I'm hearing is general support for moving forward on alignment
- ... WPT issue example is an encouraging one
- ... Could have benefitted from some sort of structured server reporting
- ... Thanks!
Forward Referencing Data-URIs - Amiya
Minutes:
- Amiya:(Microsoft)
- Early stage idea… a couple weeks ago we published a blogpost on perf techniques from Bing.com…
- …was discussing with Patrick Meenan
- …Forward-Referencing Data-URI’s is a way for declaratively reference payload that appear later in a document
- Use cases:
- Page with highly dynamic content (not finante we set of images)
- Images are lightweight, small, desire to load inline with Data-URI (this is a good idea, lets say)
- Caching is not beneficial, so send it down inline with the response
- Large catalog of images, many rendering options (sizes, etc), so it makes no sense to pre-compute all Data-URI for every possible version of each image… must be truly dynamic
- HTML can be delivered using streaming/chunking, chunk transfer encoding etc
- Example: search engine results page, esp for images, but other categories exist
- <Demo of “naive approach”>
- On the server side, you’re blocking on each image
- End up with inefficient waterfall
- To work around it, you’d pipeline parallel background calls and put the base64 markup at the bottom of your page
- You put placeholders inline with the HTML (say a 1x1 image thats like 40 bytes), then insert the base64 images at the bottom of the HTML and use inline JS to replace the assets
- … its ok, but its a race condition, may paint without images injected, don't look great, and you rely on inline JS for functionality
- Idea: what if we could in HTML natively accomplish something similar?
- …what if we could generate the base64 payload async, pass them in after-the-fact, but full in the forward reference directly
- STRAWMAN: data:forwardref;red-square in the src, then <datauri id=”red-square”> later down
- Advantages: can eliminate the need for this inline JS
- Also remove places where there’s repetitive data URIs
- Avoid the need to decode them repeatedly
- Still pretty early stage, but thought it’d be good to get feedback
- Started looking through the spec, haven’t been updated since 1998
- Olli: Data URIs are defined in Fetch and URL specs in the WHATWG, https://fetch.spec.whatwg.org/#data-urls
- Jeremy: Skeptical on how better is this than the JS approach, but this doesn’t seem data URI specific
- … could define an unresolved URL that are similarly useful for http URLs
- Ian: URL promise?
- Jeremy: that’s what it basically is
- Eric: createOject URL method that could represent a resource that can be referenced multiple times could solve some of the repetition issues
- … My mental model is that it might work
- Pat: Would help the repeated case, but not the case of unique images
- Nic: Usable for transparent 1x1 pixel?
- Pat: Sizes are low, so no huge saving
- … A browser optimization could be to keep the decoded versions in case
- Alex: For this use case, you’re worried about encoding on the server
- … I’m worried about data URL decoding on the client
- … Can we just emit the binary instead of base64 and decode it?
- Jeremy: sounds like a mess? (HTML parser, charsets, etc)
- Barry: sounds like an SVG xlink where you can reference an image later on? Have you looked into that? Not sure if that works forward
- Amiya: haven’t tried it, the use case was jpegs which could be wrapped
- Michal: Can you do that with web components where you have a custom component that references another component further down the page. May be more complicated than the JS solution
- … One concern was around intermediate paints
- Amiya: doesn’t get rid of those paints for sure
- Nolan: Liked using CreateObjectURL as it avoid the base64 decoding issues. Can be put into indexDB. You can get a readable stream from the blob but can’t attach a writable stream to it. Would that solve your use case
- Amiya: primary use case is for remote images
- Pat: You would need the data to be encoded in HTML, so not better than inlining TODO
- … If it was a separate element, we could do a lot of the heavy lifting outside the main thread, as part of the lookahead tokenizer
- … Or we could look into web bundles in a different container format, which will have internal URI references for these images that are referenced from the HTML
- … Send the HTML document to the parser, and send the resources to another thread
- jbroman: In H2 and beyond you have an ability to stream those separately at the transport layer. Isn't that what you want?
- Pat: It may not be the same server serving that content. Having the content be able to control where the chunking happens can be beneficial.
- Yoav: This does sound like a potential use case for web bundles (i.e. navigation to a web bundle)
- Pat: almost like a half-signed exchange
- Yoav: you don't need the signing
- Jeremy: Isn’t there a CBOR index at the beginning
- Pat: Not sure about the bundling format, do you need the resource in its entirety?
- Yoav: Maybe we want to send some parts of the html, then those resources, then other parts. DOnt' believe it supports it now, but maybe it could
- Jeremy: if you don't want interleaving, you could use existing multipart mime encoding.
- Pat: the example ws a truncated version of a search results page where there’s a lot of below the fold data
- … Significant main thread overhead. You can do this with script today. Is there enough benefit to provide a general case solution?
- Yoav: numbers on benefits as well as how many other sites would use it?
- Pat: there’s a general problem of incorporating resources into HTML. (e.g. fonts)
- Nic: You might be able to look at HTTPArchive to see how big of a problem this is
- Michal: Is it possible that this is a problem people are already solving? There could be some framework for dynamically generating images that’s not using data URIs at all
- Yoav: We could get numbers to estimate impact


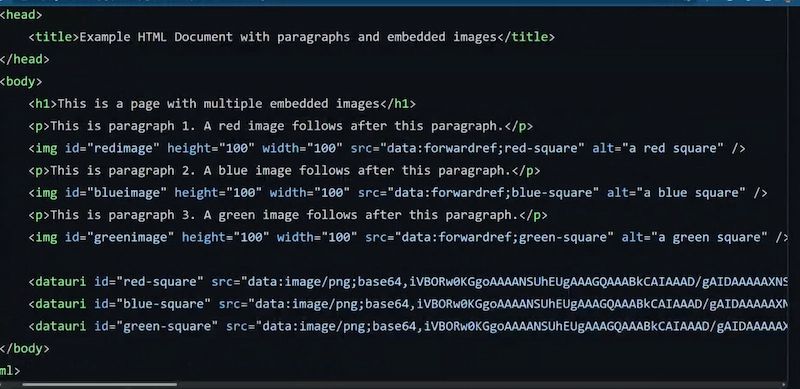
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Performance beyond the browser - Lucas
Minutes:
- Lucas: click-baity title.
- … Mark Nottigham talked early in the week about the CDN timing
- … two aspects - how much do we care about the performance of things that are in the critical path of the request
- … the performance timeline has all these checkpoints, but there’s a big gap between the timestamps
- … as part of that opaque blob, it could be a CDN that’s sitting on a cache server
- … The other part is the use of web platform APIs in different places
- James Snell: Work on the runtime team. Working on a new CG called WinterCG (interoperability)
- … bring together developers of Node, Deno, Bun - ensuring we’re maintaining consistency with the browser as much as possible
- … Trying to work with existing venues, not create new standards
- … the performance APIs are implemented in Node and Deno
- … For workers in cloudflare no implementations because of Spectre
- … But still want to collect that timing information and be able to use it outside of the worker
- … so can only provide partial implementation for e.g. user timing marks and measures
- … Also freeze time as the worker’s running Date.now() doesn’t advance
- … Any amount of sync code running doesn’t advance time
- … Constraints on how the performance APIs can be implemented
- … Node and deno don’t have similar spectre concerns, but deno deploy does
- … Haven’t done anything on what needs to be standardized
- … The one thing we recently been asked to look at is resource timing
- … There’s no agreement on how non-browser platforms should implement these things
- … No compat between different platform
- Lucas: is anyone in a similar env where this matters?
- … How much forward collaboration can be between this group and the CG?
- Michal: Excited about WinterCG. Why are there different requirements in those deployment platforms?
- James: variance is based on use cases. E.g. workers are significantly more constrained.
- … edge workers are always used in a particular way
- … Node provides timers and lets users constrain it from there
- … workers are multi-tenant, have to isolate it
- … Deno is interesting because they’re doing both
- … Have to enable a permission to get high resolution timing
- … Perf APIs without the permission give you limited resolution
- Michal: moving to a world where a single application is running on the server, edge and client makes sense to me.
- … makes sense for this to be in scope
- … Are there any crisp suggestions/concerns?
- James: For things like the performance API - spec on how you get the data there, and how you query the data
- … In workers, we want the marks but don’t want workers to be able to query the data
- Michal: Reminds me of the aggregate reporting conversations, but this is different.
- James: debate on how much delay/aggregation you’d actually need
- … Some discussion to delay it by a full day, but that’s a bad dev experience
- Michal: Would the timings be available to the runtime or in a dashboard?
- James: Developers run in our env, we want to give them information but not directly as it can reveal information
- … Would be aggregated information over an entire region at the lowest resolution
- Michal: Reminds me of individual event handled in the page vs. periodic worker events
- Pat: Challenges similar to CrUX, where you get a full histogram, but can’t nail down any one specific timing
- James: have devs be able to performance.mark(). Want to be compliant with the spec, and need to define that subset ourselves
- Nic: Akamai may want to engage with the CG
- James: Calls every two weeks. Next call is about Fetch, but we can schedule a call about performance APIs
- Yoav: We had a Node developer that came in independently for user-timing, and they wanted one change
- ... We already had some interaction from Node community
- ... On one hand we should have this conversation
- ... Figure out how this fits, how should non-browser implementations fit into how we think about these APIs
- ... Subsetting the spec into what you need to query and measure and making your life easy from an editorial perspective, sounds very simple to do
- ... Just so you can say you're complying with one part vs. another
- ... Real questions arise when you need to take into consideration what the processing model should be
- ... Question we'll have to deal with on a case-by-case basis
- ... Principled approach, to see what we come up with in terms of how can we fit those different environments and constraints under a processing model roof
- James: I did initial implementation of performance.mark() and measure() in node
- ... After a month of release, I think we have a memory leak
- ... They were adding marks and measures, forgetting to clear them
- ... Running in server environment
- ... Spec says recorded and kept around in memory until they're cleared
- ... I updated implementation to not persist unless you had a performance observer
- ... Internal table of marks, but JS objects go away
- ... We're now accumulating those, and requires to clear them
- ... Major footgun
- Yoav: We settled on namespaces being an easy solution to clearing those resources
- ... Demand was to create a buffer-clearing API which would be something that is a different type of footgun
- ... Different providers clearing buffers accidentally or not from others
- Michal: Specifics of this case less interesting
- ... But we make expectations of the environment
- ... Feedback early is helpful
- ... Even with aggregate reporting, we made assumptions, record first and aggregate last
- ... In your case you may aggregate first and report later
- ... We should craft wording that is flexible for either
- Yoav: Back to example of UserTiming, are we interested in defining a method that clears the buffer but isn't implemented in browsers
- ... Browsers don't implement but others might
- Michal: Case-by-case basis
- James: Even if not clearing, but some room for constraint, like limiting the buffer size
- Yoav: That buffer is already constrained, the environment can bump up that buffer
- ... Maybe limits to how much developers can bump up buffer
- James: Wanted to start the conversation
- ... As convo's around some of these APIs come up, using WinterCG as a forum to get some ideas and feedback would be welcome
- ... We're all there and talking, will give you our opinion
- Yoav: And likewise, the inverse
- ... We similarly have bi-weekly calls and feel free to bring issues to the group
- ... We'll happily discuss
- Lucas: A few things beyond the browser, external to the page load
- ... Would be better if we can improve
- ... A lot of my time spent on H/2 and H/3
- ... Some folks have setup tests or characterize behavior
- ... You can export HAR file, or beacon back some information too
- ... But the abstraction layer doesn't give you much insight into this
- ... Two things, WPT can give insight by capturing netlog
- ... I've done a capture and tried to analyze it, but it's hard to use
- ... HAR files have a similar thing, not a standard spec but just a de-facto
- ... Second question, sometimes failures just happen because there's a network-layer issue
- ... We have something like NEL that can help w/ those things
- ... But some events are not categorized enough
- ... Troubleshooting technique is opening in cURL and seeing the failure
- ... Population of people that are able to get this information back, you lose some insight into what's happening to a particular subpopulation of people
- Yoav: HAR used to be a spec this WG worked on
- ... That's no longer the case
- Patrick: Spec'd once, 10-15 years ago, wasn't flexible enough
- ... DNS, socket, etc times all deltas, you can't have preconnect/etc
- ... What WPT does is use proprietary fields to convey more information
- ... Something like qlog or something more modern might be more useful
- ... Or just a radically newer version of HAR
- ... Messages going into netlog are just whatever the developer wanted to write
- Lucas: qlog is in IETF in QUIC WG, schema
- ... There are some things only endpoints know, qlog is like netlog, feasible but not in scope of immediate work
- ... We're not looking to replace anything outright
- ... Troubleshoot with HAR
- ... Is there interest, I didn't realize the constraints of HAR
- ... I'd be happy to contribute
- Yoav: Seems related, but very different from the rest of the things the group works on
- ... We're geared toward field measurements, and lab are related but different
- ... Don't know if there's appetite to expand this into something that's covered by WG
- ... Or spin into a CG
- ... If you're interested in working on it, I'm happy to help with the right venue for this
- ... Main reason HAR hasn't been worked on, isn't lack of venue, just lack of someone interested in work
- ... NEL is currently a WICG spec, Ian is editor/owner for the feature
- ... What's the best way to communicate new feature requests
- Ian: Raise issues in NEL repo
- Lucas: Not just the spec, there's real use-cases I can do w/ that information
- ... It's not one error code, 10 different cases underneath it
- ... Past I've heard there's different teams that own these things
- ... Hard to understand how to bubble up information
- Yoav: File an issue, list use case, we can take it from there
- Patrick: I can connect w/ dev tools on Chrome side, they have a forum for discussing interop
Task Attribution - Yoav
Minutes:
- Yoav: <Saving the best for last>
- …Task Attribution is some infrastructure I built for Chromium which opens up interesting opportunities
- …Theme: “why can’t we have things?”
- …for soft-navigations, why can't we track when a click triggers a change…
- … long task attribution
- … resource timing initiator
- … cross-task prioritization
- …can be expensive to do these things at runtime
- …but I really really wanted to have soft navigation heuristics, and the other things seemed useful too, so I went and built it
- Soft navs heuristics… right now Chrome as a browser collects data on the speed on navigation, but we do not know what happens inside of SPAs… SPA community claims for the last 10 years that SPAs are faster, and others claim the opposite.. no one really knows.. we want to know!
- …With these changes we can mark SPA navigation and re-fire FCP and LCP, at least inside Chrome with its own metrics.
- …want to also expose to RUM the time point of the spa navigation to be cross-reference with their own metrics to compare.
- Long Task Attribution - we shipped long tasks… developers feedback was that it’s great to know when the main thread is busy, but it's hard to act on this data in the field without attribution – e.g. which 3p was the cause?
- ... with Task attribution, at the very least we can tie to URL of the 3p resource that caused the long task
- Resource TIming initiator info - could build up dependency trees… this resource cued up these other resources (all the way down) so we can report totals for the initiator resource
- … As another example, for LCP resource, all the dependencies
- Cross-task prioritization - …right now we can prioritize a script, but what about things it itself fetches? Would be nice to trickle down
- …same for postTask, can prioritize the task, but what about things it queues? WOuld be good to propagate all this
- …i.e. ensure a whole set of JS always runs in low or high priority
- Cross-Task privacy protection
- e.g. prevent access to high-entropy API from certain scripts (and things it triggers)
- …can better keep track of entropy accessed and provide accountability
- How does it work?
- …Each new Task creates a TaskScope
- …If a new Task is created while a TaskScope is active, it is set as a parent and replaced
- …Any new promises created in v8, they have an ancestry chain??
- Currently this is just an implementation detail.. would be good to standardize as a platform concept.
- …at the moment no clear use case to directly expose this to the web, but either specs maybe should make reference to it?
- Q&A
- Olli: Does Chrome use this for its own purposes? e.g. prioritization?
- Yoav: Not at the moment, but I would love to see this direction. Right now, only SPA heuristics builds on it, beginning to experiment
- Olli: I would love more details… Gecko has something similar, TaskTracer? But it wasn’t very used? We also have a way to track task dependencies, but it also seems very ununed… right now very low-level… so we don’t have much experience
- Yoav: This is very much tired to JS tasks, not to other (internal) tasks
- Olli: JS tasks are just tasks, in Gecko JS tasks are the same, but yes, we do have others
- Yoav: Not yet, hoping to gather that with these first origin trials (Soft nav heuristics)
- …need to experiment for a while before exposing.
- …I’m curious to learn more about task tracer
- Olli: it was used for perf profiling type things… but then out actual profiler became so much better that we stopped using it.
- Ian: are we concerned about fundamental limits about what we cannot attribute?
- … running things through eval(), moving things across scopes?
- Jeremy: I agree, for some applications, where its just heuristics, it seems the case is fine– but for privacy related features, this seems out of scope
- Yoav: I would love to see a list of these cases, WPT would be even better
- … For soft-nav reporting we don’t need to think defensively, but for other use cases we do
- … so far we have been able to fix holes
- Jeremy: One example is modifying properties of Object.prototype (e.g. getter/setter) so that other scripts are calling it and exfiltrate the data for the offending script
- Yoav: Hmmm, now we are not sure who is the initiator… but it's still script running in the same task…
- Jeremy: Right, but now I’ve found a way to hook onto and run code on behalf of another task chain…
- Ian: Maybe it's more important to track the initiator originally, vs correctly attribute each and every part of code running in the chain?
- Michal: To follow up on Ian's point on initiator vs code in the chain
- ... Can we not find out?
- Ian: For navigation, something initiated this code, it's a single task
- ... Who started it, kicked it off?
- Yoav: Concept of the initiator and registrant for events, for UserTiming you could have one task that registers UserTiming and another that triggers
- ... Different tasks and different parents
- ... Maintain two data-structures that are linked to both
- ... Code polluters could be another potential issue
- ... I think there's a way to track those, but we'll have to go through V8
- Nolan: If this is possible, it might be useful to expose JS API
- ... Some JS frameworks have error boundary, error caught in render function in React
- ... It does not work with things like setTimeout or rAF
- ... Could implement something on top of this to work around that
- ... Angular Zones, async tasks, logic after task ran
- ... Towards performance side of things, we're trying to do component timing
- ... All parts of lifecycle to that component, but if it's using rAF you can lose track
- Michal: I don't know enough about Zones, I thought one use-cases was to have a zone/scoped context
- ... I wonder if Task Attribution if it could enable that context, features we can't do today
- ... Scheduling API has the context?
- ... Enable a feature like that that sometimes pops up as useful
- Scott: I've spoken with ANgular folks in context of Scheduling APIs
- ... Evolved in propagating priority across promise boundaries
- ... For yielding
- ... Angular folks are interested, can't solve async/await
- ... Lot of overlap in use-cases
- Nic: If this was available from a RUM perspective… benefits would be…
- …We do a lot of work in RUM to implement SPA… we have to have MutationObservers active etc, and we would really prefer not to have to do that
- …plenty of work to track how resources chains are affected
- …to the extent that some of this infra is exposed to the platform, we could do a lot less and depend on the browser to do a lot more for us.
- Yoav: Indeed the idea is to enable those use cases
- Colin: In a macro view, I’m not sure how much value this has… but I do see value in enabling this granular view for headless / CI contexts especially… in this case we would love more detailed view into how these things relate
- … if there is a concern about exposing too much data, e.g. collecting in the wild, maybe there are concerns, but we could be more high-resolution in the lab
- Yoav: Exposing traces?
- Colin: sure, or behind a feature flag
- Yoav: We have implementations that are not exposed yet
- Colin: The real value is when it becomes cross-platform
- Michal: For SPA heuristics, detecting the SPA transition
- ... Maybe user-interaction or history.replaceState() or DOM manipulation
- ... Can happen in different tasks but happen together
- ... Link together
- ... After SPA nav starts, is Task Attribution useful?
- ... A whole bunch of performance metrics would build on top of it
- Yoav: If we detected Soft Nav, do we count LCP from scratch, or only descendent paints
- ... My initial thinking was to just count from scratch
- ... Might be interesting to play around with descendent paints
- ... At paint time we don't know which DOM manipulation triggered the paint
- ... Require a bunch of extra hoops to jump through that
- Michal: With event timing, we also have these questions, initial paint is easier
- Ian: We do want to start annotating performance entry events with navigationId, SPA to be part of that
- ... Segment CLS events, but whether we trigger another LCP is another question
- ... For ResourceTiming we're not going to only correlate the ID with resources that are a direct result of this task
- ... Not plan unless we'll have to
- Michal: When it comes to paints we have concepts like was it contentful
- ... Maybe you have initiators that contributed to generating the paint
- Michal: Back to charter conversation
- ... Colin raised the question of tracing
- ... More valuable if it's supported across implementers
- ... Earlier we had HAR w/ WinterCG folks
- ... How much is scope outside of PerfTimeline in scope of WebPerf WG
- Yoav: Good question
- ... I will need to think about it and see
- ... Originally it was in scope, then it was removed
- ... Look into archaeology why that happened
- ... Maybe it's in scope but different work stream
- ... Risk of splitting audience
- ... Could fit into another group that we work closely with but is separate
- ... Will have to think about it
- Colin: Maybe fit into WebDriver, care about performance side of getting data into my CI pipelines
- ... Privacy or noise concerns we don't want to enable in the wild
- Ian: Browser testing + tools WG that may be interested
- Michal: Concertetly WebKit doesn't expose LCP, but can expose those concepts
- Alex: Things like that we have in inspector tools that we don't expose to web
- Yoav: Could expose in traces that lab tools can use