Participants
Sia Karamalegos, Pat Meenan, Giacomo Zecchini, Mike Henniger, Amiya Gupta, Nic Jansma, Ian Clelland, Alex N Jose, Katie Sylor-Miller, Aoyuan Zou, Michal Mocny, Abhishek Ghosh, Alex Christensen, Sean Feng, Sohom Datta, Yoav Weiss, Hao Liu,
Admin
- Nic: Next meeting April 27th - 8am PT
- …In the process of extending the charter
- …Working through the existing charter and updating it
- …Filed issues
- …If you’re interested in the charter’s future and have feedback, hop on and discuss
Minutes
Cross-origin timeline support - Ian
- Ian: A couple of months since we’ve discussed this
- … Identified a few privacy issues with the original proposal and wanted to provide an alternative shape
- … Want to have a way to share entries from an embedded frame to its parent
- … Want perfobservers to intercept that, existing code should work
- … Original proposal had an explicit request from the parent and opt-in from child
- … Then the delivery from child to parent was implicit
- … Some issues:
- … Child frames need more control over what’s sent - omit info, restrict types, may need different conditions for different embedding origins
- … New approach - explicit request from the parent frame, child calls an explicit API to do that
- Simple example
- More complex example
- … Want feedback on this
- Nic: Like the idea of giving child frames the flexibility. Missing the ease of opting in for the child frames.
- … Easier to do automatically if child frames don’t need that level of control
- … possible to have both?
- Ian: The existing header we proposed would not be compatible with this. We could add a “please send everything unfiltered” if we wanted that?
- Nic: What’s the difference?
- Ian: The document policy would have a very different meaning
- Nic: You probably want to do one or the other
- … that’s my only thought, want to make it for both sides to participate. Help with adoption
- Sean: What happens with nested iframes?
- Ian: Entries delivered all the way to the root and any origin that matches would get the entries
- Sean: What if I want to expose entries to my parent but not my parent’s parent?
- Ian: Haven’t identified this as a use case
- Sean: For COEP credentialless, I would assume that whoever receives the child iframe needs to explicitly specify the origin
- Ian: Would the entry need to explicitly passed up the chain?
- … Use case is RUM providers where the top-level frame wants to get all the data from embedded frame. Comment on the issue
- Alex: Similar to Sean - if I’m an iframe that includes lots of iframes, there needs to be a way to prevent children from broadcasting. Implementation of that with site isolation would involve a lot of hops
- Ian: Slightly different. A child wants to limit vs. a parent wants to limit
- … We should explore that at a GH issue
- Nic: related to that - wouldn’t you need to filter out everything broadcast below you to prevent it from being broadcast to your parent?
- Ian: The other thing missing is we’re looking into adding a source attribute to the entries to make it clear where they came from
- Nic: Code sample would result in both grandchild and child broadcasting entries to the top
- … RUM providers would need to dedup that info. A header based mechanism may enable the browser to do the deduping
- Ian: Could also restrict this so that only perf entries generated by this frame can be broadcast. But would need to look at that more carefully
- … Hope to update the GH issue and move more discussion there



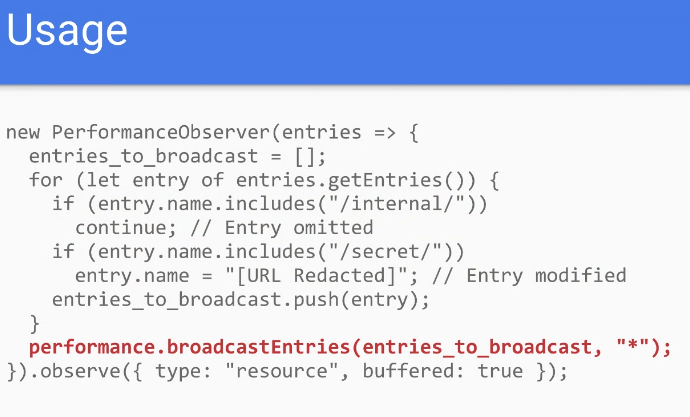
Adding HTTP method to ResourceTiming API structure - Sohom
- Sohom: the general idea is - was working on a hobby project and POSTs was taking more time than GETs
- … Would’ve helped to get this data split on HTTP method
- … Would make it easier to debug issues
- … I think it can be added as a field on Resource Timing entries
- … Are there cases where we would want to hide the request method?
- … Given that the browser is generating the request
- Nic: Would be useful for segmenting REST API loads
- … Also for form URLs, could have two different modes for these pages that can be segmented
- … No opinions around the security implications
- … Thoughts? Concerns?
- Yoav: Haven't run it past security folks yet
- ... Risk is for cross-origin leaks? Failing to think of scenarios where the HTTP method would expose something particular about cross-origin resources
- ... Need to run it by folks who know those threats, I don't see any immediate problems with it
- Alex: Definitely makes it easy to turn on, expose everything and accidentally realize you've exposed something you didn't mean to. There is a concern.
- Yoav: Turning it on at browser level and realize you've got a new X-O leak?
- Alex: I was actually thinking of something else, ignore that
- Amiya: GET vs. POST, there's a size limit. Could be used to identify if a user is signed in. Someone not signed in using GET vs. not a POST.
- Yoav: Would be part of URL
- Sohom: Request from page itself, considered by the page. Not decided by the browser automatically.
- Yoav: If done by Fetch(), top-level page could intercept.
- Nic: Would this be covered behind cross-origin or TAO?
- Yoav: Need to have threat model aligned to opt-in, not sure we currently have one
- ... One question, what happens with preflights?
- ... We would want request method to be actual method and not OPTIONS
- ... For redirects as well, which do we want? The last one
- ... Some cases where there are hops
- Sohom: Wouldn't you want the first one? The one the website is sending out
- Yoav: We have an open issue to expose redirects more clearly, open for a long while
- ... Wouldn't block on that. Worthwhile to think through what we'd want to represent here, which request.
- Nic: Next steps is a request to ask browser vendors to review from a security/privacy angle?
- Yoav: Sohom, in terms of implementation is this something you're considering tackling?
- Sohom: Yes
- Yoav: On Chromium side, best way is to send to an intent-to-prototype to get in their queues
- ... Alex, Sean - filing for positions to get your folks' eyes on it? (webkit, mozilla)
- Sean: Yes
- Alex: Yes
Adding resource discovery time to ResourceTiming API structure - Giacomo
- Giacomo: Related to the other issue. This is about exposing the discovery time
- … Would be useful to have it in RT
- … use case - late discovery of LCP elements
- … From a security perspective, this may fit with other cross origin data
- Nic: This is for the discovery time of the pre-parser/parser? How different is that from the start time?
- … Isn’t the start time when the browsers kicks off the work to fetch it?
- Yoav: Limits in browser's resource prioritization, difference between discovery time and actual start time
- ... In HTTP1 we had a certain number of connections and limits
- ... Allows you to say you provided URL to browser, but it's not ready to fetch yet
- ...
- Nic: We’re getting blocking time today, but there are other scenarios where the browser discovers the resource but doesn’t act on it? Sounds good to expose
- Yoav: There's also some work happening to better collect this data in Chrome internally, so it could shed some light on the usefulness of data. Facility exposing to performance entries.
- ... Is this data useful for any random resource, or just LCP?
- Ian: Wondering where or if this discovery time is specified. How does this play with media dependent image lookups?
- Yoav: Good question. I think a lot of the heuristics that browsers employ (that create that gap) are not specified, and finding a way to specify the discovery timestamp.
- ... e.g. if by preload scanner, we'd need to define what the preload scanner is
- ... that's a lot of work, and a not a lot of motivation behind that
- Pat: Beginning of some specs for preload scanner in HTML spec. I'd caution against discovery specifically, where you discover it well ahead of when you intend to fetch it vs. when you do fetch it.
- Yoav: If LCP is lazy-loaded, you want to specify that the browser knew about it early, and didn't do anything about it because you lazy-loaded it. Useful?
- Pat: I guess so? Can't tell the difference between lower-in-the-viewport images etc. Just knowing there's a gap can be useful.
- ... When images get deferred or contention around connection pools and things like that.
- ... In extreme case there's per-connection limits (e.g. H/2 100), have clients waiting for slots to free up as well
- ... Useful to add to WPT to know when a resource is discovered vs. fetch
- Nic: referred to in many blog posts
- Giacomo: the idea started from using WPT, and want this in RUM data as well
- …Need business case to know if we need to invest dev time in improving LCP discovery
- … If browsers have heuristics for non-image files, this will be useful for other resources as well
- … From a user point of view, I don’t know browser heuristics and want to use it across browsers
- Pat: Useful to know what problem you’re trying to solve. All sorts of weird cases where you can get queueing and scheduling delays for iframes, etc
- … As far as the spec goes, as soon as the fetch is created, that’s the timestamp
- Yoav: Thinking through implementation details, it maps out
- Pat: In Chrome, as soon as Fetch is created that's the start of the fetch
- ... Doesn't account for lazy-load case if you do want the lazy-load gap discovery
- Yoav: To Nic's point, wouldn't the Fetch timestamp be the same as the fetchStart timestamp that we currently have?
- ... I don't remember off the top of my head
- ... See if those are meaningfully different
- ... From an implementation perspective, the points where we grab those timestamps, they happen before fetchStart
- Pat: Way the spec is, there are things before fetchStart for worker stuff, as far as Chrome is concerned after it's created and scheduled
- Nic: There's also the startTime
- Pat: Probably the same as what we're talking about here
- Barry: All we do there is we look at difference between TTFB and fetchStart and that's what we're saying is the discoverable delay
- ... Doesn't count for lazy-loaded, just the earliest possible time is first bytes received
- ... Don't know if that's sufficient
- Pat: I don't think that contains Chrome's resource scheduler time
- ... fetchStart itself is after it's gone through the worker layer and some level of redirect stuff the network's aware of.
- ... Not sure web-vitals captures that time
- Barry: Is measuring that sufficient?
- Pat: Looking for the time between the time the HTML was parsed and the time the resource was scheduled to be fetched. Solve this either by bumping priority or by inserting the resource to the HTML itself
- … Extra value is the same as seeing the lightbars in the WPT waterfall
- Nic: I thought startTime was the point we initiated requests on the network. Discovery time is negative to that?
- Pat: yes
- Nic: So we’d have a timestamp before the startTime that we’d want to expose. Just trying to understand how that would flow
- Yoav: negative to the resource, not the time origin
- Nic: Best steps forward?
- … Yoav mentioned some internal data being collected
- Hao: I sent out the CL for Yoav to review, and it’d land once approved
- Yoav: So a few months out to get the data