WebPerf WG @ TPAC 2023
Logistics
Where
Meliã Sevilla Hotel, Seville, Spain
When
Registering
- Register by Aug 31 for the Standard Rate (increases on Sep 1 to late/on-site rate)
- Health rules: Masks on, daily COVID tests
- All WG Members and Invited Experts can participate
- If you’re not one and want to join, ping the chairs to discuss (Yoav Weiss, Nic Jansma)
Calling in
We’ll be using the W3C zoom this year. (For the WHATWG session, we’ll be using this one)
Attendees
- Yoav Weiss (Google) - in person
- Nic Jansma (Akamai) - in person
- Michal Mocny (Google) - in person
- Sia Karamalegos (Shopify) - maybe remote
- Benjamin De Kosnik (Mozilla) - in person
- Sean Feng (Mozilla) - in person
- Barry Pollard (Google) - in person
- Andy Luhrs (Microsoft) - remote
- Jason Williams (Bloomberg) - in person
- Jeremy Roman (Google) - in person
- Patrick Meenan (Google) - remote
- Neil Craig (BBC) - will attend remotely as much as possible
- Tsuyoshi Horo (Google Chrome) - in person
- Khushal Sagar (Google) - in person
- Lucas Pardue (Cloudflare) - remote (best effort)
- Shunya Shishido (Google) - in person
- Andrew Comminos (Meta) - in person
- Lorenzo Tilve (Igalia) - in person
- Antonio Gomes (Igalia) - in person
- Andy Davies (SpeedCurve) - remote (best effort)
- Alon Kochba (Wix) - remote (best effort)
- Alex Christensen (Apple) - in person
- Ryosuke Niwa (Apple) - in person
- Kevin Babbitt (Microsoft) - remote
- Nidhi Jaju (Google) - in person
- Domenic Denicola (Google Chrome) - in person
- Leon Brocard (Fastly) - remote
- Mu-An Chiou (Ministry of Digital Affairs, Taiwan) - in person
- Tim Vereecke (Akamai) - remote (best effort)
- Noam Helfman (Microsoft) - remote (best effort)
- Mark Nottingham (Cloudflare) - in person
- Benjamin Feigel (Navy Federal) - remote
- Carine Bournez (W3C) - in person
- Ming-Ying Chung (Google) - remote
- Fergal Daly (Google) - remote
- Nathan Schloss (Meta) - in person
- Sam Weiss (Meta) - in person
- Brain Strauch (Meta) - in person
- Andrew Cominos (Meta) - in person
- Anne Van Kesteren - in person
- Aoyuan Zuo (Google) - remote
- Erik Anderson (Microsoft Edge) - in person
- ... please add your name, company (if any) and if you’re planning to attend remotely or in person!
Agenda
Times in CEST
Monday - September 11 (11:30-13:00, 14:30-16:30)
Timeslot (CEST) | Subject | POC |
11:30 | Nic, Yoav | |
12:00 | Domenic, Jeremy | |
12:30 | Fergal, Ming-Ying | |
13:00-14:30 | Lunch Break | |
14:30 | Tsuyoshi, Patrick | |
15:00 | Michal | |
15:30 | ||
16:00 |
Recordings:
Tuesday - September 12 (14:30-18:30)
Timeslot | Subject | POC |
14:30 | Yash | |
15:00 | Kenneth | |
15:30-16:00 | Break | |
16:00 | Long Animation Frames | Noam |
16:30 | ||
17:00 | Yoav, Nic | |
17:30 | Scott | |
18:00 | Crash Reporting | Andy |
Recording:
Thursday - September 14 (14:30-16:30)
Timeslot (CEST) | Subject | POC |
14:30 | Ian | |
15:00 | ||
15:30 | Michal | |
16:00 | Yoav |
Recording:
Friday - September 15 (11:30-13:00, 14:30-16:30)
Timeslot (CEST) | Subject | POC |
11:30 | Nidhi/Adam | |
12:00 | Ian | |
12:30 | Benjamin | |
13:00-14:30 | ||
14:30 | Joint meeting with WHATWG - Giralda III (-2) | |
15:00 | ||
15:30 | ||
16:00 |
Recording:
Sessions
Day 1
Intros, CEPC, agenda review, meeting goals, introspection
- Nic: Mission to provide methods to observe and improve aspects of application performance of user agent features and APIs
- … Highlights - moved preload to the HTML spec
- … new triage process =>progress on open issues
- … Rechartering is in progress. Extension ongoing
- … Proposed charter draft
- … Notable changes: EventTiming, spec unification, hoping to revitalize the primer
- … Doc around perf APIs security and privacy
- … Discussion session tomorrow at 5pm
- … New incubations
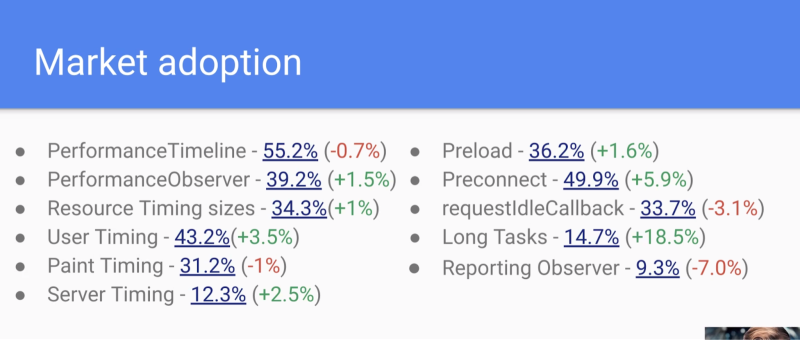
- Market adoption slide
- … Interesting changes year over year, e.g. why is long tasks up 18% and Reporting down 7%?
- … <round of intros>
- … Agenda for the week at https://bit.ly/webperf-tpac23
- … Housekeeping
- … Health rules overview: masks, tests, and stay isolated if you’re symptomatic


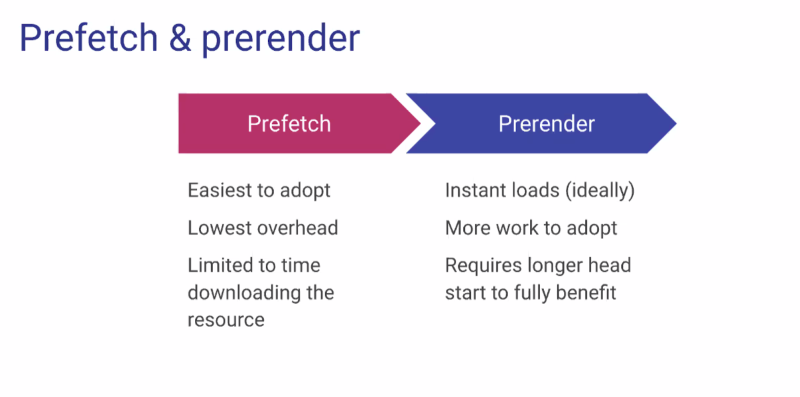
Speculative Loading (prefetch & prerender)
- Jeremy: How to make navigations go faster
- ... Page Load Time matters to users, LCP one key way we measure how long a page takes before presented to user
- ... Benefits beyond that
- ... Can accelerate by optimizing images, lazy load, hints, preconnect, etc
- ... Sometimes getting a headstart on top of that is nice
- ... Prefetch and prerender gives more options
- ... Allow APIs, developer tools, libraries to assist with this
- ... Because prefetch is simpler, we can do it cross-site and preserve privacy
- ... Prerendering can only work on same-site for now (more concerns on arbitrary scripts)
- ... UI speculation, URL bar might trigger it
- ... Speculation rules with APIs available
- ... For prerendering, some changes site may need to make changes to allow for (e.g. no auto play sound)
- ... Browsers can get value for users from these features
- ... We need to handle page-to-page navigations
- ... Speculation declarative way to tell browsers of a strategy to use
- Domenic: Working on these technologies for a few years now
- ... This year we've switched our focus to figure out how ecosystem can adopt better
- ... Dev-tools updates
- ... API gaps our partners have found
- ... Working on expanding URL bar prefetching and prerendering beyond simple ones
- ... Working on No-Vary-Search feature
- ... Plus document rules, delivering through headers, and improved document heuristics
- ... How much does this actually help?
- ... Deployed this on web.dev, developer relations site for Chromium team
- ... Relatively simple static site
- ... Significant gains for same-site navs
- ... 200ms for prefetch, 700ms for prerender
- ... Using document rules for Origin Trial
- ... This data is not necessarily apples-to-apples
- ... Mobile shifted significantly compared to desktop
- ... Based on when Prerendered succeeded vs. when it didn't trigger
- ... Exciting result to see change in distribution
- ... Working with NitroPack
- ... They insert a specific URL for prerender, and see 168ms improvement on LCP for prefetch
- ... Almost 2 seconds of LCP win vs. not doing any loading at all
- ... They have a lot of data, shared with us
- ... Benefits of these technologies for other perf metrics vs. LCP (CLS and input delay and whether page responds on tap)
- ... Happy to report we have approval to share agg numbers for Chrome itself
- ... 602ms improvement when Prerender triggered
- ... Improved the global LCP average by 9ms
- ... Not a lot of lead time from SERP results, but still enough to have savings above
- ... Counterfactual analysis data
- ... Speculation rules are having an impact across the web
- ... Based on counterfactual data with small holdback groups
- ... This might be a reflection of which sites are giving prerender a try - typically sites that are faster to begin with
- ... More percentiles of data in speaker notes
- ... Higher precision is less waste
- ... Recall is how often you speculatively loaded the things needed
- ... Lead Time is how quickly you speculatively load things
- ... Lots of people are experimenting with hover predictors right now
- ... We think we can do better, it's not a zero-sum triangle
- ... Maybe ML models that can optimize these axis
- ... If your platform has access to analytics data, you can use this to boost some angles
- ... When experimenting, might be surprising that Prerender might cause LCP go to "zero", but there's possibly not enough lead time to render whole page in background
- Jeremy: Clearing hurdles to adoption
- ... Complications
- ... Query parameters that don't affect semantic meaning
- ... e.g. for analytics, don't affect query processing, or ordering of parameters
- ... We'd still like to be able to use a Prefetch for same semantic result
- ... Using the response header No-Vary-Search can help define parameters or ordering to ignore
- ... Related to that, when a Prefetch goes out and before it's complete, we want to be able to use that lead time we have
- ... If the URL that's being Prefetched and the URL the user is going to, what if the response has a No-Vary-Search HTTP response header, there's a timing issue
- ... Speculation rules can have a expects_no_vary_search
- ... Tells UA there's a No-Vary-Search policy that should be waited for
- ... Subtle but doesn't have a lot of extra complexity
- ... Can use Prefetched pages in more cases
- ... One that's a little bit complicated is User State
- ... Ideally state should be discarded on some changes, e.g. when user logs in or out
- ... Some ideas which could be e.g. HTTP Variants proposal or something similar, denotes where the document will vary on a specific Cookie
- ... Just varying on cookie will probably over-match, as sites have many cookies
- In some cases the Rules would be specified by a third-party or another service provider, there could be a HTTP response header that provides the content
- … Been experimenting with a response header that would enable prefetching without modifying the markup to ease deployment.
- ...
- Other things authors need
- ... Can check if document was delivered via navigational-prefetch type, or document.prerendering in JavaScript
- ... Or Sec-Purpose header on server side
- ... Allows analytics to understand what's happening and slice data'
- ... Dev Tools updates to understand why something in the background isn't working
- ... Developer Tools can show what UA is doing
- Domenic: To wrap things up, some call to actions
- ... Looking for other browsers to implement
- ... Web Developers and platforms should add speculation rules for page. Can start small, mark everything as safe to prefetch
- ... Use analytics data
- ... RUM and analytics update for prerendering measuring
- ... One of the hardest thing we've heard in adoption is they're not sure if all third parties are updated
- ... Not everyone is there, the more we get there the better
- Questions:
- Neil: I'm wondering if you've thought to allow users to opt-out, users for whom bandwidth is expensive. e.g. Save-Data
- Domenic: Several opt-outs in place. There's a setting in chrome://settings, we respect OS and battery-saver mode
- Khushal:
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)

.png.webp)
.png.webp)
.png.webp)
.png.webp)
- ?
- Speculation rules for logged in users?
- Pre-render anti-pattern example: limit to 3 articles per month, and pre-render “eats” that budget.
- Keith: impact on server-side load?
- Jeremy: should set proper caching policies, etc
- … you can set the speculation rules eagerness level to only trigger prerenders or prefetches when the user is very likely to actually need them
- Domenic: people can vary priority based on sec-purpose headers
- Jeremy: or decline them on the server side when under heavy load
- … any error status code would cause the user to drop it
- Keith: What’s `sec-`?
- Jeremy: means the request can’t be set by fetch() or SW
- Domenic: in practice, it means post 2020 header
- Michal: From a UX perspective, only the activation time matters, but developers want to know about their lead times. If the user spent more time prerendering but that wasn’t felt, does it matter?
- Domenic: are you using analytics to measure user-facing performance or your implementation. CWV are defined in terms of activation start. But the raw data enables you to measure the things that happened before activation
- Michal: That’s a theoretical problem? Should we just measure from activation? If your aggregate data improves, but becomes more extreme in the outliers and that goes unobserved.
- Jeremy: your data could go bimodal, but I don’t see this a problem
- Barry: You should also be able to split your data by prerendered, bfcache, etc buckets
- Domenic: approach we’ve seen, and saw sites that split their traffic to prerendered/non buckets
- Jeremy: (uncaptured)
- Barry: compared second page navigation, to prerendered but most navigation were still landing ones
- Jeremy: and some sites can have more internal navigation than others
- Nic: As a RUM provider as we’re splitting on prerendering, do we want to measure from the user’s perspective or the backend perspective. Trying to figure out how to communicate “cheap for the user, but expensive to the backend”. Slightly more complex
- Barry: Was already a thing before this, with e.g. preconnect
- Shuo: Does chrome start a new process and start parsing?
- Domenic: promising but hard to implement. Need to wait for security headers to be back before starting the process.
- Khushal: Trickiest API that pages use in the background? E.g. location?
- Jeremy: Most of these APIs are async, so we delay them until activation. Async means the site doesn’t have to change
- Domenic: Some sites have issues with waiting for too long. Cross-site prerendering means hanging on localStorage which is sync, so that didn’t yet happen
- Tom: Have you come across sites where most of the site is Prerenderable but there are just a few small script tags that aren't compatible?
- Domenic: common for pretenders. Some folks do that, and others consider it a lot of work. Thought of adding attributes to scripts to help with that
- Dominic: Frozen async things get flushed to script after activation?
- Domenic: First the prerender changed event fires and then all the frozen things fire in order
- Michal: You showed one partner with interactivity data improving. How long that loading period is for certain sites? After activation start for things to settle?
- Domenic: hasn’t been a huge case because the lead time is limited. For sites that prerender at the very top, we’ve seen larger numbers than we’d like (400-500ms)
- … part of that is that we’re not doing layout and paint in Chrome. Some may be due to scripts that were deferred to activation, but we haven't heard specific complaints about that yet. So overall, I can't say conclusively.
FetchLater
- Fergal: Lots of work by Ming-Ying and Noam R. Pretty close to starting off a second OT
- … Don’t want people using fetches in the unload handler, which is also unreliable, especially on mobile
- … Typical use case is analytics data - want to send the last version of your cumulative data. Want to send it even if the page crashes
- … API shape, quite different from the last time we presented. Reused as much of the fetch() API as possible
- … Returns an object that tells you if the request was actually sent, in case you want to update the data
- … Cancellation happens using an AbortController
- … Can also pass a background timeout, indicating a preference to the browser, but there’s no particular guarantee on the times
- … 'Before' scenario doesn't always work, e.g. pagehide isn't reliable in all scenarios
- ... If you really want your data to get there, your last chance to have a good chance is visibilitychange[hidden], but maybe that's too early. The user could come back in seconds.
- ... With this API, you can just say fetchLater()
- ... Data will definitely be sent, as long as the browser process isn't killed
- ... With timeouts, you can control when it's sent
- ... Another example for using a backgroundTimeout
- ... With BFcache, you could look at persisted state and send a beacon
- ... Especially on mobile when you get a visChange event and page goes hidden, JavaScript can keep running. But e.g. browser may stop running timers.
- ... Hopefully that will still fire if page gets BFCached
- ... Another example for sending after page was backgrounded for 1 minute
- ... The "before" example here doesn't work, this is a new feature that works with fetchLater()
- ... You can also cancel a pending fetch, via abort()
- ... Then start a new fetch with updated data
- ... You need watch against races, keep the result and be able to call .abort()
- ... Implementation could have a maximum background timer
- ... Per document, there are 64 KB of deferred fetch content waiting to go out
- ... If a new request is made, that pushes over limit, it's rejected with an exception
- ... Cannot use streams for this
- … If you’ve gone into the background, network requests sent later can reveal information about your browsing that may have happened on a different network. We want to avoid that, unless the site already has permission to do that with BackgroundSync or Service Workers.
- … So if background sync is on, we can defer requests. Otherwise, we send the request as soon as the page is backgrounded
- … When the page becomes hidden, JS continues to work and timers continue to fire and then they stop, and there’s no event that signals that they stop
- … So it’s impossible to guarantee sending that data to the page.
- … Didn’t test Safari for the same behavior, but Firefox and Chrome do
- … So even though the background timeout gives us this power, that doesn’t help for frozen, backgrounded pages
- … The code to handle pagehide is quite complex. It’d be better to have a timeout baked into the API
- Anne: Confused with timeout stuff at the end
- ... I thought the idea was fetchLater() call would be queued to be sent later, and the timeout would be happening there
- ... How does JavaScript matter?
- Yoav: Discussions around having two separate timeouts, one for bfcached pages that can no longer run script, and another for backgrounded pages that can run script for some time
- ... Second one was removed because those pages can manage their own timeouts, and send fetch whenever
- Fergal: I would say we took the old API and we aggressively removed anything you could do something in a similar way, e.g. "send after N seconds"
- ... but there are situations where JS is not working but we’re not really backgrounded. And there’s no event that triggers that
- Anne: document that’s hidden but not BFcache? For such documents browser throttle timers quite aggressively, so that makes sense
- Fergal: Not related to backgroundTimeout, that's only used when BFcache
- Yoav: Background word being used ambiguous, bfcache vs. hidden
- Fergal: "Frozen" and BFCache
- Yoav: Page Lifecycle specs and info on WICG. Defines “frozen” events.
- Michal: Code to do this is complex
- ... Can you remind me the use case for foreground timers for fetchLater
- Fergal: They want to deliver first data within e.g. "n minutes"
- Michal: Wouldn't be correct to create fetchLater immediately then set a timer later
- Fergal: Simplest and reliable would be get rid of backgroundTimer and swap to just a "timeout" parameter
- Anne: Some "timer" might make sense, but "timeout" might be ambiguous for future use for Fetch
- Domenic: It's in second parameter
- Fergal: Pair with activated thing
- Nic: Note about the limits for 64KB to be queued. sendBeacon has a similar limit
- … with fetchLater people will be using this queueing up more payloads to be queued later, where
- Yoav: limit per origin
- Andrew: curious about streaming constraints. Compression streams would be exciting. Have you considered allowlisting specific stream implementations
- Fergal: I don’t recall
- Domenic: can imagine a
- Ryosuke: can you clarify “background timeout capped by implementation”?
- Fergal: Chrome has a maximum of 10 minutes. There was no good way to decide what’s a good limit.
- Anne: Need to think about this. If the user changed networks we may not send it anymore.
- Fergal: depends on the background sync
- Anne: Per origin limit makes me think we will have a partitioning problem. Does it take the top level site into account. Needs more clarification
- Ming-Ying: it’s per document per origin
- Anne: Is there a global cap?
- Fergal: we haven’t discussed that.
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Compression Dictionaries
- Tsuyoshi: Working on Compression Dictionary Transport team in Chrome
- ... Uses previous responses as compression dictionaries for future requests
- ... Compression agnostic, new schemes could be adopted in future
- ... Example of using a previous JavaScript library as a dictionary for future version
- ... Another example is using dictionary for HTML pages, used in future requests
- ... Here are results of lab experiments
- ... New HTTP response header
- ... Announces dictionary for future requests
- ... match is most important parameter. ONly for same-origin requests
- ... Optional ttl to designate how long dictionary can be used, independent of cache lifetime
- ... Chrome uses "expires" currently
- ... hashes is list of algorithms supported
- ...
- ... Client advertises dictionary in future requests
- ... New Accept-Encoding of br-d and zstd-d. Can be extended in future
- ... If server has matching dictionary and Content-Encoding it can serve using dictionary-compressed
- ... Adds headers to designate the response is encoded and using those dictionaries
- ... Also has a new <link rel=dictionary>, as well as a Link header
- ... Example HTTP interaction above
- ... Dictionary above can be used for any future navigation to the origin
- ... Browser sends Sec-Available-Dictionary header, and server responds with smaller version based on that dictionary
- ... Another example with external dictionary
- ... Browser downloads dictionary after first request, server sends Use-As-Dictionary
- ... Browser later navigates to another URL and notes Sec-Available-Dictionary
- ... Client decides whether to use dictionary, manages its own privacy risk
- ... Dictionaries are assumed to be private information
- ... Origin Trial are becoming available in Chrome
- Patrick: Standards-wise, most of the protocol-level is in IETF
- ... Browser-specific parts (link rel=dictionary and CORS protections) are going through W3C process into HTML spec
- ... Active areas of discussion, e.g. on match= string in dictionary response.
- ... Some desire to re-use URL patterns stuff in Service Workers
- ... HTTP WG prefers to not have complex processing, but most evaluation would be in client side
- ... Requires stable filename patterns for things you want dictionaries for
- ... e.g. for JS resources, you'd need a stable app.js path. Using a hash of contents won't allow you to use dictionary as currently defined
- ... Use-As-Dictionary discussion, keyed by hash of contents which you have to process the whole response for the hash. Maybe some helpers where advisory hash included in the response as well that intermediaries or client could use in some scenarios (e.g. to know if it's already in cache)
- ... There are size constraints on various parts of it, 100MB per dictionary item limit in Chrome
- ... Brotli CLI won't process anything over 50MB (no Zstd limit)
- ... Depending on Chrome version there may be limits that we're exploring
- ... Overall dictionary cache size limit as well, partitioned like cache
- Questions?
- Carine: In the IETF is the HTTP WG the one you're working with?
- Patrick: Yes
- Carine: Is the HTTP WG working on the Content-Encoding and headers?
- Mark: Yes
- Ryosuke: Who computes the cache?
- Patrick: Client-side computes the hash, and makes it available as part of the next request. Server-side could pre-calculate and use hashes to know how to process.
- ... At static build-time, you'd calculate hash of previous version, compress the current version using the previous version as a dictionary and store the compressed version with the hash of the previous version in the file name (i.e. main.js.br-d.<hash>). At serving time, check to see if a version with the requested dictionary hash is available and fall back to the full file if not.
- Ryosuke: browser computes hash based on content?
- Patrick: Yes, the browser computes this when the response is received and stores it along with the hash. Even if we add a hash on the response as a helper to reduce the need to calculate the hash multiple times, when the client stores it, it still needs to calculate and verify the hash matches the contents.
- Anne: Is it just a hash of the contents, or does it consider other parts of the response?
- Patrick: Just the contents. Just to make sure that the dictionary being used is really the same, so the decompressed contents is correct. It's not a cache identifier or anything else, just for dictionary integrity.
- Ryosuke: If the hash doesn't match, what happens?
- Patrick: The client sends a request to the origin with an available dictionary and hash; if it doesn't have a resource delta-compressed with such a dictionary, a response will be sent without dictionary compression.
- … For a lot of cases, there will be multiple dictionaries in flight, with clients having different dictionaries. It can ignore dictionaries it doesn't recognize for the requested resource.
- … You don't want it to happen too much, so we have a separate TTL on the dictionary. You don't want lots of stale dictionaries filling up intermediate caches.
- Anne: Dictionaries are supported for any subresource?
- Patrick: Any HTTP response – text, binary, etc.
- Anne: Including navigation?
- Patrick: Yes. You probably won't use a navigation response as a dictionary, but any HTTP response can be used as a dictionary.
- Anne: How does that reconcile with the CORS requirement?
- Yoav: It's CORS-readable, so same-origin or CORS-enabled.
- Patrick: It's both. Has to be same-origin as the content it's encoding, and cors-readable within the document it is fetched from.
- … A script can be used as a dictionary for future requests for the same logical resource, later on when the app has been updated.
- … There are "passive" dictionaries, used to update to a newer version, and "active" dictionaries built specifically for to be used for certain kinds of HTML or other resource, but not used other than as a dictionary.
- … The first navigation obviously cannot be dictionary-compressed, because there's nothing in the partition that has been seen before.
- Anne: How do you deal with redirects? If you have a cross-origin redirect to a same-origin resource, is that tainted?
- Tsuyoshi: can't use it if it ever redirects cross-origin
- Anne: Okay, so there's also tainting. But then how does it work for navigation? May follow up.
- Nic: A dictionary used for HTML might be different than for JS, etc. Is this just based on URL matching, or can you vary based on fetch dest?
- Patrick: Just based on URL right now. Fetch destination could potentially be added.
- Nic: Particularly, HTML pages usually don't have a common path prefix.
- Patrick: On path matching, most specific path is what's picked, so if you have "higher" and "deeper" paths, the deeper path will match.
- … You can have different HTML dictionaries for different path patterns, but right now everything is path-based.
- Barry: If you have example.com/* and example.com/*.js, will it use the former for navigation?
- Patrick: Yes, and for everything that doesn't match *.js.
- Ryosuke: We take the most specific match?
- Patrick: "Most specific" is currently "having the longest match string". If you have multiple matches, it's whichever has the longest string in the match definition.
- Ian: Why not just support multiple matches in the request?
- Patrick: Complicates the Vary caching; it's better for caches if we have just a single variant on the request. Especially intermediary caches.
- Further feedback to https://github.com/WICG/compression-dictionary-transport
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Hands-on Workshop on measuring Event Timing, LoAF, and INP
- (not being recorded or scribed)
- https://github.com/mmocny/tpac_2023_workshop_responsiveness
Day 2
Initiator attribute
- Yash: Proposed addition to the ResourceTiming API
- ... Unique identifier that can be associated with each resource fetch and RT entry
- ... Discussion on Issue #263, continue talk there
- ... Helps with identification of parent resources, to build dependency trees
- ... Can use this to provide insight into loading scenarios
- ... E.g. 3P scripts that are loading a lot of resources or weren't intended
- ... Security products could benefit from backtracking
- ... Points to identifier of parent resource
- ... Whether this should be a Fetch ID, or would it make more sense to have a Resource ID
- ... We concluded it would better to use a Resource ID
- ... String concatenation of URL and StartTime attributes
- ... Readonly initiator attribute type
- ... Collecting ResourceIDs and logging the initiator
- ... Other cases where we collect this ID
- ... Resources fetched by link, img, iframe, or inline scripts
- ... In Chromium, use the parser preloading to know which resources were fetched by the document
- ... For CSS case where stylesheets are @import'ing, we can point back to the stylesheet as the initiator
- ... Some things are a little more complex
- ... The ancestor or direct parent script can be marked as the initiator
- ... For an on-stack script case, where a carousel relies on a library to fetch resources, to speed up resource loading, we may need to optimize the carousel and the library code it depends on
- ... Cases for on-stack async scripts
- ...
- ... Some questions:
- ... How should we present this complexity?
- ... Is a single initiator sufficient?
- ... Option to add a list of scripts that block execution
- ... Loading dependency and execution dependency tree
- ... Followups in https://github.com/w3c/resource-timing/issues/380
- Discussion
- Barry: What happens with a SCRIPT inserts a IMG into the DOM, what will the initiator?
- Yoav: Insertion of IMG tag is done by the SCRIPT, correct?
- Barry: Yes
- Yash: If it's an inline script that's fetching the resources and adding to the DOM tree, the initiator would be the document itself
- ... If its' an external script, it would be pointing to the 3P script
- Barry: It's a HTML modification that's causing the IMG to be fetched
- Ian: My understanding is at the point we're inserting the DOM entry, we know the script is running
- ... As long as it's not more complex where the script inserts another script that creates the DOM entry
- Barry: If you can't make this reasonably reliable in most cases, then it's not as useful
- Yaov: In this case as long as we're building a dependency tree, we'd attribute it to script 2, where script 2 was attributed to script 1
- Michal: async scripts on stack that block resources, I'm looking at the timestamps, is the last timestamp from ResourceTiming not when the response ended?
- ... It blocks execution start of the script, but not the responseEnd?
- ... Example given where there were 3 scripts, where the 3rd is blocked from executing since they were executed in order
- ... But the resource fetch wouldn't get blocked
- ... And ResourceTiming doesn't depend on the execution of that resource
- ... 3 scripts, they would all be parallelized and completed, there's no notion of ResourceTiming that the 3rd script blocked the 2nd script
- Yoav: The fetching of multiple scripts in succession, the fetching wont' be delayed by scripted in the middle, but if script 3 is fetching yet another resources, and script 2 is delaying that resource
- Michal: It's blocking resource discovery
- Yoav: There's some dependency chain there
- ... Maybe initiator isn't the right semantics for that, but maybe there's another signal for deferred scripts?
- Michal: Should RT have one more metric, executionStart or action
- ... But initiator would be delaying that
- ... Let's say there's a chain of 3 resources
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
- Resource 1 “blocks” resource 2 from execution (because it was “defer” and was ordered first, so executes first… but only if both are loaded together before DCL… it’s complicated!)
- Resource 2 is initiator of Resource 3
- Resource 3 now officially “depends” on Resource 2… but it also is indirectly ends up “blocked” by Resource 1.
- General observation: resource timing starts with resource discovery, but resource discovery is based on execution of work. Resource timing can report initiators but Resource timing does not report on work execution, just fetch.
- Noam: Use-case is to provide a network waterfall?
- Yoav: The use case is to provide a RUM-available dependency chain
- ... If we want to focus on a single resource and what's delaying that, going up the dependency chain should give us that answer
- Nic: prefer to have more details than less. Single initiator is useful. Other bits of information would help as well
- … What would wrappers do?
- … Would wrappers get blamed for everything?
- … It may help to have more than one initiator to avoid blaming 3Ps.
- Barry: comes back to Michal’s point that RT is about resource loading not execution
- Michal: It’s also about discovery. Resource 1 blocks 2, which initiated resource 3
- Nic: Could get out of hand
- Noam: Promise.all
Compute Pressure
- Ken: initiated by Google. System pressure - cpu, heat, etc
- … video chat systems put pressure on the computers during COVID
- … So for systems under pressure could adjust the number of frames or resolution to make things better
- … Introduced a lot of challenges. CPU pressure is global state that could be shared across origins and apps
- … Do we need permission prompts?
- … 4 pressure states: nominal, fair, serious, critical
- … developed with collaboration with Zoom and other API clients
- … Added support for workers and iframes
- (awesome demo)
- .. Global states can result in privacy issues
- .. Sites can use global pressure by changing workloads, enables them to broadcast data
- .. The attack requires a very quiet system, but is possible
- … Two mitigations in the spec: breaking the calibration and trying to identify that folks abuse the system using abnormal compute pressure
- … In OT, active users, lots of interest
- … Know that some people would really like low level access for that info
- Oli: How do pressure states match with the hardware? Android CPU vs. intel CPU
- Ken: Trying to align on CPU specifics was complex and utilization was undefined.
- … Wanted to define high level state that developers can reason about, but allow UAs the liberty to define
- … Wanted to do this in a way where hardware can run at e.g. 80% cpu utilization and not report critical (TODO)
- Oli: There’s interop questions if different systems report different values
- Ken: Values should align with user experience, not strict cpu conditions
- Nic: Would the levels be defined by the UA? OS+UA?
- Ken: A mixture. A lot would require some hardware collaboration. Maybe we’d use machine learning to detect the levels. It doesn’t matter much that it’s the same across systems. No real interop concern.
- Khushal: Can this be used as a hint from the user to lower system utilization? TODO
- Ken: Systems already do this somewhat, like start throttling if stressed for too long, and the Intel Thread Director on Windows can move processes around etc. But apps might function quite differently and want to be in control.
- … Streaming video game wants to get most out of the system ,but without killing the machine
- … another example is adding more people to a zoom call
- Noam: possible use case - adaptive initial response to user interaction based on pressure.
- Andy:
- Ken: Thought about attributing some blame to current origin to notify the site that it’s causing load
- Khushal: Any thoughts on serially dispatching this notification. For example, give it to a background tab/iframe first. Allows the more important content to get more CPU utilization.
- Ken: If you’re backgrounded you don’t get that info. It’s available to visible iframes
- … A few exceptions, especially in the video case. Sharing my screen means that zoom is in the background.
- … Same with picture in picture
- Khushal: Maybe dispatch it to the iframe first?
- Ken: both main frame and iframe would be able to get it. But you have to set the permission policy on the iframe
- Noam: expand on the comment I wrote. A case we see at Excel is that some interaction would provide a response in 200ms. In a small percentage of cases we can’t do that, and we’d like to provide some feedback to the user.
- … Would that work or would the state fluctuate too frequently.
- Ken: There are ways to set the frequency, but would be great to file an issue with that use case
- Nic: Looking at the explainer, it seemed geared towards real time applications. How can this be used for analytics? Can we split data based on the compute pressure?
- Ken: Haven’t thought a lot about that. Let’s collaborate!
- Nic: Not an explicit non-goal, though
- … I’ll open an issue
- Oli: Introducing a fingerprinting vector
- Ken: Some fingerprint-ability, but fairly limited. Limited number of states
- … could correlate the same user on the same system in some circumstances
- … Very hard to do, and we have mitigations in place
- Shou: Even if the spec limits the number of calls to 1 per second, still seems like a new fingerprinting factor
- Ken: TODO
- Alex: these words are more fun than low medium and high
- … Thanks for the research on side channel attack
- Ian: Spec says that algorithms are not deterministic?
- Ken: Spec is missing the limits, still ongoing work
- Ian: Analysis that has X% randomness resulting in lack of calibration
- Ken: The system may take some time to cool down and change states.
- … Could manipulate what it means if you treat the change as a range. Can move things on that range, to break the ability to calibrate
- … /*goes over “supporting algorithms” in the spec*/
- … mitigation proved to be quite effective
- … Plan to add default values in the spec
- Ian: interested in information theory perspective
- Ken: On really fast computers, it is impossible to find workloads. Attack varies based on machine
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Long Animation Frames
- Noam: "Lo-Af"
- "No-am"
- ... Recap: We want a web that's more responsive
- ... Avoid jank and wait and other bad words we can find for these events
- ... Measure sluggishness
- ... INP we can measure regressions in responsiveness, worst interaction
- ... Regression metric, what caused INP?
- ... How does it become actionable?
- ... Look from our accumulated hours of tracing, what causes sluggishness
- ... 3 main causes
- ... 1. Direct / slow event processing
- ... Click event, took long to paint, INP
- ... 2. Main thread congestion -- things on the main thread, maybe not related
- ... 3. Other, things happening on the system, compositor, high compute pressure, input handling was slow
- ... We're talking about the second one here, in a way that's actionable
- ... Up until now we've had Long Tasks as a way to do this for a while
- ... 3 issues we've found issues with LT in the field
- ... First, "tasks" are an artificial term. In the browser, in the spec, but term can be used for multipel things. Not directly connected with UX.
- ... Task length is an implementation detail that's not necessarily useful
- ... Second is a missing feature, no attribution beyond what window
- ... Long Animation Frames, Long Tasks version 2
- ... LoAF is the time between idle and paint
- ... Start with idle, do some work, maybe it needs a render? if 50ms or more have passed after doing work, then its' a LoAF
- ... What's in a LoAF? Provides time spent rendering, blocking input feedback and layout thrashing
- ... Need to wait for rendering to know if style and layout were the last ones
- ... We also know which scripts ran during animation frame
- ... Script entry points
- ... Not the whole script profiled, the top of the stack
- ... For each script er can expose:
- ... What's been done so far:
- ... Most of the implementation, currently on Origin Trial
- ... Several active participants providing feedback
- ... RUM Vision is providing this in their dashboards
- ... Found script cause of bad execution
- ... "Game changer" easier to pinpoint issues
- ... Big productivity suite using this in the field to find scrolling jank
- ... Third case-study: a 3P ad provider, doesn't want to be the cause of INP issues
- ... Doing field regression testing
- ... Giving themes something actionable will help them take responsibility for this
- ... Relationship with EventTiming and INP
- ... Trying to match INP and LoAF directly is a red-herring
- ... Doesn't always give results you expect
- ... Doesn't tell the whole story, but might incidentally tell you
- ... We measure sluggishness with EventTiming and INP
- ... We measure main-thread congestion with LoAF
- .... Requires analysis in the middle, could mean different things for different sites
- ... Analogy is ElementTiming and LCP, and ResourceTiming
- ... Work together, but it's intentional they're not merged into one
- ... Gotchas
- ... Can't 100% cover all scripts, but sometimes may be misleading
- ... Education challenges in teaching people that there's not a red-line between LoAF and blaming script. Gives hints and data, and requires analysis in the middle
- ... For example in RUM Vision slide, they had Sentry.io which wraps all JS calls. Doesn't mean Sentry is to blame for performance
- ... Also reasons like cross-origin frames (running on same process), or system congestion, extensions
- ... You may have LoAF but don't know why
- ... Missing things
- ... Clearer connection with EventTiming
- ... Want better support in Dev Tools
- ... Fix script entry attribution to be less partial
- ... Next steps is to finish OT, fix those missing bits
- ... Our focus on interop and spec'ing to fullest, will be after we learn a little bit more
- ... Responsiveness and congestion are related but separate
- Yoav: Mentioned this as Long Tasks v2. We're going to talk about rechartering soon. Should we rename Long Tasks something more generic that will cover both APIs?
- Noam: We can call it Congestion or Main Thread XYZ.
- ... I see the Timeline as one big thing that has multiple views into it, LongTasks with several entry types is fine
- Sean: Are we trying to deprecate Long Tasks?
- Noam: I don't know. It's possible, a future question
- ... Main step in the way is for Lighthouse / TBT support. People are using LT to measure that
- ... Once we use LoAF to measure that, we can consider
- Oli: How does this work in background tabs?
- Noam: LoAF is only for visible frames
- Oli: For the algorithm, this stuff is implementation-dependent, might lead to different results
- Noam: How this works is implementation dependent, yes. In Chrome for example, rendering throttled to 100ms, if no input event, we do every 100ms
- Oli: And Firefox doesn't at all
- Noam: The effect is the same though. You had an idle moment until paint.
- ... Blocking duration is the time which a possible UI event would have been blocked
- ... Different between browsers
- ... We use these metrics for improving ourselves
- Noam H: Use-cases, we are evaluating this API, but don't align exactly to the intent
- ... One is to identify bottlenecks during page load time
- ... Analyze events happening during page, to see if bottlenecks were JS or compile or style related
- ... So far I can't tell if it's useful, need to analyze the data
- ... Related to script compilation and evaluation, sometimes it's inline evaluation, and this only collects the root evaluation
- ... Second use-case is identifying smoothness and scrolling of viewport, identifying bottlenecks there. Seems promising to that scenario.
- Noam: To the second question, compilation should catch inline scripts.
- Noam H: Not inline scripts, when compiles happen, the first pass of the root items in the JavaScript then it may do JIT compilation
- Yoav: Pre-parse vs. compile vs. JIT
- ... Pre-parse phase, then parse the script, then interpret, then JIT hot paths. But not defined in any way.
- Noam H: Initial parse
- Yoav: Up until interpreter started running
- Noam: responseEnd until first time performance.now()
- ... Broad strokes, kind of intentionally
- ... We wanted to find the right balance of low overhead
- ... Enough information to be useful
- ... The needle can move to either side as we're researching and talking to others in this room
- Nic: Excited to hear about 3P scripts excited about this to improve. Did they try to experiment with LTs?
- NoamR: LTs don’t have scripts. We started this trying to add scripts to LTs and finding issues, then spinning that off
- Yehonathan: what about attribution of LoAF to an element or a layer? What if I’m animating something too heavy for the machine
- Noam: Showing style and layout only. No current plans. Not sure how to do that in a way that’d be reliable
- Andy: Would script attribution be useful for worker thread scenarios?
- Noam: Not exactly. JS profiling may be more suitable for workers than this. You don’t have lots a lot of types of tasks that happen in the worker. Attribution is typically to the worker
- Andy: Minification - sourcemapping and obfuscation?
- Noam: That’s for the analytics tools or (in the future) on the devtools side. Don’t even send column/line positions to reduce overhead for this field metric
- Oli: How high is the overhead with this? Thinking about speedometer 3. Have you measured in such benchmarks?
- Noam: Ran this with all the benchmarks. Had to revert some bits and pieces
- Oli: taking timestamps is slow on Linux
- Noam: can and will benchmark more
- Michal: Event Timing has to measure things anyway.
- Oli: this is overhead per event listener, not per event dispatch
- Noam: We can find mitigations. Can be a lossy hint to the developer. If it’s not 100% accurate that’s fine, as long as devs have info about where to start looking
- Nic: great data for traces and understanding. You mentioned TBT.
- … Do you see a similar aggregation metric related to LoAF?
- Noam: Hoping to port TBT to use this, as it does it more justice.
- … careful with too many aggregate metrics
- Nic: For RUM providers, aggregates help to monitor changes in them and alert developers on regressions
- Noam: Main change would be when stopping to measure TBT for invisible frames
- Michal: Worth discussing effective blocking time
- Noam: Not at the moment
- … With the OT we added to it, anything that can be measured to see what people use, and learn from it what needs to be shipped
- Nic: how long would the OT run?
- Noam: Been out for 2 month and would be active until we fill we learned enough
- Ian: Chrome 115-120, may be extended
- Michal: the “needs render” in the cycle, from Chromium’s impl, we differentiate the first invalidation from other invalidations. Multiple layers to be figured out. Can other implementations eagerly decide when a rendering stage is needed?
- Oli: Roughly what firefox does. Can eagerly paint as a result of input
- Emilio: what does it convey? Something may have changed? Something definitely changed?
- … e.g. an intersection observer churns a rendering loop. Does it count?
- Noam: yes
- Emilio: why? Is it well defined?
- Noam: You can define it in the HTML spec.
- Michal: The reason you measure a single task being long is that it’s blocking everything else in the queue. If you requested rendering, future work is being delayed by your task
- Emilio: is there a pending “update the rendering” step?
- Noam: yes
- Michal: Maybe it’s feedback about the naming
- Noam: Wanted to call it “frames” but didn’t want to confuse it with iframe. “Long rendering cycle”
- Michal: this is all related to “effective blocking time”.
- Olli: rendering is prioritized, but we force paint after interaction
- … high priority task is we think we have something to render
- Michal: Many reasons why you may cluster work and then render, and that’s browser specific. “Effective blocking time” would give you end to end duration
- … but the EBT would give you the longest block of work + rendering task
- Olli: There might not be “idle” but just not work
- Noam: After you've painted you’re “idle” even if it’s for 0ms. But you could call it something else
- Ryosuke: replace LT or complementary?
- Noam: We don’t know yet. You could say it’s an extension
- … we need to learn more about this space in order to know the answer
- Barry: Nothing in LT that this doesn’t answer?
- Michal: Could have multiple LTs in a single LoAF. May not matter in practice
- Noam: Could have a LoAF entry that has a few tasks in it
- Barry: Any reason not to use LoAF?
- Noam: If this succeeds this should deprecate LongTasks
- Ryosuke: LongTasks would take us years to implement, while this is implementable
- Noam: Working on this together would be better for the web than waiting to implement LongTasks
- Olli: This measures quite well what happens in the speedometer3 runner. It measures from a raf call till the TODO
- Andy: Is there a case where there’s an LT that doesn’t involve rendering so no LoAF fire?
- Noam: Only case is when the page is not visible for part of the time
- … If there’s no rendering, it still counts as a LoAF
- … This is main thread congestion even if it didn’t paint. Can say it’s a noop, but it’s an invisible animation frame
- Ryosuke: There are some computation that doesn’t result in a DOM change, where there’s no animation frame at all
- Noam: We have those as well
- Ryosuke: keeping track of that is less important, as users may not notice it
- Noam: Wanted to measure all that stuff. You could see clearly in the entry that this did not render.
- … Goes back to “this is a congestion metric”, and there was congestion
- … Maybe you did work for a second and it didn’t matter, but it might in other scenarios
- … so important to expose speculatively for other cases
- Ryosuke: So LoAF would report?
- Noam: Report and tell you it didn’t render
- … So 2 types of LoAF and we report both of them
- … maybe needs bikeshedding
- Michal: Could you imagine a model where you always schedule rendering work and bail if there’s nothing to be done.
- … rAF based reporting, if there’s no actual rendering
- Ryosuke: Can’t understand that in WebKit as we don’t know how tasks are run
- … So it would be impossible to implement right now the “no rendering update” case
- … rendering update is well defined and we know if it got delayed
- … but we have no knowledge if something took more than 50ms
- … We know when the rendering update was scheduled
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Incubation adoption & Charter
- Yoav: Let's talk about pending incubations
- ... Stuff in WICG and some intention to move this to our WG
- ... Not about incubations inside existing WG efforts
- ... ElementTiming
- ... Main reason to get into group is it's heavily relied on by LCP (which is in the group)
- ... Spec in WG that's reliant on spec in incubation
- ... Would be great to resolve that
- ... There could be value in uniting some of the existing specs into larger ones
- ... Particularly, move processing model of both ElementTiming and LCP into PaintTiming
- ... For example, have their single definition of Contentful. A single spec will help clarify this.
- ... My question to the group is can we ElementTiming is adopted by WG, then move all into a single spec?
- ... If not, there could be other creative solutions but let's see if we need to discuss those
- ... Obviously this meeting doesn't replace a Call for Consensus, but I'm trying to get a feel from the room for support or objections on this front
- Alex: For moving the spec, adopting ElementTiming?
- Yoav: Yes
- Ryosuke: What's the implementation status?
- Sean: We're implementing LCP, but not ElementTiming
- ... (just the ElementTiming algorithm)
- Michal: Half of ElementTiming is an extension to PiantTiming, and the other half is TODO
- Yoav: If there is no consensus in adopting ElementTiming, one thing we could do is move processing model off ElementTIming, and have ElementTiming spec just be IDL + a couple of hooks.
- ... We could do that, I guess
- Sean: Could be weird, FCP doesn't use that processing model.
- ... Currently PaintTiming has FP and FCP
- Yoav: First, we need to look into aligning on a single Contentful definition
- ... LCP Contentful and FCP Contentful
- Michal: Contentful could be shared for the most part, but the idea of first paint is of contentful content
- ... Whereas elementtiming and LCP represents the final paint of contentful content
- ... Different demarcations of paint and time
- ... Should be shared
- ... PaintTiming has many facets which should also be defined
- Yoav: Should be united in a single document, instead of 3
- Ian: Foundational Paint document, perhaps ElementTiming is off of that, LCP is also off of it
- Yoav: Is ElementTiming not on roadmap?
- Sean: We're not against it
- ... Do we need implementations?
- Yoav: No, we need WG members to be favorable of adoption is the criteria
- ... To move spec further down the line, CR or PR?
- Carine: Requirement for CR
- Yoav: Maybe we want to keep ElementTiming apart as long there's no other implementations, in order to not block PaintTiming from CR
- ... But that doesn't block WG adoption
- ... If you're generally favorable
- Sean: I'm more favorable having a main PaintTiming document, and keeping separate docs
- Yoav: Bringing all processing model into PaintTiming, but keeping separate documents? That would still be an improvement
- Sean: Yes
- Carine: PaintTiming is just WD
- Yoav: From my perspective, moving processing model doesn't require an adoption decision. But we could separately discuss exposing the API part as an adoption decision?
- ... Should I send CfC?
- Patrick: Does adoption mean pushing ElementTiming forward as a spec, or we want to take responsibility and taking what's in it and making sure they're all connected
- Yoav: Fixing stuff up is something we already need to do, WG is committed and adopted LCP. Therefore we need to fix up the underlying dependency issues
- Patrick: Aren't we responsible for impact on ElementTiming as a result
- Yoav: A situation we want to avoid is a situation where we effectively have all the things in PaintTiming are implemented, but ElementTiming is blocking rest of the spec making progress in W3C process
- Patrick: If ET doesn't become a standalone spec, and we take the relevant parts into the other specs, are we still responsible for ET or do we leave it as a straight incubator
- Yoav: Incubation that relies on processing models that live in WG specs
- Ian: Take off W3C hat and put on WICG hats and make work on it
- Yoav: Should I send a CfA or now?
- ... I think it's worthwhile to have API in separate spec anyway
- Alex: No multiple implementations of ET
- Sean: LCP is almost implemented
- Carine: If we fix issues in PaintTiming, what would be schedule roughly
- Sean: "Soon"
- ... We are going to have LCP, so we'll support algorithm of ElementTiming and LCP part
- ... So moving those parts around would be fine for Firefox
- ... If we just incorporate algorithm into PaintTiming doc
- Yoav: From my perspective it doesn't require a CfC
- Carine: And it's just a WD doesn't take anything
- Alex: I think having ET and a shared infrastructure separated would be good
- Carine: Should we send a CfC for adoption of ElementTiming
- Yoav: That would be a new document, yes
- Ryosuke: No consensus that we want this in the working group
- Michal: Unambiguous consensus that if ElementTiming were split in two that would be good. I heard no concerns about ElementTiming, a second implementation coming.
- Sean: No objection for a new document for algorithm of ElementTiming
- Yoav: Option (a) we adopt ElementTiming, we throw everything ET+LCP in PaintTiming. One Spec covering all 3.
- ... Option (2) we do all that, but we keep the hooks in ET separate to not stall larger document
- ... Option (3) we keep the same thing, but have the thing wrapper and keep ET wrapper in WICG
- ... I prefer Option 2 with thin wrapper in WG, unless there are objections we can go with Option 3
- Ryosuke: We'd have a significant problem implementing ElementTiming
- ... Algorithm needed by LCP and ET should be moved into WG
- ... Question is whether ET API should be included in charter of this WG
- Sean: I'd prefer we put ET algorithm into PT
- Yoav: In case we don't need consensus
- Ian: We can revisit after the algorithm is moved
- Sean: Sure.
- Yoav: Concerns around implementation's complexity
- ... Discussion earlier this year, and to try to share ideas for how this could be implemented elsewhere
- ... Right now this is Chromium implemented only
- Sean: Firefox has not implemented
- Yoav: What is missing?
- ... In the past the Mozilla folks were supportive of the concept, but had performance concerns
- ... I think some of those performance concerns were addressed
- ... What could be next for adoption?
- Sean: I'll ask folks to review difficulties, I'm not sure if they have new thoughts for this
- Yoav: If there's anything else to help push this work further
- ... Other incubations
- ... I think Memory Measurement had some desire from Mozilla in the past
- ... What can we do to push further?
- ... Incubations planned to go directly to WHATWG
- ... Talked about Scheduling APIs last year, one big spec
- ... Consensus it should be implemented directly into HTML
- ... Do we tie requestIdleCallback to the other Scheduling bundle? We'd need to add that to the charter
- ... Thoughts in that direction?
- Alex: Putting into the same spec as those other scheduling things?
- Yoav: Probably into HTML
- ... fetchLater() is going into Fetch
- Noam: But only Later
- Yoav: Page Lifecycle is related to things WG worked on in the past light Page Visibility, not sure about current state nor cross-browser implementations
- Olli: Implemented only in Chromium? Which didn't have BFCache?
- Yoav: Yes and yes
- ... It may need some revisiting
- ... I can try with my Chrome team hat on, push to figure out the situation on the Chrome side, if you can file issues
- ... This is parts of the snippets that Fergal used the other day for fetchLater()
- ... If this isn't cross-browser implemented, that won't be a viable solution
- ... Good to push on that
- Ryosuke: Which memory API were you talking about
- Yoav: Measure User Agent Specific Memory
- Michal:
- https://github.com/WICG/performance-measure-memory (MDN)
- Yoav: performance.measureUserAgentSpecificMemory() limited to COI
- Michal: Question about adopting this to the group
- ... I heard others may not want it to be part of the web platform
- ... Is lab tooling within WG in general
- ... Concept of a layout shift is worth being in purview of WG
- Yoav: Algorithm without Web API available?
- Michal: Yes, are we interested in discussing the challenge of layout shifts in this group
- Alex: Is there a group for web tools?
- Yoav: Yes, this would be shared concept between the two groups
- Michal: Should we have this even if there are concerns in shipping it to the field.
- Ryosuke: We're not interested in implementing this thing
- ... We wouldn't want this included in deliverables in WG, we'd be on hook to implement
- ... Want to minimize scope as much as possible
- Nic: Including a doc in the WG doesn't require a commitment to implement right?
- Yoav: Correct but it require IP commitments
- Carine: TODO
- Yoav: I've heard no appetite to adopt the concept, we'll follow up
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Scheduling APIs
- Scott: Update on scheduling APIs. presented in the past, but wanted to give a high level update
- … breaking up work into smaller pieces can help with responsiveness
- … these strategies have proved very effective inside of Chrome as well
- … Shorter tasks can help responsiveness, but how should they be scheduled?
- … notion of priority gives some control over that
- … used to schedule prioritized tasks
- … modern API that returns a Promise, takes an abort signal
- … shipped this in Chrome 94. Usage is trending up as part of the focus on responsiveness
- … can be polyfilled
- …
- … Geared at improving responsiveness. Yielding to the event loop gives us a rendering opportunity
- … Enables a single large task, that yields to enable other tasks to run
- … Talked about this a few years back and keep hearing about this from developers
- … Concern that yielding can result in long time before they get rescheduled
- … Problem presented in the chart above
- … setTimeout can get in the way of continuations
- … with yielding and continuations, we’d prioritize continuations, so that once the render runs, we’d continue the task we were working on before
- … API shape needs to work well with async tasks
- … takes the same options as postTask so you can define fine-grained control over priorities
- … Yield also supports inheritance - continuations get the same priority as the task that triggered them
- … Example - task controller with a priority. Function loops over items and yields after each item.
- … calling abort would result in the Promise rejecting
- … Saw latency improvements in Facebook experiments compared to the regular React scheduler
- … Other ideas - you want to yield but not block rendering
- … semantics to wait after rendering happened and then resume
- … replaces double-raf hacks and doesn’t force rendering
- … Another use case - want to yield but wait for some timeout
- … requested by developers to essentially have a promise based setTimeout
- … Difference here is that it doesn’t need to be prioritized as the other APIs, but you could specify a priority if needed
- … other use case - Extending the priorities system to other APIs
- … thinking of an API that might make sense
- Olli: Priorities aren't specified anywhere, so we'll need to work on that. Don't match Firefox.
- Scott: Yes we have an open Issue there as well. I started a patch, but got distracted by other stuff.
- Noam H: Can you explain more between yield() and render()
- Scott: Yield doesn't wait for a render to happen. No guarantee. For example, you've updated the DOM and rendering hasn't happened, you call yield(), Chrome can just resolve the promise in the next task. Doesn't wait around.
- ... with render() if you make a DOM update, you're guaranteed the next time the promise is resolved, those updates would've been painted
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Crash Reporting
- Andy: This may want to get pushed off to Charter Discussion
- ... Reliability isn't owned anywhere, in any WG
- ... Came up in crash-reporting repo should this be in scope for WebPerf
- ... Is that a Charter thing?
- ... What's the line between performance and reliability?
- ... Tied tightly, a Hang is a Long Task in many cases
- ... Memory crash can be poor memory usage, etc
- ... An error or reliability issue can happen due to performance issues
- ... Came up with reports from hangs causing crashes
- Yoav: Thank you
- ... I think this is in scope for our Charter if we're looking at mission and
- Yoav:
- Earlier we discussed reporting api, etc, which are in WICG
- All of these are in scope but may not have quite enough interest to adopt
- I suspect, any new reporting features, while they may be in scope, may find themselves in a similar position (not enough support for adoption)
- Andy:
- Makes sense.
- Yoav:
- Let’s look at the Charter proposal
- Missing/Scope
- Nic:
- We do not currently discuss reliability
- Alex:
- What did we refer to earlier?
- Crash Reporting, Deprecation Reporting (?), Intervention Reporting
- Who manages that? Us.
- Yoav:
- Web App Sec group also use that and rely on us, as does NEL and other things?
- What is the status of Crash Reporting
- Still in WICG
- When was it last published as a draft? …
- Yoav:
- What Andy is proposing is similar but different, and Andy is looking for a home and asking if Web Perf WG is the place.
- Andy:
- The current charter and many specs “imply” a concept of reliability but not explicitly. Maybe some of the lack of interest is due to lack of explicit mention of it.
- Yoacv:
- Perhaps add a PR to the Charter to see
- Nic:
- (Discuss draft Charter and how to comment/PR)
- (Going through Github issues, tags)
- Carine:
- This is going to be spent out (to AC) soon–
- I would rather ask to file and issue than to make a PR at this point.
- Andy:
- I can do that.
- <Reviewing Draft Charter>
- Yoav:
- Beyond that, there is a Web Perf Primer that may be better to move elsewhere. Will discuss with MDN
- There is also Security and Privacy doc that needs work. Could be spun out… TAG is working on a privacy principles doc… I tried to push some of that there, or have our own document about “deployability principles”. This would be used to help balance tradeoffs vs various principled documents.
- First step would probably be to update this document
- Those are the main things being updated in the current charter.
- Carine:
- Current charter says that we adopting “way of doing things”. One of them is to keep things in draft and not CG… I anticipate that this will get pushback. Not sure what the implications will be on the WG
- Yoav:
- Can you expand on the objections?
- Carine:
- Not really an objection..
- 1. Some things are sup[rised that we dont expect to make Any Recommendations…
- 2. Normally we get out of CR when we have multiple implementations. If we never leave CR, it makes things tricky.
- …Changes to specs may mean returning to CR… so maybe only snapshots, or change
- <Apologies imperfect notes>
- …This may be pushing the boundaries of the process
- We may need to discuss specifics of the CR process, 2x implementation requirements, etc. We will get feedback back from AC review.
- Carine suggests that we go into the AC review with suggestions / proposed solutions.
- Yoav:
- …<POH?> mentioned this in passing but I had not quite expected…
- Nic:
- Do you recommend wording changes to the Charter right now?
- Carine:
- I think I would, I can make some changes to wording as recommended.
- Yoav:
- I would prefer to better understand the “threat model” here first 😛
- Carine:
- The biggest threat is the holes in the process… no other group declared in the charter their intentions the same way we did. (Also pointing out other ways to break the process)
- Yoav:
- There are several ways to this: CR and versioning… We tried that system and it didn’t work well for us. We are in the process of moving away from that and we tried to be upfront about this.
- I need to better understand the process and implications and think through this.
- Carine:
- There is a new process for updating REC without changing version numbers… but somewhat it is also a hole in the process, since there is no check on the new CR for implementation status. The group is trusted with review…
- Yoav:
- …we decided to choose this route because the other was not quite defined, didn’t seem to work… maybe we take another look.
- <Some suggestions on living standards approaches>
- Carine:
- The decisions to make now is:
- Leave charter as-is and hope, or
- Change before the AC review…
- Yoav:
- I prefer to think about this
- Carine:
- I support that :P
- …
Day 3
NEL discussion
- Ian: Survey of open issues in NEL and what's going on
- ... A couple of immediate issues that some may want to discuss
- ... Network Error Logging (NEL) helps site owners understand why users can't reach their site
- ... Reports on network error conditions, i.e. DNS, connectivity, application errors
- ... Set a header on your site, later visits will use header to send error reports
- ... Different than other APIs, as we're reporting on cases where user isn't successfully on the page
- ... Since last year we've partitioned the policy cache, subdomain reports are downgraded to DNS
- … expire policies
- ... 27 open issues that fall into multiple categories
- … tasks, new information types, filtering and privacy issues
- … 5-6 outstanding issues on the privacy front
- ... Signed Exchanges (#99) would be sent through a different path than going through the destination report server, needing different signing requirements.
- ... And signed exchange may have its own Reporting API headers
- ... Request to include Subresource Integrity errors (#155), but NEL may not be the place to do it
- ... Extended DNS errors (#129) there could be additional DNS information, but questions on potential privacy violations - revealing the identity of the DNS resolver to the site
- ... Certificate fingerprints (#127) in cases there are TLS failures
- ... Two issues about minimizing report volume
- ... Filtering reports by path (#124) so you can get volume. #133 is similar but by error type (DNS vs HTTP etc)
- ... We discussed these in April and we'd like to move forward on it, but just need to do the work
- ... Last section is Privacy Issues
- ... First one (#105) there's certain information that's not relevant for the request depending on the type of error it is
- ... We have a potential issue with Cookies (#111, #112)
- ... And two outstanding issues that came up earlier this year by some researchers (#150 and #151)
- ... For Clearing Report Body fields (#105)
- ... For DNS error example (above), we're including things like URL, path and query
- ... Some of these aren't relevant since you haven't even made the request yet
- ... Remove HTTP-level fields
- ... Similarly for connectivity, TCP aborted
- ... The path, query, method, etc haven't been requested yet
- ... For cases where error collector is different origin, may want to clear path/query
- ... Suspect we don't want to do this as the path itself is quite relevant, and site owner has said they'd trust this third party with their error logs
- ... Two issues with Cookies
- ... Then SameSite cookies can be sent cross-origin to a collector
- ... HttpOnly cookies (not readable by site) would be readable by being included in the reports
- ... Should we be taking it on ourselves to modify the header for those reports
- ... Maybe we should be removing these things?
- ... Or if we're not showing the exact stream in the request, is it still useful?
- ... For issue #150
- ... Upshot seems to be two things. One is that NEL reports on requests other than the top-level document
- ... We don't do NEL on things that happen in the background
- ... Regardless of origin, if you're requesting things from CDN and we can't get to them, we should report on those
- ... Second is that usage/presence of DNS-based firewalls could be exposed
- ... I think this is a fundamental to what NEL does
- ... Last one we have is allow limiting information exposed in NEL by URL
- ... When setting up NEL policy, how much information do you want to report?
- ... Maybe you want to exclude certain information depending on where that report is going
- Questions
- Martin: Mentioned the block list example (DNS or any based)
- ... Network fetches are going to fail depending on the blocklist of different scenarios
- ... We have to assume at some level these blocklists are being applied by user-choice
- ... Net effect w/out NEL is that sites know a resource isn't loaded but don't know why
- ... That why is important to keep secret, because it could be a non-retaliation issue
- ... Resources can be blocked for privacy reasons
- ... Users could be retaliated against for them using privacy blocking lists
- ... I'd be uncomfortable providing this information tied directly back to the user
- ... OK with this in aggregate
- Ian: Not include anything blocked on the client's machine (e.g. extensions)
- ... When the UA does everything it would normally do to get a resource, how do we distinguish blocklists from a misconfigured DNS server
- Martin: It reveals more granular information than what was being reported before
- ... e.g. Users using pi-hole
- ... Creates a discriminator for people using those tools
- Scott: How would you know what would cause DNS to fail
- Yoav: Not missing a piece of information, no technical way to detect blocked from server failure
- Scott: Browser extension, pi-hole, ISP filtering, Google DNS blocks, I've not seen a way where we could determine that
- Martin: Concern is with existence of granular information, not the signal
- ... May be a case where DNS does provide information to browser through extended DNS error codes
- ... But most DNS blocking configs would return NXDOMAIN and can't distinguish from others
- Yoav: In that case, any guess of this was blocked by DNS or accidentally failed to resolve via website would be speculative. Website wouldn't know which is which.
- Michal: About retaliation, NEL doesn't issue report in contents of the request, some network errors happen, but they don't' immediately get log from NEL, report is sent out of band "later" (i.e. a couple of minutes)
- ... Not observable
- Ian: Correct
- Michal: Could they cross-reference somehow?
- ... That this particular user had these failures before
- Yoav: You would have to be extremely vindictive to retaliate
- Martin: Comes down to the privacy threat model, should we be giving this information to sites anyway?
- ... Delay gives breathing room
- ... Whereas if you're wanting to provide disconnect between report and action that failed, then a couple minutes of delays won't be adequate
- Ian: Delay is not for any privacy reasons, just the mechanism
- ... Other thing that might be relevant here, 48h timeout on policies
- ... Timewindow you're limited to if DNS blackhole goes up, after 48h we won't send any error reports
- Martin: Questions is should any of this information be available to websites
- Neil: I don't see a way to distinguish where blocking happens
- ... Why is it a problem if web server operator knows there's content filtering in place
- ... Wouldn't know what to do with that
- Lucas: From my perspective, it's all good. If you're a website operator, and some content doesn't load because of a DNS error, maybe the person who loaded that thing just forgot to renew that domain or something. If things start breaking in subtle ways, NEL really helps identify there's an issue.
- ... Whether there's explicit blocking or another subtle issue
- ... As a website operator, I'm seeing all these ad domains are being blocked. I could switch to another ad operator.
- Scott: Only if those own those 3p domains?
- Ian: Those 3p domains won't get reports, unless they registered for NEL for them-sleves
- Barry: If I load jQuery from cdn.jquery.com
- Scott: You wouldn't get reports unless you owned cdn.jquery.com
- Barry: I wouldn't know my own site was broken?
- Ian: Correct
- Scott: I think there was a source of some confusion?
- ... Only details of our own domains would be blocked
- ... Does that help with concerns?
- Martin: Yes it does
- ... One of the manifestations of blocklisting, was IP scraping
- ... Resolved IP is given to entity that is blocked
- ... So they can collect info on what are being blocked
- ... Question of IP Release which is a different discussion
- Scott: I operate report-uri.com, we are processing billions of NEL reports a month
- ... Researched ways CSP can be used in other ways
- ... Nothing found too particular. Supportive in restricting fields that leak security or privacy info
- ... #105 seems to make sense
- ... If leaking IP, we could redacted or reduced NEL reports, so site operator can know and investigate on their own accord
- ... Goal is to help customers know if their site is broken
- ... No other sense if using ad-blocking or something like that
- Ian: Which scenario would redacting IP be useful
- Scott: If DNS changes because of blocking, return new IP
- ... e.g. new site IP being changed by blocking software
- ... Assuming we got a volume of them, we'd investigate.
- ... Regional issues would have a high volume of reports
- Martin: #105 has a good proposal
- Ian: Removing fields when not relevant, e.g. removes server IP from DNS-based reports
- Yoav: You'd get resolution and connection would fail, in non-blocking scenario and IP is relevant
- Neil: Our perspective, we don't use most of those fields (with strikethrough)
- ... We operate split mode, inside UK form own infrastructure and outside UK from CDN
- ... Either a redaction on IP, or ASN, or something
- ... Other fields apart from type, time, age
- ... Just in terms of URL highlighted, we need path, as different teams operate different areas of website
- ... We need to know whose area that was in
- Scott: But you wouldn't need that until you get to application-error reports
- Alex: I've heard various people say we need cookies to find X, path to find Y, DNS to find Z issues.
- ... We're more in favor of this than you might think, and are in favor of standard
- ... But something we'd be more likely to implement is if DNS issue, you'll receive anonymous DNS issues
- ... Would that be more useful than status-quo from our clients, which is nothing
- Ian: I think we talked about aggregated reporting, I don't rely on this information so I don't know if that would be useful
- Yoav: Question to Scott and Neil
- Scott: It's a sliding scale, the more information that would help, the better
- ... Slider to be useful, while respecting the boundaries
- ... Broad info available, but it's redacted is better than nothing
- ... Let's be as helpful as we can without crossing any boundaries
- Neil: Agreed
- ... Really know who to go to so they know to fix it
- ... But we absolutely side on angle of preventing privacy leakage
- ... We don't want cookies, headers, query strings
- ... We can make do without IP
- Alex: If I said let's implement this Reporting API where we send paths, queries, cookies
- ... They would say no, not a chance
- ... But if I said let's send anonymous network reports, they'd say that sounds useful
- Neil: If I said we want cookies and headers, we'd have rounds of legal review
- Scott: Our default position is to strip query string and fragment
- Alex: That can be in path as well
- Scott: Correct, we're trying to take a sensible solution
- Yoav: If I were you I wouldn't frame this as sending cookies to third parties
- ... This is the origin of the request delegating this information to a single reporting collection facility, which may be same- or cross-origin from that origin
- ... Distinction to be made here
- ... But I see where you're coming from
- Matt: It's an origin agent, delegate, surrogate
- Lucas: Our perspective at CloudFlare, we might not expose this to people running the site. We're trying to spot infrastructure issues itself
- ... Agree in data minimization, but things like IP address could potentially be useful depending on how things can be configured
- ... In scenario where you're reporting endpoint is independent of any CDN, multi-CDN situation, for some reason some place in the world connections are failing
- ... TCP or Quic layer might have something wrong
- ... Or during the connection something goes wrong
- ... Wherever we can, let's minimize
- Michal: In terms on anonymized aggregate reporting, has anyone crossed that hurdle yet
- Martin: Not for this
- ... Using it for telemetry (non web exposed)
- Michal: Chrome uses that as well, e.g. CrUX
- ... I just wonder if that's acceptable path to keep pushing towards
- ... I would worry about centralization there
- ... But for domain owners they now defer control
- Mark: We have someone in CF research looking into this
- ... They seem to be getting some promising results
- ... Using PPM for NEL, and 0HTTP
- ... Seem promising techniques, looking for collaborators
- Ian: There's definitely interest. Connect them with me
- Michal: Techniques don't worry me, what I'm thinking instead is moving all performance measurement to only anonymized aggregate reporting
- Yoav: Lot of things we're currently reporting that we'd like to move to aggregate (e.g. DNS resolution times)
- ... Potentially things we can't report for security reasons, we'd like to report in aggregate
- ... Same time, there's a lot of information loss when aggregating, and can restrict ways in which people can use performance data
- ... If we could do all that with zero loss of use-cases, that's great
- ... Barring that, as long as reported data is currently useful and isn't leaking privacy and security, no reason to move everything to aggregation
- ... Still very much in research, but not yet there
- Neil: If anyone knows if NEL is in scope for Privacy Budget?
- Ian: I am not aware, but can try to find out
- ... Alex, would it be useful to define if something was present but redacted, and UAs could choose not to report something e.g. "..."
- Alex: That would be a good way to go.
- ... Sending anonymous reports, when a web page won't open, is useful
- ... Not objectionable
- ... But sending identifiable reports is
- ... If there was an affordance for a UA that does not, that would be more helpful
- Ian: Better than not sending anything
- Alex: "You have a problem somewhere" is better than no signal
- ... A compromise is necessary to get any signal from us
- Martin: I think that's true for us as well
- ... In slides, one was redacting path and query
- ... Then error reports would be "for home page" which isn't correct
- Ian: If error collector is on different origin, then you should trim everything but the origin
- Neil: One possible concern with aggregate reporting might be timeliness - we ideally want to know about errors quickly
- ... WRT URL - we decompose into scheme, hostname, path - maybe doing that is good as it could be clearer which are redacted and remove processing burden from the reporting endpoint
- ... In our pre-aggregation layer reports, we don't know path, our group-by would be the hostname
- Ian: Could be a breaking change, would like to talk about how it could be deployed
- Martin: Make sure you can redact portions, then make sure you can decompose and pick out things relevant for you
- Ian: No but if URL field disappears or changes
- ... On privacy ones, clearing body fields would be a good idea. But not path
- ... Cookies I'm not sure, solutions from don't send cookies to redacting
- Yoav: Cookies on opt-in
- ... Only for Origins
- Martin: HttpOnly is interesting here
- ... Going over HTTP and to a server, they are highly identifying
- ... Not necessarily privacy reasons (we'd send to the same server), security risks with information in a different context outside of the one with controls
- Scott: Has anyone made the argument to keep this?
- ... We make efforts to strip this, don't want to keep auth tokens and secrets
- Neil: Agreed
- Yoav: Last time we discussed, at least one that wanted it
- Martin: Put comment in issue, request for feedback
- (in chat)
- Lucas: I want to know if wss:// requests are failing
- Neil: I’d love to see cookies removed
- ... Makes my life much easier
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Exposing arbitrary presentation times
- Michal: various paint timing issues
- … decided to refactor ElementTiming into PaintTiming, but there are some long standing quirks and issues RE interop there
- … also we’re hearing feature requests from developers RE paints
- …
- Element timing have an implicit time origin
- LoAF for a setTimeout, there could be a delay between the time the task was queued to when it was executed
- … Even for ElementTiming, the resource has to go back to the main thread before it was presented
- … These APIs expose rendering animation times. For paintTiming TODO
- … startTime can mean any one of these things in any of these APIs depending on the entry
- … this can be confusing and also a source of interop issues
- … Could we apply consistent labels to this - maybe we can add consistent labels to each of these.
- … Already do this for LCP - the startTime value depends on context. Best available value.
- … The concept of “contentful” - there isn’t just a single paint that matters
- … e.g. for animated images you may want to know the first frame, but also the last frame when the image was fully loaded
- … can mix concepts TODO
- … FCP vs. LCP - the same element may have its first frame as FCP, where LCP would expose the fully loaded time
- … Non-Chromium browsers - the FCP algorithm would have a first paint that initiates a decode and then a paint that commits the decoded image. Interop differences RE which paint is reported
- … so FCP timings have different semantics in different browsers
- … Something to keep in mind
- … missing use cases
- … User interactions with async effects - the browser dispatch events and we measure the next paint with event timing
- … But if the event triggered a Fetch, where the continuation did something, there’s no way to measure that continuation
- … Developers would want to know the end-to-end time of that response
- … Very common pattern in frameworks - they’d lazy load the interaction, causing the browser to lose its ability to measure
- … JS-driven rerenders is the other use case TODO
- … Request #1 - get the next paint time
- … We don’t have requestPostAnimationFrame
- … Can add ElementTiming, but this only gives us the first paint
- … Request #2 - can we improve Element Timing
- … Doesn’t work on a containing element, doesn’t report on child nodes
- … Folks want to know when the page is visually complete, but that’s hard
- … Allow resetting of FCP/LCP algorithms
- Questions
- Benjamin: In terms of next paint time, after FP, LCP, or something else?
- Michal: after the page is settled, the page state changed, and the developer wants to know how long it took, so right now you can measure when the JS ran, as well as a rAF, but you don’t know how long it took
- NoamH: GetNextPaintTime might be a very useful API. My understanding is that you can just run JS and get a timestamp for the next paint time. Is that it?
- Michal: Haven’t evaluated proposals and tradeoffs, but probably a function call or an observer. Async callback
- … Or resetting FCP and getting another.
- NoamH: regarding interaction with an async effect. Trying to tackle it with existing APIs and it’s not a trivial effort. Trying to make it work with heuristics, but being able to natively correlate interaction and a resolving UI change would be great
- Michal: If an event handler supported a SW-like waitUtil, where you can pass a promise to the event itself, that could help the browser know when the event was complete.
- NoamH: Meaning my effects from going to the network, other async work, etc
- Michal: Just for async work
- NoamH: Common that work can split across multiple executions
- Yoav: Regarding promise pattern, we could also use Task Attribution to get the same effect
- Michal: With Task Attribution you don't know when it's done
- Yoav: You need termination support
- ... Hard in current implementation
- ... I can think of ways we can improve that potentially
- Sean: I agree we should try to have a clear definition of timings
- ... Last year we had an Interop proposal
- Michal: Interop proposal wan't accepted but we thought it was useful work to be done
- ... We can try again
- ... We don't need an Interop project to do this work
- Yoav: It does motivate some people
- Michal: We can try a proposal again
- Sean: existing APIs are browsers telling developers about events, but request paint time enables developers to get information by themselves?
- Michal: One is pushed out by the browser, the other is pulled by the developer
- .. .maybe we should limit the rate in which you’re getting that pulled information
- … but not allow it for any single frame, not sure
- … but this enables developers allowing developers to do their own telemetry
- … both are important
- Thomas: we just monkeypatch lots of APIs in order to figure it out ourselves
- Michal: Polyfilled with rAF and setTimeout, and that’s costly and cumbersome. But no rate limit
- Sean: Should be careful here
- Michal: Favorable of a narrowly scope proposal
- … don’t want to play whack a mole as different developers do different things
- … but async events are here to stay
- … many frameworks that will lazy load your event handlers which will just make it hard to measure. Developers have no control
- … there’s a world in which every first interaction is lazy, and that’s great for perf, but we need to measure that
- … LoAF can plug some of that, if you don’t care about events that are first
- Yoav: hard to measure async stuff, the browser is not aware
- Michal: Event Timing and LoAF are not identical. Event Timing could be not long
- Michal to file issues and link to these notes

.png.webp)
.png.webp)
Soft Navigations update
- Yoav: Update on Soft Navigation effort
- ... Talked about this for a while, TPAC '21, '22, Oct '22
- ... Want to give an update on progress
- ... has moved from personal repo to WICG
- ... Spec skeleton
- ... Relies on Task Attribution which is also hand-wavey spec'd
- ... Model that can be specified in relation to HTML event loop
- ... We ran on OT, weren't a lot of active participants
- ... But late-entrants ran some comparisons
- ... SpeedKit ran comparison between running Next.js app as SPA vs. MPA and see which is faster
- ... Interesting result was MPA was faster. Anecdotal, but type of comparisons I'm aiming for.
- ... Great confirmation
- ... I fixed a bunch of bugs as well as holes in heuristics and task attribution that it relies on
- ... We are kicking off a second Origin Trial (OT) in Chrome 117
- ... Use-cases
- ... Enable folks to know if their input delays or EventTiming issues or layout shifts are related to specific routes in their SPA page
- ... All reported vs. landing page, problems in specific routes
- ... Developers can't know that unless they're using History or Navigate, whereas this will tell them if they have a problem
- ... Beyond that, we want to know if there are load-related entries e.g. PaintTimings on Soft Navigations
- .... FP, FCP, LCP main goal here
- ... User-initiated interactions such as clicks, resulting in URL modification + DOM changes
- ... Modifications can be async
- ... If a fetch did something else, that took time, that did DOM/URL modification
- ... That is being tracked and taking into account
- ... When those things are detected, we fire LCP, restarted with size of 0
- ... The origin trial initially also exposed FP and FCP, and there were some issues with that in terms of history leaks that resulted in pulling that from the OT
- ... Effectively we have the :visited attribute, which is a pothole in platform, and rules which CSS selectors can be applied to :visited links
- ... But effectively there's a leak related to :visited that was possible with FP and FCP exposed
- ... Ongoing work to partition the visited link as the last cache in the platform that's cross-origin for some reason, to get rid of this cross-origin state
- ... This could potentially enable us to re-enable FP and FCP
- ... At the same time, there are conversations with security folks about this and exposing arbitrary paint times, they still have concerns in a world where cross-origin resources can be loaded before 3P cookies can be deprecated and in non-Cross-Origin-Isolated contexts
- ... Challenges
- ... With CSS-only soft navigation
- ... Looks at DOM modifications
- (demo)
- ... This looks like a soft navigation, but all transitions are CSS only
- ... No DOM modifications
- ... Heuristic doesn't pick that up as a soft nav
- ... Fixing this would require some changes to heuristic
- ... Question on defining navigation
- ... Picking options such as color changes e.g., the price
- ... Is this a navigation or a modification of the existing one
- ... Second example on right, different options change the image
- ... More people think it's a navigation, subjective call
- ... One option is to tie in some sort of rendering input into heuristic
- ... Working change for text
- ... Image content is a bit more complex
- ... Doesn't seem impossible, just more complex than text
- ... If we're doing that, what is reasonable threshold
- ... Some percentage of viewport painted
- ... Or all of the above?
- Questions
- Ian: For the CSS only one, did the URL change?
- Yoav: User interaction changed the URL, the visibility=hidden on the current tab, and changed visibility on tab user clicked to move over.
- ... Transform to move things outside the screen to inside
- ... CSS animation to move tabs around
- ... User's perspective they don't care
- Barry: What's the problem with that?
- Yoav: URL changed but no DOM modifications
- ... Anything that triggers a style recalc, we need stronger signal than style has changed
- Michal: IIRC main reason for DOM modifications, e.g. fragment navigations
- we didn't want to trigger Soft Navs
- Yoav: Clicking an anchor that only move the page around, we may want to take that into account
- Nic:
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
- Some of the issues are common to what boomerang does
- History / pushstate, then we got to the point where the customer was doing…
- We tried to do more things automatically… now its a long tail… today we basically just ask customers to use API to let us know
- Yoav:
- There is nothing in the navigation API that forces it to be a navigation.
- Don't’ want to be any different than history.push()
- Nic:
- Could we have something similar that is more powerful
- If it becomes to complex it may report “too much”
- Yoav:
- The goal here is to be able to collect this information at scale, on existing content.
- Adoption of new things will take time.
- Also, when it comes to accuracy, we can do more to improve heuristics to plug holes
- ...but maybe a developer signal can help here.
- Nic:
- My feedback is simply that trying to handle all heuristics may be difficult, because we had to try and we backed off.
- Also for interop and polyfill, it would be better ot have a developer signals
- Yoav:
- Sure, but this is equivalent to User Timing with conventions
- Michal: Comes back to a previous discussion with Sean, the developer asking for data vs. pushing data
- ... The developer knows their own site and they should be able to do this
- ... One does not stop the other
- Yoav: The bit that scares me about that, is that we have a definition for LCP in code that if we give developers the ability to reset LCP
- ... Adds complexity
- Nic: Can't they just change URL and modify DOM
- Yoav: Yes but requires user interactions
- ... Polyfill available
- Michal: LCP is very useful because it matches SpeedIndex
- ... But if you had a developer API, would you want LCP
- ... Or Container Timing
- ... Maybe we want both, and they don't overlap
- Yoav: LCP for this vs. "official" LCP
- ... How can developers use this information, vs. third-parties using that information
- ... Think about complexity this adds
- ... Could be valuable use-case
- ... Requires some thought
- Barry: Going back to example of ElementTiming, depending on whether you want the content you're interested in or the largest one
- Michal: Most developers I've asked aren't aware it exists
- ... Inconvenience of ElementTiming gets in the way (container doesn't apply to less, applied to thing already rendered doesn't work)
- ... Post-soft-Nav LCP already has issues
- ... For a developer to be able to say some time point, I've applied a visual update and I'd like to know it's visually complete, using LCP to get that is imperfect
- ... Equivalence with Hard Nav LCP, all those reasons
- ... If it's a developer API, you want a better Element Timing
- Yoav: One thing I forgot to mention, exposing FP and FCP, visited links, etc
- ... The same discussion applies to proposed APIs Michal talked about
- ... Origin Trials and bug bounties are for
- Michal: Click vs. keyboard, EventTiming has concept of interaction
- ... Use-cases of Soft Navs vs. ones you're listing
- ... Are there any reasons not to?
- Yoav: Would be nicer to rely on interactions from EventTiming rather than reinvent the wheel
Day 4
Z-standard on the web
- Nidhi: working with Adam on z-std on the web
- … zstd is a fast lossless compression algo
- … in the browser we’re expecting most benefits for first view dynamic
- … Accept-encoding in the request
- .. used by Meta, Akamai (log storage), Android
- … performance benefits - zstd provides better compression ratios for dynamic ratios (better than gzip 5)
- … similar times can result in smaller payloads
- … faster decompression across the board as well
- … current status in Chrome. Behind a flag in 117 and running an experiment
- … seeing good results in beta
- … beta data is not necessarily representative of real users
- … shared zstd is also available in 118 (requires the OT)
- … one issue we’d like to discuss
- … backrefs are instructions that the compressed stream indicates to copy from an earlier point in the stream
- … Window for backrefs is a sliding window, and the sliding window has to be in memory
- … larger window => better compression
- … gzip gives us 32KB windows, z-std supports windows up to 2GB, but we can’t store 2GB in memory
- … So there’s an issue around defaults. Zstd defaults to 128MB window, but can request a smaller window size
- … Chromium accepts up to 8MB window size, leading to errored stream and unloaded resources
- … naively creating your input with the zstd command line any file larger than 8MB would not load
- … Initially didn’t put that limit, but based on a recommendation in the RFC, someone from Meta provided a patch to reduce that. The recommendation is about accepting data from untrusted input
- … So there’s an interop issue - need to make sure all browsers align on the same window size
- … developer usability issue - default settings won’t work with large files
- … 7MB file would work, but a few months later if the file grow, things will break
- … Wanted to discuss potential solutions to this problem - make sure implementers align
- Alex: Since different UAs might accept different window sizes, do we want to put the window size in the accept header
- Yoav: can reduce caching due to variance in cases where it doesn’t matter
- Barry: In theory the number of encoding types can increase. But most browsers would settle on a few values
- Alex: the RFC already recommendation
- Yoav: Ideal if implementers of web browsers can decide on one value that works for all of us, and we can code this somewhere
- ... Not sure where that somewhere is?
- ... Latch onto RFC rec?
- Ian: Browsers in 10 years might be hobbled by the decision we make now?
- Michal: Were you tying that to Alex's suggestion? zstd8 vs. zstd64 in the future
- Yoav: Sure, as long as we don't have 20 of those
- Michal: If you're going to cancel the stream if it exceeds 8, then accept-encoding ztd8
- Barry: If the stream is canceled, can you re-request as br or gz?
- Yoav: Retry at app layer
- Barry: This is a bad thing
- Adam: In IETF land, there's one solution which is to standardize ztd8/16/64/128/256
- ... An alternative might be an errata against the existing Zstd RFC, saying Zstd encoding with an 8 MB window size, and we meant that all along
- Yoav: Future could have zstd64
- Adam: 8 MB is pretty big, even 8 MB makes me somewhat uncomfortable since we can have 100s of streams going on at once
- ... 8 MB feels the right compromise
- ... 128 MB feels very big indeed
- Pat: If I’m seeing it right, and CLI defaults to 8MB unless you specify the long
- … and there was a discussion of not going about 8M by default
- … Looked into curl and what they are using for accept-encoding
- Adam: It’s easy to set different window sizes
- Eric: changing the tokens is interesting. Describing a property of the resource is weird. You’re really saying you’re willing to take smaller or equal to 64. Would be good to determine that 8M is the ideal value based on data.
- Barry: What's the window for brotli? It’s up to 60MB. Do we support that?
- Adam: I’m assuming that’s the case, which would go to argue we should support the same here
- Barry: Interesting to find out if there’s prior work or issues
- Adam: There are diminishing returns when increasing the window. Separate situation with shared dictionaries. When the dictionaries are larger we use a larger window size, to make sure the dictionary is useful
- Michal: On CLI, does it allocate an oversized window?
- Adam: Depends on the file size
- Michal: So impossible to need a larger size?
- Ian: decompressed size, not compressed size
- Adam: This makes the developer ergonomics tricky. As files can increase size over time
- Michal: Are there compression tools that are sophisticated enough to test different window sizes?
- Adam: I don’t think they do that. It’d require multiple paths
- Pat: Worth discussing at the IETF WG. In a server situation you’d be allocating 8MB per stream. Incentive not to go bigger.
- Nic: zstd command line tool, CDNs that compress it. Would be good to settle on a fixed widow size. One supported max window size
- Ben: Why are they supporting window sizes of up to 2GB?
- Adam: wasn’t there. Maybe there are use cases. E.g. shared dictionaries. If your shared dictionary is 1GB that can be useful
- Pat: It’s also an archiving format, so in that case you can want huge backrefs for those cases. Not a web case
- Ian: The sliding window is in the decompressed data. Are we keeping that separately from TODO
- Adam: technically possible, but incompatible with how the cache works
- Pat: Architectural issues - some data is in the network part of the code, other in the renderer
- Nic: Where can we continue the discussion?
- Adam: We can open an issue on webperf and then file an errata on the RFC
- Yoav: The main point with Accept-Encoding is checking what curl, wget, etc
- ... We need to ensure compatibility with that
- Adam: Though if cURL is accepting 128MB that doesn't mean they want to accept 128MB
- Yoav: We'll need to figure out a plan that works for them
- Erik: not a breaking change for CURL
- Patrick: My guess is it's a non-issue and we just need an RFC update
- ... I'd be surprised if cURL allowed a larger back window than that
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
LCP and animated media
- Ian: Update on how Chromium is supporting animated content in LCP
- ... Update the spec so other implementers can do the same
- ... Status quo is that video content is effectively ignored
- ... Even though video-heavy sites this is the most important content on the page
- ... We'll take into account poster images since they're images
- ... Doesn't catch auto-playing videos
- ... Videos with sound can't be auto-playing, so an interaction to start, and interaction stops LCP algorithm
- ... For those cases, this won't be an issue
- ... But for autoplaying videos, we miss this entirely
- ... At the same time, animated images, they trigger LCP at the "wrong" time
- ... Only issue LCP candidate once the image is completely available (whole thing downloaded and encoded)
- ... For larger animated images, this can be long after it's started
- ... For some animated streams, you can send content forever (so no LCP)
- ... In Chrome 116, videos and animated images trigger LCP candidate the first time a frame renders to a screen
- ... For videos that's poster or actual video content
- ... For animated images that's the first frame
- ... announced on all the channels - want to make sure people are aware of this. As it can effect your LCP scores
- … It resulted in roughly 1% drop in LCP. Some challenges in specifying this
- … Animated images are mentioned in the spec, but animation timeline is not defined at all
- … similar to video. May need to extend this in Element Timing. Want to add these timings to Paint Timing. Need to add these hooks as places where we fire
- … Should we extend ElementTiming to also fire the first frame of animated images and videos?
- … Michal talked about the different paint timings. Let’s discuss!
- … Questions? Concerns from LCP implementers?
- Ben: Current chromium behavior is unspecified?
- Ian: Yeah, working on specifying this
- Ben: How do you expect other vendors to deal with this?
- Ian: Would be great to work with you to get the spec matching the implementation
- … We’ve been talking about this
- Yoav: I think it would be relatively easy to hand-wave language that says things about first animated frame of animated images and videos in LCP and add to the spec
- ... Good first step to help cope with this change
- ... The bigger question is properly specifying this requires more infrastructure on animated images and video that's not in HTML spec
- ... Requires work and consensus to get it there
- ... In my view, hand-wave what we're doing in LCP
- ... Become more specific and precise over time
- Michal: Wanted to ask, all the major browsers support FCP, have we dont any testing where this is the only content, what FCP would do today?
- ... Timing of the first frame that's contentful enough, is the same time we'd want for FCP
- ... Is that spec'd or unspecified
- Ian: Haven't looked to see how FCP is spec'd for these
- Michal: I would guess, if the only content is a giant animated image or video, FCP would still fire on all browsers
- Benjamin: Does this include SVG animated images
- Ian: Does not include animated SVGs
- Yoav: SVG images, and SVG elements, the former is included, the later is not
- ... I don't think SVG element images can be access through script and animated
- Benjamin: Why did we do animated images before SVG elements?
- Yoav: Seems like more content on web today has an animated image as a LCP element than a SVG element
- ... That's why prioritization
- Michal: Animated gifs not main motivation, videos were
- ... SVGs are difficult, easy to make large quickly, you could break whole heuristic of LCP
- ... Not just size of the element, is it contentful content
- ... Broad issue with SVGs
- Yoav: SVGs are supported in LCP, just not SVG elements
- ... Depending on the way it's embedded
- Ryosuke: How about Canvas?
- Yoav: Canvas not yet supported, added support for Canvas where you drawImage()
- ... Where you can just take that image size
- Ryosuke: Websites where canvases are the main content?
- Yoav: Tricky to reason about what the contentful content there is
- Michal: As page load, larger content appears, you get larget timing
- ... In case where a canvas doesn't get reported, you using the representative LCP that loaded earlier
- ... Site feels earlier, reported to have loaded faster
- ... Video is more representative of real loading of the page
- ... Only in cases where video loaded after existing LCP and is larger
- ... Useful for large canvas site owners to know why it was slow to load
- ... Owner of canvas can measure draws
- Barry: Things missing from LCP, animated content, videos, canvas, SVG
- ... We're fixing animated content here, videos
- ... They're all separate things that aren't supported yet, we're making progress
- Ian: Paint timing does handle videos and just mentions the first video frame being available?
- Ben: Do we know when is the last frame?
- Ian: No. The first frame is only reported for FCP. This text may be sufficient for LCP as well, we can probably use something similar
- Michal: So for Video element LCP, we’ll fire something similar to that
- … For element timing, we report the last frame loaded
- Barry: Similar to the FCP case. I may be interested in the last frame, but TODO
- Michal: thinking through, reporting the last one doesn’t make sense. It could repeat, etc
- Ian: Should we change Element Timing to report the first frame?
- Michal: Yeah, or report multiple timings. If not, the first makes sense to me
- Barry: I don’t like divergence, so it would be good to align Element Timing on that.
- Ian: We’d have to extend it so that you could put Element Timing on the video element
- Barry: currently reports poster, but not the video
- Michal: What about TAO on animated images that are rendered before they’re done loading. We fallback to load time right now. It’s always the case that the render time value is larger than load, and in this case it won’t be.
- … we expose load time, but animated images can progressively load
- Barry: knowing when you had enough to present the first frame exposes data we can’t expose for cross origin images
.png.webp)
Accessibility metrics
- Ben: Introduction for experimental work from Mozilla that we're doing
- ... Trying to come up with performance metrics for measuring how web browsers interact with accessible technologies
- ... Hoping for a lot of discussion
- ... How are we performance testing accessibility?
- ... Talk about work in W3C going on at different groups
- ... Some of the work we're doing at Mozilla
- ... Problems and challenges we're finding
- ... Motivating question
- ... Performance teams and accessibility teams at Mozilla are trying to solve this issue
- ... How can I evaluate new web content for this?
- ... What tools does webperf give me for this?
- ... How do I avoid things that are known bad?
- ... Web users who need accessibility tech is increasing (demographics, COVID)
- ... Accessible Technologies (AT) include screen magnification (most used), screen readers, on-screen keyboards
- ... That's how we approach and size it
- ... 10k ft view, in browser you load document, create DOM, you create a separate Accessibility Tree to deal w/ an accessible device
- ... Work at W3C for this issue
- ... In webdriver
- ... Integration in WPT test suite as part of Interop 2023
- ... Nice initial momentum here, going to continue into 2024
- ... Test harness part of this is starting to be solved
- ... Parts being solved are more performance in practice, and not "is this performant"?
- ... This is all lab testing, not RUM testing
- ... First thing is we ran page load tests w/ a11y on, then off (results are, with no screen readers, we're hoping to see browsers not incur a huge overhead for just allowing a11y w/ no AT)
- ... Second thing is page load time w/ a11y on, AT active (screen reader), this was instructive for us because we wanted to see how existing web perf dealt with this
- ... Could we use things like navigation metrics, does it correlate with accessible user's behavior
- ... When discussing internally with a11y team, and they're trying to make our implementation faster, they desired other metrics
- ... We branched off into (3) where we have internal metrics just for Firefox, where we're measuring real details of our implementation (not applicable to other browsers)
- ... Just a measurement to make sure that work was making things faster
- ... Instrumented Accessibility Tree to get those timings
- ... e.g. first cache update of a11y tree
- ... Those internal metrics were helpful in terms of understanding if we're doing the right thing, going in the right direction
- ... Doesn't solve the motivating question, how can web users test web content without lab setups
- ... In discussing with a11y team, after working through problems, consensus emerged, what would be useful for web developers?
- ... "how big" is the a11y tree? We haven't implemented that yet, but could be a performance metrics
- ... Would help solve motivating question
- ... One thing we thought would be useful, is similar to early web perf, TTFB.
- ... Coalesced around solving motivating question, could be started by Time to First Speech
- ... Accessible User, w/ screen reader, loads a page, when do they first hear that screenreader start to speak?
- ... Generally useful, we think this is a metric the public would want
- ... Ran into a lot of questions, comments, problems
- ... Screen reader behaviors vary by platform
- ... Often installed on OS, screen readers different on Windows, Mac, Android
- ... Not sure we can configure screen readers between platforms so we can have fair comparisons
- ... On Linux starts reading after a paragraph
- ... On Windows it reads the whole document
- ... So we may not be able to do platform-to-platform comparison
- ... We're hungry for industry feedback
- ... What are other people doing? Are we in the weeds here?
- ... We feel like we're a little alone here
- ... Want feedback and have industry best practices here
- ... Is this in scope for group? How does it fit in with other webperf APIs?
- ... Shaping it like NavTiming, is that correct?
- ... Is there a better approach, or something obvious we're missing?
- ... Would love feedback
- Barry: If the intent is to measure TTFS, we don't build a11y tree if there's no screen reader. Is this a privacy issue?
- ... Make a lot of effort to make sure you can't measure that
- Ben: Because only in lab, we haven't been focused on that
- Barry: Are there certain assumptions someone would make if a11y was detected, could give different content based on the person
- Yoav: One thing that would make it slightly less of a problem in this case, is you're not giving an explicitly "i'm an accessible user signal", so people are less likely to use as a content negotiation method
- ... Many reason AT is built, not all are a11y related, e.g. password managers
- ... Still look at it as a performance signal, but not a accessible user
- Erik: On Windows, turning a11y tree is a big overhead
- Ben: We don't want to make accessible users vulnerable on the web
- Yoav: What were the results of running AT on/off
- Ben: We ran it with ? on ? off, both Chrome and Firefox had low-overhead implementations
- Yoav: What's the overhead of AT construction?
- Ben: Can be significant
- ... Wikipedia entry for WW2
- ... Before we started working on caching, delays of 14s+ before screen readers started
- ... Severe impairment for disabled users
- ... Unacceptable, we have to fix this
- Erik: Privacy concerns doesn't make it too difficult, increasingly novel ways like aggregated reporting or MPC
- ... Browser vendors use their own telemetry systems
- ... Even if it doesn't work out as a web-exposed way, internal usage
- Ben: Do you think on the privacy front if users could opt-in would that make a difference?
- Erik: Is the user able to understand the choice they're being asked to make? Probably not
- Barry: Last year we had the accessibility team at WebPerf WG, motivated by same things
- Yoav: A lot of interest
- ... On some platforms the screen readers start reading per document, there's no progressive rendering for screen readers?
- Ben: Exactly
- Michal: Have you thought about or started looking at a11y for interactions?
- Ben: Not yet
- ... Right now we're only using MDDA in Windows, a hack puts in a timestamp in the log
- ... Not something that can be done for end-users
- Michal: I haven't done extensive testing, but some testing with INP e.g. w/ screen readers
- ... A lot of overlap, mostly works, I've wanted to follow-up more
- ... Some screen readers do interesting things, like they take AT from previous state and it creates a new AT eventually, but it'll predict what happened
- ... Trying to get ahead of the game
- ... Interacting really early before first AT is generated
- Ben: Not sure that's possible
- Michal: More testing necessary
- Yoav: Going back to progressive rendering
- ... 5 years in the future, we report these numbers
- ... We have aggregate reporting so no privacy issues
- ... Unclear what you tell developers to do?
- ... On same browser even, different platforms behave different
- ... As a web developer you may want to do different things for Firefox Linux vs. Firefox Windows
- Ben: We'd like to help web developers
- ... If we can't make a web facing metric, then we have to share what's in the lab
- ... Partial solution to initial question but not a full question
- ... How is the Chrome team testing a11y?
- Yoav: Don't have the right people in the room to answer, we can follow up
- Alex: Same answer for Apple
- ... I reached out to the right person
- Ryosuke: Main thing we found with AT isnt' initial load time, but with responsiveness
- ... If AT is being traversed, and JS runs, main thread is busy running JS, it won't be able to respond quickly
- ... We recently changed architecture so it can be thread safe, big improvement for us in performance
- ... Not sure of how measurements were done
- Nic: After the discussion last year, we started talking about the AT tree internally. Nothing we can do right now, waiting for any info to be web exposed
- … talked to customers to see if there’s interest. A few more advanced customers were interested, but still far out
- Benjamin: Time to first speech is ambitious, but have an internal metric Time to first accessible cache might be more feasible to do in the short term
- Ryosuke: Building the AT tree costs us 5-10% on speedometer. Specific content isn’t necessarily slow. Disparity between slowness for AT users and slowness for non-AT users
- Nic: Other thoughts - there are different regions and legal requirements. Could be interesting to consider if something like that can play into such requirements
.png.webp)
.png.webp)
.png.webp)
.png.webp)
.png.webp)
Joint meeting with WHATWG
- (copied over from https://docs.google.com/document/d/1V6_s_VsaWcI9J-ZATbIKKijn59JbVmRMsHXYyH29sho/edit#heading=h.9gswhzv85q2)
- Topic: Web Perf WG/WHATWG collaboration process
- Anne: WHATWG is considering adopting a "staged" incubation process, similar to TC39
- … recommend looking at that and seeing if it meets your needs for things that migrate into WHATWG
- … when things happen in HTML that Web Perf should be, we should notify a performance team on GitHub when there is a performance issue
- … alternatively, we could have a label that you monitor, which is what i18n wg does
- Yoav Weiss (Google Chrome): having a team that you @ sounds great
- Domenic: on the staged process, don't see them as hoops
- … you've been working well, this isn't a new requirement, just some optional structure
- Anne: It seemed like Yoav wanted more indication about implementer sync points, which the staged process provides
- Yoav: for moving into WHATWG, we'll have to integrate with staged mold
- Anne: read it and see
- Yoav: when we have a feature implemented in multiple engines and there is consensus but it makes sense to move the processing model closer to HTML, does that start at stage 1?
- Anne: that's stage 3, or maybe stage 2
- Domenic: maybe 2 given level of spec maturity, using example of preload
- Yoav: okay, so decide which stage things should be in, no need to climb ladder
- Anne: the whole process is optional; you can still send a PR under the existing working mode
- Domenic: recently you've been doing a good job with HTML integration
- … upstreaming monkey patches, moving things into HTML wholesale, etc
- … other groups should emulate this
- Anne: call the team "perf"?
- Yoav: 👍
- Topic: fetchLater
- Yoav: this started as unload beacon, then PendingBeacon, and then feedback led to the current API shape which seems to have more consensus: fetchLater
- … the API is built around Fetch primitives
- … it would have been great to get that feedback earlier; what could have been different in our process to bring that feedback earlier?
- … I know that review bandwidth is scarce
- Alex Christensen (Apple): part of it is my fault, sorry
- Yoav: Is there something systemic that we can do?
- Anne: originally it didn't really seem like a new Fetch feature; if it had an issue on the whatwg/fetch repository would have been natural
- … still not a bad idea to talk to the fetch community when doing things related to fetch
- Domenic: maybe it should be a principle that if you're doing requests, talk to Fetch
- Anne: TAG isn't looping in domain experts for things like crypto and Fetch, which could be better but is hard
- Olli: Did PendingBeacon go through TAG review?
- Domenic: TAG gave feedback after 5 months that was not addressing this sort of issue Pending Beacon API · Issue #776 · w3ctag/design-reviews · GitHub
- Yoav: early review is still open about a year later
- Domenic: my proposal would be if you're starting a new fetch via a web developer exposed API, especially if it's generic, probably talk to Fetch people
- Yoav: private state tokens is also doing something like that
- Domenic: specs do need to fetch all the time; if you're introducing an API that allows developers to send semi-arbitrary or arbitrary data, maybe that should be fetch or look more like fetch
- Yoav: we can keep that in mind within Web Perf WG
- … maybe it should be added as a design principle, as you suggest
- Jeremy: it's more about process than design
- Yoav: maybe TAG or Blink process should be telling people to do this
- … spec PRs are coming along https://github.com/whatwg/fetch/pull/1647
- … any other concerns/topics related to fetchLater?
- Anne: I think we're in a pretty good place now.
- Yoav: OT ongoing or will be soon, with good feedback on previous API shape
- Anne: next time will hopefully be better
- Yoav: hopefully not another iteration of this API 🙂
- Topic: compression dictionaries
- Compression Dictionary Transport (WebPerf WG @ TPAC 2023)
- Patrick Meenan (Google Chrome): another pass at dictionary compression for content encoding, using previous versions to compress new versions, or side channel dictionaries for better compression
- … previous versions existed, this version hopefully better integrates with browser privacy models
- … any HTTP response can be used as a dictionary to decompress a future response
- … use cases are things like JS lib updated to new version (e.g., updated YouTube JS player library 60-90% savings on the wire)
- … in origin trial right now in Chrome
- … any response can include a Use-As-Dictionary response header which defines what it applies to, notably including a match pattern (likely a URL pattern) because URLs are often versioned
- … TTL is needed to avoid blowing up caches
- … when the browser sends a request, it looks at available dictionaries for that origin in that cache partition, sees if any match patterns match the URL about to be requested
- … if multiple match, it picks "best", currently longest string
- … if so, it will send a Sec-Available-Dictionary header with a hash of the available dictionary and the available compression protocol, currently Brotli and Zstd
- … Chrome 116 has Brotli, Chrome 118 also has Zstd
- … if server has a static version delta-compressed with that dictionary or has the dictionary available and can compress dynamically, it can indicate with Content-Encoding
- … client only advertises one dictionary, so server will either use that or send a full response
- … some discussion about explicitly indicating what dictionary was used
- … one thing likely to affect HTML is, in the case of a custom-built dictionary that has all my HTML templates etc, we need a way to trigger a load of a resource that would then have Use-As-Dictionary response
- … currently considering using <link rel=dictionary> which would download the dictionary at some idle time so that the network layer sees it
- … [examples on slides]
- … we have had history of privacy and security issues in this space
- … all partitioned and cleared with cache and cookies
- … oracle attacks have been the big problem where compression dictionaries can reveal information about either the dictionary or the resource
- … for this reason, dictionaries and compressed resources need to be non-opaque to the origin they're fetched from
- … spec-wise, we're working on the actual headers and content encoding in the HTTP spec
- … it clearly touches Fetch and HTML in some places; Fetch in particular touches CORS and [various other things]; HTML touches <link rel>
- … have had internal privacy & security reviews which we've cleared, don't think we've talked to PING
- … think we're in good shape, but still need to take it through the privacy team
- Yoav: re. HTML integration, it doesn't seem super complex
- Anne: dictionary needs to be stored somewhere, that sounds somewhat complex
- … needs to be integrated with Clear-Site-Data and other things
- Yoav: I believe it's tied into CSD, UI equivalents
- Patrick: whenever cookies, cache or site data are cleared, it's wiped out
- Anne: is it grouped under cache or under cookies?
- Patrick: it's in its own partitioned storage which mirrors cached, but is also cleared and follows rules of cookies
- … whichever is more restrictive at the time
- … in Chrome today, dictionaries are partitioned along with cache even though cookies aren't yet
- … if you CSD: cookies, cache, or *, the dictionaries are cleared in all such cases
- Anne: we could spec that, though it seems a little weird
- … definitely requires patches to several specs
- Domenic: is there a reason not to pick one? Like cache?
- Patrick: main reason is that dictionaries can be abused as an identifier, since the hash of the dictionary contents is sent and could be used to track individual people
- Domenic: is that different from HTTP cache?
- Yoav: you would need a timing attack for the HTTP cache; this is explicitly advertised to the server
- Domenic: okay, it's more explicitly like cookies in that regard
- Anne: if you cache a response and then read it from the cache, isn't that the same thing?
- … don't we have only-if-cached? Or force-cache? This is also CORS?
- Patrick: it's possible we were being overly cautious given the history in this space
- Yoav: can hash that out over an issue
- Domenic: I had concerns about navigation; have those been resolved offline?
- Patrick: we did reply; there is CORS tainting for subresources if it bounces but doesn't redirect
- … in the case of navigation, they are not tainted
- … as you follow each redirect, the partition for which the dictionaries are stored follows the partition for the current request
- … this is consistent with the cache
- Anne: the concern was a confused deputy attack on the target origin
- Patrick: what could be confused, since the dictionary has to be same-origin and has to be in the partition
- Anne: could be confused by the referrer in some way
- … same reason we have SameSite=strict cookies
- Patrick: I don't follow how a referrer could impact the compression dictionary for an origin
- Anne: origin creates the dictionary
- Patrick: and it's on the request to that origin, independent of what referrer it came from
- Yoav: final document is readable by the origin, regardless of how it got there
- Anne: we have SameSite=strict cookies for a reason
- … I would like someone to analyze why it's okay behaving like lax cookies for some reason
- Patrick: it's more like cache
- … we don't not use cache in case of a navigation redirect
- Yoav: need a more explicit explanation of what the confused deputy attack here would be
- Anne: some kind of query string that influences the dictionary creation in some way that the origin hadn't intended
- Patrick: navigations cannot themselves be dictionaries, they can only use dictionaries
- Jeremy: a document can use a dictionary but it cannot create a dictionary
- Anne: then it might not apply…?
- Yoav: confusion could affect content of a current navigation but not the content of the dictionary
- Jeremy: you'd also need a hash collision to be able to confuse decompression, since they're keyed by a content hash
- Anne: if the target content can't become a dictionary…I'd have to think about it again
- … creates a murkier definition in Fetch, because we have to know what the response is going to be for
- Patrick: fetch destination exists
- Anne: is it just a document? Document is only for top-level, so you also have to look at others
- … there might be a shortcut
- Tsuyoshi Horo (Google Chrome): request mode "navigate"
- Patrick: either way, seems solvable
- Anne: might also want to exclude WebSockets
- Patrick: we've explicitly excluded them, they have their own compression issues
- Anne: no-cors is not excluded necessarily, if it's same-origin and tainted, then it's fine
- Simon: if it's tainted, then no-cors
- Anne: tainted no-cors is not used
- Patrick: previous thing fell flat for multiple reasons, but one is that at the HTTP/2 layer there was no concept of partitioning, so oracle attacks could be done across sites
- … private data could end up in dictionaries, and you could see into opaque requests
- … since most of the use cases we care about don't need to do delta compression for opaque requests
- Yoav: at the transport layer, you could mix origins in a single HTTP connection
- Anne: I don't like that feature, though CDNs probably like it
- Yoav: any comments on the venue split, IETF, etc
- … I know on the IETF side there is some grumpiness.. Web model, dependency on CORS
- Anne: given what we just discussed, I don't see how we could avoid it
- Patrick: we could keep most of the CORS stuff out of the HTTP layer, because most of it's client-side at fetch time
- … the only place it is exposed is when you get a non-CORS cross-origin request where you depend on the ACAO response header – the server needs to not send a dictionary in that case, even though the client couldn't read it and would ignore it
- … so we do have a requirement in the IETF draft that if the fetch origin & mode are a certain combination, don't use dictionary compression
- … there is some discussion about making it advisory in HTTP
- … the other main heartburn is around URLPattern for matching, they already didn't like wildcards and the more complex processing logic around URLPattern isn't going to be popular
- Anne: re. URLPattern, can we restrict it to only path and query?
- Domenic: discussed that; I don't think it really helps
- … it just creates new variants of URLPattern, and you can get functionally equivalent results and if it's a different origin, it just won't match
- Jeremy: the server just emits it
- Patrick: the processing logic is all on the client, it would only affect other HTTP clients
- Anne: that means the server will parse it, server-to-server communication
- Patrick: if it is a client which is storing dictionaries, and wants to use this pattern, then it will have to do that
- … a lot of server-to-server cases will be using hardcoded configuration and won't need to parse the pattern
- Anne: IETF won't buy that you just emit this
- Domenic: I really think it's okay; URLPattern is well-specified and has a JSON test suite that any client could use
- … appreciate pushing through heartburn at IETF
- Anne: another question about the protocol – are responses identified other than with the dictionary
- Patrick: Content-Encoding
- Anne: do need to handle cases where you unexpectedly get a content encoding back, or if you get it for an opaque response
- Yoav: erroring seems likely the only option
- Patrick: failing hard in edge cases is the plan
- … will proceed with OT, file issues with Fetch and HTML
- Topic: isInputPending
- Yoav: WICG incubation which is part of the scheduling APIs
- … probably makes sense for it to land in HTML
- … at the same time, Meta folks editing that incubation are not WHATWG HTML workstream members
- … we'll have to figure out how that works
- Shuo Feng (Mozilla): if something is in WICG, editor can modify any time they want
- Yoav: commitments were given when that spec was committed
- … it's a portable license
- … anyone can modify the existing spec, but open question on whether one can take those contributions and integrate them into a WHATWG workstream without original contributors
- Domenic: my understanding from talking to steering group and lawyers is yes
- … we've done it with other WICG specs, like web components and navigate API
- … lots have had PRs from various people, and we've never tracked them down to confirm they're WHATWG members
- Yoav: are there mechanics about who should move things?
- Domenic: someone who is a member, typically add a reference to the previous license under Acknowledgments
- Shuo: need implementer interest to modify things in WHATWG
- Yoav: I'm not saying isInputPending has multiple implementer interest, so I'm not saying it will happen tomorrow
- … we expect in Web Perf WG that these things that integrate into the event loop will eventually target landing in HTML
- Olli: re. isInputPending itself, I wonder if WebKit has any feedback
- … your process and scheduling models are still so different
- … is it safely implementable in WebKit?
- Anne & Alex: don't know, ask ? or Ryosuke
- Yoav: in memory-constrained devices, yes, cross-origin iframes can be same-process in Chromium
- Olli: you might be able to know whether someone is interacting with another page in the same process
- Yoav: there was some work around mouse—
- Olli: more about keyboard event handling
- Anne: was this also the API that if you invoked it twice, might get different answers? Or was that different?
- … I think it returned shared state
- Olli: I don't think it has to be implemented that way
- Anne: oh, it is a method now
- Ryosuke: right now that would be hard for us to implement
- … we're not looking to implement right away
- … fundamental premise of checking if there is pending input seems like a good idea
- … I don't think we're opposed to the idea
- Olli: possible issues with cross-origin iframes when you're on a mobile device where the iframe might need to be in the same process
- Ryosuke: needs to be isolated by top-level frame to avoid a side channel, but that's true regardless of site isolation
- Olli: thinking about a pending keyboard event, change focus to the iframe
- Domenic: in spec, it's already partitioned because it uses agents as the largest possible scope
- Topic: Form-associated custom elements: being a submit button WICG/webcomponents#814
- Keith: web components have no semantics until you start applying them
- … as we're adding more behavior to things like buttons, things like popover
- … custom elements are diverging from that featureset
- … have added form-associated custom elements to get some behavior back
- … when new proposals add more behavior to built-in controls, component authors want to know how custom elements can participate
- … no concrete proposal, but question: how can web components be like buttons, have these button attributes?
- … we just had a conversation about slotted in CSSWG, where a similar topic arose
- … if you want to pretend to be a list element, how do you get to the required elements?
- … is there a more general solution? Do we need behavioral components?
- Domenic: if only there were some way to customize built-in elements…
- Anne: people also want shadow trees
- Keith: if you could have a shadow tree that pretended to a button…
- Anne: I made a somewhat concrete suggestion of adding something to ElementInternals
- Domenic: matching :default and participating in implicit form submission came up
- Form-associated custom elements: being a submit button · Issue #814 · WICG/webcomponents · GitHub
- … concrete proposal to put a submitButton=true on element internals
- … long discussion after that, and then Anne ended up with a similar concrete proposal, which was more extensive
- … then people arguing about activation behavior
- … new constraint: what about being a <button> button not a submit button
- … very last suggestion is elementInternals.button = 'button'|'submit'|...
- Anne: what we outlined there is a good way forward
- … it's okay to offer being a button or submit button, maybe also reset button
- Keith: concern from Web Components CG is that a lot of these are added imperatively but not declaratively
- Anne: we haven't yet tackled declarative custom elements
- … don't want stuff on <template> because that's the shadow root, similar concern with ARIA stuff
- Westbrook Johnson: if we were to add a button property to element internals, by default if you set that you get tab stop, roles, etc?
- … are you customizing a builtin by doing this? Are we reinventing an old idea?
- … we could just create, imperatively, the most complex version of customized builtins, by forcing them to configure all the element internals to make it happen
- Domenic: that is the idea of custom elements, though – you should be able to replicate built-in elements in JS
- Westbrook: there are implementers against is="", but if we're going to put that same API in a different, more complex, surface, then why?
- Anne: don't have the same limitations; a customized built-in can't have a shadow root, custom element name, etc
- … I'm not too concerned about the builder of the custom element having to use script
- … but don't want users to have something weird that doesn't look like an HTML element
- Westbrook: is button the right level? Focusing deeply on button seems like a misstep if you're open to this pattern. If I have to separately say that tabindex=0 and separately role="button", are you intending that a custom element has to set all of those?
- … or are you getting a different path to customized built-ins?
- … it would be great for people to get the functionality that's already developed by browsers, because a11y is great
- Anne: HTML already has a concept of buttons, which is how we say that attributes like popovertarget apply
- … that's a state an element can have, so exposing it on ElementInternals makes sense
- … maybe as we add more then there will be conflicts (e.g., you can't be a button and a label at the same time)
- Keith: valid concerns about developer experience, whether <button is="..."> is natural
- … we really need mix-ins
- Domenic: mix-ins are a bad API shape for inheriting particular behaviors
- Anne: ElementInternals already went down this path, exposing a bunch of state of form controls
- … we do need to consider possible conflicts, like buttons having a restore value or whatever
- … exposing fundamental states that elements have makes sense to me
- Keith: could you just say a custom element can't be a button and form-associated, but has some other link to the form
- Anne: submit button does have a submittable value
- Keith: intricacies around form-associated custom elements, might want to just say you can't be form-associated and also have a button
- Domenic: I'd go the opposite direction – allow as many things as possible, and only prevent when you have an explicit conflicts
- … maybe it's a little weird to have some things, but nothing prevents many combinations
- Anne: if you say something is a button—
- Domenic: there should be separate composable things for role, participates in :default
- … a11y, focus, buttonness, form-associatedness, etc are all separable
- Keith: currently too much work to do all that stuff
- … we can already do what buttons can do today
- Domenic: you cannot be a submit button or match :default today
- Joey: popovertarget?
- Keith: you can do that via script, but it's unwieldy
- … I understand that there are certain capabilities that aren't there
- Domenic: the custom element approach that we originally started was to work on all the low-level tools that let developers build as flexibly at they want
- … we added form-associatedness, we still haven't added focus
- … maybe this approach is a dead-end, and instead we should do high-level stuff instead
- … the original vision of custom elements was to expose these low-level capabilities
- Anne: it would be useful if saying you're a button in ElementInternals gives you a bunch of things for free
- … it seems unlikely you'd want to override them, and you can still do so explicitly
- Domenic: packages of defaults seems like a separate project, "customized built-ins v2"
- Keith: still means some kind of imperative API to elect to be a button
- Domenic: not necessarily, if it's a whole new project it could be declarative, like <button is="..."> which was declarative
- … Anne seemed okay with <my-button is="button">
- Keith: users of libraries then have to opt-in to that
- … are we talking about declarative custom elements?
- Anne: that's something WebKit would like to see happen, too
- … maybe we don't need an imperative API, but if you do, you might know roughly what the declarative APIs need to look like
- Domenic: we could add new low-level capabilities, or design packages of capabilities
- … in the latter case, do we do imperative or declarative first?
- Keith: tandem specifications for declarative and imperative
- … or some idea that they're going to happen within a meaningful time period
- … right now we have many imperative APIs but not many declarative APIs
- Domenic: because we have a foundation of imperative APIs, adding declarative APIs would be blocked on the existence of declarative custom elements
- Anne: need more imperative things, too, to solve the ARIA problem
- … don't want to block that on solving [declarative custom elements]
- Keith: we saw a good amount of work on attaching shadow roots imperatively but held up on declarative things
- … we still need JavaScript to be running to access imperative APIs
- Westbrook: one nuance on declarative vs imperative API is, it's not always clear that they can come out at the same time
- … when we're making imperative APIs, we need to be conscious of what would be necessary to make it possible to expose them declaratively, even if they don't ship at the same time
- … there's no clear path about how you would make ElementInternals declarative; it's hard to see how you could do that
- … doing something is definitely more important than doing nothing, but keep in mind how we could do that, so that we don't hit roadblocks if/when we want to build the declarative part of the API
- Domenic: sounds like people wouldn't want this PR even if we wrote it
- Keith: it feels like we're getting piecemeal APIs, which are welcome, but it seems not to be providing the bigger picture and I'm somewhat fearful that web component authors are going to end up with a huge block of code to set a large number of ElementInternals properties
- Anne: it's not that easy, even these things are somewhat involved to add
- Domenic: it would be a very large request of browser vendors to build a whole declarative custom element API
- Anne: incremental evolution feels like how we get there, rather than designing the whole thing from scratch
- Olli: we still need to anticipate what the future will look like, so we don't design bad APIs that won't work with that
- Keith: today it's form-associated and button behaviors, tomorrow it will be dialog behaviors, etc
- … to be clear, big fan of web components and would like to see it continue to evolve
- … don't want to stall because we can't come to an ideal resolution
- … as a developer, I would like to see more
- Topic: scheduling APIs
- Olli: would like to know: can WebKit implement these APIs, and how can we integrate these into the HTML specification?
- … it doesn't have the concept of priorities, etc
- Update on Scheduling APIs (TPAC 2023)
- Yoav: family of APIs to improve task scheduling performance
- … essentially, trying to reduce thread contention and, on the one hand, break up work and prioritize tasks that are being scheduled in ways that match what developers want
- … goal overall is to improve responsiveness and user-perceived latency
- … scheduler.postTask is the first – post a task with appropriate prioritization
- … without this API, users use setTimeout, postMessage to self, but no way to assign priority to this queue so high-priority tasks run first
- … underlying assumption is that developers will break up long tasks into smaller chunks and then prioritize those chunks appropriately
- … the API returns a promise and tasks posted are cancellable using TaskController
- … shipped in Chrome 94, used in up to 1.25%, polyfill using setTimeout and MessagePort
- … scheduler.yield: postTask assumes developers are trying to break apart work into different tasks, but in many cases developers have existing long tasks that they would like to stop and then continue without explicitly breaking them for convenience or sense
- … want to keep a continuous task if possible, but yield to browser when higher priority tasks, like user interactions or rendering opportunities, need to happen
- … this makes the app more responsive to input, and allow the overall task to complete faster than occasional setTimeout
- … hesitance of the part of web developers to yield because you don't know when you'll get control back
- … scheduler.yield provides better guarantees for when the continuation will run, so that other scheduled tasks will not get in the way even if you're yielding to input or rendering
- … inheritance: task continuation will inherit the priority of its parent task
- … future work planned for scheduler.render(), scheduler.wait(), etc, which is more speculative
- Domenic: can I have scheduler.wait yesterday?
- Olli: missing piece from spec of scheduling API – priorities haven't been defined
- … they have names, but no description of what happens
- https://github.com/WICG/scheduling-apis/issues/67 https://github.com/WICG/scheduling-apis/pull/71
- Domenic: PR in progress
- … it was vague because of feedback from Boris Zbarsky (Mozilla)
- Olli: HTML spec doesn't have a concept of priorities so need to add something there
- … at least Gecko and Chromium use separate task for rendering updates
- … the specification doesn't have that model, don't know about WebKit
- Ryosuke: yes, rendering update is a separate task in WebKit
- Olli: we should change that
- Domenic: it's not observable
- Olli: it might help in specifying these priorities, like the highest-priority "user-blocking"
- Anne: are you saying everything that happens in "update the rendering" is a queued task?
- Domenic: yes, but unobservable
- Anne: what about microtasks?
- Domenic: we flush them when the stack is empty, so not observable
- Olli: I don't think it's observable, but in order to specify the priorities we need to understand what is being prioritized before and after that
- Anne: might make that other algorithm more readable, since it's such a large step
- Olli: specifying priorities is blocking us from enabling the API anywhere else
- Yoav: TaskPriority enum – my imagination of integrating this into the event loop would be to add some kind of priority queue to the event loop to decide which task is being pulled next
- Olli: have to determine what is compatible with all of the engines
- … Chromium and Gecko seem to have similar models, but I don't know how WebKit works and what they think about the scheduling API
- … you mentioned in Web Perf WG that you can't always control your tasks that well
- Ryosuke: that makes implementing this API challenging
- … it's not impossible, though – we can schedule the ones that we have control over to respect these priorities
- … the biggest problem with this API is the lack of handling of priority inversion
- … you schedule something with low priority but something high-priority depends on it
- Yoav: developers already don't have that control
- Ryosuke: there are cases where you schedule something, you initially thought it was low-priority, but that situation may change
- … if you fetch some script asynchronously, it may not be important initially, but then later the user tries to interact with what that script provides, it is now high priority
- Michal Mocny (Google Chrome): TaskSignal can adjust the priority of a previously scheduled task, though you have to do it explicitly
- Ryosuke: AsyncContext seemed interesting and might address the issue
- Olli: our TaskController in Gecko can express dependencies between tasks, but we use it very rarely
- Michal: scheduler.yield alone has been incredibly useful; is that something that you could?
- Ryosuke: we would not implement
- Michal: could you run render steps and then continue, without actually yielding to the task queue?
- Ryosuke: Maybe.
- Michal: Key use cases for yield are for high-priority work, and then you resume immediately. In Chromium, new input events & rendering.
- Olli: based on spec issue, rendering defaults to normal priority
- … very high if you haven't rendered in 100 ms
- Michal: in chromium, for 100 ms we keep rendering at normal priority and then boost to highest, but then after any new input it automatically goes highest
- … a very common and important use case is for a long-running task in the context of an interaction to yield and be certain that rendering is a high priority
- Ryosuke: so just updating rendering wouldn't work because you'd have to process input
- Michal: a long blocking task might yield to input, which then yields to rendering
- Ryosuke: so yielding to rendering isn't sufficient; we would need to yield to input as well
- … we do some rAF aligning, but it's sent as a separate IPC so we have to yield back to the system run loop to process input
- … today, there is no way to implement something like that
- … it's not impossible, 5-10 years from now, but it won't happen anytime soon
- Michal: API is polyfillable, but ergonomics alone are valuable even if it backs onto setTimeout(..., 0)
- Yoav: but still pay the performance cost
- … as I understand it, nothing prevents postTask from being implemented in WebKit, but still a question about whether you're interested in implementing, but yield would be much more complex
- Ryosuke: Correct, yield would require significant work.
- Olli: in Gecko, we don't have yield implemented but it should be relatively easy to implement.
- https://github.com/whatwg/html/labels/agenda%2B