Participants
- Nic Jansma, Yoav Weiss, Alex Christensen, Sia Karamalegos, Charlie Harrison, Patrick Meenan, Sean Feng, Rafael Lebre, Dan Shappir, Tariq Rafique, Andy Lurhs, Barry Pollard, Mike Jackson, Hao Liu, Philip Tellis, Benjamin De Kosnik, Andrew Galloni, Amiya Gupta, Jacob Groß, Carine, Michal Mocny, Annie Sullivan
Admin
- Next meeting: December 7th (same time)
- (Not Nov 23, US thanksgiving)
- Discussion with Fetch folks around fetchLater(), will send an invite for interested
Minutes
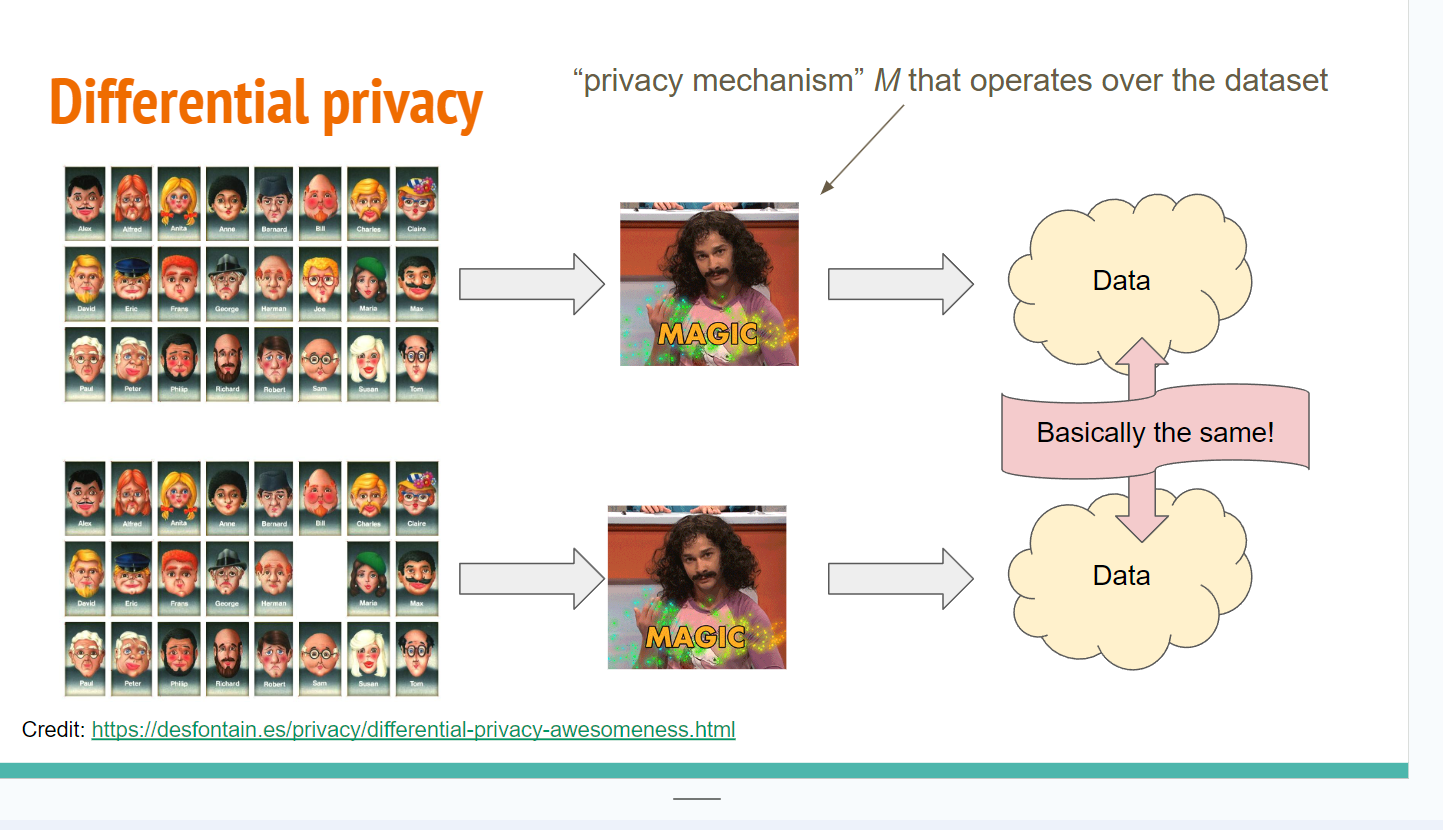
Differential privacy - Charlie Harrison
- Charlie: On Google Chrome team on Privacy Sandbox APIs
- ... Use a lot of differential privacy
- ... Familiar with the concept
- ... Extensive history, I can share references but we don't have a ton of time
- ... Operates on a dataset, a group of people submitting their data
- ... Raw data goes through a black box, outputs more data
- ... Guarantee that DP gives you is after the magic, you won't be able to distinguish two outputs if they came from inputs that different from one individual
- ... Whether you participated in the system or not is not going to change the end result in a formal mathematic way
- ... Assuming the parameters you choose are strong enough
- ... Looked over this proposal for bimodal navigation
- ... Local DP is something you're considering?
- ... Here we assume dataset is one user, example, row
- ... Want guarantee that whatever the input, the data looks the same
- ... If you can post-process this data in aggregate, you can get decent aggregate results, even if you look at one row from magic box and there's almost signal
- ... High-level intuition
- ... We want the input to not change the output
- ... Formal definition
- ... We have some randomized algorithm M that satisfies epsilon differential privacy if for all pairs neighboring datasets and for all outputs x, we show the probability of producing output is e^epison
- ... Mechanism induces a probability distribution
- ... We look at every point in this distribution and we can show they're close
- ... epsilon is measure of privacy loss
- ... We'll go over a semantic interpretation of what this means in a few slides
- ... When we think of a new feature on NavTiming, we can say that we want to make sure navigation is protected. Or whether we want to protect all of a user's navigations over a timewindow.
- ... Both parameters to definition are important to think through when designing a DP mechanism
- ... We want to ensure we have this relation holdforth
- ... A lot of math, but it's not too bad
- ... How do we interpret epsilon?
- ... epsilon is notorious for being hard to interpret
- ... Look at this in a bayesian sense
- ... Adversary has a prior on the user's data, and if they have the output mechanism, they look at the output to compare with how much it changes
- ... We can look at various values of epsilon to see how they update a prior
- ... For graphic, X axis is suspicion, prior
- ... Y is how that data looks after updating the data
- ... Most private mechanisms won't update too far
- ... When epsilon is low (purple) you're not straying too far
- ... Higher epsilons you're straying too far
- ... (examples on slide)
- ... Might be able to stare at chart and consider adversary you're trying to protect against
- ... Consider what priors they have for sensitive data
- ... And what comfort level data is sensitive to
- ... Less epsilon is more private
- ... As it goes towards zero, probably of any output is equal no matter the input (signal being completely removed from system)
- ... Most private is not revealing anything about the input
- ... DP is composable
- ... If you have two separate inputs and they've invoked over same dataset, epsilons add up
- ... If you're trying to protect nav performance and you have a noisy bit, and want to introduce another bit, you can sum epsilons that the privacy loss is of the combined mechanisms
- ... Post processing: Staring at output of DP mechanism and and trying random inputs is not going to cause privacy loss
- ... Group privacy: If you want to protect more than one user, a group, you can use DP as well
- ... Adding or removing a whole group of K people, you can protect and make sure their input is not overly affecting the output
- ... Useful for bimodal navigation proposal
- ... Compute flip probability based on epsilon parameter, you pick a random bit
- ... In above example, giving truthful answer 25% of the time and false 75% of the time
- ... Laplace invokes laplace distribution
- ... Not necessarily local DP mechanism
- ... Takes in as sequence of booleans, sum fhem up, centered around true value, scaled to epsilon
- ... Gives probably dist centered around true value
- ... Most of the time you'll get around 30
- ... How does this relate to systemEntropy proposal?
- ... Considerations when thinking of adding DP to something
- ... (1) Consider what is the neighboring relation, scope of what you're trying to protect
- ... Protect entropy of a particular navigation? Or lots of users' navigation
- ... Describe different kinds of protections
- ... (2) DP will add noise to the data
- ... Have to make sure noise is OK, don't want to ship something so noisy it's not going to be used
- ... Want to do research and vetting
- ... (3) Think about what mechanisms are available
- ... Two generate techniques, local DP vs central DP
- ... Think about the systemEntry as inducing a bimodal distribution
- ... Generated some random gaussian sample distribution
- ... If you naively apply response to histograms, you can get something scrambled and biased
- ... If we randomly flip every input, and put it in low/high histogram, it's going to be mixed together
- ... Mass from low-entry bucket moved to high-entropy bucket
- ... Now looks like high-entropy is more performant than the real answer would be
- ... Ways to de-bias data
- ... What this would look like after using unbiased bucket estimator
- ... Third graph similar to the first one
- ... Overall not terrible
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Bimodal navigation and fuzzy dimensions - Mike Jackson
- Mike: Brief overview for folks
- ... Goals are to allow developers to eliminate outlier metrics when user-agent is in a non-optimal performance state
- ... Data indicates that delays can happen any time in navigation pipeline
- ... Avoid being a real-time method to determine if a user-agent is in a non-optimal performance state
- ... Current code checked into Chromium
- ... Origin Trial in Edge
- ... High level feedback:
- ... No one likes the name
- ... Concern is as more data gets added, value degrades over time
- ... Defining UA startup is difficult
- ... PerformanceTimeline shouldn't be used to detect info yuo can't get in other ways
- ... Need to expose in privacy preserving way, avoid side-channel attacks or user-fingerprinting
- ... Proposed changes:
- ... Rename to navigationStartedDuringUserAgentLaunch (boolean)
- ... Should we expose this off of navigator or performance object?
- ... The preserve privacy use DP?
- ... We have good data with systemEntropy
- ... Proposal is to adopt DP changes first, run an OT
- ... Look at changing name after it's finalized
- ... Proposal to adapt randomized response algorithm
- ... Verified DP algorithm's output, truth 75% of the time
- ... Proofs play out in the data I'm seeing
Discussion
- Charlie: Feedback on plan, given we can simulate effect of randomized response, I would encourage running a more sophisticated analysis of real data before running another OT
- ... If we have good data for it
- ... I feel like we could get a sense of the effect of this mechanism, using existing data
- ... The test was good, you could take what I had on my last slide and see how we could partition histograms, etc
- ... That might be a good place to start, vs. high overhead of OT
- Yoav: Suggesting to take a pile of real-life NT data with systemEntropy bit and run simulate a randomization of that bit, and see if the data still makes sense roughly
- Charlier: Not an expert, if the data exists, did we run an OT without noise?
- Mike: Yes we have partners that have done it
- Charlie: Easy assuming we can get access to the data
- ... Run a simulation of the algorithm, test different values of epsilon with overhead of an OT launch
- Michal: Last slide answered preemptively how you could denoise the data after the fact
- ... Curious, do you need to know the specific algorithm and epsilon chosen to reverse-engineer?
- Charlie: Yes, you do
- ... One-liner, operating on a per-bucket basis
- ... Every bucket, look at count per-bucket, total across both high- and low-systemEntropy, look at P, it's just this formula
- ... Deployment problem I would say
- ... If we add a noisy systemEntropy bit and we expect epsilon not hard-coded in spec, I suggest we expose epsilon value or flip probability
- Michal: That was my second question
- ... For other APIs, are they sometimes spec'd, exposed?
- Charlie: For Attribution Reporting API, we allow you for binary randomized response, flipping a bit, we specify a K, in that case you can choose that flip rate
- ... We expose what P is in our API
- ... I don't know of too many other APIs that have introduced DP, if all vendors are aligned on an epsilon, it could be hardcoded
- ... There could be another vendor that wants to do something differently
- ... Err towards including it
- ... Align for low values of epsilon if that’s tolerable, any more privacy conscious browser would be fine
- ... Utility/privacy tradeoff
- ... How to do this algorithm for multiple values of P and combine that, I might have to talk to a data scientist
- Michal: wondered about future changes. Exposing the epsilon makes sense to me.
- Nic: Thanks for presenting this! Generic web developer perspective, I wonder how much they’d be able to use this without some significant training. Seems like a lot.
- … Seems like it’d be challenging to help people understand this
- … A second thought from a RUM provider’s point of view - customers expect data to be represented accurately. Because this data is intentionally not accurate, I wonder how it’d be able to be used
- … Or if we’d need to present this data in some different way
- … maybe correct in aggregate, but we provide waterfalls of individual views, so we’d need to caveat that
- … Will lean on data scientists to figure out how we can use this data
- Yoav: From a web developer's perspective, I think the randomized response algorithm doesn't need all the math
- ... Response is randomized, this is the randomization percent, can use that as a dimension to split your data on, some cases where you're throwing away good data and some where you're incorporating bad data
- ... And it's MAGIC
- ... I don't think developers would need to dive into correctness proofs
- ... On RUM provide side, I don't think this is a useful for us to deal with measurements
- ... But useful way to deal with dimensions
- ... For measurements for some sort of aggregation
- ... Accumulate a lot of measurements, provide a private summary of that
- ... For dimensions, apply to data we're already collecting, this will enable us to drop the navigations we don't currently care about
- ... Deep-dive on a waterfall, that deep-dive will have to be caveated
- ... Piece would need some communication
- ... If we compare to current state where we don't have access to this data at all, this would be an improvement
- Andy: I feel like LCP isn't as complicated but has caveats and characteristics that we figured out a couple times, it's not a perfect 1:1 what happened, it's a best-effort
- Amiya: Echoing what Yoav mentioned, booleans or a discrete set of options, or distributions. For perf metrics, depending on the metrics distributions may be different, not everything is normally distributed
- ... I wonder how mathematically, with a lot of data points it's fine
- ... But with splitting other dimensions does it introduce data
- Yoav: Maybe exposing epsilon will give better guidance "this data makes sense only if K samples" from various users, don't look at it otherwise
- Charlie: I think with data from API you could compute error bars
- ... With histogram you can look at variance per bucket
- ... Could present dashboard with some things omitted with error bars too high
- ... One approach
- ... I heard two things from this convo. From Yoav, not doing fancy math? Let's verify that
- ... What's the best way to consume this data and have an agreement, very important thing
- Michal: On the topic of dimensions and agg reporting, we don't know what a given developer's dimensions are. They might measure A/B with perfect precision, could give a perfect distribution
- ... I love this mechanism because we're saying if there's a difference on this dimension between two sets of users, we're going to shrink your ability to measure that, but you can still adjust it
- ... Aggregate reporting API is powerful, but we don't know what dimensions are. Do we need a first-class concept for dimensions, and on-purpose we're controlling this dimension
- ... It's going to be a can of worms, this is middle-ground
- Yoav: User-defined dimensions is important for aggregated reporting
- Dan: Related to concept of RUM provider showing data for a specific session
- ... Obviously that's the thing you lose, I hate opt-ins, but we might think of some sort of consent for opting out of adding of the noise
- ... Might be a possible solution
- Yoav: Can work if debugging a specific session, ask them to give more information
- ... This is one where a specific permission could be better
- ... I suspect for RUM provider showing a Waterfall, that's not necessarily where a user complained
- Michal: To Charlie's point, if we support variable epsilon, it could be the UA's decision, you could factor that in
- ... Envision an explicit call to ask for an undifferentiated value the user has to accept
- ... To the point of entropy, the privacy principles were really well laid-out.
- ... It's either necessary data or auxiliary data, gives us a middle ground to treat aux as something else
- ... Are signals useful on their own
- Yoav: Agree, and in this case the Compute Pressure effort is similar and different
- ... I don't know we should tie this to that spec
- ... Not sure if this data will be exposed down the road
- ... Variable epsilon would be useful in that case
- ... I don't think this changes whether this data is ancillary or not
- ... This is one of those mitigations