Dan Shappir, Katie Syler-Miller, Fergal Daly, Nic Jansma, Pat Meenan, Noam Rosenthal, Dave Hunt, Ming Ying Chung, Aoyuan Zuo, Ian Clelland, Barry Pollard, Michal Mocny, Carine Bournez, Timo Ijhof, Benjamin De Kosnik, Mike Jackson, Noam Helfman, Yoav Weiss, Alex N Jose, Tariq Rafique, Amiya Gupta, Mike Henniger
NoamR: fetchLater is the new pending beacon, slightly lower level.
.. A drop in replacement for fetch() that waits until the page is destroyed or invisible for a long time
… Allows creating something like PendingBeacon in user land
… The API uses bandwidth after the page is loaded, by design. Other fetches are canceled at the point
… This creates a situation where closing the tab could trigger many MBs of data to be sent, if this would unlimited, and the user would have no recourse (closing the tab doesn’t help)
… So we need to limit the amount of bandwidth in the context of a top-lvel window, as that’s where users have control
… Decided on 640KB as a number that’s shared between same origin iframes.
… The other side is that we don’t want a single provider takes up the whole quota, preventing other scripts from getting any quota
… So we decided on 64KB limit per reporting origin
… Also, for cross-origin iframes that are allowed to use the quota, they’d also get 64K, as if they were another reporting origin
… This is where the discussion is atm
Timo: does that mean that for a site, its limit would be different if it’s iframed?
NoamR: Yes, for cross origin iframes. And they’d share the limit across that origin.
Dan: We’re talking about upstream data?
NoamR: Yeah, request data
Dan: Also 64K should be enough for anyone
NoamH: Is there a reason why we shouldn’t give a 64K quota to anyone and that’s it?
NoamR: If you had unlimited amount of data sent, the user would not have control
NoamH: Why not a smaller quota per frame?
NoamR: 640K seemed reasonable for the whole tab. 64K would be too low. You have your RUM provider, 1P, image CDN, etc
NoamH: So 10 of those, but not for each cross-origin frame
NoamR: Wanted to keep it simple, so have 64K per iframe to reduce complexity. We could also add more complexity in the future if needed.
Katie: So if a site is setting their own beacons and have dozens of iframes, there’s no quota on sending data sync. Afraid that a small quota would discourage 3Ps from switching to this mechanism, despite it being better for users
NoamR: It’s guaranteed(ish) to go through, so a tradeoff
Michal: An alternative - a global limit incentivizes to stuff the pipe, hence the reporting origin limit. What if we allowed anyone to attach any beacon and then prioritize the smaller ones
NoamR: That would go against the guarantees of the API. Add a lot of uncertainty. When fetchLater fails it fails fast, so you know immediately that you need to use an alternative mechanism
Nic: From the perspective of a RUM provider, one concern was that the limit would incentivize folks to register early, with a dummy payload, etc. and we don’t want folks to do that.
… Data grows over time, and at some point that growth may trip over the quota. What should we do then?
… Trying to think through the edge cases. It’d be a bit complex
… That seems like one of the consequences from protecting against lots of data being queued up
Timo: Try to incentivize folks to use the API, which means it needs to be reliable.
… If your data payload grows over time, that may not be a big issue
… When you reach the limit, you send immediately and then continue with fetch later
… Also wanted to ask if there’s a plan to redefined sendBeacon in terms of fetchLater
NoamR: Unaware of such plans. It’s an immediate fetch, but uses the keepalive quota (separate 64KB quota)
Quota is per origin
Dan: May be beneficial to have a guaranteed fallback mechanism, to enable some critical data to be sent over anything else
NoamR: you can do that by sending a request with no body, with the data in the URL. If that becomes an abuse vector, we may need to do something about that
Fergal: An alternative was to have some sort of a FIFO queue, so that pending requests are sent immediately when we run out of quota. Had its own drawbacks, where one provider can push another’s beacons
Slides: Bimodal Performance Timings in WebApps April 2024 - Google Slides
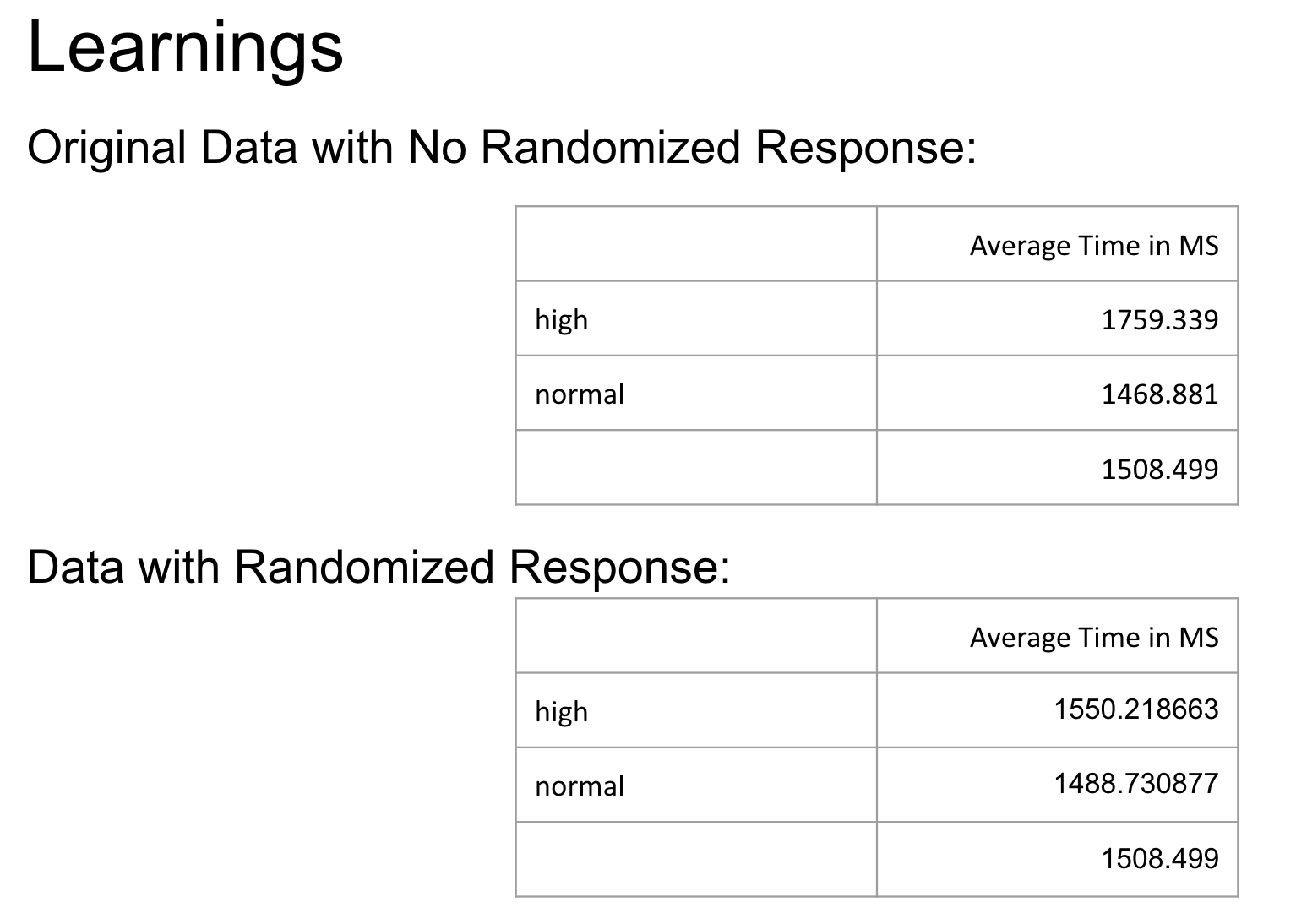
Mike: Want to allow developers to eliminate outlier metrics (local machine noise, high CPU, etc)
… Called system entropy but no one liked the name
… Needed to be exposed in a privacy preserving way
… Ran an Origin Trial, collected data and applied differential privacy debiasing
…
… data with the randomized response significantly shifted the averages, but when debiasing the data, we got most of it back
…
… So feels like an avenue that’s worth continuing to pursue. Allows RUM providers to collect that data in aggregate, but not useful for picking any particular session
… Included the algorithm for debiasing in the slides
… 2 questions for this group:
… Given this data, is this worth pursuing? And assuming we do, we have 2 rough proposals.
…
… TODO
… the downside is that the data as exposed is useless for developers
… The second approach is plugging into the reporting end point API
… Send the data to the reporting API, send this kind of payload
… some interesting opportunities there, TODO
… That seems like roughly the approach that we want
NoamR: related to other things, e.g. battery level, memory, etc
… Were looking at something that’s more similar to your second direction - the private aggregation API
… It’s reporting, but the browser itself maintains the fuzzing and anonymizing
… Ian and I started poking at this
… If we could collaborate on this, that could be a direction for the bimodality you’re seeing
Nic: Was helpful to inform us. Interested as a RUM provider. Thinking about the 2 options, either in JS land or through reporting.
… The benefit for us of getting this data in JS is that we can then associate that data with other dimensions we’re getting
… Reporting decouples that dimension from other dimensions that we currently have
…Can bring it through JS, but not through reporting
… That’s why that information in JS could be useful
Mike: The reporting API does have reporting observers, but it’s not connected to NavTiming
Yoav: Noam a lot of things on your list aren’t dimensions but metrics, and we need to be careful to distinguishing the two
… The reason Mike is interested in this data is not on its own, but in order to filter out other things. So it’s a dimension rather than a metric.
… Anonymously reporting metrics vs. dimensions require different solutions
… I would like to get a better understanding why the information in JavaScript is not as useful as information to report
… Not as useful on the machine in order to do stuff, as you don’t want to make the wrong decision and change the user experience based on that randomized data
Mike: My statement was around the first point, the JS developer can’t take action in that moment to change the experience. And they can’t even de-bias it locally. Unless they stored these for every session, can’t de-bias locally.
… So the only thing to do with this is bundle it up and send it off, aggregate it.
… That’s the bit that feels weird to me to hang of the object
Yoav: Answers my question, but agree with Nic that usefulness is it can tie with other metrics on the client. If we report this regardless of those metrics, that would make it hard to use that data.
Noam: What Yoav and Nic were saying were exactly the design decision with the Privacy Preserving API
Yoav: Amazing!
Charlie: To follow-up Yoav on exposing metrics vs. dimension, one reason why the local API has some benefits.
… It will typically give noisier data vs. PA API
… But gives you flexibility to do these splits online
… Imagine you want to design a dashboard, and arbitrary splits on dashboard, on boolean or date or whatever
… With this boolean, it’s not “easy” to do that at query time, but doable
… But with Private Agg API you need to setup those dimensions on the client
… If you want a histogram of UA across the hour, you need to set that up on the page
… So when we decide whether to use a local or central mechanism, that’s a key factor we should think about
… Central mechanism gives you much less noise, but cumbersome to use in the way I see this being used (dynamic histogram views exposed to customers)
…
Noam: This would be a design constraint in using Privacy Aggregation vs. this type
Yoav: For some things, if we want to measure e.g. Total Page Weight, it’s not a dimension, we can’t use this mechanism for that, we need some sort of aggregation + server-side anonymization
… But things where a dimension is what we’re after, this pattern could be a good pattern to use
… Mike also mentioned beyond just CPU load, you looked at decoupling those, was that part of experiments?
… Not something we collected data on, just the implementation already in Chromium itself
… Original proposal is everything coalesced into one value
… If we wanted to e.g. calculate compute pressure at navigation time, that would be in there
… Following randomization algo, we need to apply the right algo to ensure privacy levels are protected
Yoav: Charlie in terms of the maths involved, how does this work for multiple dimensions?
… e.g. discard measurements where any one of them were positive?
Charlie: It’s definitely possible, I think there’s a decision the group will have to make on privacy front which will impact how doable this is
… Are we privatizing all variables independently, or together as a batch?
… Doable with two dimensions instead of one, but with 50+ dimensions it could be tough, algorithm starts breaking down after that many dimensions
… I think we should not prematurely launching something without thinking though how this would work
… You mentioned wanting a breakout if any of dimensions are true, in that case, put them all combined into a single boolean
… We should also think about the use-case
… Discard anything in case one of these booleans is true, we should coalesce
Noam: In that list of nice things we can’t have, for things that are a dimension, many of them are boolean
... e.g. something happened outside of website’s control that maybe the website should discard the measurements
… e..g not high confidence
Mike: One of the proposals I had discarded, confidence=high|low
Yoav: Next steps?
… Better understanding of use-cases beyond this boolean?
Mike: I want to have a chance to read the other links, and I’ll reach out to get a conversation started around what we do want to do or next-steps
… Once we’ve had that conversation, next step would be to update the explainer. Move to WICG once we’ve coalesced around a proposal that we’re happy with. Maybe get an update in Chromium once we decide what to do.
Hearing that the reporting API is not the preferred approach - we’d put that as an alternative considered.