Rafael Lebre, Sean Feng, Pat Meenan, Nic Jansma, Yoav Weiss, Hao Liu, Ian Clelland, Aoyuan Zuo, Abhishek Ghosh, Benjamin De Kosnik, Michal Mocny, Mike Henniger, Giacomo Zecchini, Barry Pollard
Michal: 2 different groups came up with the same problem at the same time - performance entry measurement over time
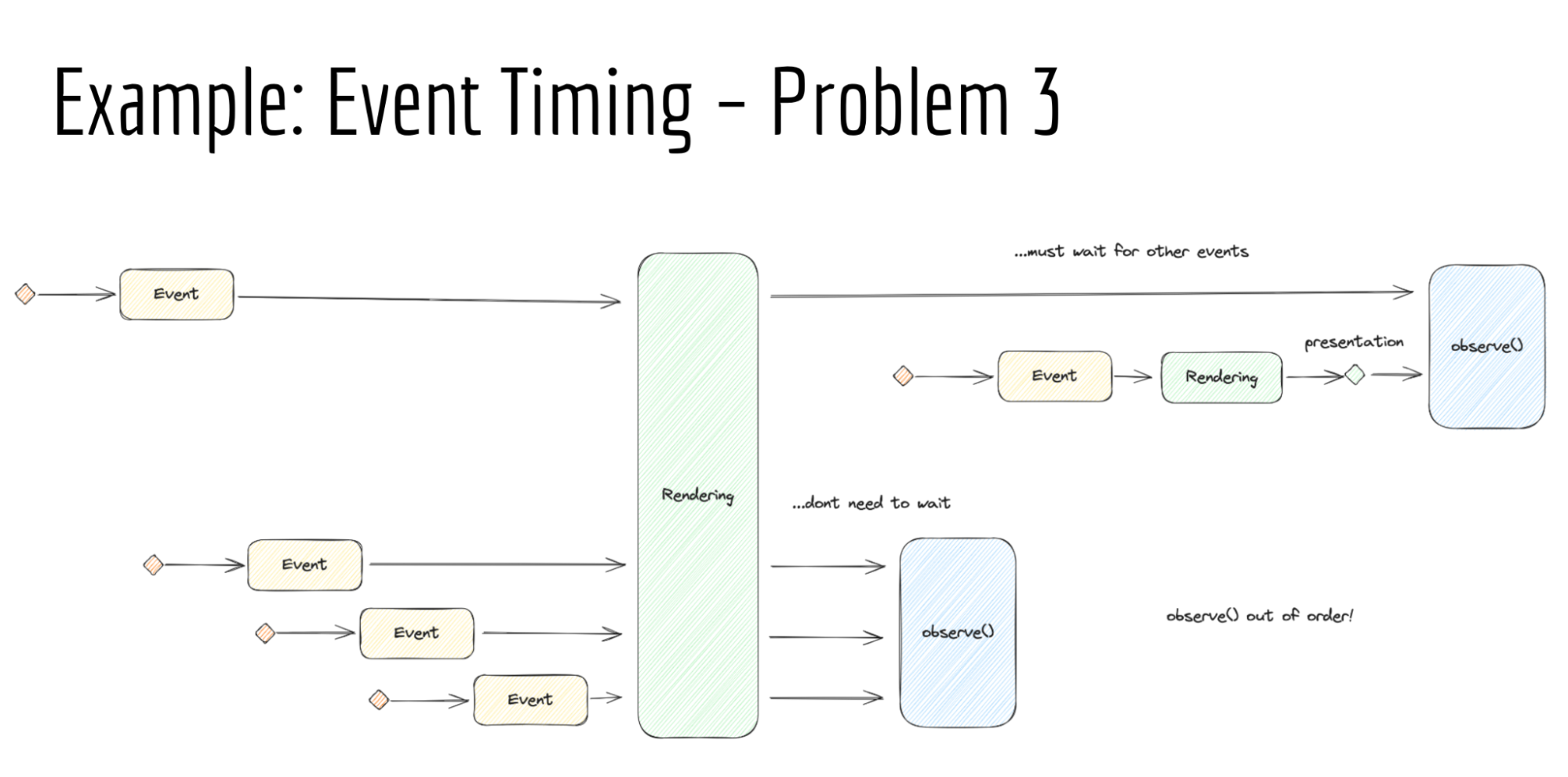
… Performance measurement takes time but any one complete performance entry is expected to be complete
… causes issues: buffering, reporting delays or measurement complexity, tradeoffs on which data is reported
… with event timing, the first thing we know is the start time timestamp, then processing start, after a hit test we have a target, and after all JS ran (including event listeners) we mark the processingEnd.
… Then we wait for next paint for the duration
… In chromium we try to assign an interaction ID, and you’re not sure until other events happen (e.g. touch down has to wait for touch up)
… Then the observer may get delayed further when reporting
… What happens if the document was modified - the event target may no longer be there, and we lose our ability to observer that target because we delayed things
… Another problem - the document may get unloaded before any of these things is observed
… Example - event timing waiting on data
… what happens when some things need to wait and others don’t? Should we buffer everything in order to have a consistent timeline? Or emit the data we have when we have it?
… Sometimes those time delays can be substantial
… With LoAF, we can get entries before the relevant event timing entries have fired
… so you may want to buffer, but that has tradeoffs
… Navigation timing has that issue for a while. Might be complete after onload, but you have to poll the entry to see if all of its entries are there
… For resource timing, the entries are fired only after fetch is completed
… We want to wait longer - e.g. processing time
… At the same time we want to know when a fetch was started - so want these entries sooner
… For Paint and Element Timing - we may want more paints than just the first paint, but not necessarily to wait on them
… We wanted an “isFinal” bool on LCP, but can’t know that until after its emitted
… So, what do we want?
…
Nic: Are there stats on people using perf observer?
… For resource timing it’s easier for us to getEntriesByType
Michal: A few entry types only have observable support. Anything with data coming in over time
… personally interested in the observer version of it
Nic: From our experience there are ergonomic reasons to use both
Barry: I wonder why we’re not looking at the last 200 entries rather than the first 200 entries. Personally, wished we supported both
Michal: You’d still have to do a bunch of polling, so you’d never know when new entries show up. A sliding window can help, but you’d still have to process the full list to do grouping, etc.
… Also for buffering, any new observer added to the page may care more about the first 200 rather than the last 200. So may need a fixed window upfront and a sliding window at the end
Nic: Is the goal here to find guidance for us for future specs?
Michal: For me, there’s a problem with EventTiming being hard, especially with LoAF
… Preference for option 1, but it’s complicated, even with the perf timeline doing default buffering
… We’re duplicating effort and need to offload it to the platform
… At the same time,
Yoav: Backward compat concerns are fine as long as we go with an opt-in
... We can easily do that with Observer option
... I don't think it should be a significant consideration
... Main bit I'm personally missing is I haven't tried to actually write observer code with each one of these options that would take into account lagging information
... If I'm reporting a certain perf entry that doesn't have all of its values, do I delay it, report it later
... If I choose one option or the other, how does that affect things?
... It might be interesting to play around with code examples for what these things may look like in real life
... Interesting for RUM folks to do that
... Wondering if Nic would be interested in playing around with
... Joint exploration to see which pattern actually works in practice
... Current status-quo works, but adds delays
... Element ID is a perfect example, and something we also have for LCP
Michal: Just those things we're aware of
... As soon as that callback is fired, if you're trying to do any cross-checking
... Let's say you're in a SPA you're in a different state of the world
Yoav: Anything like userland CLS attribution, what elements around this element, but by the time anyone is looking at this, they could be gone
Michal: Two problems: eagerness vs. lazy
... Lazier you are, riskier things get
... Second problem is around grouping different entries by time
... Maybe Performance Timeline needs a feature for that API
... Maybe ask for a time-range I'm interested in, an PO could have a start/end time
Yoav: Browser buffers all the things...
Michal: It already is, knows its' in the middle of buffering, website doesn't know that
... Website author doesn't know new entry might just arrive
... EventTiming is canonical example
Nic: And ResourcTiming observing outstanding entries
Yoav: For ResourceTmiing pending entries, you could ask to get all RT entries happening right now, even ones not emitted
... Interesting way of looking at this
... Concerned around complexity on developer side
... How do they know what information is there, and what's available later
Michal: Rough goal is to continue measuring and updating values to the latest, until we can no longer do that. That's when we flush whatever we have
... All outstanding requests, now get resolved and we measure
... At least we know what we're waiting for
Nic: if we have all these observers outstanding and unload fires, I’ll grab all the data I have and send it
Michal: Before any page lifecycle even begins to fire, we’d flush anything. We’re already doing this kind of buffering
… So the question is should we report what we have earlier?
… Currently we’re being maximally lazy
… today we don’t know if we’re seeing all the data or some of the data
… Regarding an opt-in - We’d need to support both variants forever
Yoav: Agree an opt-in means that old behavior remains valid and useful
... Adds complexity on browser implementation side
... Unless it can be abstracted away
Michal: You can always fallback to "Option 1" by Observer await all of the lazy values
Yoav: Are promises for missing values useful? Detect, in code, that those are promises
... Don't want RUM code to know which bit of information is always available vs. sometimes available
... Some way to detect that, value currently holding is complete or not
Nic: So to bring it back to all the proposal, you mentioned a few scenarios that would need that
… We could take those use cases and different options
… pseudocode can help us understand things
Michal: Would be great if webvitals.js could also explore that
Barry: Definitely things were more painful due to buffering, resulting in out of order entries
Michal: Option 1 leans more into these problems
… Being less lazy can improve things
Nic: For tracking, can you file a performance timeline issue linking to the slides, so we’d be able to track this work and move this forward
Michal: *thumbs up*
Nic: wanted to revive this issue as it hasn’t moved since 2022. If a preload is initiated, e.g. with Early Hints
… we want to know if the resource is actually used by the page, or if the resources are somehow wasted as they were never used
… You get all the resources that are fetched in resource timing, but no indication if they were used
… Couple of different proposals on the issue
… One option is to have a second entry when a preloaded resource is actually consumed
… Current observers would get more entries that they expect
… Another option is another timestamp on the existing entry, which is updated once the resource is actually consumed, if that happens
… Relevant to previous discussion regarding late update of entries
… Any other folks that want this data? Akamai are interested in this
… You can get this information in devtools, but no other indicator
… e.g. in Chrome you can see it, but not in reporting API nor resource timing
… Thoughts on the easiest way to consume this info (beyond the previous discussion)
… Personally prefer the second proposal - timestamp that gets updated later
… The first can cause us to create additional entries
Yoav: Super interested in this problem, I keep seeing many times opening Dev Tools on websites, there's a pile-up of resources-that-were-preloaded-but-not-used console warnings
... Websites may not have this problem if they knew this was happening at scale
... Seems like a problem we need to solve
... Between the two options, I'd prefer (2) an additional property that updates over time
... Even more if we solve this in a well-paved-path solution to updating Performance Entries after-the-fact
... This would be a natural candidate for that. I don't think there are any tradeoffs
... Third option: Reporting API that we could use here. Here's a list of resource URLs that were never used.
... You get RT on one hand, and a pile of Resources that weren't used for this particular session
... Like mentioned in the past there's a problem coordinating one with the other
Nic: One could use Reporting Observer in-page to grab that data
Yoav: Yes you could combine that data with what you have in the page
Ian: Resource would have to be sent at the end of the page right?
Yoav: Console warnings in Chrome, also in Webkit (possibly) effectively a timeout after onload
... We don't really know these resources are never consumed
... But if they were preloaded early on and not used until a good chunk after onload has passed, presuming they're not going to be used
... Because this would web-expose information, maybe need better heuristics for this
... But it could be a heuristic approach
... e.g. "this" is likely unused
... We could also send a Reporting API report after render dies, with more concrete info
Barry: I like doing it at the end of the page, I find simple bugs with DevTool implementation.
... e.g. after timeout, or with low priority that's not blocking anything
... loads of things that heuristic isn't perfect
... Where at the end of the page you can more definitively know
Yoav: Tradeoff is at the end of the page hard to correlate with a specific session
... Question in a previous meeting, right now Reports are credential-less
... Is there a specific reason why that is
... Having credentials on reports could help w/ correlation after the fact
Barry: Doesn't have to be with Reporting API, could be option 2 here
Yoav: Option 2 could be after renderer dies
... onvisibilitychange do that kind of check
Ian: Credentials question was around privacy and cross-site tracking
... We do send credentials if same-site-origin
Yoav: Just cross-origin we omit credentials
Nic: There’s some page-specific info that’s lost with the reporting API
… that’s why in-page is more powerful
Yoav: Reporting observer of give me all the unused preloads "so far", could kick off from visibilitychange
... Do correlation at that point
Nic: If we have the preloadConsumed attribute being zero that would give you the same information
Abishek: *commenting in chat*
… Is it possible to look at a ResourceTiming entry and understand if the request was a preload?
… Maybe something like the initiatorType ? Combined with the param like preloadConsume and its existence/timestamp it might give website owners more control to identify all the resources preloaded and define more flexible thresholds to measure wastefulness (if it did not happen by X event, may not be just end of page load)?
Nic: there’s an initiatorType for preload
… So developers can apply their own thresholds
Barry: When a resource is used from the memory cache, that doesn’t create a second entry
… Abishek’s proposal here would not work due to the missing subsequent requests
Nic: Thanks! I’ll try to summarize this in the ticket
Yoav: One option is to wait for delayed attributes to be a thing (previous discussion), other option is to move forward with some sort of Reporting API

