Participants
Noam Helfman, Andy Luhrs, Nic Jansma, Yoav Weiss, Andy Davies, Noam Rosenthal, Patrick Meenan, Sean Feng, Jeb Barabanov, Amiya Gupta, Benjamin De Kosnik, Ian Clelland, Hao Liu, Mike Jackson, Philip Tellis, Giacomo Zecchini
Admin
- Next meeting: August 1, 2024 at 1pm EST 10am PST
- Please post ideas for TPAC to the agenda!
Minutes
- Noam: For last weeks’ topic on ServiceWorker agenda, in order to prioritize issues, we want to see that it would help more people
- … Not a lot of folks discussing other than Google folks and Nic/Akamai
- … We would need more engagement on issue, otherwise it might not be prioritized
[LoAF] Allow for annotations for long animation frame to further help debugging · Issue #3
- NoamR: raised before the OT. A limitation where what we call a script is a “script entry point” - the first time the platform calls an author script (that ca call others)
- … In many occasions it’s not granular enough. It’s low overhead to measure, so there’s a tradeoff here
- … But in cases like new relic brought, when you wrap up the native APIs, it seems like the cause is new relic (or the wrapper) rather than the internal script
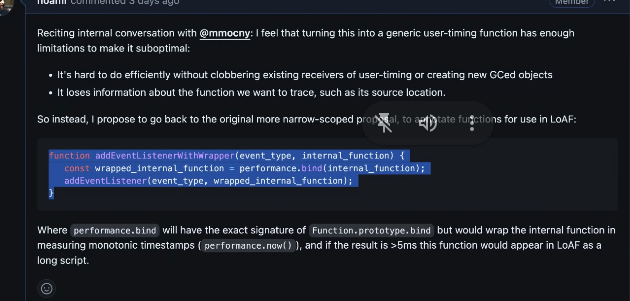
- … You can use user timing for this, but it will have overhead and it’s not the right tool for the job (e.g. creates GC objects for detail, fills the buffer, etc)
- … I think it should be something where you have a bind function that wraps the user function and makes that function into a script entry point
- …Bind itself would have overhead, we can’t deal with sourcemaps, so it’s not perfect
- … we’d not gonna do it all the time, only when setting the listener
- … but then when the event is called it’s low overhead
- AndyL: doc on perf overhead of user timing?
- NoamR: Not that I’m aware
- Jeb: Wanted to weigh on the importance of this, wanted to share an internal Wix dashboard
- … The absolute majority of the scripts that participate in LoAF are coming from React and React-DOM, lots of cases where there’s no script URL
- … If we just perform hydration and someone clicks, it’d be a LoAF and attributed to React
- … We don’t have a way at scale to debug this
- … It’d be incredibly helpful to have something that allows us to indicate from within our code where issues come from
- … The latest proposal is less useful than performance mark, because of minification
- … however something similar to user timing that would enable us to label LoAFs from within our code. We could put such labels inside our code
- … and during react hydration it can help us know which labels are marked
- Philip: in mpulse we see similar complaints where mpulse is a top contributor on PSA (which we tell them is irrelevant)
- … this kind of annotation would help if it’s displayed in developer tools as well
- … perf.mark would help with our code, but not with external dev tools
- NoamH: I can share a similar experience we have with JS profiling.
- … We’re seeing similar problems where the root function is less interesting
- … We created an exclusion list of root functions we don’t care about, so that only the code we care about gets displayed
- … Maybe a similar approach can help here? I can imagine passing a list of functions to the observer that would be excluded
- NoamR: from an overhead perspective, it requires hooking into the stack. We can’t do stack traces for performance reasons.
- … For entry points that’s a lower overhead
- … That’s why it needs to be allowlisted
- NoamH: So if you bind, you’d get what?
- NoamR: The bound function. Additional script entries but marked by the platform
- AndyL: I like the concept and think it’d be helpful. The sourcemapping side of things - in a number of places we don’t have sourcemaps and maybe that’s something that should be looked at holistically
- … Maybe we can add a hash of the source file so that sourcemap lookup can happen async?
- … Similar issue with JS profiling
- … So WebPerf APIs could be more useful if we had sourcemapping as a first class citizen
- NoamR: Glad to hear the need for this feature. With sourcemaps we could do something at the browser level
- … Also possible to create a SW that does this - reads the source map and augments the entries
- … Can also be done as post processing, but not straight forward
- … Wonder what’s the role of the browser in that
- … Wanted to ask Jenia - if this had a mark name string, would it make this more useful?
- Jeb: Having a label would be enough for us. We’d mark several places in our code and see that script URL, but with our annotation
- NoamR: This would be more like a measure than a mark
- Jeb: Ideally we want a measure with a start and an end. I understand this might be complicated from an overhead perspective. But even just a set of labels without a duration would help
- NoamR: So I’m hearing two cases here - one for diagnostics and one for attribution
- … We can have the string but not a source location. When we pass the mark we don’t get the source location
- Jeb: yeah, but the mark can represent the source location
- NoamH: How would binding to two functions in the call stack look like?
- NoamR: They’d both appear as entry points
- NoamH: So I’d be able to implement a profiler in LoAF
- NoamR: For only functions 5ms and above
- Yoav: I’m wondering, as part of soft navigations, there’s task attribution architecture, can you build a LoAF variant based on that, that would give more intentional attribution rather than entrypoints
- NoamR: Start of LoAF, task attribution was early at that time. It’s a bit of a different problem space.
- … To get source location of those, you’d also need a stack trace
- Yoav: Those won’t give source location, but they could give you the source, but maybe that’s not granular enough
- NoamR: Task Attribution and friends are less granular than what we have here in a way
- Yoav: Yes, but they wouldn’t be pointing at the wrapper if coming from a different source
- … Not granular enough to give you, without walking stack trace
- NoamR: Since React calls aEL by itself, it’s still show React
- … Invoker vs. Registration
- Yoav: That depends on implemented semantics
- … Registration semantics vs. callee semantics
- … Won’t pinpoint an exact location, something you need from stack itself
- NoamR: For UserTiming, overhead is just about current API of UserTiming, with the fact it accepts a dictionary w/ details etc
- … It will have to be something a bit different. performance.trace() that doesn’t accept a dictionary, or you create a marker in advance, and you mark it every time
- … I see those as not conflicting solutions
- … Both have pros and cons
- Philip: Similar things have come up with attaching to onerror handler, when you wrap errors, the wrapper gets listed as the source
- … In that case we have the full stack trace, many cases we can pull ourselves out, but useful for things like PageSpeed or DevTools that are looking at errors’ full stack
- … To understand the error that happened rather than the wrapper
- NoamR: You can do something like NoamH was using, you can block out origins or URL patterns
- Philip: There are multiple tools, and each tool will remove itself but not others
- … mPulse can remove itself, but can’t remove New Relic, and vice-versa
- NoamR: Problem space is similar but solution space is different
- … When you get an error you already have a stack
- … Errors shouldn’t happen many times per frame
- … Worthwhile to have a separate issue open on this
- Philip: Primarily for onerror cases
- NoamR: Summarize as general positive sentiment, usecases for both mark-style API and a wrapper function. One more for diagnostics and one more for attribution.
- … We’ll come up with an actual spec proposal for this
Paint Timing - Timestamps should be specified in an interoperative way (PT 62)
- NoamR: Something I’ve been keen on fixing, but haven’t come up with something good so far
- … PaintTiming (FCP) and LCP we have a “presentation time” which is defined as “time for pixels on screen” which isn’t interoperable
- … It’s not testable in a web observable way
- … In WebKit this is the last place in the main thread loop right before paint starts
- … In Chromium this is when we get a frame timestamp from the compositor, when the frame was swapped to be displayed
- … I’m not sure how to resolve this
- … We can rely on the end time of FCP and add a new presentation time that is implementation specific (probably Chromium-only)
- … We can use the next animation frame time, but it’s a bit arbitrary and can change based on browser implementation
- … The other thing about paint timing is that you can’t really control what happens after the last point the main thread handles it. Should we expose this “browser time” to the web?
- Jeb: We want to represent the user experience. If the timestamps are before when the user saw what’s on screen, they don’t represent the user experience.
- NoamR: I agree with this in theory, but we’ve made that compromise elsewhere. E.g. navigation start is not when you clicked the link but when we started fetching the new document
- … presentation delay of FCP is not in the same order of magnitude of FCP itself (milliseconds vs. seconds)
- Jeb: If in some edgecases there were a large difference between browsers, we’d want to see that in the data reported in RUM (e.g. we’d know we have an issue in RUM in Safari)
- NoamR: Yeah, but Safari will not implement this information. Right now it’s Chromium only
- NoamH: How hard would it be to implement your first suggestion of keeping a common timestamp and adding an implementation specific timestamp
- NoamR: Easy for chromium
- NoamH: But it could break existing implementations
- NoamR: I imagined an interoperable timestamp and another non-interoperable one
- NoamH: Seems reasonable but could break
- Pat: supportive of aligning as long as we kept the presentation time. Important for alignment with CrUX but also important for sites that impact the presentation time (e.g. a huge queue of images to be decoded)
- Yoav: From my perspective, I think it’s important to outline usecases that Pat described
- … Right now we’re presenting extra data that’s not observable by other means and we don’t specifically outline why we need as close to possible to UX timestamps vs. more interopable ones
- … Would be good to be explicit about why it’s needed
- Pat: Concern in situation where WPT is doing video recording and doing RUM capture of metrics, you get a 500ms case where browser reported time from what showed up on the screen
- … Things not under developer control aren’t just paint, i.e. INP where start time has browser stuff before it gets to JavaScript
- Yoav: I don’t disagree, it would be useful to outline these use-cases
- … One could imagine us reporting discrepancies, if we run into a 500ms case we need a “paint congestion entry” or Reporting API
- … Let’s outline use-case explicitly and it’ll help us discuss this
- NoamR: We can add intraoperative timestamp to CrUX or UKM and we can float up the situation where there’s a big delta
- … Reason with them and see where they are
- … That’s data that’s missing here
- Pat: Are there spec concerns with adding both times?
- NoamR: I see it as pointless, specs are for interoperable things, there’s no WPT we can write for the timestamp that would prove it
- … We can have something optional there, but where this comment came from is when a browser says we’re supporting this spec, they support all properties in it
- … If some properties that aren’t supportable or interoperable, there’s diminished value in doing that
- Pat: Diminished value in spec land and browser land maybe, not sure there’s diminished value for developers
- … Can we understand what the gap is between interoperable and presentation time, is it 1 vsync or does it vary enough that it’s worth measuring?
- Yoav: (thumbs up)
- NoamR: Perhaps something optional to the spec, but I’m cautious to that
- … Big undertaking to make this spec agreed upon by Apple and Mozillla, and I want to keep that quality of the spec there. Don’t want to add a controversial Chrome-only thing
- Pat: Was also big effort to get presentation time in Chrome as close to video as possible
- Yoav: Summary - we need to document these use cases and it’d be neat if Chrome folks measured the diff between the timestamps.