Participants
Nic Jansma, Noam Rosenthal, Alex Christensen, Patrick Meenan, Alex N Jose, Sean Feng, Noam Helfman, Michal Mocny, Aoyuan Zou, Carine Bournez, Jacob Gross, Abhishek Ghosh, Benjamin De Kosnik, Philip Tellis, Katie Sylor-Miller, Yoav Weiss, Marcel Duran, Andy Luhrs, Mike Jackson, Bas Schouten, Jase Williams
Admin
- Community surveys
- English Members: https://gzobeteisdd.typeform.com/to/uaESY6Q8
- English External: https://gzobeteisdd.typeform.com/to/TeoUTslq
- Next call - September 12th - 8am PT, 11am ET, 5pm CET
- TPAC Request for Topics
Minutes
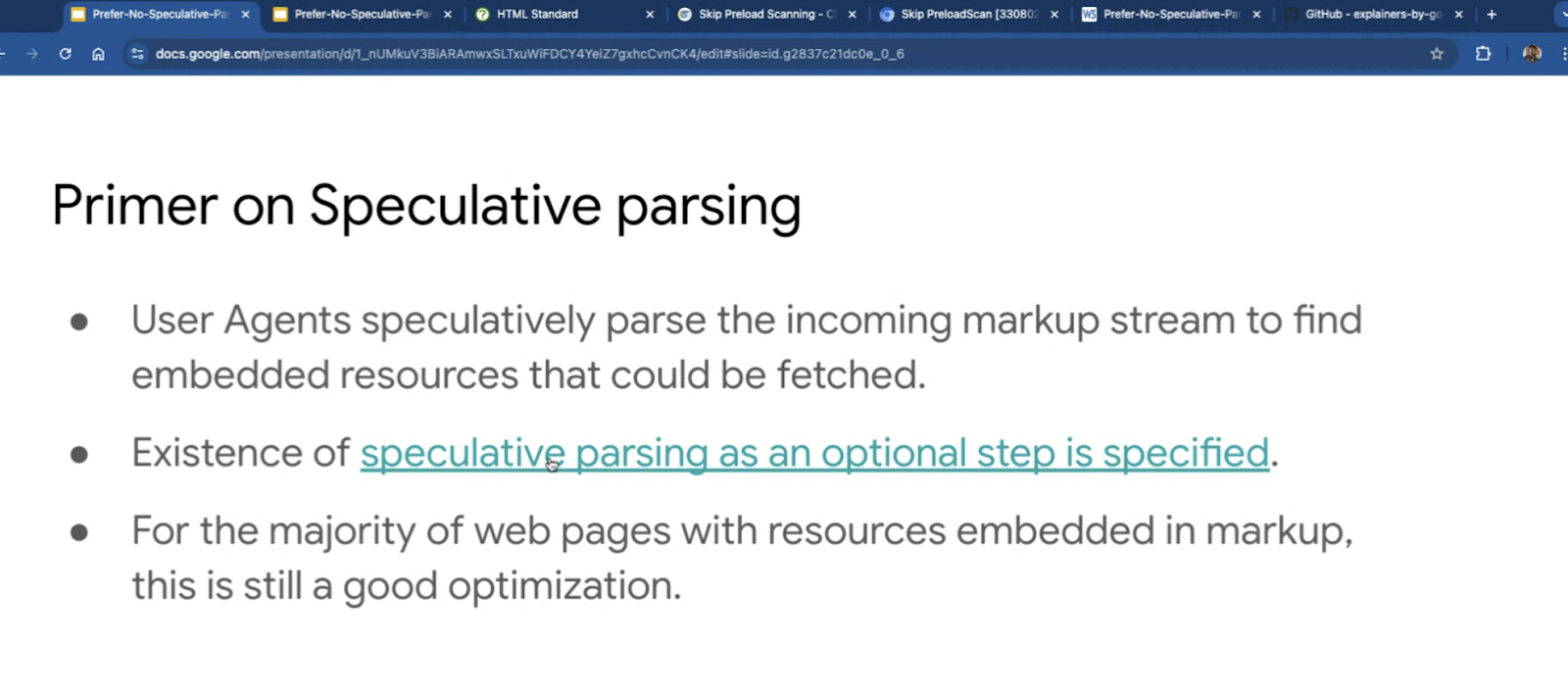
Prefer-No-Speculative-Parsing - Alex N. Jose
- Prefer-No-Speculative-Parsing: W3C Perf WG / August 29, 2024
- https://github.com/explainers-by-googlers/prefer-no-speculative-parsing
- https://explainers-by-googlers.github.io/prefer-no-speculative-parsing/
- Alex: here to talk about an OT that we ran in Chrome
- … HTTP header proposal coming up
- … Speculative parsing is an optional step that’s specified (without specifics)
- … UAs scan the incoming HTML tokens
- … This is very useful for the vast majority of pages on the web
- … But some use cases don’t benefit. E.g. pages that have no resources (everything inlined or minimal)
- … Cases where minimal resources are specified but the page surfaces them through preloads
- … Otherwise there are cases with privacy concerns
- … Ran an OT on that, that disabled the speculative scanner step in Chromium
- … Saved a few ms to some pages - depending on DOM complexity, page size
- … e.g. the HTML standard takes a few hundred ms
- … Some community feedback related to consent management - using CSP to prevent preloading
- … Intended to allow well informed web developers by hinting the browser that preload scanning is better not used
- … “Prefer” allows UA to ignore the hint, to avoid a binding contract
- Explainer: https://github.com/explainers-by-googlers/prefer-no-speculative-parsing
- … Spec proposal monkey patches the HTML spec related to it
- Jacob: Which metrics improved?
- Alex: loading metrics, LCP, FCP, main thread blocking time
- … depending on the browser implementation
- Ian: have you considered using document policy?
- Alex: No.
- Ian: Might work better, as it related to the document
- Yoav: You mention the benefits were higher in weightier pages like HTML spec, vs. more standard pages, have you considered trying to speculatively load the first 10-20 KB or N tokens, and then cutting off the parser that way?
- ... You can preload scan assets at the top of the HTML if there are any, but stop after 30 MB of HTML
- Alex: Yes, one consideration. Looking for the sweet spot on the web. That number is hard to predict. There are still savings to be had by explicitly disabling it.
- ... Full advantage if knowing the page has no resources to fetch, or other use cases mentioned, explicitly disabling the speculation is much more performant
- Yoav: I don't think it should be a blocker for this, not as a replacement, above 1 MB of HTML don't preload scan.
- Alex: Scope of the proposal doesn't look at optimization of the preload scanner, one of the reasons I want to make it optional and avoid binding contracts, I want to make it still possible
- Jase: How does this interact with 103 Early Hints, does the speculative parsing still run when that is active and a developer is already explicitly specifying resources to fetch?
- Alex: I don't think this would affect Early Hints
- Abhishek: Does the approach of using "prefer" make the privacy benefits potentially non-deterministic from the perspective of a website owner?
- Yoav: Cases where you have URLs in the HTML, and somehow scripts prevent them from going out?
- ... Not very clear what that concern is, would be useful to get more information
- Alex: Trade-off between explicitly disable and "preference", downside is the former is it's binding at that point
- Yoav: One thing I'd prefer, if this was not necessarily aligned with the action, but with what the browsers are trying to tell the browser.
- ... Could it be called "resourceless-document" it would be more aligned hint
- ... Was that something considered?
- Alex: Yes, but not too much. More targeted signal
- Nic: Yoav are you saying "resourceless-document" might trigger additional behaviors in the future?
- Yoav: I've heard feedback from devs to turn off speculative parsing where we shouldn't be turning off speculative parsing
- ... Even though it's a non-binding contract, browser still needs to decide if the action would be correct or not
- ... A hint more aligned with the document
- ... e.g. you hinted there were no consoles, but 20 were fetched, there could be console warnings
- Alex: If a page declared that I don't want Speculative Parsing, but it had resources that could be prefetched, browsers could do PGO.
- Yoav: Personal opinion
- Alex Christensen: Could we have a way to say "this is a document w/ no subresources", turn off speculative parsing but would also disable all fetching
- ... If you load a document that actually has sub-resources, we'd be in a mode that we wouldn't fetch under any circumstances
- Yoav: Document could say it doesn't have any HTML-based resources, but it could fetch resources based on user actions
- Alex: Turning off Speculative Parsing seems to give more flexibility
- ... Turning off the fetch all together seems more scary somehow
- Jacob: Would be very interesting to see a "sweet spot" calculation if that's somehow possible. E.g. at what point does the overhead on large docs regress loading related metrics? That might help webdevs to understand when they'd want to add this (or platforms could automatically add it, if they know the HTML output during e.g. static generation).
- Alex: That number is hard to find, even the smallest documents do have savings
- ... As far as guiding devs on when to add it, that's an interesting note
- Pat: Main concern is it's browser-specific. A site may do something that would help one browser but hurt another. Browser behavior may help at one time but hurt in the future.
- ... Feels like adding a layer of voodoo on top of the browser that's complex already
- ... vs. the "resourceless-document" gives the browser a better idea of what to tune
- Alex: That makes sense
- ... Any other opinions on the header name, though moving into document-policy may change that
- Pat: "Prefer-Minimal-Document" or something along those lines. Or some way to indicate most of the content of the page is in the HTML vs. external resources.
- Alex: My thought was it would give more flexibility to control that feature, vs. a page that has sub-resources, but it's not important to have speculative parsing
- Pat: You could have subresources, but still tell the browser most of the content needed to render is in the HTML itself. So stop or defer prescanning.
- ... Concern is about browser-specific assumptions, that may be different by browser
- Yoav: On that front, is this something considered
- Bas: Not something that would be terribly difficult. I do share Pat's concern around an additional layer of voodoo in this part of the browser
- ... This isn't well spec'd, and if our browsers do slightly different things, what size do you call it quits, those kind of things
- ... Feels like a rather-vague hint
- ... "Why" is the website telling you this? Is there an option other than respecting the hint? If not, probably shouldn't be a hint at all
- ... Struggle with voodoo-ness and the vagueness of the hint itself
- ... I was part of the will-change CSS property, I don't think that worked out very well
- Carine: I would not call it voodoo but it does not necessarily simplify the developer's life, because it assumes the developers know what happens in the browser, but that's not the case.
- ... It could have different effects on different browsers
- ... One thing developers have today is different response time in different browsers and it's not always clear why
- ... I do like this going into document policy
- Jacob: For web devs, it would be awesome to understand when you want to enable this or not enable this. Developers may not understand what it does. More and more people may just slap it on their webpages. Worst case is it starts decreasing performance.
- Bas: Some precedent to people doing that. Understanding use-cases better: what are the concrete use cases and how common are they?
- ... It's not just not-fixed in browsers, but it's not fixed over time.
- ... If it's a hint that there's a lot of resources under the fold, that's more concrete
- ... Not clear what we do with that hint
- Alex: If we switched the naming to more hinting about the number of resources in the HTML, like "no resources in HTML", might that be more declarative?
- Yoav: Yes, and would also allow tools to tell developers if they're doing it wrong
Confidence API shape discussion - Mike Jackson
- Mike: Back and forth in Github issue around API shape
- ... Whether or not it should hang off PerformanceTiming objects itself, or introduce a new method
- ... 3 different options here
- ... Hanging off timing object
- ... Contains confidence, value and randomizedTriggerRate
- ... Pro: Extensible, always available
- ... Cons: Could change over time, initial nav we may get some low confidence, but as we look at more data over time it might be high confidence
- Second proposal
- …
- ... Still loves off NavTiming object, but you need to opt-in to it through PerformanceObserver
- ... In this particular case, you wouldn't get the value back unless you asked for confidence metadata
- ... Wouldn't get value until onload fired, but you would get a finalized value
- ... Third proposal
- ... On performance object itself
- ... Once confidence is finalized we'd be able to return it
- ... Extend to other types, such as server request or element layout
- ... Q&A?
- Nic: Could you explain why the confidence may change over time?
- Mike: The main thing - imagine you have an extension installed that loads the system after the initial navigation start
- … That could be something that happens later
- Bas: I struggle with what “confidence” means here. It names some scenarios that would happen on a first page load
- … but there are other things - background activity, GCs
- … Are those not represented? Which of these things should generate low vs high confidence
- … background activity also risks adding privacy and security concerns
- … Seems very tricky and fiddly
- Mike: In the past the focus has been around abnormal conditions - UA launch (DLLs loaded off disk)
- … we’ve see other anecdotal feedback around extensions
- … Or system OOM/CPU at 100%
- … Not run of the mill activity
- Bas: leaking information about whether the browser just started out
- Yoav: One important thing here is that this is all fuzzy info, none of this is usable to the page itself. It's only usable in aggregate to filter out measurements that are probabilistically low-confidence. There's a roll-of-dice element here that this information is effectively probabilistic
- ... Can't do anything as a web-developer on the spot, just in aggregation
- Bas: But low/high could be use
- Yoav: In n% of those pages, that is a lie
- ... Presumably that should be manageable
- ... Can't presume info is correct in any particular case, only in aggregate, after de-biasing the data
- Michal: There's a term for this that we borrowed, this approach is used by Differential Privacy APIs
- Andy: Linked to minutes from previous conversation if anyone wants to review that
- ... https://w3c.github.io/web-performance/meetings/2023/2023-11-09/index.html
- Michal: For proposal 3. The advantage of the previous proposals 1/2 is that the data is there, and you know it's available. 3 you don't know
- Mike: You would get data when the load event triggered. For option 3, data wouldn't be available until we "finalized" it. If you're trying to get data when you start on the page, the data may not be there.
- Michal: I wonder if Proposal 2, the UA could defer how late it issues the observer calls. Ah it's not triggered on the confidence, but on the type of entry.
- ... Once the data is measured, if the confidence changes after, it shouldn't affect the navigation metrics
- Yoav: In my mind the main question here is do we want to attach the confidence data to more entries, or would we want that in the future? Other than just NavigationTiming entries?
- ... That would potentially impact the API shape
- ... Talking about the complexity that Bas mentioned, maybe only focusing on NavigationTiming now would be a good idea
- ... Because of the cases you mention where it's mostly around browser launch. Out of memory, CPU could happen later in the page. More sensitive and leaky and complex than just dealing with the navigation.
- ... Is it fair to say navigation is the only use case we envision at the moment
- Mike: The only one I'm aware of
- Yoav: In that case, if we focus on Proposal 1 vs. 2, 2 is only available at onload, meaning we'll miss 20-30% of cases where onload never fires, what are the advantages of 2 vs. 1.
- Mike: Advantages of Proposal 2 vs. 1, is that developers have to opt into it, so we're not leaking it to people who don't care about it. And RUM providers you're only getting one confidence at the end vs. dealing with that value changing.
- Yoav: Do we envision that changing over time in Proposal 1?
- Mike: Example of starting the navigation and we think it's a high-confidence state, but at some point an extension comes in and we think it's no longer a representative navigation.
- Yoav: Loading until load time gives the browser more time to understand the confidence
- Mike: In the data I've seen and reviewed, we haven't seen the variation between DCL and load event, they're happening in the lead-up to that section
- ... I was very focused on User Agent launch
- ... Variations between DNS, those types of things
- Andy: Navigation vs. other things, after the page is there and loaded, this confidence could be represented by compute pressure maybe? But in many cases it couldn't be.
- Mike: Compute Pressure talks about what's happening "now" on the system, and the things you're interested in are in the past, and may have happened before your script could get started running to measure Compute Pressure
- Bas: Extensions were mentioned. How could they affect this? If some extension would reliably make the confidence level low, you could identify clients with that extension setup look at agg high that value. How does this represent extensions?
- ... More to implementation complexity, how does the browser know what extensions could affect confidence?
- Mike: The scenarios I was thinking of are:
- ... 1. Focusing on Chromium, with web requests and ad blockers, preventing trackers from running, it potentially impacts the performance of the page as it does less work.
- ... If there's a substantial number of those, the extension makes the page faster (or misbehave) then what people would expect if no extensions are installed
- ... 2. On the other side if the extension is causing a lot of work, it could be making that site slower
- Bas: Would those extensions always make the confidence low?
- Mike: Depends, not all extensions impact all sites in the same way
- ... If I just have an ad blocker installed, if it's blocking 20 request it's fine but 100 requests maybe that's not fine
- Bas: Could devise a site that could detect if the user has that extension over several navigation if the confidence is under N %?
- Yoav: Let's continue the discussion in a couple weeks
.png)
.png)
.png)