Nic: wanted to talk about surfacing cache and proxy information
… proposal from Mark Notingham
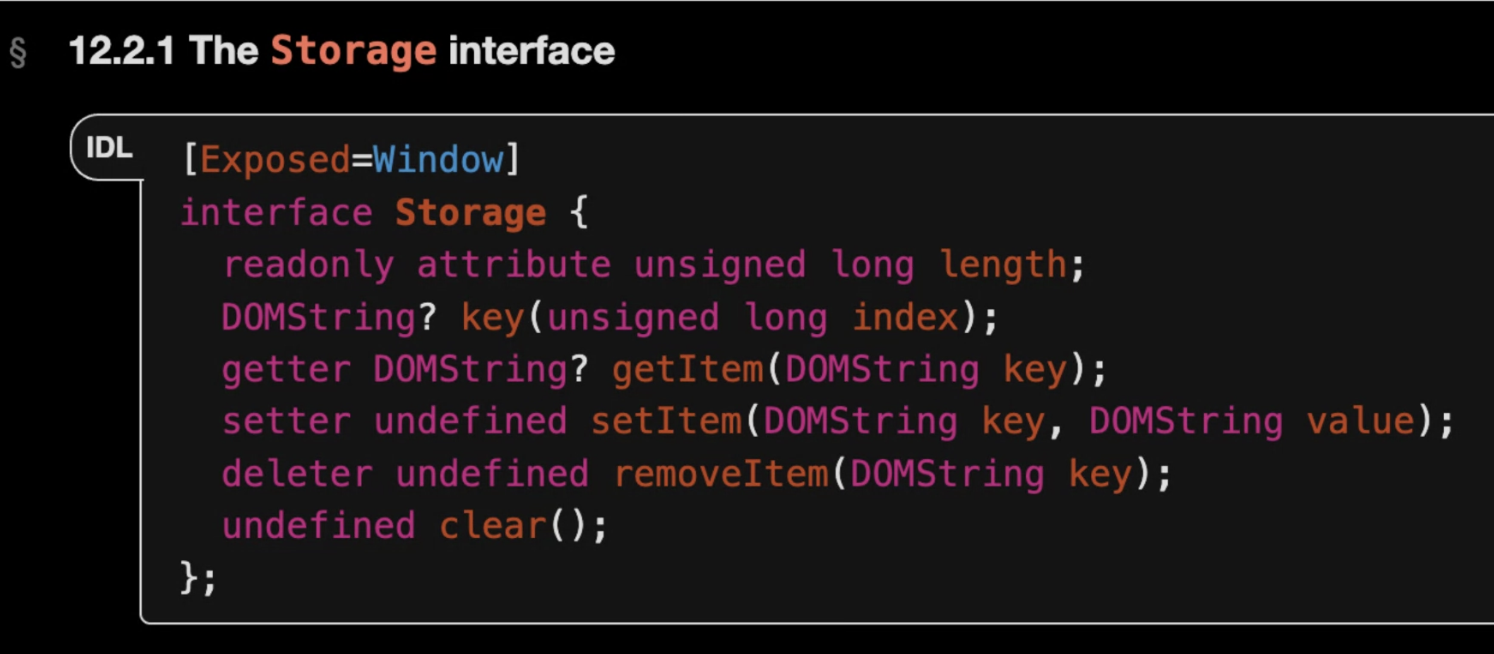
… part of the proposal depended on Structured Fields and being able to get their information in JS
… Talked about it at TPAC, there’s an explainer
… Builds on top of Cache-Status and Proxy-Status RFCs
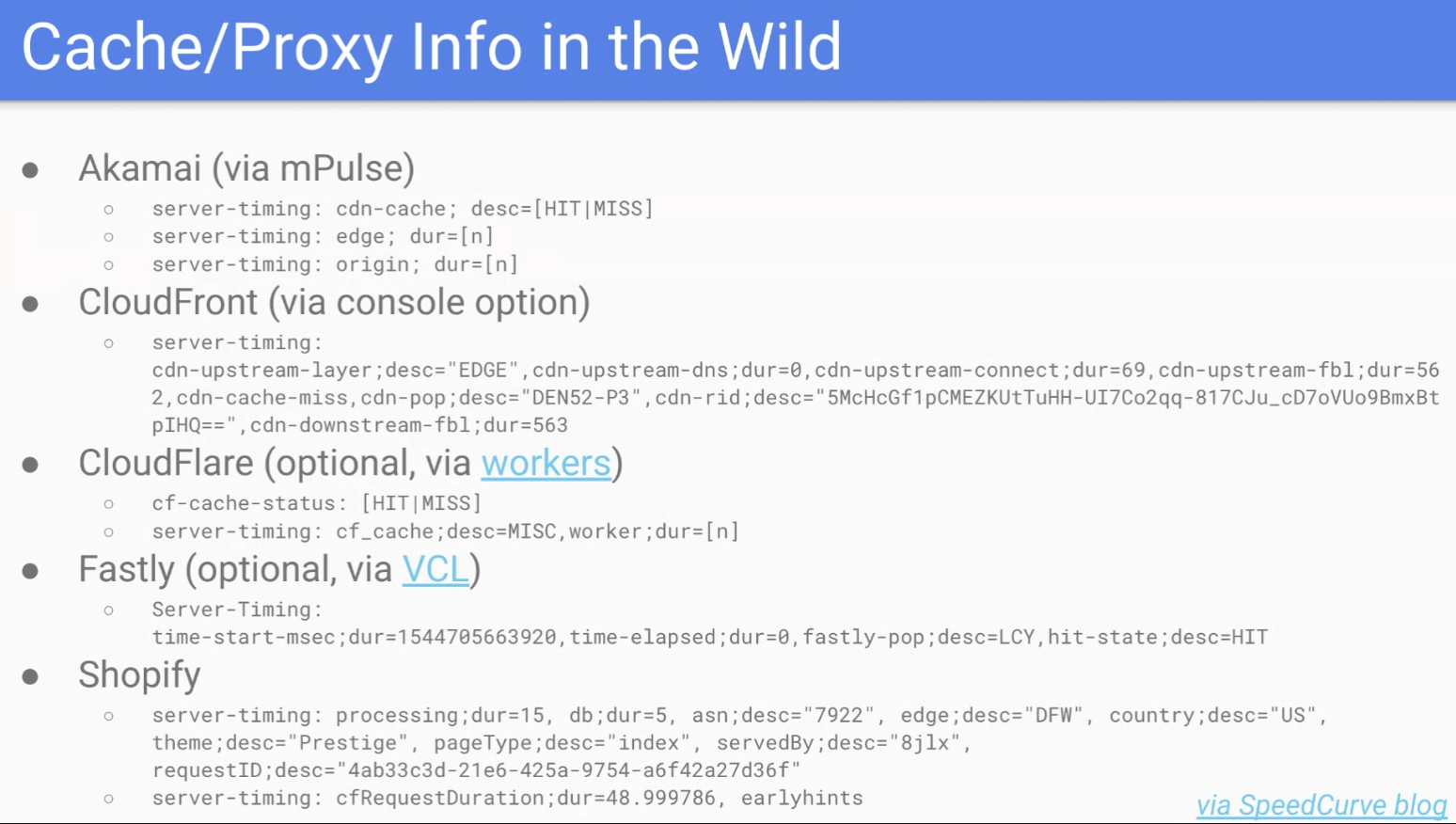
… This information is part of CDNs HTTP headers
… A lot of it is via Server-Timing
… Akamai emit a CDN-Cache header for hit or miss, other CDNs do similar things
… Shopify does as well
… The proposal builds on top of proposed RFCs, couldn’t find examples in the wild
… Seems like the CDNs are willing to expose this information to server timing (maybe as an opt in)
… Not consistent and different header names and values mean different things
… Proposal from Mark is to surface the conventions of Cache-Status and Proxy-Status
… Structured Fields can be exposed through Fetch
… Proposal to add a “rum” keyword that everything after it would be exposed to JS
… A few questions for the group
… Do we (RUM and performance folks) want this information? Can we (CDNs) emit this information?
… How would we (WebPerfWG) would map this data to ResourceTiming?
… Example from Mark was a cacheStatus/proxyStatus attributes on the RT entry
… Bringing this up as structured fields made some progress
NoamH: Could be useful when doing work integrating compression dictionaries. It was challenging to understand CDN hit/miss at large scale.
Nic: The examples I shared were server timing. There are non-exposed headers
NoamH: From a script tag we can’t access those headers
Nic: As a CDN/RUM, we merge that data together for our customers. So interesting data for us
… For multi-CDN customers, it can be useful to have similar semantics and compare different CDNs
Jacob: Concern about Server-Timing was arbitrary content inside it. Is that still a concern? Would those headers be also abused? E.g. you could use it for A/B testing?
Nic: It is structured, but it can contain arbitrary data
Yoav: If you want to send arbitrary data, ServerTiming is there
… This is an effort to move things to more semantically stable terrain
… Not as much incentive to use this instead of ServerTiming
… Could try to ensure it’s clamped to values surfaced
Nic: but it can contain arbitrary names
Neil: hybrid public edge at the BBC. Distinguishing between the two and cache hit status would be super interesting. We’d like to integrate those with CWVs. Can use Server Timing, but would like this to be more structured. So this would be valuable.
Nic: Speedcurve has been pushing for this as well. Want to discuss this at the RUMCG as well
NoamH: I wonder if more complex scenarios that are CDN specific should also be enabled and exposed through that. How much do we want to expose?
Nic: Given the flexibility of the cache status header, it would allow for multiple layers to be exposed
NoamH: Could we agree on known patterns
Yoav: Are you hoping to standardize the names?
NoamH: Yes if we could map the most common scenarios?
Yoav: Yes e.g. Layer1 Layer2 Layer3, can know miss/hit/hit etc
NoamH: Yes
Yoav: Would be good to involve the IETF with those semantic definitions
Sergey: overlap with server timing is mostly the “hit/miss” parts. Additional information would be the CDN name, other attributes. Will this provide us enough unification on its own?
… Might need to be more flexible
Nic: Even the hit/miss comes as a different value in ST so, anecdotal, mPulse aren’t trying to decipher today
NoamR: Does the browser have a say in this? Or is it just passing information?
Nic: The proposal would be to surface it through resource timing
NoamR: but it’d be similar to Server Timing. So why not attaching the payload to Server Timing
Yoav: Advantage of this over specifying semantics in ServerTiming is that there are already standard headers that are supposed to reflect that information.
NoamR: Reflecting existing things. Putting more stuff in other headers that are kind of like ServerTiming.
Yoav: Intention isn’t to add arbitrary strings, it’s to have well-defined semantics in server-side Headers, have browser expose those headers similar to way it exposes ServerTiming.
NoamR: It’s not something the browser actively does something with. Arbitrary strings in that anyone can lie about it.
Yoav: That is true
NoamR: You can access via ServiceWorker or via Fetching
Yoav: If you have the privilege of using those
NoamR: If some of the solution in browser space, clarify in static ServiceWorker space, declare XYZ headers are passed to ResourceTiming
… Something allows you to expose them
Yoav: Static SW thing that translates Cache-Status and Proxy-Status that translates to some well-defined ServerTiming structures, that could work but is complex
NoamR: If browser doesn’t know about this data it could expose just as a string
… Otherwise just pushing browser interop issues in to the schema
… Version1 has somethingsomething, Version2 has something different, why do you need the stuff browser doesn’t really do anything with this
Neil: In terms of caching layers, that will vary a lot depending on what page requesting/mode, etc, so having a numbered approach would be tricky for us.
… In terms of Cache Status itself, there’s HIT, MISS, HIT-CLUSTER, MISS-CLUSTER
Nic: Akamai has a revalidate status
… Next steps?
… General agreement that there’s value in the data, but potential disagreements on how to surface it
… Need to talk to CDNs and see if we can agree on consistency
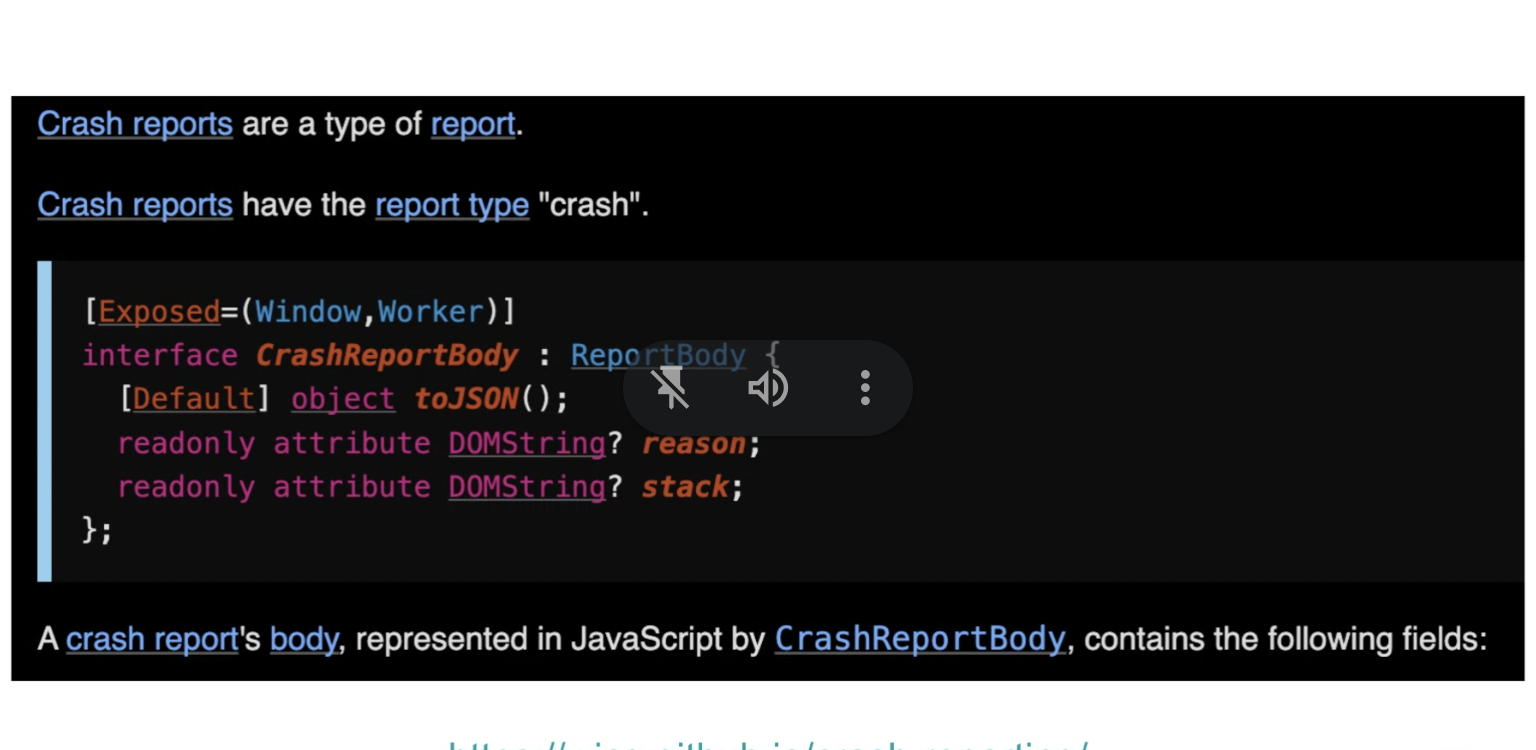
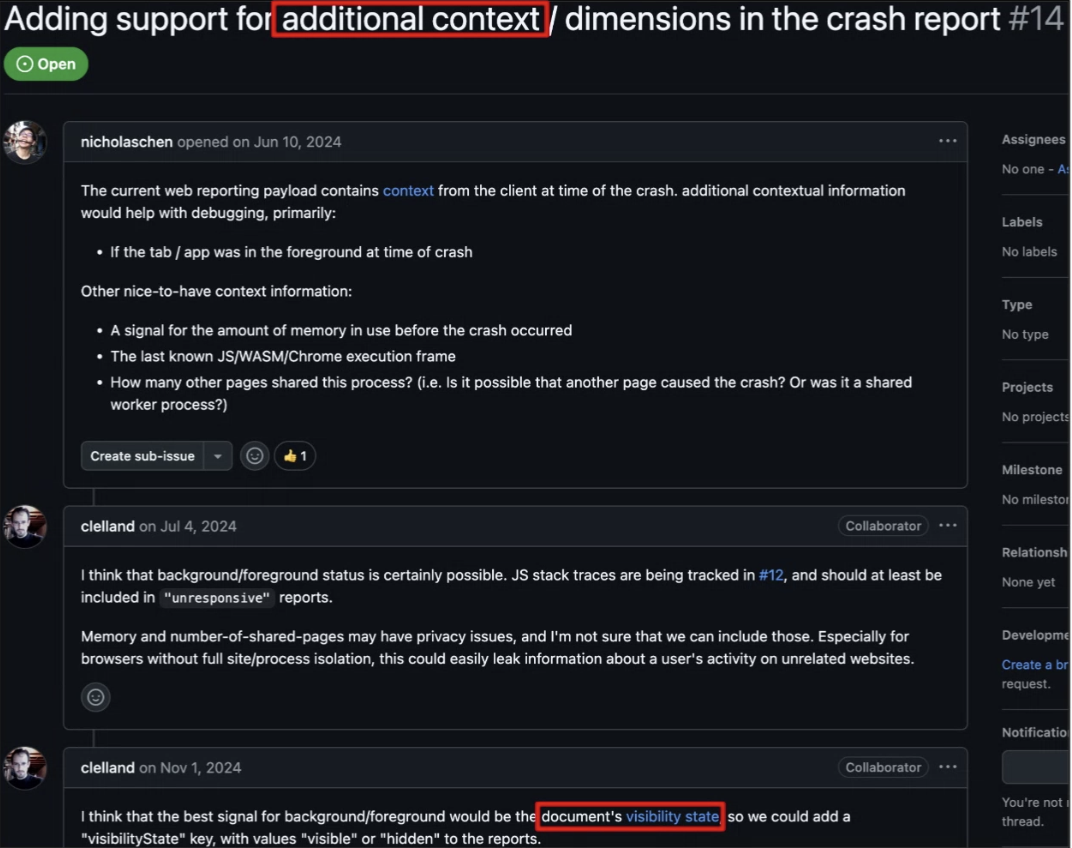
Dom: We’ve been hearing from Chromium partners about missing context in the crash reporting API
… A bunch of default bits of information
What was the cause of the crash and a stack available in unresponsive pages
… useful but want to make it more useful
…
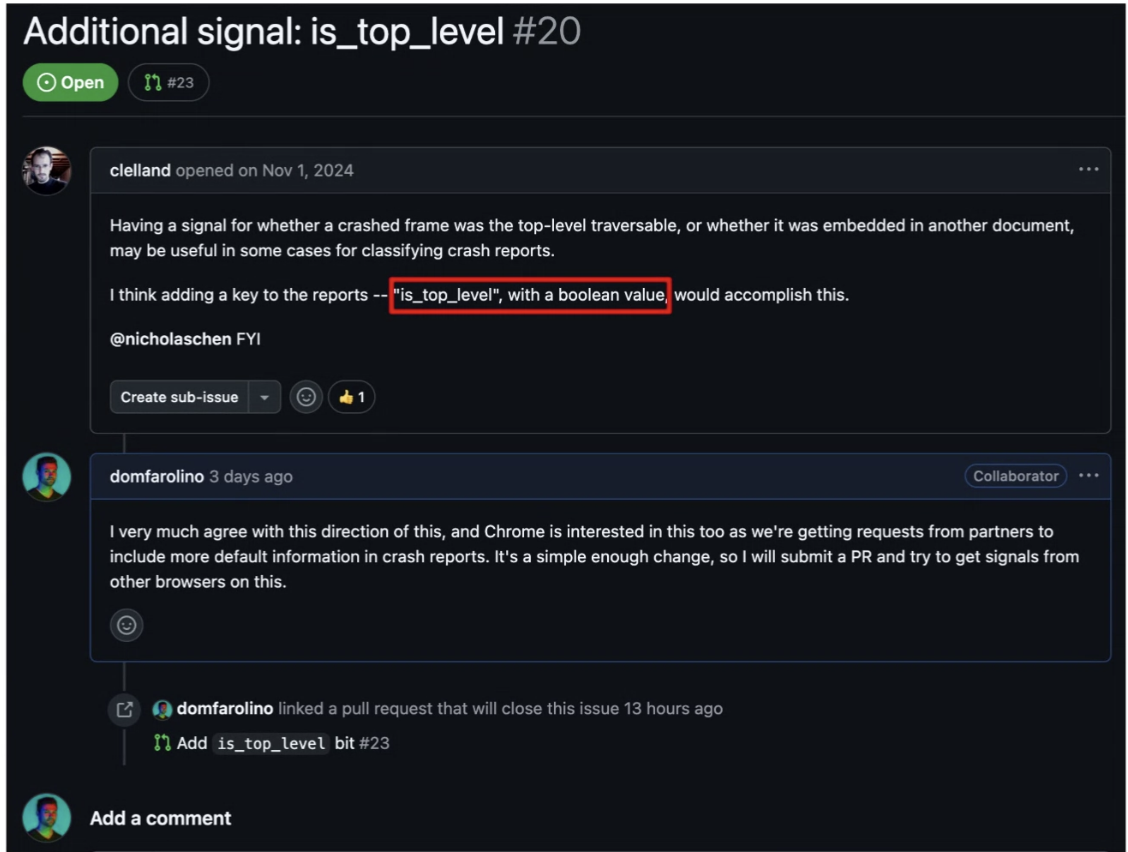
… Are we in a top level context or not?
… General issue about adding more context: is the process forgrounded?
… Issues have been open for a little while. We think there’s low hanging and safe fruit to add to these reports.
… Playing with spec and implementation, but wanted to get some more feedback
… Second part of the proposal is about adding arbitrary information to the crash report
… Proposing a key/value store that will be sent in the case of a crash
… Enable to capture more application state, client side feature flags, etc
… Developers have expressed interest
… Chromium is supportive
… The easy version of this is
… Have a crash reporting API storage that would enable you to pass app state and that would be compile if the page crashes
… Open questions around this: where should the getter be placed? Are there privacy implications? (developers can already send arbitrary data)
… Wanted to gather thoughts on usefulness and risk
Peter: works on telemetry for workspace. Want to understand crash reports. key/value metadata would make the reports we’re seeing significantly more actionable
Andy: Filed a Safari reporting API position a few months ago, when we added stack reports
Dom: you had a question about browser version crash ID
… Different browsers do different things with crash IDs, we can still do that in Chrome, but it’s a little tricky
… collecting all the state for that would be hard to spec
https://github.com/mozilla/standards-positions/issues/288
Andy: Vendor ID is a separate thing, so let’s split it
Ian: Vendor ID would have privacy issues
.. Apologies if I misrepresented your position, Bas
Bas: We are positive, but haven’t commented on this specifically. Seems harmless
Dom: harmless and useful
Ian: Seems useful. Unclear if we want it for reporting in general, but useful for crash reports
… You can associate the data with a crash, so that’s the only extra bit exposed
Dom: Even that bit can somehow be estimated..
Sean: We have it disabled (Reporting API), but plan to enable it
… Talking about disabling crash reporting
… Privacy issue with exposing the memory
Dom: Some discussion about that on the issue. Agree that this is tricky
… Would a new API require a different standards position issue?
Sean: separate mozilla position
Dom: good feedback. Would also file issues for a TAG review. Planning to get a spec PR on it and go from there.