WebPerf WG @ TPAC 2025
bit.ly/webperf-tpac25

Logistics
TPAC 2025 Home Page
Where
Kobe International Conference Center - Kobe, Japan
When
November 10-14, 2025
Registering
- Register by 23 Aug 2025 for the Early Bird Rate
- Register by 20 Oct 2025 to avoid late rate
- All WG Members and Invited Experts can participate
- If you’re not one and want to join, ping the chairs to discuss (Yoav Weiss, Nic Jansma)
Calling in
Join the Zoom meeting through:
https://w3c.zoom.us/j/8801790059?pwd=aPFvyrwhnW4TqfCIROznMNMoVob3Xr.1
Or join from your phone using one of the local phone numbers at:
https://w3c.zoom.us/u/kb8tBvhWMN
- Meeting ID: 8801790059
- Passcode: 2025
Masking Policy
We will not require masks to be worn in the WebPerf WG meeting room.
Attendees
- Yoav Weiss (Shopify) - in person
- Nic Jansma (Akamai) - in person
- Barry Pollard (Google) - in person
- Dave Hunt (Mozilla) - in person
- Bas Schouten (Mozilla) - in person
- Nazım Can Altınova (Mozilla) - remote
- Joone Hur (Microsoft) - in person
- Guohui Deng (Microsoft) - in person
- Robert Liu (Google) - in person
- Noam Rosenthal (Google) - in person (select sessions probably)
- Nikos Papaspyrou (Google) - remote
- Luis Flores (Microsoft) - remote
- Andy Luhrs (Microsoft) - remote
- Fabio Rocha (Microsoft) - in person
- Patrick Meenan (Google) - remote
- Hiroki Nakagawa (Google) - in person
- Fergal Daly (Google) - in person
- Lingqi Chi (Google) - in person
- Jase Williams (Bloomberg) - remote
- Michal Mocny (Google) - in person
- Kouhei Ueno (Google) - in person
- Keita Suzuki (Google) - in person
- Hiroshige Hayashizaki (Google) - in person
- Mike Jackson (Microsoft) - in person
- Eric Kinnear (Apple) - in person
- Carine Bournez (W3C) - in person
- Justin Ridgewell (Google) - in person
- Adam Rice (Google) - in person
- Benoit Girard (Meta) - in person
- Nidhi Jaju (Google) - in person
- Nicola Tommasi (Google) - in person
- Euclid Ye (Huawei) - in person
- Rakina Amni (Google) - in person
- Alex Christensen (Alex) - in person
- Sam Weiss (Meta) - in person
- Takashi Nakayama (Google) - in person
- Minoru Chikamune (Google) - in person
- Ben Kelly (Meta) - in person
- Takashi Toyoshima (Google) - in person
- Samuel Maddock (Salesforce) - in person
- Javier Garcia Visiedo (Google) - in person
- Eriko Kurimoto (Google) - in person
- Shunya Shishido (Google) - in person
- Anna Sato (Google) - In person
- Ming-Ying Chung (Google) - in person
- Shunya Shishido (Google) - in person
- Anna Sato (Google) - In person
- Jan Jaeschke (Mozilla)
- José Dapena Paz (Igalia) - remotely, some sessions
- Mingyu Lei (Google) - in person
- Shubham Gupta(Huawei) - in person
- Amiya Gupta (Microsoft) - remote
- Gabriel Brito (Microsoft) - remote
- Tsuyoshi Horo (Google) - in person
- Kazuhiro Kureishi (Cisco) - In person
- Randell Jesup (Mozilla) - remote
- Tim Vereecke (Akamai) - remote
- Ari Chivukula (Google Chrome) - in person
- Kota Yatagai (Keio University) - in person
Agenda
Meeting room request from W3C: https://github.com/w3c/tpac2025-meetings/issues/61
Lightning Topics List
Have something to discuss but it didn't make it into the official agenda? Want to have a low-overhead (no slides?) discussion? Some ideas:
- Lightning talks
- Breakout topics
- Q&A sessions
- Questions for the group
- Short follow-ups from previous sessions
Add your ideas here. Note, you can request discussion topics without presenting them:
- Please suggest!
- Web Font metrics - Yoav (0.5h)
- Unused preloads/prefetches - Yoav (0.5h)
- Party town and workerDOM discussion?? (0.5h)
- Memory-induced reload - Yoav (0.5h)
- CSS performance reporting - Yoav
Day by Day Agenda
Monday - November 10 (9:00 - 16:45 JST)
Recordings: Day 1
Location: 505
Tuesday - November 11 (9:45 - 18:00 JST)
Recordings: Day 2
Location: 505
Thursday - November 13 (9:00 - 12:30 JST)
Recordings: Day 3
Location: 505
Meeting Minutes
Day 1
Intros, WG feedback
Recording
- Nic: mission - measure things and make them faster!
- … progress - Excitement around Interop and CWVs, LoAF adoption, NEL and reporting are a separate workstream, speculation rules
- … 80 closed issues
- … Charter coming up for renewal. We’ll ask an extension and discuss rechatering on Thursday
- … RUMCG gained steam. Summary at 4pm
- … Incubations - need to review the list for the rechartering discussion. Not in the charter but interesting
- … Market adoption - up and to the right!
- … Looking at chair feedback survey: variety of experience in WG participation, people catch up on artifacts after the meeting, feedback on meeting times (keeping the current cadence)
- … recording (people like the meeting recordings)
- … requests to update the agenda and post it on slack
- … people like the meeting minutes posting
- … Keep recording the presentation and try to send agenda invites to slack
- … Please reach out with any feedback
- … There’s a request for a “getting started” guide. We should do a better job. The chairs take that as an action item
- … Full agenda for the next 3 days
- … Code of conduct
- … Record presentations and save discussions for after the recording
Recording
Agenda
AI Summary:
- Chrome’s speculation rules have expanded beyond the initial document “where” rules to include URL list rules, header-based rules, tags for analytics/experiments, No-Vary-Search awareness, and `target_hint`, with strong adoption (≈12% of navigations, major platforms like WordPress/Shopify) and measurable latency wins, especially on mobile.
- Eagerness levels have been refined: desktop uses hover/mousedown; mobile now uses viewport-based heuristics (links entering view) to avoid over-speculation while still gaining significant prefetch/prerender lead time.
- Chrome has added protections and limits (e.g., constraints around cross-origin iframes, HTTP cache reuse even when speculation is unused), and is rolling out features like same-site cross-origin prerender under flags;
- A new `prerender_until_script` mode is being explored as a middle ground (no script execution until activation) to ease deployment for sites worried about analytics/ads/JS side effects; there were detailed discussions about inline event handlers, race conditions, and how/if to measure error impact before standardizing.
- Open questions remain on safely handling inline events, scroll/hover tracking, and activation sequencing (paint vs run activation handlers), so `prerender_until_script` is considered too early for Interop, with further experimentation via feature flags and an Origin Trial planned.
Minutes:
- Barry: Work with speculation rules team
- ... Hasn't formally been adopted into this charter, but have presented before
- ...

- ... Introduce API we've worked on at the time
- ... Not just a web API, part of Chrome UI
- ... Dev tools support
- ... Origin Trial (OT) and plans for API
- ... Good results from early adopters
- ... Talking today about what's happened since then
- ... What's changed since then?

- ... Shipped document rules "where"
- ... More experiments going on
- ... Two types
- ... URL List rules

- ... Similar to link rel=prefetch syntax
- ... Document rules gives a where clause, matches URL

- ... URL list is useful if you know what the next page is
- ... Document rules is if you're uncertain and you want to wait to see how user will interact with the document
- ... Source is now optional
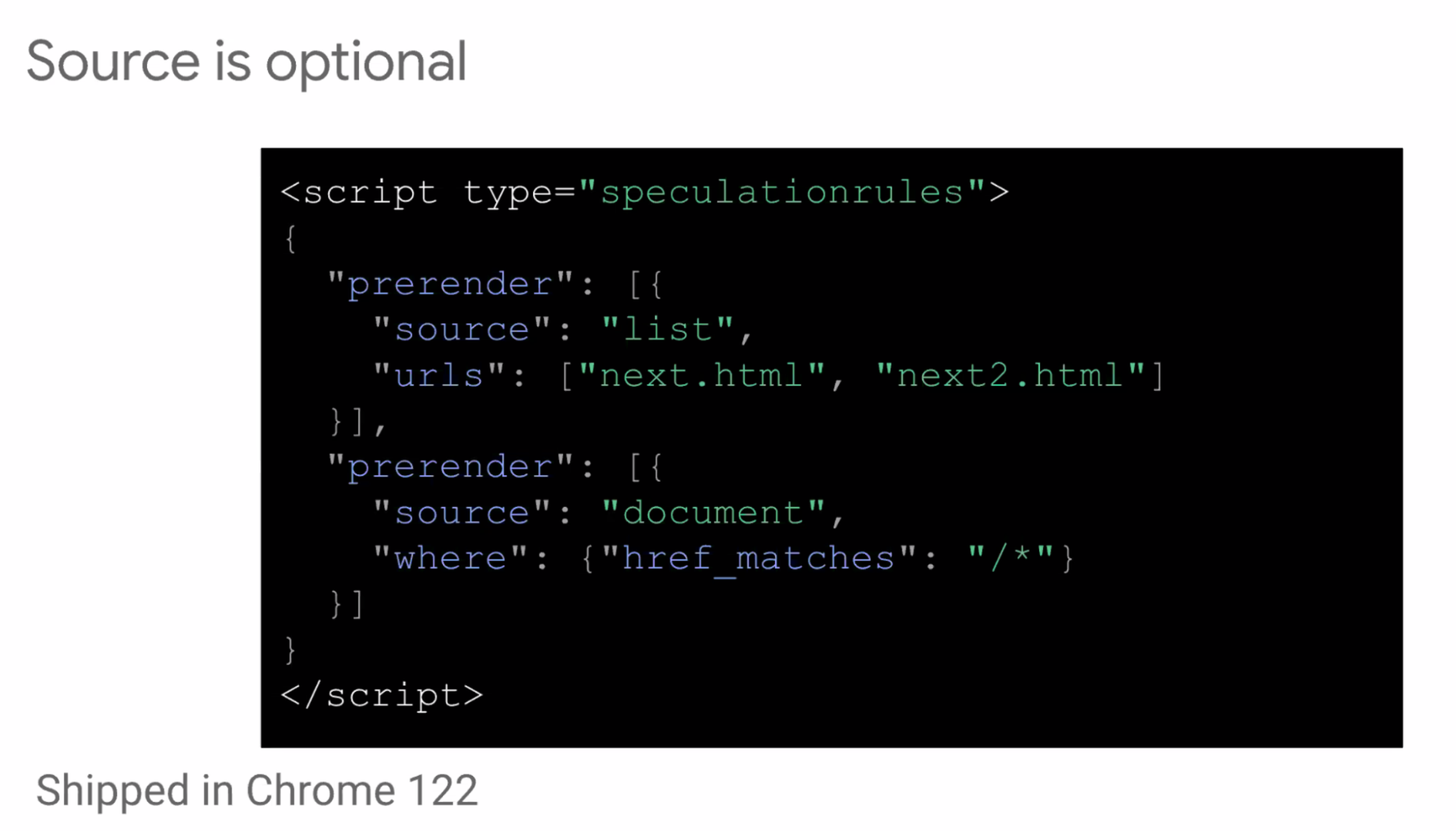
- ... Will be kept, may not make sense to remove
- ... You can have more complicated document rules
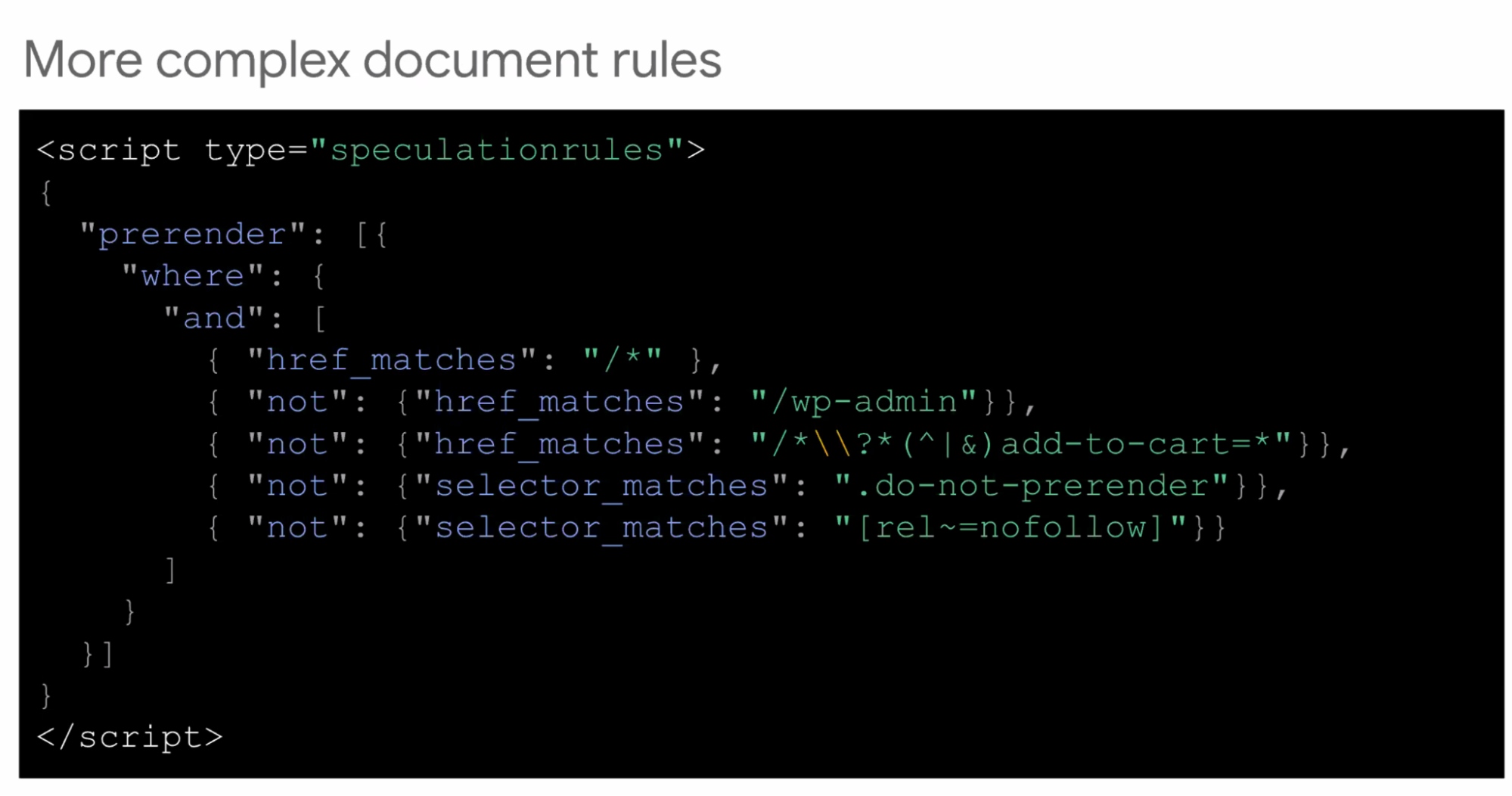
- ... and, or, not clauses
- ... Exclude things like wp-admin, add-to-cart
- ... Language available to you for selecting the most appropriate rules for you
- ... Inclusion lists can be safer

- ... where/or clause
- ... Document rules are the preferred way for most sites to deploy
- ...
- ... No-Vary-Search
- ... What's the difference between these two URLs?

- ... In most cases, these two URLs are identical (content of the page is)
- ... Same HTML may come back. Some URL parameters matter (on the server side), some don't
- ... HTTP header to specify what matters

- ... Exclude certain params
- ... Speculation rules is No-Vary-Search aware

- ... Can even tell there's a No-Vary-Search expected in the response
- ... If the query does change client-side, then you need to wait until the activation there

- ... Added support relatively recently for HTTP cache
- ... CDNs could use this as a standard way of specifying
- ... Header-based speculation rules

- ... Can include in external JSON rather than inline in HTML
- ... Useful for CDNs or platforms to add more easily

- ... Tag speculation rules
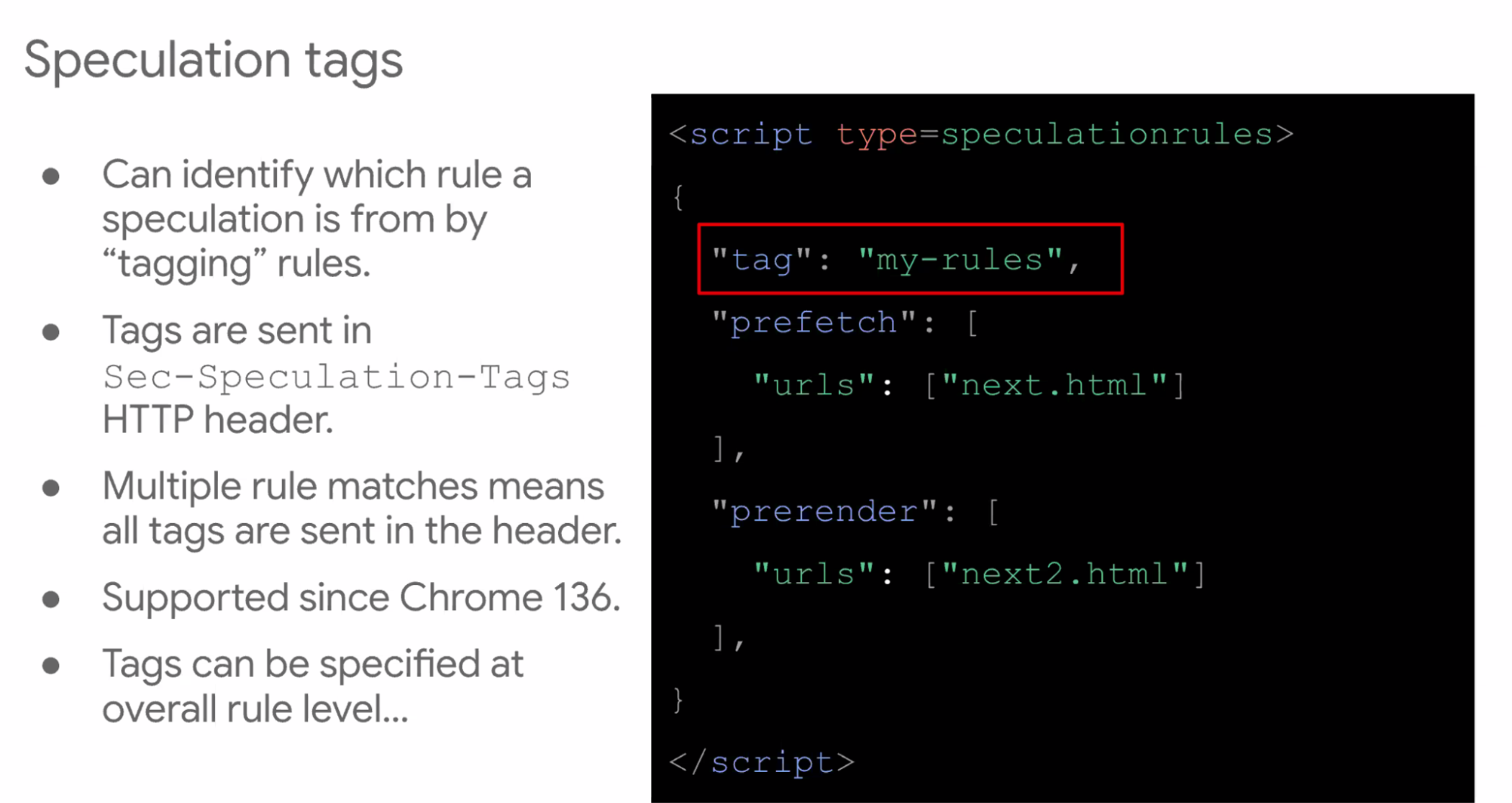
- ... Those tags are sent when sending request to the server
- ... Specified at overall rule level, or you can have separate tags. Useful for platform deploys.

- ... Useful for analytics, logging, a/b tests
- ... target_hint support added
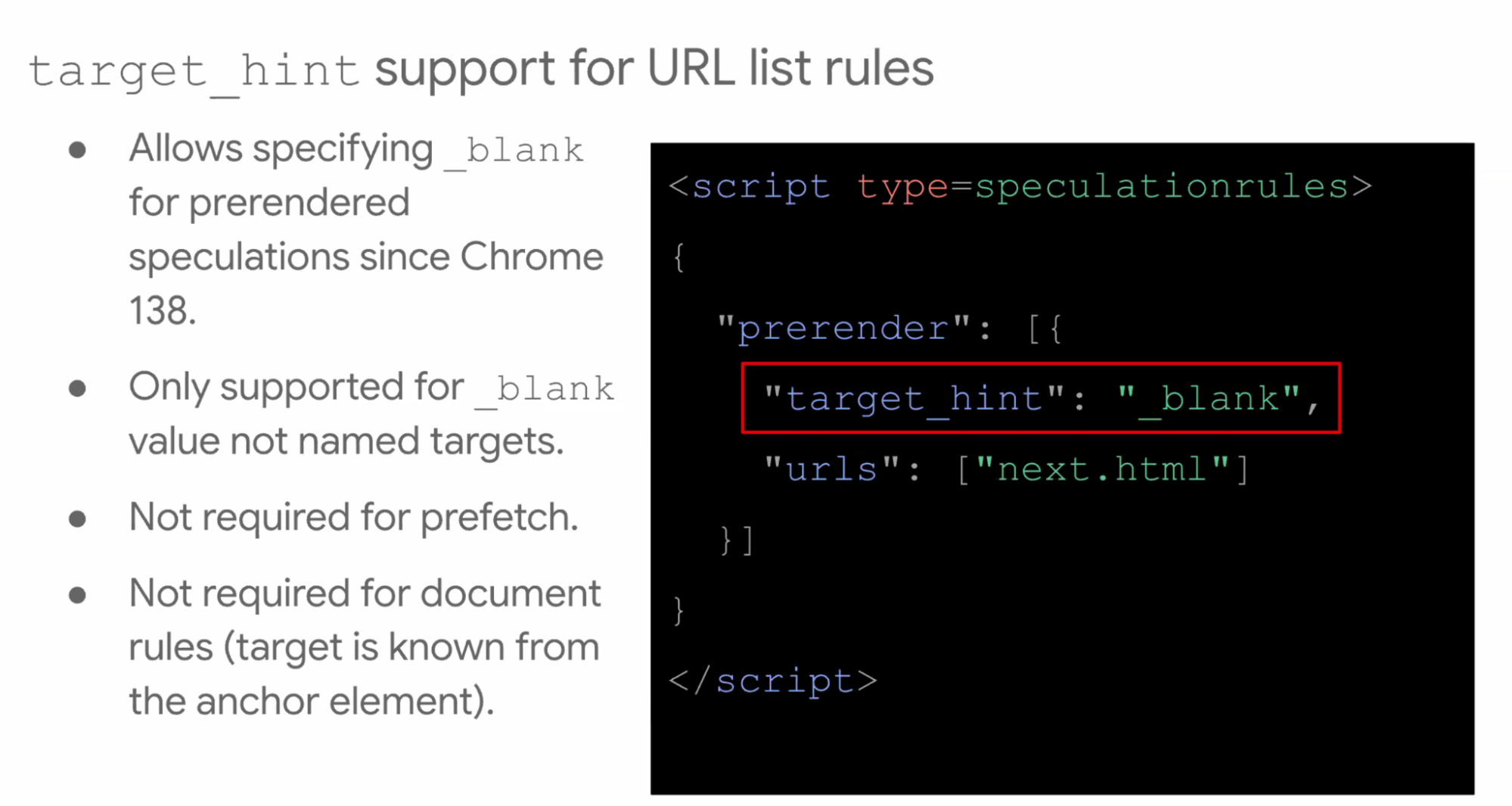
- ... If you wanted a real background tab with target=_blank, we allow you in your rule to specify that
- ... (don't support named targets)
- ... Isn't required for prefetch, more if you have a hard list of URLs

- ... clear-site-data allows you to clear those speculations
- ... Eagerness value you can specify
- ... Before:

- ... Immediate and eager used to mean same things, make network requests at low priority
- ... Moderate gives you the hover activity over a link, after 200ms we'll do that
- ... Conservative is when you start clicking (e.g. mouse down before mouse up)
- ... Now we're moving ahead with:

- ... On mobile we've added viewport heuristics since there's no mouse hover
- ... As your links scroll into viewport, we assume that's as close to hover as we can get
- ... Moderate viewport heuristics, anchor is within ~n pixels distance
- ... As people are scrolling you don't want to speculate loading

- ... Prefetch on eager thing, upgrade to prerender on something more
- (demo)
- ... From Akamai (Tim Verecke), rolling out eagerness changes
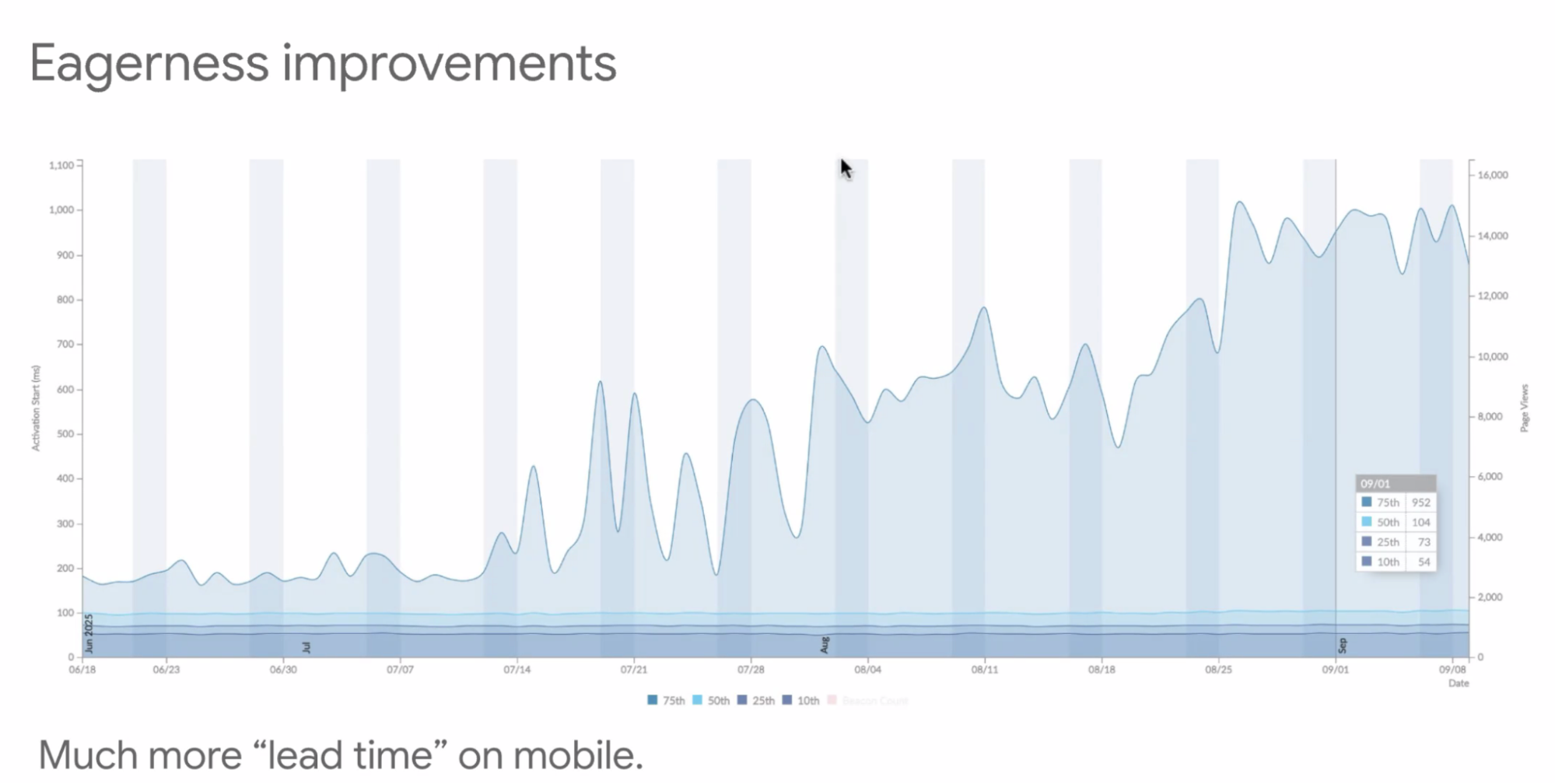
- ... From ~190ms header start to almost a second lead-time on mobile
- ... Speculations have a cost, from site owner, CDN, end-users
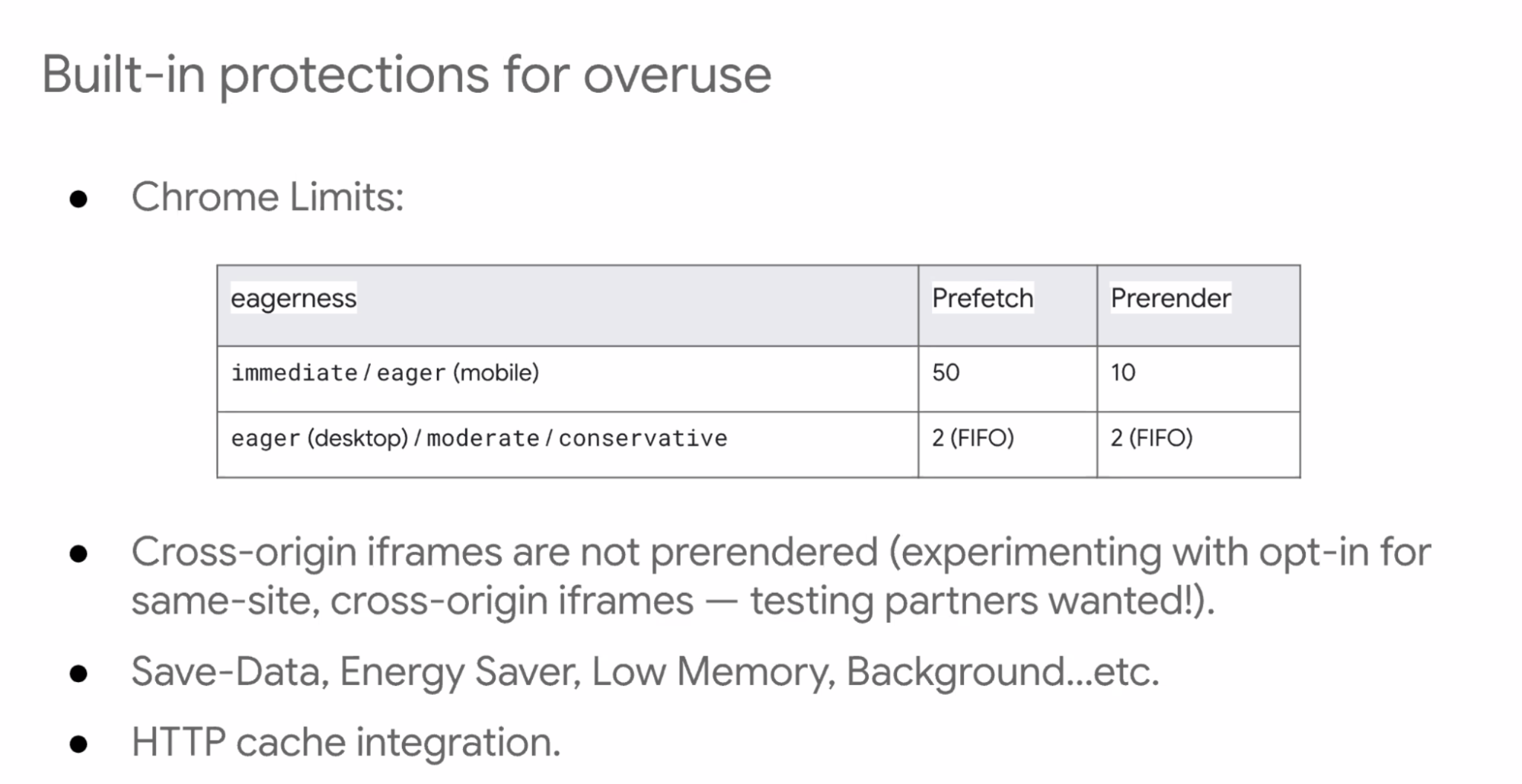
- ... Chrome has limits
- ... Cross-origin iframes, those aren't prerendered by default, there's a way to opt-in for same-site X-O iframes
- ... Lots of automatic built-in protections there
- ... Want people to use this in the right way
- ... Will store and check from HTTP cache, even if speculation isn't used, you may have already preloaded it into the cache
- ... prerender_until_script

- ... Sites are nervous/anxious about impact from analytics, ads, etc
- ... Prerender is hard lift for many platforms to deploy
- ... Some platforms need to be quite conservative
- ... Most of this is used to unintended consequences of JavaScript
- ...

- ... Tried to improve awareness of this for third-parties to be prerendered aware
- ... Even with that, it can be hard for 3P and 1P scripts to be aware
- ... We had a link rel=prerender, deprecated in 2018, changed to no-state prefetch
- ... Which prefetches document and all resources (via preload scanner)
- ... Thought it'd be a middle-ground between prefetch and prerender
- ... prerender_until_script

- ... Scripts are not executed
- ... This has interest from partners
- ... Want feedback

- ... Inline event handlers

- ... Is it OK to run them? Most do require user interaction
- ... In a lot of cases it'd be better to run, e.g. common async css hack. Once finished loading, we want CSS to be applied immediately
- ... Fewer cases I'm finding that need this paused
- ... Some more obscure features for cross-origin prefetch
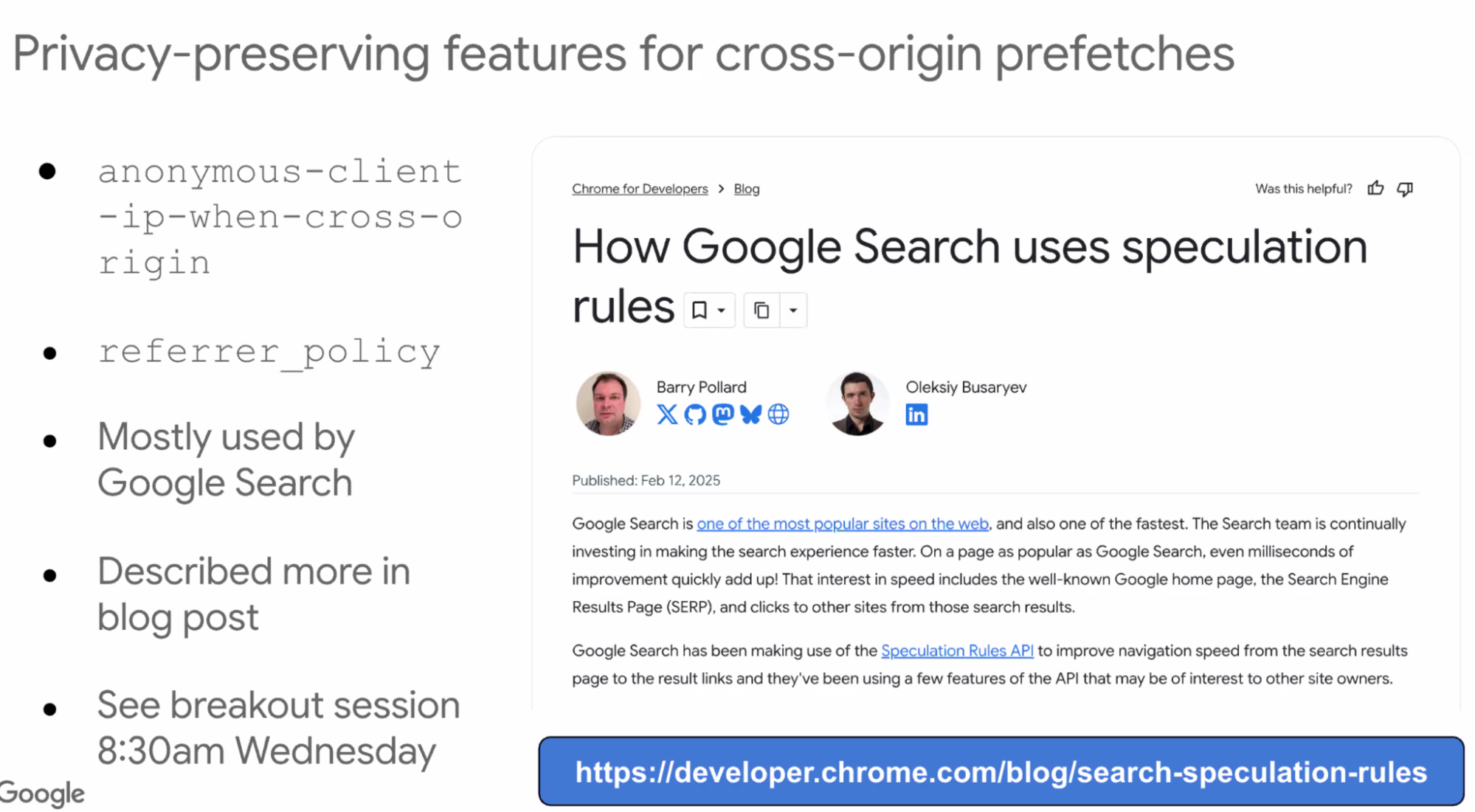
- ... Google Search are first two preloaded automatically, uses Google anonymous proxy for privacy
- ... These features are mostly used by Google Search
- ... Breakout talking about this in more detail
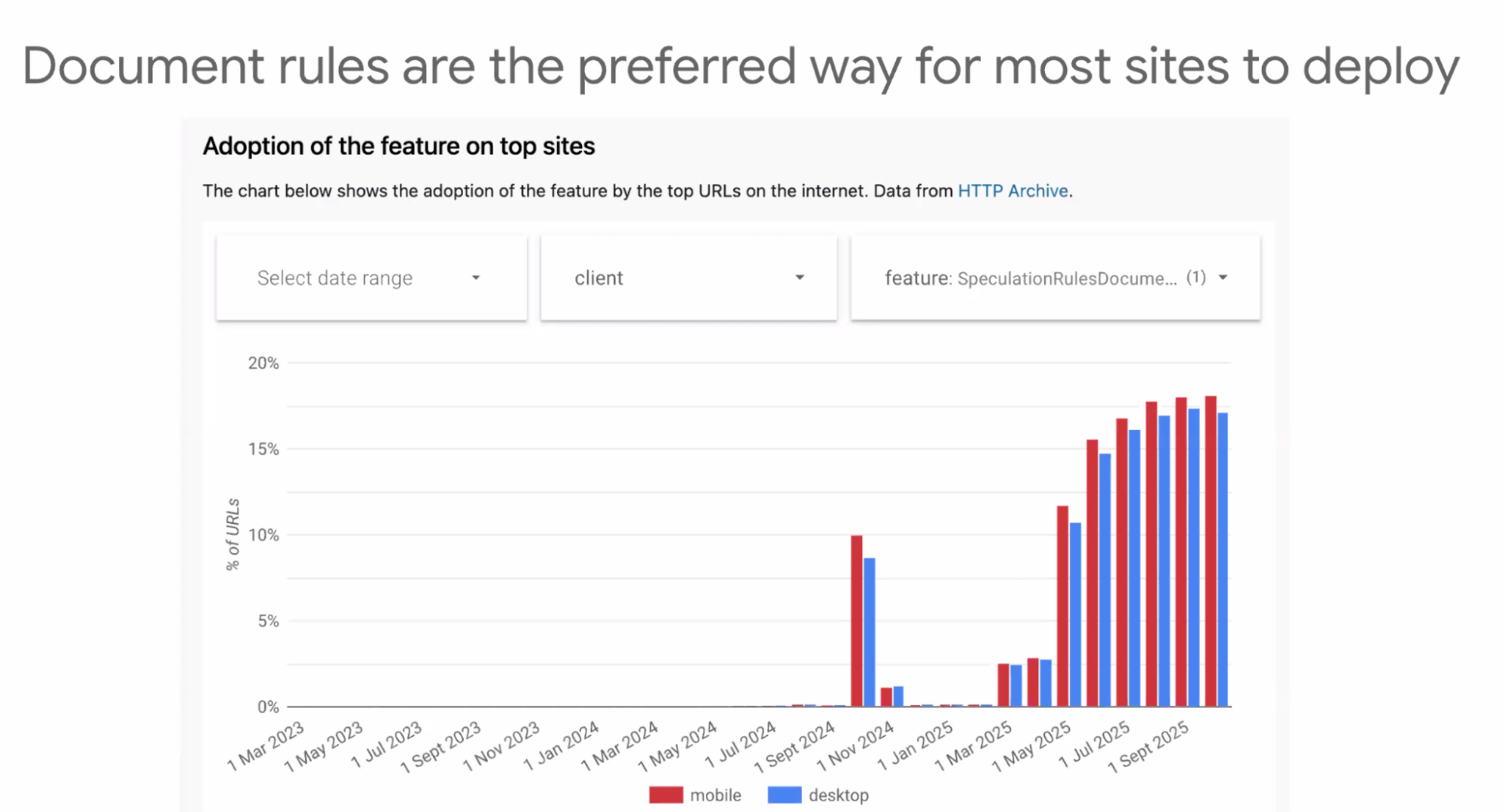
- ... Adoption
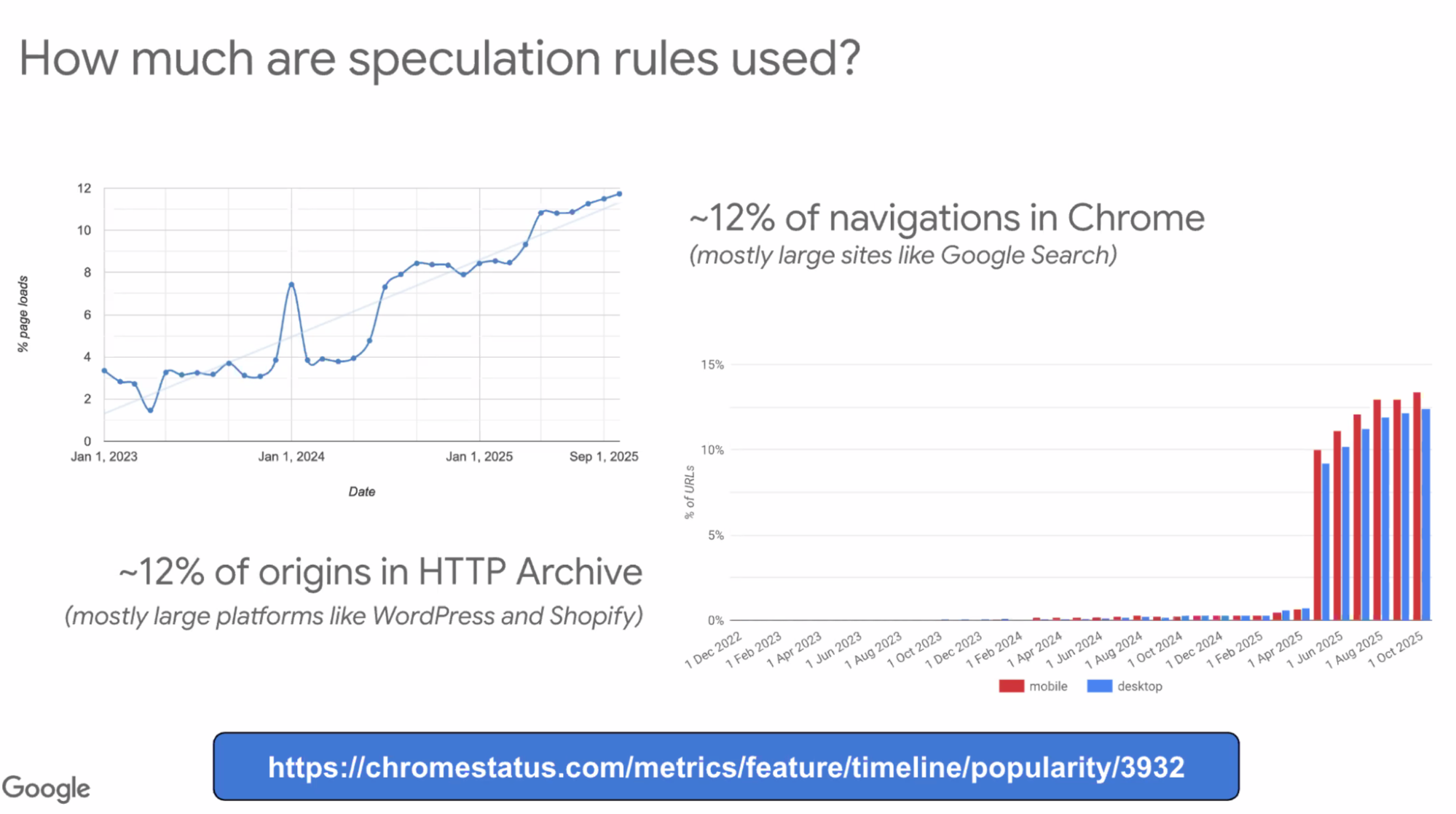
- ... ~12% navigations in Chrome
- ... 12% of origins in HTTP Archive, mostly large platforms (WordPress and Shopify)
- ... Who's using this?

- ... Top section is rolled out by default
- ... Middle section are offering hover activity
- ... Bottom row is where they've rolled out full prerender
- ... Impact graphs
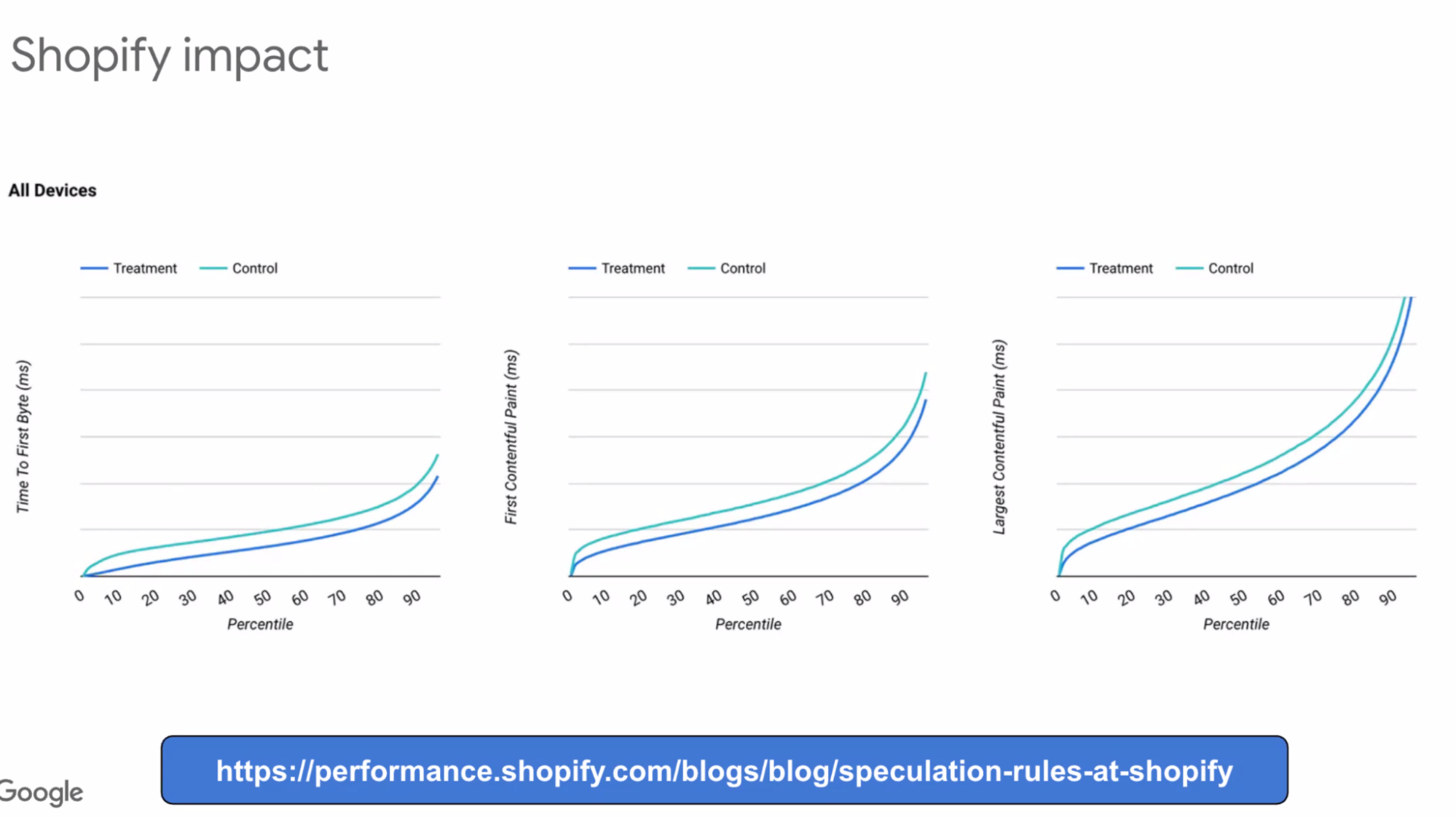
- ... Mousedown activated
- ... Improvements across the board across percentiles
- ... Etsy is on hover
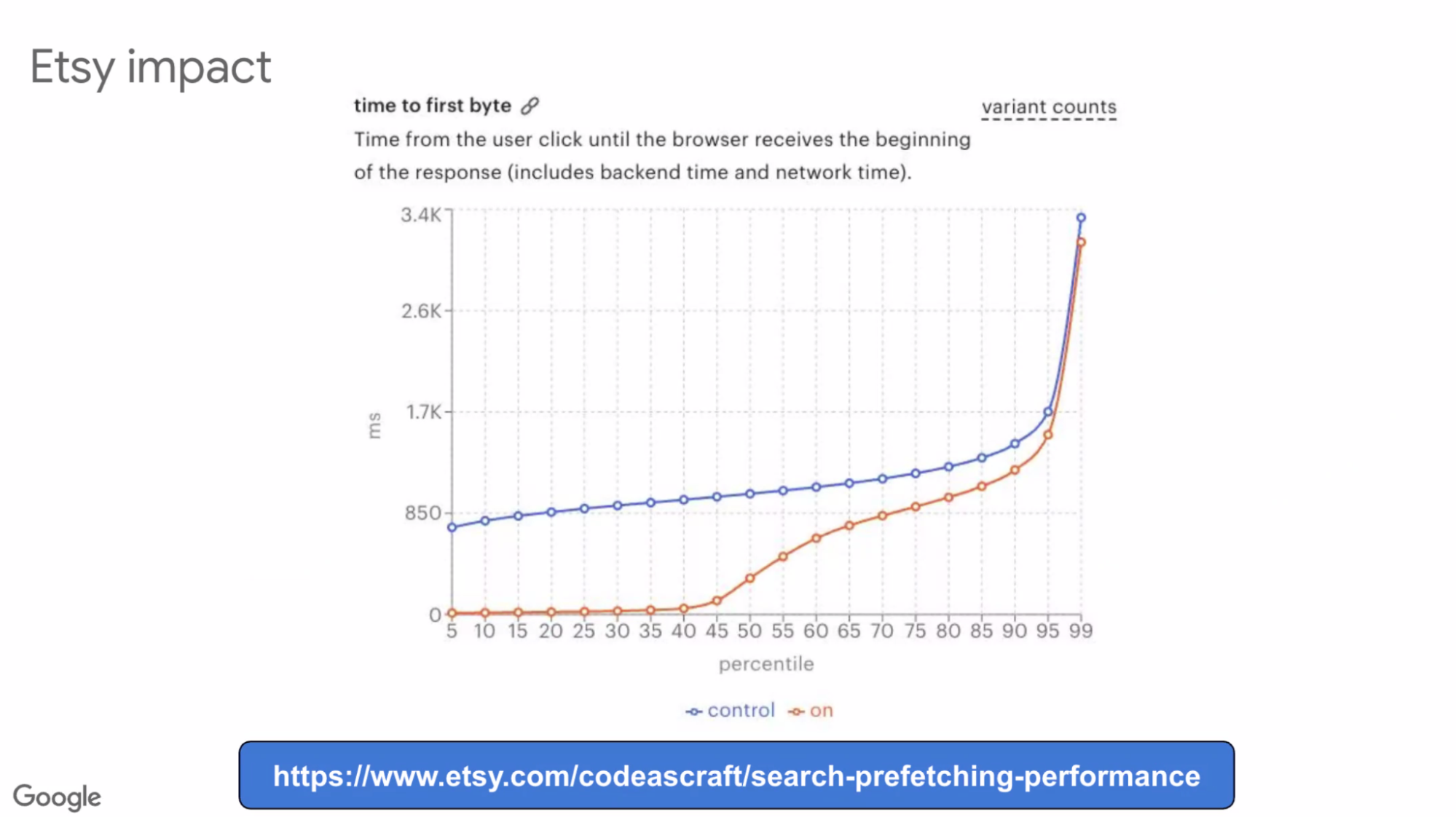
- ... Often has 800ms TTFB, up to 45th percentile that's down to ~0ms
- ... Chromium-only at the moment
- ... Basis recently landed in WebKit
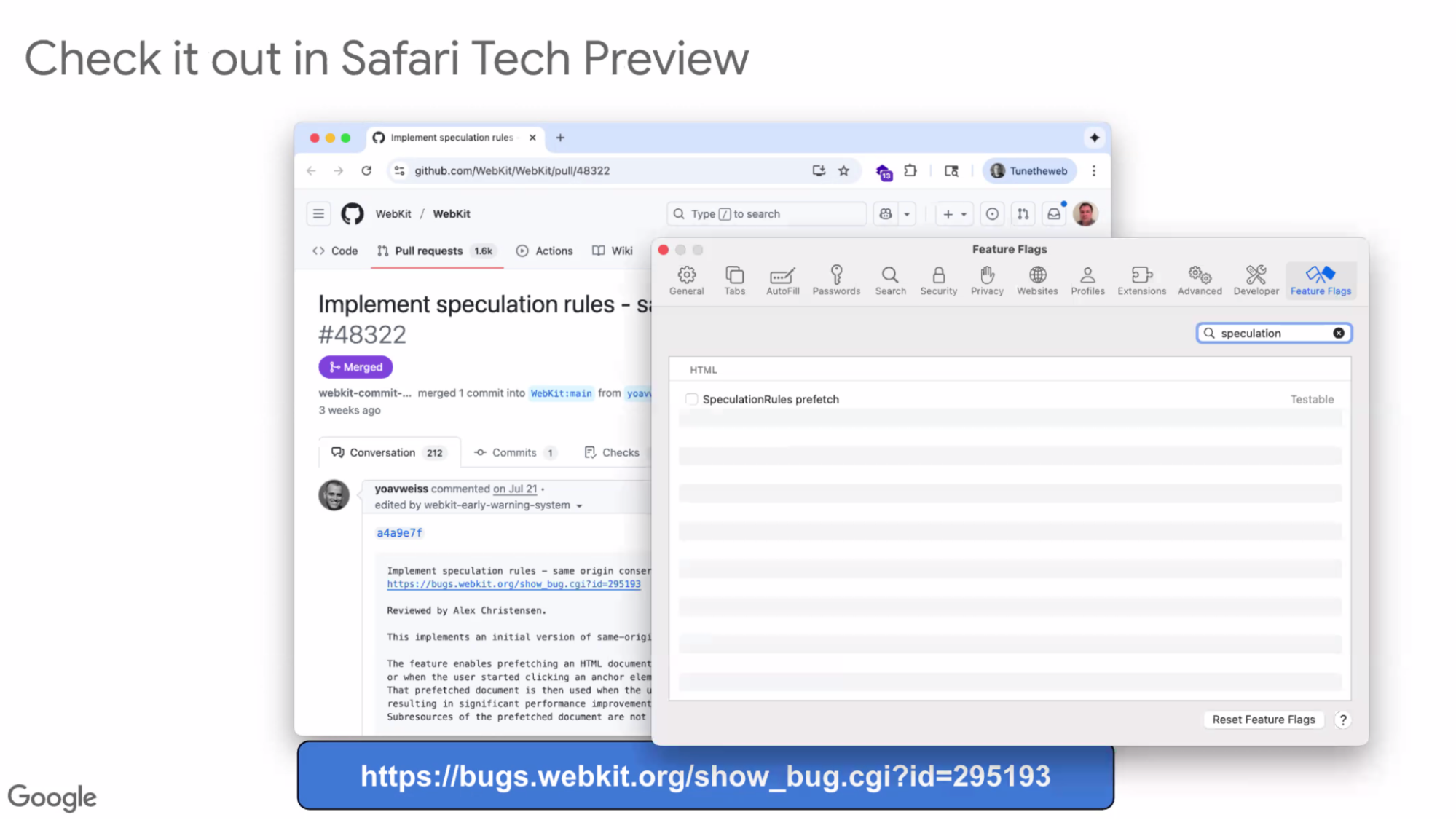
- ... First of many PRs
- ... Mozilla also working on it this and next quarter
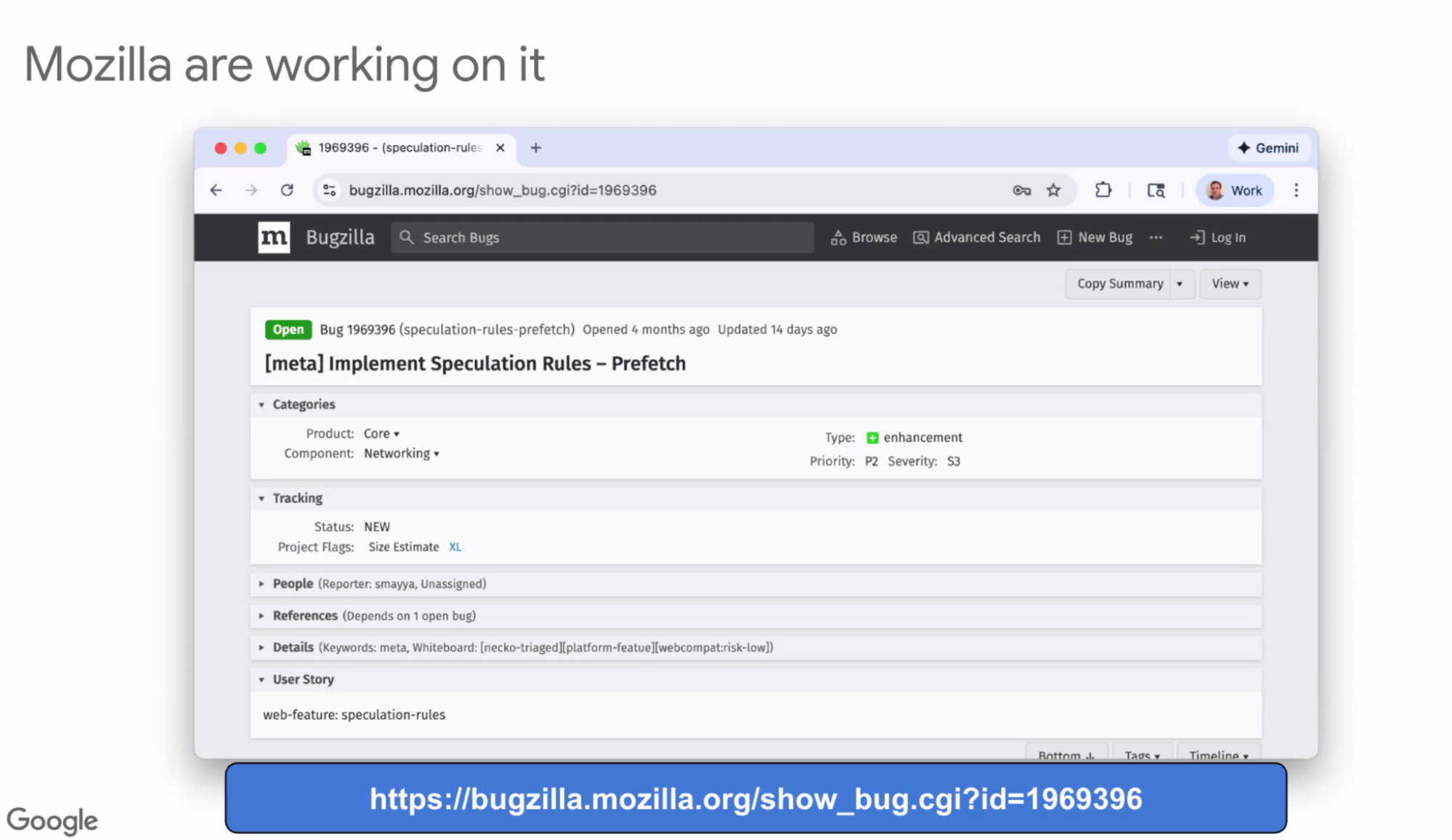
- ... Ideally we'd have, if you're using prerender, and browsers don't support, would fall back to prefetch
- ... Ideally we'd get into Interop 2026

- ... Questions:
- ...

- ...
- nhiroki: Regarding same site X-O prerender, it's cross-site-cross-origin that is already supported
- Nic: Is there a way for a script to annotate that it’s fine with prerender for prerender-until-script?
- Barry: not at the moment. It adds some complexity but we talked about it, but not a lot of people were interested
- Nic: For an analytics script, it could be useful to be mark it
- Barry: you typically load those at the bottom of the page
- Nic: Some Akamai scripts insert themselves in the head but are prerender aware
- Barry: If there’s demand, let us know
- NoamH: Multiple ways to add the rules. Does the last one win? Are rules merged?
- Barry: Anything that matches works
- NoamH: Can there be a conflict if one excludes and one doesn’t
- Barry: The exclusion won’t work. Tags would allow you to see which rule worked
- NoamH: Cross-origin iframe prerender is enabled?
- Nhiroki: Still experimental using a feature flag
- Yoav: Would it be possible to somehow measure when these inline events refer to other scripts?
- ... Scenario that scares me is that inline event handler calls a function that should have been defined by a blocking script that is no longer
- Barry: Blocking script stopped, first thing run on activation, inline event handler isn't set up since it's above that
- Yoav: IMG tag that has online event, handler defined in script lower down
- ... A race that isn't lost in
- Kouhei: The onload function is blocking prerendering
- Yoav: When the image is actually loaded, onload will not fire if prerendering is blocked
- Kouhei: No guarantee, bug in the first case
- Yoav: Race isn't lost
- Barry: Cached image the race would be lost
- Michal: Onload events are async, no guarantee
- Yoav: Would it be web-safe to deploy? Can we measure their existence in the wild?
- Kouhei: Can't measure these ones
- Yoav: Can we measure that race condition? Inline event where it refers to something defined in an external script, you can measure this in terms of preload
- hiroshige: Measurement is hard, especially because it requires a deep analysis, catching of the error event may be helpful. Hard to measure. Those types of guarantee, trigger may effect other web platform changes. Slightly changing the timing of the event handler may have a hard trigger, internal changes may very slightly change task by one ahead, could trigger a bug report.
- ... This might be a risk. That kind of dependency may already be broken. Not just render and script changes, but other implementations and in the future.
- Yoav: With my deploying speculation rules as a platform as a hat on, if a website is written badly and it breaks that's their problem, if this is a flag I enable and it breaks, it becomes my problem. How big of a risk for race conditions?
- Michal: Async and defer script also gets postponed a lot longer than it would have been
- Barry: Continue prerendering then run later
- Michal: If it's a race, a race that was always won, and now defer could break it
- Barry: JS depending on JS
- Kouhei: Why don't we measure the amount of JavaScript errors, we can monitor while deploying
- ... Agree it's a possible scenario, change it's happening sounds low risk
- Yoav: You'll need platforms to participate in experiment to see those errors
- Michal: Platforms that opt into prerender_until_script
- Barry: Pausing inline event handlers is too difficult
- ... For us to update the code
- Michal: Can't measure errors until first inline script
- Yoav: Deploy prerender_until_script and see if there's a bump in the error rate
- Barry: Something that sites or platforms that turn on
- Yoav: I can see platforms experimenting before we determine whether it's safe or not
- Justin: Delivered as a script tag but it's actually JSON
- ... wanted to ask around scroll tracking
- Barry: Many signals where we slightly disable it
- Michal: prerender_until_quick, moment I click, now entire script has to run
- ... Moment where site looks interactive but it's not
- ... Do we swap first then run, or do we do any holding
- Barry: I think we swap first then run
- Lingqi: We have proposal to paint first then run the activation event handler
- Michal: In a perfect world, we'd wait some amount of time then get feedback
- Michal: Another question, hover on mobile. Order of events that fire, hover events the moment you touch before pointer down.
- ... Even tho it's in same task, opportunity
- Barry: Before we switched to mobile viewport things, clicking would trigger hover, but not same as multiple seconds you got on desktop
- ... Now in viewport, it's earlier any way
- ... Based on mouse-down
- Michal: It's Chrome's internal event that triggers hover
- ... Situations where a site's hover events are long-running, blocking INP
- ... On mobile it's left in there
- ... I wonder if that would affect our ability
- ... Depends on how it's implemented
- ... touchdown/mousedown hardware event, that will dispatch hover events/pointer over/pointer entered before pointer down
- ... Event dispatch could come later that it could
- Barry: Could be a micro improvement here
- Nhiroki: Experiment in feature flags, try on Chrome canary
- Barry: Origin Trial in January
- Yoav: On Interop, sounds too early for prerender_until_script, open questions that need to be figured out
Speculation Rules, link rel, preconnect
Recording
Agenda
AI Summary:
- The group proposed clearly separating “current-page” vs “next-page” preloading: `link rel=*` for the current page, and speculation rules (prefetch/prerender/preconnect) for anticipated navigations, with an eventual deprecation path for cross-page `link rel=prefetch`.
- A new speculation-rules `preconnect` action is being explored to restore cross-site preconnect in a world with network/state partitioning, while addressing privacy risks (TLS client certificates, partition keys, anonymization/proxy behavior).
- Participants discussed how to signal/observe preconnects (e.g., via headers, tags, or TLS-layer mechanisms like ALPS), noting current layering issues and the need for careful design.
- There was debate on whether cross-origin preconnects need full anonymization like prefetch, and how to balance that with complexity and performance, especially once a credentialed request reuses the connection.
- Developers would likely use speculation-rules preconnect as a more conservative, lightweight alternative or fallback to prefetch (e.g., preconnecting to a checkout domain), with explicit signals for dynamic or stateful resources.
Minutes:
- Hiroshige: working on speculation rules. Want to talk about separating pre*
- … A few APIs to preload things. Either for the current page or for next page navigation
- … Different requirements around privacy
- … Different behavior and need a separate API for these two categories
- … Speculation rules prefetch and prefender work across site boundaries with privacy considerations covered
- … Adding more API in this category - speculation rules for preconnect
- … Want to propose separate API surfaces that make it explicit which category of preloading is needed by users
- … e.g. link rel=prefetch is mixing these two pages
- … Requires users to think about these categories and be explicitly aware of them
- … Separate API shape: link rel for the current page, speculation rules for the next page
- … Eventually would need to deprecate link rel APIs for the next page
- … Risk - requires users to move to the new API shape, but these APIs are already not necessarily working as expected, so suspect that the impact would be low
- … Would also require developers to be aware of these categories (added cost). But it’s better in the long term
- Keita: Proposal to add a preconnect action to speculation rules
- … when we didn’t have network partitioning, it used to work for both subresources and documents
- … With network partitioning we need preconnect in speculation rules to have cross-site preconnect
- … Security considerations: used to work. Cross site tracking needs to be mitigated (e.g. eliminating credentials)
- … For preconnect the main vector is the TLS client certificates. (care less about cookies)
- … There’s also anonymization, preconnects would need to care about this
- … State partitioning - we’d need a different network partitioning key for these connections
- … In Chromium it’s 2.5 keys
- … In preconnect, we’d need to have the top-frame part of the key be the destination site
- … This may expose user browsing habits but that’s a broader concern
- … Wanted to ask if this is something useful in general and if there’s anything missing
- Ben Kelly: For anonymization, you’re going through a proxy. Did you measure the overhead of what happens if the entire resource then needs to be proxied?
- Keita: No numbers off the top of my head, but we’ll look into that
- NoamH: What happens with speculation rule tags?
- Keita: In the handshake there won’t be any way the server would know it’s a preconnect. No way to mark it right now
- Yoav: If that preconnect is used on request, could you add a HTTP header / tag?
- Ben: Reminds me we have a terrible layering inversion where some things are sent through TLS layer. Happens on preconnect. Might need to address how you'll handle that. Maybe in TLS layer. Could be a Client Hint.
- ... Opportunity to use ALPS
- ... When that flag is set, we don't do critical client hints negotiation, and things like that
- ... Needs to be addressed in your design
- Toyoshim: do we really need the anonymization of the IP address? The site can already fetch the cross-site. Preconnect for the cross-site is much cheaper than (what)?
- Keita: preconnect needs to be consistent with the existing pre*, so reasonable to have anonymization support
- Toyoshim: but using a proxy to connect to the cross-origin site makes sense, but using it for preconnect seems not reasonable?
- Ben: When you anonymize cross origin prefetch you're also not sending cookies, but with preconnect you could do anonymization and then send a credential request. That could be complex
- Eric: ALPS is complex. Separating between same-origin and cross-origin makes sense. In terms of separating the anonymization areas - preconnecting may not require it, but at the point you want to use the connection you’re in the same spot where you need it to be partitioned.
- Michal: what’s the use case for preconnect compared to prefetch? Could this be a graceful fallback to prefetch? Or do we want the developers to explicitly limit to preconnect?
- Keita: Could go either way. Depends. Preconnect is more lightweight
- Ben: Would benefit from some use cases. E.g. one domain for shopping and want to preconnect for a stateful checkout
- Bas: Could be a more conservative form of prefetch
- Michal: So dynamic resource that could change - a developer-explicit signal
Privacy-preserving prefetch and cross-origin prefetch
Recording
Agenda
AI Summary:
- Cross-site speculative prefetch should not reveal user-identifying information (IP, cookies, service workers, headers); existing specs mention “anonymized-client-ip” but don’t yet define a full anonymization model.
- Google’s Privacy-preserving Prefetch Proxy (P4) is an example of such anonymization in practice; discussion focused on defining a common threat model and deciding what else (beyond IP) must be stripped or partitioned.
- The group debated “site-provided” (origin-owned) proxies vs browser-provided multi-hop proxies: origin proxies are easier to trust and pay their own costs, while browser-wide proxies raise competition, cost, and default-on privacy concerns (hence ideas like 2‑hop designs and token-based rate limiting).
- Concerns were raised about abuse, DoS, and tracking; most agreed these risks largely exist already, but mechanisms like `.well-known/traffic-advice` and PAT/token-based rate limiting could help responsible proxies limit traffic and amplification.
- There was also discussion of user trust and responsibility: with same-origin proxies, any response tampering is effectively the origin’s responsibility (protected by HTTPS tunnels), but UI/UX and attribution must avoid misleading users about where content really comes from.
Minutes:
- Robert: Cross origin and site prefetch - crossing site security boundary and a speculative load is not a direct load from the user, so should not reveal information about the user.

- … want to hide where the request is coming from, the IP address, and any cookies/service-workers that can identify a specific user
- … the spec states a need for anonymization but doesn’t talk about how it’s used
- … The HTML spec has “anonimzed-client-IP” but it doesn’t say a lot. Doesn’t talk about a lot of other things that should be anonymized
- … I’m maintaining Google’s Privacy-preserving Prefetch proxy (P4)
- … Other sites can also use it for users that have “extended preload” enabled
- … Want to build a common threat model

- … also want to strip identifying headers
- … Direct prefetch leaks all the above things
- …

- …

- … There’s a WICG issue for site provided proxy
- … Should the anonymized client IP also indicate that other identifying characteristics won’t be sent?
- … Privacy preserving preconnect could be a way to enable credentialed requests later on
- …

- Gouhui: for site-provided proxy, how can we trust that proxy?
- Robert: in the Mozilla proposal, having the proxy on the same-origin for the site, that’s easy to trust. An issue when it’s cross-origin.
- Eric: It has to be same-origin
- Robert: has the same information as the referrer
- Bas: That’s also true with a cross origin proxy, right? The site could already leak
- Yoav: You're making it easier, but Bas is saying it's already possible
- Eric: The client doesn’t need to do anything to cause that leak
- Bas: If there was a 3P setting up a malicious proxy, they can already do this
- ... I think the referrer provided proxy is interesting
- ... Unless you allow that, you are in a situation here services created by operators who also operate a browser are fundamentally advantaged, vs. 3Ps
- ... e.g. Google Search vs. someone else
- ... I think that is at conflict with equal and open web
- Yoav: I think there's also incentive and cost alignment if the referrer wants outgoing traffic to be anonymized, it has to pay the bill. Some browsers may not want to pay for all sites on internet.
- Ben: Right now P4 supports Google traffic, beyond there, it's a UA setting. Why is that?
- ... Capacity seems reasonable
- Barry: If you go to Google Search and we prefetch first (blue) link, going to Google Search proxy is fine
- ... If you want to use Google Search proxy, Google doesn't know anything about that. Chrome does.
- ... We don't allow that by default but you can opt in.
- ... Opt in rates are low
- Ben: Makes sense, but what I'm taking away there. Thread model of P4 proxy, doesn't have any double-blind scenario, they have a trusted environment
- Barry: We could have a browser proxy, any site to protect anything. A level removed here.
- ... Google.com has a proxy, only one to use it.
- ... Ideally allow bing.com to use their own proxy.
- ... Should browser have their own proxy?
- Eric: Making that on by default instead of opt in, is why Private Relay is a 2-hop proxy
- ... In order for it to be by default, 2-hop so Apple doesn't learn
- ... Masked proxy, multi-hop connect.
- Yoav: In same-origin proxy scenario, you don't need 2-hops
- Eric: Origin provided proxy, 1 hop is fine. Browser provided, 2 hops is needed.
- Barry: Is there any other interest in other sites providing their own proxy, e.g. bing.com or Shopify
- Ben: In scenario where origin is providing own proxy, does browser know if it's "good"
- ... Spamming end destination. All of those problems could manifest.
- Bas: For DOS'ing, I don't need a proxy for this
- Ben: Which of those considerations are those things this group needs to care about in order to enable this?
- Bas: Not malice but incompetence
- ... For malice all those things you can do already
- Yoav: If building, you could DOS all the sites you're linking to
- Ben: Could I put a tracking parameter?
- Yoav: Just do it on the website
- Barry: Once at proxy, no real way to understand what happens after that
- Eric: We use PAT for private relay stuff, you could do same thing here
- ... I'd need to fetch a token from proxy, provides natural rate limiting
- ... How much is this proxy allowing to amplify traffic
- Bas: If I'm colluding, could I do that anyway?
- Eric: Taking infinite tokens, I'm causing proxy to do that
- Yoav: DNS concern is around bots and a single IP creating a lot of traffic
- Eric: Bad actors can do that today
- Robert: Regarding bad actors, I think it's good to have .well-known/traffic-advice file. Standardize?
- Barry: Dependent on proxy being implemented correctly, and listening
- Robert: Good proxies could listen to that file if in spec
- Ben: When is that read? Is there some delay?
- Robert: Proxy is reading the traffic-advice files and caching with HTTP semantics
- Yoav: So destination origin controls how often it can update effectively
- Barry: My experience it's not used much
- Bas: Not used that much because cross-origin prefetch isn't used outside Google Search
- ... if other situations where speculation rules were used liberally
- Barry: I could see other sites using it
- Bas: Competition problem, where a smaller browser couldn't fit the bill for that
- Michal: Focus was on referring origin, and having proxy not DOS
- ... As a user I trust UA on the site the result wasn't tampered with, if a referring origin can opt into a proxy, is it delegating trust
- Barry: HTTPS
- Robert: Proxy opens a H2 connect tunnel
- Barry: HTTPS confidence
- Bas: Does it work for non-HTTPS?
- Barry: No
- Yoav: In terms of trust, even if we didn't have that, same-origin proxy it's still same origin
- ... If proxy would modify the response, the origin's responsibility because it's same origin
- Bas: But it could appear to user it's coming from 3P origin
- Yoav: You’re right, I’m wrong
- (voice-over: the first time)
- Robert: Giving a breakout on Wed at 8:30am
Scroll Performance
Recording
Agenda
AI Summary:
- The discussion focused on improving web scrolling UX, especially for complex apps like Excel, by defining and measuring “good” scrolling in terms of both smoothness and interactivity.
- Key use cases included: detecting and mitigating checkerboarding (missing content during fast scrolls), accurately detecting when scrolling ends (e.g., a lower-latency `scrollmoveend`/`scrollpause` event), knowing scroll start timing, and reading scroll offset without layout thrash.
- Measuring scroll smoothness and compositor jank (beyond main-thread LoAF metrics) was seen as valuable both for product quality and for performance regressions, with interest in compositor-driven metrics similar to native Android scrolling metrics.
- There was exploration of using or extending PaintWorklet (and possibly more declarative approaches) to render better “checkerboard” placeholders during scroll, though concerns were raised about complexity, limits on data access, and the risk of blocking compositor threads.
- Privacy and fingerprinting concerns were noted around exposing scroll input source (e.g., trackpad vs scrollbar), and participants agreed the proposals should be broken into smaller, independent pieces that can be evaluated and shipped incrementally.
Minutes:
- NoamH: Working on Excel and scrolling is something I’m working on
- … Lots of users don’t pay much attention to it, but it’s really hard to provide a good scroll experience
- … Mainly because there’s no definition of what’s “good” is
- … combination between smoothness and interactivity
- … Trying to get more info to make improvements
- …

- … will outline the usecases with a bunch of API proposal starting points
- … Scroll smoothness - researched in the past
- … Ongoing work done by microsoft
- … Checkerboarding - fast scrolling can result in user not seeing the content, due to compositing not sending the data fast enough
- … optimizing smoothness over content
- … There’s no way to avoid it, but we can measure it

- …Also maybe we can provide a better experience. Currently users are seeing the background color.
- …Could be achieved by extending the PaintWorklet API

- … Second use case, detect when scroll movement ends
- … scrollend event is async and not firing fast enough
- … can introduce scrollmoveend event to be faster
- … usecase - detect source of scroll input type

- … Measuring scroll start time
- … There could be a gap between the user’s scroll interaction and the first event. No way to measure it
- …

- … Determine scroll offset

- … Current methods can introduce layout thrashing, so..

- Benoit: Spec like this would be interesting for Facebook and other websites
- ... It feels like everyone tries to do this incorrectly with requestAnimationFrame
- ... Getting parity with metrics we can get on android, native scrolling metrics
- ... Two components, whether you're checkerboarding plus frames per second
- ... If drawing commands are too complex, getting feedback from that would be useful
- ... Did you consider looking into getting feedback from compositor for FPS?
- Noam: Considering, using rAF loop with all its drawbacks and problems
- ... Look at compositor could be more reliable
- Eric: Most makes sense. Source of scroll input, is there a fingerprinting vector. Accessibility devices. One of small amount of people using a specific style.
- ... Does knowing user grabbed scroll bar vs. swiped, is the use-case clear? Opportunities for fingerprinting higher
- Noam: Does provide more information for trackpad vs. scrollbar, privacy concern?
- Eric: Seems like it could be
- Yoav: Seven different proposals here, if you solved some of it would it give you some value? Or do you need all the things?
- Noam: Separate independent proposals, solved individually, incrementally, maybe some never solved or addressed (privacy issues or technical limitations), any one will solve use-cases for many users
- Michal: I love breaking it down into small chunks.
- ... On measuring smoothness, what could you do with it?
- ... Having a measurement would be useful to motivate other fixes
- ... Real-time measure of smoothness would be hard. Could sites adjust to be more smooth?
- ... In aggregate, invest engineering resources into optimize
- Noam: For why smoothness? Even with limited way of measuring smoothness with rAF loop, users are happier, more satisfied when interaction is smooth. But not satisfied when they see checkerboarding.
- ... We aggressively track many metrics, any time one regresses, we go to that engineer causing that regression
- ... Can potentially roll back that change
- Michal: Sold on value of measuring smoothness. Main-thread jank is somewhat measured by LoAF.
- Noam: While scrolling using LoAF observer to use hint, but it's not enough and sufficient indicator of checkerboarding
- Bas: Not an animation frame when janking up scrolling
- ... scrollmoveend, is that heuristics? Request browsers have a consistent end?
- ... Last scroll may not coincide with stopping of scroll
- Noam: Want to measure smoothness or other aspects, and respond to different things
- ... During scroll we pause fetching resources or other activities
- ... Not just scrolling as an interaction, from first scroll to last that's our movement
- Bas: Reducing latency to know when scroll is stopped
- Michal: Propose scrollpause
- Noam: OK to bikeshed on name
- Bas: Measuring smoothness vs. checkerboarding, compositor jank when scrolling is quite interesting
- ... Know there's interest in motionmark development group, having better ways of knowing when things aren't smooth just measurable from main thread
- ... Goes into any time of compositor driven animation
- .... Proposal somewhere
- Noam: Link in presentation
- Bas: Custom checkerboarding handling, interesting, having a paint worklet, has to work in compositor
- Noam: Already does
- Bas: Can, but doesn't have to
- Noam: Worklet driven by compositor thread, has some time to finish drawing activity then gives back
- Bas: Could be true in some implementations
- ... One of the reasons compositor smooth, is because you can't run javascript in compositor blocking manner
- Noam: Can perform limited set of drawing activities, could be abused with a long loop
- ... Compositor doesn't wait or little for worklet
- Yoav: Could something declarative, background color or image
- Noam: Can be done already, but won't be animated
- ... if we can declaratively say it can be moved, that would help
- ... Challenges for use-case in Excel, varying geometry of the grid, it would be expensive to regenerate images and swap them
- ... If you don't create images correctly, you can't get a smooth experience. Not just a single axis scroll, X and Y.
- Yoav: Even with SVG, can't do the same
- Benoit: Would like to see more motivations of using checkerboarding, difficult to use correctly, more supporting examples would be helpful. How would you even use it well for Excel? For a news feed?
- Bas: PaintWorklet is limited on what data it can access as well.
- Noam: Reduced experience, but we think we can do it. Could maybe be achieved with static image.
- Michal: Regarding checkerboarding, can you rAF loop in worker, to get a sense of compositor framerate. Main thread performance is biggest cause of checkerboarding. I suspect there's some implementation issues e.g. in Chrome
- ... Moment you show something else than checkerboarding, maybe the UA could solve this itself
- ... For checkerboarding I would push on implementations to find these situations and see if we can just make them go away before pushing on measurement
- Noam: We investigated, clean isolated repro cases, even without JavaScript
- Bas: Low-end devices with main thread
- Benoit: Having this metric would help with where to invest
- ... That's what we do on Android with native scrolling metrics
- Michal: If you can render in under 16ms, and constantly yielding, and it still checkerboards, what else can you do? Sounds like that's the situation
- Benoit: Don't target 16ms
Soft-Navs updates / InteractionContentfulPaint
Recording
Agenda
AI Summary:
- The group discussed extending LCP/interaction metrics to “soft navigations” (SPA-like same-document navigations) via new PerformanceObserver entry types: `SoftNavigation` and `InteractionContentfulPaint` (ICP), plus a `navigationId` to slice timelines similar to cross-document navigations.
- Chromium’s Origin Trial shows that 20–50% of user journeys involve soft navigations that current LCP doesn’t measure, motivating heuristics that tie trusted user interactions, history (push/pop) changes, and DOM/paint updates into coherent soft-nav sessions.
- Under the hood, Chromium uses an “interaction context” (linked to Async Context and Container Timing work) to track which DOM regions and paints result from a given interaction, then reports ICPs and associated paints (including potential future metrics like total painted area, “visually complete,” and Speed-Index–like signals).
- There was extensive debate over heuristic vs explicit signaling: browsers need heuristics for defaults and CrUX-style measurements, but many participants also want explicit APIs (Navigation API hooks, container timing hints, “last paint done” signals) to reduce ambiguity and improve interoperability.
- RUM providers and developers raised ergonomics and performance concerns (large event streams, complex stitching in JS), leading to suggestions to: expose more raw but well-labeled data (e.g., both hardware and heuristic start times), improve PerformanceTimeline ergonomics, and possibly keep some higher-level “soft LCP/ICP” heuristics in JS libraries/specs outside core browser infra.
Minutes:
- Michal: <Demo of LCP candidates>
- … With interop, LCP is making it to all browsers
- … The page starts loading blank, and remembers what was painted and then not report on it again
- … Expose this data to performance timeline
- … As soon as we interact with the page, the page stops getting new LCP elements
- … interaction measurement is from the interaction to the next paint
- … When navigating as a result of interaction (SPA) LCP doesn’t work
- … To the user, it’s the same thing as a navigation
- … The page doesn’t start blanc so you can’t just ignore
- … <demo of a soft navigation paint tracking>
- … When an interaction happens and it updates the page and the URL, there’s a soft navigation
- … INP was made with thought on extending it later

- … It’s been a performance timeline feature request since forever
- … Range of intuitions of whether JavaScript is good, or causes issues
- ... All of those reasons are obvious and hopefully exciting
- ... Another motivation on the horizon
- ... The way we build sites is evolving to blur more and more the lines
- ... In terms of deploying sites, blurred from a technology perspective. From server-rendered MPA to client-rendered SPA

- ... Sampling of one talk of benefits of MPA vs SPA
- ... Frameworks like Astro are a server-rendering framework, but with a flip of the switch, it can do client rendering
- ... Dynamically update in the page. Developer develops MPA, but framework supports same-document navigations.
- ... Same with Turbo, HTMX
- ... Sites that used to be developed with client-rendered JavaScript, are now doing some server rendering
- ... Technology choice as a developer, you can pick and choose what navigation is the best
- ... Navigation is one of the biggest factors that should go into that decision, and there's no way right now to adequately measure
- … Also Speculation Rules that we talked about don't really work for soft navigations..
- ... Declarative partial updates session, possible to give power to all websites to update
- ... In Chromium we did an analysis to detect how much traffic out there goes unmeasured
- ... 15-30% estimate that we're not measuring
- ... Now that we've deployed some Soft Navigations code, we think it's at least 20-50% extra traffic out there
- ... Chromium is Origin Trial, closer to end of OT
- ... Two new PerformanceObserver entry types
- ... Somewhat as easy as observing for new types
- ... How to model events. Start from hardware timestamp. New entry type for a soft-navigation.
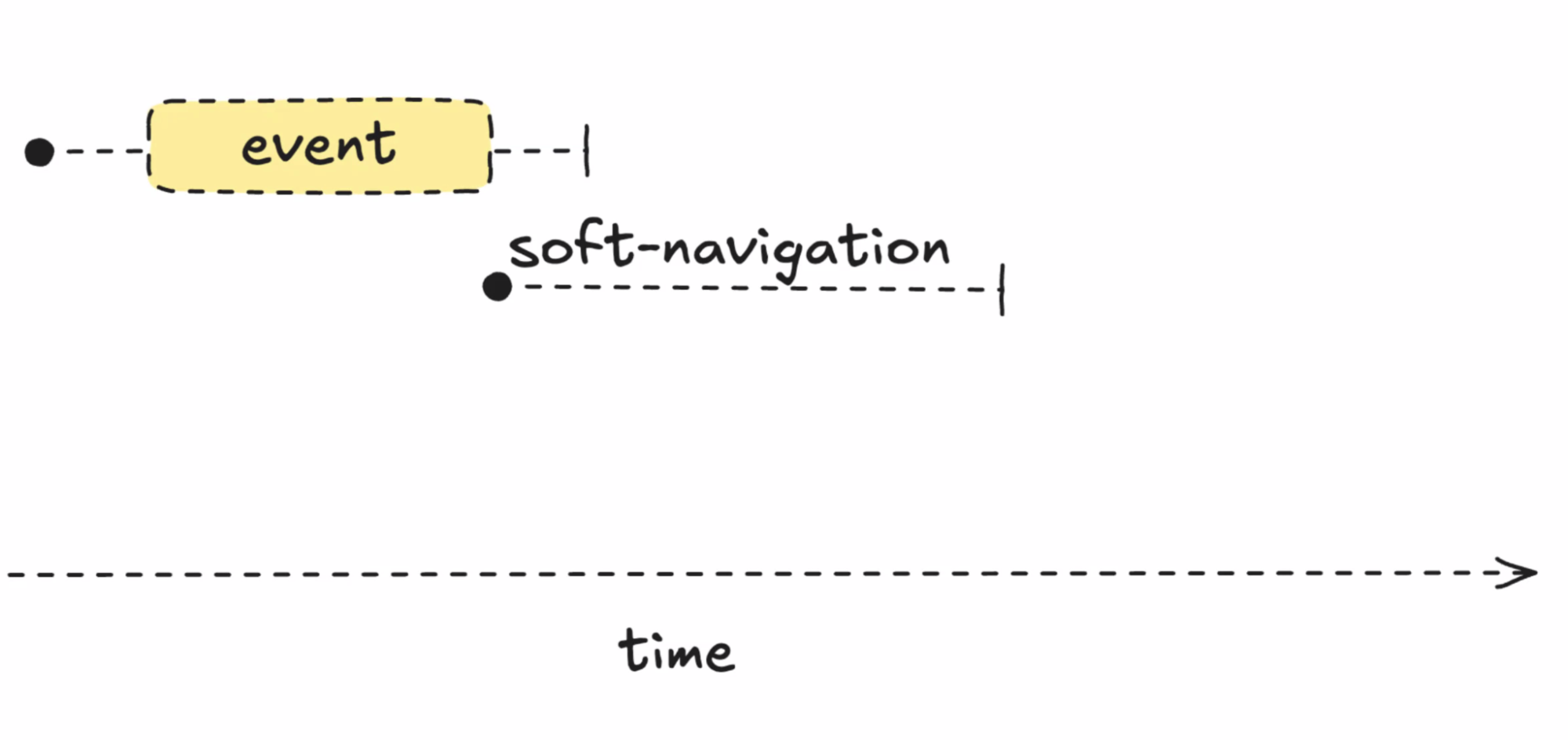
- ... Eventually you meet all criteria of a soft navigation, we report this in the future about the past
- ... Tell you in the future, in the past, a soft navigation started at X timestamp
- ... If you have PaintTiming mixin enabled, you get paint and presentation time
- ... First Contentful Paint of that soft navigation
- ... Today in Chromium you can join the Event Timing with soft navigation, but the times align

- … Eventually you get a stream of new entries, all same metadata as LCP
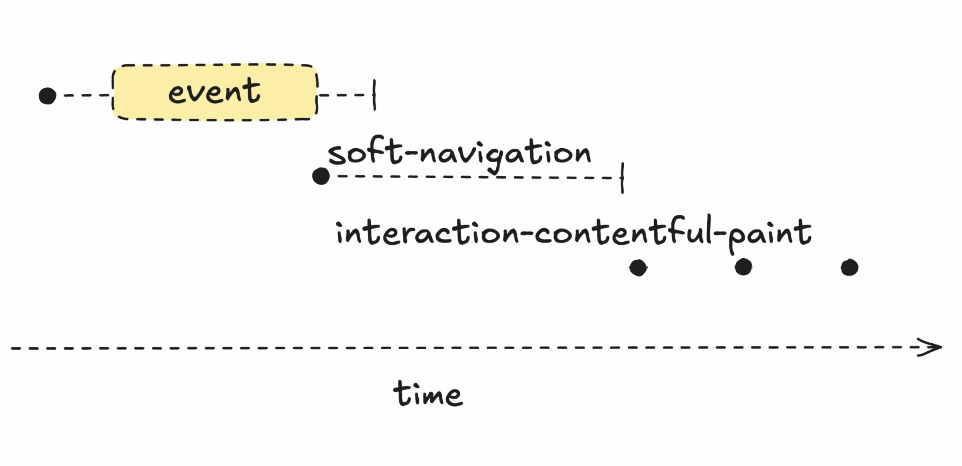
- ... All have a timestamp, but it's just some time value
- ... Based on original document timeOrigin
- ... Interaction at 30s in, I'm going to have an INP at 31s. You shouldn't measure relative to timeOrigin, you measure to soft navigation (an alternative timeOrigin)
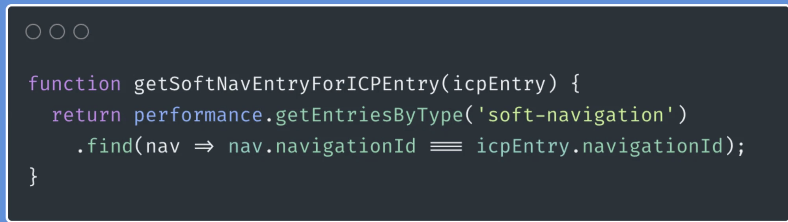
- ... Lookup SoftNav and compare to ICP entry
- ... Reason the timeOrigin is placed at the end of the event, is it's similar that way to cross-document navigations.
- ... Regular navigation on today's web, clicking a blue link and page is janky and slow, the new page won't even process until the page resolves that event
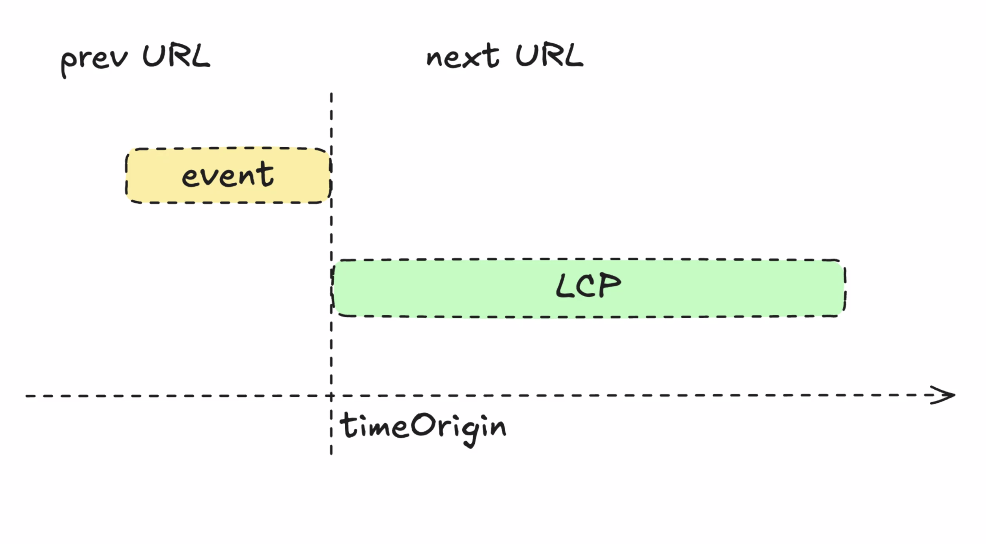
- ... Eventually the event is done running, a chance to run before unload event listeners
- ... That's the timeOrigin for the incoming page
- ... The time of the event goes to that URL
- ... The next URL gets the LCP
- ... For Prerending that's similar, but you need to compare against activationStart value
- ...
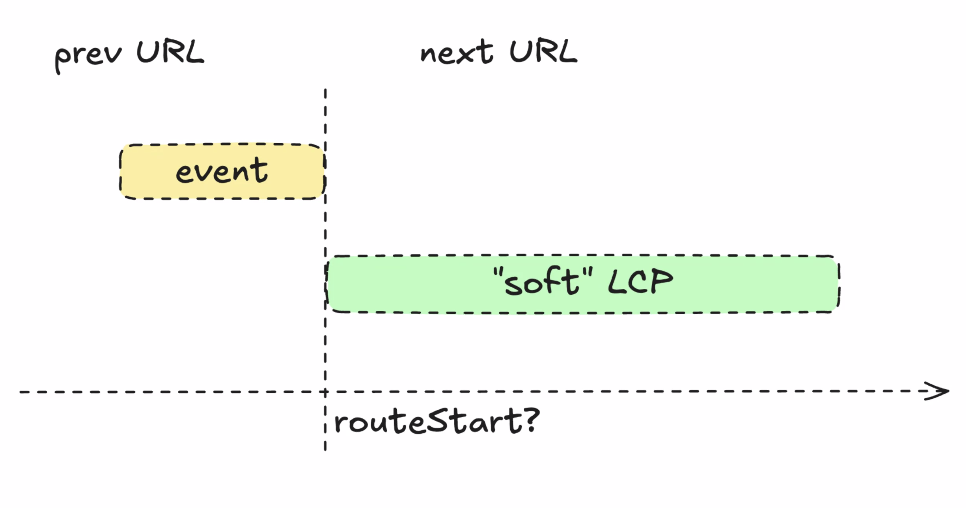
- … Also important for attribution purposes
- ... How does this work under the covers?
- ... Starts with monitoring interactions
- ... Monitor a few event types, to constrain any risks with the implementation
- ... When you have an interaction happen, you now have an interaction context, wrapping the event listeners that fire
- ... We can build a body of evidence over time when it changes
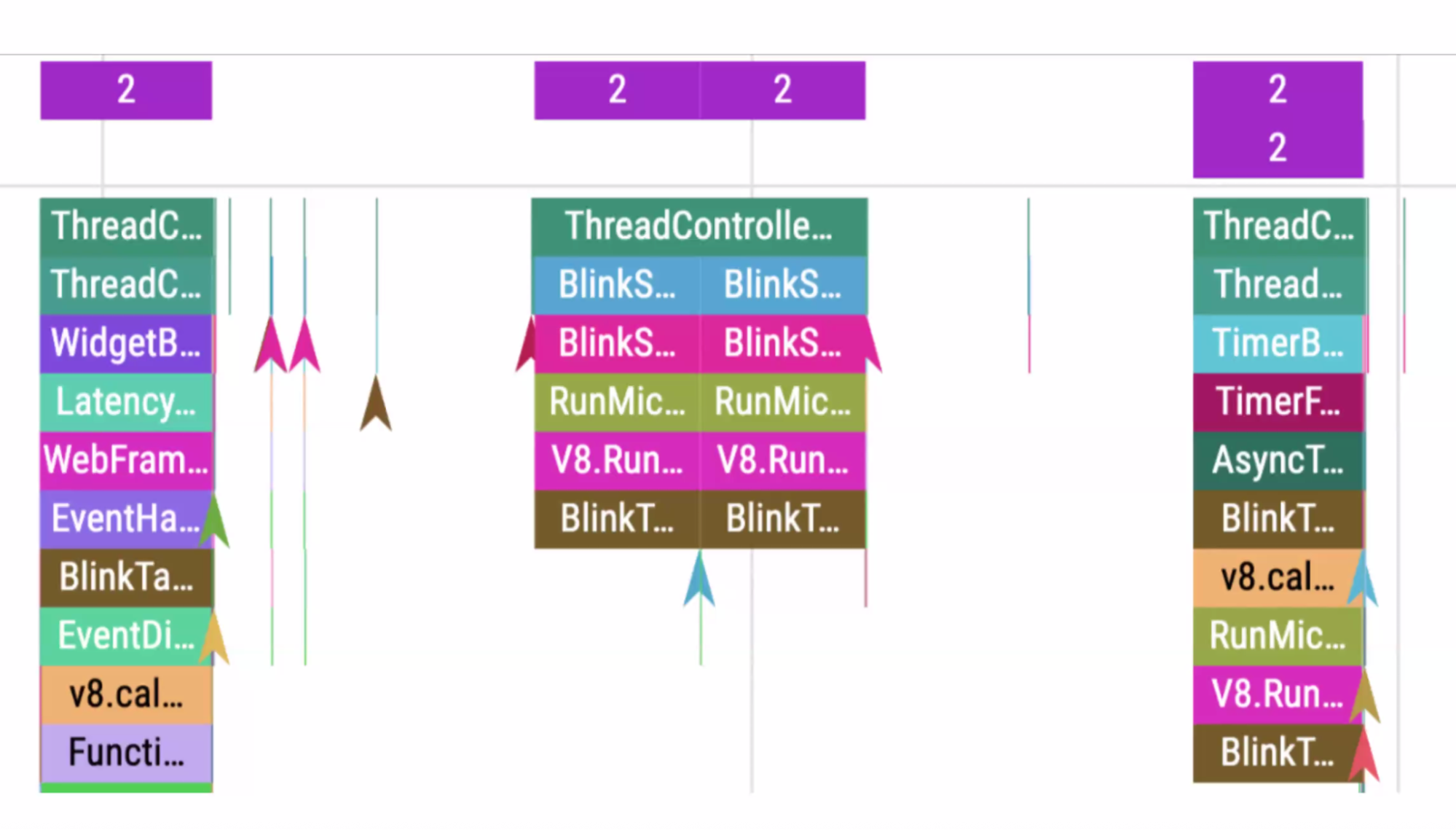
- ... Example interaction where an interaction happened, a network event fired, then a deferred task to resolve it. Task ID is tracked throughout.
- ... Async Context is related
- ... We had an interaction, created a context, we then observe modifications to the document itself
- ... Changing images, DOM appending, etc -- we observe those entry points, and we a apply a label to the root nodes to note that this interaction is changing this part
- ... Difficult to mark the parts of the page that were modified
- ... So if it further modifies itself, all of that bubbles up to this interaction
- ... Same problem description as Container Timing project
- ... We have these foundational features, coming to web platform anyway
- ... The only other thing we did is gluing together and adding heuristics
- ... Some of those that Chromium currently has
- ... We want to see trusted user interactions vs. programmatic navigations. e.g. autoplay to next video is not tracked
- ... Heard feedback from Origin Trial, some cases are useful
- ... We also require you push/pop history stack (replaceState is not sufficient, heard there are some valid use-cases)
- ... One of the big heuristics, we only report ICP entries if there is a history navigation
- … But technically, we could report every contentful paint after interaction
- ... WICG repo for this, proposed spec, entry itself doesn't offer much above base PerformanceEntry
- ... InteractionContentfulPaint is similar to LCP
- ... New navigationId property added to PerformanceEntry
- ... We also expose it to LayoutInstability API, EventTiming
- ... Once you're in a new URL, and we've emitted Soft Nav entry, it makes sense to slice/dice this new timeline
- ... This ID is exposed to a range of things

- ... Some of the heuristics we're considering changing
- ... We had limited to some events we're measuring, click, navigation and some keyboard events. But we should consolidate concept of interactions across all specs. EventTiming has a list of events.
- ... We'd have to expand EventTiming for some other events
- ... When I hit back-button in browser UI, I get an event fired on the page itself, so it's useful to report to EventTiming anyway to measure
- ... Trusted user interactions are required right now, but you also need a hook for initial scope to track Async Context. With new Navigation API, you can inform the browser
- ... With pushState sites could do effects then pushState, so it's too late.
- ... Navigation API you would call first.
- ... Some patterns of replaceState could be useful to report

- ... In Chromium we require Soft Navigation before reporting ICP
- ... We could report interactions that don't navigate
- ... Feedback from OT, told us it'd be convenient to report metadata about interaction
- ... Soft Nav or ICP was triggered by an interactionId or event name or something on those events
- ...

- ... Future opportunities
- ... We started calculating total painted area and how it changes over time
- ... We have the ability to do a Speed Index-type thing. Not exposed anywhere
- ... Container Timing may have this concept as well
- ... Knowing Visually Complete, LCP has some heuristics, but it's useful to know when it's all done
- ... Any time a new Paint and after some time it's settled, visually complete
- ... If any scheduling, network stuff, etc, may not be visually complete. Could declare it once all is done.
- ... One use-case is automation or agentic browsers, you need to know when the page is done interacting
- ... Generally speaking for interactions, async is a trend that's happening. As sites are loading, site authors are choosing to not execute JavaScript right away.
- ... Thin shim measuring all interactions, once JS bootstrapped, replay the event.
- Bas: You mentioned the total painted area. Why is it interesting for soft navigations?
- Michal: Part of solving this problem improved the way we’re doing bookkeeping, we needed to do this. So we could now expose this to LCP
- … When you know you only want the largest element, but for all the updated content you need to do extra bookkeeping.
- Toyoshim: Why do we need the start time to be heuristic based rather than exposing an API? This could be unreliable
- Michal: The feedback we got from an OT the heuristics can be hard to understand. The current version tries to minimize the heuristics baked into the timeline. Here you get both data points, so maybe we should report the hardware timestamp as well to the navigation entry. End-to-end attribution is very easy.
- … But there’s an advantage for RUM to do the slicing at the end of the event
- … Useful to know of the time you wasted before you started routing
- Barry: Why do we have heuristics at all? We only emit ICP for soft navigation
- Bas: The definition of a soft nav is heuristics driven. Even if specced, people can fall out of it
- Michal: Heuristic is the trigger that starts the context. I’m proposing to extend it to cover any interaction
- … For the navigation, it has to be pushState rather than replaceState, but we could remove them as well
- … Navigation event makes it easy to meet the criteria
- Bas: Even if ICP is exposed, soft nav will continue to be a heuristic event
- … High level description is easy, but there’s a lot of devil in the details
- Michal: Punt the hard parts to Container Timing and Async Context
- … Remaining heuristics are fairly slim
- Yoav: Theoretically we could go the route of EventTiming and INP
- ... All contentful paints of all interactions are being recorded. As well as extra information regarding pushState, to have to prevent listening to that
- ... Implement userland parts as a heuristic thing
- ... e.g. INP is not an API, it's JavaScript heuristics
- ... People want it to be spec'd
- ... These kind of heuristics could be spec'd as a non-browser spec in RUMCG
- Barry: Great to have scope and potential, and measure what you want. But interoperability concerns.
- Bas: Userland libraries doing heuristics
- Yoav: web-vitals.js reports navigations based on entry, ICP, etc
- ... It is a way to spin the heuristics out of infra
- Barry: Every event creates navigationId rather than soft one
- Yoav: But we'd lose navigationId part
- Bas: Async Context could allow you to track it
- Yoav: Stitch Async and Interaction Context
- Michal: Between moment event happens and navigation commits, you're in both previous and new route at the same time
- ... We debated a layout shift in middle, is it new layout or old one. Depends on context.
- ... For some things like ResourceTiming, the browser could more easily decide based on heuristics.
- ... Do we think it's useful convenience.
- Barry: It's painful
- Michal: Can we improve PerformanceTimline APIs better?
- ... Here's how we think about it from our site vs. how you think about it
- Alex: I like the discussion about moving away from heuristics
- ... Content authors saying Soft Nav, I'd like to reset all LCP and Shifts and stuff
- ... Rather than browser guessing
- Michal: Two ways to do that, Navigate API saying I'm going to begin doing some work
- ... As long as we don't restrict it to user interactions
- ... Other way to do it is just Container Timing, if you're dynamically updating page, you can apply Container Timing hints
- ... Don't need any heuristics
- ... Where useful to have a default
- ... Hard for site authors to know all of the parts, many things comes together
- ... Browser actually sees everything and you get a difference from what happened
- Barry: Existing SPAs, cutting off 99% value on day one
- ... Consistency of it, library "A" I measure these things, library "B" measures differently, looks terrible
- Yoav: Do we really need the website declare anything? I don't think we should move away completely to site says Soft Nav, we need those heuristics and ways for websites to override.
- ... Where do we put these heuristics?
- Michal: Chromium runs a program where we measure for sites, CrUX
- ... If you want to measure your own metrics with PerfTimeline, you'll have the most insights
- ... By default, we need heuristics to do that
- Nic: tracking visually complete is something we’re extremely interested in
- … This could be measuring soft navigation “page load time”
- … We’re trying to do that, but this can be significantly efficient
- Michal: Sometimes things never end. You can more eagerly decide when things have ended
- Nic: Our customers are using that with the less-precise heuristics we’re using.
- Yoav: Async Context do we have an end-time
- Justin: Hard to do, we know when context can't be held anymore
- ... We've had discussion in the past, context could be marked ended
- ... No good way to solve it at the moment
- …https://github.com/tc39/proposal-async-context/issues/52
- Michal: Finalization and garbage collection, timer-based. Delay relative to the actual end time.
- Nic: That's what we're doing exactly
- Noam: +1 on explicit API to indicate that the last paint happened
- ... Crucial for us, even when we don't use Soft Navs
- ... Open a large element, but it only starts loading real content later
- Barry: We follow LCP heuristics where we only emit larger paints
- Noam: Spinner to tell the user to wait
- Barry: Could want all paints of different sizes
- Michal: Stream of paints, each paint offers some extra value
- ... How container timing proposal roughly works
- ... Subset of page you care about is one virtual container
- Barry: Low-level APIs gives huge potential, but could be doing more processing. web-vitals can be a lot more work just to get Soft LCP.
- ... When measuring 20k interactions across a long-lived soft nav, that's a lot of work.
- Yoav: Processing overhead in JavaScript, raw API
- Michal: I think the PerformanceTimeline could be more ergonomic
- Yoav: Won't solve this now, but it might be interesting to determine how these two different paths may look like
- ... Hear Barry's concerns of this being a huge hassle to work through
- ... Or boomerang.js or other RUM providers
- Barry: Two APIs, ICP vs. Soft LCP
- Michal: Ergonomic questions I'm going to try to cover tomorrow in LCP talk
- ... One anecdote
- ... Google News has same-doc navigations
- ... Through extensive instrumentation they figured out all dynamic content updates
- ... Stitched it through together
- ... They then mark done, but it's when they put new HTML
- ... That's when browser finds new images, etc
- ... Moment they end is totally transparent, then you start to animate in opacity, load images, etc
- ... Measure hundreds of milliseconds with no work on behalf of the developer
- Benoit: We see this all the time, things aren't annotated correctly
- Michal: Facebook works relatively well to measure, you optimize on pointerdown, your click event does the thing to do the rendering, but pointerdown accelerates the interaction
- ... Because we only wrap click event, not pointerdown
Unload deprecation, permission-policy: beforeunload
Recording
Agenda
AI Summary:
- Chromium is deprecating `unload` (which blocks BFCache and is unreliable, especially on mobile/Safari) and has shipped `fetchLater` plus a `Permission-Policy: unload` rollout that’s already reduced BFCache blockers; very few sites are opting back in.
- `beforeunload` has legitimate uses (e.g., unsaved-form confirmation, informing the server about session/state teardown) but also slows navigations and is often abused for logging and lifecycle work.
- To mitigate third‑party abuse, there is a proposal for `Permission-Policy: beforeunload`, letting top-level pages block subframes from registering `beforeunload`; third‑party data should instead be persisted via visibility/page lifecycle events.
- The group compared `beforeunload` vs `pagehide`: `pagehide` doesn’t block BFCache, carries a `persisted` flag to distinguish BFCache vs real unload, and can run in parallel with navigation, making it better for most server/state signaling—though it’s not guaranteed to fire in all shutdown scenarios.
- There was agreement that: confirmation prompts for unsaved data remain a key reason to keep `beforeunload` (ideally used temporarily), while destructive/cleanup work should move to `pagehide`/visibility events, with a longer‑term goal of tightening defaults (e.g., permission-policy defaulting to `self`).
Minutes:
- Fergal: Worked on BFCache so want to get rid of unload
- … unload deprecation - last thing in the page lifecycle, unreliable on mobile and safari desktop
- … Blocks BFCache in Chromium
- … Failed to get vendor support for permission-policy: unload, so went for a deprecation
- … So we built fetchLater
- … Added permission-policy to Chromium with gradual rollout (per domain) of disabling the permission policy
- … Reduced BFCache blocking by a few percentage points
- … Some sites are disabling it to protect their BFCache
- … Less sites are enabling unload
- … The current plan is to wait for complaints, if any. (none so far)
- … Unusual rollout, as rolling to big sites first
- … ~10% per month
- … beforeunload is similarly problematic. It has legitimate uses (e.g. to save the user’s data)
- … But it slows down navigations, even if you do nothing (~20ms on Android in lab, no measurement in the wild)
- … Can install the handler temporarily, but a lot of people abuse these event and e.g. save logs in all the lifecycle events
- … There’s probably no legitimate use for a 3P to install a beforeunload
- … Proposal to add Permission-Policy: beforeunload to give the top level site the ability to prevent subframes from registering beforeunload
- … 3P data should be saved from visibility changes
- … No explainer yet, I’ll add a link later
- … Are there legitimate uses for beforeunload? Other things we need to provide?
- NoamH: Another usecase, reducing server state management
- … If the app maintains a state, it can use beforeunload to let the server know that it no longer needs to maintain that state
- Fergal: so as you navigate away from the page, the server can drop the state? You can do it from pagehide
- … It fires when you navigate away, so same timing as beforeunload
- Bas: difference between pagehide and beforeunload?
- Fergal: It won’t block BFCache. The event has a persisted flag on it that helps BFCache
- … If you’re putting something into BFCache, the unload handler makes it so that you’d get an unreliable page state on restore
- Bas: So a pagehide that tells you you’re going into BFCache, what do you do?
- Fergal: You can signal to the server that a navigation away happened.
- Bas: But you might come back from BFCache
- Barry: unload can do destructive things
- Yoav: Noam's use-case is server-side destructive
- Barry: pagehide is also not guaranteed
- ... e.g. on mobile can go to another tab
- Noam: We had a bug, where incorrect signal linking to server that it needs to discard state
- ... Increased COGS significantly
- ... If pagehide would've worked?
- Fergal: Could have had some bug, and ignored beforeunload stopping navigation.
- ... Every beforeunload has a pagehide before
- Bas: Destructive things from pagehide you can still do things
- ... For cases going into bfcache, you can choose what to do
- Fergal: pagehide has a little bit more information
- Yoav: What you could do is not going into bfcache, go into state. If going into bfcache, start a server on server-side to clear state.
- Michal: If I close the tab I'm not getting beforeunload?
- Fergal: You should get it
- Barry: If you're explicitly closing it, but if you background first, and browser later closes it, you won't
- Bas: Value of bfcache could be not enough to keep
- Fergal: Still destroy state on server in pagehide, and get back into good state on pageshow
- Takashi:From the viewpoint of navigation performance perspective, a big difference, beforeunload can block navigation, so we can't run navigation in parallel. For pagehide, we can just run in parallel.
- Fergal: For chrome, cross-site navigation, pagehide will run in different process.
- Michal: I thought main use-case was to confirm prompt
- Fergal: You have some unsaved data, it just tells you, stops you navigating away.
- ... You want to be able to stop the user before navigating away
- Michal: Confirmation prompt, has saved me. I don't like that it slows down every navigation.
- ... Pattern to temporarily register makes sense.
- Fergal: If you're going to save data in some nav event, you should do it on vis change
- Michal: Still support beforeunload on pages with forms
- Fergal: Some pages care about nav performance, they embed, 3P or related, those may be misguided to use unload/beforeunload, and they should be able to say "not allowed"
- Barry: Would default ever be?
- Fergal: Would be nice if it was "self" vs. "*". Maybe in a year's time.
RUMCG updates
Recording
Agenda
AI Summary:
- The RUM Community Group (RUMCG) is a year‑old, open W3C CG (no W3C membership required) focused on measurement and reliability, serving as a public coordination channel between RUM vendors and browser teams, and working on topics like TAO, Server-Timing (including a registry and guidance), and feature requests (e.g., `fetchLater`, LCP improvements).
- The group offers regular monthly meetings, public minutes/recordings, and is intended as a venue for follow-up on WebPerf proposals and for RUM providers (large and small) to collectively surface needs and potentially influence browser priorities.
- A major discussion topic was whether high-level metrics like INP (and more broadly CWV) should be standardized and/or browser-implemented vs. left as library-defined heuristics built on low-level primitives like EventTiming and LayoutShift.
- Browser and vendor perspectives differ: some argue for only standardizing primitives and keeping CWV-like metrics in JS/non‑normative guidance, while others want more alignment (to avoid divergent implementations between libraries, CrUX, and RUM tools) and even eventual browser-exposed metrics.
- The tentative conclusion was that RUMCG cannot publish normative specs, so the practical path is to add non‑normative “how to calculate the metric” guidance (e.g., INP definitions) into relevant WebPerf specs, giving RUM providers and browsers a common reference without forcing all UAs to ship the high-level metrics themselves.
Minutes:
- Nic: Lots of intersection between the groups.
- … It was formed after TPAC last year
- … It’s a CG, not a WG. 3 co-chairs and active for roughly a year
- … Wanted to share updates, why it exists, and look for opportunities for collaboration
- … The group meets once a month. Agenda docs, mailing list group for cal invites
- … Discussions happen in the webperf slack
- … One important difference - W3C membership is not required
- … It’s also more focused on measurements
- … Individuals can join without status, companies that can’t/won’t be a Members can as well
- … ~20-40 individuals joining every month
- …

- … It’s a useful communication channel to RUM folks, so had updates from browser teams (Chrome, Firefox)
- … interesting discussion about funding browser dev work - can RUM providers band together and fund browser dev work
- … Not a ton of action came out of it, as it’s complex. But it’s an interesting option
- … Good discussion on header adoption (TAO, Server-Timing)
- … Trying to do our work in public as much as we can
- …
- … Requests on things we want from browser (fetchLater, LCP), hoping to influence priority
- …Also tracking work happening in WebPerf
- … e.g. Resource initiator information, content type
- …

- … Trying to influence things like Server-Timing, so created a Registry that documents common-cases of Server-Timing seen in the wild
- … Also want to create guidance on Server-Timing, to propose well-known Server-Timing header names for common use-cases
- … Same for TAO
- … F2F meetup in Amsterdam before perf.now
- …

- … Could be a good venue for followup questions on use cases and API proposal shape.
- … Inversely the RUMCG could try to motivate the agenda of browser vendors and influence what goes into the platform
- NoamH: Is the CG focused on monitoring or also tries to define performance best practices?
- Nic: more on measurement. Less on best practices
- NoamH: performance only
- Nic: Performance and reliability
- Barry: Some RUM people also help their customers improve things. So there’s no clear cut on “measurement only” and they are interested in improvement
- Nic: Do we see any other ways of better coordination? I feel like I could’ve discussed it more
- NoamH: Recordings and minutes?
- Nic: Everything is linked from the RUM
- Barry: Google used to have closed-doors meetings with RUM providers. This is more public and helps smaller RUM providers
- NoamH: Is there a process for following up with the vendors?
- Nic: The issue list is more for the group itself to keep tabs on what it needs to do
- … Communicating to the group - anyone could hop over and discuss things with the CG
- Yoav: INP spec
- Michal: The hard parts are in event timing. INP as a metric is only special because of CWV
- Barry: different opinion. We’ve made it a “standard”. Different libraries should implement it in similar ways. Also CrUX needs to measure it
- … The doc is not a spec. We have a reference implementation
- … Fair ask - we want people to measure this the same way
- … Lots of complexity around the attribution object, etc
- … I think it was answered, but the ask makes sense
- Yoav: what would be the venue? CG, WG, IG?
- Bas: Need to define what the terms mean, but also do we need normative standards to define what’s outside the UA? Or should we move the algorithm definition into the UA?
- Barry: Low level APIs are great, but we need the high level API that just gives you INP
- … Ideally webvitals.js should not exist and the browsers should just emit these value
- Nic: Things that we are doing commonly. CLS vs LayoutShift is the same thing.
- Barry: Also LCP makes opinions in the browser—more so than the other two CWVs.
- Nic: Does that feel like a best-practice guide that the RUMCG can cover? Or based in?
- Barry: UserTiming can be used for anything. Though the downside of that is it’s used differently by different people. RUM CG have discussed how to standardize that
- …But for CWV there are rough edges that anyone that tried to measure CWV outside of web-vitals will have hit.
- Nic: There are differences between web-vitals.js and boomerang. A spec would’ve helped us
- Barry: Extensible web manifesto is about eventually paving the cow-path
- Bas: There’s an argument for doing low-level APIs, but when you standardize a high-level feature that becomes a de-facto standard. But then UAs need to adopt and invest resources in maintaining these defacto-standards.
- Barry: Two questions: do we need a standard? Does it need to be baked in?
- NoamH: What’s the argument for baking it in?
- Bas: that’s what we’re standardizing
- Yoav: not necessarily
- Michal: A non-normative note that defines INP on top of Event-timing would be 2 lines.
- … There will never be a 1:1 match between RUM and CrUX
- … The RUM provider gets e.g. LoAF data which is richer
- Barry: LCP has a lot more weirdness. When to stop, subparts and where do they split
- Michal: visibility changes were solved with EventTiming
- Barry: but not LCP
- Michal: Yeah, because there’s no LCP “end” event
- Bas: Wondering about apple’s opinion on CWV as a defacto standard
- Alex: CWVs has Google’s fingerprints all over it, but that’s become parts of the Interop project and we’re working on pieces of it
- Bas: Appetite about standardizing more parts of it?
- Alex: Skeptical due to distribution schedules, implementation changes being more complex
- … We can add the missing primitives, but standardizing the conglomeration of the primitives that not our level. I implement the primitives, yall can use them
- … If you standardize and measure the same things - great. If not - also great
- Nic: So what would be our recommendation?
- Bas: What’s the outcome we want? Should the CG work on having more normative standards for RUM providers?
- Barry: Can they produce normative standards?
- Nic: I’ll need to look
- Carine: CG can’t produce specs, IG can’t have non-Members join
- Barry: so maybe a non-normative section in the relevant specs
- Nic: Let’s resolve on that!
Day 2
Agenda
AI Summary:
- The Audio Working Group wants to expose the `Performance` interface (notably `performance.now()`, and likely `timeOrigin`) inside `AudioWorklet` to enable high‑precision timing for latency measurement, DSP load benchmarking, and real‑time processing decisions.
- Precision would follow existing Cross-Origin Isolation rules: reduced precision in non‑COI contexts, with the possibility of higher‑precision timers when the owning document is COI; this requires plumbing the COI “bit” into the worklet.
- Using `performance.now()` directly in the worklet avoids timing‑sensitive round‑trips via `postMessage`, although results may still be sent back to the main thread for analysis when feasible.
- For correlating worklet and main-thread timestamps or multi‑origin scenarios, `performance.timeOrigin` should also be exposed and clearly defined for `AudioWorklet` in the spec’s processing model.
- Security and privacy concerns are expected to be manageable but will need review by browser security teams; related discussions around animation smoothness/latency metrics suggest future extensions (e.g., worklet-side UserTiming-like primitives).
Minutes:
- Nic: Exposing the performance interface to the audio worklet
- Michael: From the Audio WG. Lot of desire to have high precision timers in audio worklets
- … The actual change to the spec is just to expose the interface in audio worklet
- … But there were concerns around privacy
- … There was also a request to understand what developers want this for
- … Want to use it monotonic clock, latency metric calculation and benchmarking tests for audio and DSP load
- Yoav: One of the questions that came up when we discussed, was around Cross Origin Isolation (COI), what's the precision required, and how can we get that in a AudioWorklet
- Michael: The precision is already reduced if it's not COI, in terms of requirements that seems fine
- ... If the AudioWorklet is running in COI context could we get a HR timer?
- Yoav: Theoretically yes
- ... Is that something feasible? Is there a use-case?
- Michael: Use-case for higher-precision in COI context
- ... As far as piping the bit, I'm not sure what would be involved in that
- Yoav: Is AudioWorklet owen by the document, that they can get that bit from? Ownership structure?
- Michael: Components of Web Audio that have a similar mechanism, where we provide similar reduced information if not COI
- NoamR: Owned by document
- ... Use-case is about measuring latency, reminds me a bit of measuring animation smoothness
- ... Currently the Performance APIs are not that great in measuring animation smoothness
- Yoav: Performance APIs in general or just performance.now()
- Michael: Just performance.now()
- Yoav: Pre-UserTiming just being able to grab timestamps
- ... Useful first step, last time we discussed this, discussion evolved into things like UserTiming
- ... Right now the model is measure things in Worklet, the postMessage/communicate to the main thread
- Michael: With performance.now(), after measuring, depending on the usecase, some of it could be posted back to the main thread
- ... Some could be used within AudioWorklet to change the signal processing itself
- ... Communicating back to main thread isn't as feasible if they have a timing requirement
- Yoav: First step is exposing performance.now(), if there are use-cases where having other APIs can help you do UserTiming/measure/mark in worklet, then grab them on main thread without having to communicate, that could be a future extension
- Michal: If you just send performance.now(), the worker is in a different origin, so you can't sync timestamps
- ... If you have performance.timeOrigin, you could sync
- Yoav: So we'd also need timeOrigin
- ... Seems reasonable to just expose
- ... Beyond just changing interface, you need to change the processing model
- NoamR: Wherever the integration is, in AudioWorklet, you need to get the bit and pass it along
- ... In the spec PR need to define what timeOrigin is
- Michael: Can we iterate on this?
- ... Are there ongoing security concerns?
- Yoav: No spec security concerns here, but you may need to sync with security teams to get approval
- NoamR: I would suggest to followup on animation smoothness thing, it's a measuring latency thing
- ... In terms of measuring latency in statistical way, how much latency did we have over the last second
- ... You want to measure periods of time where you have higher latency than others
Recording
Agenda
AI Summary:
- Joone presented a proposed “delayed message” performance API for `postMessage`, aimed at measuring message delays (including in workers), attributing delays to scripts similarly to LoAF, and adding metrics like `taskCount`, `scriptTaskCount`, and average script duration.
- There was debate on how actionable some metrics are (e.g., task counts and averages, differences in “task” concepts across engines, and browser variance), and whether to expose raw totals instead so developers can derive their own metrics.
- Participants discussed attribution across main thread and workers, including: how many entries are generated per delayed message, whether sender/receiver both see delays, stitching timelines across threads, and challenges with unsynchronized high‑precision timers and multi-hop (main → worker → worker) paths.
- Privacy/origin and scope concerns were raised: limiting to same-origin, implications for shared main threads across same-site pages, and the fact that some message channels (e.g., cross-origin iframes) can’t monitor each other’s delays.
- Next steps include drafting an incubation spec/design document, further prototyping, and exploring extensions (e.g., trace IDs or developer-provided tags for correlating messages, potentially extending LoAF and using timestamp propagation to pinpoint where delays occur).
Minutes:
- Joone: Presented at WebPerf in June

- … postMessage events can be delayed on web workers
- … Proposing the delayed message API

- …
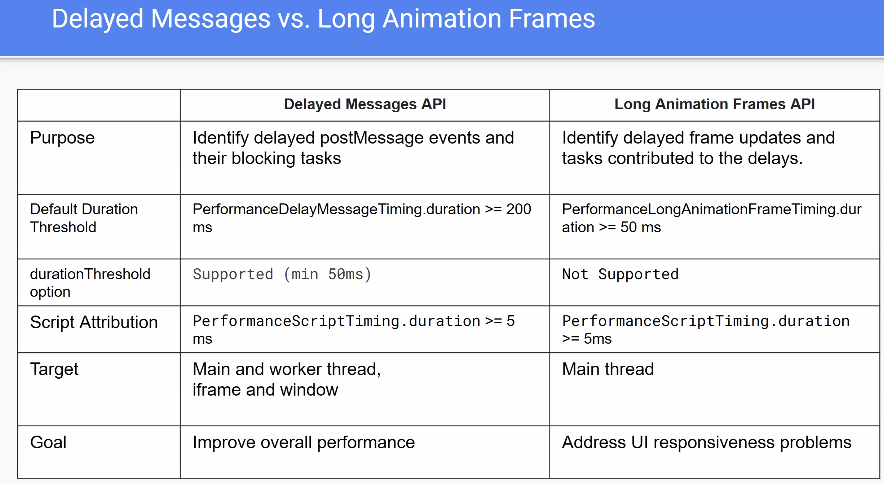
- … difference from LoAF is the support for workers
- … supports multiple types of message events
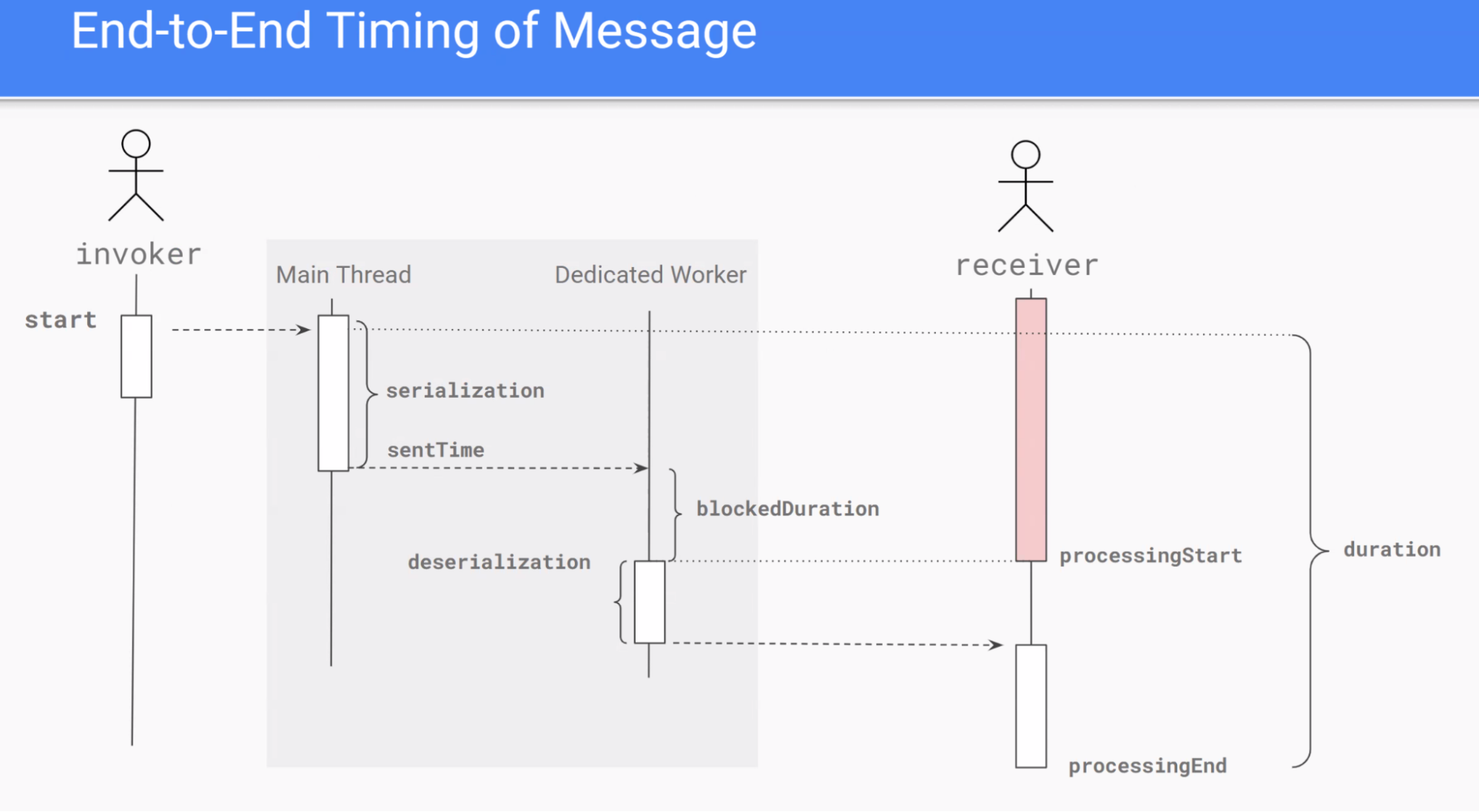
- … measuring how long it took from the receiver perspective
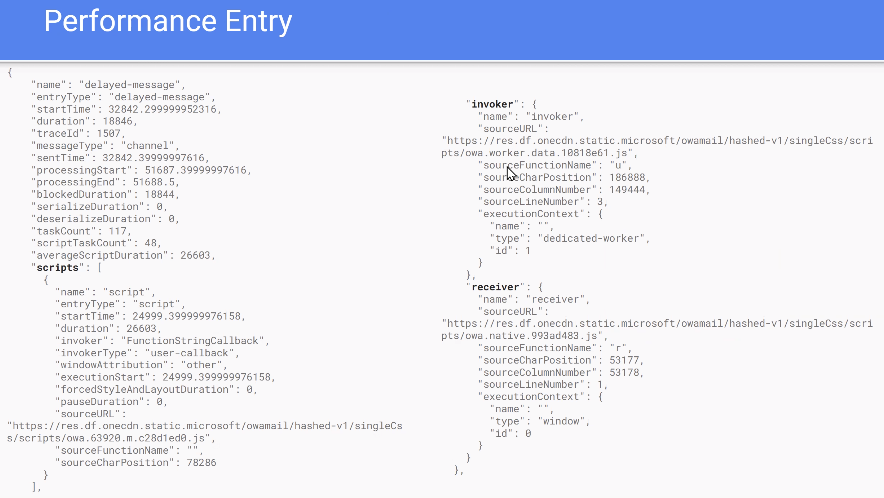
- … Scripts lists all the scripts that contributed to the delay, like LoAF
- … Added taskCount and averageScriptDuration

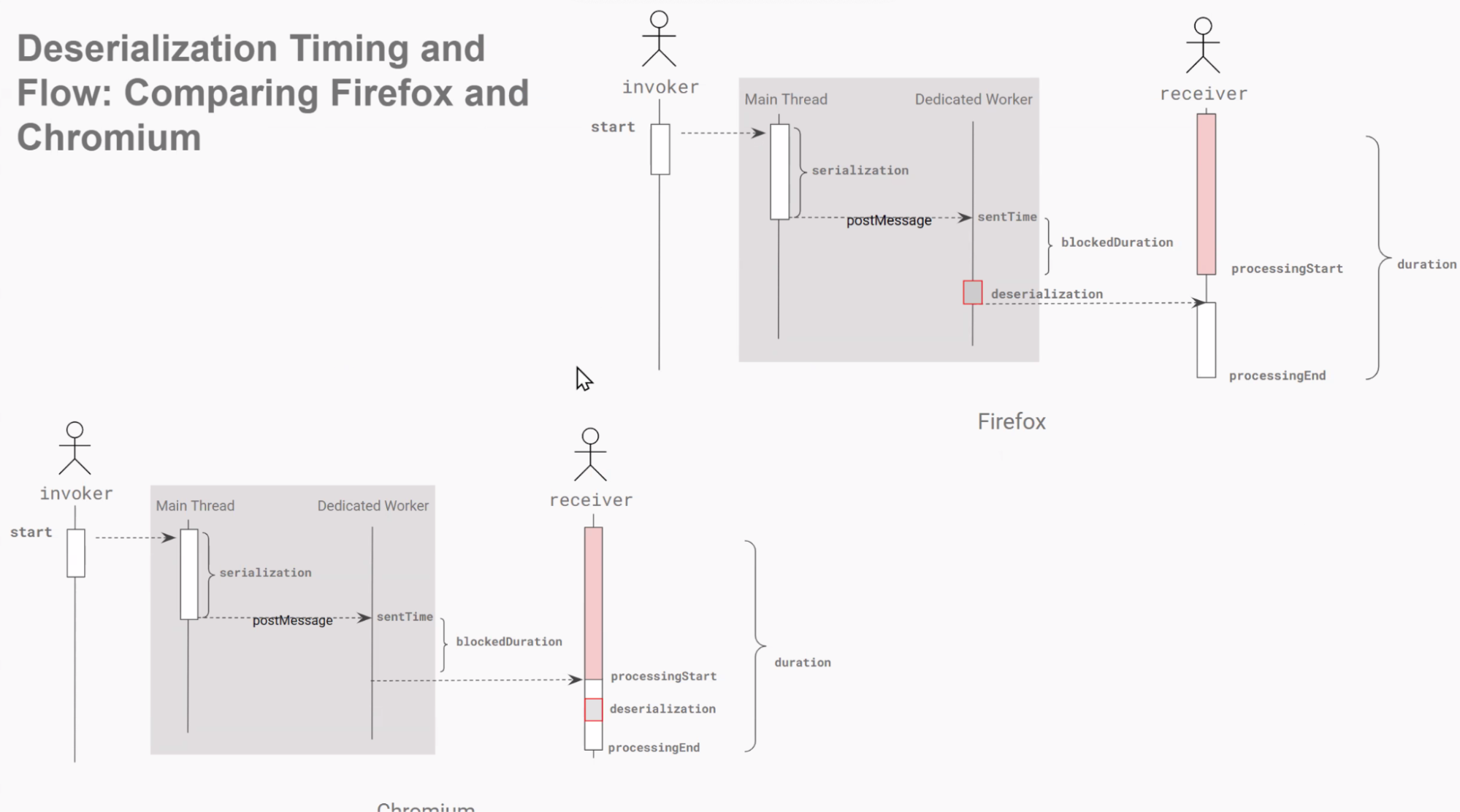
- … there are cases where deserialization slows things down
- …
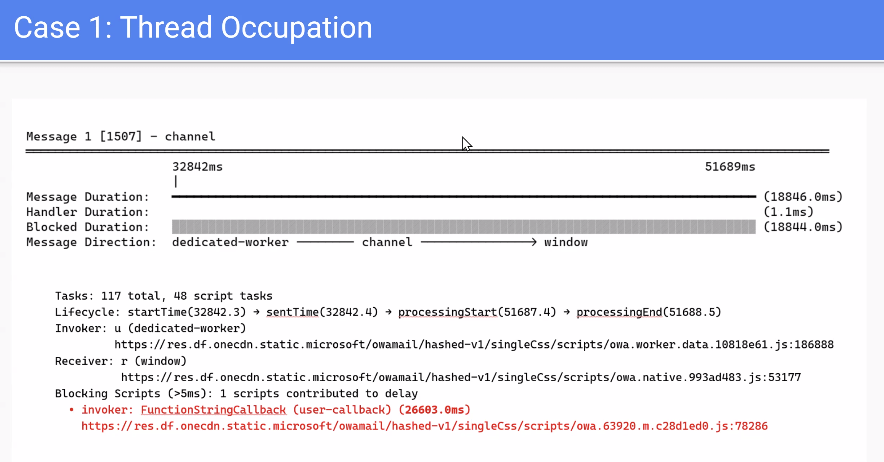
- … Long task that blocks the receiving of the event
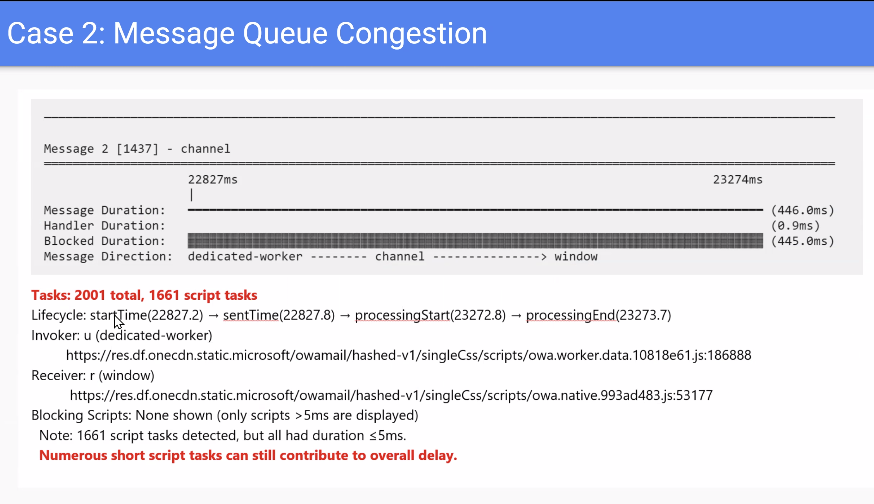
- … No long task, just many small messages. taskCount and scriptTaskCount are high in the performance entry
- … Unsure about taskCount and scriptTaskCount
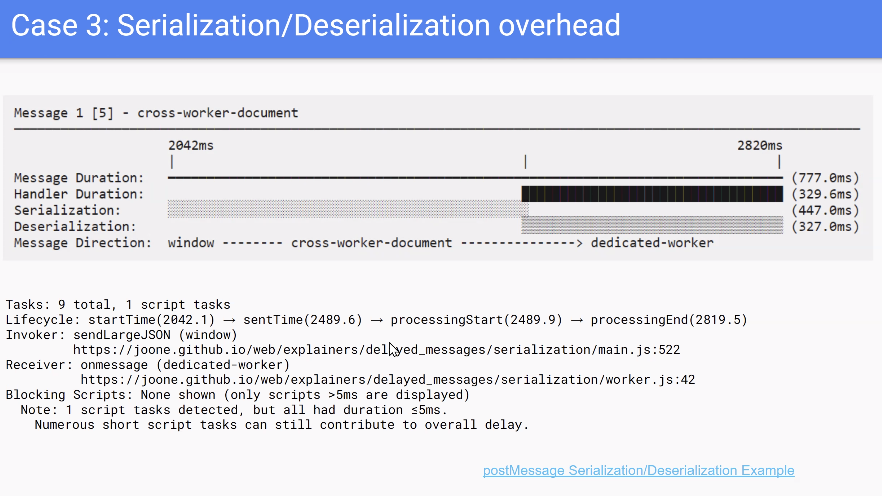
- … reproduced this using 7000 JSON entries to be serialized
- … <demo time>
- Michal: Reports go to the sender? Do they both get a copy?
- Joone: Same timing yes
- Yoav: If we have two messages, main -> worker and worker -> main, both delayed. How many messages do we see one either end
- Joone: One for each
- Michal: Let's say there's a task on the main thread. Could be useful to stitch them together. Should developers do that manually?
- Joone: yeah. On the main thread this and LoAF provide the same sources of delay
- Gouhui: The high precision timers are not synced between the worker and the main thread and there are time drifts. Can we measure the precise time difference between the two?
- Joone: If you’re running the browser for a long time, there’s a time difference. You need to manually sync the time
- Ben: All workers?
- Joone: yeah
- Ben: There’s IPC times and start up times. Not sure if it’d be useful to share that information as well
- Shunya: SW startup time is already exposed in resource timing
- … Not sure how actionable it is. E.g. the number of tasks - what should developers do with that? How can they know if the number of tasks is high or low? There are also browser differences
- Yoav: Not the spec concept of tasks?
- Michal: Yes, but it is arbitrary how you schedule work
- NoamR: Webkit and Mozilla don't have the same concept of tasks
- Michal: Remember similar discussions for regular LoAF and scripts
- ... In EventTiming, there's a HW timestamp, takes some time for it to be scheduled
- ... For tasks you have the queuing delay
- ... If you setTimout, there's the time it should have fired, and when ti's executing
- ... Speculated how early it could be scheduled, then when it fired
- ... for postMessage() you could track this is when it could have run, but there was an input delay
- ... Counting tasks is indirectly
- Yoav: Task counting, you have duration, but it's part of the attribution. Long tasks, or queueing.
- Michal: Maybe the other part of this is exposing LoAF on workers
- NoamR: Origin thing that lead to this
- Michal: Attribution across the boundary is uniquely interesting
- Yoav: You'd have to coordinate timelines to figure out what happened
- NoamR: Didn't realize you're doing this for main thread
- Joone: Should only do this for same origin
- NoamR: Main threads shared across site
- ... LoAF this is crude to measure anything about same site
- ... Could have a lot of same-site pages, creating delays
- Joone: In case of channel message, or other document messages, a.com sending to IFRAME, IFRAME cannot monitor postMessage event
- NoamR: On same thread so they can see if something is delayed by something they don't know
- NoamH: Question on avgTaskDuration, how actionable it is
- ... Average could be misleading, could have a long task and a lot of short tasks
- Joone: Yes
- Noam: Could expose total duration and count, someone could calculate on their own. It’s forever increasing, per-message TODO[a]
- Joone: We got the API for testing implemented locally. Tested this with our team
- Michal: Unrelated comment - talked about async context and keeping tabs of tasks
- Joone: Each message has a traceID so we can stitch things together
- … Writing a design document and planning to land this. Prototyping stage
- NoamR: Could be useful here to be able to pass a string to the postmessage that would tag the performance entries
- Michal: I expected that it would be the receiver of the message to get the timing, not the sender. If the worker thread is the busy one, how could it communicate that there was a delay to the sender. The main thread could possibly adjust the task queue so the worker can communicate back easier.
- NoamH: We have a scenario where we have multiple hops - main -> worker -> worker
- Michal: Would be cool to extend LoAF, as this would segment the data.
- Guihui: the timing would sync the clocks, if everything that defined the time and passed it onto the next receiver
- … If we had timestamps across the path, we would be able to know where the message got delayed (e.g. in a multi hop path)
- NoamR: Needs an incubation spec first and then we can talk about adoption.
Recording
Agenda
AI Summary:
- The group discussed enabling compression dictionaries for widely used third-party static resources (e.g., analytics.js), but current `no-cors` loading of these scripts makes responses opaque and unusable for dictionary compression.
- Today, making such responses CORS-readable requires HTML changes (`crossorigin=anonymous`) and per-origin `Access-Control-Allow-Origin` handling, which is operationally heavy, hurts caching (per‑origin variants), and often requires an extra connection.
- Pat proposed new server-side headers (e.g., a “Content-Readability” opt-in plus `ACAO: *`) that would allow certain `no-cors` responses (scripts, styles, possibly images) to become CORS‑readable without HTML changes, thereby enabling dictionaries and other use cases like drawing images onto canvas.
- Participants explored constraints and risks: limiting by `sec-fetch-dest`, avoiding preflights, compatibility concerns when responses stop being opaque (error muting, stack visibility), and the need for alignment with Fetch/WHATWG; a future document policy that enforces CORS-enabled fetches was also suggested.
- There was tension between the long‑term “just add `crossorigin` everywhere” answer and the practical difficulty of updating billions of existing embeds; compression dictionaries may be a strong incentive, but probably not enough alone, so a gradual, CORS‑if‑available style mechanism was considered valuable.
Minutes:
- Pat: Refreshing on Compression Dictionaries
- ... Deltas for same resources, e.g. 3P scripts. Google Analytics or ReCaptchas
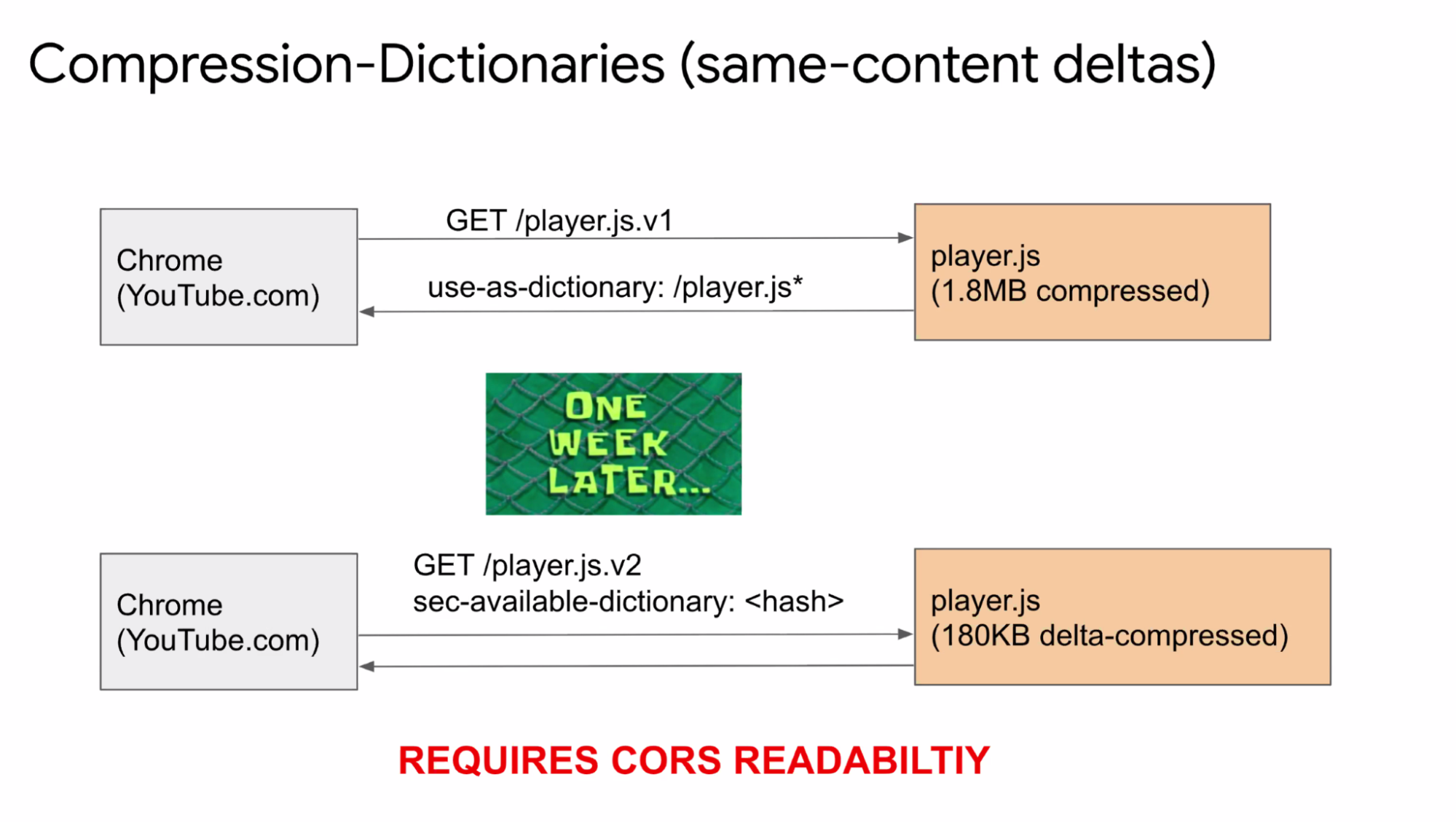
- ... Current version of analytics.js, come back a week later and you want the delta to the latest
- ... Dictionaries need to be CORS-readable, and responses CORS-readable

- ... Which leads us a problem of no-cors requests for 3P embeds
- ... All 3P scripts currently, you can't 3P compress because they're opaque

- ... You can force 3P scripts to be credentialed for CORS
- ... Have to do something on origin page, and all scripts to get adoption
- ... Pre-flight performance concerns
- ... Each CORS request needs a ACAO that's specific to the origin that requested it
- ... Can't have a CDN storing requests for analytics.js without storing responses for each origin requesting

- ... Other option is crossorigin=anonymous
- ... Chrome needs an additional connection
- ... Proposing to allow for origins to opt-in to CORS readability for no-cors requests

- ... Say this is a public static resource
- ... Two HTTP headers proposed
- ... Content-Readability bikeshed
- ... Would require ACAO: *
- ... Make way for some level of no-cors requests to opt-into CORS readability without having to update the embedders
- Yoav: Use-Credential example, do you really need credentials? These resources from public cacheability, they're not based on cookies
- ... Cross-Origin bit, main constraint is the update-the-web part
- ... Do we know if separate uncredentialed connection is a problem outside of Chromium
- Alex: I don't know
- Yoav: Deployment cost is the update-the-web part
- Pat: Scale of 3P resources, a static CDN for a site you own, you could same-site if you wanted to
- ... It's the 3P embeds, to get any viable adoption, you're talking decades
- Barry: Complicated with link rel=preconnect
- ... Here's another reason they'll get it wrong
- Pat: Other cases where you'd want something no-cors to be readable? Not sure
- ... Dictionaries is the use-case I care about
- NoamR: Being able to draw images to canvas
- Pat: Server for image would need to opt-in to advertising that it's public, but it wouldn't have to do per-origin
- Yoav: Wouldn't need to change the HTML that loads the image for that purpose
- Alex: Header to opt-in to 3P use of dictionaries
- Pat: To opt into CORS readability of response, which has a side effect of allowing dictionary compression
- Yoav: So I'm loading <script src=public.com/example.js">, Content-Readable+ACAO=*, now the browser can read it
- ... Doesn't have the crossorigin attribute, so no-cors fetch initially
- ... In Parallel, it would be nice to have a document policy that could enforce all fetches to be CORS enabled
- ... It would reduce the uncredentialed 2nd connection problem, because you'll no longer have the first connection
- Pat: What I don't have historical context on, why ACAO=* isn't allowed for credentialed requests initially. Footgun?
- Yoav: Yes
- Pat: Now it's a double-footgun
- ... Since developers don't understand CORS anyway, they'll slap these headers on every response whether they should be there or not?
- Yoav: Other signals that also indicate it's public, Cache-Control or lack of Cookies?
- Pat: Lack of cookies on request feels like overkill and challenge
- ... Cache-Control public, I don't see why not
- ... Not sure CORS readability requires public cacheability
- ... CORS readability for a single private cache partition, you're saying it's readable, but doesn't mean same response for every user
- Yoav: Content-Readability, 'public' means it's a public resource that doesn't vary by cookie
- ... That's how I interpreted it
- Pat: You could have an API call that's not cacheable at all
- ... Already sandboxed in document any can access any request that was made
- ... Doesn't necessarily mean it needs to be cached across all caches, or that it is cacheable at all
- Yoav: They often do tho
- Pat: For use-cases I care about, they're often the same.
- Ben: For compatibility POV, if there's web compat concerns with sites not getting opaque responses from Fetch API, now responses with non-empty query-string URLs
- Yoav: Their 3P will break them, and not this feature
- Ben: Loading a website with some 3P, you haven't updated it, some assumption that they have a null URL, would something break? Some web compat risk here?
- Alex: I've seen issues like that
- Ben: CORS has some request headers that prevent CORS from happening. You need CORS-safe headers.
- Yoav: Triggers preflight, here you won't have that. Preflight is to protect server.
- Ben: Lot of details here
- Pat: For a CORS request, server needs extra headers to determine if it needs to allow it to be readable
- ... That would all have to be spec'd
- Ben: For compat concerns, no-cors request, it gets Content-Readable, ?
- Yoav: Fetch would be a cors-enabled request?
- Ben: You could make a no-cors request
- NoamR: Restrain to specific fetch destinations, scripts and styles
- ... Limited by sec-fetch-dest
- Pat: Yes
- Yoav: We don't care about case where it's script loading
- NoamR: Spec now for CSS resources and CORS ?
- Yoav: We need a document policy
- Takashi: Why doesn't this work?
- Yoav: There are a lot of sites out there that added a snippet without that attribute
- ... You will not get them to change it
- Takashi: For script tag, will it work with just crossorigin= attribute
- Yoav: Yes, but you need every site to
- Pat: Billions of websites that use it need to update for responses to dictionary-usable?
- Takashi: What is special for dictionary?
- Yoav: For dictionary you need response to be CORS-readable, otherwise it's unsafe to use
- ... We'd like a way for server to say this response is CORS-readable, without client HTML having to change anything
- Takashi: In this case can we read the contents of the image
- Yoav: Yes except if sec-fetch-dest restrictions
- Alex: This is allowing 3P to say "yes it's OK to CORS read me"
- Yoav: Yes
- ... Not aware if the change is compression dictionaries and things get faster
- Pat: 3P can already update the contents without first party being aware
- Alex: Seems scary
- ... We do already have a way to do this, with crossorigin=
- ... I've seen numerous loading issues where something's no longer empty or opaque and that breaks something
- ... A well-formed website shouldn't have this issue
- Yoav: Concern is compat issues once 3P start using this
- Alex: Shortcut to adding crossorigin= everywhere, without 1P opt-in
- ... If we had opt-in?
- Yoav: That would be a document-policy we've been dreaming about
- Pat: Subtly different because no-cors still sends cookies for example
- Ben: Harder to send everything into cors, really needs CORS if available, fallback to no-cors
- ... Can't just add crossorigin to everything
- ... Have a two-step thin
- Ben: Limiting to certain destinations, would penalize service workers
- ... Cached stuff
- NoamR: Script compat issue because no-cors script errors would be muted, would they still be?
- Pat: Would be interesting to see
- ... Triggers on mode it was fetched or readability of response
- Noam: no-cors error is “muted” and this would change it
- Nic: See the stack?
- Ben: stack can change
- Nic: yeah, but current invisible
- Euclid: Shouldn’t this be a WHATWG issue?
- Yoav: shared but issue is on Fetch
- Ben: Would be nice to say “I’m open to CORS readable”. CORS-if-Available, but don’t break if the other side doesn’t support it
- Pat: From the script dictionary side of things beyond analytics is GTM tag manager where the tags are unique per page and want a dictionary that compresses the common stuff, but keep the unique stuff
- … TODO[b]
- Alex: Are the benefits of compression dictionaries not a big enough carrot to get people to add an attribute?
- Pat: It took 15 years to stop people from loading analytics in the head
- Ben: Are the 3Ps recommending crossorigin tags?
- Pat: Nope. crossorigin anonymous requires a separate connection from everything else.
- Ben: seems like a good first step.
Agenda
AI Summary:
- The group discussed refactoring and layering of timing specs (PaintTiming, ElementTiming, LCP), with a leaning toward centralizing shared “infrastructure” concepts (e.g., per-frame paint/presentation timestamps) in a PaintTiming/paint infra spec while keeping higher-level APIs in separate, implementable chunks.
- Consensus emerged that LCP should produce a single report per frame/presentation (covering the largest of text or image candidates), aligning implementations and fixing current multi-candidate-per-frame ambiguity in the spec.
- There was extensive debate on LCP stop conditions (scroll/interaction definitions, “trusted scroll,” automatic scroll restoration, benchmarking impacts) and on whether to expose ways to disable buffering or accounting, with follow-up issues planned rather than immediate changes.
- The group examined loadTime vs paintTime/presentationTime semantics (including cached/reused and background images), agreeing these are distinct and both useful, and that clearer spec hooks and diagrams are needed to define when images are “ready to paint,” decoded, and presented.
- For background and repeating images as LCP candidates, participants agreed to rely more on entropy/area-based heuristics and potentially limit how repeated tiles count toward area, so placeholders (like repeated sheet backgrounds) can be reported when meaningful but not overshadow later, more contentful LCP candidates.
Minutes:
- Michal: PaintTiming spec does a lot of heavy lifting in terms of the algorithm
- ... References from ElementTiming and LCP to PaintTiming
- ... History is LCP would refer to ET to PT
- ... But ElementTiming was not adopted into WG, in WICG
- ... Refactored LCP to only depend on PT
- ... Since then ElementTiming is adopted into this group
- ... We now have a few new layering issues

- ... Suggestion PaintTiming details timing on a single animation frame
- ... Lots of interest and excitement in LoAF timing
- ... PaintTiming concepts, every animation frame has these timestamps
- ... Folks are using these things for more than just scheduling, e.g. smoothness and postMessage() delays
- ... What are the common elements of every animation frame and what's in side of it
- ... Then ET should determine on which paints should report
- ... Several paints
- ... That spec should be responsible for defining
- Barry: FirstPaint and FirstContentfulPaint, not elements
- Michal: Once an IMG goes into a DOM, that could be the moment we discover an image, but there's nothing contentful in there
- ... A single pixel of image content, you'll have FirstPaint
- ... FP and FCP entry type, related to whole page
- ... Every element has this concept
- ... This is not exposed right now, but we keep track of it in Chromium
- Barry: Call "Element First Paint"
- Ben: Is it necessarily to have different spec docs here?
- Michal: Two alternative proposals, we'll get there
- ... At the moment, ElementTiming describes a single timing
- NoamH: Debates in the past about these topics
- Michal: Let's leave for later if we can
- ... Maybe expand these concepts and move paint to later

- ... More related paint-related entry types coming down the pipe
- ...

- ... Concepts might make sense to merge together
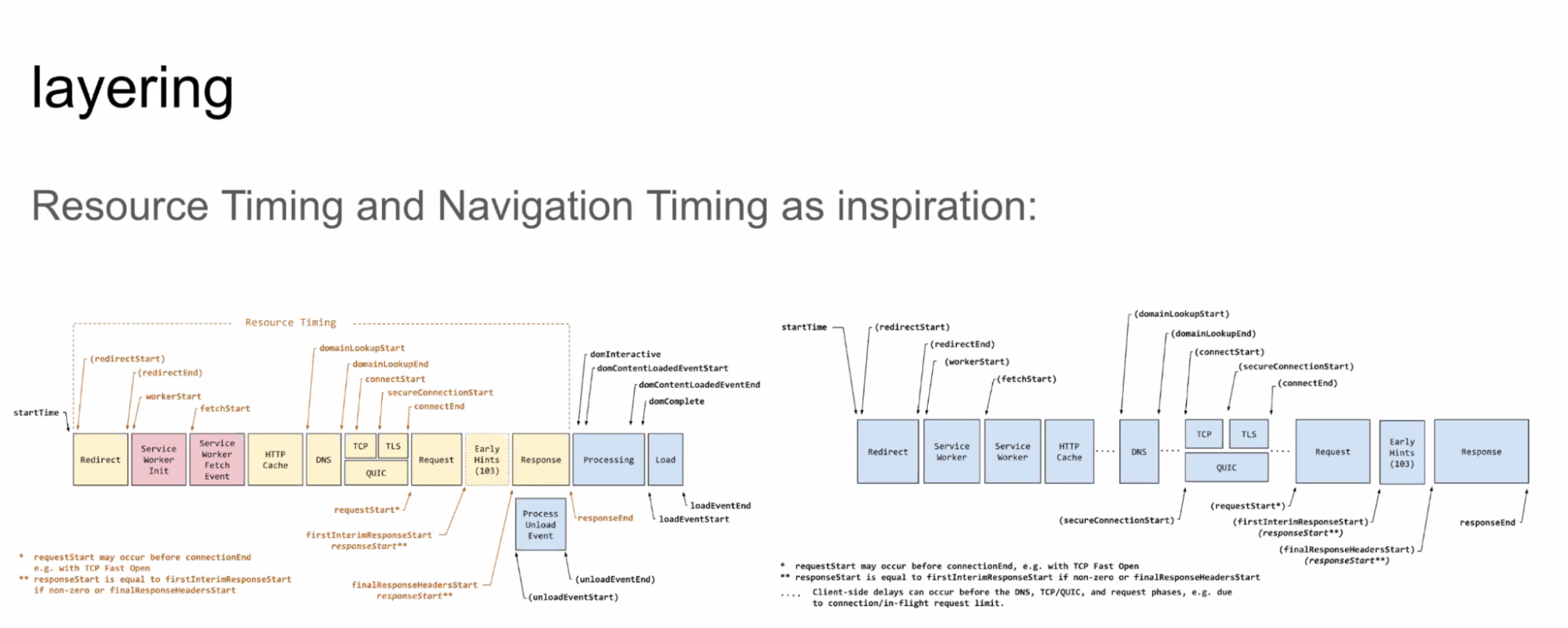
- Ben: Infra concepts, then API level things that sit on top of it
- Yoav: Or theoretically we could have one big timing spec
- ... All relevant specs are living standard now
- ... This feels orthogonal to issues in title
- Michal: It is
- ... Some of these are more complicated than how to spec a single paint timing
- Simon: Not to merge specs, not all UAs will not want to implement all things
- ... Not necessarily bought into doing each
- ... Prefer specs are implementable chunk
- Michal: ElementTiming is a set of concepts as well as an API
- Yoav: Pull concepts into another spec
- Michal: We have thin separate specs that define entry types, algo, etc
- ... We partially did this, let's finish the job
- Bas: Simon do you think there's a fundamental issue if we merged into a single spec
- ... What would stop a UA from implementing part of a spec, vs others
- Simon: Hard to describe what a UA supports vs. others
- ... For interop can't argue about a whole spec
- Bas: For e.g. MDN docs, per API not per Spec
- Simon: A bit easier
- Barry: FirstPaint isn't implemented by some but FCP is
- Yoav: WebKit isn't implemented, but there's a spec exemption
- Rysouke: Because FP and FCP are the same
- Yoav: Could be easier to have high-level specs, and since this is the current structure roughly, keep that, move infra to a central location
- Michal: We have had oversights and inconsistencies with current
- ... ElementTiming may be thing wrappers around concepts
- ... EventTiming there's a lot of other things
- Bas: Real value in having all definitions of what paint, presentation means in one place
- Michal: great diagrams for Resource and Navigation timings
- ... Haven't done graphs for paints
- ... Might be useful to diagram all APIs and how they fit together

- ... Today if you have EventTiming or ElementTiming, you could get LoAF sometimes, and get whatever other things you want, maybe we move this into PaintTimingMixin.
- ... Duplication of data, but more convenient for observers

- ... Onto issues
- Bas: Spec requires you to have 2 LCP candidates, lists them in order, adding them in order
- ... Unclear to me what people want
- ... Iterate over things, over all text elements, find a bigger one, you add an entry. Order in which iterating matters, you may get multiple if sequentially increasing.
- ... Next you go over images, if have both in same frame, spec-wise you have both
- ... Do you want both text LCP and image LCP, do you want more than one of them in a paint at all
- ... What Chrome is doing seems most obvious
- ... You want one of both of these, and one per paint
- Barry: People said it was useful without fully understanding what it was
- Yoav: Useful as LCP, or as something else (all paints)
- Barry: Some people wanted largest text and image CP, but this wouldn't give this to them
- Bas: Exact same page, refresh, depending on timing, you'll get 2 or 1
- Barry: In Chrome, never get 2 LCPs in one frame, Firefox you can
- Yoav: Potential use-cases for something else entirely, and this is a bug we need to fix
- ... Bug in spec
- Barry: Bug in spec, or bug in Chrome since we're not following spec
- Yoav: Spec should define the behavior we want
- Michal: Spec should say you get one report per paint
- ... That report could have both text and image
- Yoav: Breaking change
- Michal: Once you pick the largest element, then it should follow-through all the way to reporting
- ... In Chromium if next paint has largest, we'll keep overwriting it. That's race-y.
- Bas: Report one per presentation
- Michal: Another way to say, is user sees screenshots/film strip, each may be contentful
- Barry: Ultimately the point is to get the largest one, if you care about scoring
- Michal: Only if you care about scoring, you may want incremental updates
- ... Current way that Chrome does it is inconsistent
- Bas: Agreed
- Yoav: It is true there for LCP there's not a use-case to report both, if there's a future thing, but for consistency between implementations, and compat/interop, we'd like to report two of those
- ... If we wanted to define just a final score, then we do that.
- ... Consistent way is one per frame
- Barry: One per frame seems natural thing
- Michal: Does that match implementation in Webkit or what you'd like it to be
- Simon: Report one LCP per frame, and largest of text or image paints
- Yoav: Align to that, spec
- Nic: Sold

- Michal: Two related issues
- ... LCP has stop criteria
- ... Moment an interaction with the page happens, rate of paints isn't a loading experience anymore
- ... LCP defines stop criteria for scrolling, calls into EventTiming for input
- ... Issue with wording
- ... For scrolling we have an issue where we talk about “trusted scroll event” which doesn’t do what we want
- … Need to update the interaction ID
- … Only important to differentiate tap from scroll, but LCP doesn’t care about that
- … Also mentioned that maybe we should measure these types of interactions
- NoamH: When the spec was defined we discussed it but it was too hard to accurately define it
- … The interaction that triggered the scroll
- Bas: For continuous events it’s tricky, but for discrete events, there’s no point in not having an interaction ID
- Michal: Yeah, you need to define it with actions that are defined as interactions
- … Janky web defined scroll feature is already part of interaction tracking
- Bas: If you do the pointer cancel you don’t care
- Michal: Pointerdown is passive but you can make it not passive
- Simon: Don’t want to define start scroll as the event. Also we don’t send it to the renderer if there aren’t events registered
- Bas: You tell the content that scrolling started
- Simon: yeah, to make content sticky work
- Michal: automatic scroll restoration shouldn’t stop LCP
- Bas: Not obvious to me. As you’re auto-scrolling parts of the element move into view and it’s not clear what the LCP should be
- Michal: In Chromium we don’t track the maximum size the element occupied
- … Issues to resolve this, but maybe not resolve it here
- Simon: can make LCP data less useful and more noisy
- Bas: So maybe the trusted part
- Yoav: Trusted part wasn't for automatic scrolling based on navigation, but to prevent sites from determining when LCP ends
- Bas: Let me stop LCP before I put in my largest element
- Yoav: Part of motivation
- Bas: Motivation driven by search rankings, there's a reason for them want to measure it
- ... Doesn't seem like a thing the spec to care about
- ... I can see why Google would care about that
- ... As a website, yuo can mess up your own measurements
- Barry: Can be affected by other third parties
- Yoav: Definitely a thing
- Barry: Site owner doesn't understand what they're doing
- NoamH: Semantics to fix regressions, cases where measuring element timing, simple fix was to just add a setTimeout()
- ... New ICP may solve that
- Bas: Scroll of a certain distance
- ... 5%+ viewport
- Michal: Define initial viewport and keep constraint on that
- ... Sounds like follow-up here
- ... We need a trusted scroll concept, or remove restriction all together
- ... You allow scrolling but keep track of scrollable area
- Simon: No preference
- Bas: No way forward yet, concept we want doesn't exist
- ... Restrict to initial viewport suggestion
- Simon: Don't necessarily paint things to initial viewport, e.g. large initial scroll offset
- Michal: You would just get no LCP candidates, or enough of initial viewport has scrolled away
- Bas: Or define as scroll offset on first paint of viewport
- Barry: Don't we have smooth scroll
- Michal: Viewport on first contentful paint is interesting
- ... After FCP that scrolling becomes a problem
- Barry: Sometimes when linking to bottom, shows top then scrolls down
- Simon: Finding when implementing LCP, when running benchmarks you don't have stop conditions, no user input and scrolling
- ... Had to minimize effects of LCP on benchmarks
- ... Especially if having CSS transforms etc
- ... Stop conditions in the benchmarking case
- ... Test FF and didn't detect any benchmarks affect, couldn't test Chrome
- Yoav: Flag would have to remove accounting, not just turning off API
- Bas: Flag in FF does turn off accounting
- Michal: a flag for all the accounting makes sense
- Simon: LCP never stops without interaction, which is weird
- Bas: See this in carousels without interaction where you can get LCP after a minute
- Michal: There’s no timeout that you can pick though
- Bas: There are things like Layout Instability that require more accounting than LCP
- Simon: Can’t implement LI without a benchmarking clause
- Alex: benchmarks should measure what user sees
- Michal: Some benchmarks simulate interactions, but in this case we’re just thrashing the browsers in non realistic scenarios
- Alex: Having a way to say “please stop measuring” can be useful
- Simon: A benchmark could trigger an LCP which is the size of the viewport to stop
- Bas: Is the malicious case really something you care about?
- Michal: Would it suffice to run the benchmark in an env with flags or do we need to web expose a way to turn off the feature?
- Simon: Prefer the idea that the website can say it’s no longer interested in LCP
- Bas: Solved by Interaction Contentful Paint?
- Michal: Chromium is moving towards all accounting all the time
- Bas: Benchmark regressions are you seeing?
- Simon: I saw it before I did a bunch of optimizations
- ... Some of the Speedo subtests, e.g. data: URIs
- ... Got it to pretty much zero regressions
- ... If we talk about future specs with more accounting this may come up
- Yoav: At some point we run accounting is before any PO is registered, because we have buffering
- ... Could turn off buffering for certain features, then the browser doesn't need to do the work
- Michal: I feel comfortable with that
- ... Browser could optimize for it
- Yoav: Stop measuring LCP now is more intrusive
- Michal: Requests to turn off Buffering were also to increase buffers
- Yoav: Orthogonal discussion
- ... Doesn't feel difficult
- ... Maybe increase the buffer for certain things
- ... Have it be a header vs. something on the page
- ... That way 3Ps can mess it up
- Simon: I can file an issue for this request
- Michal: Issue "What is loadTime?"

- ... The onload handler was not fired in same animation frame/paint, it was async
- ... Spec'd to be async, but the place it gets scheduled, we'll show image to user before JavaScript fully acknowledges
- Bas: We prioritize vsync vs. running any additional JavaScript
- Michal: Wording is same moment task running, but one timing advantage is you get the paint where the image was first available
- ... More valuable when you wouldn't always get a paint time
- ... For TAO and other, you couldn't get it
- ... We now always get it with PaintTimingMixin
- Bas: Point where UA has determined image fully available for painting
- ... Regardless of where they happened
- Yoav: Use-case for loadTime when we have paintTime is to measure the delta between the two
- Michal: Bunch of reasons why loadTime wouldn't be resource responsEnd and not paint time
- Simon: An already loaded image, e.g. background image, but now I'm doing appendChild()
- Michal: It would be after you append the new content as we'd re-fire onload handler
- Yoav: background-image there was no handler
- Simon: Existing image, you loaded. Then re-used as background-image for element on DOM, but it's loadTime may have been some minutes ago.
- Michal: Same Image() object that has called decode, or a URL string re-used
- Yoav: It's already in the HTML spec concept of memory cache for images
- ... Loading a URL that you loaded in the past, same object from HTML spec image
- Michal: Register a new onload handler it would fire
- Bas: For purpose of this, that seems OK, the loadTime was way earlier than timings from PaintMixin
- ... You did have all the data to draw the image
- Yoav: Then you have a difference between loadTime and paintTime that isn't a bug, should we care?
- Bas: Feels like there's value in these two timings. loadTime isn't useless
- Carine: loadTime different when there's assistive device that doesn't paint?
- Michal: I think they still paint
- Bas: Accessibility thing where you don't paint
- Yoav: Does the browser concept of paint?
- Bas: I think there's a Firefox setting to not paint images
- Barry: link rel=preload where it loads but doesn't paint it
- Bas: LCP candidate later but responseTime in the past
- ... rel=preload element wouldn't be load handler we're talking about
- Michal: Implicit concept here not exposed, it's the discovery time of the element
- ... We now know there's an image with background-image, the moment you discover the fact you want image on the page
- ... You could've pre-loaded bytes
- ... When you want it in the DOM, it might be immediately loaded, or immediately painted
- ... If you add IMG to DOM before it's loaded, it might take moments to load, or never paint at all
- ... For progressive/animated images, we trigger ElementTiming, before loadTime, and we don't reissue
- ... Spec for all moments of element's life, what do they mean?
- ... For Simon's question, the moment you load that background image, you'd get a new loadTime
- Bas: Tying this to just the load handler seems useful
- ... "beginning of the onload hander" --> whenever the browser can describe when the beginning was
- Ryosuke: We don't have onload handler for background
- Yoav: They are LCP candidates
- ... Better to have hooks
- Michal: Background images must have a loaded concept we can hook into
- ... Might even be value in more timings
- ... LCP subparts
- Barry: We use ResourceTiming for that
- Michal: Define Hero Image, bytes are all available, but page is blocked for many seconds for rendering, that gap of time is interesting
- ... Subparts right now we just go all the way to presentation
- ... For one element, you may want to have subparts
- NoamH: IMG loaded already, the load event handler was running
- Michal: Before load event handler fired, same image reference
- NoamH: Append reference to DOM, onload should fire again
- ... Tried in Chrome
- Yoav: Load event not relevant here, it's load event readiness that we want
- ... We need to define that
- Ryosuke: Background image doesn't define any fetch integration
- ... CSS also has clause that implementers may optimize by not downloading images not visible
- ... SVG some are visible, some are not, browsers don't have to download
- Michal: If you can optimize away load, paint because it's not visible content
- ... You'd be able to provide a better LCP
- ... For spec consistency and interop it'd be nice
- Yoav: Non visible background images, if browser doesn't load them, they're not candidates
- ... Ideally we'd have fetch integration for CSS

- Michal: LCP isn't perfect, even if it's occluded
- ... If one browser didn't report it and one did, you'd get different timings, not interopable
- Yoav: Need to define hooks in spec where definable, and file bugs in specs where not definable
- ... Bug until CSS fixes spec
- Ryosuke: We'll try to say load time is when the browser is conceptually ready to schedule an event, not when it's going to fire
- Michal: Conceptually ready to paint image, but there may be other reasons why it doesn't paint
- Ryosuke: Decoding time
- Michal: Difference between paint and presentation time
- Bas: Might decode before the paint
- Michal: Firefox has two paints, before decode and after decode in Chromium we don't do that.
- Ryosuke: sounds like decoding also need to be defined somewhere
- Yoav: Taking PNG, removing gzip, changing to image bits
- Michal: In WebKit do you go back through main thread imaging, or through compositor?
- Simon: Presentation time would come after decode
- Bas: Everyone but us is doing paintTime before decode
- Michal: There's no optimization we're driving for
- ... In Firefox, your paintTime is after decode
- Ryosuke: Presentation time is what you use for LCP?
- Michal: That's what we use yes
- Bas: Doesn’t it report when we hook into the paint loop
- Michal: That’s not how we landed in the PaintTimingMixin
- Bas: Does it change without Mixin
- Michal: The concepts are part of that, but even if you don’t expose it, the paintTime and RenderTime are defined there
- Ryosuke: So LCP is presentation time, unless browsers don’t implement it
- Michal: You can have a blank page without presentation (before decoding) where WebKit reports FCP
- Bas: so if you don’t have implementation-defined presentation time you report the paint time
- Ryosuke: inconsistency
- Michal: If you implement paintTimingMixing you get an interoperable way to compare those times
- … you could have an interoperable comparison or have what’s best for developers
- Bas: Can’t find a good definition for rendering update end time
- Michal: So we should review the PaintTimingMixin but there was an effort to clarify this
- Ryosuke: Need to create a diagram on which event happens where
- … Lots of confusion here even in this room

- Michal: can have multiple CSS BG layers. Looked into Chromium and we would paint from the bottom layer up. If they are all the same size, the bottom-most would count (currently)
- .. Maybe it’s not a BG images issue at all - if you have one paint and we’ll pick the one candidate, it should be the last largest one to paint.
- .. would also solve Z-index issues
- Bas: Chrome ignores viewport-size images and we don’t
- Michal: wanted to ignore “background” images
- … If we pick one candidate element per paint, should it be the last one?
- Alex: Is paint ordering well defined?
- Michal: I think not
- Ryosuke: We can't depend on paint order, undefined
- ... z-index ordering or whatever is on the "top"
- Simon: Paint order is defined
- Michal: Say "the last to paint" and the order will be consistent with other specs?
- Simon: I think doing "last one" is fine
- ... Repeating background is more interesting in this case

- Bas: I would say the Firefox behavior is what the user sees
- Michal: If you take a small image and scale it up, LCP will take natural size of image
- ... Repeating background image
- Bas: Issue on image scaling?
- Yoav: Not talking about scaled up, but repeating
- ... Scaled up could be blurry, low quality
- Bas: How much of viewport is represented by element
- Ryosuke: Scaled image could be just as crisp, e.g. solid color
- Michal: Spec says these are heuristics
- Ryosuke: Some consistent wording is desired
- Michal: I can see argument for user seeing whole area
- ... Could also see this is low-entropy and we ignore it
- ... Spec by number of bytes
- Barry: There's a formula
- NoamH: We played with repeating images horizontally and vertically, to emulate grid structure
- ... Image is just a rectangle
- Michal: Would you want the timing when that loads, primary / hero content?
- NoamH: If that indicates the main part of loading process, then to some degree that's how it's implemented right now
- Ryosuke: One case is when using repeated image, is some main content occupying large case. Other is repeated image is a background situation with more interesting content on top of it, which is what we want.
- ... But we don't know as a browser which one is more important
- Alex: Unless we give the developer a way to say what is important
- Michal: Set of cases where background images are hero content
- ... e.g. textured backgrounds of divs loading late
- ... e.g. some high-fidelity image comes in behind
- Bas: Banner or image carousel
- Ryosuke: Spreadsheet app, cells
- Michal: Divs with background color that's not candidate on its own
- ... What is the user waiting for, to be useful enough to use
- NoamH: Agree it's not common
- Gouhui: Can you use ElementTiming in that case
- ... LCP is a heuristic, ElementTiming covers
- Bas: For entropy threshold, we take visual size into account, isn't that a reasonable argument to say size of area covered is the right thing
- ... Background image is low-fi stretched
- ... that would bring it below the entropy threshold
- …Amount of image data per area covered, if it's repeating for 10x repeat to hold contentful stuff
- Michal: Sounds like if we take a full rendered size
- A few points to amend the conversation, perhaps:
- 1. Simon Fraser mentioned at the end of the call to perhaps consider a limited number of repeated images for area (I think 10 was thrown out). He added notes about this to the issue without a specific number proposed.
- 2. After the call we looked at a specific example with Noam Helfman of Excel loading a sheet where there is a repeated background image as a placeholder while the sheet loaded. We agreed this was a contentful paint worth reporting-- but Noam agreed this should not override other LCP candidates from being emitted afterwards once the real content loaded. (in other words-- this was a large repeated image but was NOT considered largest based on raw pixel counts)
- Ryosuke: Entropy is a mechanism to judge if it's a candidate, using a mechanism here seems right.
- Yoav: Next steps is iterate over all the things
Recording
Agenda
AI Summary:
- Navigation Timing currently exposes only three `navigationType` values, but RUM tools and CrUX need to distinguish more cases (e.g., prerender, BFCache restore, soft navigations) because they have very different performance characteristics.
- There was broad support for expanding the model (either more enum values, flags, or additional performance entries) to cover cases like: prerender (and activation), BFCache restore vs regular back/forward, and potentially other “restore” types.
- Participants debated whether `navigationType` should reflect “what the user did” (e.g., back/forward vs reload) or summarize “navigation characteristics” (e.g., prerendered, cached) since RUM usage cares more about the latter.
- Ideas included: dedicated BFCache performance entries with their own timestamps, separate prerender activation entries, and/or navigation entries that ICP/LCP could reference directly for easier slicing of the performance timeline.
- There was agreement that more detailed navigation classification is needed, but open questions remain about exact shapes (additional enums vs flags vs new fields/entries), to be resolved in the Navigation Timing GitHub issue.
Minutes:
- Barry: NavigationTiming defines 3 navigation type, but there are other navigation types
- … Used for dimensions

- … RUM solutions often measure navigation types and segregate them
- … Added to CrUX, mpulse also does it

- …Developers need to know a bunch of things
- …

- … having one summary type is sufficient and useful and is what RUM providers do
- … Capturing one type requires standard order and preference

- … NotRestoredReasons tell you that, but it’s not a rare example
- … Should we expand these enums?

- Yoav: Another problematic aspect, that this requires knowledge
- ... Forward compat suffers as a result
- ... We introduce prerendering, people don't know about it, they have to go look for activation stuff
- ... Are things prerender-ready or not?
- ... Beyond discoverability, it would force people to make decisions
- Barry: Prerendered in cases even if sites don't know about it
- Yoav: If platform is starting to Prerender you, or 3P isn't prerender ready
- Barry: Soft Navs are also a new navigation
- Nic: concrete list of the proposed enums we should expand to?
- Barry: prerender, restore, navigate, back-forward-cache
- Bas: Is the BFCache a thing that specs know about
- Barry: yes, HTML
- Michal: Does Firefox update things beyond the type for BFCache navigation?
- Barry: haven’t checked
- Nic: does it update L1 API?
- Barry: not sure
- NoamH: should we do a different thing than enums?
- Barry: They can be flags of the navigation type
- NoamH: in this case it’s prerender or cached
- Barry: In other cases you could care about this, but prerender is the summary type
- Nic: Should BFCache restores have their own entry? It would be convenient
- … Boomerang tries to get an additional timestamp for the BFCache FCP. This can help
- Barry: You could get multiple entries. Tried looking at expanding the navigation array for softnavs but saw that sites would break
- Bas: Looks like we only update the type on restoration from the BFCache
- Barry: Arguably should be back-forward-cache rather than back-forward
- Bas: If we restore from history we set it as well
- Fergal: same in Chromium
- Barry: existing issue 192. Agreed that this is the right behavior, but no tests and no spec
- Bas: Inclined to agree that we should have more types
- … kinda weird to have navigation timing just update the type, because the timings described are not in the BFCache
- Barry: So performance entry for BFCache with extra timestamps
- Bas: I thought it’s already a thing
- Michal: Should we have lots of different performance entries for types of navigation
- Bas: prerender is also interesting. For RUM providers you want to split different navigation that would have different performance characteristics
- Barry: Domenic argued that they are orthogonal. I don’t care as “prerender” is the bigger change
- Michal: You could have a separate event for a prerender activation? All new navigation?
- Barry: should be separate types
- Michal: prerender activation is useful for slicing the performance timeline
- Barry: it should be there
- Michal: But it’d be better if this was one stream
- Barry: But then you’d have entries that follow each other For example, to calc LCP you’d need to listen to prerenderActivation entry, and then LCP entry, and then calc second based on the first. Seems overly complicated for this use case.
- Michal: Would save you from checking a bunch of listener or attributes
- Nic: You wouldn’t need to listen to it as it would happen always
- Michal: There are probably sites that don’t check for prerendering
- Barry: but for prerender we knew it’s a prerender from the beginning
- Michal: If an LCP had a reference to a navigation entry type that would be nice
- Barry: We can do that for prerender, as it’s the first navigation
- … Would a new navigation-type mean that we’d deprecate the current type
- Fergal: the type tells you what the user did to get there. But it’s not a user action to prerender
- … Currently it’s user-facing. Prerender muddies those semantics and makes the information go away
- Barry: I argue it’s not the semantics for “how the user got here” but “navigation characteristics”, this is how RUM uses this
- … Would only give high level summary
- Fergal: In Chromium big difference between BF and reload
- … A back-forward can be significantly faster than a reload for caching reasons
- … Maybe should be a new field
- Nic: how does a back-forward navigation get prerendered
- Barry: If you went back and then forward
- Fergal: Had an idea that if BFCache didn’t happen, we’d prerender the likely back navigation
- Nic: A "prerendered" flag loses whether it could be a navigated-prerendered or a back-forward-prerendered
- Yoav: Maybe we have separate entries for them
- ... Is that a useful dimension to be sliced by?
- Michal: I wonder where we don't have BFCache entry proposed then cleaning NavTiming would be obvious
- Bas: general consensus on more types but need to bikeshed which types?
- Michal: I think that prerender should be a performance timeline event
- … all the arguments apply. Only prerender gets a special treatment and I don’t know if it makes it easier or harder.
- Nic: Let’s summarize on the issue and continue discussion there
- Issue updated: https://github.com/w3c/navigation-timing/issues/184#issuecomment-3515176005
Network Error Logging Privacy concerns
Agenda
AI Summary:
- NEL is effectively unowned/under‑maintained with many stale issues; Mozilla currently holds a negative position and a taskforce exists but has stalled — the group agreed this needs active work to resolve or close outstanding items.
- Primary concerns are privacy and data exposure (request headers, same-site cookies, IPs/private IPs, error granularity); collectors today often strip sensitive fields, and the spec needs clearer limits or anonymization/aggregation guidance.
- Adoption is non‑trivial (HTTP Archive shows ~20% of top sites send NEL; platforms like Akamai/Shopify and some CDNs use it), but Firefox has the feature switched off for privacy and Safari has no implementation — more vendor buy‑in/implementations are needed for standardization.
- Potential mitigations discussed include proxies/anonymization (e.g., P4), differential aggregation (DAP), and narrowing/removing problematic fields (e.g., request headers); concrete spec edits are required rather than only high‑level debate.
- Next steps: commit to making progress (either fixes or a rewrite), recruit editors/implementers and engage CDNs/platforms, and continue work in the taskforce/issue tracker to address specific actionable issues.
Minutes:
- Bas: Currently negative position on NEL from Mozilla. Post with list of open NEL issues that are stale
- … Is NEL unowned and unmaintained? Do people care about it?
- … How can we get the issues addressed?
- Yoav: We have setup a NEL taskforce that has not moved anything forward
- ... Yes people care about it, yes it is unowned and maintained, and we should change that state
- Bas: Besides spec issues, positions, there look like a number of valid concerns
- Yoav: Some of it is things that should be removed
- ... If folks are around on Friday, we should try to make progress
- ... A lot of the issues are spec fiction issues
- Bas: Issue #111 that same-site cookies may be sent cross-site through request headers
- ... NEL collectors in room were stripping that info and have no use-case for it
- Yoav: Last time I looked, Chrome does not send it
- ... NEL collectors actively don't want that information
- Bas: Check if currently disabled implementation follows new spec
- Eric: On WebKit standards position there was some concern around granularity of errors
- Yoav: IP address is potentially there
- Eric: Specific things failing are broken down
- Yoav: Request headers specifically was not implemented
- Bas: Private IPs not being filtered out
- Yoav: We may have make progress spec side since then
- ... We need to do work, that could be a good motivator if Firefox is interested in shipping NEL
- Bas: Not negative about idea of the spec
- Nic: Any open issues that weren't verbally resolved?
- Bas: We discussed in 2023, and resolved it
- ... Granularity concern still?
- Alex: We're OK that "DNS is misconfigured" but have no indication of where it came from
- ... Like URL path is included
- Bas: Issue 151
- ... Default policy only reports domain
- Alex: We've made no implementation progress since then
- Bas: One other issue, 150 ensure that NEL does not report on requests that user does not make voluntarily
- Yoav: Issues that PING opened
- ... Most requests are not that user performs voluntarily, except top-level navigation
- Bas: Maybe there's nothing here, I don't know how much of objections in issue remain and are valid. We'll want to come to a resolution, by addressing or closing.
- Andy: The non-voluntary, Prefetch or Prerender?
- Bas: Issues are about online trackers and advertisements, a user or network operator can deploy DNS firewall, returning invalid IPs.
- Yoav: Concrete issues that we should address before we can resolve philosophical questions
- Eric: Looking at predefined errors, some are specific to user and environment
- ... Goal was to look to origin and problems it has
- ... MITM'd are from users, not related to origin
- ... Would like to know some people are affected, not which people are
- Yoav: Could IP anonymization proxy, without identifiers?
- Michal: P4 Proxy?
- Yoav: If the site pays for P4, this would be what it would go through
- ... If they wanted to use the proxy, they could choose to
- Eric: If you want to not relay, is there a differential privacy thing?
- ... That it would bubble up?
- Yoav: Like navigational confidence
- Eric: By definition the things you want to go bother and fix, are happening to enough people for you to care
- Bas: DAP cheaper than oHTTP
- Yoav: For Nav Confidence, you carry the bit and flag. Aggregation happens by receiver.
- ... User and site bears cost.
- Bas: Different users randomly report a bit, and you aggregate it.
- Yoav: Based on probabilities
- Eric: Can pull out most prevalent type of errors seen
- ... PPM working group is doing DAP stuff
- Bas: Would that be a hard requirement?
- Eric: Not sure
- ... Something applicable to a population without identifying specific people
- NoamH: For privacy, are we trying to protect against the case that we're sending more info about user
- ... What prevents site receiving cookie from client, respond back with report-uri that has ident info from user?
- Eric: Give every user a different report-uri endpoint
- Bas: Site specifies NEL endpoint, it could already collude
- Eric: I think this is a different concern
- ... Not that it can tell a user, but that it shouldn't be able to tell more information about a user
- Yoav: Or airplane where there's a MITM proxy
- Eric: New exposure of information that wasn't previously available
- ... Concern that it and Fetch() are vague about this type of error
- ... New thing you can learn about that user
- Bas: Ability to describe user's network topology
- Gouhui: If exposing report, and there's something new, it can collect new information to a specific user.
- Eric: Certificate that you're presenting is expired, is something observable from any user in that region. Property of the site you're hosting.
- Bas: Captive Wifi portals
- Eric: Observable by many users, hosting should fix
- ... I don't think the goal was one particular user has a bad modem at home, 50% of DNS requests are bad
- ... How do we know if there's a specific high % of users seeing an issue, it's more of a site problem than user unique issues
- ... We're helping a site maintainer know it's good/available/responsive to users are possible
- Bas: Taskforce?
- Nic: There already is
- Yoav: Do we do what we can to fix the current thing, or build a new thing?
- ... If we don't have bandwidth to delete request headers from spec in last 2 years, do we have bandwidth to do a rewrite
- Bas: How much demand is there for this
- ... How much do sites use this?
- ... How much are in practice site maintainers discovering problems through sites with NEL
- FYI, running a quick query on HTTP Archive:
- 20.28% of the top 1,000 sites are sending this.
- 15.35% of all sites overall.
- https://docs.google.com/spreadsheets/d/1D9rL9NDSRT_S8yk5xGzk174EGuyVPK_SguVfz6Lzh_c/edit?gid=0#gid=0
- Carine: Who's using it currently?
- (Akamai, Shopify is relying on platforms using it)
- Yoav: 3P using it
- ... All CDNs using it?
- Bas: Firefox has implementation but switched off due to privacy concerns
- Eric: Safari does not have an implementation yet
- Bas: Value in spec even if one vendor implements it, you'll discover a region or cohort has issues
- Carine: For standardization we need two implementations
- ... Spec has been parked for a while, now it's in progress
- ... Resources and planning problem
- ... If we don't plan to implement, it could go back to WICG or incubation
- ... At this point do we need new editors?
- Yoav: Maybe a third implementation if we solve the privacy concerns
- ... Not sure if these are ones that would have come up in a horizontal review but maybe
- ... There's appetite, moving the spec out would not be the right move
- ... We need to join forces and clarify to all interested parties that use the API that work is needed to improve the situation
- Bas: For spec work, do we need to look our neighborhood CDNs
- Yoav: Some of those left as members
- Carine: If not members, can't contribute to spec
- Yoav: Can they sign off on single PRs
- Carine: An individual can do that personally
- ... I don't think he can sign by himself, he can grant the rights
- ... Better to have discussing with group
- Nic: We need to commit to making progress
- Bas: I could see if someone on networking side could help
Recording
Agenda
AI Summary:
- Recap/status: Async Context is progressing (TC39 Stage 2, WHATWG Stage 1). The group wants a consistent story for how async context (AC) propagates across API classes, but acknowledges many moving parts and memory implications if contexts are propagated too broadly.
- Core debate: should observers/callbacks inherit the registration context (who created the observer) or the dispatch context (what triggered the callback)? Registration context helps “blame” and tracing use-cases; dispatch context helps attribution to user actions.
- API-specific concerns: PerformanceObserver, UserTiming, Intersection/Resize/Performance observers and Soft Navigation/Task Attribution all need clear rules — defaults, opt-ins, or both were proposed. Mozilla raised strong memory/leak concerns if propagation is automatic.
- Frameworks and batching (e.g., React) complicate semantics: userland batching can merge multiple contexts, causing “contamination” and making context merging behavior unclear; this suggests the need for opt-in propagation or limited captured variables.
- Next steps: gather userland/implementation experience, file issues (TC39 repo), and converge on a consistent, implementable default plus opt-in mechanisms and limits to address memory/privacy concerns.
Minutes:
- Nicolo: Recap - it let’s you have state that’s implicitly propagated to flows
- … Stage 2 in TC39, Stage 1 in WHATWG
- … started discussion about internal variables and how they can propagate context
- … Need a consistent story for various APIs - classes of APIs should behave similarly with regards to AC
- … Lots of complexity, many moving parts
- … Memory implications of too much context propagation
- … Specific APIs: PerformanceObserver - should they propagate the registration context or the dispatch context
- … It was suggested that we could have both where one is the default and the other an option
- Yoav: UserTiming, is the mark() the one that triggered the callback, or the RUM script registering UserTiming
- Michal: UserTiming is an example
- ... Difference between new callback and .observe(), I don't know propagating context of caller or dispatch context use-cases where it'd be more useful than register
- Yoav: Main use-case here is blame
- ... Code doing something as result of event is bad code, that bad code is to blame by script that registered it not the thing that triggered it
- Nicolo: Callback just runs in empty context, maybe PO does not really inherit context from who registered it
- ... For example tracing
- Yoav: For tracing, a user-click it's a new dispatch context, blank, but the registration context if it's bad, you should be able to blame the script that registered it
- Nicolo: Registered or defined function with callback?
- Yoav: Click you have stack traces
- ... That's what LoAF does for blame
- ... Runs into issues with wrapping
- ... In context of soft navigation you care about registration context
- Michal: Internal variable .run, that soft navs?
- Nicolo: Yes
- Michal: Snapshot restore
- ... Internal concept, every event listener is already wrapped and we're restoring a special variable value
- Chengzhong: How bad is it for us to set the PerformanceObserver empty context, preferring to capture registration context. Where PO has been created. How bad for PO to call callback in empty context and possibly propagate the variables like task attribution.
- ... Address the memory concerns from Mozilla, PO APIs will not default capture every async context variables
- ... Only capture a single instance like Task Attribution
- Nicolo: Normally create PO at top level of scripts, nested?
- Yoav: Typically have an analytics script that calls various POs, and callbacks collect information
- ... 1P, 3P
- Michal: I've seen element timing as a type of scheduling primitive
- ... Dynamically updating a page, apply DOM tag, now looking for rendering update is complete
- Yoav: Using FCP as proxy for page is rendered so we can do more work, without blocking initial render
- NoamH: Abuse of Observer?
- Yoav: I don't know
- Nicolo: Wrap in a promise, then promise-based propagation works
- Yoav: Question is what's the use-case here, one is to layer soft navigation on top of Async Context
- ... Then various browsers adopt, they have infra, they could more easily build Soft Navs on top of it
- ... For that I think you need a way to provide exceptions for specific cases
- ... That's one use-case, another is various tracing, I would think the registration propagation is better
- ... But I can see an argument, you have to opt-in to that
- ... As a userland primitive, you need to opt-in
- ... You create a context that gets propagated
- Nicolo: 1P code and 3P code
- Yoav: Run in top-level context, you're responsible for it
- ... That opt-in could be, if you need a specific context, it maybe eats up more memory that we'd like
- ... Tracing has memory cost
- Nicolo: Option to propagate
- NoamH: How is it more memory
- Nicolo: You can tell if it's used or not
- Andreu: If you're doing an await, you don't necessarily know all variables registered in the specific context
- ... If we're doing registration context for events, no one ever calls removeEventListener
- Michal: For Soft Navs I don't see a strong use-case to have context for PO
- ... Whatever you do for observables would be useful here
- ... If uniquely problematic, no context seems
- Andreu: Reg context for PO, probably not
- ... Depends on the use-cases
- ... Moz is very concerned about potentially inadvertent memory leaks from websites
- ... Ideally all observers should obey the same
- ... If we're doing empty context for registration context, that's fine
- ... If we couldn't have that dispatch context because resize observer, depends on layout, can trace what causes a particular layout / resize / intersection change
- Yoav: Intersection Observer also maybe
- Benoit: Meta tried to do some tracing similar for perf analysis
- ... React and other frameworks will just batch work
- ... Async context becomes useless
- Nicolo: Framework have to use API when batching contexts
- Yoav: What I see in Soft Nav and Task Attribution, that batching happened with postMessage() or functions that contain the context
- Michal: Userland task scheduler
- NoamH: Not a consistent batching, depends on device
- Benoit: React tree, marked as dirty, not until you reconcile what's dirty. 20 setStates. Unless you reconcile 20 times, you do it in one step.
- ... We detected that we merged
- Nicolo: Userland batching, does not say how to merge multiple contexts
- Justin: If component A has a setState, component B, each capture their own context
- ... Whatever work you want to do for A, when B is done, can restore context and do work
- Benoit: Shared descendents
- ... Don't know what's responsible
- Justin: Left for React to decide
- Benoit: Should be investigated, I'm not sure there is a good solution to that
- ... Merging happened on home feed load, those two contexts would cross immediately
- ... "contamination" when they'd get merged
- Nicolo: Very specific to how you're using async variables
- Benoit: Interesting problem, but potentially blocking if no great solution
- Andreu: Very common problem, gets batched into next tick.
- Yoav: Great to have implementation experience in userland to review spec
- Benoit: Raise github issue?
- Andreu: Yes in TC39 org
Recording
Agenda
AI Summary:
- Discussed goals for Container Timing (CT): measure initial paint of DOM subtrees (e.g., carousels) without counting subsequent visual updates, via a new `"container"` entry type whose start time reflects initial paints of its elements.
- Compared approaches for defining containers:
- Attribute-based (`containertiming`): simple, 1:1 DOM→container mapping, but conflicts with multiple scripts / observers and implies “modes”.
- Selector-based via `PerformanceObserver` options: more flexible (subtrees, multiple observers, ignoreSelectors), but potentially high bookkeeping, memory, and selector-matching cost.
- Declarative `containerRules` manifest in the document head: enables early registration and buffering, supports mixing with imperative APIs, but adds JSON-like configuration complexity.
- Debated dynamic vs. static registration: early declarative rules enable buffering from first paints; late observer-based registration can only see events from registration onward unless the browser stores per-node paint timestamps (high cost). Consensus leans toward early preregistration plus limited dynamic extension.
- Shadow DOM considerations: want CT support; open roots expose internal elements; closed roots expose only hosts (with true size). General sentiment that attribute-based approach and/or simple rules should work, similar to Element Timing, and that Shadow DOM support might not require full container rules complexity.
- General direction: prioritize simple, attribute-based CT (possibly with a minimal manifest / rules layer and limited selectors like ID/class), run an Origin Trial to gauge real-world use cases and demand, and avoid over‑engineering selector/manifest systems unless clearly needed.
Minutes:
- Jase: element timing allows us to measure individual elements.
- …
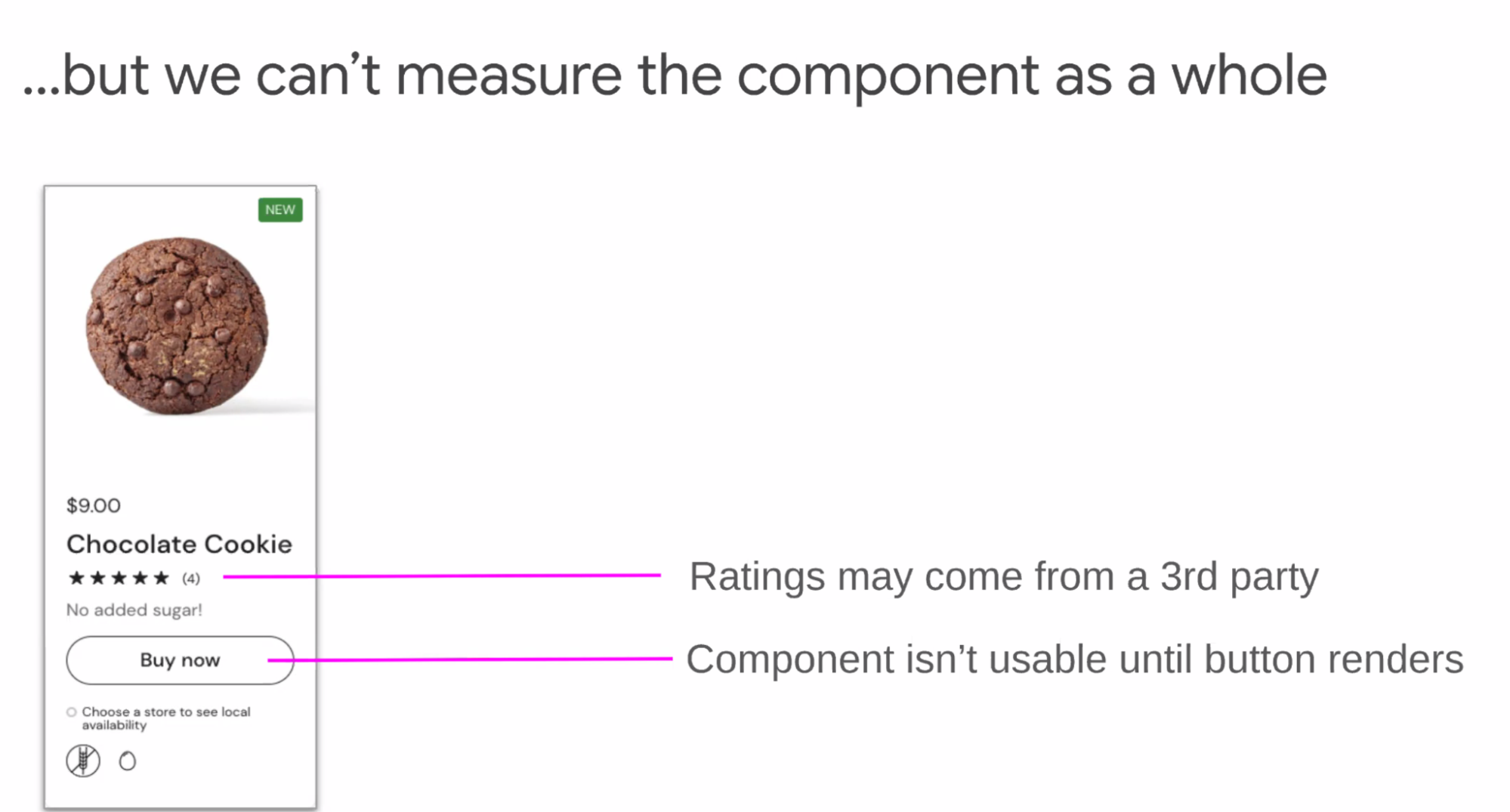
- … but we want to target a subtree in the DOM and have it tell us when the initial paint event happens
- … If we just look at paint events we’d get containers that update forever
- … We started by using element timing on all the things, but continued to get entries coming through
- …

- … Imagine a carousel - a carousel update wouldn’t count as a fourth entry
- … So this enables us to know when the initial paints are done

- … new entry type “container”, start time is when each of the elements painted
- … how do we define containers to keep track of?
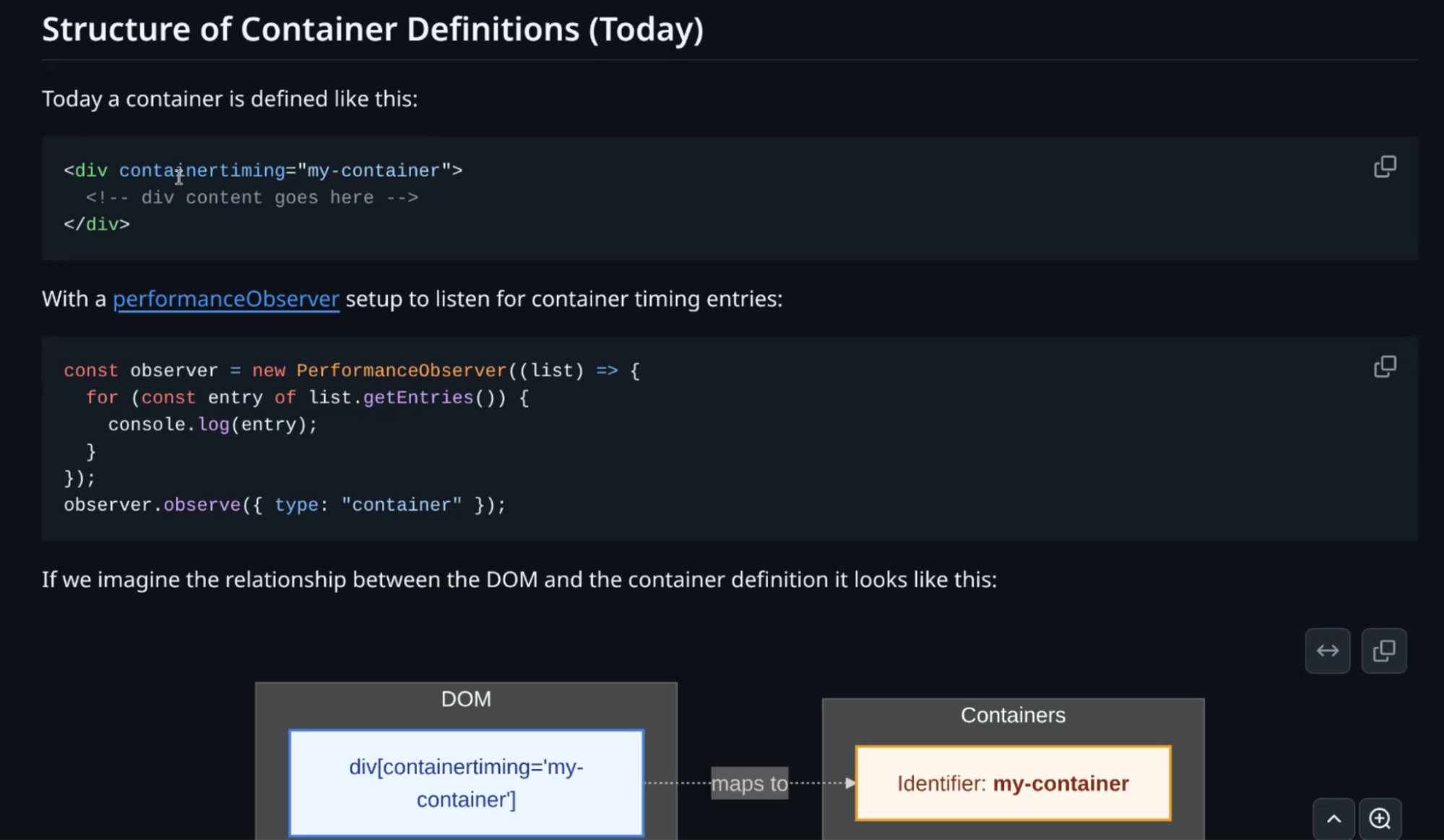
- … today it’s attribute driven - containertiming
- … limitation - 1 to 1 mapping of DOM to containers
- … One container per element, multiple scripts tracking the same entries will override one another
- …
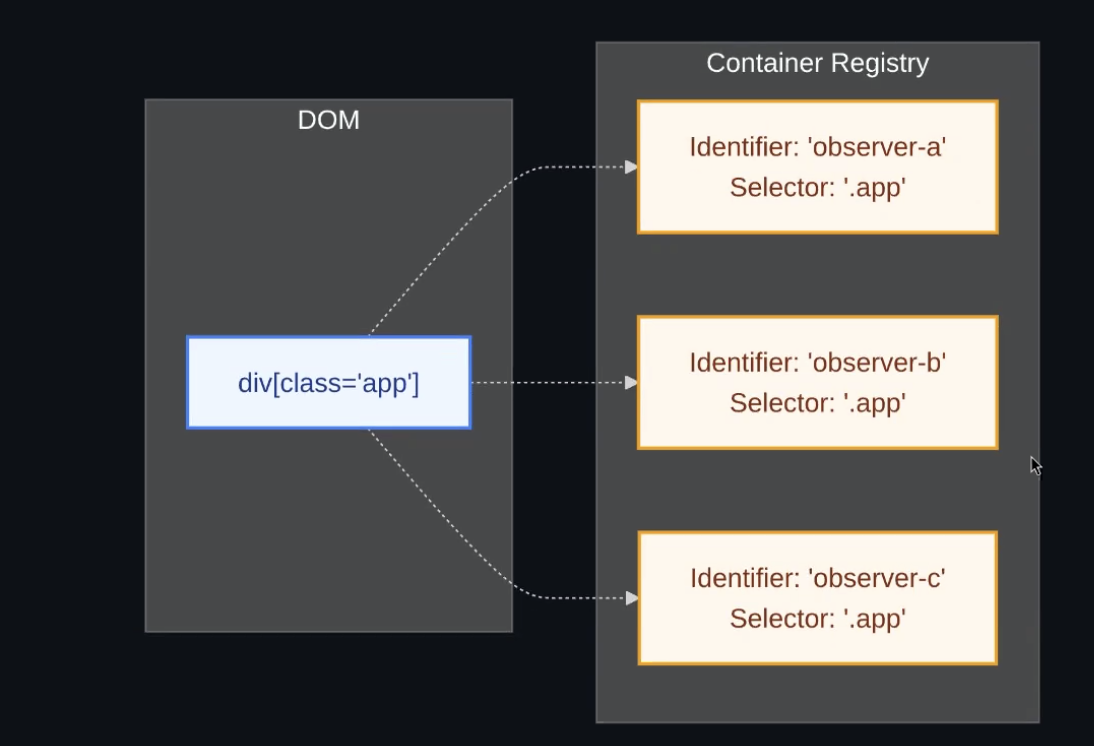
- … Can have 3 different observers watching the same subtree
- … Pass a containerDef to the relevant performance observer, using selectors
- … Challenges with dynamic registering - with this model we don’t know what’s the container until we start observing. There may be more accounting work with this model
- … option 1 - get rid of nesting modes as they make less sense with observers
- … we also had shadow mode that didn’t propagate information from inside the tree, but shadow DOM can do that
- … may want to ignore parts of the DOM, so maybe can pass ignoreSelectors
- … Problem is still that the browser has too much accounting work to do
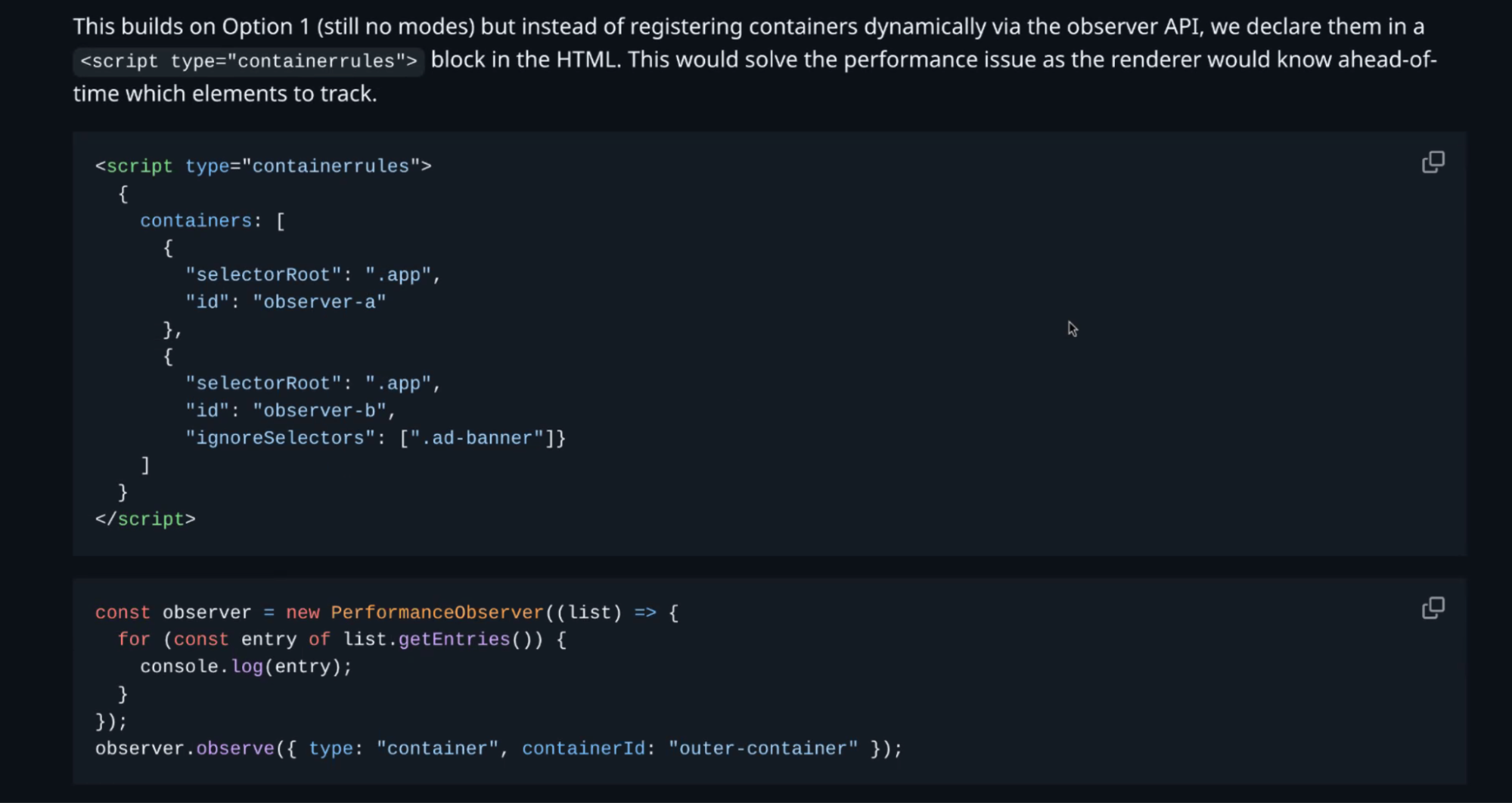
- … option 2 - define containerrules in the head that tell the browser what it needs to do
- … option 3 is keeping things as is
- … shadow DOM is something we want to support, especially if we get rid of nested modes
- … open roots show all the elements inside the root
- … closed roots only expose the host, other than size which is the true size
- … May be OK based on past conversations on element timing
- NoamH: You mentioned high memory for the selector based option. Would there also be a performance impact as well?
- Jase: yeah, I’d expect that
- Michal: Selector matching is the concern?
- NoamH: yeah
- Michal: When you measure a contentful paint you already have the data. You just need to check against a list of selector
- Yoav: Could have parent selectors, need to take count entire tree
- ... Run through exercise N times, number of registered selectors and paints
- Michal: Depending on complexity of selector and DOM
- Bas: Bookkeeping becomes more complicated for all cases
- Yoav: Writing to book
- Bas: If it can be added after the fact, treat every element as candidate anyway
- Yoav: Applied after the fact does it apply?
- Michal: ET, opt-in for measurement, opt-in for buffering
- ... for CT, you have manifest up top, so early manifest, apply tests along the way
- ... Another version is late register, the browser may have a memory of what happened, what's on the DOM right now
- ... What's been painted already/now
- Yoav: For every node, to keep a timestamp of when contentfulness happened
- Michal: Depends on if we want to rebuild filmstrip of history
- Yoav: If arbitrarily adding containers, and need truthful answer of when pained, need to know when it as painted
- Michal: Manifest would be useful
- ... Other version of CT, I'd like confirmation if it's painted
- ... Any subsequent updates you'd have timing info
- Yoav: Declarative part, with similar things, import maps and speculation rules, you can inject dynamically
- ... With those container rules, are they only static or you can inject dynamically, what would happen
- ... Maybe ignore everything dynamic and only read when static
- Jase: Undefined, want to bring up with group
- ... How would we deal with making these dynamically add a container later
- ... Inject or add w/ script tag
- ... Statically declared and that's it
- ... Register a container later on
- Dape: Important to preregister things
- ... Known when element is created is that it's important for timing
- ... Rules in header (or ahead of time) so we can do buffering, for paints, before registering Observer
- ... We could take a mix of options 1/2
- ... ContainerRules but inject when we're ready when nodes are created
- ... When wanting to register new observers, an API allows to add more container rules
- ... Not just declarative way
- ... Another idea in Option 3, we can have more than one tree of Container Timing roots
- ... Another observer has a different view, part of specific subtree
- ... Getting a paint knowing it's affected by a selector, need to know an element is a descendent
- ... Selector could match more than one element, for all nodes of a class are painted
- ... Can explode very easily in memory, opt-in
- ... Number of events we generate could be problematic
- Jase: You would need to store a timestamp, for every element in order to build a filmstrip
- ... You have everything from beginning, if you observe dynamically, you only get events from that point onwards
- Bas: Only option
- Yoav: Agreed
- ... When it sees containerrules script, buffered from then on, but not before
- ... For a RUM provider, it's the site that would be responsible what need to be observed
- Bas: My feeling is that not a tremendous amount of appetite for random JSON
- Michal: One problem with attribute-based approach, implying mode
- ... Maybe just 'containertiming='
- Yoav: You still need to define something else to get it
- Nic: It would start tracing of it
- Yoav: Any specific selector is bad from a footgun
- ... ID, class only?
- Michal: Can you understand why you need selector
- Yoav: IDs and Classes are highly optimized
- Michal: In terms of manifest, there's another part of this where components are dynamically injected, container roots auto-track
- ... PerformanceObserver having a selector, option 1
- ... Reason we choose a selector in this one, why?
- Jase: Sometimes JavaScript can be setup before DOM has been populated
- Noam: Start observer based on some interaction, wait for future
- Michal: Can set either attribute, or MutationObserver, or the script that dynamically updates the page, registers
- ... vs. asking observer to be dynamic
- Noam: Not typical use of Observer
- ... Usually what's passed in observing is a simple option list that describe behavior
- Dape: In the end, one of the good things of the attribute approach is it's pretty simple
- ... For knowing which elements are interesting for Container Timing
- ... Having an idea that some components provide Container Timing information
- ... Provide this-and-that data for CT
- ... Problem is the ID
- ... If we could still go with an attribute approach, see a way to get our CT root node if needed at a later point
- ... IDs are still a way to know info about nodes
- ... DOM nodes that don't exist anymore or have been removed from the tree
- ... Still see value here
- ... I would see someone having different effects in element that you can paint or has elements that paint inside it
- ... Complexity of tracking rules is difficult
- ... We can have some different views of tree, container root elements, have option
- ... Have attribute way similar to element timing
- Bas: Not sure I'm a fan of multiple ways of doing it
- Yoav: Question to Jase, from your use-case perspective, are attributes enough or do you need more sophisticated registration, multiple containers scenarios
- Jase: Our use-case, attributes are enough
- Yoav: Question are there other use-cases in the wild?
- ... Origin Trial can weed these use-cases out
- ... Maybe: One declarative, one imperative, that's reasonable
- ... We need to solve Shadow DOM for Element Timing anyway
- Michal: Can't measure the performance of components
- ... One use-case
- ... Container Timing it'll become increasingly simple and common to ask for whole trees of things
- ... Where they carefully control their component it makes sense
- ... Other complicated case is dynamic elements inserted into page and markup, you have a new observer and give a custom name, fairly complicated
- ... Would be easier to say I want to wait for specific things
- ... Problem is late registration affects
- ... If we had buffering, would be better
- ... I don't know how much contentful elements above the fold are measured
- ... How many truly contentful elements do you need to keep track of?
- Bas: Need to construct number at container level
- ... Need to track at all elements and store that information
- Michal: If you had a contentful text trigger and it was 10px, maybe we ignore
- Bas: In order to save space?
- Michal: Bunch of things where we overflow buffer
- Yoav: I think we need to anchor to use-cases
- ... Shadow DOM is important but it doesn't necessarily require all these container rules
- ... Could solve within Element Timing w/out this
- ... Just a matter of reaching a decision on what we should do
- ... ElementTiming is under-used
- Michal: 2.2% of navigations
- Bas: I would expect more demand for Container Timing than Element Timing
- ... Sympathetic to do simplest thing first, and gauge demand
- Yoav: Origin Trial simplist
- Guohui: Explainer for every painting update PE is generated, and for an update, there can be multiple links, makes sense. lastPaintedElement, records last, why we keep all the regions, but only keep the last element there.
- Jase: We are tracking all elements, when we first did the prototype, we had an array of all elements that had a paint, it wasn't that useful. One of those elements would be OK. Up for discussion
- ... Internally everything is taken into account, last is just what is surfaced to developer
- ... OT is the simplest option
- Yoav: Good options, but a lot more complexity
- ... Want to make sure it's absolutely needed
- Bas: Prefer based on classes vs. CSS selectors
Recording
Agenda
AI Summary:
- Defined “Unattributed Navigation Overhead” (UNO) as the gap between the sum of Navigation Timing phases and TTFB; in practice, large UNO is often caused by cross‑origin redirects that are currently hidden for privacy.
- Case study: Akamai used UNO and RUM data (e.g., `utm_source` parameters) to identify slow ad/traffic providers and improve their performance, showing real‑world value in exposing redirect‑related delays.
- Discussion on privacy vs. usefulness: current obfuscation doesn’t truly hide redirects (they can often be inferred or seen by the unloading page), yet it blocks precise attribution for performance engineers; high UNO (>100ms) is reported as ~99% first‑view redirects.
- Explored options to expose redirect timing more explicitly and/or probabilistically (e.g., WebKit‑style Option 2, aggregate or eTLD+1 reporting, coarsening, differential privacy), while considering attacks like inferring login state from timing.
- Consensus themes: redirects are already observable in various ways; pure opt‑in is unlikely to see adoption; need a solution that gives performance engineers aggregated/approximate redirect timing without materially increasing cross‑origin privacy risks, with some issues to discuss with WebAppSec (e.g., unload behavior, paint holding).
Minutes:
- Tim: About unattributed timings in NavTiming
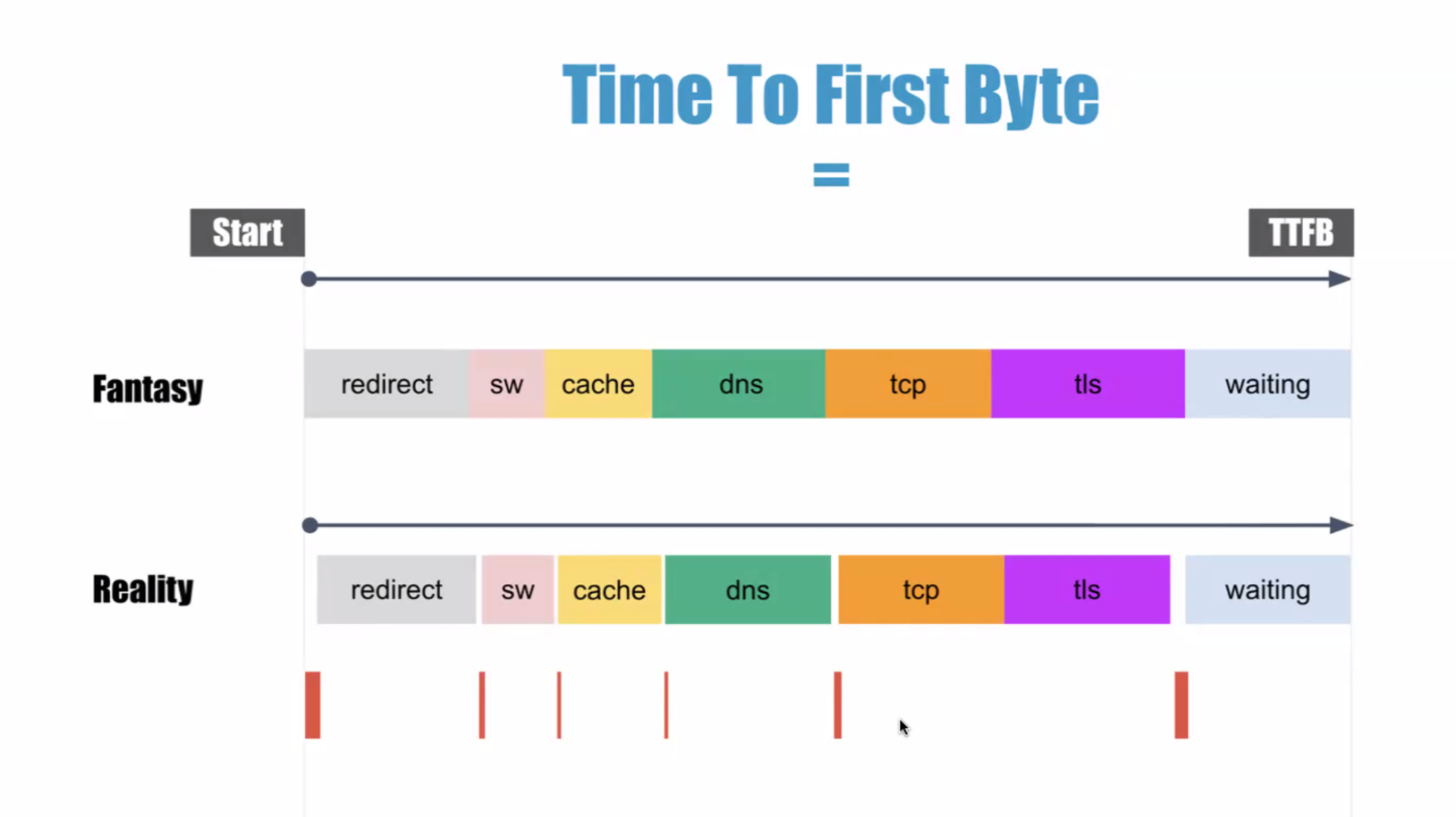
- ... between steps there are certain gaps
- ... We created a new timer that is the sum of all of these gaps
- ... Unattributed Navigation Overhead (UNO)
- ... Take sum of all phases, subtract TTFB, what's rest is UNO
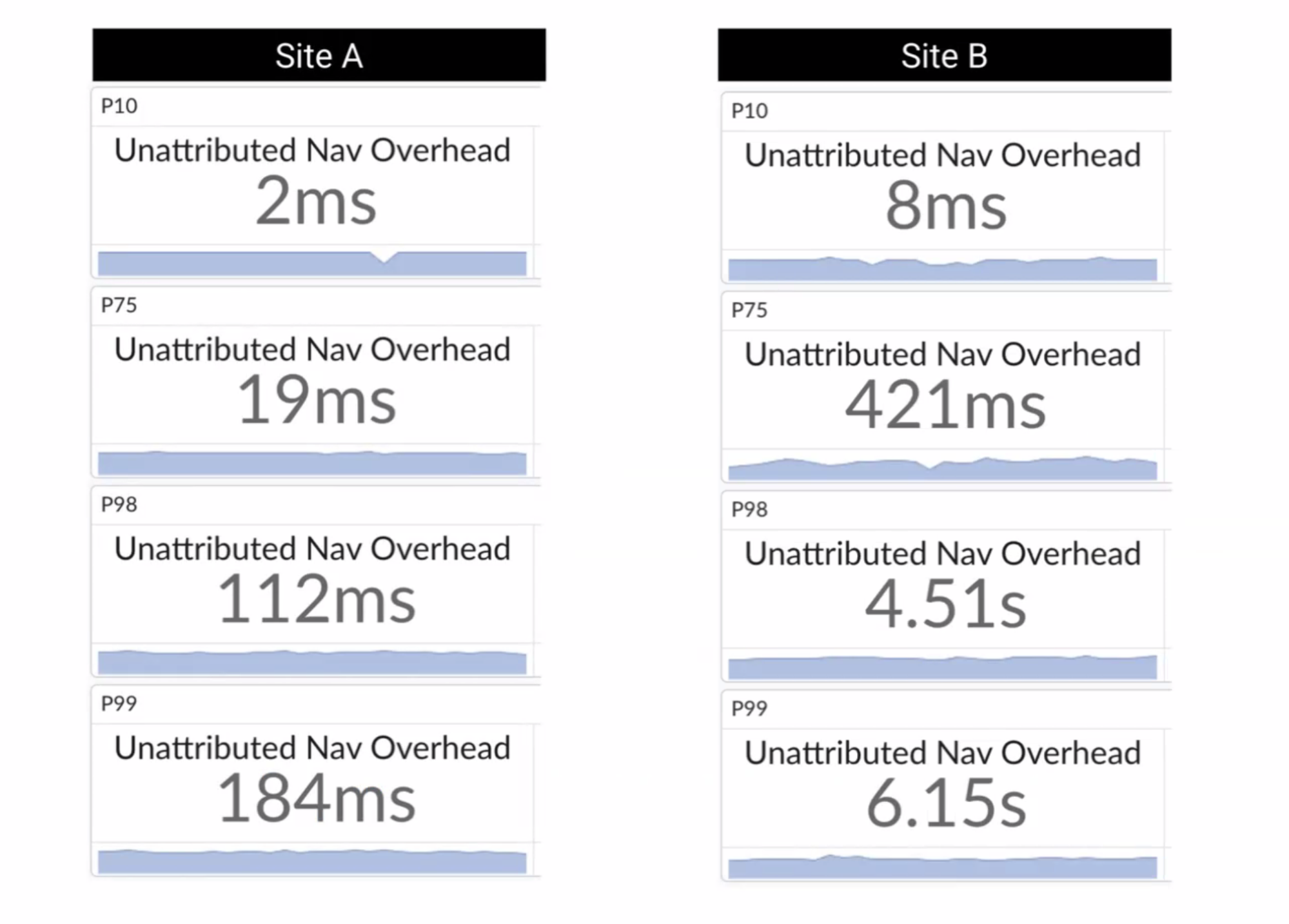
- ... Smaller site vs. larger site, UNO can become substantial
- ... Site came to Akamai, said TTFB was high
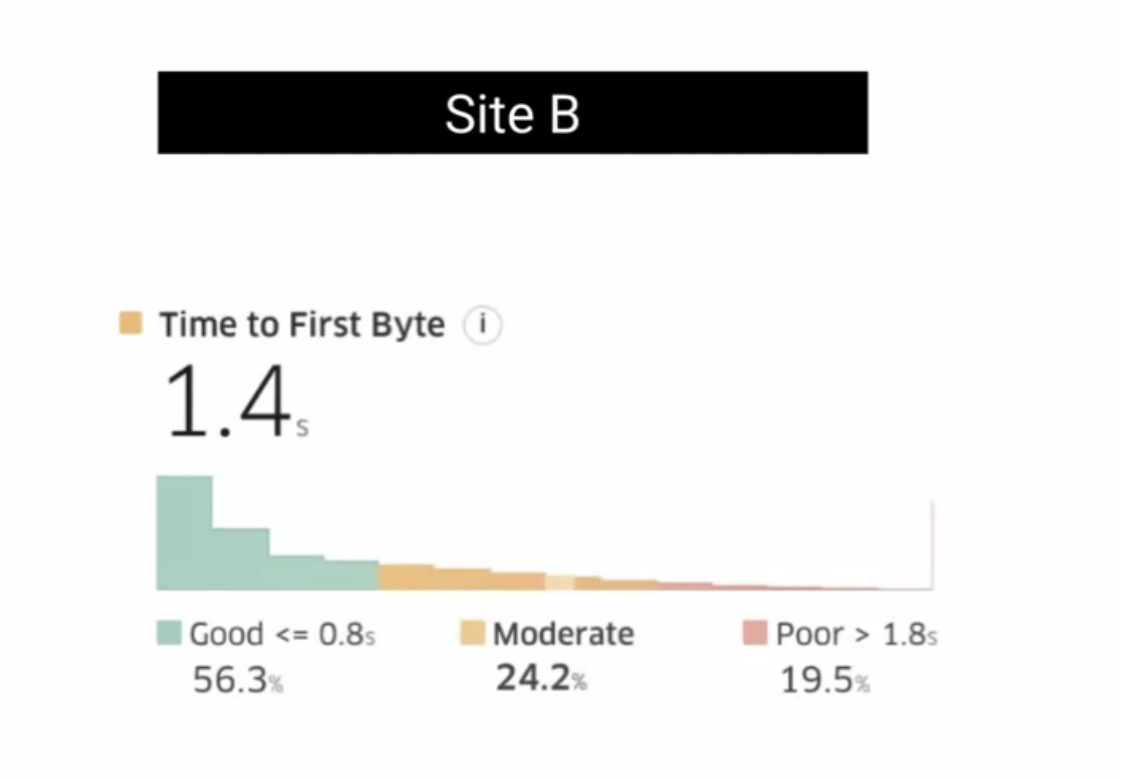
- ... Was not origin, CDN, security, etc
- ... We noticed it was cross-origin redirects
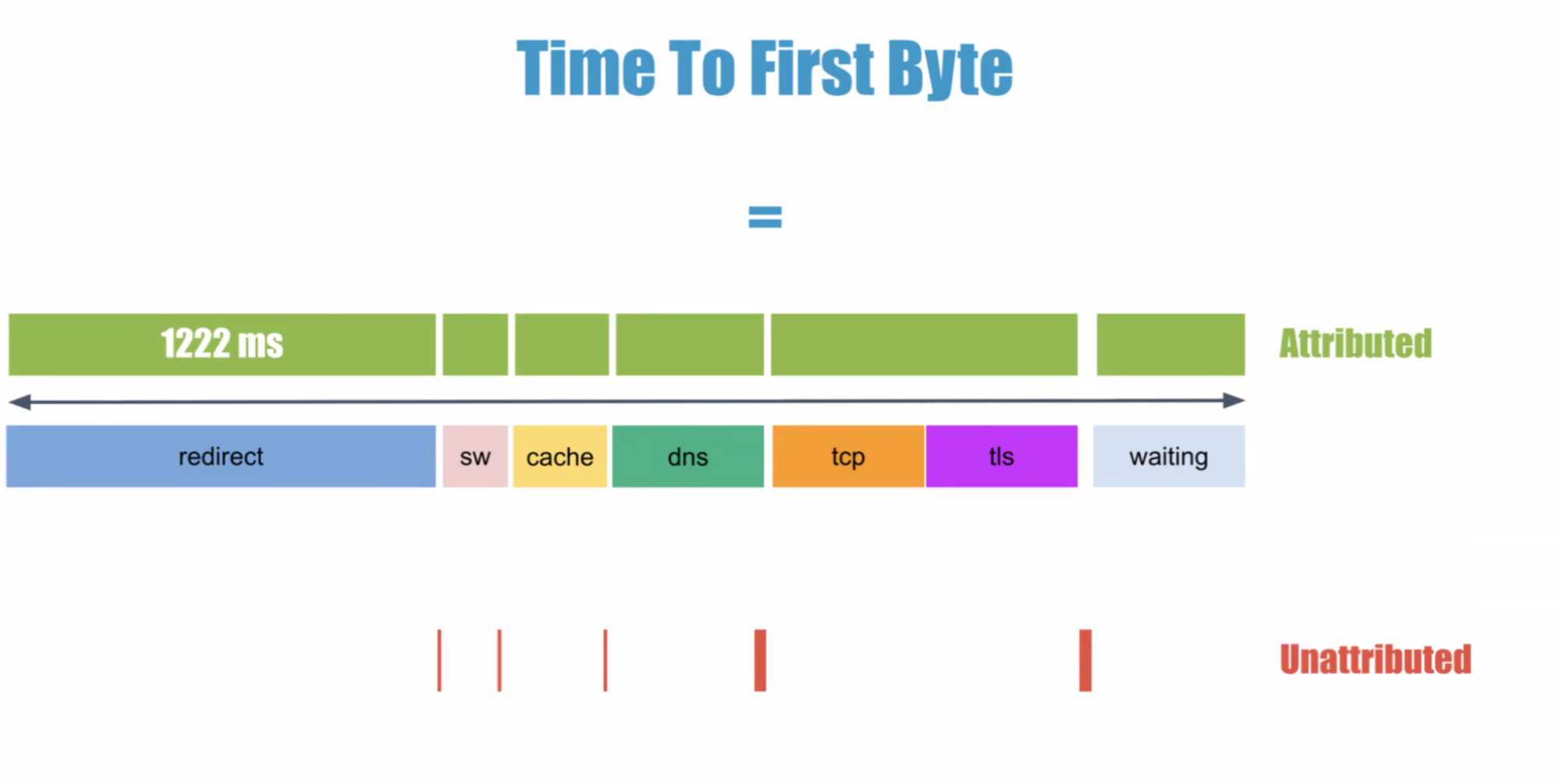
- ... 1222ms attributed to redirect, for privacy reasons it's not
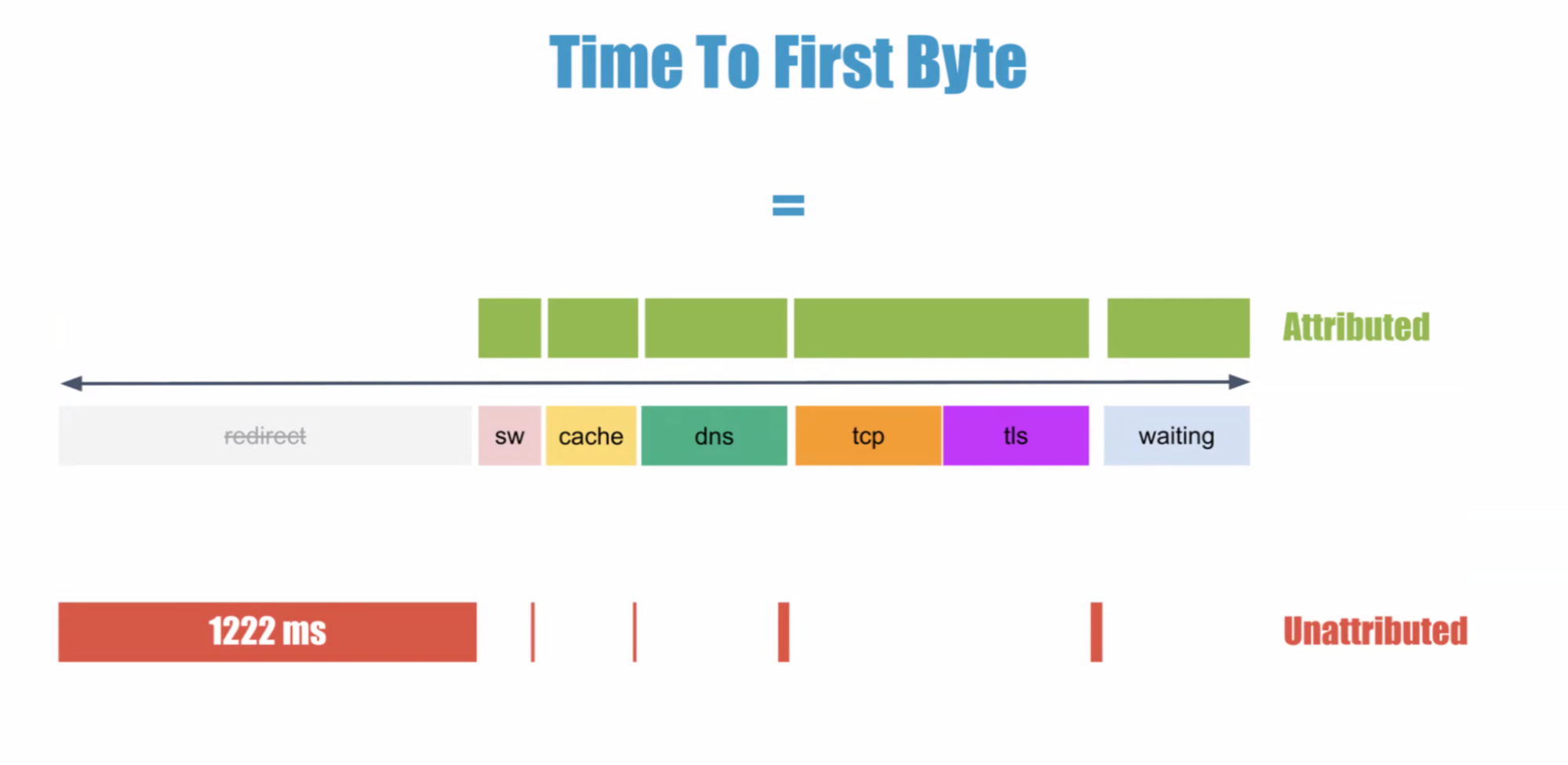
- ... What we also did is checked in RUM what was the UNO how it was linked to different sources
- ... Based on ad provider or how traffic arrived, some providers had issues
- ... We used this data to speed up some of those providers
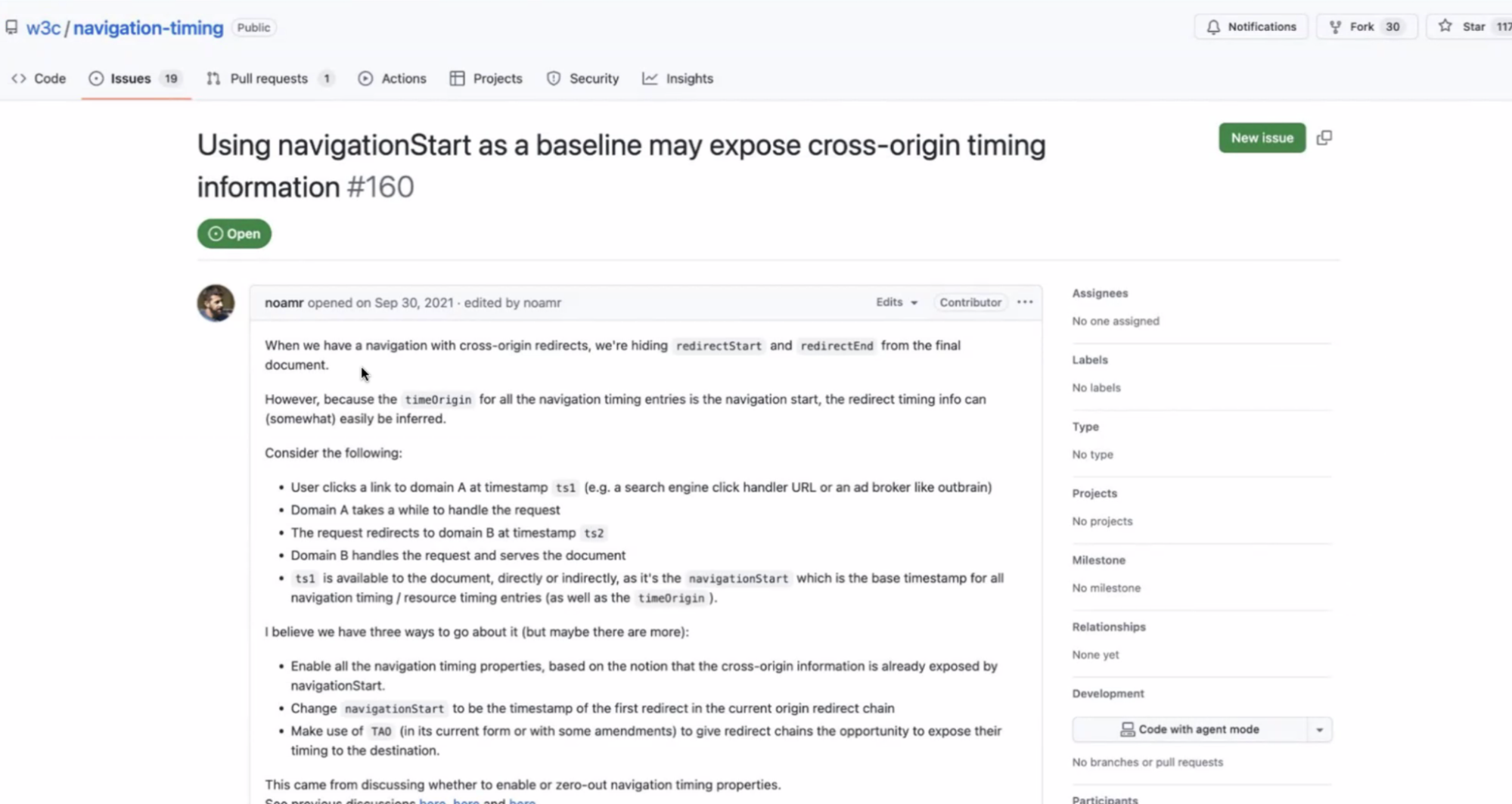
- ... Noam came up with a few suggestions
- ... Currently data is not there for privacy reasons
- ... You can already see it's a redirect, if it's so large you can tell it's a redirect
- ... You could also change navigationStart, but you're then changing user experience
- ... Once we did this, ad providers have zero triggers to improve their performance

- ... UNO time is so big, people look at the wrong direction
- ... You can deduct it anyway
- Yoav: I believe that Webkit are currently doing is Option 2?
- Alex: I think navigationStart is the end of the cross-origin redirect chain
- Yoav: On one hand we're pretending they're not exposed elsewhere, false. On the other hand, perf engineers need to do their job. That triggered me to revisit 160. Last week at perf.now() Harry Roberts discussed a case that was very similar
- ... Real-life problem we need to solve
- ... We're not providing privacy guarantees we want to provide and we're also not providing performance metrics we want to
- ... Thing encouraged me is you were able to find culprits from Referrer info
- Tim: Correct
- Yoav: Redirects can have referrer policy and that would make it a blackhole
- ... We could do some server-side split
- Tim: We didn't get from referrer, as it's empty
- ... Very often ad campaigns, UTM query string parameters added, which is visible client-side
- ... If you see utm_source, and UNO is high, you know where they come from
- Bas: I feel like we had this discussion last year
- Yoav: We need to reach some conclusion
- ... Discussion last year was theoretical, we have real-life cases information being useful
- ... Relying on utm_source is not exciting
- Noam: Possible to generalize, since redirect is a known issue, just inferred?
- ... Do we have data to back this claim?
- ... 500+ms is likely a redirect
- ... Is that really true?
- Barry: You had other things in UNO, is it 99% redirects
- Bas: Further down timeline, there's other things
- Yoav: This is up to TTFB
- Tim: What I see on our side, other sites, below 30ms it's a sum of the little things. But over 100ms, it's always the first page view in a session, and 99% it's a redirect
- ... Which we can't do anything about it
- NoamR: fetchStart-startTime, you get redirects
- ... Close enough approximation
- ... Obfuscation is not doing anything
- ... Are we OK with exposing this redirect that doesn't belong to us
- Yoav: Talking about navigation confidence on Thurs
- ... Breakout this morning about ad-related attribution aggregation, devolved into some sort of probabilistic reporting, differential privacy
- ... One way to solve this is to align on Option 2, align with WebKit, expose redirect time through some probabilistic mechanism that for a single user you have no idea
- ... How would you split by utm_source then?
- Bas: I wonder if there's not origin, but eTLD+1 reporting
- ... A lot of redirects that are under control
- ... Those are common
- Barry: What is the risk and can we get around it by coarsening?
- Bas: Situations, depends on the network the user is on
- Yoav: Unless you coarsen everything to 0
- Michal: Asking what you're leaking?
- Barry: High resolution timing the problem, or that there was a redirect
- Yoav: Attack vector, user is logged into X, redirect to that takes longer, allows you to know about their login state
- NoamR: That entire time is visible to unloading page, because they know when the button click timestamp is available, know redirect
- ... When page unloads is fetchStart
- ... Navigate event starts before redirect
- Yoav: If a.com navigates to b.com and redirects to c.com, does a.com see timing?
- NoamR: Yes
- ... old page knows this already
- Bas: Sending page has more control over where they're going to
- NoamR: Attribution of this time, the exit music time is unattributed, belongs to old page somehow, we're attributing it to new page as TTFB
- Michal: For Soft Navs, that outgoing page gets an INP, it doesn't include async effects, but it prevents new navStart, responsiveness problem of outgoing page
- ... Maybe we have async interaction responsiveness, it's to unload, but if last interaction if it takes 2s before it starts loading, it's a problem for either
- Alex: What if there's no sending end, example.com/redirect-to-website
- ... Exposes time right?
- Yoav: Yes
- Nic: isn’t this the responsible of the website that sends you to redirects
- NoamH: lots of auth is based on redirects
- Bas: Lots of cases where the page redirects you to a part of the URL
- Michal: you put a poster to visit a URL that shortens the URL, that’s your domain
- … OTOH, if you right click from social media, that adds a redirect wrapper
- Yoav: From receiving end it's the same problem right?
- ... You just don't have utm_source
- Bas: The unload handler should fire as soon as first non-same-origin response is received...
- Yoav: What if chain ends with 204?
- NoamR: Web-breaking
- Bas: Obvious solution for other side of problem, is same-origin
- Barry: Happens a lot, HTTP to HTTPS, maybe small redirect
- Tim: From HTTP to HTTPS, or from www to non-www, typically 100ms redirects
- ... Very small portion from inbound advertising campaigns
- Bas: Cross domain redirects?
- Tim: Yes
- ... Won't solve problem of seeing huge UNO values, don't know what's going on
- NoamR: Recourse is doing an opt-in sharing but it wouldn't get adoption
- Yoav: Opt-in won't get adoption
- ... We need to find a way to expose info in aggregate in a reasonable way
- ... Redirects are already exposed and we can't fix that, what would be privacy impact of doing that work instead of just exposing them
- ... Anyone that wants to bounce the user through a cross-origin
- Michal: When do we start paint holding
- NoamR: After request start and before first render
- Michal: Visually you wouldn't notice the difference
- NoamR: Bigger problem because of unload, take with WebAppSec
Day 3
Recording
Agenda
AI Summary:
- Proposal: a new static, CPU-focused “device performance level” API that exposes a coarse bucket (e.g., 1–4) indicating how powerful a user’s device is, to let sites adapt content (ads, animations, media quality, third‑party scripts, etc.).
- Design goals: simple, implementation-defined buckets that can grow over time; no active benchmarking; CPU-only; low‑entropy to limit fingerprinting compared with richer shapes (like arrays or many dimensions).
- Discussion on extensibility vs. fingerprinting: suggestions to use arrays or more granular/multiple metrics were pushed back as they increase entropy; some argued for adding new separate APIs in future rather than baking extensibility into this one.
- Interoperability concern: if different browsers choose very different bucket counts or semantics (e.g., 4 vs. 64 levels), the API becomes hard to use; several participants argued that the number and meaning of levels should be standardized or at least comparable across engines.
- Broader context: parallels drawn with Device Memory, Network Information, hardwareConcurrency, and the deprecated Battery Status API—highlighting tension between usefulness for adaptation and risks of fingerprinting and long‑term obsolescence if over‑ or under‑standardized.
Minutes:
- Nikos: API to expose to webapps how powerful a user device is
- … motivation is to adapt web content based on performance information
- … use cases: control non-essential tasks (3P scripts, heavy libraries), adjust the complexity (lower video quality or no video, no animations)

- … RUM dimensions, client-side vs. server-side
- … Select ads that are better suited (format and content)

- … “fast” today will be “slow” tomorrow (or for another type of application)
- …


- … Related API: device memory (static), compute pressure (dynamic)
- … This is about: just CPU, static, safe
- …


- … As time goes by, more buckets will be added
- … Exact mapping is implementation specific



- … static, no benchmarks, stable buckets over time and only considering CPU performance

- Guohui: have you considered an array instead of a single number? In the future you could have one device more capable than others in certain tasks
- Nikos: so the array would contain different type of performance? You could consider CPU performance as the first element of the array
- … The problem with an array of numbers is that it gives more bits for user fingerprinting. So we started simple
- Gouhui: An app can take the first item of the array, but it would leave room for future extensibility
- … Maybe we could have added another element to DeviceMemory instead of a new API
- Barry: why do we need to overcomplicate this one for future use cases? We could just add new things
- Dominic: Want to avoid userland categorization at the platform level
- Justin: The data you’re exposing. I want to know if the device is powerful enough to show animations. Hopefully targeting 60fps.
- … Would like to know more about how the device runs animations
- Barry: Buckets are 1 to 4
- Justin: So you need to decide how buckets translate to frame rates. Ok.
- Nikos: Each application needs to decide. The buckets should be enough for the application developers to make that decision. It should monitor its performance compared to the bucket, and then make a future educated guess
- Andy: There’s also Network Information API that’s in the same vicinity
- … We need to revisit the edges (e.g. DeviceMemory is max 8G). Needs to be a recurrent TPAC topic
- Barry: Made the spec deliberately allowed to add more categories. A browser could launch tomorrow with 56 categories
- Nikos: There’s some risk with different browsers using different levels
- Dominic: I’d expect the number of buckets to be fixed.
- Yoav: If Chrome has 4 buckets and Safari as 64, web developers will need to split by engine and CPU level
- Dominic: Would level 1 compare to max?
- Barry: Maybe we should expose the max
- Yoav: Max angle of this, but buckets are implementation defined
- ... Bucket 1 doesn't have fixed semantics
- Dominic: For it to be useful we need to know if 1 is equivalent
- Nikos: Problem with overstandardizing is with device memory
- ... 8 GB is upper bound
- ... Making API useless now there's more than 8 GB of memory
- ... If spec doesn't leave as implementation specific, there should be something much more flexible than device memory has right now
- Andy: I wouldn't bring that up as a downside
- ... I think we need to actively expand as things grow
- ... Spec issues around engines not being consistent
- Alex: Remember lessons of Battery Status API
- ... Use-case was very helpful in many cases
- ... Was used for fingerprinting
- ... Lots of aspects of performance, hard to put into a number
- ... hardwareConcurrency is already exposed
- Markus: HW concurrency doesn't say much these days
Performance Control and Cross-Document Reporting
Recording
Agenda
AI Summary:
- Microsoft presented an “IFRAME Performance Control” concept using Document-Policy plus Reporting API to identify and constrain poor performance behavior in embedded documents, starting with “network‑efficient guardrails” (e.g., enforcing compression).
- Goal is to give both embedders and embedded documents visibility into violations: embedders get high‑level “finger pointing” (which frame misbehaved), while embedded content can receive detailed reports about specific problematic resources.
- Reporting design questions: how cross‑document reporting should work (shared vs. negotiated endpoints, Required‑Policy implications), how much detail is safe to expose, and whether/when to use aggregation or probabilistic reporting to address privacy concerns.
- Policy dimensions under consideration include binary checks (e.g., uncompressed text), size/“oversized” thresholds, and future relative/usage‑based criteria (CPU, memory, share of overall network usage), while avoiding overly subjective or drifting definitions and cross‑origin leaks.
- Ideas like per‑iframe “network budgets” (absolute or percentage of page bytes) were discussed but considered tricky for privacy/timing‑side‑channel reasons; current focus is on simpler guardrails with fuzziness and limited developer “levers” rather than strict byte budgets.
Minutes:
- Luis: Performance Control we've talked about in the past
- ... Other names: Performance Control of Embedded Content, IFRAME Performance Control
- ... Identify and block performance impacting behavior in documents
- ... We have a lot of embedding scenarios at Microsoft
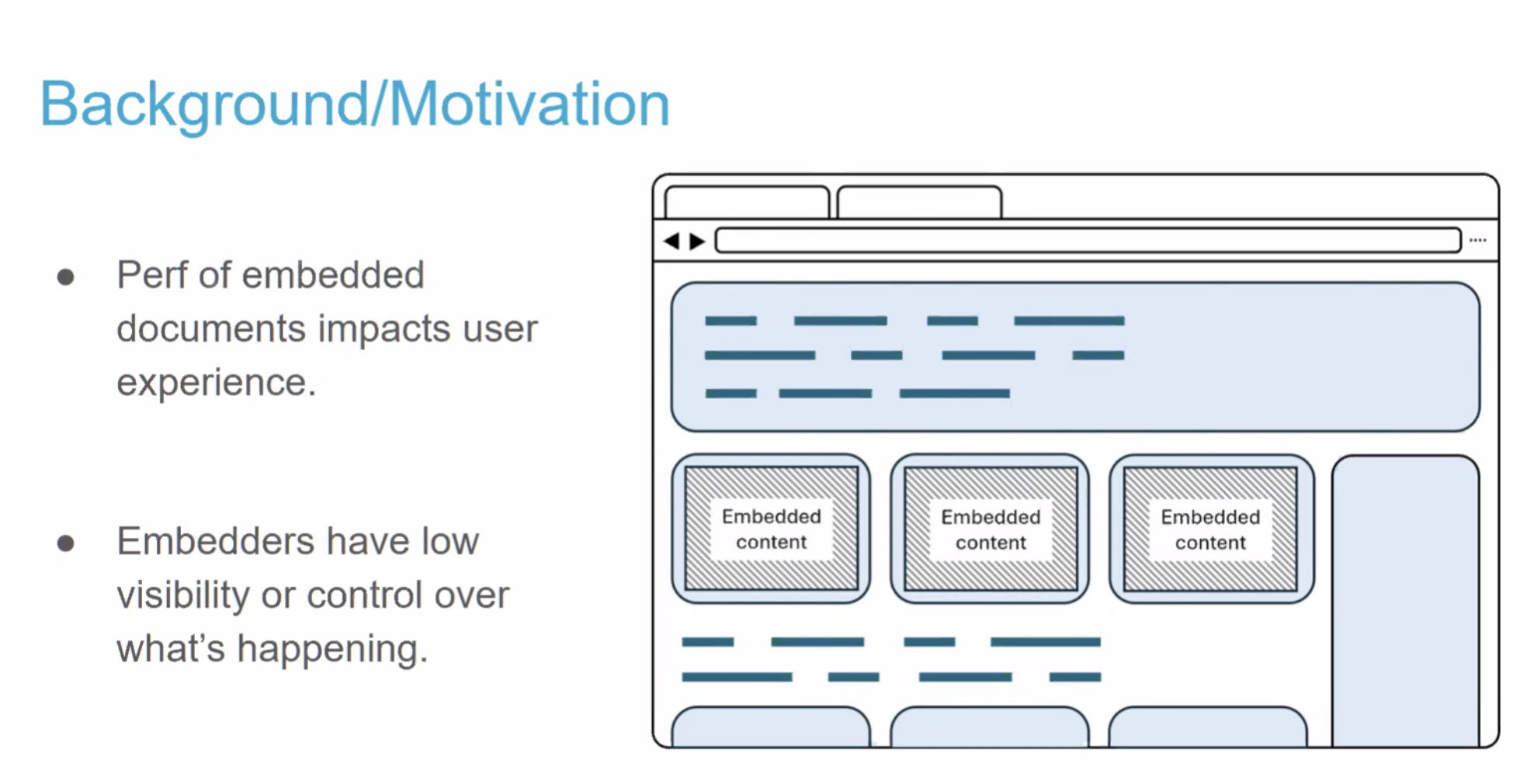
- ... Embedded documents have poor performance practices, hurt users
- ... Not a lot of visibility into what's going on in the wild

- ... Approaching this with different practices, put into buckets/policies
- ... Patterns we see at the network level

- ... Mechanism based on Document-Policy
- ... Reporting API integration for violations

- ... Prototyping on first category, Network Efficient Guardrails
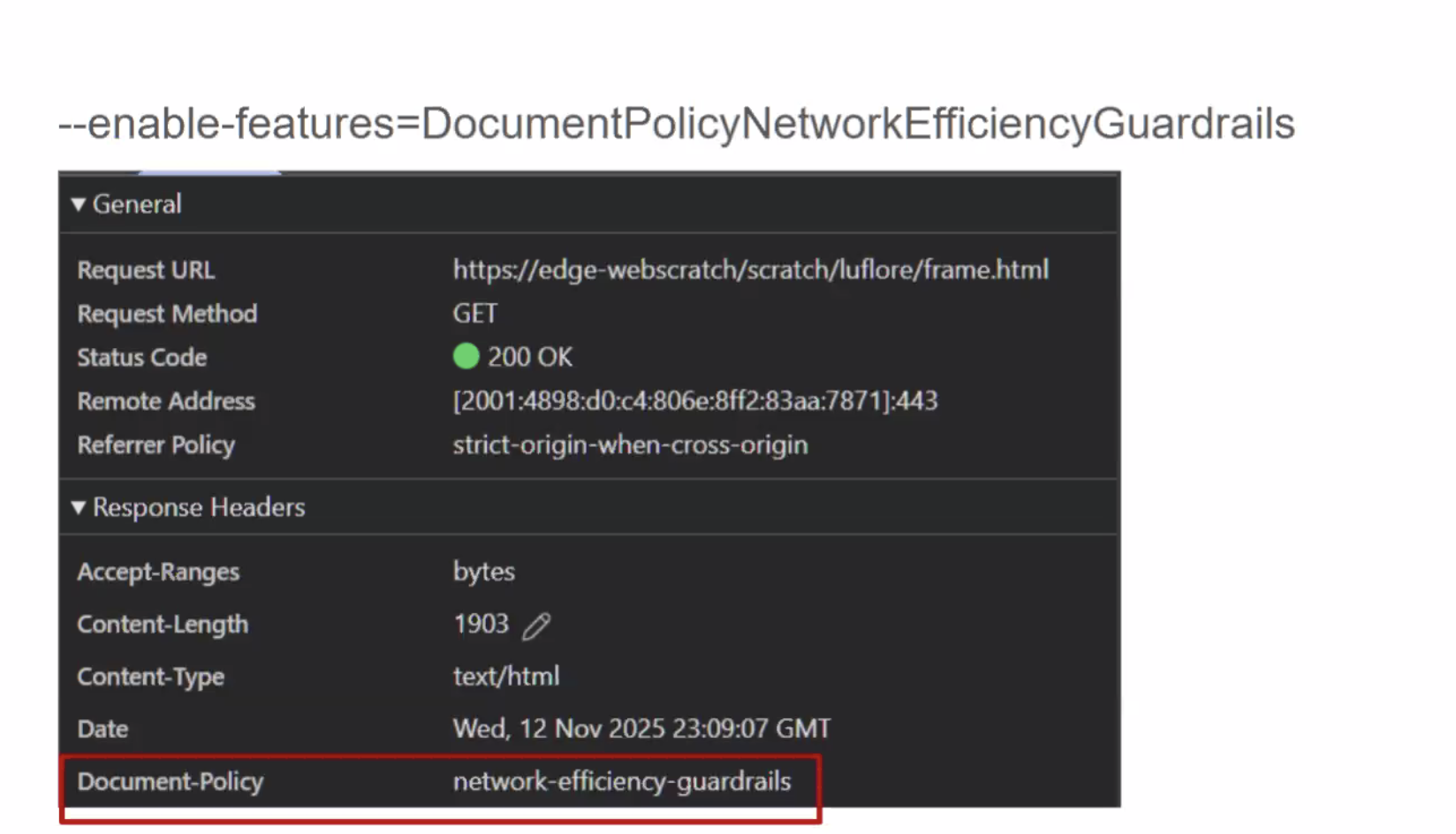
- ... Flag in Chromium
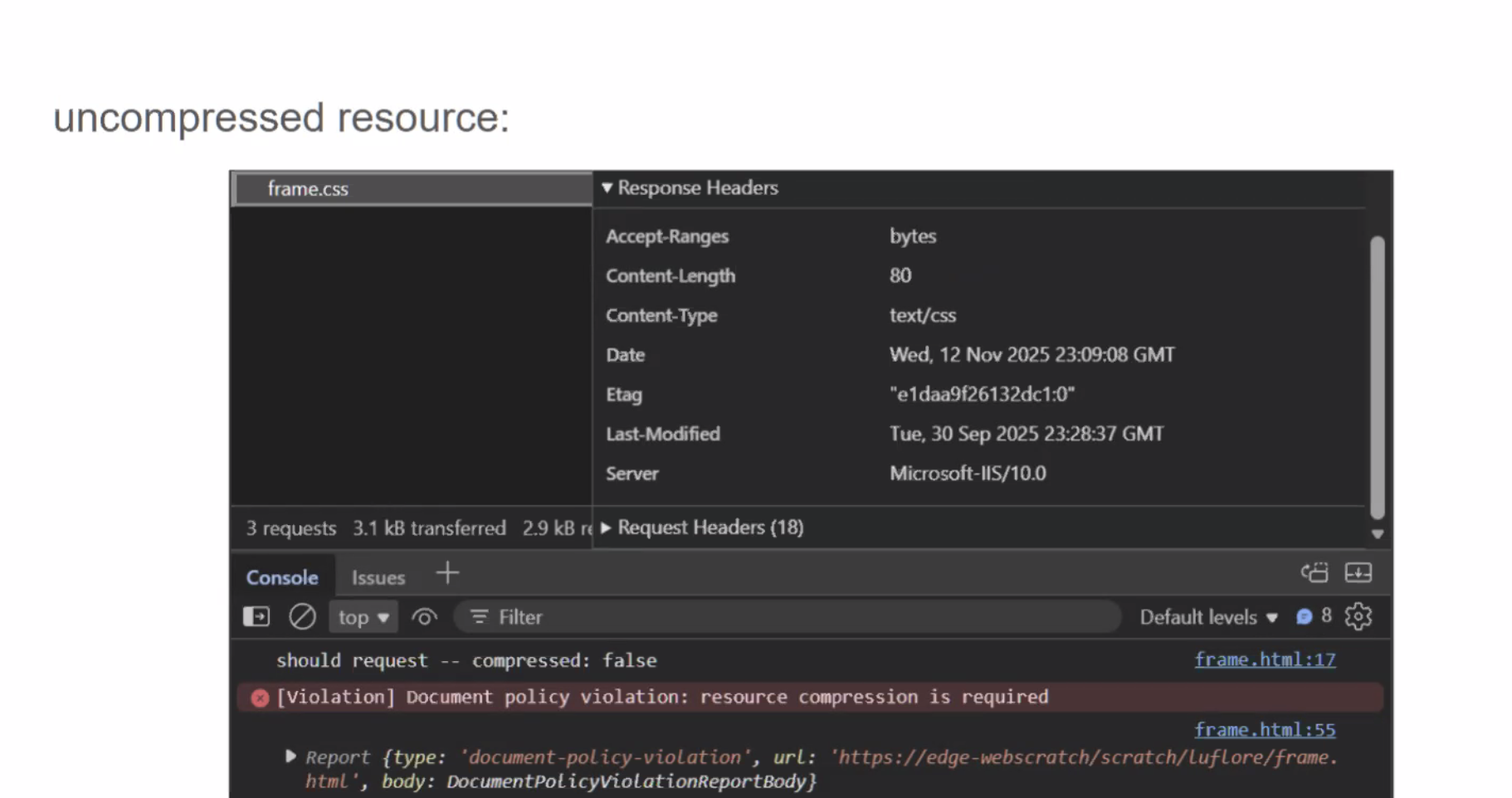
- ... Uncompressed violation results in a dev tools console report, plus Reporting API
- ... Because we care about embedding scenarios, we want info available to embedders
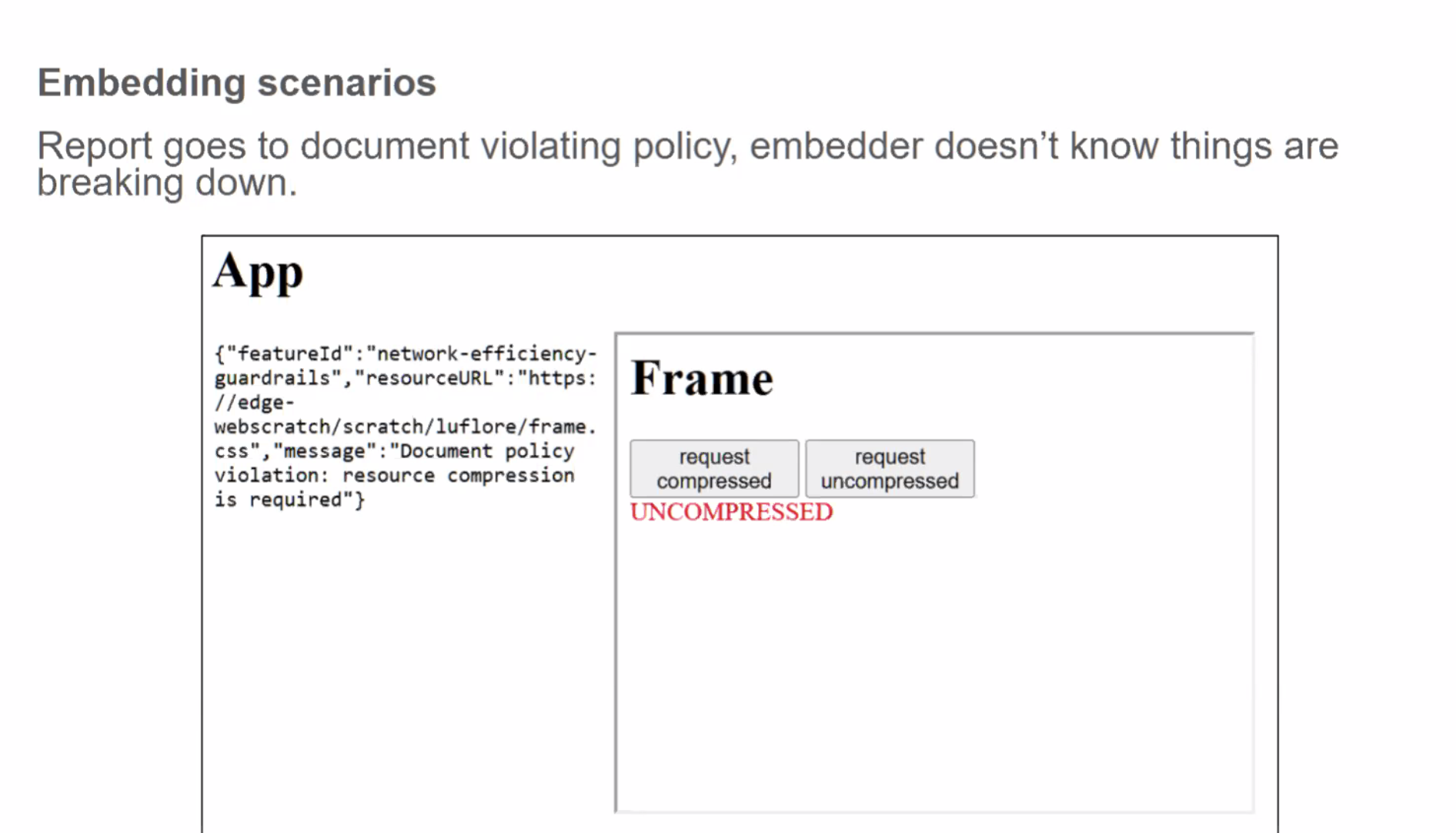
- ... Want document to know things aren't going well

- ... Documents available to get info in what's happening in frame tree

- ... Make Cross-doc reporting part of Required Policy
- ... When embedded document agrees to policy, it also sends it up
- ... Goes to reporting endpoint or setter endpoint
- ... Has to specify same endpoint, or it's implied
- ... Other approach is to have reporting negotiate separately
- ... Add a new header or mechanism
- ... Allow set of origins to receive reports to specify endpoints
- ... Something we might consider is what we want these reports to contain
- Ari: Great idea. A bit concerned about the Required-Policy bit where embedded iframes would just copy paste the embedder’s policy
- … Reports was mainly set up as means for the frame to send reports to itself
- Luis: Fair point. Discussed before what kind of information we want to expose
- … Maybe something similar to what CSP is doing. We want to give the embedder some notion that something went wrong. They set a policy, but the embedded docu
- Yoav: Talked about Network Error Logging this week. How we can further restrict the information it exposes in order to allow more browsers to adopt it within their privacy guidelines
- ... One of the principles we land on, is if NEL allows site-operator to point the finger, and not more than that
- ... If DNS issue, talk to DNS provider, but don't necessarily say exactly what went wrong
- ... Similar principle here
- ... You want frame name to understand what violated the policy, it's up to them to get reports getting more information about what went wrong
- ... Two kinds of reports: embedder reports, very little info, just the frame
- ... Embedded reports would contain the specific resources that had compression issues, what were those issues, etcetera
- Luis: Makes sense, one of the things we've been talking about
- ... As long as we have a way to point a finger, don't need full details of the violation
- ... One of the other things that's been mentioned in earlier discussions around this is aggregated reporting
- ... Not too familiar with what's already out there, we may not need for every individual violation
- ... As long as we know things are going on that we want to address, something that would help
- Guohui: Policy is requiring compression, it could be more useful, instead of blaming someone downloading a lot of stuff, if some origin is doing excessive resources compared to frame, then report it.
- ... Embedder can get information about pointing a finger
- Yoav: To better understand, probabilistic reporting despite the opt-in, or that we don't need an opt-in
- Guohui: Still requires opt-in
- ... If browser detects consuming excessive
- ... When deploying the app, it can determine which frame is causing the problem
- Luis: For opt-in, things are included in policy
- ... For now, we grouped categories, some were most straightforward
- ... e.g. compressed or not
- ... Don't necessarily want images over N MB
- ... We're looking to include more relative base criteria, CPU and memory, for things we want in the policy
- ... In terms of opt-in, if a frame doesn't opt-in, it's not loaded
- ... More in terms of how do we make information point fingers to flow to the embedder
- ... Whether either of these two options are sufficient, or whether it would need to be specified separately
- Yoav: Go back to the network policy slide
- ... Uncompressed text resources, binary category
- ... Oversized seems subjective, and could drift over time
- ... How do you expect to define semantics of oversized
- ... Make sure they're consistent now and over time
- Luis: Ties a little back to previous conversation about idea of different browser implementations would need to agree on something
- ... How do we keep that up to date with what's out there?
- ... One potential option might be to have this group review those things
- Alex: Proposal to give IFRAME a networking budget, total number of bytes?
- Guohui: Or a percentage, if IFRAME is downloading more than 50% of content, downloading budget
- ... Passed in as a parameter, budget
- Yoav: This would be trickier from a cross-origin leak perspective, then when the cutoff happens, how much embedder loaded
- ... Overall budget proposal was shot-down for "reasons"
- ... Maybe if an opt-in from IFRAME that solves it? Not sure that solves it
- Luis: Budget is something considered
- ... We think we need both of those
- ... Resources not optimized are bad
- ... Fixed budget is something we've considered, but not what we're focused on right now
- ... Agree to policy and reply with header
- ... Leak and timing side-channel concern
- ... Fuzzy budget
- ... Ideally the direction we want to go is to not give too many levers from the developer
Navigation confidence
Recording
Agenda
AI Summary:
- Goal: provide a boolean “confidence” signal so developers can discard RUM outliers caused by sub‑optimal UA/system state, without making it a reliable real‑time per‑user metric.
- Design: value is set once per navigation (around DOMContentLoaded), then fixed; differential privacy is applied by randomly “flipping” the true value (e.g., 25% of the time), tunable by UA via a flip rate exposed in the API.
- Experimental results: after de‑biasing the noisy data, aggregate metrics (including p90) closely approximate the true distribution, with some regression toward the mean—showing this approach can safely expose useful aggregate signals without special aggregation infrastructure.
- Discussion points:
- RNG and spec: need a well‑defined, uniform random distribution but probably not a fully specified RNG algorithm; implementations should avoid correlations between the randomness and the underlying system conditions.
- Intended use: segment and filter RUM data in aggregate (e.g., discard low‑confidence navigations or analyze them separately), not to change runtime behavior per user since individual values are noisy.
- Future considerations: how much noise is “enough” (statistical expertise needed), whether similar differential‑privacy techniques can be applied to other perf signals (e.g., redirect buckets), and challenges of combining multiple noisy dimensions without reducing privacy guarantees.
Minutes:
- Mike: want to allow developers to discard their RUM outliers due to suboptimal UA state
- … wanted to avoid this being a real time metric
- … Introduced differential privacy where we randomize the response

- … In reality 75% of the time you get the right answer and 25% of the time you get the noisy answer

- … Ran an experiment comparing the system entropy (without noise) compared to confidence (with noise)
- … Collected results
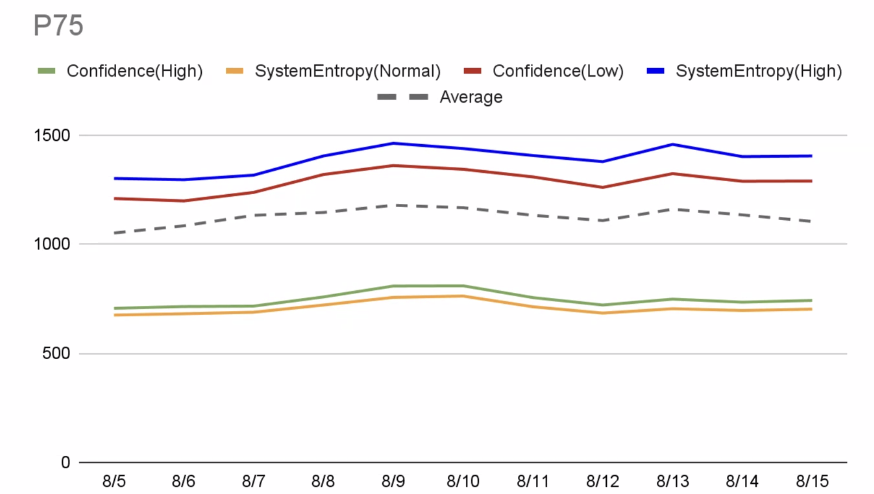
- … this shows that after debiasing the data you get a pretty decent representation of the actual value (even if there’s some shift towards the average)
- … p90 shows the same
- Yoav: Awesome, thanks for getting this data
- ... New data, based on privacy principles document
- ... That we're exposing not individually but in aggregate. Shows it worked.
- ... Shows us a way to expose new data without new fancy aggregation infrastructure that someone needs to pay for
- ... This looks like the future, shows what we hoped it would
- Michal: Mentioned flipping of coins, weighted die role?
- Mike: Implementation in Chromium, RNG, we can adjust this up and down, not just 50-50
- Michal; The difference of the lines, you could adjust how much confidence you have
- Yoav: Tradeoffs between fingerprint ability vs. accuracy
- Michal: Earlier this week we talked about fetchStart placement and redirects
- ... Here you have two values, boolean classification
- ... Perf data you can segment and de-bias
- ... For redirects, you could imagine exposing some sort of bucket-value, but we wouldn't have a histogram
- ... For redirects, none or a lot
- Yoav: Not sure how we could apply this to timestamps vs. boolean values
- ... Feasible
- ... Fake value not 1/0 but a random number
- ... Not immediately translatable to timestamps, but there could be similar methods
- Mike: Buckets, no-redirect, or redirect-or-really-long-redirect bucket
- Yoav: Maybe a long-redirect bucket is sufficient
- NoamH: How important is RNG in ensuring de-biasing is not exposing
- ... secure random or any?
- Mike: I don't know, would have to look up how it's implemented
- NoamH: That would be spec'd out, how to RNG
- Mike: I don't think we'd need to specify anything other than "you need to generate a random number"
- ... Flip rate allows UAs to tweak value over time
- ... Flip rate is part of the API
- NoamH: During OS boot or load time, if we just use a simple not secure RNG, might not have same random distribution that you want
- ... Ideally you want uniform distribution
- Guohui: Number can be adjusted, who would adjust the randomness
- ... User Agent could potentially make adjustments themselves
- Michal: Server needs to know value, part of the API
- Yoav: For this specific API, the conditions that impact the true value could impact RNG
- ... Good point for implementations to look into
- ... Implementor note to say look out for this gotcha
- NoamH: Specify distribution of randomness, how random something is
- Alex: I missed what value is actually being measured
- ... If queryable multiple times, not useful
- Yoav: Simple boolean value set at nav start
- ... Indicating whether the system or browser is considered under load, for some conditioned UA defined
- Alex: So set once
- Mike: Yes
- ... Effectively finalized at the end of navigation around DOM Content Loaded time, then it never changes
- ... Even if you were able to spin up IFRAME, you can't make any determination of it
- Alex: How much noise is enough
- Yoav: Charlie Harrison gave a presentation on related problems
- ... We need to have real statisticians making those calls
- ... UAs can decide on these values and change over time.
- ... Flexibility that it is safe and remains safe
- NoamH: What is expected user action?
- Mike: Depending on distribution of it, a number of high-confidence things, your app could go improve those metrics
- ... Intent is that things are under control for high confidence
- ... Low confidence is maybe bad because something happened. Discard. Or might help provide insights is more often XYZ.
- NoamH: If you load less resources, it should improve app in general, but the user would lose some value
- Mike: One of the things we've seen is that users that get into low confidence things, e.g. DNS lookup took too long, load less resources won't help
- ... If you can eliminate outliers or low-confidence values
- NoamH: Queried, change app behavior in runtime
- Yoav: You don't want to do that, since it's not always accurate at runtime, only in aggregate
- Michal: Segment data, see more stable segments of data
- ... See difference in distribution in counts over time
- ... Might be an interesting signal, but difficult to act on that
- Benoit: Trying to get a better since of using high/low confidence
- ... At Meta, Chrome+others do heavy throttling to background a tab
- ... Treat those differently
- ... Data you already have, useful
- ... What would be the thing that would give us low confidence, startup?
- Mike: That's primary, other ones we've prototyped, ad-blocker circumstances, if an extension took too long to respond to a request
- ... In Chromium mostly on UA start, UA session restore, device restart, things like that
- ... Visibility and background throttling tabs
- Yoav: Don't want to put that into here, since we already have an API to measure those with full confidence, don't need to flip a coin
- Mike: I could imagine a world where you're initiating a navigation, where it's backgrounded+throttled, it's still in range
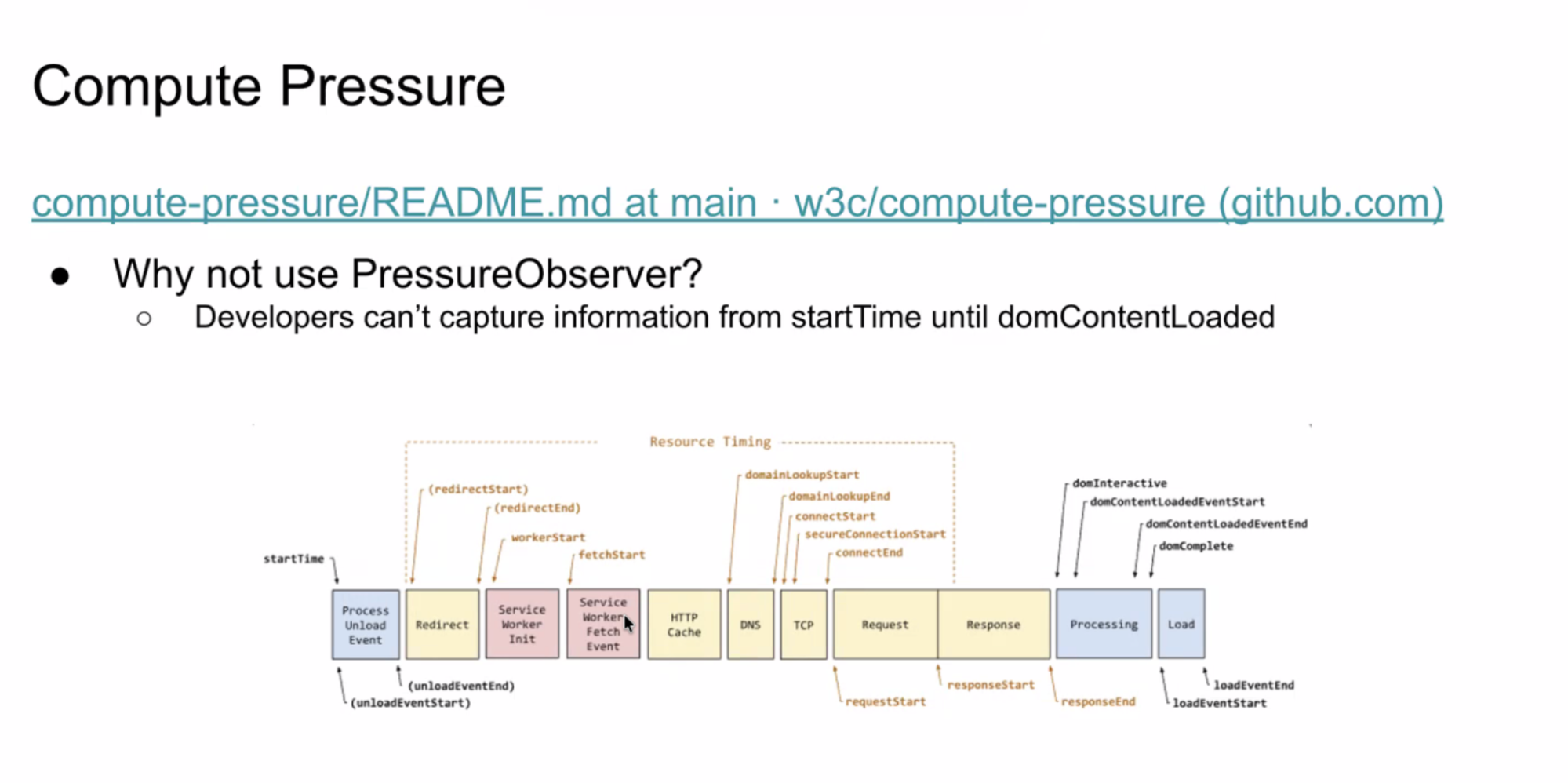
- ... One reason we looked at Compute Pressure and ruled it out, up to this point you have no code running
- Yoav: If we had multiple of these, confidence and other things, redirect time
- ... Is there a way to de-bias using multiple dimensions
- Mike: Charlie and I had this conversation
- ... The more dimensions you add, the trickier you might get
- ... Algo's to help differentially compute the whole dataset
- Yoav: If we have 5 things, and RUM provider could split as a dimension 2 or 3 of them
- ... We'll have to bring Charlie back to discuss these
- Mike: One extension of this, is a reason why, that got complicated
Where is Web Performance going?
Recording
Agenda
AI Summary:
- The group reflected on WebPerf’s past focus: “cheating” (preloading/avoiding loads), rich measurement APIs (Numerous *Observer* APIs, scheduling, compression features), and some “improving,” and asked where to focus next as part of rechartering.
- Strong demand was identified for better attribution/diagnostics (especially for style/layout and JS work), more actionable measurements (e.g., LoAF vs. raw JS Self Profiling), and dealing with under‑measured phases like click‑to‑navigation for page transitions.
- Discussion highlighted low adoption and high complexity of JS Self Profiling and similar tools; suggestions included better tooling, libraries, and documentation (possibly via collaboration with DocCG/MDN) and more user‑centric framing of APIs (loading, user activity, animation).
- Third‑party scripts were flagged as a major ongoing performance problem; the group explored ideas like off‑main‑thread execution (PartyTown‑style patterns), enforced yielding or preemption policies, document policies (e.g., passive events, script limits), and broader efforts to “offload/restrict” 3P work without breaking functionality.
- Process and coordination topics: need more discipline in progressing specs through maturity levels, a possible advisory/horizontal role for this WG on performance in other specs, and closer collaboration with documentation and RUM ecosystems to make APIs more accessible and correctly used by non‑expert developers.
Minutes:
- Yoav: Before rechartering discussion, I wanted to brainstorm on where we collectively think WebPerf in general is going, and what this WG should focus on
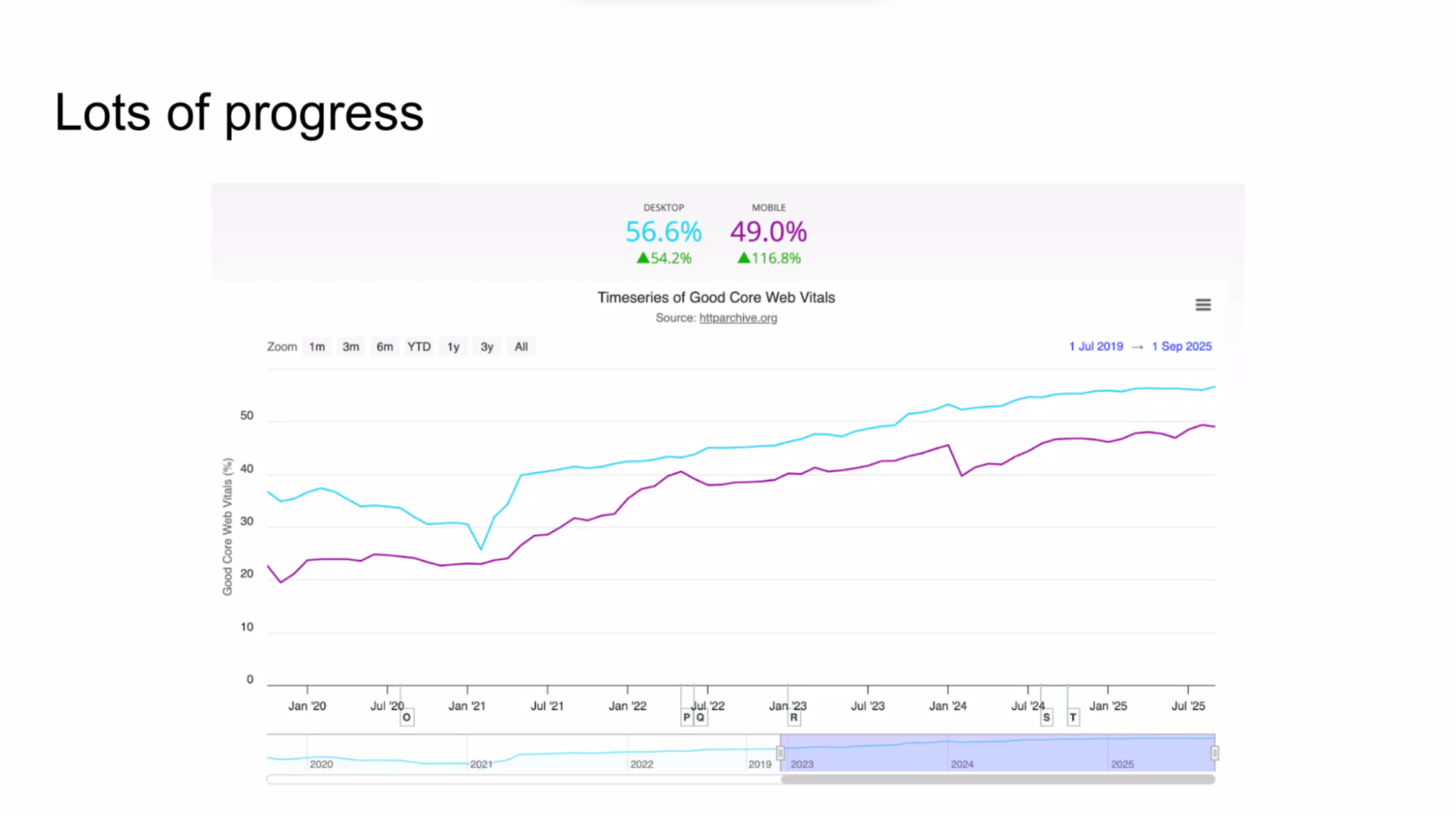
- ... We've made a lot of progress over the years
- ... More and more sites are passing Core Web Vitals over time
- ... Web Performance Optimization (WPO) has 3 pillars
- .. 1. Cheating
- ... Loading content ahead of time, or making it so we don't have to do the hard work of loading pages and optimizing them
- ... 2. Measurement
- ... Being able to track performance over time and track
- ... 3. Improving
- ... This working group has been focused on Measurement and Cheating, and Improving whenever we can
- ... What did we do in the last 3 years?

- ... Allow us to not load a page, or get parts of loading/entire loading done ahead of time

- ... On the measurement front, we have a large array of Observers
- ... LoAF, Long Tasks, Vis Observers

- ... Scheduling allow developers to better schedule their code
- ... Compression Dictionaries are an improvement on how we can do compression
- ... Beyond new features, we work on Interoperability, Spec Quality, Privacy Improvements to existing APIs, Privacy preserving reporting of new data
- ... Future things



- ... Work that we need to do there so the spec reflects reality, and to be able to expand beyond a single implementation
- ... What else??
- ... Where should we take the work?
- NoamR: From measurement POV, I think there are two things
- ... Measuring Core Web Vitals/better/worse, future measurements are all there
- ... The other is actionable measuring, LoAF
- Yoav: Measurement vs. Attribution
- NoamR: I think we could do a lot better w/ attribution
- ... Strong need
- ... Way better attribution for style and layout
- Yoav: I've spent a lot of time trying to figure out how to make progress there
- Barry: Big risk, not mentioned, is AI
- ... Agents saying don't download 2 KB of data and now models are 2 GB
- ... Measurement will it create slop, or will it improve things?
- Bas: New APIs with WebML, and there will be performance issues
- Benoit: We have more pages and product that we could ever do
- ... Things like JS Profiler we don't have the ability to even view it
- ... Agents could chew through this data, impact could be quite positive
- ... Is this something you've played around with
- ... Automatic audits, using the tools we have
- ... Want to leverage better RUM, haven't started yet with JS Self Profiling
- Nic: Datadog folks were recently interested in JS Self Profiler
- Bas: Who uses it? Meta
- NaomH: Office uses it
- + Slack is used
- Benoit: Open source agents, RUM libraries itself now
- Barry: Not even 0.1% of page loads
- Yoav: Even those that use it, use it sampled
- Michal: There have been some spikes, adoption would be higher if overhead wasn't as bad
- Yoav: There is a cost, it was 5x higher usage, tried to do higher rollouts, then it dropped
- NoamH: Initially limited to COI, but that was removed
- Barry: LoAF will give a lot of what's needed, for cheaper
- NoamH: Cheaper on measurement, not analysis. JS Self Profiler is more accurate and rich.
- ... Tells exactly where the problem is
- ... Major barrier for adopting it, not easy to use
- Bas: Infrastructure to collect and use and aggregate
- NoamH: Not easy to use, collect, analyze it
- ... Library could help with adoption
- Benoit: RUM agent would do this
- ... Self Profiling API would become more within reach
- ?: Don't see data from Slack's desktop client
- Bas: I'm not familiar with procedures, but I think that in general at Mozilla, is that they'd like us to be more disciplined to moving specs from Working Draft to the next stage.
- Yoav: Agree we need to be more disciplined
- ... I can't tell you which drafts are in which state
- ... Good feedback
- Barry: Does moving to Living Draft change that?
- Yoav: We need to move things from Working Draft to Living Standard
- Bas: Higher quality requirements on that
- Takashi: When we say page loading, it always starts with Nav Start. Loading performance starts from user's click in previous page. We are missing part of click to navigation start.
- ... Not sure if we're interested in this, it's an important part
- ... Some discussion on privacy concerns
- ... If we can measure same-site navigation, it may be still useful
- Yoav: We've discussed a lot, generally info belongs to outgoing page, not incoming page
- ... If they're same origin it doesn't matter a lot, but if not, it matters quite a bit
- ... Discussed in the context of redirects
- ... Can delay the user going out, generally it's information going to the outgoing page
- ... Very hard to report that because the page is being terminated
- ... Makes sense to have reporting API that gives you data on how long it took to navigate away from you
- Bas: NEL-related thing for out of bound reporting
- Nic: Abandonment?
- Bas: Crash Reporting API
- Michal: Last event, last interaction with the page, gets measured as Event Timing
- ... We put effort into visibility change, we flush to PerformanceTimeline, POs may not fire, but you could grab that last thing
- ... Typical case you could get that reporting
- Yoav: But there are events after visibilitychange
- Bas: People are encouraged to not do work blocking nav
- ... May not collect RUM data when going to another page
- Barry: That data is for that page, but the next page suffers
- Bas: A well-meaning developer would want to wrap things up quickly
- Barry: Fundamental thing if things aren't reported, there's no consequences, the user impact is the next page feels slow
- Michal: For sync blocking stuff, before unload, already available to the outgoing page, and through CrUX and Chrome
- ... Working on an async interactions metric, should also stop at navStart
- Bas: For Core Web Vitals, does the final interaction count for INP
- Michal: Issues with abandonment, but PO may not fire
- ... Throttled to idle times, you could .takeRecords()
- ... Last event may not be as reliable to collect
- Yoav: This would account for the INP of that interaction, does it account for beforeUnload
- ... Beyond that, pagehide/beforeunload
- Bas: Often won't be paint after that interaction
- Michal: For events that don't paint, we report up to the moment it didn't paint
- ... For a normal interaction, anything that changes vis, EventTiming won't be forever
- Bas: During vischange event, is the EventTiming after or before
- Michal: We put in Observer before firing vis change event
- Barry: Not sure if that's spec'd
- Michal: To the other events that follow, for cross-doc navigation, you don't block upcoming nav
- ... For same-origin navigation, I don't recall if that's already accounted for
- ... Most of this time is accounted for, some convo's this week we need to adjust
- Takashi: If we use beforeunload, our process needs to wait for IPC, will happen after rendered completes everything. We still have a period we're missing
- Bas: Is the outgoing page to blame?
- Michal: Can't be given to incoming page
- ... Unless we have private aggregation reporting service
- Takashi: Can we improve prev page vs. next in reporting same-origin cases
- Yoav: Problem it'd be negative timestamps
- Bas: Nav initiation time relative to time start
- Nic: We've visited negative times questions many times, always say no
- Michal: Always go to hardware timestamp?
- Bas: Yes
- NoamH: Makes sense to look at user-centric use-cases
- ... Cheating/Measuring/Improvement
- ... Methods to achieve
- ... Performance for user-centric use-cases, I think of 3
- ... Loading Experience, User Activity, Animation
- ... Trade-offs
- ... Loading you have multiple breakdowns and use-cases
- ... We could frame discussions on this type of user categorization
- ... API fits into specific categories
- Yoav: A lot of this has it in our head
- Nic: Could be useful as a primer for web performance
- Florian: From documentation CG
- ... Questions earlier on adoption and use
- ... Could be working with documentation people, technical writers
- ... CPU, etc
- ... After documenting a few of these it was hard, but this session helped
- ... Would be nice to do some more documentation work, and research on how regular web developers are doing
- ... Not large engineering teams, everyday developers, how they're able to work with these APIs
- ... DocCG we looked into survey results from web components
- ... I'm pitching into look into more documentation
- Bas: Type of documentation that isn't targeted on web performance expert, layman terms
- ... Tells more of an accessible story of what they exist
- Yoav: We have a deliverable in our charter that was aimed at that
- ... It makes sense for us to drop our deliverable and work with OpenWebDoc folks and MDN that's more up to date
- ... Rebasing that primer to today's reality is too hard
- Barry: I took that action, but made no action on it
- ... Does it belong in Working Group?
- ... We make specs for implementors, not docs for developers
- ... Not that an average web developer needs to read the spec
- Florian: You get people from quite a different set of people using the APIs
- ... Might be able to understand how to make better APIs
- ... Self Profiling APIs
- ... How are the ergonomics
- Bas: A lot of what we do, and our communication, relationship with web developers, passes through RUM frameworks than them directly
- ... Developers using APIs directly or through RUM providers
- Yoav: RUM providers are democratizing the use of these APIs
- ... For very large and medium sized companies, they're collecting those metrics internally
- ... Performance teams that are responsible to make sure they go X
- Barry: We get questions all over the place
- ... Do we build APIs with core data like EventTiming, or higher-level like INP
- Yoav: A lot of these APIs, there's the client-side and explaining the landscape. Important.
- ... But there's collecting the data, how do I clean it up, there's a lot of complexity that's out of scope for this Working Group
- ... For regular web developers, even if they use those libraries, they need to deal with the data later on
- ... We should better document all the things, categorize all the APIs into different use-cases
- ... Still a world out there, that we can point into the right direction
- ... Documentation, we want to make sure as many people can use the APIs as possible, and use them correctly
- ... Beyond that, going towards improvement, I'm curious e.g. PartyTown and delegating 3P work, ensuring it happens out of the main thread
- ... Any experience with those things?
- ... I've yet to see data that shows this is useful
- ... Trade-offs of 3P performance (degrades), but does it show 1P improvement?
- Michal: Two weeks ago at perf.now() the Mozilla folks hosted a sync, someone who deployed it, with data that showed how to reduce impact of PartyTown, and how it improved 1P
- ... They are a web-performance expert
- ... Leveraging it
- Bas: PartyTown is a way to allow workers access the window object, and it transparently proxies, calls that go to workers, get proxied to main thread
- ... Without worrying too much, move it to a worker and off main thread
- ... Main thread only pays cost of what is proxied
- ... Downsides, depending on which browser, atomics to proxy
- ... 10,000s of network requests to use, going through ServiceWorker to main thread
- Michal: It's a clever library, that presentation showed how much effort it took it to work
- ... Not sure if it's scalable or viable
- ... Gains by forcing 3P to yield
- ... Or in passive mode
- ... Interventions where you limit scripts
- Yoav: Or Doc Policy
- ... All events are passive
- ... PartyTown is a hack, because the platform doesn't give a better way to do this thing
- ... Maybe we should give a set of Doc Policies to force passive events
- Barry: Dream of it, gives access to DOM APIs not available in Workers seamlessly
- ... Awful a lot of work, breaks things
- ... That to me makes reality of using this library, no longer actively maintained, risky
- ... Only one wildscale deployment I know of
- ... I know of one other person using it, not easy
- NoamH: Can it be something specified, annotated script runs off main-thread
- Yoav: I'm not saying let's get everyone to use PartyTown, what can we extract from this experiment
- ... Better yielding 3P is one, passive events is another
- ... Worker DOM thing?
- Barry: Learning from me, Worker DOM a lot more tricky that we realized
- Michal: PartyTown does two things, moves CPU cycles off to worker thread, you have to monkey patch DOM environment
- ... DOM APIs remain narrowly scoped
- ... JS doesn't have preemptive multitasking
- ... Value of state changes over time
- ... I wonder if a lighter weight alt is scripts enable a mechanism
- ... scheduler.yield() today
- ... If every DOM API had a yield point, everything would be breaking
- Yoav: An opt-in
- Bas: Assumed coherence you get from playing with DOM from script, preemption doesn't exist, makes things simpler
- ... What can you do during pre-empted time? What if something else touches same elements
- ... For purpose of this meeting, 3P scripts are enormous issue, is there value in explicitly thinking more of this problem
- ... Worth going forward more explicitly thinking how we improve?
- ... What tools can we provide? Where 3P scripts can run off main thread
- Yoav: Worthwhile to think through it
- Michal: Project Zaraz, tried to become a CG, a variety of tag manager support server tagging, some appetite in this area before
- Barry: Now deprecated, because it caused its own problems
- Bas: Maybe there are things the web could provide
- Barry: Hoping scheduler.yield solves some of that stuff
- Yoav: If all 3P adopt
- Barry: That's one thing, complication the end of clicking link, don't know if you'll get back
- ... People are nervous to yield, we've solved some with fetchLater()
- Bas: Not as convinced that I'm willing to live with this much crap on the main thread
- ... I would just like many more things to be running off another thread
- ... A lot of things you'd want to run on an E core vs. P core
- Alex: I agree 3P scripts have a lot of performance issues on the web
- ... Don't think we should limit solution space to putting it on a thread
- ... Enforcing a script needs to yield every N ms
- Bas: 3P preemption policy
- Alex: Lots of possible solutions
- Bas: Interesting to allow a website to set a policy in header, where if a 3P script runs > 15ms without yielding, it stops
- Michal: Reiterate the point Barry was trying to make, the 3P would be happy to yield, knows about the problem, but they see the reporting rates goes down more than its worth for them
- ... Guaranteed continuations
- ... As soon as yield(), reliability goes down
- ... Opt-ins would be taken more if that tradeoff was given
- Justin: Can't throw every script off-thread, IPC is exceptionally challenged
- ... AMP script every commis explicitly async
- ... So you could batch multiple things to main thread at one time, so instead of paying 100 IPCs, do it all at once
- ... Solving is extremely difficult
- Bas: Has similar continuation mode problems
- Justin: Would love to adopt, but it's async, everything has to be async now
- Bas: What would you be yielding?
- Michal: Another task
- Yoav: Preempting code
- Justin: Only parts marked as scheduler.syncYield() become yielding
- ... Everything else is normal
- Michal: Just because you await a yield point, your task may not fully await
- ... You're not yielding, my continuation is OK to run later
- Yoav: My high-level takeaway from this, is we should find more ways to offload/restrict 3Ps in ways that would make it generally faster
- Bas: Would like us to do move in Improving
- Michal: How can we force them that is useful/impactful, a lot would follow patterns better if tradeoffs
- ... Flushing continuations that were guaranteed to run to continuation, as guaranteed as they can
- Yoav: Enable to be good citizens without taking a loss
- Bas: What role does this WG have, in advising other groups to develop or move forward things that aren't under our control to design specs, but should we have a more advisory role?
- Yoav: With web fonts, Incremental Font Transfers many years ago, but it was a one-off
- ... Some part of a wide-review or ongoing advisory role
- Florian: Horizontal review for privacy, security, one for perf?
- Yoav: I don't think a review process is what you do at the end of the thing, I'd want us to be involved earlier.
- Bas: More proactive, but we encourage new proposals to happen in groups and venues out of this group
Rechartering
Agenda
AI Summary:
- The Web Performance WG must renew its charter (2‑year term); plan is to request a 6‑month extension as a refinement period and have a new charter ready by February, with Carine starting related discussions.
- Rechartering context: historically used to define milestones (pre–Living Standards) and push specs to CR; there’s concern about complexity rising if work is deferred, but also about overhead if rechartering were more frequent (e.g., yearly).
- Charter content updates under discussion include: adding LoAF (and possibly removing/renaming Long Tasks), confirming status of Element Timing, deciding criteria for listing specs like Device Memory, and potentially retiring the “Primer” in favor of MDN documentation.
- Coordination role: proposal to more clearly describe how this WG both requests and provides review to other groups; suggestions to formalize yearly reviews of MDN/Web‑perf docs as an ongoing deliverable.
- Next steps: Carine will initiate the extension process and work from the existing charter repo/PR; group should also cross‑check with Interop priorities when deciding which specs and features (e.g., LoAF, Element Timing, Long Tasks) to emphasize in the renewed charter.
Minutes:
- https://www.w3.org/guide/process/charter.html#existing-groups
- Carine: It’s been two years so we need to renew our charter
- … Suggested to request a 6 month extension
- … Refinement period, Carine would chair the related discussions
- … We should get a charter ready by February
- Bas: What’s the goal of the periodic rechartering and what are the criteria for extensions?
- Carine: The idea was to define milestones as we didn’t have Living Standards
- … Defined timeline and milestones
- … Advice now is to do explainers immediately when starting the work
- Bas: Tricky for a WG like this one, where it’s hard to gauge in advance what web developers would pick up
- Carine: we need to move all the things to CR
- Yoav: yes
- Bas: came up during Interop discussions at Mozilla
- Carine: we should not wait too much, as complexity rises over time
- Barry: Why not every year?
- Yoav: overhead
- Barry: reflection every year would be good
- Nic: First action is to extend the charter
- Carine: I’ll send a notice to start the extension
- … There’s a repo where all the charters are, but some folks prefer their own repo
- Nic: Opened up a PR against the charter
- … Do we want to go through the spec for review at this point?
- Barry: We have Long Tasks in there. Should it be replaced with LoAF?
- … What’s the criteria for adoption? E.g. Device Memory
- Bas: Device Memory had objections for implementation
- Nic: But not to bring it to the charter
- Bas: LoAF should be in there
- Yoav: I think it was adopted but should verify
- Nic: Primer and performance security, do we want to keep it?
- Yoav: Should retire it and move the work to MDN
- … Not sure about the privacy and security principles
- Bas: Should we have something about our roles with regard to other WG?
- Carine: Coordination
- Bas: It’s about us requesting review from others. Should it also include what we provide others?
- Carine: We can still ask other groups that are not listed here
- Florian: Could add a review of the MDN documentation. Maybe want to do yearly review of those
- Michal: We did some review in the past
- Florian: Changed the perf docs based on your feedback. That’s interesting for us to make improvements. Could be a yearly deliverable.
- Alex: HAR file format?
- Carine: LoAF and Element Timing should be published before we recharter
- Nic: we can remove it
- Barry: Should we look at the interop list and see what it needs
- Michal: should we drop Long Tasks?
- Bas: No interop future
WebPerfWG + Sustainable Web IG (@ room 404)
[a]@nrosenthal@google.com