This report aims to define the requirements for interfaces that enable the implementation and management of federated learning systems. Federated Learning is an
innovative approach to building efficient machine learning models through collaborative learning across multiple devices or servers, while prioritizing data privacy
and security. This document comprehensively addresses the fundamental interfaces, protocols, and data handling standards necessary for the effective implementation
and management of federated learning systems.
The report identifies the key elements required for the design and implementation of a standard API and defines their interactions to support developers in more
easily building and operating federated learning systems. By doing so, it aims to maximize the potential of federated learning, enabling the creation of powerful systems
that can effectively learn in various devices and environments while maintaining security and data privacy. This report serves as an essential guideline for developers,
researchers, and technical experts in standardizing and understanding federated learning systems.
GitHub Issues are preferred for
discussion of this specification.
1. Introduction
The scope of the requirements for Federated Learning API specification encompasses the development of a standardized interface that enables the implementation and management of federated learning systems.
It focuses on the communication and coordination between central servers and client devices participating in federated learning, with an emphasis on privacy-preserving machine learning techniques.
The specification covers the interactions, protocols, and data formats necessary for secure and efficient model training across decentralized devices.
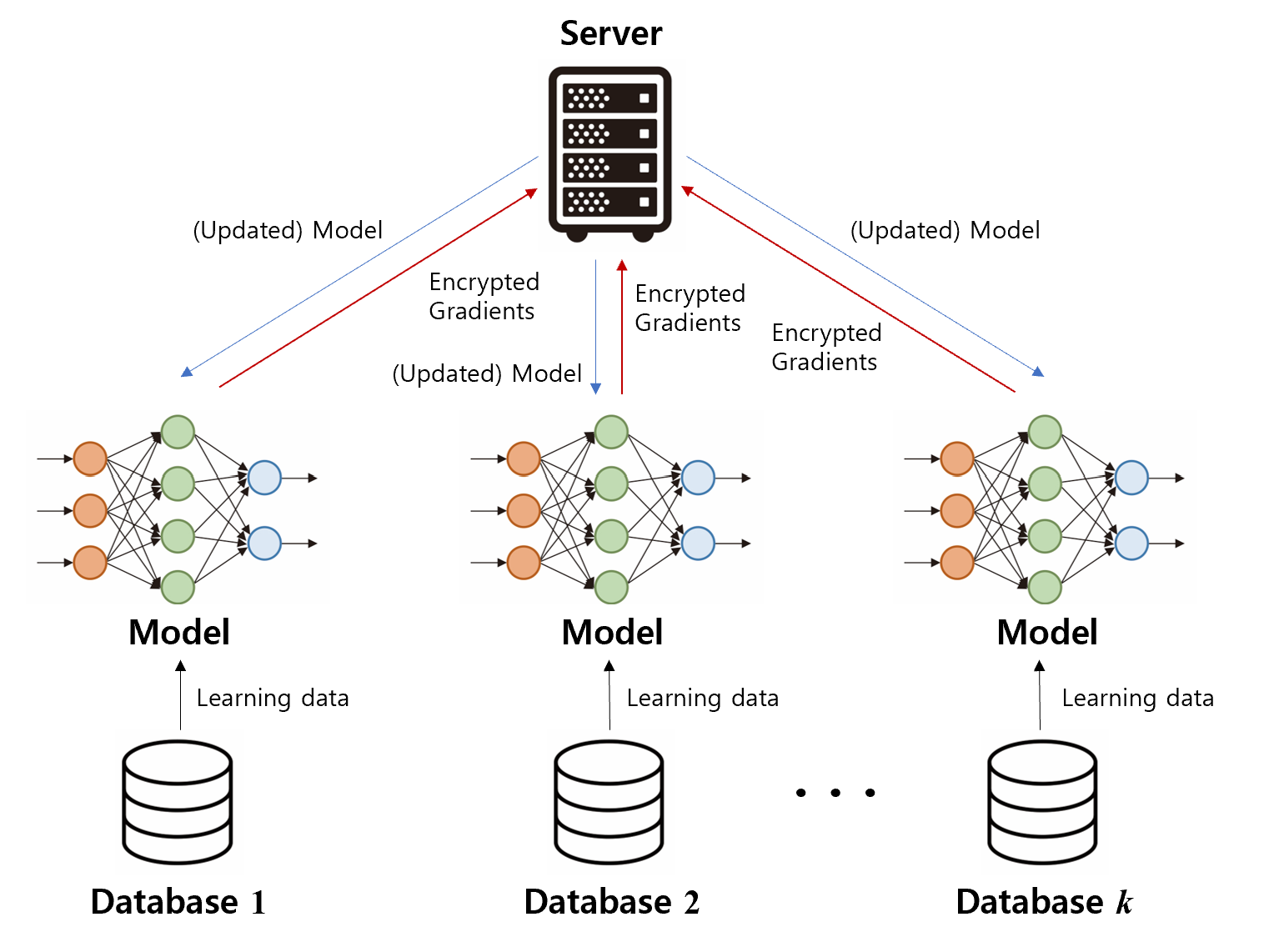
Figure 1. Basic process of executing federated learning
The Figure illustrates the basic process of executing federated learning after configuration of central server and client nodes, and setup the topology of model to client nodes.
Model Training Initiation: Each database 1, 2, ..., k is used at their respective client nodes. Each client node uses its local database to train a model independently.
Sending Encrypted Gradients: The gradients (which are the necessary information to update the model) from the trained model are encrypted and sent to central server A. This step is marked as (1) in the diagram.
Secure Aggregation: Server A securely aggregates the encrypted gradients received from various clients. This step is represented as (2) in the diagram. At this stage, the server combines the updates from all clients into one aggregated update.
Sending Back Model Updates: The aggregated update is then sent back to each client node, as indicated by (3) in the diagram. This ensures that each client's model is kept up-to-date.
Updating Models: Client nodes update their models using the updates received from the server, which is shown as (4) in the diagram. This updating process is iterative.
Through the process, the central server effectively trains a model without having to access the actual data from clients, thereby ensuring data privacy while leveraging the learning capabilities of multiple clients with distributed data.
The key technical aspects of federated learning are described in Chapter 4, and requirements are described in Chapter 5.
2 Terminology
The following terms and definitions are described in connection with the context of federated learning, providing a foundational understanding for the concepts discussed in this document.
Central Server: In federated learning, the central server acts as a hub that coordinates the learning process, aggregates model updates, and distributes aggregated updates back to client devices.
Client Devices: These are decentralized devices participating in federated learning. Each client device uses its local data to train models independently and sends updates back to the central server.
3 Conformance
As well as sections marked as non-normative, all authoring guidelines, diagrams, examples, and notes in this specification are non-normative. Everything else in this specification is normative.
The key word MUST in this document
is to be interpreted as described in
BCP 14
[RFC2119] [RFC8174]
when, and only when, they appear in all capitals, as shown here.
4. Key Technical Aspects
The key technical aspects section outlines the fundamental techniques and approaches to federated learning. This section encompasses the fundamental techniques and approaches for executing federated learning including configuration of parameter servers and clients, node and model assignment,
parameter aggregation strategies, model training and optimization, synchronous and asynchronous learning, and parameter server operations.
4.1 Parameter Server-client Assignment
The parameter server and the clients are essential components for executing federated learning. The parameter server acts as a centralized repository for model parameters, while clients perform model training using local data.
Parameter server setup: The parameter server manages the parameters of the trained model and aggregates updates received from clients. It maintains the current state of the model and, when necessary, distributes model updates to the clients.
Client assignment and configuration: Each client independently trains a model using its local data. Clients send updates generated during the training process back to the parameter server.
Client nodes are assigned specific models or parts of a model. This assignment varies depending on the client's processing capabilities, the type and amount of data held, and their network location. Efficient node assignment is crucial for optimizing the overall system performance.
4.2 Model Distribution Strategy
Model distribution is a key part of federated learning, determining the type and scope of models assigned to clients.
Full model distribution: Each client receives the full model. This ensures that every node has the same topology of the model, leading to uniformity in training and evaluation processes across the network.
Model splitting: For large-scale models, the model can be divided into several parts and assigned across different clients. This allows for parallel processing of model training and reduces the computational burden on individual clients.
Customizable topologies: The customization of model topology is possible for specific federated learning task. Dynamic assignments can be adapted to changes in network conditions, client availability, and data distribution.
Client nodes are assigned specific models or parts of a model. This assignment varies depending on the client's processing capabilities, the type and amount of data held, and their network location. Efficient node assignment is crucial for optimizing the overall system performance.
4.3 Parameter Aggregation Strategies
The foundational algorithms for federated learning, Federated Averaging, or FedAvg, aggregates model updates by averaging them. The central server calculates a weighted average based on the number of data points from each client.
4.4 Model Training and Optimization
For model training, clients can use their local data to train models. The frequency of synchronization with the central server varies based on the algorithm and design decisions. To further ensure data privacy, noise can be added to model updates, providing differential privacy.
This protects individual data points while allowing the central model to learn general patterns.
4.5 Synchronous and Asynchronous Learning
Depending on the application, federated learning can operate in synchronous mode (all clients send updates simultaneously) or asynchronous mode (clients send updates at different times). The bandwidth optimization techniques such as model compression or quantization can be used to reduce the size of model updates,
optimizing for limited bandwidth scenarios.
4.6 Parameter Server Operations
A hierarchical structure can be used where multiple local aggregators collect updates before sending to the central server for large-scale deployments. Techniques and tools to optimize parameter server, such as model pruning of neural network, can be supported to make federated learning more optimalize for resource-constrained devices.
5. Requirements
The functional requirements for Federated Learning API are produced in a high-level, functionally outline the essential
capabilities and specifications necessary to enable seamless communication, secure data transmission, and effective
coordination of federated learning systems. These requirements encompass device registration, data upload,
model synchronization, evaluation, result retrieval, training control, and ensuring security and privacy measures.
5.1 General Requirements
The following requirements have been expressed.
APIs should be accessible through a unified and structured namespace to ensure ease of understanding.
APIs should provide operation for cancellation and error handling to improve resilience and controllability.
APIs should be designed for supporting compatibility across various platforms and devices.
The API architecture should be extensible, allowing for upgrade and management without breaking existing functionality.
5.2 Device Registration
The following requirements have been expressed.
The API must provide secure endpoints to support registration for client devices with the server of federated learning system.
The server should validate client credentials and maintain a registry of authorized client devices.
5.3 Data Upload
The following requirements have been expressed.
The API should enable clients to upload data securely to the server by support encryption mechanism or data anonymization
The API must support multiple data formats to provide efficient data transmission.
The API should provide metadata specification for various data formats.
5.4 Model Synchronization
The following requirements have been expressed.
The API must offer endpoints for clients to download global model and upload local model updates.
The API must offer endpoints for the server to send back aggregated model updates.
The API should ensure secure and efficient transmission of model parameters (or gradients), considering network status including bandwidth and latency.
The API must facilitate version control of models to manage different iterations of the training process.
5.5 Model Evaluation
The following requirements have been expressed.
The API should allow model evaluation and provide the reports of evaluation results.
The API must enable the server to process evaluation requests on user demand.
The API should ensure that the evaluation metrics are consistent and accurately to measure model performance.
5.6 Result Retrieval
The following requirements have been expressed.
The API must provide secure endpoints for clients to retrieve and search the final model or aggregated results.
The API should support versioning and tracking of different model iterations.
The API must include mechanisms for access control and verification of client authorization.
5.7 Training Control
The following requirements have been expressed.
The API should provide endpoints for control model training process including initiating, pausing, and terminating the process.
The API must allow clients and the server to monitor training process and log of training status.
The API should enable dynamic adjustment of training hyper-parameters based on real-time feedback.
5.8 Security and Privacy
The following requirements have been expressed.
The API must incorporate end-to-end encryption for data and model transmission.
The API should implement robust authentication for client-server interactions.
The API must adhere to data privacy standards and allow for compliance of new regulations.
5.9 Extensibility and Compatibility
The following requirements have been expressed.
The API should be designed to facilitate the addition of new functionalities or endpoints.
The API must ensure backward compatibility with existing federated learning models and systems.
The API should support integration with a variety web standards, framework, platforms, and tools.
6. Example of Federated Learning API
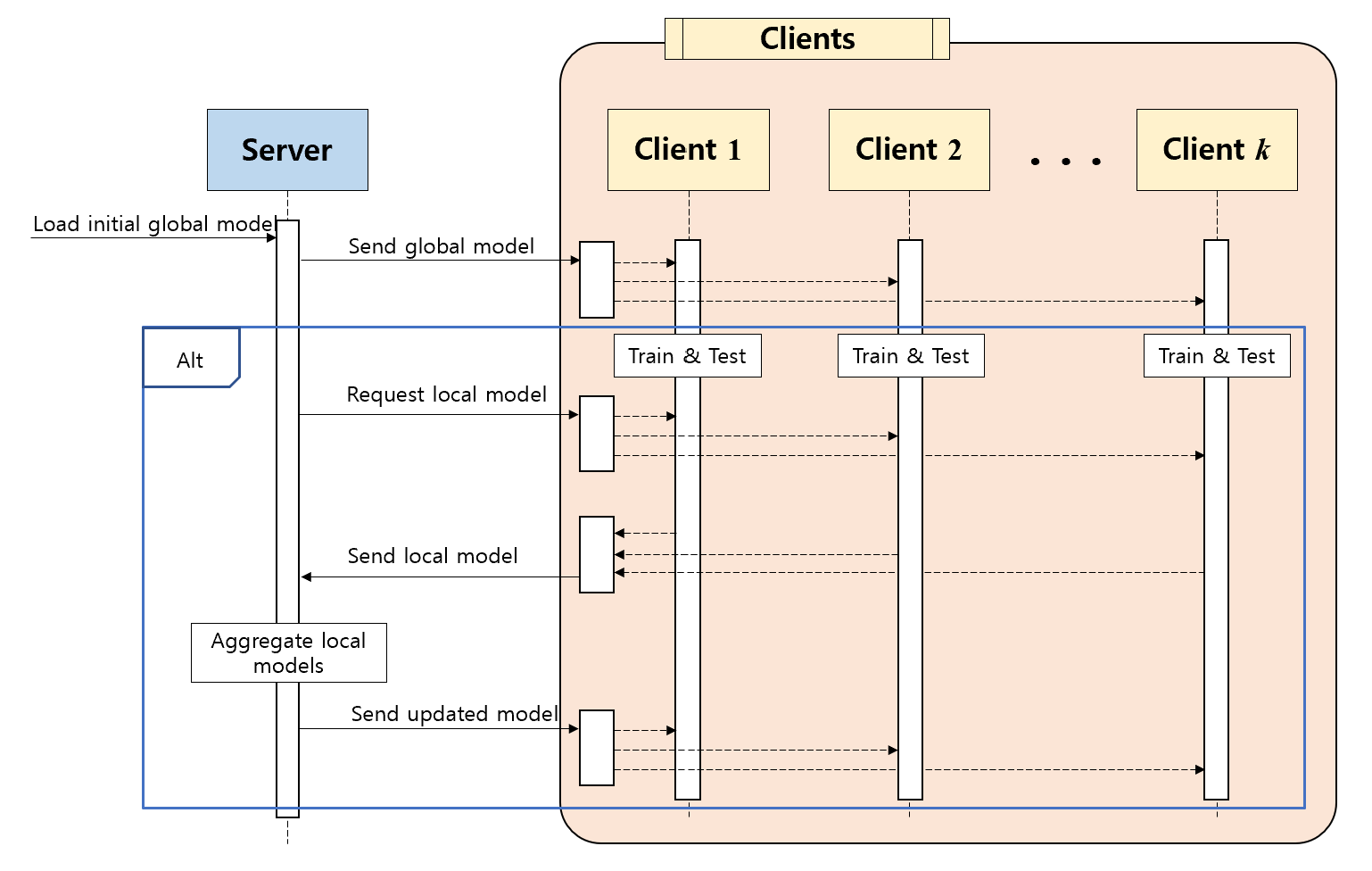
The sequence diagram depicts a federated learning process involving a server and multiple client nodes.
Figure 2. Federated Learning Process involving a Server and Multiple Client Nodes
Followings are the steps shown in the diagram:
Initial Global Model: The process starts with the server having an initial global model.
Sending New Model to Clients: The server sends this initial model to the clients.
Local Training and Testing: Each client (Client 1, Client 2, etc.) then trains and tests the model with their local data. This is referred to as 'local model 1' and 'local model 2' for each respective client.
Requesting Local Models: After training, the server requests the updated local models from the clients.
Sending Local Models to Server: The clients send their locally trained models back to the server.
Aggregation of Local Models: The server aggregates these local models. This could involve averaging the weights or applying more complex aggregation algorithms.
Sending Updated Global Model: Finally, the server sends the updated global model back to the clients, and the process can repeat, as indicated by the loop in the diagram.
This iterative process improves the global model over time while preserving the privacy of the local data. Followings are candidates or example of high-level API descriptions for web federated learning, considering the above steps:
Model and parameter transmission API:
Distribute global model {/api/post/global-model}: Server use this endpoint to send the latest global model to the client. The client responds with the model file or parameters acceptance.
Get local model {/api/get/local-model}: Clients send their locally trained model updates to this API. The request includes model parameters and possibly metadata about the local training.
Request updated weights of local model {/api/post/local-model}: The server requests the trained model weights from the clients.
Get global model {/api/global-mode}l: Clients fetch the current global model from the server.
Aggregate models {/api/model/aggregate}: The server receives models from the clients to trigger the aggregation process. The response would contain the aggregated model parameters.
Federated Learning execution and management API:
Load model {/api/models/load}: The server loads a global model into the training environment. The request payload includes the model identifier or path to the model file.
Initiating learning {/api/training/start}: The server initiates the federated learning algorithms. This API should include training parameters such as batch size, number of epochs, and learning rate.
Configuration of schedule {/api/training/schedule}: The server schedules training tasks. The request could specify timing, frequency, and priority of updating or aggregation of parameters.
Model evaluation {/api/evaluation/start}: The server starts the evaluation of the global model using a validation dataset. The request should include details about the dataset and evaluation metrics.
Post evaluation {/api/evaluation/results}: Clients or server fetch the evaluation results after the computation is complete.
Training status management {/api/training/status}: Clients or server query the status of the training process and status, including progress and any errors.
Control training process {/api/training/control}: Allows pausing, resuming, or stopping the training process as needed. The request specifies the control action to be taken.