This document gathers metadata proposed within the MultilingualWeb-LT Working Group for the Internationalization Tag Set Version 2.0 (ITS 2.0). The metadata targets web content (mainly HTML5) and deep Web content, for example content stored in a content management system (CMS) or XML files from which HTML pages are generated, that facilitates its interaction with multilingual technologies and localization processes.
This document gathers metadata proposed within the MultilingualWeb-LT Working Group for the Internationalization Tag Set Version 2.0 (ITS 2.0). The metadata targets web content (mainly HTML5) and deep Web content, for example content stored in a content management system (CMS) or XML files from which HTML pages are generated, that facilitates its interaction with multilingual technologies and localization processes.
The work described in this document receives funding by the European Commission (project MultilingualWeb-LT (LT-Web) ) through the Seventh Framework Programme (FP7) in the area of Language Technologies (Grant Agreement No. 287815).
This document gathers metadata proposed within the MultilingualWeb-LT Working Group for the Internationalization Tag Set Version 2.0 (ITS 2.0). The metadata is used to annotate web content (referred to henceforth just as content) to facilitates its interaction with multilingual technologies and localization processes with the aim of publishing that content on the Web in multiple languages. In this context, content can refer to static web content in HTML or XHTML, deep web content, for example content stored in a content management system (CMS) or XML files from which HTML or XHTML pages are generated.
The target audience for this document includes the following categories:
Since a lot of the terminology is not known across communities, this document contains a glossary of terms.
Following the terminology introduced in the Internationalization Tag Set (ITS) 1.0 specification, ITS 2.0 metadata items are called data categories. Data categories are defined conceptually (e.g. Translate). In ITS 1.0, they are implemented in XML, see the implementation for Translate. ITS 2.0 will provide additional definitions and offer implementations at least for HTML5.
To lower burden on implementors and to foster adoption, the data categories are proposed as in independent items. See the section on support of ITS 1.0 data categories for more details.
The MultilingualWeb-LT working group currently plans the following implementation approach.
Please send feedback to the public-multilingualweb-lt-comments list (archive).
At the current stage, the working group has gathered a long list of potential ITS 2.0 data categories. We especially welcome feedback on the following aspects:
The working group will gather feedback until end of June 2012. This feedback will be the basis for creating the first draft of the data category standard definition. After June 2012, this document (the "requirements document") will not be updated anymore.
Requirements are used to define the set of data categories to be addressed in the standard definition which is due for a feature freeze November 2012. The WG has closed the open gathering of requirements by the end of April 2012, and has performed an initial round of consolidation for a working draft of the requirements document to be published for 20th May. The WG will continue a process of requirements consolidation, such that a prioritised and consistent set of data category requirements is available by the end of June 2012. A major milestone in this process will be an open requirements workshop to be conducted in Dublin 12-13 June.
A public consultation questionnaire has been executed, resulting in 17 responses. A summary of results has been produced that assesses responses against current state of requirements.
A requirements assessment conducted 4th May 2012, and is now being supplemented with implementation commitments. This will guide the prioritisation of work on the different data categories.
The following terms common in multilingual technologies and localization processes are used in this document:
To clarify the product classes impacted by ITS 2.0 requirements, and referenced by use cases, the following classes are identified:
The following are descriptions of potential roles for use case actors that benefit from the use of data categories:
ITS 2.0 will support several business scenarios around the production of multilingual web content and the operation of localisation processes over web content. The following use case description serve as a broad orientation. Some use cases are linked to proposed data categories. More links will be created in a subsequent version of this document or in the to be published ITS 2.0 draft.
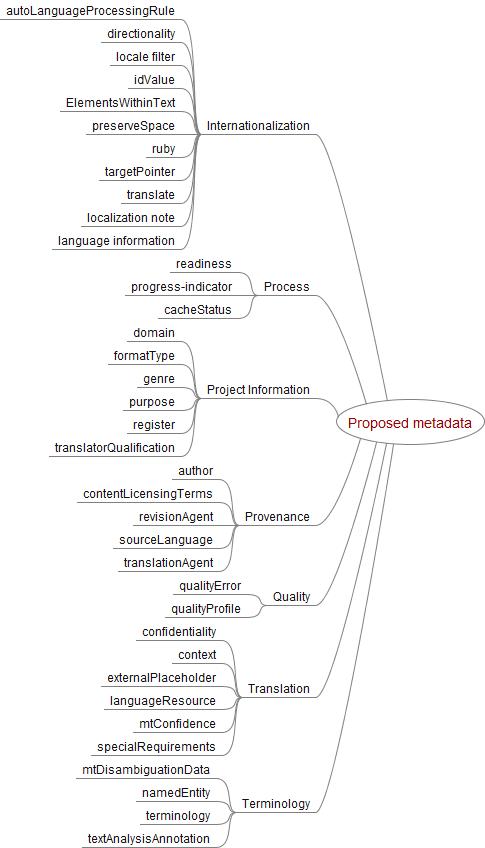
The following figure provides a broad overview of the proposed data categories.
The table below lists proposed metadata elements with a brief description and statement about which level(s) they apply to (document = applies to the entire document, element = applies to defined elements in the document, span = applies to user/tool-defined spans). Links go to more detailed information below. For a table showing which data categories are needed by which work packages, see this document.
| Name | Short description | Level |
|---|---|---|
| Internationalization | ||
| autoLanguageProcessingRule | This data category captures information that it is acceptable to create target language content purely based on automated language processing (such as automated transliteration, or machine translation). | span |
| directionality | Improve handling of ITS directionality rules | element, span |
| locale filter | provides instruction that content should be excluded from translated version (not just untranslated, but deleted) in all cases or for specified locales | element, span |
| idValue | mechanism to associate ITS translateRule with unique IDs | element |
| ElementsWithinText | Provide a way to identify elements nested within other elements | element |
| preserveSpace | identifies whether white space should be preserved in the translation process | document, span |
| ruby | Improve ITS ruby model | span |
| targetPointer | identifies relationship between source and target in a file at the element level, e.g., specifies that the translation for a <source> element goes in a <target> element | document, element, span |
| translate | specifies whether the content of the element to which the attribute is applied should be translated or not | document, span |
| localization note | used to communicate notes to localizers about a particular item of content | document, span |
| language information | used to express the language of a given piece of content | document, span |
| Process | ||
| readiness | provides positive guidance regarding steps to be undertaken in a CMS/localization process | document, span |
| progress-indicator | reports the proportion of a document that has completed by a process | document |
| cacheStatus | indicates need to (re)translate dynamic web content for real time MT | document, span |
| Project Information | ||
| domain | information about the domain (subject field) of the content | document, span |
| formatType | provides information about the format or service for which the content is produced (e.g., subtitles, spoken text) | document, span |
| genre | information about the genre (text type) of the content | document, span |
| purpose | information about the purpose of the text | document, span |
| register | information about stylistic/register requirements (e.g., formality level) | document, span |
| translatorQualification | information about the qualifications required for the translator | document, span |
| Provenance | ||
| author | provides information about the author of content (= dc:author) | |
| contentLicensingTerms | Licensing terms for content (e.g., can it be used in databases or for TM?) | document, span |
| revisionAgent | provides information concerning how a text was revised (e.g., human postediting) | document, span |
| sourceLanguage | provides information concerning what language the original text was in | document, span |
| translationAgent | provides information concerning how a text was translated (e.g., MT, HT) | document, span |
| Quality | ||
| qualityError | describes an authoring or translation error | span |
| qualityProfile | describes the profile/results of a language-oriented quality assurance task | document, element, span |
| Translation | ||
| confidentiality | States whether text is confidential (and thus cannot be exposed to public translation services) | document, element, span |
| context | Provides information about where the text occurs (e.g., in a button, a header, body text) | element, span |
| externalPlaceholder | Provides instructions for translators on how to deal with external resources | element |
| languageResource | states what translation-oriented languages resource(s) is/are to be used | document, span |
| mtConfidence | Information provided by an MT engine concerning its confidence in the result | span |
| specialRequirements | information about any special localization requirements (e.g., string length, character limitations) | span |
| Terminology | ||
| mtDisambiguation | Information required to assist MT to distinguish between ambiguous cases | span |
| namedEntity | Values for types of named entities, | span |
| terminology | marking of information about terms used in the content | span |
| textAnalysisAnnotation | embed information generated by text analysis services | span |
In this document, language is identified via BCP 47 language tags.
Locale information is based on UTC #35, with the following approach to convert a language tag to a locale identifier:
http://unicode.org/reports/tr35/#BCP_47_Language_Tag_Conversion
An example language tag is de-de. An example locale is de_de.
Both language tags and locale identifiers are case insensitive and are written in lower case throughout this document.
These categories relate primarily to the internationalization of content and are generated prior to translation (and may be consumed in translation). Includes any items that build on existing ITS functionality.
Example A: <doc> <msg name="id1"> <text>Content of text</text> <desc>Context of desc</desc> </msg> </doc> --> Corresponding XLIFF output: <trans-unit id='1' resname='id1_text'> <source>Content of text</source> </trans-unit> <trans-unit id='2' resname='id1_desc'> <source>Content of desc</source> </trans-unit>
withinText with a value yes|no|nested (See Example A)
Example A <text xmlns:its="http://www.w3.org/2005/11/its" xmlns:itsx="http://www.w3.org/2008/12/its-extensions" its:version="1.0"> <body> <par>Text with <bold itsx:withinText='yes'>bold</bold>.</par> </body> </text>
Example A:
<para>This is the first
sentence of the paragraph. It's followed
by a second sentence.</para>
Example B:
<data name="CMD_USAGE">
<value>Usage: po2xliff input[ options[ output]]
Where options are:
-trg: create target entries
-fill: fill the target entries with the source text</value>
</data>
Example A: <file> <entry xml:id="one"> <source>Text one of the source</source> <target>Text one of the target</target> </entry> <entry xml:id="two"> <source>Text two of the source</source> <target></target> </entry> </file>
Example B: <file> <entry id='1'> <text loc='1'>Very important text</text> <text loc='2'>Texte très important</text> <text loc='3'>非常重要的文本</text> <text loc='4'>Zeer belangrijke tekst</text> <text loc='5'>Очень важный текст</text> </entry> </file>
Example C: <its:rules xmlns:its="http://www.w3.org/2005/11/its" version="2.0" xmlns:itsx="http://www.w3.org/2008/12/its-extensions"> <its:translateRule translate="no" selector="//file"/> <its:translateRule translate="yes" selector="//source" itsx:targetPointer="../target"/> </its:rules>
These categories are used primarily for controlling or indicating the state of the content production process.
These categories provide information about the project that may be useful for controlling processes, but they do not convey or control process state themselves.
These categories provide a record of the origin of information and the agents that have acted on it.
These categories are used for explicit quality assurance steps undertaken on content (source or target).
These categories are used or generated in the translation process. (There is some conceptual overlap with Internationalization that we may want to resolve)
Data Categories related to the association of content with terminological data.
MLW-LT must support all ITS 1.0 data categories and their functionality, using the following approach:
A references section will be provided in a future version of this document.
This document has been created by participants of the MultilingualWeb-LT Working Group.
{kind=link}