Tibetan script overview
Tibetan can be written using two different styles: དབུ་ཅན dbu can with a head, the block style of the Tibetan script used in print, pronounced u.cen; and དབུ་མེད dbu med headless, the cursive style of the Tibetan script used in shorthand and calligraphy, pronounced u.me. This page concentrates on the former. Pronunciations are based on the central, Lhasa dialect.
Historically, Tibetan text was written on loose-leaf sheets called pechas, ( དཔེ་ཆ pé.t͡ɕʰá book, scripture ). Some of the characters used and formatting approaches are different in books and pechas.
Tibetan text runs left to right in horizontal lines.
Words boundaries are not indicated. However, Tibetan words are made up of one or more units called tsheg-bar which are basically equivalent to phonological syllables. The tsheg-bar units are separated using ་ U+0F0B TIBETAN MARK INTERSYLLABIC TSHEG.
These tsheg-bar units are composed of structural elements that include vowel signs and consonants used as prefixes, root characters, subscripts, superscripts, suffixes, and secondary suffixes. A common realisation includes a stack and additional consonants to either side of the root consonant. These may indicate syllable-final consonant sounds, but more often than not they qualify or modify the root value, and are not associated with their nominal sound value. The actual pronunciation of Tibetan is usually much more simple than a typical romanisation would suggest. For example, the word བཀོད kǿː to create is transcribed as bkod.

To write the sounds of the standard Lhasa dialect, Tibetan uses 28 consonant letters (plus their subjoined forms). 6 more letters are used to write Sanskrit.
A distinguishing feature of Tibetan is the set of separate code points for subjoined consonants, used to create consonant stacks. Of the 77 combining characters in the Tibetan block, 48 represent subjoined consonant forms. Unlike many other Indic scripts, the modern Tibetan orthography doesn't use a virama to create stacks.
Tibetan is an abugida with one inherent vowel. When writing the Lhasa dialect, other post-consonant vowels are represented using 4 vowel signs, all combining marks.
There are no pre-base, circumgraph, or multipart vowels in the Tibetan used to write the Llasa dialect (though there are when writing in Sanskrit).
Standalone vowels are written by adding vowel signs to either འ U+0F60 TIBETAN LETTER -A or ཨ U+0F68 TIBETAN LETTER A, depending on the tone.
Sanskrit vowels written in Tibetan use additional vowel signs and combining marks, some of which represent diphthongs, and some of which form circumgraphs or multipart characters, depending on the encoding.
Tone is indicated by the choice of root character and/or its associated prefixes and superscripts.
Modern Tibetan writing uses few punctuation marks or symbols, but the Tibetan script block in Unicode contains many of these.
Tibetan has its own set of numbers.
Tibetan Syllables
The following diagram shows characters in all of the syllabic positions, and lists the characters that can appear in each of the non-root locations. The two-syllable word in the example is འགྲེམས་སྟོན 'grems-ston ɖɹemton exhibition.
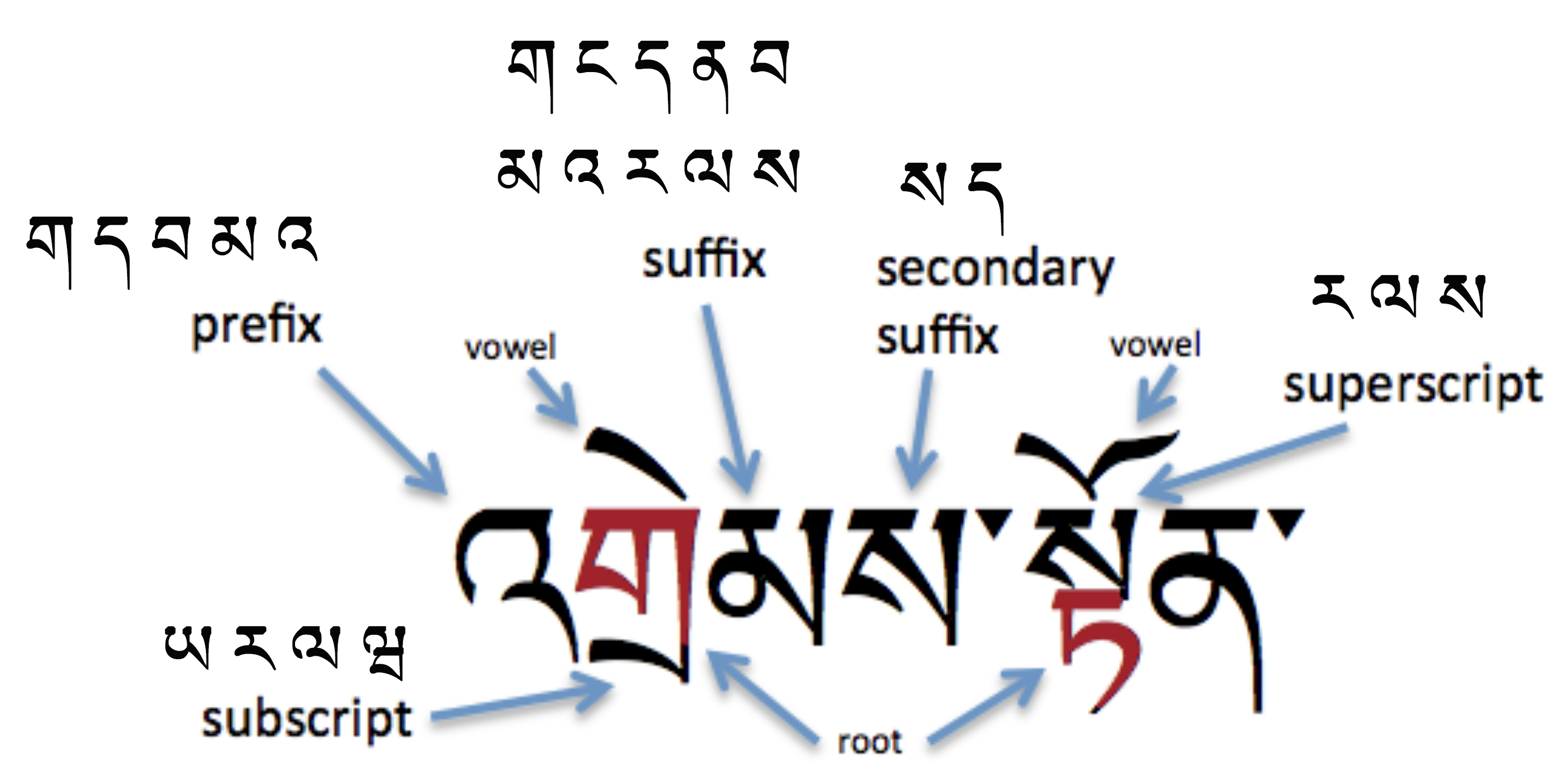
See more information about how the various parts of the tsheg-bar work together.