Domain Specific Use Cases
Smart Agriculture
Greenhouse Horticulture
- Submitter(s)
- Ryuichi Matsukura, Takuki Kamiya
- Target Users
- Agricultural corporation, Farmer, Manufacturers (Sensor, other facilities), Cloud Provider
- Motivation
- Greenhouse Horticulture controlled by computers can create an optimal environment for growing plants. This enables to improve productivity and ensure stable vegetable production throughout the year, independent of the weather. This is the result of research on the growth of plants in the 1980s. For example, in tomatoes, switching to hydroponics and optimizing the temperature, humidity and CO2 concentration required for photosynthesis resulted in a five times increase in yield. The growth conditions for other vegetables also have been investigated, and this control system is applied now.
- Expected Devices
- Sensors (temperature, humidity, brightness, UV brightness, air pressure, and CO2) Heating, CO2 generator, open and close sunlight shielding sheet.
- Expected Data
- Sensors values to clarify the gaps between conditions for maximizing photosynthesis and the current environment. Following sensors values at one or some points in the greenhouse: temperature, humidity, brightness, and CO2.
- Dependencies
-
WoT Architecture
WoT Thing Description - Description
- Sensors and some facilities like heater, CO2 generator, sheet controllers are connected to the gateway via wired or wireless networks. The gateway is connected to the cloud via the Internet. All sensors and facilities can be accessed and controlled from the cloud. To maximize photosynthesis, the temperature, CO2 concentration, and humidity in the greenhouse are mainly controlled. When the sunlight comes in the morning and CO2 concentration inside decreases, the application turns on the CO2 generator to keep over 400 ppm, the same as the air outside. The temperature in the greenhouse is adjusted by controlling the heater and the sunlight shielding sheet. The cloud gathers all sensor data and the status of the facilities. The application makes the best configuration for the region of the greenhouse located.
- Gaps
- In the case of the wireless connection to the sensors, the gateway should keep the latest value of the sensors since the wireless connection is sometimes broken. The gateway can create a virtual entity corresponding to the sensor and allow the application to access this virtual entity having the actual sensor status like sleeping.
Open-field Agriculture
- Submitter(s)
- Cristiano Aguzzi
- Target Users
- Agricultural corporation, Farmer, Manufacturers (Sensor, other facilities), Cloud Provider, Middleware provider, Network providers, Service Provider.
- Motivation
- Water is vital for ensuring food security to the world’s population, and agriculture is the biggest consumer amounting for 70% of freshwater. Field irrigation application methods are one of the main causes of water wastage. The most common technique, surface irrigation, wastes a high percentage of the water by wetting areas where no plants benefit from it. On the other hand, localized irrigation can use water more efficiently and effectively, avoiding both under-irrigation and over-irrigation. However, in an attempt to avoid under-irrigation, farmers feed more water than is needed resulting not only to productivity losses, but also water wastages. Therefore, technology should be developed and deployed for sensing water needs and automatically manage water supply to crops. However, open field agriculture is characterized by a quite dynamic range of requirements. Usually, solutions developed for one particular crop type cannot be reused in other cultivations. Moreover, the same field can have different crop types or different sizes/shapes during the years, meaning that technology to monitor the state of crop growth should be highly configurable and adaptive. Even agriculture and irrigation methods can change and also they are very different depending on the size of the field and its clime type. Consequently, silos applications are deployed leveraging on IoT technologies to gather data about the crop growth state and irrigation needs. The Web of Things may help to create a single platform where cost-effective applications could adapt seamlessly between different scenarios, breaking the silos and giving value both to the environment and the market.
- Expected Devices
-
Sensors:
- Weather sensors (maybe collected together inside a
weather
station)
- temperature
- air humidity
- air pressure
- pluviometer
- global solar radiation
- anemometer (wind speed)
- wind direction
- global solar radiation and photosynthetically active radiation
- gas/air quality sensor (i.e. CO2)
- Soil sensors (usually packed together in soil
probes)
- soil temperature
- soil moisture/water content
- soil conductivity (detecting salt levels in the soil)
- water table sensor
- Drone sensors
- camera
- temperature sensitive camera
- multispectral camera
Actuators:
- drones: used for data collection, applying pesticide, or pollination
- sprinklers
- pumps
- central pivot sprinklers
- hose-reel irrigation machine
Additional devices:
- Solar panels
- Loggers: units that collect data from close sensors.
- Gateways
- Weather sensors (maybe collected together inside a
weather
station)
- Expected Data
-
Sensor data plays a central role in Smart Agriculture. In
particular, it is critical that the information sensed is
associated with a timestamp. Common algorithms use *time
series* to calculate the water needs of a crop.
Furthermore, soil sensors usually are calibrated over a
specific soil type (which may differ even in the same
geographic region). For example, the calibration data for
a soil moisture sensor is represented by a function that
maps sensor output to soil water content. In literature,
this function is knowns as a *calibration curve*.
Commercial sensors are precalibrated with a
"standard" curve but on most occasions, it
fails to accurately measure the water content. Therefore,
it can be configured during the installation phase (which
may happen every time the soil is plowed). Finally, a
crucial aspect is forecasting. Farmers use this
information to actively change their management
procedures. Services exploit it to suggest irrigation
schedule or change device settings to behave accordingly
to environmental changes. To summarize here it is a list
of most important expected data from Open field
agriculture:
- Calibration curve
- Time series
- Forecast data
- Geolocations: sensor data must be contextualized in geolocation. Also, geolocation is critical in massive open fields to localize instrument position.
- Weather data
- Unit of measure: commercial soli sensor may output their value in a different unit of measures (i.e. volts or % water in an m^3 of soil)
- Relative values
- Depth position: geolocation is not sufficient to describe the parameters of the soil. Depth is an additional context that should be added to an observed value.
- Device owner information
- Battery level and energy consumption
- Dependencies
- WoT Architecture, WoT Thing Description
- Description
-
In open-field agriculture, the IoT solutions leverage on
different radio protocols and devices. Usually, radio
protocols should cover long distances (even kilometers)
and be energy efficient. Devices too need to be energy
saving as they are deployed for months and sometimes even
years in harsh environments. A sleeping-cycle is one
mechanism they use to save energy usually coordinated by
*loggers/gateways* or preprogrammed. *Loggers* are
deployed closed to sensor devices and have more storage
space. They serve as buffers between sensors and higher
services. Often *loggers* and sensors are embedded in the
same board, otherwise, they are connected using cables or
close-ranged radio protocols. On the other hand,
*gateways* serve as a collection point for data of an
entire field or farm. They are much more capable devices
and usually are more energy-consuming. In some deployment
scenarios, they host a full operating system with
multiple software facilities installed. Otherwise,
gateways only serve as relays of data sent from the
loggers and sensors to cloud services and vice-versa. The
cloud services may be partially hosted in edge servers to
preserve data privacy and responsiveness of the whole IoT
solution. Possible cloud services are:
- Weather forecasting/local weather forecasting
- Soil digital twin to simulate and predict water content
- Plant digital twin (growth and water needs prediction)
- Irrigation advice service: combining the previous services and knowing the irrigation system topology is possible to advise farms with the best times to irrigate a crop.
- Pesticide and fertilize planning

- Variants
-
Open-field agriculture varies a lot between geographical
location and methods. For example in the SWAMP project there three
different pilots with different requirement/constraints:
-
Italian
pilot (Reggio Emilia region):
- Relative small field size
- Multiple connectivity solutions available: 4G, LPWAN, and WiFi
- Variance in crop types, sometimes even inside the same farm
- Small soil type variance
- Precise model soil behavior
- A great influence of the water table
- Variance in the irrigation system
- Channel-based water distribution
- The main goal is to optimize water consumption
-
Brazilian
pilot (Matopiba and Guaspari location):
- Huge field size
- Central pivot irrigation systems: need to optimize each sprinkler output
- Soil type variance within the same field
- A low number of connectivity options: no 4G, only radio communication base on LPWAN
- Low crop type variance
- the main goal is to optimize energy consumption
-
Spain
pilot:
- Efficient localized irrigation and application of the right amount of water to the crop
- arid location
- The goal is to minimize water consumption but maintaining a good field yield.
-
Italian
pilot (Reggio Emilia region):
- Gaps
- Currently, there is no specification on how to model device status (i.e. connected/disconnected) Examples of how to handle a device calibration phase may help developers to use a standardized approach. Possibly define standard links types to define the relation between loggers and sensors Handle both geographical position and depth information. Ontology class for battery and energy consumption Model historical and forecast data
- Existing Standards
-
- LPWAN [[rfc8376]]
- SDI 12
- CoAP [[rfc7252]]
- MQTT [[MQTT]]
- Comments
- This use case is designed using the experience gained in the European-Brazil Horizon 2020 SWAMP project. Please follow the link for further information. Since SWAMP is heavily oriented to optimize water consumption, this document just mentioned issues like plant feeding, fertilizing, pollination, yield prediction, crop quality measurement, etc. Nevertheless, WoT technologies may be employed also in these scenarios.
Irrigation in Outdoor Environment
- Submitter(s)
-
- Catherine Roussey
- Jean-Pierre Chanet
- Target Users
-
- Device Users: farmers
- Service Provider
- Motivation
-
Depending on the type of crops (e.g. maize), cultivated
plots may need specific irrigation processes in outdoor
environments. Depending on the country there exist some
specific pedo-climatic conditions and some water
consumption restrictions. Thus an irrigation system is
installed on the plot. It is used on a several days basis
(e.g. every 7 days), for each plot. The goal is to
optimize the irrigation decision based on the crop
development stage and the quantity of rain that has
already fallen down on the plot. For example an important
rain may postpone the irrigation decision.
This use case aims to evaluate the number of days to delay the irrigation system, in addition to the basis irrigation frequency (e.g. 2 delay days means 9 days between two irrigations). - Expected Devices
-
- 6 tensiometers in the plot (soil moisture):
- 3 tensiometers at 30 cm depth
- 3 tensiometer at 60 cm depth
- 1 weather station:
- thermometer (outdoor temperature)
- pluviometer (rain quantity)
- 1 mobile pluviometer (quantity of water provided by the watering system)
- 6 tensiometers in the plot (soil moisture):
- Expected Data
-
To decide when to water a cultivated plot, we evaluate
the crop growth stage, the root zone moisture level and
the number of delay days:
- To evaluate the Crop growth stage, we need:
- Min and max temperature per day: the min temperature per day is evaluated on the period [d-1 18:00, d 18:00[. The *max temperature per day is evaluated on the period [d 06:00:00, d+1 06:00:00[.i
- Growing degree day values uses min and max temperature per day, the sowing day and the type of seed. The Growing degree day is compared to some thresholds to evaluate the crop growth stage
- To evaluate the Root zone moisture level, we
need:
- Mean moisture per day per probe: in order to get reliable values, each tensiometer sends several measurements of soil moisture, at fixed hours of the day (usually in the morning), that are aggregated; their mean value is considered
- For the set of 3 tensiometers localised at the same level of depth, the median value is evaluated from their mean per day moisture measurements. One tensiometer may not provide accurate values (the soil around the probe is too dry and the soil matter is not connected to the probe). The median value of three different tensiometers at the same depth will improve the accuracy of the moisture measurement.
- Then the sum of the two median values at two different depths is evaluated, to take into account the quantity of water available in the root zone volume. This aggregated value estimates the root zone moisture level.
- The root zone moisture level is compared to some thresholds (dependent on the crop growth stage) to evaluate if the crop needs water or not at the end of the basis irrigation period.
- To determine the number of delay days, we
need:
- The time period between two waterings of the same plot is dependent on the farm and known by the farmer. When a watering is launched, no new watering should be planned during the basic irrigation frequency. The quantity of rain that falls down on the plot may postpone the watering plan. The total quantity of rain per day is compared to some thresholds to determine the number of delay days.
At the end, the farmer may decide if they follow the irrigation recommendations or not. They could force the watering for one of the next days.
- To evaluate the Crop growth stage, we need:
- Affected WoT deliverables and/or work items
-
- WoT Architecture: wireless communication in outdoor environments presents some issues: communication consumes lots of energy, sensor nodes have limited energy, weather conditions impact communication quality
- WoT Thing Description: the affordance should be precise enough to describe the soil at a specific depth or the root zone volume or the min temperature per day
- Description
-
To avoid Property right and consent management issues
between farmers and cloud Service Providers on
these computed data, sensors are connected to the farm
infrastructure and the services that evaluate aggregated
data are executed locally on this infrastructure.
The weather station may be located outside of the farm.
The tensiometers are located inside the farm. The tensiometers and the mobile pluviometer are connected using wireless communication to the gateway. The gateway sends the measurements to the farm infrastructure. - Variants:
- The crop growth stage may be observed by the farmer. In this case, they can force this value to update the service inputs.
- Security Considerations
- The 6 tensiometers and 1 pluviometer are installed on the plot, but only the farmer should be able to change their configurations (frequency of communication). Wireless communication should be used but the measurement data should only be accessible through the farm network infrastructure.
- Privacy Considerations
- Data concerning quantity of water, type of seed, sowing day should be protected.
- Gaps
-
The main potential issues come from tensiometers located
in the plot, as they are known to be cheap and easy to
use probes but not always reliable. They can face
multiple issues: if the soil gets too dry or the probe is
improperly installed, there may be air between the probe
and the soil, therefore preventing the probe from
providing accurate conductivity measurements.
To be sure of the quality of those measurements each tensiometer sends its measurements several times (3 to 5) per day. The tensiometer may send an inappropriate value due to the bad connection between the soil and the probe, that is the reason why three tensiometers are used and the median value is computed. If the gateway does not receive the value of one sensor during a whole day, an alert should be sent. To take an irrigation decision, at least one measurement per sensor and per day should be provided.
The gateway can create a virtual entity corresponding to the sensor and allow the application to access this virtual entity having the actual sensor status like sleeping.
Sensor nodes deployed in outdoor environments may take into account that their energy supply device (battery, solar panel) constrains the lifetime of the device. Thus they should be able to alert that they may not be able to provide a service due to lack of energy or they should be able to change their configuration and switch communication protocols to save as much energy as possible.
Moreover wireless communication can be impacted by weather conditions or any outdoor conditions. For example a tractor that comes too close to the sensor node may move the communication device and destroy some components. Some kind of network supervision must be achieved (for instance by the gateway) to check node availability. - Existing Standards
-
- Semantic Sensor Network Ontology (SSN/SOSA) [[vocab-ssn]]
- SAREF4AGRI ETSI Standard [[SAREF4AGRI]]
- PROV-O
- CASO
- IRRIG
A thesaurus climate and forecast that describes the weather properties and associated phenomenon is available at http://vocab.nerc.ac.uk/collection/P07/current/.
The weather measurements provided by the agricultural weather station of Agrotechnopole is available at http://ontology.irstea.fr/weather/snorql/. [5] - Comments
-
This use case has been implemented in France, following
local conditions and regulations. There exists an open
manual irrigation decision method called
IRRINOV® developed by Arvalis [2] and INRAE
dedicated to France and some specific crops: maize, wheat
and cereals, potatoes and beans.
IRRINOV® can be automated using wireless sensor networks and semantic web technologies. The considered network is of star type: all sensors can communicate with a common gateway, which is connected to the Internet. The IRRINOV® implementation was developed in [3]. This work presents an expert system for maize using drools. It automates the irrigation decision for maize based on sensor measurements.
To measure weather properties, we use the recommendation provided by the French National Weather Institute: Météo France[4]. Its web site defines how to evaluate the min and max temperatures per day in http://www.meteofrance.fr/publications/glossaire/154123-temperature-minimale (in French, we found no equivalent description in English). - References
-
[1] https://www.inrae.fr/
[2] https://www.arvalis.fr/
[3] Q-D. Nguyen, C. ROUSSEY, M. Poveda-Villalón, C. de Vaulx , J-P. Chanet. Development Experience of a Context-Aware System for Smart Irrigation Using CASO and IRRIG Ontologies. Applied Science 2020, 10(5), 1803; https://www.mdpi.com/2076-3417/10/5/1803
[4] http://www.meteofrance.fr/
[5] C. ROUSSEY,S. BERNARD, G. ANDRÉ, D. BOFFETY. Weather Data Publication on the LOD using SOSA/SSN2022-11-07 Ontology. Semantic Web Journal, 2019 http://www.semantic-web-journal.net/content/weather-data-publication-lod-using-sosassn-ontology-0
Automatic milking system for dairy farm
- Submitter(s)
- Mun Hwan CHOI, ChangKyu LEE, Sunghyun YOON
- Target Users
- Service provider, device manufacturer, device owner, cloud provider
- Motivation
-
Dairy farming requires significant labor in the feeding, milking, breeding, and manure disposal as well as the control and management of the environmental conditions inside and outside the livestock barn. In particular, the milking accounts for more than 40% of the total working time for handling a cow.
Recently, advanced countries in the dairy industry have introduced an IoT-based automatic milking system using various IoT devices and equipment to reduce the labor for milking. The automatic milking system (AMS) with IoT devices and equipment, such as sensors, high performance cameras, laser equipment, and robot arms, can perform the entire milking process which includes identification of cows entering the milking box, washing udders, milking, collection, sterilization, storage, and milk composition analysis. The AMS has advantage of solving the labor shortage problem in the dairy farm by enabling labor allocation for tasks other than milking unlike conventional methods like pipeline, herringbone, tandem machines, etc. In addition, the AMS can improve productivity and quality of milk while reducing the incidence rate of disease in cows.
- Expected devices
-
- Object (cow) identifier such as RFID reader, QR code scanner or barcode scanner
- sensors for detecting position and behavioral characteristic of cows, for measuring milking volume, and for monitoring environmental conditions inside and outside the livestock barn
- 3D camera, laser equipment for identification of nipple location of a cow
- Robot arms for attaching/removing milking cups
- Milk composition analyzer
- Milk tank with cooling function
- Expected data
-
The AMS generates the following data, and the data need to be managed in an organic relationship with data for other purposes such as feeding, parturition, disease control, and growth control in order to establish a comprehensive production and operation management strategy for dairy farms.
- Daily Number of milking, milking volume, and milking time per cow
- Target production and actual production of the farm
- Historical data for milking
- Target milk yield for each cow and/or farm based on historical data
- Health and disease management data for each cow
- Component analysis results of milk
- Operational status of devices, equipment, etc. installed in dairy farm
- Dependencies - Affected WoT deliverables and/or work items
- WoT Thing Description
- Descriptions
-
When a cow enters a milking box, a object identifier installed in the milking room identifies the cow’s ID from the RFID tag, QR code or bar code attached to the cow. Through this, the milking can be performed more systematically based on historical data, such as the number of milking or milk yield, managed by AMS.
Then, 3D camera, laser equipment, and sensors accurately identify the position of udders, and the robot arm attaches the milking cups to the udders quickly to perform milking. Before and after the milking, cleaning and disinfection should be performed to remove any contaminant and bacteria. A sensor installed in the milking cup measures the elapsed time and milk yield during milking.
In addition, the components of milk, which are content of fat, protein, lactose, etc., are analyzed, and the analysis results are transmitted to the AMS in order to manage the quality of milk, disease and health status of the cow. After milking, the milk is delivered to a milk tank with cooling capability to maintain freshness of the milk. The AMS collects the data generated during the entire milking process, and analyzes the data to establish a milk production strategy of a dairy farm. The farmer or the manager of a dairy farm can monitor the milking process through a web page or a mobile app.
Automated system should be designed to minimize human intervention; however, it is more desirable to have the capability to directly control the AMS in order to respond to an emergency situation.
The devices and equipment such as RFID reader/tags, milking cups, robot arms, milk component analyzer, and sensor are connected to a gateway, which is a controller, installed in a dairy farm through wired or wireless networks. The gateway controlling various actuators and transferring the data is connected to the cloud system through the Internet. Thus, all devices and equipment on the dairy farm can be accessed and controlled through the cloud. The cloud utilizes technologies, such as AI and big data, to analyze the data transferred from the AMS. The analysis result can be shared and distributed to all stakeholders and can be utilized as basic information for the creation of various new services enhancing productivity and convenience of the dairy farm.
- Variants
- None.
- Security Considerations
-
This use case does not specify any specific requirements on security matters. Any well-defined security management mechanisms can be applied for this use case.
- Privacy Considerations
-
In addition to farmers, various stakeholders such as farm workers, Service Providers, manufacturers, consumers of agricultural products, third-party companies and government departments are also involved with the operation of a dairy farm. The data with various types and characteristics generated during the operation of the AMS can be shared and distributed to one or more stakeholders.
Consequently, the right to access the data must be systematically managed according to the type, characteristics, and purpose of data utilization. Through this, it is possible to protect the experience, know-how and unique agricultural knowledge or techniques of a farmer, and to secure the dairy farm’s competitiveness.
- Accessibility Considerations
- None.
- Internationalisation (i18n) Considerations
- None.
- Requirements
-
A wired or wireless communication link is required to exchange data generated by operation of AMS and commands for controlling IoT devices and equipment. To prevent interfering with the free movement of cows and other agricultural works, using wireless communication link is recommended.
The data for the AMS should be delivered and stored with a common format regardless of device types and manufacturers, and should be expressed in a standardized way for AI-based analysis and processing.
- Gaps
-
In general, a gateway, which is a controller, installed in a dairy farm collects data and transmits the data to an external cloud connected through a network. The gateway also delivers the control commands received from the cloud to the various actuators through the network. However, if data loss or delay occurs due to a bottleneck, a disconnection between the gateway and the cloud, or due to the excessive internal processing time of the cloud, it may be difficult to perform efficient and reliable milking operations. In order to solve these problems, it is recommended to applying edge computing technologies to maintain essential functionalities for performing agricultural works including the milking.
- Existing standards
- None.
- Comments
- None.
Pest control in Open-field
- Submitter(s)
- Mun Hwan CHOI, ChangKyu LEE, Sunghyun YOON
- Target Users
- Service Provider, Device Manufacturer, Device Owner, Device User, Cloud Provider
- Motivation
-
Recently, the interest in pest control using unmanned
aerial vehicles (UAVs), such as drones, for open-field
agriculture is growing as the technology related to smart
agriculture is advanced.
UAVs equipped with high-performance cameras and a variety of sensors closely monitor a wide range of agricultural land and detect unique spectral signals of crops. Meanwhile, sensors installed on the ground collect crop-growth status information. The data collected by UAVs and ground sensors are analyzed using various technologies including AI. UAVs take appropriate pest control, if the occurrence of pests is identified according to the analysis results. UAVs can set the target area and use the minimum amount of pesticides on the area in order to improve the productivity of farmhouses while minimizing the damage caused by pests. The pest control using UAVs can alleviate the labor shortage in rural areas due to the decrease of the agricultural population and the aging of the farmers. In addition, UAVs can also be an effective solution to protect farmers from serious side effects of pesticides by reducing the frequency of farmer’s contact with chemicals such as pesticides. - Expected devices
-
- UAVs (drones) equipped with high-performance cameras and sensors for monitoring and detecting pests
- Sensors for monitoring crop-growth status in ground
- Controllers for UAVs, and for related actuators installed in ground
- Data (image, video, etc.) analyzer in cloud
- Expected data
-
- Image and/or video data of farmland and crops
- Data of soil conditions and crop-growth status
- Data on types of pests and appropriate control methods
- Result of pest control works
- Dependencies - Affected WoT deliverables and/or work items
- WoT Thing Description
- Description
-
The pest control using UAVs includes the steps of data
collection, data analysis and prescription, pest control
operation, and utilization of data including operation
results.
- In data collection step, UAVs collect data, such as images and/or videos, on farmland and crops by using built-in high-performance cameras and sensors, and transmit them to the cloud. In addition, the sensors installed on the ground collect data related to the soil condition and crop-growth status and transmit them to the cloud through a controller.
- In data analysis and prescription step, the cloud analyzes the collected data using various technologies including AI and big data technologies to identify the occurrence of pests, occurrence area and the range of occurred pests, and types of occurred pests. Then the cloud generates a prescription including the type, amount, and spray method of appropriate pesticides based on the analysis results. This prescription is delivered to UAVs or a separate ground-operated pest control machine. To generate accurate and effective prescription, the cloud may utilize public database provided by government or related Service Providers.
- In pest control operation step, according to the prescription received from the cloud, UAVs perform pest control operation. UAVs can spray the correct amount of pesticide around the area where the pests occur, depending on the type of pests and the severity of symptoms.
- In data utilization step, the cloud stores and manages the data collected throughout the entire process for pest control. The accumulated data are used as basic materials for establishing an optimal control plan regarding the location of farmland, soil condition, the types and status of crops, the types of pests. Farmers can monitor the details and results of the overall control operations using the web page or mobile app.
- Variants
- None.
- Security Considerations
- This use case does not specify any specific requirements on security matters. Any well-defined existing security capabilities can be applied for this use case. However, appropriate security plan is required to protect the image or video data for pest control which are closely related to the profits of the farmhouse.
- Privacy Considerations
- To protect the agricultural technology of the farmer and secure competitiveness, it is required to establish a systematic access method for all data acquired during the pest control using UAVs. Only the stakeholders who have been contracted or promised in advance are allowed to access the data to be share or distributed, because various stakeholders may participate in other agricultural works as well as pest control.
- Accessibility Considerations
- None.
- Internationalisation (i18n) Considerations
- None.
- Requirements
-
In addition to the International Civil Aviation
Organization (ICAO), each country has regulations for the
safe operation and management of UAVs for non-military
purposes. UAVs for pest control should be operated safely
within the scope of related regulations, such as the
available altitude and range of flight and the allowable
weight of the payload.
UAVs, sensors and equipment from different manufacturers may not be compatible with each other. For data sharing and analysis, a standardized data format and compatible connection interface between different types of equipment and devise should be provided. - Gaps
-
Farmers may have own database and analysis system for
pest control using UAVs. However, a significant cost is
required to secure high-performance computing resources
for analyzing images or videos and to manage
large-capacity storage space. Therefore, it can be much
more economical to utilize the cloud service.
In addition, a large-capacity battery and fast charging technology should be considered for the stable operation of UAVs that require a long flight. Wireless power transfer (WPT) technology may be a potential charging method for future agricultural UAVs. - Existing Standards
- None.
- Comments
- None.
Livestock Health Management
- Submitter(s)
- ChangKyu LEE, Mun Hwan CHOI, Sunghyun YOON
- Target Users
- Service Providers, Device Manufacturers, Device Users
- Motivation
-
IoT and AI-based animal health management technologies are being introduced to overcome the difficulty of separating sick livestock from other livestock in narrow spaces where many livestock herds live. This helps to safely maintain livestock by monitoring their behavior and health status and taking quick and appropriate responses if disease is expected or occurs.
IoT and AI-based animal health management technology plays an important role in monitoring livestock health, preventing diseases, and detecting them early. Through this technology, livestock's health status can be monitored in real-time by collecting and analyzing their biological signals, such as body temperature, heart rate, and respiration, and setting normal ranges. If abnormal data is detected, it sends an alert to the farmer to take appropriate measures.
Additionally, AI technology can be used to predict livestock's health status. By analyzing the relationship between livestock's health status and disease occurrence using AI models, predictive results on health status can be provided to take preventive measures.
This IoT and AI-based animal health management technology is very useful for maintaining livestock's health, improving productivity, and minimizing disease occurrence by monitoring their health status, taking preventive measures, and providing early responses.
- Expected devices
-
- Sensors and/or cameras to collect data on behavioral characteristics and health status of livestock, environmental conditions inside and outside the livestock barn
- Wearable devices such as collars or ear tags attached to the livestock’s body to monitor the livestock’s location, behavior, and vital signs
- Communication devices including object identifiers (RFID readers, QR code scanners or barcode scanners), Bluetooth or Wi-Fi modules, and cellular to transmit the data from the sensors, cameras or wearable devices to a cloud server for analysis
- Environmental control devices such as light, air conditioner, etc.) to control the breeding environment of livestock
- Cloud-based analytical system to analyze the collected data. Edge devices including microcontrollers, gateways, and edge servers may be required for network stability and real-time data processing
- Expected data
-
- Identification data of a livestock: identification number, sex, age, etc.
- Health status data of a livestock: body weight, body temperature, heart rate, respiration rate, activity level, feed and water intake, fecal volume and its condition, etc.
- Disease data of a livestock: disease occurrence, type of disease, diagnosis and prescription results, etc.
- Environmental condition data of a livestock barn: temperature, humidity, ammonia, carbon dioxide level, etc.
- Dependencies - Affected WoT deliverables and/or work items
- WoT Thing Description
- Description
-
Overall, livestock health management involves a complex system of data collection, transmission, processing, analysis, and decision-making. By using this, it is possible to improve livestock health, prevent the spread of disease, and increase productivity. Livestock health management can be described from the perspective of data flow as follows.
(Data collection) Data for livestock health management are collected from the livestock and the livestock barn being monitored. This data can include various types of physiological data, such as body temperature, heart rate, respiration rate, and fecal output, as well as environmental data, such as temperature, humidity, and air quality.
(Data Processing) The data is then preprocessed on edge devices before being sent to the cloud server. The preprocessing step can involve cleaning the data, compressing it, and performing basic analysis to reduce the amount of data that needs to be transmitted.
(Data transmission) Collected data is transmitted to a cloud server for analysis. This is typically done using wireless communication technologies such as Bluetooth, Wi-Fi, RFID, or cellular networks.
(Data Analysis) The cloud server uses machine learning algorithms and AI models to analyze the data collected from the sensors and wearable devices. The analysis can include identifying patterns, predicting future health risks, and detecting early signs of illness or disease.
(Decision Making) Based on the data analysis results, the livestock health management Service Provider or veterinarian with insights can make decisions about the care and treatment of the livestock. This can include taking preventative measures to reduce the risk of disease or illness, administering medication, or isolating sick livestock from the rest of the herd. Also, the livestock health management Service Provider or veterinarian establish a livestock health management plan that reflects the results of analysis.
- Variants
- None.
- Security Considerations
- This use case does not define specific considerations for security issues. However, all data collected and analyzed for livestock health management should be managed using well-defined security technologies. In particular, it should be treated more safely because it is used as data for prescribing medicines for disease treatment.
- Privacy Considerations
- Establishing a systematic access method for all data acquired in livestock health management is necessary to protect the agricultural technology of farmers and ensure competitiveness. Only stakeholders who have a pre-existing contract or agreement are permitted to access and share/distribute the data.
- Accessibility Considerations
- None.
- Internationalisation (i18n) Considerations
- None.
- Requirements
-
- Protocol Requirements: Flexible.
- Contents Type Requirements: Flexible.
- Platform or Standard Requirements: None.
- Authentication and Authorization Mechanisms Requirements: Flexible.
- Communication Requirements: To transmit and share data collected from livestock or from the livestock barn, appropriate communication links and identification methods for individual livestock are necessary. High-speed communication links may be required to collect large data such as images or videos in real-time or to transmit data to external cloud server for data analysis.
- Data expression Requirements: Various data for livestock health management should be represented in a standardized format that is independent of the type or manufacturer of the device or equipment. Furthermore, all of this data must be stored and managed in a separate repository to maintain a history of the data, and data interoperability must be ensured.
- Other Requirements: Unlike a greenhouse or an open field, a livestock barn has an environment that is very humid and easily exposed to toxic gases due to manure. Since devices such as sensors and cameras installed in livestock barn can easily fail, the state of the device must be continuously managed remotely, and it must be replaced immediately if necessary.
- Gaps
- None.
- Existing Standards
- None.
- Comments
- None.
Agricultural Machinery Management
- Submitter(s)
- Mun Hwan CHOI, ChangKyu LEE, Sunghyun YOON
- Target Users
- Service Providers, machinery manufacturers, machinery owners, Device Manufacturer
- Motivation
-
Smart agriculture in open fields, which covers a considerably large area, requires various types of agricultural machinery such as tractors, combines, weeders, and pesticide sprayers, unlike greenhouse with limited space. However, since the cost of agricultural machinery is generally high, it is important to efficiently operate and manage the machinery to save costs and labor required for operating them.
To manage agricultural machinery efficiently, farmers need to first establish an agricultural works plan that reflects the type of agricultural works required for each growth stage of the crops, the estimated time required, the type and quantity of machinery needed for each agricultural works. By implementing the established agricultural work plan, farmers can use machinery to complete the required agricultural work in the shortest time possible. In addition, IoT-connected machinery can share real-time progress status of the agricultural work and, if necessary, additional idle machinery can be added to shorten the time required for agricultural work.
Various types of sensor devices installed on agricultural machinery collect data related to environmental conditions of the field and crop growth status. The collected data is used for the establishment of optimal production management strategies and optimization (update) of agricultural works plan to improve the productivity (convenience, operating cost) of farmhouse through AI-based analysis. Farmers can monitor the operational status of the agricultural machinery and the progress of the agricultural work anytime, anywhere through web or mobile devices, and can also transmit appropriate instructions in case of changes in the farming plan or equipment failures.
- Expected devices
-
- Communication device for data sharing between agricultural machinery and farm operation system
- GNSS (Global navigation satellite system) device or other geolocation system for tracking and monitoring the location of agricultural machinery
- IoT sensor devices for collecting environmental conditions and crop-growth status of farmland
- Operation recording devices of agricultural machinery and component failure monitoring sensors
- Data analysis systems for optimizing agricultural works plan and agricultural machinery management model
- Expected data
-
- Data including type of agricultural works, necessary agricultural machinery, required working hours for agricultural works plan according to crop-growth stages
- Operation status of the agricultural machinery, including location, operation status, fuel consumption, failure occurrence, etc.
- Environmental condition data of farmland and crop-growth status data collected from IoT sensor devices
- Agricultural work progress status and result report data
- Historical data related to agricultural works and agricultural machinery
- Dependencies - Affected WoT deliverables and/or work items
- WoT Thing Description
- Description
-
Efficient management of agricultural machinery is achieved through systematic management of various data, such as optimal agricultural works plans, machinery operation status, agricultural works execution results, and history of malfunctions or damages. This data can be analyzed based on AI and big data technology to establish the optimal production management strategy. Through this series of procedures, farm productivity can be improved.
The farmer or agricultural machinery management service provider establish an agricultural works plan based on data such as the location of farmland, the types of agricultural works required, the time required to perform the agricultural works, the types of agricultural machinery required and their availability, and the history of past agricultural works execution. The establishment of the agricultural works plan is crucial because it serves as the basis for efficiently operating and managing agricultural machinery at the lowest cost possible. To establish an agricultural works plan, the farmer's requirements must be reflected, and consulting results from an agricultural expert group or expert system should be incorporated as necessary. The system may also take into account factors such as local weather conditions and forecasts, including historical conditions such as accumulated precipitation. Management of machinery can also take into account predicted events, such as the possible need for maintenance or repairs.
Based on the established agricultural works plan, the necessary agricultural machinery is deployed and executes the corresponding agricultural works. During the process of agricultural works, the agricultural machinery collects and reports data on its operating status, occurrence of malfunctions or damages, agricultural works execution status and its results, as well as the status of the farmland and crops-growth to the farm operation system. The farm operation system can monitor the agricultural works progress in real-time, and can modify the agricultural works plan to immediately deploy the machinery that is not yet deployed or that can finish the assigned agricultural work soon, thus improving the operational efficiency of the agricultural machinery for the farm.
The farm operation system analyzes the collected data comprehensively and utilizes it to update existing agricultural works plan and optimize production management strategies for the improvement of farm productivity. The collected and analyzed data can be shared with stakeholders, such as service providers, agricultural machinery manufacturers, and maintenance companies. Based on the shared data, service providers can improve the quality of agricultural machinery management services, while agricultural machinery manufacturers and maintenance companies can utilize the data to produce and maintain agricultural machinery that is optimized for the agricultural works demanded by farmers. Additionally, farmers can monitor the progress status and results of agricultural works through web or mobile devices.
- Variants
- In small-scale farms, individual systems can be installed for managing agricultural machinery, but for managing various types of machinery in large-scale farms, it would be more cost-effective to use agricultural machinery management services provided by related business. In this case, the agricultural machinery is directly connected to the cloud server of the service provider to receive instructions for performing agricultural works and to report the results of the agricultural works.
- Security Considerations
- This use case does not define specific considerations for security issues. However, all data collected and analyzed for the agricultural machinery management should be managed using well-defined security technologies.
- Privacy Considerations
- In order to safeguard the agricultural technology utilized by farmers and maintain their competitiveness, it is essential to establish a structured approach for accessing all the data collected and shared during agricultural machinery management. Only stakeholders who have a pre-existing contract or agreement may be granted access to the data that is intended to be shared or distributed.
- Accessibility Considerations
- None.
- Internationalisation (i18n) Considerations
- The data formats and units need to be adapted to the local standards, instructions need to be made available in the farmer's language, and scheduling needs to take into account cultural differences, such as holidays, daylight saving changes, or required breaks and hours for workers.
- Requirements
-
- Protocol Requirements: Flexible.
- Contents Type Requirements: Flexible.
- Platform or Standard Requirements: None.
- Authentication and Authorization Mechanisms Requirements: Flexible.
- Communication Requirements: Diverse agricultural machinery and farm operation systems must be connected through a communication network to direct agricultural works and transmits the agricultural works execution results and collected data. As agricultural machinery is placed across a significantly large area for agricultural works, wireless communication methods utilizing technologies such as GSM, UMTS, LTE, CDMA, or 5G should be considered.
- Data Expression Requirement: Farmers may need or want to use equipment from various different manufacturers, either simultaneously or over time. Therefore, various data for agricultural machinery management should be represented in a standardized format that is independent of the type or manufacturer of the agricultural machinery or equipment. Furthermore, all of this data must be stored and managed in a separate repository to maintain a history of the data, and data interoperability must be ensured.
- Gaps
- None.
- Existing Standards
- None.
- Comments
- None.
Smart City
Smart City Geolocation
- Submitter(s)
- Jennifer Lin, Michael McCool
- Target Users
-
A Smart City managing mobile devices and sensors, including passively mobile sensor packs, packages, vehicles, and autonomous robots, where their location needs to be determined dynamically.
- Motivation
-
Smart Cities need to track a large number of mobile devices and sensors. Location information may be integrated with a logistics or fleet management system. A reusable geolocation module is needed with a common network interface to include in these various applications. For outdoor applications, GPS could be used, but indoors other geolocation technologies might be used, such as WiFi triangulation or vision-based navigation (SLAM). Therefore the geolocation information should be technology-agnostic.
NOTE: we prefer the term "geolocation", even indoors, over "localization" to avoid confusion with language localization.
- Expected Devices
-
One of the following:
- A geolocation system on a personal device, such as a smart phone.
- A geolocation system to be attached to some other portable device.
- A geolocation system attached to a mobile vehicle.
- A geolocation system on a payload transported by a vehicle.
- A geolocation system on an indoor mobile robot.
- Expected Data
-
- Sensor ID
- Timestamp of last geolocation
- 2D location
- typically latitude and longitude
- May also be semantic, i.e. room in a building, exit
-
Optional:
- Semantic location
- Possibly in addition to numerical lat/long location.
- Altitude
- May also be semantic, i.e. floor of a building
- Heading
- Speed
- Accuracy information
- Confidence interval, e.g. distance that true location will be within some probability.
- Gaussian covariance matrix
- For each measurement
- For lat/long, may be a single value (see web browser API; radius?)
- Geolocation technology (GPS, SLAM, etc.).
- Note that multiple technologies might be used together.
- Include parameters such as sample interval, accuracy
- For each geolocation technology, data specific to
that technology:
- GPS: NMEA type [[NMEA-0183]]
- Historical data
Note: the system should be capable of notifying consumers of changes in location. This may be used to implement geofencing by some other system. This may require additional parameters, such as the maximum distance that the device may be moved before a notification is sent, or the maximum amount of time between updates. Notifications may be sent by a variety of means, some of which may not be traditional push mechanisms (for example, email might be used). For geofencing applications, it is not necessary that the device be aware of the fence boundaries; these can be managed by a separate system.
- Semantic location
- Dependencies
- node-wot
- Description
-
Smart Cities have the need to observe the physical locations of large number of mobile devices in use in the context of a Fleet or Logistics Management System, or to place sensor data on a map in a Dashboard application. These systems may also include geofencing notifications and mapping (visual tracking) capabilities.
- Variants
-
- A version of the system may log historical data so the past locations of the devices can be recovered.
- Geolocation technologies other than GPS may be used. The payload may contain additional information specific to the geolocation technology used. In particular, in indoor situations technologies such as WiFi triangulation or (V)SLAM may be more appropriate.
- Geofencing may be implemented using event notifications and will require setting of additional parameters such as maximum distance.
- Security Considerations
-
High-resolution timestamps can be used in conjunction with cache manipulation to access protected regions of memory, as with the SPECTRE exploit. Certain geolocation APIs and technologies can return high-resolution timestamps which can be a potential problem. Eventually these issues will be addressed in cache architecture but in the meantime a workaround is to artificially limit the resolution of timestamps.
- Privacy Considerations
-
Location is generally considered private information when it is used with a device that may be associated with a specific person, such as a phone or vehicle, as it can be used to track that person and infer their activities or who they associate with (if multiple people are being tracked at once). Therefore APIs to access geographic location in sensitive contexts are often restricted, and access is allowed only after confirming permission from the user.
- Gaps
-
There is no single standardized semantic vocabulary for representing location data. Location data can be point data, a path, an area or a volumetric object. Location information can be expressed using multiple standards, but the reader of location data in a TD or in data returned by an IoT device must be able to unambiguously describe location information.
There are both dynamic (data returned by a mobile sensor) and static (fixed installation location) applications for geolocation data. For dynamic location data, some recommended vocabulary to annotate data schemas would be useful. For static location data, a standard format for metadata to be included in a TD itself would be useful.
- Existing Standards
-
- NMEA: defines sentences from GPS devices [[NMEA-0183]]
- World Geodetic System (WGS84) [[WGS84]]:
- Defines lat/long/alt coordinate system used by most other geolocation standards
- More complicated than you would think (need to deal with deviations of Earth from a true sphere, gravitational irregularities, position of centroid, etc. etc.)
- Basic Geo Vocabulary [[w3c-basic-geo]]:
- Very basic RDF definitions for lat, long, and alt
- Does not define heading or speed
- Does not define accuracy
- Does not define timestamps
- Uses string as a data model (rather than a number)
- W3C Geolocation API [[geolocation-API]]:
- W3C Devices and Sensors WG is now handling
- There is an updated proposal: https://w3c.github.io/geolocation-sensor/#geolocationsensor-interface
- Data schema of updated proposal is similar to existing API, but all elements are now optional
- Data includes latitude, longitude, altitude, heading, and speed
- Accuracy is included for latitude/longitude (single number in meters, 95% confidence, interpretation a little ambiguous, but probably intended to be a radius) and altitude, but not for heading or speed.
- Open Geospatial Consortium [[OGC]]:
- See OGC Abstract Specification Topic 2: Referencing by coordinates [[OGC-coords]]
- Referring to locations by coordinates
- Has standards defining semantics for identifying locations
- Useful for mapping
- ISO:
- ISO 19111 [[iso-19111-2007]],
[[iso-19111-2019]]
- Standard for referring to locations by coordinates
- Related to OGS standard above and WGS84
- Various other standards that relate to remote sensing, geolocation, etc.
- Here is an example (see references): https://www.iso.org/obp/ui/#iso:std:iso:ts:19159:-2:ed-1:v1:en
- ISO 19111 [[iso-19111-2007]],
[[iso-19111-2019]]
- Semantic Sensor Network Ontology (SSN/SOSA)
[[vocab-ssn]]:
- Defines "accuracy": https://www.w3.org/TR/vocab-ssn/#SSNSYSTEMAccuracy
- Definition of accuracy is consistent with how it is used in Web Geolocation API
- Also defines related terms Precision, Resolution, Latency, Drift, etc.
- Timestamps:
- W3C High Resolution Time [[hr-time-3]]
- See also related issues such as latency defined in SSN
Note that accuracy and time are issues that apply to all kinds of sensors, not just geolocation. However, the specific geolocation technology of GPS is special since it is also a source of accurate time.
Smart City Dashboard
- Submitter(s)
- Michael McCool
- Target Users
-
A Smart City managing a large number of devices whose data needs to be visualized and understood in context.
Stakeholders include:
- Device Owners: need to make data from devices available to dashboard system.
- Device User: users of the dashboard system, such as members of city management, are indirectly "using" the devices by accessing their data, and in one variant, sending commands to actuators.
- Cloud Provider: the dashboard system itself or components of it (such as a database or data ingestion system) may be hosted in the cloud.
- Motivation
-
In order to facilitate Smart City planning and decision-making, a Smart City dashboard interface makes it possible for city management to view and visualize all sensor data through the entire city in real time, with data identified as to geographic source location.
- Expected Devices
-
Actuators can include robots; for these, commands might be given to robots to move to new locations, drop off or pick up sensor packages, etc. However, it could also include other kinds of actuators, such as flood gates, traffic signals, lights, signs, etc. For example, posting a public message on an electronic billboard might be one task possible through the dashboard.
Sensors can include those for the environment and for people and traffic management (density counts, thermal cameras, car speeds, etc.). status of robots, other actuators, and sensors, data visualization, and (optionally) historical comparisons.
Dashboard would include mapping functionality. Mapping implies a need for location data for every actuator and sensor, which could be acquired through geolocation sensors (e.g. GPS) or assigned statically during installation.
This use case also includes images from cameras and real-time image and data streaming.
- Expected Data
-
- Environmental data for temperature, humidity, UV levels, pollution levels, etc.
- Infrastructure status (water flow, electrical grid, road integrity, etc.)
- Emergency sensing (flooding, earthquake, fire, etc.)
- Traffic (both people and vehicles)
- Health monitoring (e.g.fever tracking, mask detection, social distancing)
- Safety monitoring (e.g.wearing construction helmets on a construction site)
- Reports from non-IoT sources (for example, police reports of crimes, hospital emergency case reports)
- Images and data derived from images (people traffic and density can be derived from image analysis). All data would need an associated geolocation and timestamp so it can be placed in time and space.
- Affected WoT deliverables and/or work items
-
- Thing description - support for data ingestion and normalization, geolocation and timestamp standards.
- Discovery - directories capable of tracking and managing a large number of devices on a large and possibly segmented network
- Description
-
Data from a large number and wide variety of sensors needs to be integrated into a single database and normalized, then placed in time and space, and finally visualized.
The user, a member of city management responsible for making planning decisions, sees data visualized on a map suitable for planning decisions.
Variants:
- Historical data may also be available (allowing an analysis of trends over time).
- It may be possible to also issue commands to actuators through the interface.
- The system may be used for emergency response (for instance, closing floodgates in response to an expected tsunami)
- A subset of the data visualization capabilities may be made available to the public (for example, traffic)
- Filtering based on parameters such as location (area, state, county, country, zip code, etc.), sensor type, subject matter, etc.
- Ability to generate alerts off of various parameters
- Ability to produce logs off historical data
- Security Considerations
-
- Access to data should only be provided to authorized users, although some may be made available publicly
- Access to actuators should only be provided to authorized users, and commands should be recorded for auditing.
- Privacy Considerations
-
- Management of privacy-sensitive information, for example images of people, should be controlled and ideally not associated with specific individuals
- Data that can be used to track movements of particular individuals should be controlled or eliminated.
- Data purge functions should be supported to allow the permanent deletion of private data.
- Gaps
-
- Geolocation data standards
- Timestamp data standards
- Scalable Discovery
Interactive Public Spaces
- Submitter(s)
- Michael McCool
- Category
- Accessibility
- Motivation
- Public spaces provide many opportunities for engaging, social and fun interaction. At the same time, preserving privacy while sharing tasks and activities with other people is a major issue in ambient systems. These systems may also deliver personalized information in combination with more general services presented publicly. A trustful discovery of the services and devices available in such environments is a necessity to guarantee personalization and privacy in public-space applications.
- Expected Devices
- Public spaces supporting personalizable services and device access.
- Expected Data
-
Command and status information transferred between the
personal mobile device application and the public
space's services and devices.
Profile data for user preferences. - Dependencies
-
- WoT Thing Description
- WoT Discovery
-
Optional:
- WoT Scripting API in application on mobile personal device and possibly in IoT orchestration services in the public space.
- Description
- Interactive installations such as touch-sensitive or gesture-tracking billboards may be set up in public places. Objects that present public information (e.g. a map of a shopping mall) can use a multimodal interface (built-in or in tandem with the user's mobile devices) to simplify user interaction and provide faster access. Other setups can stimulate social activities, allowing multiple people to enter an interaction simultaneously to work together towards a certain goal (for a prize) or just for fun (e.g. play a musical instrument or control a lighting exhibition). In a context where privacy is an issue (for example, with targeted/personalized alerts or advertisements), the user's mobile device acts as a mediator for the services running on the public network. This allows the user to receive relevant information in the way they see fit. Notifications can serve as triggers for interaction with public devices and services if the user chooses to do so.
- Variants
- The user may have additional mobile devices they want to incorporate into an interaction, for example a headset acting as an auditory aid or personal speech output device.
- Gaps
- Data format describing user interface preferences.
- Existing Standards
- This use case is based on MMI UC 3.1 [[mmi-use-cases]].
- Comments
- Does not include Requirements section from original MMI use case.
Meeting Room Event Assistance
- Submitter(s)
- Michael McCool
- Category
- Accessibility
- Expected Devices
- Meeting space supporting personalizable services and device access.
- Expected Data
- Command and status information transferred between the personal mobile device application and the meeting space's services and devices. Profile data for user preferences.
- Dependencies
-
- WoT Thing Description
- WoT Discovery
- Optional: WoT Scripting API in application on mobile personal device and possibly in IoT orchestration services in the meeting space.
- Description
- A conference room where a series of meetings will take place. People can go in and out of the room before, after and during the meeting. The door is "touched" by a badge. An application on the user's mobile device can activate any available display in the room and the room and can access and receive notification from devices and services in the room. The chair of the meeting is notified by a dynamically composed graphic animation, audio notification or a mobile phone notification, about available devices and services, and can install applications indicated by links. The chair of the meeting selects a setup procedure by text amongst the provided links. These options could be, for example: photo step-by-step instructions (smartphone, HDTV display, Web site), audio instructions (MP3 audio guide, room speakers reproduction, HDTV audio) or RFID enhanced instructions (mobile SmartTag Reader, RFID Reader for smartphone). The chair of the meeting chooses the room speakers reproduction, then the guiding Service is activated and they start to set the video projector. After some attendees arrive, the chair of the meeting changes to the slide show option and continues to follow the instructions at the same step it was paused but with another more private modality for example, a smartphone slideshow.
- Variants
- The user may have additional mobile devices they want to incorporate into an interaction, for example a headset acting as an auditory aid or personal speech output device.
- Gaps
- Data format describing user interface preferences. Ability to install applications based on links that can access IoT services.
- Existing Standards
- This use case is based on MMI UC 3.2 [[mmi-use-cases]].
- Comments
- Does not include Requirements section from original MMI use case.
Cross-Domain Discovery in a Smart Campus
- Submitter(s)
- Andrea Cimmino and Raúl García Castro
- Target Users
-
- Device Owners
- Service Provider
- network operator (potentially transparent for WoT use cases)
- directory service operator
- Motivation
- In this use case a network full of IoT devices is presented, in which these devices are registered in several Middle-Nodes. The challenge presented in this scenario is to be able to discover the different sensors, by issues a SPARQL query, and without having prior knowledge of where those devices are allocated. Therefore, the discovery SPARQL query must start from a specific Middle-Node and reach all those Middle-Nodes that are relevant to answer the query. This scenario requires that discovery does not only happen locally when a Middle-Node receives the query and checks if some Thing Description registered is suitable to answer the query. Instead, the scenario requires also that the Middle-Node forwards the query through the network (topology conformed by the middle-nodes) in order to find those Middle-Nodes that actually contain relevant Thing Descriptions. Notice from the following example that the query is not broadcasted in the network to prevent flooding, instead the Middle-Nodes follow some discovery heuristic to know where the query should be forwarded. Also, notice that in this scenario not all the Middle-Nodes have the IoT devices registered directly within, they are Middle-Nodes collectors, such as Middle-Node C, I, G, and D.
- Expected Devices
- Any device from the energy context (e.g. solar panels, smart plugs, or smart energy meters), devices from the building context (e.g. light bulbs, light switches, occupancy sensors, or thermostats), devices from the environmental context (e.g. soil moisture, flood detection, or air humidity), devices from the wearables context (e.g. smart bands), and/or devices from the water context (e.g. water valves, or water quality sensors)
- Expected Data
- Data coming from different contexts, such as Energy, Building, Environmental Wearables and Water.
- Affected WoT deliverables and/or work items
- Current WoT-Discovery approach
- Description
-
A campus has a wide range of IoT devices distributed
across their grounds. These IoT devices belong to very
different domains in a smart city, such as, energy,
buildings, environment, water, wearable, etc. The IoT
devices are distributed across the campus and belong to
different infrastructures or even to individuals. A
sample topology of this scenario could be the
following:

In this scenario, energy-related IoT devices monitor the energy use and income in the campus, among other things. From these measurements, an Energy Management System may predict a negative peak of incoming energy that would entail the failure of the whole system. In this case, a Service or a User needs to discover all those IoT devices that are not critical for the normal functioning of the campus (such as indoor or outdoor illumination, HVAC systems, or water heaters) and interact with them in order to save energy, by switching them off or reducing their consumption. Besides, the same Service or User will look for those IoT devices that are critical for the well-functioning of the campus (such as magnetic locks, water distribution system, or fire/smoke sensors) and ensure that they are up and running. Additionally, the Service or the User, will discover relevant people's wearable to warn them about the situation.Sample flow:
A service, or a user, sends a (SPARQL) query to the discovery endpoint of a known Middle-Node (which can be wrapped by a GUI). The Middle-Node will try to answer the query first checking the Thing Descriptions of the IoT devices registered in such Middle-Node. Then, if the query requires further discovery, or it was not successfully answered the Middle-Node will forward the query to its *known* Middle-Nodes. Recursively, the Middle-Nodes will try to answer the query and/or forward the query to their known Middle-Nodes. When one Middle-Node is able to answer the query it will forward back to the former Middle-Node the partial query answer. Finally, when the discovery task finishes, the former Middle-Node will join all the partial query answers producing an unified view (which could be synchronous or asynchronous).
For instance, assuming Middle-Node F receives a query that asks about all the discoverable Building IoT devices in the campus. First, the Middle-Node F will try to answer the query with the Thing Descriptions of the IoT registered within. Since Middle-Node F contains some Building IoT devices a partial query answer is achieved. However, since they query asked about all the discoverable Building IoT devices Middle-Node F should forward the query to its other known Middle-Nodes, i.e., Middle-Node G. This process will be repeated by the Middle-Nodes until the query reaches the Middle-Nodes H and B which are the ones that have registered Thing Descriptions about IoT buildings. Therefore, the query will travel through the topology as follows:

Finally, when Middle Nodes B and H compute two partial query answers, those answers will be forwarded back to Middle-Node F which will join them with its former partial query answer obtained from its registered Thing Descriptions. Finally, a global query answer will be provided. - Security Considerations
- None, in this case an underneath infrastructure that handles security is assumed
- Privacy Considerations
- None, although relevant in this case the core of the use case relies on the feature of finding across the network different IoT devices. It is assumed that there is an underneath infrastructure that handles privacy
- Gaps
- Been able to find suitable Middle-Nodes that are relevant to answer the query, with no prior knowledge
- Existing Standards
- None
- Comments
- None
Cultural Spaces (Museums)
- Submitter(s)
- Konstantinos Kotis, K. Zachila, A. Dimara
- Target Users
- Motivation
-
This use case is related to the semantic modeling of trustworthy IoT entities in energy-efficient cultural spaces such as museums.
Nowadays, energy-saving issues have awakened the research community's interest due to the more and more increasing global electricity demand. An excessive use of energy is believed to derive from public and industrial buildings to cover their daily load requirements in the context of the provision of their services. Thus, the necessity of developing energy-efficient buildings could be proved beneficial. Notably, the improvement of buildings' energy efficiency leads to Building Energy Management Systems (BEMS).
BEMS objectives include but not limited to:- the continuous management of energy towards energy consumption optimization;
- the optimization of buildings' visiting conditions towards enhancing visitors experience and comfort,
- the optimization of buildings' environmental conditions towards the protection and preservation of artifacts (indirect contribution).
The application of BEMS in the context of energy-saving at cultural spaces, and especially at the museums' spaces, is an evolving recent research interest. The protection and preservation of artworks and ancient objects isolated in museums, leads to the necessity of continuous monitoring of the environmental factors and indoor conditions like temperature, humidity and CO2. This monitoring involves Internet of Things (IoT) entities, which may be considered as an integral part of BEMS, to reduce energy consumption without: a) sacrificing humans' visiting experience and comfort indoor levels, and b) sacrificing artworks' protection and preservation.
The aim of the presented use case is to sketch and highlight the following requirements for knowledge representation:- representing knowledge related to the trustworthy IoT entities that are deployed in a museum i.e., things (e.g, exhibits, spaces), sensors, actuators, people, data, applications;
- dealing with entities' heterogeneity via semantic interoperability and integration, especially for 'smart' museum applications and generated data;
- representing knowledge related to saving energy e.g., lights, air-conditioning;
- representing knowledge related to museum visits and visitors towards enhancing visiting experience while preserving comfort;
- representing knowledge related to environmental conditions towards protecting and preserving museum artwork via continuous monitoring.
- Requirement (a) (trustworthy IoT entities representation and management): Count all the sculptures of the museum that are related to visits made by trustworthy students (with a trust degree more than 0.8). Name all the trustworthy paintings of the museum created by "Picasso" (paintings that were created by Picasso with a trust degree more than 0.9).
- Requirement (b) (interoperability and integration): If there are more than two visitors in room "UoAMuseumRoomA1" close to (nearby) an exhibit, classify this exhibit as an "interesting exhibit in room UoAMuseumRoomA1", turn up the light of this exhibit, and lower the light of the remaining exhibits in the room. This scenario is related to objectives (c) and (d) at the same time. If the temperature of room "UoAMuseumRoomA1" and room "UoA-MuseumRoomA2" is less than 18 degrees Celsius, and there are visits in progress in these rooms, then activate the heating device in the rooms that those visits take place, and deactivate other sources of energy in the remaining rooms of the building.
- Requirement (c) (energy saving): If there are no visitors in room "UoAMuseumRoomA1", then turn the lights off (or all the sources of energy). If the museum's internal and external temperature is between 20 and 30 degrees Celsius, then keep the heating and cooling devices off.
- Requirement (d) (enhancing visiting experience and comfort): When a visitor enters the museum for the first time, send him a message (e.g., SMS or tweet) with the number and types of rooms, the number and collections of exhibits, and the average duration of a visit per room. If a visitor comes out of the museum, then send him a message with the names of the exhibits he liked most based on the observations he made during his/her visit.
- Requirement (e) (environmental conditions): If the temperature in room "UoAMuseumRoomA1" is less than 18 degrees Celsius, then activate the heating device (for visitors' comfort). If the humidity in room A is more than 55%, then activate the humidifier device (for exhibits protection). In respect to current WoT Things Description, the requirement here is to extend schema in order to represent trust (trustworthy things, trustworthy devices, trustworthy IoT entities in general).
- Expected Devices
- Humidity sensor, temperature sensor, motion sensor, light sensor, proximity sensor, camera, air quality sensor, humidifier, light, smart lamp, smart lock, smart door.
- Expected Data
- Weather (indoors/outdoors) and climate data, sensor data, visitors/visiting data, profile data, movement (trajectory) data, cultural data.
- Dependencies - Affected WoT deliverables and/or work items
- Web of Things Thing Description (WoT TD): to represent trust (trustworthy things and trustworthy IoT entities in general i.e., devices, people, processes, data).
- Description
-
From users perspective, this use case sketches knowledge
required for an ontology-based BEMS to answer queries
such as:
- Which exhibits are located in UoAMuseumRoomA1?
- How many sensors (all kinds) are hosted by IoTmuseumPlatformLG?
- Which rooms have been visited by Visitor01?
- What temperature measurements have been made in UoAMuseumRoomA1 between 09.00 and 17.00 on 07/12/2020?
- For observations that are made for Painting01 (in UoAMuseumRoomA1) at 09.00 on 15/01/2021, what is its status in terms of its lamp brightness level and nearby visitors?
Reasoning with this knowledge, the identification of interesting exhibits and energy-related observations (based on sensing visitors' proximity to exhibits and observation of exhibits' lamp brightness level) is realized.
For instance, if the brightness level of an exhibit's lamp is "medium" and there are more than two visitors near the exhibit, then this observation is classified as a) an interesting-exhibit observation and b) an observation to high level energy, meaning that the level of energy (light) for the lamp of the exhibit of this observation must be raised to high. In addition (another example), if the brightness level of the exhibit's lamp is "medium" and less than two visitors are nearby this, then classify this as an observation to low level energy, meaning that the level of energy (light) for the lamp of the exhibit of this observation must be raised to low. These examples indicate that a change (decrease or increase) to the level of light (energy) of the observed exhibit must be applied.
- Security Considerations
- Due to visitors/visiting and profile data access requirement, as well as access to data related to public/private buildings, security issues must be considered.
- Privacy Considerations
- Due to visitors/visiting and profile data access requirement, as well as access to data related to public/private buildings, privacy issues must be considered.
- Accessibility Considerations
- Accessibility must be a concern in the Cultural Spaces domain. Collaboration with the W3C Linked Data for Accessibility Community Group is needed.
- Internationalisation (i18n) Considerations
- Internationalization must be a concern as the Culture is an international industry. Need to provide multilanguage labels in different languages e.g., English, French, Chinese.
- Requirements
- Gaps
-
Web of Things Thing Description (WoT TD): representation of IoT entities trust (trustworthy things, trustworthy IoT entities in general i.e., devices, people, processes, data). An IoT-trust related knowledge representation (in OWL) is provided by Kotis et al. as an example: https://github.com/KotisK/IoTontos/blob/master/Ontologies/IoT/IoT-trust-onto-v06.owl (or https://i-lab.aegean.gr/kotis/Ontologies/IoT/IoT-trust-onto-v06.owl).
Related paper: Kotis, K., I. Athanasakis, and G. A. Vouros, "Semantically Enabling IoT Trust to Ensure and Secure Deployment of IoT Entities", Int. J. of Internet of Things and Cyber-Assurance, vol. 1, issue 1: Inderscience, pp. 3-21, 2018. (http://www.inderscience.com/storage/f596810317421112.pdf)
- Existing standards
-
- SAREF4ENER ETSI Standard [[SAREF4ENER]]
- SAREF4BLDG ETSI Standard [[SAREF4BLDG]]
- Semantic Sensor Network Ontology (SSN/SOSA) [[vocab-ssn]]
- Comments
-
This use case has been driven by the research directions
discussed in the following papers:
- Zachila, K., K. Kotis, A. Dimara, S. Ladikou, and C. N. Anagnostopoulos, "Semantic modeling of trustworthy IoT entities in energy-efficient cultural spaces", 17th International Conference on Artificial Intelligence Applications and Innovations (AIAI 2021), Crete, Springer, 2021
- Dimara, A., C. N. Anagnostopoulos, K. Kotis, S. Krinidis, and T. Tzovaras, "BEMS in the Era of Internet of Energy: A Review", 17th International Conference on Artificial Intelligence Applications and Innovations (AIAI 2021), Crete, Springer, 2021.
Building Technologies
Smart Building
- Submitter(s)
- Sebastian Käbisch
- Target Users
- Motivation and Description
- Buildings such as office buildings, hotels, airports, hospitals, train stations and sports stadiums typically consist of heterogeneous IoT systems such as lightings, elevators, security (e.g. door control), air-conditionings, fire warnings, heatings, pools, parking control, etc. Monitoring, controlling, and management of such a heterogeneous IoT landscape is quite challenging in terms of engineering and maintenance.
- Expected Devices
- All kind of sensors and actuators (e.g. HVAC).
- Expected Users
-
- systems engineers
- system administrators
- third party user
- Expected Data
- Heterogeneous data models from different IoT systems such as BACnet, KNX, and Modbus.
- Affected WoT deliverables and/or work items
- WoT Thing Description and Thing Model, WoT Architecture, WoT Binding Templates (covering protocol specifications)
- Existing Standards
- BACnet [[BACnet]], KNX [[KNX]], OPC UA [[OPC-UA]], Modbus [[Modbus]]
Connected Building Energy Efficiency
- Submitter(s)
- Farshid Tavakolizadeh
- Target Users
-
- Device Owners
- Device User
- directory service operator
- Motivation
- Construction and renovation companies often deal with the challenge of delivering target energy-efficient buildings given specific budget and time constraints. Energy efficiency, as one of the key factors for renovation investments, depends on the availability of various data sources to support the renovation design and planning. These include climate data and building material along with residential comfort and energy consumption profiles. The profiles are created using a combination of manual inputs and sensory data collected from residents.
- Expected Devices
-
- Gateway (e.g. Single-board computer with a Z-Wave controller)
- Power Meter
- Gas Meter
- Smart Plug
- Heavy Duty Switch
- Door/Window Sensors
- CO2 Sensor
- Thermostat
- Multi-sensors (Motion, Temperature, Light, Humidity, Vibration, UV)
- Expected Data
-
- Ambient conditions
- Occupancy model
- Description
- Renovation of residential buildings to improve energy efficiency depend on a wide range of sensory information to understand the building conditions and consumption models. As part of the pre-renovation activities, the renovation companies deploy various sensors to collect relevant data over a period of time. Such sensors become part of a wireless sensor network (WSN) and expose data endpoint with the help of one or more gateway devices. Depending on the protocols, the endpoints require different interaction flows to securely access the current and historical measurements. The renovation applications need to discover the sensors, their endpoints and how to interact with them based on search criteria such as the physical location, mapping to the building model or measurement type.
- Privacy Considerations
- The TD may expose personal information about the building layout and residents.
- Gaps
-
There is no standard vocabulary for embedding
application-specific meta data inside the TD. It is
possible to extend the TD context and add additional
fields but with too much flexibility, every application
may end up with a completely different structure, making
such information more difficult to discover. In this
use-case, the application specific data are:
- the mapping between each thing and the space in the building model
- various identifiers for each thing (e.g. sensor serial number, z-wave ID, SenML name)
- indoor coordinates
- Existing Standards
-
- OGC Sensor Things [[OGC-Sensor-Things]] model includes a `properties` property for each Thing which is a non-normative JSON Object for application-specific information (not to be confused with TD's `properties` which is a Map of instances of PropertyAffordance
Automated Smart Building Management
- Submitter(s)
- Edison Chung, Hervé Pruvost, Georg Ferdinand Schneider
- Category
- Smart Building
- Target Users
-
- Device Owners
- Device User
- Service Provider
- Device Manufacturer
- Gateway Manufacturer
- Identity Provider
- directory service operator
- Motivation
-
When operating smart buildings, aggregating and managing all data provided by heterogeneous devices in these buildings still require a lot of manual effort. Besides the hurdles of data acquisition that relies on multiple protocols, the acquired data generally lacks contextual information and metadata about its location and purpose. Usually, each service or application that consumes data from building things requires information about its content and its context like, e.g.:
- which thing produces the data (sensor, meter, actuator, other technical component...) in a building;
- which physical quantity or process is represented (temperature, energy supply, monitoring, actuation);
- which other building things are involved (e.g. sensor hosted by a duct or a space).
Through the increased use of model-based data exchange over the whole life cycle of a building, often referred to as Building Information Modeling (BIM) (Sacks et al., 2018), a curated source for data describing the building itself is available including, amongst others, the topology of the building structured into e.g. sites, stores and spaces.
Automatically tracking down data and their related things in a building would especially ease the configuration and operation of Building Automation and Control Systems (BACS) and Heating Ventilation and Air-Conditioning (HVAC) services during commissioning, operation, maintenance and retrofitting. To tackle these challenges, still, building experts make use of metadata and naming conventions which are manually implemented in Building Management Systems (BMS) databases to annotate data and things. An important property of a thing is its location within the topology of a building as well as where its related data are produced or used. For example, this applies to the temperature sensor of a space, the temperature setpoint of a zone, a mixing damper flap actuator of a HVAC component, etc. In addition, other attributes of things are of interest, such as cost or specific manufacturer data. One difficulty is especially the lack of a standardized way of creating, linking and sharing this information in an automated manner. On the contrary, manufacturers, service providers and users introduce their own metadata for their own purpose. As a solution, the Web of Things (WoT) Thing Description (TD) aims at providing normalized and syntactic interoperability between things.
To support this effort, this use case is motivated by the need to enhance semantic interoperability between things in smart buildings and to provide them with contextual links to building information. This building information is usually obtained from a BIM model. The use case builds on Web of Data technologies and reuses schemas available from the Linked Building Data domain. It should serve as a use case template for many applications in an Internet of Building Things (IoBT).
- Expected Devices
-
- Actuators
- Sensors
- Devices from the building context
- Devices from the HVAC system
- Smart devices
- Expected Data
-
- Sensor ID
- Thing Descriptions
- Protocol integrations
- Sensor readings
- Building topology
- Semantic location
- Geolocation
- Affected WoT deliverables and/or work items
-
- Web of Things (WoT) Thing Description (TD) [[wot-thing-description]]
- Web of Things (WoT) Binding Templates [[wot-binding-templates]]
- WoT Discovery - Geolocation (Proposal) [[wot-geolocation-proposal]]
- Description
-
The goal of this use case is to show the potential to automate workflows and address the heterogeneity of data as observed in the smart building domain. The examples show the potential benefits of combining WoT TD with contextual data obtained from BIM.
The use cases is based on the Open Smart Home Dataset, which introduces a BIM model for a residential flat combined with observations made by typical smart home sensors. We extend the dataset with Thing Descriptions of some of the items. The respective Thing Description of a temperature sensor in the kitchen of the considered flat is as follows:
{ "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#TemperatureSensor", "@context": [ "https://www.w3.org/2019/wot/td/v1", { "osh": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#", "bot": "https://w3c-lbd-cg.github.io/bot#", "sosa": "http://www.w3.org/ns/sosa/", "om": "http://www.ontology-of-units-of-measure.org/resource/om-2/", "ssns": "http://www.w3.org/ns/ssn/systems/", "brick": "https://brickschema.org/schema/Brick#", "schema": "http://schema.org" } ], "title": "TemperatureSensor", "description": "Kitchen Temperature Sensor", "@type": ["sosa:Sensor", "brick:Zone_Air_Temperature_Sensor", "bot:element"], "@reverse": { "bot:containsElement": { "@id": "osh:Kitchen" } }, "securityDefinitions": { "basic_sc": { "scheme": "basic", "in": "header" } }, "security": [ "basic_sc" ], "properties": { "Temperature": { "type": "number", "unit": "om:degreeCelsius", "forms": [ { "href": "https://kitchen.example.com/temp", "contentType": "application/json", "op": "readproperty" } ], "readOnly": true, "writeOnly": false } }, "sosa:observes": { "@id": "osh:Temperature", "@type": "sosa:ObservableProperty" }, "ssns:hasSystemCapability": { "@id": "osh:SensorCapability", "@type": "ssns:SystemCapability", "ssns:hasSystemProperty": { "@type": ["ssns:MeasurementRange"], "schema:minValue": 0.0, "schema:maxValue": 40.0, "schema:unitCode": "om:degreeCelsius" } } }Where the contextual information on the measurement range of the sensor is specified using the SSNS schema. The location information of the thing TemperatureSensor is provided based on the Building Topology Ontology (BOT), a minimal ontology developed by the W3C Linked Building Data Community Group (W3C LBD CG) to describe the topology of buildings in the semantic web. Additionally, the thing description of the corresponding actuator is given below.
{ "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#TemperatureActuator", "@context": [ "https://www.w3.org/2019/wot/td/v1", { "osh": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#", "bot": "https://w3c-lbd-cg.github.io/bot#", "sosa": "http://www.w3.org/ns/sosa/", "ssn": "http://www.w3.org/ns/ssn/", "brick": "https://brickschema.org/schema/Brick#" } ], "title": "TemperatureActuator", "description": "Kitchen Temperature Actuator", "@type": ["sosa:Actuator", "brick:Zone_Air_Temperature_Setpoint", "bot:element"], "@reverse": { "bot:containsElement": { "@id": "osh:Kitchen" } }, "securityDefinitions": { "basic_sc": { "scheme": "basic", "in": "header" } }, "security": [ "basic_sc" ], "actions": { "TemperatureSetpoint": { "forms": [ { "href": "https://kitchen.example.com/tempS" } ] } }, "ssn:forProperty": { "@id": "osh:Temperature", "@type": "sosa:ActuatableProperty" } } - Combining Topological Context and Thing Descriptions
-
The scenario considered is related to the replacement of a temperature sensor in a BACS. The topological information localizing the things, e.g. the temperature sensor can be used to automatically commission the newly replaced sensor and link it to existing control algorithms. For this purpose, the identifiers of suitable sensors and actuators are needed and can be, for example, queried via SPARQL. Here the query uses some additional classification of sensors from the Brick schema, v1.1 [[Brick]].
PREFIX bot: <https://w3id.org/bot> PREFIX brick: <https://brickschema.org/schema/Brick#> PREFIX osh: <https://w3id.org/ibp/osh/OpenSmartHomeDataSet#> SELECT ?sensor ?actuator WHERE{ ?space a bot:Space . ?space bot:containsElement ?sensor . ?space bot:containsElement ?actuator . ?sensor a brick:Zone_Air_Temperature_Sensor . ?actuator a brick:Zone_Air_Temperature_Setpoint . }Similarly this data can be obtained via a REST API built upon the HTTP protocol. Below is an example endpoint applying REST style for getting the same information for a specific space name:
GET "https://server.example.com/api/locations?space=osh:Kitchen&sensorType=brick:Zone_Air_Temperature_Sensor&actuatorType=brick:Zone_Air_Temperature_Setpoint" API response: { "location": { "site": { "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#Site1", "name": "Site1" }, "building": { "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#Building1", "name": "Building1" }, "zone": null, "storey": { "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#Level2", "name": "Level2" }, "space": { "id": "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#Kitchen", "name": "Kitchen" }, "sensors": [ "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#TemperatureSensor" ], "actuators": [ "https://w3id.org/ibp/osh/OpenSmartHomeDataSet#TemperatureActuator" ] }In this example query, the REST endpoint has been defined using the OpenAPI specification and is provided by a RESTful server. A data binding is needed between the server and the underlying backend storage, here the triple store that contains the involved ontologies (osh, bot, ssn, brick...). The data binding relies on similar SPARQL queries as the one shown above. As a result the endpoint can deliver information to a target application that consumes custom JSON rather than triples. Similar implementations could be achieved using GraphQL.
- Automated Update of Fault Detection Rule based on Thing Description
-
Another related use case in smart buildings, which would greatly benefit from harmonised thing descriptions and attached location information is related to the detection of unexpected behavior, errors and faults. An example for such a detection of faults is the rule-based surveillance of sensor values. A generic rule applicable to sensors is that the observation values stay within the measurement range of the sensor. Again, in the case of maintenance as described above a sensor is replaced.
Some agent configuring fault detection rules can obtain the measurement range from the sensor's TD (see above) to obtain the parameters to configure the mentioned rule. Again, a query or API call retrieving this information (schema:minValue/ schema:maxValue) can be used to update the upper and lower bound of the values provided by the sensor.
- Security Considerations
-
Security in smart buildings is of importance. In particular, access control needs to be properly secured. This applies also for data access which can be secured using existing security schemes (API Keys, OAuth2...). Moreover, from certain observations, e.g. electricity consumption, clues can be indirectly given such as presence in a home. Hence, security needs must be defined and properly addressed.
- Privacy Considerations
-
Privacy considerations can be of a concern if observations of sensors can be matched to individuals. It is of the responsibility of building owners, managers and users to define their own privacy policies for their data and share necessary consents if necessary.
- Accessibility Considerations
-
Accessibility is a major concern in the buildings domain. Efforts exist in also providing accessibility data in a electronic format. The W3C LBD CG is in contact with the W3C Linked Data for Accessibility Community Group.
- Internationalization (i18n) Considerations
-
Internationalization is a concern as the Buildings industry is a global industry. This is reflected in some efforts, e.g. BOT used in the examples above does provide multilanguage labels in up to 16 different languages including English, French and Chinese.
- Existing Standards
-
- SAREF4BLDG ETSI Standard [[SAREF4BLDG]]
- Semantic Sensor Network Ontology (SSN/SOSA) [[vocab-ssn]]
- Industry Foundation Classes (IFC) an ISO standard
- Building Topology Ontology (BOT)
- Brick Schema [[Brick]]
- References:
Portable Building Applications
- Submitter(s)
- Gabe Fierro
- Target Users
-
- Device Owners
- Device User
- Cloud Provider
- Service Provider
- Device Manufacturer
- Gateway Manufacturer
- directory service operator
- Motivation
-
The growing adoption of energy management systems,
building automation and management systems and IoT
devices is producing larger volumes and varieties of
data. As a result, data-driven smart building
applications are becoming increasingly common and
practical to adopt. Examples of these applications
include:
- automated fault detection and diagnosis
- virtual metering (calculating the energy or power consumption of a subsystem that is not directly metered)
- building performance measurement and energy audits
- predictive occupancy, energy consumption models
- high-performance "sequences of operations" for various subsystems, such as HVAC
- Expected Devices
-
- Actuators
- Sensors
- Devices from the building context
- Devices from the HVAC system
- Smart devices
- Expected Data
-
- thing descriptions
- building system topology and composition
- building topology and composition
- Dependencies - Affected WoT deliverables and/or work items
-
- Web of Things (WoT) Thing Description (TD) [[wot-thing-description]]
- Description
-
In these settings, devices are usually not commercial off-the-shelf IoT devices, but rather "packaged units" and other "lower level" devices that perform physical tasks on behalf of a larger system: pumps, fans, variable frequency drives, variable air volume boxes and chillers are all examples. Such devices are connected to one another using wires, pipes, ducts and other mechanisms. Sensors, actuators and other data sources and sinks are associated with the devices in these subsystems. Through some digital control system, they relay telemetry on the current behavior, status and performance of devices and properties of the substances and media touched by the building subsystem.
It is important for descriptions of these systems to be built on standardized, well-known names for equipment and other devices in building subsystems. Reliance on generic terminology is not sufficient to distinguish the different kinds of systems and different kinds of equipment in a broadly consistent and interpretable manner. Research and practice shows that a common terminology must be established in order to reduce the costs associated with developing and deploying data-driven applications that touch the internals of cyber-physical systems.
To support this use case, WoT descriptions should describe the networked devices present in building subsystems and their data capabilities. These capabilities should be related to properties of the substances or media that a device is operating on. For example, a smart thermostat's API may present a "mode" as a read-only property. "Mode" commonly refers to what the thermostat is "calling for", e.g. cooling, heating, fan; this is commonly captured as a numerical value. The mode is read by HVAC equipment, such as a rooftop-unit, which then enacts the desired conditioning. The WoT description of the mode property should permit the determination of what properties of other devices and entities in the building may be affected by the value of the mode property. In this example, the mode property representation should indicate that the mode property indirectly affects the temperature of air in the rooms that are connected to the equipment controlled by the thermostat.
Example: Rogue Zone Detection
"Rogue zones" are regions of the building that drive demand by calling for heating or cooling significantly more than other zones. One simple way to detect rogue zones is to observe zones (which may consist of multiple rooms) which are consistently above or below their setpoint by more than some delta. The following SPARQL query uses Brick to identify the air temperature setpoint and sensors associated with terminal units, and to identify the zones fed by those terminal units.
PREFIX brick: <http://brickschema.org/schema/Brick#> SELECT ?term ?zone ?sat ?sp WHERE { ?term a brick:Terminal_Unit . ?zone a brick:HVAC_Zone . ?sat a brick:Supply_Air_Temperature_Sensor . ?sp a brick:Supply_Air_Temperature_Setpoint . ?term brick:feeds ?zone . ?term brick:hasPoint ?sat, ?sp . }Example: Measuring Temperature Before and After a Cooling Coil
A common fault detection and diagnosis operation is to detect broken or underperforming cooling coils. These are hollow loops through which chilled water flows; the loops are placed into an air stream in order to cool the air. The flow of chilled water through the coil is controlled by a valve. In order to tell if the coil is broken or underperforming, the temperature of the air before and after the coil is measured. If the temperature after the coil is not appreciably lower than the temperature before the coil while the valve is open, then there may be a fault on the coil.
PREFIX brick: <http://brickschema.org/schema/Brick#> SELECT ?ahu ?mat ?sat ?pos ?room WHERE { ?ahu a brick:AHU . ?sat a brick:Supply_Air_Temperature_Sensor . ?mat a brick:Mixed_Air_Temperature_Sensor . ?ccv a brick:Cooling_Valve . ?pos a brick:Position_Sensor . ?room a brick:Room . ?ahu brick:hasPoint ?mat, ?sat . ?ahu brick:hasPart ?ccv . ?ccv brick:hasPoint ?pos . ?ahu brick:feeds+/brick:hasPart? ?room . } - Security Considerations
- It is important to protect access to this representation of the building and its devices; access to the model can reveal the uses of space within the building and what equipment is required to make those spaces comfortable and safe. Proper threat models, modes of access and effective security must all be developed.
- Privacy Considerations
- With the detail available in the model, it is possible to associate data sources with the spaces in the building (indeed, this is one of the purposes of the use case) which may then be linked to individuals or organizations within the building. It is of the responsibility of building owners, managers and users to define their own privacy policies for their data and share necessary consents if necessary.
- Accessibility Considerations
- Accessibility is a major concern in the buildings domain. Efforts exist in also providing accessibility data in a electronic format. The W3C LBD CG is in contact with the W3C Linked Data for Accessibility Community Group.
- Internationalisation (i18n) Considerations
- Internationalization is a concern as the building industry is a global industry. Not only are translations of the concepts and properties to other languages necessary, but the ontology should give consideration to alternative categories and organizations. For example, in hot and humid climates, the term HVAC (*Heating*, Ventilation and Air Condition) is often abandoned in favor of ACMV (Air-Conditioning and Mechanical Ventilation) due to the lack of a need for heating.
- Requirements
-
- Integration with Brick Ontology [[Brick]]: Brick has not yet decided on how the values coming out of devices, sensors, etc. should be represented. WoT has the potential to fulfill that role.
- Gaps
-
A very useful feature would be semantic descriptions of standard enumerations of device statuses, alarms and other multi-valued properties. One example is the numerical encoding of the thermostat mode above (e.g. "0 means off", "1 means 1-stage heat", etc.).
Many of the semantics are standard across manufacturers and models because they describe well-known and industry standard properties that must be accessible by users, but are encoded in different ways. The ability to refer to standardized error codes, device status, and so on would be a tremendous advance towards enabling vendor-agnostic treatment of data.
- Existing standards
-
- Brick Schema [[Brick]]
- Building Topology Ontology (BOT) [[BOT]]
- Semantic Sensor Network Ontology (SSN/SOSA) [[vocab-ssn]]
- SAREF4BLDG ETSI Standard [[SAREF4BLDG]]
- SAREF4SYST ETSI Standard [[SAREF4SYST]]
- Web of Things (WoT) Thing Description (TD) [[wot-thing-description]]
Manufacturing
Production Monitoring
- Submitter(s)
- Michael Lagally
- Target Users
- Device Owners, Cloud Provider.
- Motivation
-
Production lines for industrial manufacturing consist of multiple machines, where each machine incorporates sensors for various values. A failure of a single machine can cause defective products or a stop of the entire production.
Big data analysis enables to identify behavioral patterns across multiple production lines of the entire production plant and across multiple plants.
The results of this analysis can be used for optimizing consumption of raw materials, checking the status of production lines and plants and predicting and preventing fault conditions.
- Expected Devices
- Various sensors, e.g. temperature, light, humidity, vibration, noise, air quality.
- Expected Data
- Discrete sensor values, such as temperature, light, humidity, vibration, noise, air quality readings. The data can be delivered periodically or on demand.
- Dependencies
- Thing Description: groups of devices, aggregation / composition mechanism, thing models Discovery/Onboarding: Onboarding of groups of devices
- Description
-
A company owns multiple factories which contain multiple production lines. Examples are production lines and environment sensors. These devices collect data from multiple sensors and transmit this information to the cloud. Sensor data is stored in the cloud, can be visualized and analyzed using machine learning / AI.
The cloud service allows to manage single and groups of devices. Combining the data streams from multiple devices allows to get an easy overview of the state of all connected devices in the user's realm.
In many cases there are groups of devices of the same kind, so the aggregation of data across devices can serve to identify anomalies or to predict impending outages.
The cloud service allows to manage single and groups of devices and can help to identify abnormal conditions. For this purpose a set of rules can be defined by the user, which raises alerts towards the user or triggers actions on devices based on these rules.
This enables the early detection of pending problems and reduces the risk of machine outages, quality problems or threats to the environment or life of humans. It increases production efficiency, improves production logistics (such as raw material delivery and production output).
- Comments
- See also Digital Twin use case.
Cross-protocol Interaction in Industry 4.0 Scenarios
- Submitter(s)
- Sebastian Käbisch
- Reviewer(s)
- Michael McCool, Ryuichi Matsukura, Kunihiko Toumura, Michael Legally, Michael Koster
- Category
- vertical
- Target Users
-
- Device Owners
- Device User
- Cloud Provider
- Service Provider
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
- Industry 4.0 is associated with next generation of manufacturing to increase efficiency, flexibility, and productivity. This also includes the broader interplay between the OT and IT domain as well as the further integration of services from different application areas. Technology domains such as from smart infrastructure and web forecasting services like traffic and weather forecasts are expected to be integrated directly into the manufacturing process as well as in the product lifecycle. To realize cross-domain applications for the Industrie 4.0 context, a frequent exchange with suppliers or local infrastructure providers (e.g., power supplier) is needed and it is necessary to interact with manufacturing systems that usually offers an OPC UA [[OPC UA]] interface. WoT can act as a common and standardized application layer and can be used to support Industry 4.0 use cases. In this context, well-formed bindings for most established industry standards such as OPC UA should be supported.
- Expected Devices
- Typically automation devices or server endpoints that are able to host an OPC UA server (controller, gateways / edges, etc).
- Dependencies - Affected WoT deliverables and/or work items
- There are some experiences of OPC UA bindings in previous WoT PlugFests and there is a sample binding implementation in node-wot. However, there needs to be a formal definition to map the interaction affordances of a TD to OPC UA. In that context an official OPC UA Binding Note document should be developed that can be used as official reference to design Thing Descriptions for OPC UA use cases.
- Description
-
A bottling line consists of a filling module (switchable
between 2 fillers and 4 fillers), a capping module, a
labeling module, and a transport system. The production
line is provided via an OPC UA endpoint for control and
monitoring purposes.
In the context of enhancing productivity and sustainability, the goal is to operate the bottling line in such a way that production is further increased when sufficient or surplus renewable energy is available. The backend system checks periodically a Smart Grid endpoint (via HTTP) how the current power production is and how much renewable energy is produced. Based on the bottling line's current power consumption, which is measured via Modbus, the backend system decides to increase productivity when surplus renewable energy is available. In doing so, the backend system interacts via OPC UA to release the 4 fillers of the filling module and increases the speed of the transport system. If the backend system detects that less renewable energy is being produced, it will initiate standard production and reduce the transport speed and return the 2 fillers of the filling module.
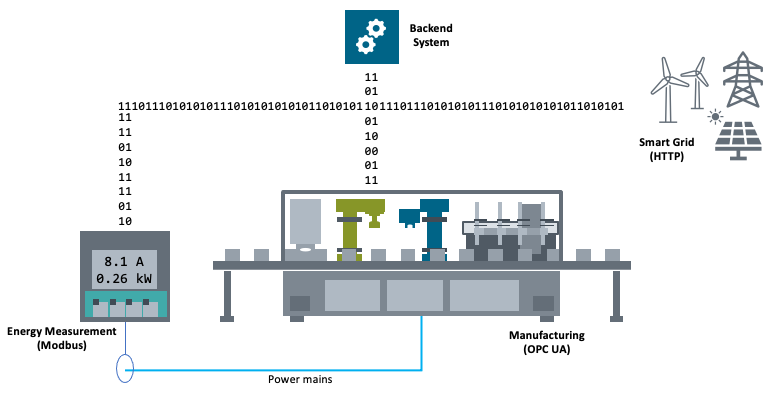
- Security Considerations
- OPC UA has different security modes (sign and/or encrypted, policies, and authentication). Those should be addressed and described in Thing Descriptions with a standardized vocabulary definition. Additional security considerations may apply if a web bridge is created using WoT servients. OT networks are often isolated and OPC UA may have special requirements for distribution of key materials and credentials.
- Privacy Considerations
- OPC UA comes with different approaches to protect data (also see Security Considerations above).
- Accessibility Considerations
- none
- Internationalisation (i18n) Considerations
- OPU-UA data model contains some places to provide human-readable text (e.g., browse name). This should be also reflected in the Thing Description with the correct language context.
- Requirements
- An OPC UA binding for Web of Things needs an own set of OPC UA specific vocabulary definitions which should be developed together with the experts from the OPC Foundation. Also see the liaison.
Retail
Retail Operations
- Submitter(s)
- David Ezell, Michael Lagally, Michael McCool
- Target Users
- Retailers, customers, suppliers.
- Motivation
-
Integrating and interconnecting multiple devices into the common retail workflow (i.e., transaction log) drastically improves retail business operations at multiple levels. It brings operational visibility, including consumer behavior and environmental information, that was not previously possible or viable in a meaningful way.
It drastically speeds up the process of root cause analysis of operational issues and simplifies the work of retailers.
- Expected Devices
- Connected sensors, such as people counters, presence sensors, air quality, room occupancy, door sensors. Cloud services. Video analytics edge services.
- Expected Data
- Inventory data, supply chain status information, discrete sensor data or data streams.
- Description
- Falling costs of sensors, communications, and handling of very large volumes of data combined with cloud computing enable retail business operations with increased operational efficiency, better customer service, and even increased revenue growth and return on investment. Accurate forecasts allow retailers to coordinate demand-driven outcomes that deliver connected customer interactions. They drive optimal strategies in planning, increasing inventory productivity in retail supply chains, decreasing operational costs and driving customer satisfaction from engagement, to sale, to fulfilment. Understanding of store activity juxtaposed with traditional information streams can boost worker and consumer safety, comply better with work safety regulations, enhance system and site security, and improve worker efficiency by providing real-time visibility into worker status, location, and work environment.
- Variants
-
- Use edge computing, in particular video analytics, in combination with IoT devices to deliver an enhanced customer experience, better manage inventory, or otherwise improve the store workflow.
- Security Considerations
-
- In retail, replay attacks can cause monetary loss, customers may be incorrectly charged or over-charged.
- To avoid replay attacks, "Things" should implement a sequence number for each message and digital signature.
- Servers ("Things" or "Cloud") should verify the signature and disallow for duplicated messages.
- For "Things" relying on electronic payments, "Things" must comply with PCI-DSS requirements.
- "Things" must never store credit card information.
- Customer satisfaction and trust depends on availability, so attacks such as Denial-of-Service (DoS) need to be prevented or mitigated.
- To prevent DoS, implement "Things" with early DoS detection.
- Have an automated DoS system that will notify the controlling unit of the problem.
- Implement IP white list, that could be part of the DoS early detection system.
- Make sure your network perimeter is defended with up to date firewall software.
- Privacy Considerations
- As a general rule, personal consumer information should not be stored. That is especially true in the retail industry where a security breach could cause financial, reputation, and brand damage. If personal or information that can identify a consumer is to be stored, it should be to conduct business and with the explicit acknowledgment of the consumer. WoT vendors and integrators should always have a privacy policy and make it easily available. By default, devices should adopt an opt-out policy. That means, unless the consumer explicitly allowed for the data capture and storage, avoid doing it.
Retail Indoor Door Sensor
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Facilities and Power Equipment
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate. Not
being able to access door sensors can drive security and
possible theft scenarios. Open refrigeration and freezer
access doors can lead to spoilage of product and food
safety concerns. Door sensors can also create false
temperature alarms or cause additional wear on equipment
that is maintaining temperatures. Store personnel are
responsible to manage access points, which can be
difficult and impacts their ability to service customers
and manage labor. Furthermore, corporate loss prevention,
security, and store support teams are not able to address
concerns in real-time. Expected outcomes:
- The status of delivery or rear entry doors can be used to send notifications if left open or unattended for long periods of time.
- The status of office and restricted area doors is also important for securing cash and reporting data, as well as access to electrical or network equipment rooms.
- Refrigerated areas also need to be monitored to protect inventory from spoilage or theft.
- Restroom doors can be monitored for usage, maintenance, or ensuring customer health issues do not emerge while using the facilities.
- Expected Devices
-
- Door sensor device.
- Expected Data
-
- The status of facility door sensors (i.e., online, offline, open, closed) coupled with date and time details for pairing with camera/video data for monitoring access;
- The status of office and restroom door sensors with details from time elapsed and from last change in status;
- The status of refrigeration door sensors (i.e., online, offline) paired with temperature sensors, which allows for temperature threshold limits to be evaluated with door sensors to explain temperature deviations, send notifications, and manage quality and safety;
- The door sensor usage for date/time and duration for monitoring and evaluating deliveries or equipment problems; and
- Tracking for the number of times refrigeration doors are opened/closed within specific time periods to allow merchandising and marketing personnel to understand usage and traffic flow, inventory management, promotional program impacts, or product placement details.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
-
Retailers need to ensure that the door sensors are
functional, as these can be vital to employee and
customer safety, as well as operations. Having the
ability to accurately identify the number of associates
and customers within the facility, as well as the status
of access points, is important for physical security,
facilities, and loss prevention groups to ensure health
and safety compliance. There are multiple door sensors
within the store:
- Door sensor for beverage vaults
- Door sensor for refrigeration
- Door sensor for bathrooms and bathroom Stalls
- Door sensors for delivery or rear entry to the facility
- Door sensor for back office/management or storage rooms
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Indoor and Outdoor Freezers
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Food Preparation and Food Service Devices
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate. Not
being able to monitor freezer equipment (temperatures,
condenser energy, etc.) places the burden on store
personnel. Freezer issues can lead to spoilage of product
and food safety concerns. Expected outcomes:
- The status of freezer issues can be used to send notifications to both store and service personnel.
- Equipment patterns can identify issues before they occur, which avoids large losses due to spoilage and/or equipment failure that then impacts ongoing sales.
- Expected Devices
-
- Indoor or Outdoor Freezer devices.
- Expected Data
-
- The status of the freezer (i.e., on, off, defrost, or maintenance mode);
- The current operating temperature of the freezer;
- The door status (i.e., open or closed), including the date and time of activity for evaluating excessive usage and temperature impacts; and
- A log of times that the temperature varied above or below desired set ranges.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers need to ensure that the freezers are online and operating within normal parameters. Monitoring freezers supports health and safety requirements and avoids wasted product, whether it’s food or other consumable items (e.g., ice). Outdoor Food Preparation and Food Service Devices
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Kitchen Refrigerator
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Food Preparation and Food Service Devices
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate. Not
being able to monitor kitchen equipment (temperatures,
condenser energy, etc.) places the burden on store
personnel. Refrigeration issues can lead to spoilage of
product and food safety concerns, as well as energy usage
issues and other kitchen efficiency problems. Expected
outcomes:
- The status of refrigeration can be used to send notifications to both store and service personnel.
- Equipment patterns can identify issues before they occur, which avoids large losses due to spoilage and/or equipment failure that then impacts ongoing sales.
- Retailers can also use the data to better understand operational details in order to improve efficiencies during specific time periods or change standards related to kitchen work area designs.
- Expected Devices
-
- Kitchen Refrigerator device.
- Expected Data
-
- The status of the refrigerator (i.e., on, off, offline);
- The current operating temperature of the refrigerator;
- Door status (i.e., open or closed), including the date and time of activity for evaluating excessive usage and temperature impacts;
- Times that the temperature varied above or below a desired set range;
- The history of high and low temperature alerts; and
- Internal light status.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers need to ensure that the kitchen refrigerator is online and operating within normal parameters. Temperature monitoring and control will ensure food is safe for sale and consumption, while also supporting temperature record-keeping requirements.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Restroom Devices
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Facilities and Power Equipment
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate.
There is a lack of visibility to the equipment for
maintenance and issue identification. Restroom issues can
go unnoticed and unreported for periods of time.
Restrooms often are a priority for customers, so restroom
issues can directly drive away business and customer
traffic inside the store. Restroom service also creates
inefficiencies in the store’s labor.
Expected outcomes:
- Quickly and proactively identifying issues from misuse or faulty devices can avoid health, safety and customer facing problems.
- Timely identification allows onsite personnel to respond, reduce problems, and avoid additional impacts to the store’s operations.
- Proactive efforts at the store level can also improve labor efficiencies by scheduling activities as needed or prior to busy periods.
- Expected Devices
-
- Restroom devices.
- Expected Data
-
- The toilets are operational and serviceable;
- The status of motion sensors and their frequency of engagement, which is used for preventative maintenance or to address issues (e.g., constant running water);
- The status of sensors for water consumption, such as flush/actuator monitoring;
- The status of bowl water levels and +/- level tolerance for preventative maintenance;
- Paper levels and the status of auto paper dispensers;
- Hand dryer status (i.e., powered on, offline, online); and
- Sink water pressure level and status.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers need to ensure that restroom toilets are operational and not experiencing malfunctions.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Lighting Control
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Facilities and Power Equipment
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate.
There is a lack of visibility to the equipment for
maintenance and issue identification. Lighting issues
impact aesthetics and the customer experience. It also
presents safety concerns for store personnel and
customers. Overuse of lighting, such as in storage rooms,
can increase costs unnecessarily. Energy consumption can
impact store efficiencies and costs. Expected outcomes:
- Service
- Tracking energy consumption
- Improving interior aesthetics
- Ensuring lighting is appropriate for time of day and areas within the store (both customer and store associate related) for safety reasons
- Expected Devices
-
- Lighting Control device.
- Expected Data
-
- The status of lights (i.e., on, off, offline);
- The status of light ballasts, where applicable; and
- The date/time information of status changes (e.g., on/off) and the location within the store.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers need to ensure that the indoor lights are operational. Controlling and monitoring lighting is applicable to restrooms, storage spaces, refrigeration units, offices, and equipment and electrical rooms.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Outdoor Canopy Lighting Control
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Outdoor Facility Equipment
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate.
There is a lack of visibility for the store operator into
equipment problems for maintenance and energy management.
There are safety concerns for the forecourt and store
entry locations. There are customer experience and brand
identity issues stemming from safety and aesthetic
issues. Expected outcomes:
- Proactively respond to device issues.
- Provide better insight into energy consumption.
- Keep locations well-lit and safe.
- Expected Devices
-
- Lighting monitor.
- Expected Data
-
- The status of lights (e.g., on, off, or offline);
- The status of light ballasts, where applicable; and
- The date/time information of status changes (e.g., on/off) and location within the store.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers want to ensure that all the canopy lights are operational and turned on at the correct times of day. Lighting is important for aesthetics but also for customer and facility safety requirements. Being able to identify when lighting is out of order, insufficient, or enabled at the wrong times can have energy and safety implications, as well as affect the overall customer experience of the brand.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Fountain Drink Ice Machine
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Food Preparation and Food Service Devices
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate.
There is a lack of visibility to the fountain drink
devices for maintenance and issue identification. Because
the equipment is self serve and customer facing, problems
will directly impact the customer experience.
Additionally, a lack of visibility can create issues for
inventory management and sales when product is out or
unavailable. Expected outcomes:
- Proactively monitor fountain drink equipment and schedule maintenance.
- Inform store personnel of issues so they can take necessary measures for labor effectiveness and customer service.
- Utilize equipment patterns to proactively schedule maintenance to occur at appropriate times for the operations of the store.
- Expected Devices
-
- Fountain Drink Ice Machine device.
- Expected Data
-
- The status of the ice machine (i.e., powered on, off, offline);
- The machine’s ice temperature and ice quality settings;
- The status of the water supply;
- The status of the water filter quality and date/time of last maintenance;
- Notifications for temperature deviations or maintenance requirements; and
- The status of available ice and reports of when the measurement has dropped below a predefined level (e.g., 25%).
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers need to ensure that the ice machine is operational with no malfunctions. Ice availability is important for product quality and can impact the customer experience.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- None. The required data is not PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Retail Camera Device
- Submitter(s)
-
- David Ezell, Conexxus
- Jack Dickinson, Conexxus (Dover Fueling Solutions)
- Category
- Retail
- Class
- Indoor Facilities and Power Equipment
- Target Users
-
- Device Owners (retailers)
- Device Manufacturer
- Gateway Manufacturer
- network operator (potentially transparent for WoT use cases)
- Identity Provider
- directory service operator
- Motivation
-
Identifying data and information relative to the devices
and systems described within this document can reduce
downtime and delays related to customer transactions.
Long lines can lead to customers leaving, diminishing
customer service, and lead to lost sale opportunities for
new or existing customers. Additionally, important health
and safety regulations can be observed, automated, and
managed to ensure quality is consistent and accurate. Not
being able to access cameras remotely is problematic to
loss prevention and store security. It also can make
research and investigations more difficult, costly
(labor), or even impossible, depending on the scenario.
Expected outcomes:
- Proactively monitor cameras and schedule service proactively.
- Inform internal stakeholders of potential issues (e.g., loss prevention).
- Use other functioning equipment to remediate potential collection challenges until service is restored.
- Expected Devices
-
- Digital camera device.
- Expected Data
-
- The positioning of the camera relative to its settings and date/time stamp of any movement;
- Camera status (i.e., power, online, offline) relative to the video recording system;
- Camera status (i.e., power, online, offline) relative to the invoicing system; and
- Details related to the recording frame rate and resolution.
- Dependencies - Affected WoT deliverables and/or work items
-
- WoT Thing Description
- WoT Discovery
- Description
- Retailers would like to ensure that loss prevention and security cameras are operational and recording events as expected, which would be required in concert with the objectives of the camera recording system.
- Security Considerations
- Devices subject to replay attacks and DOS attacks.
- Privacy Considerations
- Any recording of individuals must be protected as PII.
- Accessibility Considerations
- None. No direct user (human) interface is affected.
- Internationalisation (i18n) Considerations
- None. No direct user (internationalized) interface is affected.
Health
Public Health
Smart City Public Health Monitoring
- Submitter(s)
- Jennifer Lin
- Target Users
- Agencies, companies and other organizations in a Smart City with significant pedestrian traffic in a pandemic situation.
- Motivation
- A system to monitor the health of people in public places is useful to control the spread of infectious diseases. In particular, we would like to identify individuals with temperatures outside the norm (i.e. running a fever) and then take appropriate action. Actions can include sending a notification or actuating a security device, such as a gate. This mechanism should be non-invasive and non-contact since the solution should not itself contribute to the spread of infectious diseases. Data may also be aggregated for statistics purposes, for example, to identify the number of people in an area with elevated temperatures. This has additional requirements to avoid double-counting individuals.
- Expected Devices
-
One of the following:
- A thermal camera.
- Face detection (AI) service
- May be on device or be an edge or cloud service.
-
Optional:
- RGB and/or depth camera registered with the thermal camera
- Cloud service for data aggregation and analytics.
- Some way to identify location (optional) Note that location might be static and configured during installation, but might also be based on a localization technology if the device needs to be portable (for example, if it needs to be set up quickly for an event).
- Expected Data
-
- Sensor ID
- Timestamp
- Number of people identified with a fever in image
- Estimated temperature for each person
- May be coarse, low/normal/high
- Location
- Latitude, Longitude, Altitude, Accuracy
- Semantic (e.g. a particular building entrance)
- Thermal image
-
Optional:
- RGB image
- Depth image
- Localization technology (see localization use case)
- Integration with local IoT devices: gates, lights, or people (guards)
- Bounding boxes around faces of identified people in image(s)
- Data that can be used to uniquely identify a face
(distinguish it from others)
- Aggregation system may output the total number of unique faces with fever
Note 1: the system should be capable of notifying consumers (such as security personnel), of fever detections. This may be email, SMS, or some other mechanism, such as MQTT publication.
Note 2: In all cases where images are captured, privacy considerations apply.
It would also be useful to count unique individuals for statistics purposes, but not necessarily based on identifying particular people. This is to avoid counting the same person multiple times.
- Dependencies
- node-wot
- Description
- A thermal camera image is taken of a group of people and an AI service is used to identify faces in the image. The temperature of each person is then estimated from the registered face; for greater accuracy, a consistent location for sampling should be used, such as the forehead. The estimated temperature is compared to high (and optionally, low) thresholds and a notification (or other action) is taken if the temperature is outside the norm. Additional features may be extracted to identify unique individuals.
- Variants
-
- Enough information is included in the notification that the specific person that raised the alarm can be identified. For example, if an RGB camera is also registered with the thermal camera, then a bounding box may be indicated via JSON and the RGB image included; or the bounding box could be actually drawn into the sent image, or the face could be cropped out. This is useful if, for example, a notification needs to be sent to health or security workers who need to identify the person in a crowd.
- Instead of simply a notification, an action may be taken, such as closing or refusing to open a gate at the entrance to a building, to prevent sick employees from entering the building.
- To generate statistics, for example to count the number of people with fevers, then unique individuals need to be identified to avoid counting the same person more than once.
- The same sensors might be used to determine the number of people in an area and send a notification if crowded conditions are detected, in order to support social distancing behavior (for instance, supporting an app that notifies users when a destination is crowded) in a pandemic situation.
- Cameras that provide video streams rather than still images.
- Security Considerations
-
- Because PII is involved (see below) access should be controlled (only provided to authorized users) and communications protected (encrypted).
- Privacy Considerations
-
- Images of people and their health status is
involved.
- If later these are made public then the health information of a particular person would be released publicly.
- There is also the possibility that the camera data could be in error, and should be confirmed with a more accurate sensor.
- This information needs to be treated as PII and protected: only distributed to authorized users, and deleted when no longer needed.
- However, derived aggregate information can be kept and published.
- Images of people and their health status is
involved.
- Gaps
-
- Onboarding mechanism for rapidly deploying a large number of devices
- Standard vocabulary for geolocation information
- Implementations able to handle image payload formats, possibly in combination with non-image data (e.g. images and JSON in a single response)
- Video streaming support (if we wish to serve video stream from the camera instead of still images)
- Standard ways to specify notification mechanisms and data payloads for things like SMS and email (in addition to the expected MQTT, CoAP, and HTTP event mechanisms)
- Comments
-
- May be additional requirements for privacy since images of people and their health status is involved.
- Different sub-use cases: immediate alerts or actions vs. aggregate data gathering
Interconnected Medical Devices in a Hospital ICU
- Submitter(s)
- Taki Kamiya
- Target Users
- Motivation
- Preventable medical errors may account for more than 100,000 deaths per year in U.S. alone. These errors are mainly caused by failures of communication such as a chart misread or the wrong data passed along to machines or staffs. Part of the problem could be solved if the machines could speak to one another. Manufacturers have little incentive to make their proprietary code and data easily to accessible and process able by their competitors’ machines. So the task of middleman falls to the hospital staff. In addition to saving lives, a common framework could result in collecting and recording more clinical data on patients, making it easier to deliver precision medicine.
- Description
-
Physiological Closed-Loop Control (PCLC) devices are a group of emerging technologies, which use feedback from physiological sensor(s) to autonomously manipulate physiological variable(s) through delivery of therapies conventionally delivered by clinician(s).
Clinical scenario without PCLC. An elderly female with end-stage renal failure was given a standard insulin infusion protocol to manage their blood glucose, but no glucose was provided. Their blood glucose dropped to 33, then rebounded to over 200 after glucose was given. This scenario has not changed for decades.
The desired state with PCLC implemented in an ICU. A patient is receiving an IV insulin infusion and is having the blood glucose continuously monitored. The infusion pump rate is automatically adjusted according to the real-time blood glucose levels being measured, to maintain blood glucose values in a target range. If the patient’s glucose level does not respond appropriately to the changes in insulin administration, the clinical staff is alerted.
Medical devices do not interact with each other autonomously (monitors, ventilator, IV pumps, etc.) Contextually rich data is difficult to acquire. Technologies and standards to reduce medical errors and improve efficiency have not been implemented in theater or at home.
In recent years, researchers have made progress developing PCLC devices for mechanical ventilation, anesthetic delivery applications, and so on. Despite these promises and potential benefits, there has been limited success in the translation of PCLC devices from bench to bedside. A key challenge to bringing PCLC devices to a level required for a clinical trials in humans is risk management to ensure device reliability and safety.
The United States Food and Drug Administration (FDA) classifies new hazards that might be introduced by PCLC devices into three categories. Besides clinical factors (e.g. sensor validity and reliability, inter- and intra-patient physiological variability) and usability/human factors (e.g. loss of situational awareness, errors, and lapses in operation), there are also engineering challenges including robustness, availability, and integration issues.
- Variants
-
US military developed ONR SBIR (Automated Critical Care
System Prototype), and found those issues.
- No plug and play, i.e. cannot swap O2 Sat with another manufacturer.
- No standardization of data outputs for devices to interoperate.
- Must have the exact make/model to replace a faulty device or system will not work.
- Security Considerations
-
Security considerations for interconnected and dynamically composable medical systems are critical not only because laws such as [[HIPAA]] mandate it, but also because security attacks can have serious safety consequences for patients. The systems need to support automatic verification that the system components are being used as intended in the clinical context, that the components are authentic and authorized for use in that environment, that they have been approved by the hospital’s biomedical engineering staff and that they meet regulatory safety and effectiveness requirements.
For security and safety reasons, ICE F2761-09(2013) compliant medical devices never interact directly each other. All interaction is coordinated and controlled via the applications.
While transport-level security such as TLS provides reasonable protection against external attackers, they do not provide mechanisms for granular access control for data streams happening within the same protected link. Transport-level security is also not sufficiently flexible to balance between security and performance. Another issue with widely used transport-level security solutions is the lack of support for multicast.
- Privacy Considerations
- Medical applications need to be conformant with the appropriate medical privacy standards and legal requirements.
- References
- Standards relevant to this use case include regional standards for the management of personal health data, including but not limited to [[HIPAA]] in the United States, [[GDPR]] in the EU, and [[PIPEDA]] in Canada.
- Gaps
- Multicast support. It has proven useful for efficient and scalable discovery and information exchange in industrial systems.
- Existing Standards
- Medical Devices and Medical Systems - Essential safety requirements for equipment comprising the patient-centric integrated clinical environment (ICE) - Part 1: General requirements and conceptual model. The idea behind ICE is to allow medical devices that conform to the ICE standard, either natively or using an adapter, to interoperate with other ICE-compliant devices regardless of manufacturer. OpenICE is an initiative to create a community implementation of F2761-09 (ICE - Integrated Clinical Environment) based on DDS. MDIRA Version 1.0 provides requirements and implementation guidance for MDIRA-compliant systems focused on trauma and critical care in austere environments. Johns Hopkins University Applied Physics Laboratory (JHU-APL) lead a research project in collaboration with US military to develop a framework of autonomous / closed loop prototypes for military health care which are dual use for the civilian healthcare system.
Private Health
Health Notifiers
- Submitter(s)
- Michael McCool
- Target Users
- End user with a health problem they wish to monitor. Health services provider (doctor, nurse, paramedic, etc.).
- Motivation
- In critical situations regarding health, like a medical emergency, media multimodality may be the most effective way to communicate alerts, When the goal is to monitor the health evolution of a person in both emergency and non-emergency contexts, access via networked devices may be the most effective way to collect data and monitor a patient's status.
- Expected Devices
- Medical facilities supporting device and service access.
- Expected Data
- Command and status information transferred between the personal mobile device application and the meeting space's services and devices. Profile data for user preferences.
- Dependencies
-
- WoT Thing Description
- WoT Discovery
- Optional: WoT Scripting API in application on mobile personal device and possibly in IoT orchestration services.
- Description
- In medical facilities, a system may provide multiple options to control sensor operations by voice or gesture ("start reading my blood pressure now"). These interactions may be mediated by an application installed into a smartphone. The system integrates information from multiple sensors (for example, blood pressure and heart rate); reports medical sensor readings periodically (for example, to a remote medical facility) and sends alerts when unusual readings/events are detected.
- Variants
- The user may have additional mobile devices they want to incorporate into an interaction, for example a headset acting as an auditory aid or personal speech output device.
- Gaps
- Data format describing user interface preferences. Ability to install applications based on links that can access IoT services.
- Existing Standards
- This use case is based on MMI UC 3.2 [[mmi-use-cases]].
- Comments
- Does not include Requirements section from original MMI use case.
Biomedical Devices
Digital Microscopes
- Submitter(s)
- Adam Sobieski
- Category
- This use case could be horizontal, insofar as it advances digital microscopy for consumers, and could be vertical, insofar as it equips biomedical professionals, scientists, and educators.
- Target Users
- Motivation
- Microscopes are utilized throughout biomedicine, the sciences, and education. Advancing digital microscopes and enabling their interoperability with mixed-reality collaborative spaces via WoT architecture and standards can equip biomedical professionals, scientists, and educators, amplifying and accelerating their performance and productivity.
- Expected Devices
- Mixed-reality collaborative spaces are device agnostic. Users can collaborate while making use of AR devices, VR devices, mobile computers, and desktop computers. The expected devices include AR and VR equipment (e.g., head-mounted displays), computing devices, and digital microscopes.
- Expected Data
-
The expected data include 2D and 3D streams produced by digital microscopes and recordings thereof. These streams may contain metadata which describe the instantaneous magnifications and timescales of data. The expected data also include the output streams produced by services. These streams could, for instance, contain annotation data.
With respect to annotating video streams, one could make use of secondary video tracks with uniquely-identified bounding boxes or more intricate silhouettes defining spatial regions on which to attach semantic data, e.g., metadata or annotations, using yet other secondary tracks. Similar approaches could work for point-cloud-based and mesh-based animations.
- Dependencies - Affected WoT deliverables and/or work items
- To be determined
- Description
-
Mixed-reality collaborative spaces enable users to visualize and interact with data and to work together from multiple locations on shared tasks and projects.
Digital microscopes could be accessed and utilized from mixed-reality collaborative spaces via WoT architecture and standards. Digital microscopes could be thusly utilized throughout biomedicine, the sciences, and education. Data from digital microscopes could be processed by services to produce outputs useful to users. Users could select and configure one or more such services and route streaming data or recordings through them to consume resultant data in a mixed-reality collaborative space. Graphs, or networks, of such services could be created by users. Services could also communicate back to digital microscopes to control their mechanisms and settings. Services which simultaneously process digital microscope data and communicate back to control such devices could be of use for providing users with automatic focusing, magnification, and tracking.
Multimodal user interfaces could be dynamically generated for digital microscope content by making use of the output data provided by computer-vision-related services. Such dynamic multimodal user interfaces could provide users with the means of pointing and using spoken natural language to indicate precisely which contents that they wish to focus on, magnify, or track.For example, a digital microscope could be magnifying and streaming 2D or 3D imagery of a living animal cell. This data could be processed by a service which provides computer-vision-related annotations, labeling parts of the cell: the cell nucleus, Golgi apparatus, ribosomes, the endoplasmic reticulum, mitochondria, and so forth. The resultant visual content with its algorithmically-generated annotations could then be interacted with by users. Users could point and use spoken natural language to indicate precisely which parts of the living animal cell that they wished for the digital microscope to focus on, magnify, or track.
- Security Considerations
- The streaming of digital microscope data should be securable for biomedical scenarios. Access to the controls and settings of digital microscopes should be securable for education scenarios so that teachers can adjust the controls and students cannot.
- Privacy Considerations
- In biomedical scenarios, there are privacy issues pertaining to the use of biological samples and medical data from patients.
- Accessibility Considerations
- To be determined
- Internationalisation (i18n) Considerations
- Output data from services could include natural-language content or labels. Such content or labels could be multilingual. Dynamically generated multimodal user interfaces utilizing such content or labels could also be multilingual.
- Requirements
-
Requirements that are not addressed in the current WoT standards or building blocks include streaming protocols and formats for 3D digital microscope data and recordings. While digital microscopes could stream video using a variety of existing protocols and formats, the streaming of other forms of 3D data and animations, e.g., point clouds and meshes, could be facilitated by recommendation.
Users could select and configure one or more services and route data streaming from digital microscopes through them to consume the resultant data in a mixed-reality collaborative space. Additionally, services could be designed to communicate back to and control the mechanisms and settings of digital microscopes. Requirements that are not addressed in the current WoT standards or building blocks include a means of interconnecting services. Perhaps services could utilize WoT architecture and could be described as WoT things, or virtual devices, which provide functionality including that with which to establish data connectivity between them.
Energy
Smart Grids
- Submitter(s)
- Christian Glomb
- Target Users
-
- Grid operators on all voltage levels line Distribution System Operators (DSO), Transmission System Operators (TSO)
- Plant operators (centralized as well as de-centralized producers)
- Virtual Power Plant (VPP) operators
- Energy grid markets
- Cloud Providers where grid backend services are hosted and where Operation Technology bridges to Information Technology
- Device Manufacturers, owners, and users; devices include communication gateways, monitoring and control units
- Expected Devices
- A smart grid integrates all players in the electricity market into one overall system through the interaction of generation, storage, grid management and consumption. Power and storage plants are already controlled today in such a way that only as much electricity is produced as is needed. Smart grids include consumers as well as small, decentralized energy suppliers and storage locations in this control system, so that on the one hand, consumption is more homogeneous in terms of time and space (see also intelligent electricity consumption) and on the other hand, in principle inhomogeneous producers (e.g. wind power) and consumers (e.g. lighting) can be better integrated.
- Expected Data
-
- Weather and climate data
- Metering data (both production as well as consumption as well as storage, e.g. 15 min. intervals)
- Real time data from PMUs (Phasor Measurement Units)
- Machine and equipment monitoring data (enabling health checks)
- ...
- Affected WoT deliverables and/or work items
- WoT Architecture, WoT Binding Templates (covering protocol specifications)
- Description
- The term Smart Grid refers to the communicative networking and control of power generators, storage facilities, electrical consumers, and grid equipment in power transmission and distribution networks for electricity supply. This enables the optimization and monitoring of the interconnected components. The aim is to secure the energy supply on the basis of efficient and reliable system operation.
- Variants
-
- Decentralized Power Generation
- While electricity grids with centralized power generation have dominated up to now, the trend is moving towards decentralized generation plants, both for generation from fossil primary energy through small CHP plants and for generation from renewable sources such as photovoltaic systems, solar thermal power plants, wind turbines and biogas plants. This leads to a much more complex structure, primarily in the area of load control, voltage maintenance in the distribution grid and maintenance of grid stability. In contrast to medium to large power plants, smaller, decentralized generation plants also feed directly into the lower voltage levels such as the low-voltage grid or the medium-voltage grid. This use case variants also includes operation and control of energy storages like batteries.
- Virtual Power Plants
- A Virtual Power Plant (VPP) is an aggregation of Distributed Energy Resources (DERs) that can act as an entity on energy markets or as an ancillary service to grid operation. The individual DERs often have a primary use on their own, with electric generation/consumption being a side-effect resp. secondary use. This results in negotiations/collaborations between many different parties e.g. such as the DER owner, the VPP operator, the grid operator and others.
- Smart Metering
- For consumers, a major change is the installation of smart meters. Their core tasks are remote reading and the possibility to realize fluctuating prices within a day at short notice. All electricity meters must therefore be replaced by those with remote data transmission.
- Other variants
- Emergency response, grid synchronization, grid black start
- Building Blocks
-
- Multi-Stakeholder Operation: Multiple involved parties have to find a common mode of operation
- Device Lifecycle Management: Since the VPP is a dynamic system of loosely coupled DERs, the appearance and disappearance of DERs as well as the software management on the devices itself requires a means to orchestrate the lifecycle of individual device's respective components.
- Embedded Runtime: Especially for DERs in remote locations, maintaining a close couple control loop can be expensive if feasible at all. Therefore, it is desirable to be able to offload control logic to the DER itself.
- Ensemble Discovery: In order to dynamically find matching DERs needed for the operational goal of a VPP, a registry with different options of DER discovery is needed.
- Content-Negotiation: The different stakeholders have to interact and therefore need a common data format.
- Resource Description: The DER has to describe itself to enable discovery of single DERs and ensembles, also the operational data needs to be understood by the different stakeholders without engineering effort.
- Push Services: As there is a fan-out with many devices that probably have a rate-limited connection connecting to one single command center, a bidirectional communication mechanism is needed rather than polling for the reverse direction
- Object Memory: As multiple and interchangeable stakeholders are involved in the application, a backlog of the object is beneficial for scroll-keeping
- Non-Functionals
-
- Privacy: As fine-grained metering information provides sensitive data about a household, the system should show a high degree of privacy
- Trust: Since the data exchange between the virtual power plant and the distributed energy resource leads to a physical action that invokes high currents and monetary flows, the integrity of both parties and the exchange's data is crucial
- Layered L7 Communication: Since multiple different links are used for monitoring and control, integration requires a clear and consistent separation of information from the used serialization and application protocols to enable the exchange of homogenous information over heterogenous application layer protocols
- Existing Standards
-
- IEC 61850 - International standard for data models and communication protocols [[IEC-61850]]
- IEEE 1547 - US standard for interconnecting distributed resources with electric power systems [[IEEE-1547]]
Transportation
- Submitter(s)
- Zoltan Kis
- Sub-categories
- Transportation - Infrastructure Transportation - Cargo Transportation - People
- Target Users
-
Smart Cities: managing roads, public transport and commuting, autonomous and human driven vehicles, transportation tracking and control systems, route information systems, commuting and public transport, vehicles, on-demand transportation, self driving fleets, vehicle information and control systems, infrastructure sharing and payment system, smart parking, smart vehicle servicing, emergency monitoring, etc.
Transport companies: managing shipping, air cargo, train cargo and last mile delivery transportation systems including automated systems.
Commuters: Mobility as a service, booking systems, route planning, ride sharing, self-driving, self-servicing infrastructure, etc.
- Motivation
-
Provide common vocabulary for describing transport related services and solutions that can be reused across sub-categories, for easier interoperability between various systems owned by different stakeholders.
Thing models could be defined in many subdomains to help integration or interworking between multiple systems.
Transportation of goods can be optimized at global level by enhancing interoperability between vertical systems.
- Expected Devices
- Road information system (routes, conditions, navigation). Road control system (e.g. virtual rails). Traffic management services, e.g. intelligent traffic light system with localization and identification (by satellite, radio frequency identification, cameras etc.). Emergency monitoring and data/location sharing. Airport management. Shipping docks and ports management. Train networks management. Public transport vehicles (train, metro, tram, bus, minibus), mobility as a service (ride sharing, bicycle sharing, scooters etc.). Transportation network planning and management (hubs, backbones, sub-networks, last mile network). Electronic timetable management system. Vehicles (human driven, self-driving, isolated or part of fleet). Connected vehicles (cars, ships, airplanes, trains, buses etc). Devices needed for cargo.
- Expected Data
- Vehicle data (identification, location, speed, route, selected vehicle data). Weather and climate data. Contextual data (representing various risk factors, delays, etc.).
- Dependencies
- Localization technologies. Automotive data. Contextual data. Cloud integration.
- Description
- Transportation system implementers will be able to use a unified data description model across various systems.
- Variants
-
There will be different verticals, such as:
- Smart City public transport
- Smart City traffic management
- Smart city vehicle management
- Cargo traffic management
- Cargo vehicle management
Automotive
Smart Car Configuration Management
- Submitter(s)
- Michael McCool
- Category
- Accessibility
- Motivation
- User interface personalization is a task that most often needs to be repeated for all Devices a user wishes to interact with recurringly. With complex devices, this task can also be very time-consuming, which is problematic if the user regularly accesses similar, but not identical devices, as in the case of several cars rented over a month. A standardized set of personal information and preferences that could be used to configure personalizable devices automatically would be very helpful for all these cases in which the interaction becomes a customary practice.
- Expected Devices
- Personal mobile device running an application providing command mediation capabilities. IoT-enabled smart car supporting remote sensing, actuation, and configuration functionality.
- Expected Data
- Command and status information transferred between the personal mobile device application and the car's services and devices. Profile data for user preferences.
- Dependencies
-
- WoT Thing Description
- WoT Discovery
- Optional: WoT Scripting API in application on mobile personal device and possibly in IoT orchestration services in the car.
- Description
- Basic in-car functionality is standardized to be managed by other devices. A user can control seat, radio or AC settings through a personalized multimodal interface shared by the car and their personal mobile device. User preferences are stored on the mobile Device (or in the cloud), and can be transferred across different car models handling a specific functionality (e.g. all cars with touchscreens should be able to adapt to a "high contrast" preference). The car can make itself available as a complex modality component that wraps around all functionality and supported modalities, or as a collection of modality components such as touchscreen, speech recognition system, or audio player. In the latter case, certain user preferences may be shared with other environments. For example, a user may opt to select the "high contrast" scheme at night on all of their displays, in the car or at home. A car that provides a set of modalities can be also adapted by the mobile device to compose an interface for its functionality, for example to manage playback of music tracks through the car's voice control system. Sensor data provided by the phone can be mixed with data recorded by the car's own sensors to profile user behavior which can be used as context in multimodal interaction.
- Variants
- Additional portable devices may be brought into the car and also be incorporated into an application, for example, a GPS navigation system.
- Gaps
- Data format describing user interface preferences.
- Existing Standards
- This use case is based on MMI UC 2.1 [[mmi-use-cases]].
- Comments
- Does not include Requirements section from original MMI use case.
Smart Home
Audio/Video
Home WoT devices synchronize to TV programs
- Submitter(s)
- Hiroki Endo, Masaya Ikeo, Shinya Abe, Hiroshi Fujisawa
- Target Users
- Person watching TV, Broadcasters
- Motivation
-
A lot of home devices, such as TV, cleaner, and home
lighting, connect to an IP network. When you watch a
content program, these devices should cooperate for
enhancing your experience. If the cleaning robot makes
a loud noise while watching the TV program, it will
hinder viewing. Also, even if you set up the theater
environment with smart lights, it is troublesome to
operate it yourself each time the TV program switches.
Therefore, by WoT device to operate in accordance with
the TV program being viewed, thereby improving the user
experience. WoT devices work according to TV programs:
- Cleaning robot stops at an important situation,
- Color of smart lights are changed according to TV programs,
- Smart Mirror is notified that favorite TV show will start.
- Expected Devices
-
- Hybridcast TV
- Hybridcast Connect application (in a smartdevice such as smartphone)
- Cleaning Robot
- Smart Light (such as Philips Hue)
- Smart Mirror
- Expected Data
- The trigger value of the scene of the TV program. Hybridcast connect application know the Thing Description of the devices in home. (Discovery?)
- Description
-
Home smart devices behave according to TV programs.
Hybridcast applications in TV emit information about TV programs for smart home devices. (Hybridcast is a Japanese Integrated Broadcast-Broadband system. Hybridcast applications are HTML5 applications that work on Hybridcast TV.)
Hybridcast Contact application receives the information and controls smart home devices.

- Existing Standards
- Hybridcast and Hybridcast Connect: a Japanese Integrated Broadcast-Broadband system [[Hybridcast]], Reference Implementations), HbbTV, ATSC 3.0, etc.
- Comments
Leaving and Coming Home
- Submitter(s)
- Tetsushi Matsuda, Keiichi Teramoto, Takashi Murakami, Morio Hirahara (ECHONET Consortium)
- Target Users
-
- Device User
- Service Provider (Home Management Service Provider)
- Device Manufacturer
- Motivation
- The purpose of this use case is to improve the usability of home appliances for Device Users by allowing Device Users to configure the operation modes of all devices at home without configuring those devices one by one when they leave and come home.
- Expected Devices
- Lighting, Air Conditioner, Security Sensor, Smartphone
- Expected Data
- The operation modes of lighting, air conditioner and security sensor. Reading and updating those operation modes on demand.
- Dependencies - Affected WoT deliverables and/or work items
- Description
-
- Configuration by a Device User before
starting to use a service
- A Device User logs in the server of a "home management service provider" with which the user has a contract.
- The user specifies the operation modes of lighting, air conditioner and security sensor for the time when the user is out of home, the time when the user comes home and the time when the specified amount of time has passed after the user comes home.
- When the Device User leaves home
- The Device User accesses the server of a "home management service provider" with a smartphone and notifies the server that the user is going to leave home.
- The server updates the operation modes of lighting, air conditioner and security sensor according to the configuration specified by the user for the time when the user is out of home.
- The server reads the operation modes of lighting, air conditioner and security sensor and informs the user's smartphone of those operation modes.
- When the Device User comes home
- The Device User accesses the server of a "home management service provider" with a smartphone and notifies the server that the user will return home soon.
- The server updates the operation modes of lighting, air conditioner and security sensor according to the configuration specified by the user for the time when the user comes home.
- The server reads the operation modes of lighting, air conditioner and security sensor and informs the user's smartphone of those operation modes.
- When the specified amount of time has passed after the user returns home, the server updates the operation modes of lighting, air conditioner and security sensor according to the configuration specified by the user for the time when the specified amount of time has passed after the user comes home.
- The server reads the operation modes of lighting, air conditioner and security sensor and informs the user's smartphone of those operation modes.
- Configuration by a Device User before
starting to use a service
- Security Considerations
-
- It is necessary to prevent unauthorized users other than the Device User from using the service provided by the home management service provider.
- It is necessary to disallow home management service providers other than the home management service providers permitted by the Device User in advance to control devices at the Device User's home.
- Privacy Considerations
- It is necessary to protect the information on what operations are done on the devices that are controlled or monitored at the Device User's home. It is also necessary to protect the information obtained from the devices that are controlled or monitored at the Device User's home.
- Accessibility Considerations
- User interface provided by a smartphone had better consider accessibility.
- Internationalisation (i18n) Considerations
- User interface provided by a smartphone had better support internationalization.
- Gaps
- The method for controlling multiple devices in an orchestrated manner is dependent on the implementation of a client application in the current WoT specification. That is a reasonable design choice. However, the orchestrated control of multiple devices needs to be implemented by each client application even if the same control is done by multiple client applications.
- Existing standards
- ECHONET Lite (https://echonet.jp/spec_v113_lite_en/ ) and ECHONET Lite Web API Guideline (https://echonet.jp/web_api/ in Japanese ).
{kind=link}
{kind=link}
{kind=link}