1. Introduction
This section is non-normative
Ruby is a name for small annotations that are rendered alongside base text. This is especially useful for Japanese and other East Asian content (ruby may be called furigana in Japanese). It is most often used to provide a reading (pronunciation guide).
Ruby text is usually presented alongside the base text, using a smaller typeface. The name ruby originated from a named font size (about half the size of the normal 10 point font) used by British typesetters.
Typically ruby is used in East Asian scripts to provide phonetic transcriptions of obscure and little known characters, characters that the reader is not expected to be familiar with (such as children or foreigners learning to write), or characters that have multiple readings which can’t be determined by the context (eg. some Japanese names). For example it is widely used in educational materials and children’s texts, but it can also be readily found in many types of literature and signage. It is also occasionally used to convey information about the meaning of ideographic characters.
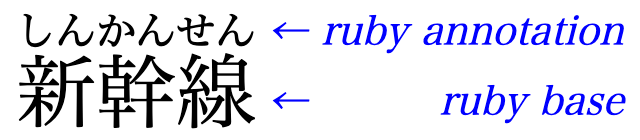
Specialized markup, as defined in this document, is necessary to describe the semantic associations between the base text and its annotations, to enable its various visual layouts as well as correct non-visual presentation and processing.
Note: CSS Ruby Annotation Layout Module Level 1 defines the ruby layout model in CSS, enabling the ruby presentation described above and frequently desired variations.
1.1. Background and Relation to the HTML Standard
A set of HTML elements to markup ruby has evolved over the years in multiple specifications, starting from the 2001 Ruby Annotation specification all the way to the current HTML Standard, with different incarnations varying in flexibility, complexity, or verbosity.
While concise and effective in simple cases, the ruby model described in the HTML Standard (at the time of writing this document) is insufficiently expressive to handle all use cases well. Moreover, some aspects of it are also not interoperably implemented; yet implementing them would not completely address the remaining use cases. Additionally, these aspects are at odds with the CSS layout model.
This specification is written to promote—and guide implementations of—a revised and extended model for ruby, in order to more completely address the needs of ruby on the Web platform. This effort is undertaken with the agreement of W3C and the WHATWG.
Appendix B: Comparison With The HTML Standard summarizes the main differences, and provides a brief overview of why these differences are desirable.
Note that the semantics of the subset of the HTML Standard that is interoperably implemented remain unchanged in this extension specification, making the ruby model described here backwards compatible with any ruby content supported by existing user agents.
It is hoped that the changes described here will in time be adopted by the WHATWG and integrated into the HTML Standard, reducing the delta between the two documents.
2. HTML Elements for Ruby
2.1.
The ruby element
- Categories:
- Flow content.
- Phrasing content.
- Palpable content.
- Phrasing content.
- Contexts in which this element can be used:
- Where phrasing content is expected.
- Content model:
- See prose.
- Content attributes:
- Global attributes
- Accessibility considerations:
- For authors.
- For implementers.
- DOM interface:
- Uses
HTMLElement.
The ruby element represents one or more ranges of phrasing content
paired with associated ruby annotations.
Ruby annotations are short runs of annotation text presented alongside base text.
Although primarily used in East Asian typography as a guide for pronunciation,
they can also be used for other associated information.
Ruby is most commonly presented as interlinear annotations,
although other presentations are also used.
A more complete introduction to ruby and its rendering
can be found in W3C’s What is ruby? article
and in CSS Ruby Annotation Layout Module Level 1.
< ruby >< rb > 霧</ rb >< rt > きり</ rt ></ ruby > とも< ruby >< rb > 霞</ rb >< rt > かすみ</ rt ></ ruby > とも
A typical rendering would be something akin to the following image:

Note: See the following example for discussion of syntax variants and simplifications.
The content model of ruby elements consists of
one or more of the following ruby segment sequences:
-
One or more phrasing content nodes
or
rbelements (or a combination) representing the base-level content being annotated (the ruby base range). -
One or more
rtorrtcelements (or a combination) representing any annotations associated with the preceding base content, where eachrtcelement or sequence ofrtelements represents one independent level of annotation (a ruby annotation range). Each annotation range, and annotation units within each range, and can optionally be preceded by / followed by / interleaved with individualrpelements. (The optionalrpelement can be used to add presentational content such as parentheses, which can be useful when rendering annotations inline, including as a fallback when ruby layout is not supported.)
Note: For authoring convenience,
the internal ruby elements rb, rt, rtc, and rp
have optional end tags.

< ruby lang = zh-TW >
< rb > 美</ rb >< rtc >< rt > ㄇㄟˇ</ rt ></ rtc >< rtc lang = zh-Latn >< rt > měi</ rt ></ rtc >
</ ruby >
Certain features of HTML ruby allow for simpler markup:
- End tags can be omitted.
-
Text contained directly by a
rubyelement implicitly represents a ruby base unit (as if it were contained in anrbelement). -
Consecutive
rtchildren of arubyelement are implicitly grouped into a ruby annotation range (as if they were contained in anrtcelement). -
Text contained directly by an
rtcelement implicity represents a ruby annotation unit.
In effect, the above example is equivalent (in meaning, though not in the DOM it produces) to the following:
< ruby lang = zh-TW > 美< rt > ㄇㄟˇ< rtc lang = zh-Latn > měi</ ruby >
Note: The CSS Ruby Annotation Layout Module Level 1 enables authors
to control the rendering of the HTML ruby element and its contents,
supporting a variety of layouts based on the same markup.
When the text is written vertically, the phonetic annotations are rendered to the right, along the base text:

In horizontal writing, they are usually also typeset to the right, in this case sandwiched between individual base characters:

However, sometimes Zhuyin annotations are instead typeset above horizontal base text:

These differences are stylistic, not semantic, and therefore share the same markup:
< ruby lang = zh-TW >< rb > 電< rb > 腦< rt > ㄉㄧㄢˋ< rt > ㄋㄠˇ</ ruby >
2.1.1. Ruby Segmentation and Pairing
Within a ruby element,
content is parcelled into a series of ruby segments.
Ignoring inter-element whitespace and rp elements,
each ruby segment consists of:
-
One ruby base range:
zero or more ruby base units,
each of which is either a DOM range containing a single child
rbelement or a maximal DOM range of child content that does not contain a childrbelement. -
Zero or more ruby annotation ranges,
each a DOM range corresponding to either
a single
rtcelement or to a maximal sequence of consecutivertelements. The ruby annotation range is further parcelled into a sequence of ruby annotation units: if it consists of a sequence ofrtelements, then each such element is an individual ruby annotation unit; if it consists of anrtcelement, then each of its childrtelements and each maximal DOM range of non-rtchild content is a ruby annotation unit.
ruby element:

Multiple adjacent ruby segments can also be combined into the same ruby parent:
The process of annotation pairing associates ruby annotation units
with ruby base units.
Within each ruby segment,
each ruby base unit is paired with a ruby annotation unit
from each ruby annotation range.
If a ruby annotation range consists of an rtc element
that contains no rt elements,
the single ruby annotation unit represented by its contents spans
(is paired with)
every ruby base unit in the ruby segment.
Otherwise,
each ruby annotation unit in the ruby annotation range is paired,
in order,
with the corresponding ruby base unit in the segment’s ruby base range.
If there are not enough ruby base units,
any remaining ruby annotation units
are assumed to be associated
with empty, hypothetical bases
inserted at the end of the ruby base range.
If there are not enough ruby annotation units
in a ruby annotation range,
the remaining ruby base units
are assumed to not have an annotation from that annotation level.
However,
for compound words in Japanese particularly,
per-character inlined phonetics are awkward.
Instead,
the more natural rendering
is to place the annotation of an entire word
together after its base text.
For example,
when typeset inline,
京都市 (“Kyoto City”)
is expected to be rendered as
“京都市(きょうとし)”,
not “京(きょう)都(と)市(し)”.
This can be marked up using consecutive rb elements followed by consecutive rt elements:
< ruby >< rb > 京< rb > 都< rb > 市< rt > きょう< rt > と< rt > し</ ruby >
If each base character was immediately followed by its annotation in the markup (each base-annotation pair forming its own segment), inlining would result in the undesirable and awkward “京(きょう)都(と)市(し)”.
Note that the markup above does not automatically provide the parentheses.
Parentheses can be inserted using CSS generated content
when intentionally typesetting inline,
however they would be missing
when a UA that does not support ruby
falls back to inline layout automatically from interlinear layout.
The rp element can be inserted
to provide the appropriate punctuation for when ruby is not supported:
< ruby >< rb > 京< rb > 都< rb > 市< rp > (< rt > きょう< rt > と< rt > し< rp > )</ ruby >
2.1.2. Markup Patterns for Multi-Character Ruby
This section is non-normative
In the simplest examples, each ruby base unit contains only a single character, a pattern often used for character-per-character phonetic annotations. However, ruby base units are not restricted to containing a single character. In some cases it may be impossible to map an annotation to the base characters individually, and the annotation may need to jointly apply to a group of characters.
Therefore phonetic ruby indicating the reading of 今日 would be marked up as follows:
< ruby > 今日< rt > きょう</ ruby >

Here a compound ideographic word has an English-derived synonym (written in katakana) given as an annotation:
< ruby > 境界面< rt > インターフェース</ ruby >

Here a compound ideographic word has its English equivalent directly provided as an annotation:
< ruby lang = "ja" > 編集者< rt lang = "en" > editor</ ruby >

In compound words, although phonetic annotations might correspond to individual characters, they are sometimes nonetheless typeset to share space above the base text, rendering similar to annotations on multi-character bases. However, there are subtle distinctions in their rendering that require encoding the pairing relationships within the compound word as well as its identification as a word. Furthermore, sharing space in this way versus rendering each pair in its own visual “column” is a stylistic preference: the markup needs to provide enough information to allow for both renderings (as well as correct inlining).
Such compound words could be rendered with phonetic annotations placed over each character one by one. In this style, when an annotation is visually longer than the character it annotates, surrounding text is pushed apart, to make the correspondance between each character and its annotation clear.

However, in various typographic traditions, it is common to present such a word with its annotations sharing space together when they would otherwise create a separation in the base text, to preserve the implication that it is a single word. This style is called “jukugo ruby” (“jukugo” meaning “compound word”).

Even when presenting as “jukugo ruby“ though, the annotation are not always merged. If a line break occurs in the middle of the word, the annotations are expected to remain associated with the correct base character.

Whether—and how much—the annotations are merged can vary, and can depend on the font size. The following figures illustrate two of several possibilities: one where “jukugo ruby“ merges an annotation wider than its base with the neighboring one without necessarily merging them all, and one where “jukugo ruby“ merges all annotations as soon as any of them is wider than its base. No specific layout is mandated by this specification; that is under the purview of styling technologies such as CSS.



Regardless of what rendering variants are made available by the styling technology, the same markup needs contain enough information to support any style, since choosing whether to render as “jukugo ruby” and its variants is a stylistic choice. Markup needs to encode both the pairing information within the word as well as the grouping of these pairs as a single word:
< ruby >< rb > 浄< rb > 瑠< rb > 璃< rt > じょう< rt > る< rt > り</ ruby >
Correct “jukugo ruby” is not possible
if all the base characters are part of a single rb element
and all the annotation text in a single rt element,
as their individual pairings would be lost.
Note: For more details on Japanese and Chinese ruby usage and rendering, see Requirements for Japanese Text Layout 日本語組版処理の要件(日本語版) (particularly Ruby and Emphasis Dots and Appendix F), Rules for Simple Placement of Japanese Ruby, and the section on Inline notes & annotations of Requirements for Chinese Text Layout - 中文排版需求.
2.2.
The rb element
- Categories:
- None.
- Contexts in which this element can be used:
- As a child of a
rubyelement. - Content model:
- Phrasing content.
- Content attributes:
- Global attributes
- DOM interface:
- Uses
HTMLElement.
An rb (“ruby base”) element
that is the child of a ruby element
represents a ruby base unit:
a unitary component of base-level text
annotated by any ruby annotation(s) to which it is paired.
An rb element that is not a child of a ruby element
represents the same thing as its children.
rb element is used, the base is implied:
< ruby > base< rt > annotation</ ruby >
The element can also be made explicit:
< ruby >< rb > base< rt > annotation</ ruby >
Both markup patterns have identical semantics.
Explicit rb elements can be useful for styling,
and are necessary
when marking up consecutive bases to pair with consecutive annotations
(for example,
when representing a compound word;
see 京都市 inlining
and jukugo ruby examples above).
2.3.
The rt element
- Categories:
- None.
- Contexts in which this element can be used:
-
As a child of a
rubyor of anrtcelement. - Content model:
- Phrasing content.
- Content attributes:
- Global attributes
- Accessibility considerations:
- For authors.
- For implementers.
- DOM interface:
- Uses
HTMLElement.
An rt (“ruby text”) element
that is the child of a ruby element
or of an rtc element
that is itself the child of a ruby element
represents a ruby annotation unit:
a unitary annotation of the ruby base unit to which it is paired.
An rt element that is not a child of a ruby element
nor of an rtc element
that is itself the child of a ruby element
represents the same thing as its children.
2.4.
The rtc element
- Categories:
- None.
- Contexts in which this element can be used:
-
As a child of a
rubyelement. - Content model:
-
Either phrasing content or a sequence of
rtelements; optionally preceded, interleaved with, or followed by individualrpelements. - Content attributes:
- Global attributes
- DOM interface:
- Uses
HTMLElement.
An rtc (“ruby text container”) element
that is the child of a ruby element
represents one level of annotation
(a ruby annotation range)
for the preceding sequence of ruby base units
(its ruby base range).
Note: In simple cases,
rtc elements can be omitted
as a ruby annotation range is implied
by consecutive rt elements.
However, they are necessary
in order to associate multiple levels of annotation
with a single ruby base range,
for example to provide both phonetic and semantic information,
phonetic information in different scripts,
or semantic information in different languages.
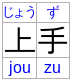
This enabled by the following markup:
< ruby >< rb > 上< rb > 手< rt > じよう< rt > ず< rtc >< rt > jou< rt > zu</ ruby >
Note: Text that is a direct child of the rtc element
implicitly represents a ruby annotation unit
as if it were contained in an rt element,
except that this annotation spans all the bases in the segment.

Which is marked up as follows:
< ruby >< rb > 旧< rb > 金< rb > 山< rt > jiù< rt > jīn< rt > shān< rtc > San Francisco</ ruby >
Here, a single base run of three base characters
is annotated with three pinyin ruby text segments
in a first (implicit) container,
and an rtc element is introduced
in order to provide a second single ruby annotation
being the city’s English name.
An rtc element that is not a child of a ruby element
represents the same thing as its children.
2.5.
The rp element
- Categories:
- None.
- Contexts in which this element can be used:
-
As a child of a
rubyorrtcelement, either immediately before or immediately after anrtcelement or a ruby annotation unit. - Content model:
- Text.
- Content attributes:
- Global attributes
- Accessibility considerations:
- For authors.
- For implementers.
- DOM interface:
- Uses
HTMLElement.
The rp (“ruby parenthetical”) element represents nothing.
It is used to provide presentational content
(such as parentheses)
around ruby annotation units,
to be shown when presenting ruby content inline,
without using ruby-specific layout.
This may happen when using a user agent that does not support ruby layout,
or for stylistic reasons.
In typical ruby layout,
it is not displayed.
rp so that in legacy user agents the readings are in parentheses:
...< ruby > 漢< rb > 字< rp > (< rt > かん< rt > じ< rp > )</ ruby > ...
In user agents that support ruby layout, the rendering omit the parentheses, but in user agents that do not, the rendering would be:
...漢字(かんじ)...
rp elements as well:
< ruby >
< rb > ♥< rp > : < rt > Heart< rp > , < rtc lang = fr > Cœur</ rtc >< rp > .</ rp >
< rb > ☘< rp > : < rt > Shamrock< rp > , < rtc lang = fr > Trèfle</ rtc >< rp > .</ rp >
< rb > ✶< rp > : < rt > Star< rp > , < rtc lang = fr > Étoile</ rtc >< rp > .</ rp >
</ ruby >
This would make the example render as follows in non-ruby-capable user agents:
♥: Heart, Cœur. ☘: Shamrock, Trèfle. ✶: Star, Étoile.
3. Optional Tags
rt and rp,
and adding two more for rb and rtc.
An rb element’s end tag may be omitted
if the rb element is immediately followed by
an rb, rt, rtc or rp element,
or if there is no more content in the parent element.
An rt element’s end tag may be omitted
if the rt element is immediately followed by
an rb, rt, rtc or rp element,
or if there is no more content in the parent element.
An rtc element’s end tag may be omitted
if the rtc element is immediately followed by
an rb or rtc element,
or if there is no more content in the parent element.
An rp element’s end tag may be omitted
if the rp element is immediately followed by
an rb, rt, rtc or rp element,
or if there is no more content in the parent element.
4. Rendering
rp { display : none; } rule
which belongs in the HTML § 15.3.1 Hidden elements subsection.
Note: HTML § 15.3.4 Phrasing content contains additional requirements about ruby; they are not overridden or invalidated by this specification and continue to apply.
The following rules are added to the HTML user agent style sheet:
ruby { display : ruby; }
rb { display : ruby-base; white-space : nowrap; }
rbc { display : ruby-base-container; } /* For compatibility with XHTML-inspired markup */
rp { display : none; }
rt { display : ruby-text; }
rtc { display : ruby-text-container; }
ruby, rb, rbc, rt, rtc { unicode-bidi : isolate; }
rtc, rt {
font-variant-east-asian : ruby;
text-emphasis : none;
white-space : nowrap;
line-height : 1 ;
}
rtc, :not( rtc) > rt {
font-size : 50 % ;
}
rtc:lang( zh-TW), :not( rtc) > rt:lang( zh-TW) {
font-size : 30 % ;
}
5. Conforming Features
rb and rtc are included
in the list of “entirely obsolete” elements
which “must not be used by authors”
in HTML § 16.2 Non-conforming features,
this specification revokes this obsolete status,
and deems these two elements fully conforming.
6. Interaction
6.1. Text search
This section is non-normative
[HTML] defines the find-in-page operation and its general mechanics
but leaves undefined
the exact way matches are determined from the query.
A window.find() API is also supported by various HTML user agents,
but at the time of writing does not have a normative specification,
and the specifics of how to determine
if particular search string matches in a document
are also undefined.
Accordingly, this specification does not attempt to define a normative behavior for the interaction of text search with ruby. However, some general user expectations can be noted, which user agents are encouraged to take into account when implementing such functionality.
- Users typically do not expect the presence of ruby annotations to interfere with search. Whether a word or phrase has ruby annotations or not, and regardless of the markup pattern used to insert such annotations, users expect to be able find the base text. Given that users have generally no awareness of the specific markup pattern used, this is the case even when annotations are interleaved between nodes of base text and the query text is not found uninterrupted in the document.
- Similarly, when ruby annotations appear in the markup after a word they annotate and before another word, users generally have no awareness that there is anything between the two words, and would typically expect a query string composed of these two words to find a match.
- In addition to base text, users may also search for text contained in ruby annotations. Here too, markup patterns are unknown and irrelevant to users, who will generally expect to find what they think of as a word or phrase, regardless of whether the text appears contiguously in the markup or whether the markup contains interleaved ruby bases and annotations.
-
As
rpelements are generally invisible, users also typically expect their searches to be unaffected by their presence.
< ruby >< rb > 東< rb > 京< rt > とう< rt > きょう</ ruby > に行く。
< ruby >< rb > 東< rt > とう< rb > 京< rt > きょう</ ruby > に行く。
< ruby >< rb > 東< rb > 京< rp > (< rt > とう< rt > きょう< rp > )</ ruby > に行く。
This is expectation is not only present when searching for the word in isolation, but also when combined with surrounding text, such as searching for “東京に行く” or “とうきょうに行く”, which a user would also typically expect to match.
Note: See also [string-search] for further considerations regarding the complexities of searching text.
6.2. Copy & Pasting
This section is non-normative
The web platform does not specify precisely the details of the copy & paste clipboard operations. In particular, while the clipboard generally supports both structured text and plain text, how one gets converted to the other, and how the content of the document gets extracted into the clipboard when copying is not generally defined.
Accordingly, this specification does not attempt to define a normative behavior for the interaction of the clipboard with ruby. However, some general user expectations can be noted, which user agents are encouraged to take into account when implementing such functionality.
-
When converting annotated ruby text to plain text
via copy & paste,
the user agent could keep the base text alone,
include both base and annotation text,
or offer the user a choice of copy & paste with or without ruby annotations.
If both ruby bases and annotations are included in a plain text rendering, they need to be linearised. In this context, it would be appropriate to render otherwise hidden
rpelements. The expectation expressed in HTML § 15.3.4 Phrasing content that user agents which do not support correct ruby rendering are to render parentheses around the text ofrtelements in the absence ofrpelements is also relevant to this context.Consider a user selecting and copying either of the following text snippets, and pasting into atextarea:My name is< ruby >< rb > 網< rb > 本< rt > あみ< rt > もと</ ruby > My name is< ruby >< rb > 網< rb > 本< rp > (< rt > あみ< rt > もと< rp > )</ ruby > Either of
My name is 網本
orMy name is 網本(あみもと)
could be expected. However,My name is 網本あみもと
keeps the annotation but merges it with the base text without doing anything to indicate that it is an annotation, and which is potentially confusing to the reader. - Users generally expect to be able to copy what they can select. If they specifically select either base text or annotation text, that is would be typically expected to be found in the clipboard after a copy operation. In other words, simply discarding all annotations unconditionally in all plain-text copy & paste operations is unlikely to meet user expectations.
Appendix A: Editorial Tweaks to HTML
This section is non-normative
In complement to the normative statements made in the main body of this specification, this section details additional editorial changes that would be desirable to make to the HTML Standard in order to make it fully align it with what is covered here.
-
Remove the outdated informative description
of CSS anonymous box generation for ruby bases
in the following paragraph in HTML § 15.3.4 Phrasing content:
For the purposes of the CSS ruby model, runs of children of
rubyelements that are notrtorrpelements are expected to be wrapped in anonymous boxes whose display property has the value ruby-base. [CSS-RUBY-1]The matter is already covered in exhaustive detail by CSS Ruby Annotation Layout 1 § 2.2 Anonymous Ruby Box Generation.
-
Replace the following note in HTML § 15.3.4 Phrasing content:
Note: When it becomes possible to do so, the preceding requirement will be updated to be expressed in terms of CSS ruby. (Currently, CSS ruby does not handle nested
rubyelements or multiple sequentialrtelements, which is how this semantic is expressed.)Note: In CSS, this is achieved by default: the initial value of the ruby-position property is alternate, which produces this effect.
-
Replacing the
row of the table in HTML § 4.5.29 Usage summary, with the following:ruby,rt,rpElement Purpose Example ruby,rb,rt,rtc,rpRuby annotations < ruby > < rb > 旧< rb > 金< rb > 山< rp > (< rt > jiù< rt > jīn< rt > shān< rtc > < rp > :</ rp > San Francisco</ rtc > < rp > )</ ruby > -
Updating the table at HTML § Elements
to add rows for
rbandrtc, and to replace the rows forrp,rt, andruby, as follows:Element Description Categories Parents† Children Attributes Interface rbRuby base none rubyphrasing globals HTMLElementrpParenthesis for ruby annotation text none ruby;rtctext globals HTMLElementrtRuby annotation text none ruby;rtcphrasing globals HTMLElementrtcRuby annotation container none rubyphrasing; rt;rpglobals HTMLElementrubyRuby annotation(s) flow; phrasing; palpable phrasing phrasing; rb;rt;rtc;rp*globals HTMLElement -
Updating the table at HTML § Element interfaces
to add the following two rows:
Element(s) Interface(s) rbHTMLElementrtcHTMLElement
Appendix B: Comparison With The HTML Standard
This section is non-normative
Note: This comparison is based on the state of the HTML Standard at the time of writing this document. If the HTML Standard adopts some or all of the changes described here, or otherwise evolves its handling of ruby, this section is expected to be updated accordingly, but there could be a delay before this happens.
While this specification reintroduces the previously obsoleted rb and rtc elements,
it makes no changes to HTML § 13.2 Parsing HTML documents:
these elements are handled there already,
including their optional end tags.
There are, however, differences in how the various ruby related elements can be used, the two essential ones being:
-
In addition to the ability to interleave
rtelements between anonymous ruby bases, the previously obsoletedrbelement is restored, enabling the so-called tabular markup pattern where several consecutive bases are followed their respective annotations:< ruby > < rb > …< rb > …< rb > …< rt > …< rt > …< rt > …</ ruby > Without
rband tabular markup, in order to have the individual base/annotation pairing necessary to correct handle the various possible presentations of ruby on compound words, interleaving thertelements between segments of base text would be required. However, such this markup would not enable correct ruby inlining.Moreover, interleaved markup is also a source of issues with operations like copy&paste, searching through the document, or speech synthesis, due to the base text being interrupted by the annotations. In the case of search, the user agent can mitigate this problem, but it remains an issue in simpler user agents and for operations other than search.
-
This document defines a different model for handling multiple levels of annotations:
-
The ability to associate multiple consecutive
rtelements with the preceding base text segment without using explicit annotation containers is dropped. This pattern does not have interoperable implementations with the semantics intended by the HTML Standard, and is in tension with tabular markup.Instead, the previously obsoleted
rtcelement is restored, providing the ability to indicate multiple annotation ranges over the same base(s), using either interleaved or tabular markup patterns. -
While the ability to nest ruby is retained,
specialized semantics for nested ruby are dropped.
That markup pattern is strictly less expressive
than using
rtcfor additional levels of annotations, since it does not allow pairing individual annotations in the outer ruby with individual bases in the inner ruby. The example about “上手” can therefore be realized usingrtcbut could not be with nested ruby.Nested ruby as defined in the HTML Standard also does not have interoperable implementations beyond the ordinary semantics of nesting, and is at odds with the layout model of CSS Ruby Annotation Layout Module Level 1.
-
The ability to associate multiple consecutive
A 2011 blog post by fantasai explains in more details these requirements and resulting design choices.
Appendix C: Security Considerations
This section is non-normative
This specification has no known security implication.
Appendix D: Privacy Considerations
This section is non-normative
This specification has no known privacy implication.
Appendix E: Accessibility Considerations
This section is non-normative
Since its predominant usage is as a pronunciation guide, ruby is itself an accessibility oriented feature, enabling readers with varying levels of literacy to access what could otherwise be challenging or impossible to read. In this usage, ruby can be helpful for people such as children or non-native speakers in the process of learning to read, people with various learning or other cognitive disabilities, or people under-privileged backgrounds and with a limited education…
A key motivation for this extension specification is recognizing the diversity of uses of ruby, as well as the diversity of users and corresponding expectations, and ensuring that the available markup patterns can provide the necessary structural information to accommodate diverse situations.
People with dyslexia may find different visual presentations of the same content more or less easy to read. Among over variants, some may prefer ruby annotations to be colored differently, to be spaced apart from the characters they annotate, or to be shown as an inline parenthetical, in order to make them easier to distinguish from the text they annotate. Similarly, usage in educational contexts can call for a range of presentational variants. While this specification does not directly cover visual layout, the markup patterns defined here are deliberately designed to enable authors to express relevant structural information about ruby annotations which in turn can be used by styling languages like CSS to offer varied presentations supporting user needs and preferences, without needing to change nor compromise the markup to do so. See [CSS-RUBY-1].
People with limited vision or no vision often rely on tools such as screen readers to provide an alternative or complementary audio rendering of the document. HTML Ruby markup and corresponding text-to-speech questions predate this specification, which neither introduces nor resolves these matters. This extension specification acknowledges that different usages of ruby can benefit from different audio renderings, but does not introduce any new mechanism to address this need, as it focuses on advancing different aspects of the problem. This important consideration is expected to be addressed by subsequent up work. In the meanwhile, HTML user agents and screen readers are encouraged to consider heuristic methods to determine the most helpful text-to-speech rendering. (See [RUBY-TTS-REQ] for discussion of common patterns and text-to-speech expectations in Japanese.)
Appendix F: Acknowledgements
This section is non-normative
This document derives from several sources (which to some degree also derive from each other). We would like to thank the contributors to all these sources, notably:
-
The many editors and contributors of the HTML Standard
-
Robin Berjon, editor of the previous version of W3C HTML Ruby Markup Extensions
-
The editors and contributors of Ruby Annotation
In addition, none of this would be possible without the expert input, many years of research, and extensive documentation by the participants of the Internationalization Working Group, notably:
-
The many contributors to Requirements for Japanese Text Layout 日本語組版処理の要件(日本語版)
-
The many contributors to Requirements for Chinese Text Layout - 中文排版需求
-
Richard Ishida
-
Elika J. Etemad (aka. fantasai)
Appendix F: Changes
This section is non-normative
Changes since the 4 June 2026 Candidate Recommendation
Significant changes since the 06 June 2026 Working Draft:
-
None yet
Changes since the 07 May 2024 Working Draft
Significant changes since the 07 May 2024 Working Draft:
-
Addition of the non-normative Appendix E: Accessibility Considerations section.
-
Addition of the non-normative § 6 Interaction section.
-
Various editorial tweaks to clarify examples, notes, and introductory prose.
Changes since the 04 February 2014 W3C HTML Ruby Markup Extensions Working Group Note
The markup model described here is substantially the same as the one established by the 2014 Working Group Note, though the text describing it, as well as the examples, has been extensively reworked.
The parsing changes proposed in the 2014 Working Group Note are no longer discussed here as they have since been adopted by the HTML Standard.
Appendix G: CR exit criteria
For this specification to be advanced to Proposed Recommendation, there must be at least two independent, interoperable implementations of each feature. Each feature may be implemented by a different set of products, there is no requirement that all features be implemented by a single product. For the purposes of this criterion, we define the following terms:
- independent
- each implementation must be developed by a different party and cannot share, reuse, or derive from code used by another qualifying implementation. Sections of code that have no bearing on the implementation of this specification are exempt from this requirement.
- interoperable
- passing the respective test case(s) in the official test suite.
- implementation
-
a user agent which:
- implements the specification.
- is available to the general public. The implementation may be a shipping product or other publicly available version (i.e., beta version, preview release, or "nightly build"). Non-shipping product releases must have implemented the feature(s) for a period of at least one month in order to demonstrate stability.
- is not experimental (i.e., a version specifically designed to pass the test suite and is not intended for normal usage going forward).
The specification will remain Candidate Recommendation for at least 28 days.